14 Κεφάλαιο: Εισαγωγή στα Πολυμεταβλητά Μοντέλα
Ο σκοπός των μοντέλων δεν είναι να προσαρμόζονται στα δεδομένα, αλλά να αποσαφηνίζουν το ερώτημα.
— Samuel Karlin
14.1 Εισαγωγή
Μέχρι τώρα, έχουμε εξετάσει μοντέλα με μία μόνο ανεξάρτητη (ή προβλεπτική) μεταβλητή (θα τα ονομάζουμε μοντέλα μίας προβλεπτικής μεταβλητής — single-predictor models). Σε αυτό το μέρος του βιβλίου κάνουμε μια εισαγωγή στα πολυμεταβλητά μοντέλα (multivariate models), δηλαδή μοντέλα με περισσότερες από μία προβλεπτικές μεταβλητές.
Θα ξεκινήσουμε κατασκευάζοντας ένα μοντέλο με μία ποιοτική ανεξάρτητη μεταβλητή και μία ποσοτική ανεξάρτητη μεταβλητή. Θα συγκρίνουμε αυτό το πολυμεταβλητό μοντέλο με το κενό μοντέλο και με τα επιμέρους μοντέλα μίας ανεξάρτητης μεταβλητής που το συνθέτουν.
Μόλις κατανοήσετε αυτό το μοντέλο, θα είστε σε θέση να επεκτείνετε αυτά που γνωρίζετε σε ένα ολόκληρο φάσμα μοντέλων, συμπεριλαμβανομένων μοντέλων με περισσότερες από δύο μεταβλητές, μοντέλων με πολλαπλές ποιοτικές ανεξάρτητες μεταβλητές και μοντέλα με πολλαπλές ποσοτικές ανεξάρτητες μεταβλητές. Όπως θα διαπιστώσετε, όλα αυτά τα μοντέλα ανήκουν στην οικογένεια του Γενικού Γραμμικού Μοντέλου (General Linear Model).
14.2 Μοντέλα με Δύο Ανεξάρτητες Μεταβλητές
Για παράδειγμα, σε προηγούμενα κεφάλαια μοντελοποιήσαμε τα φιλοδωρήματα που αφήνουν οι πελάτες εστιατορίου ως συνάρτηση του αν οι σερβιτόροι ζωγράφισαν ένα χαμογελαστό πρόσωπο στον λογαριασμό (Tip = Smiley Face + Άλλα Πράγματα) και ως συνάρτηση της ποιότητας του φαγητού (Tip = Food Quality + Άλλα Πράγματα).
Ωστόσο, οι περισσότερες εξαρτημένες μεταβλητές που μας ενδιαφέρουν μπορούν να προβλεφθούν ταυτόχρονα από πολλαπλές ανεξάρτητες μεταβλητές. Γίνεται εύκολα αντιληπτό ότι οι περισσότερες εξαρτημένες μεταβλητές μπορούν να εξηγηθούν από περισσότερες από μία ανεξάρτητες μεταβλητές, και συνήθως όσο περισσότερες ανεξάρτητες μεταβλητές προσθέτουμε σε ένα μοντέλο, τόσο μεγαλύτερο μέρος της διακύμανσης (ή της μεταβλητότητας) της εξαρτημένης μεταβλητής θα εξηγείται.
Σε αυτό το κεφάλαιο θα εστιάσουμε στον ορισμό, την προσαρμογή και την ερμηνεία πολυμεταβλητών μοντέλων. Όπως και πριν, θα βασιστούμε στο Γενικό Γραμμικό Μοντέλο και θα το επεκτείνουμε ώστε να περιλαμβάνει περισσότερες από μία ανεξάρτητες μεταβλητές. Όπως θα δείτε, θα μπορείτε να εφαρμόσετε τα όσα έχετε μάθει μέχρι τώρα για να κατανοήσετε αυτά τα νέα μοντέλα.
Θα εξακολουθεί να ισχύει ότι ΔΕΔΟΜΕΝΑ = ΜΟΝΤΕΛΟ + ΣΦΑΛΜΑ. Αλλά καθώς προσθέτουμε περισσότερες μεταβλητές στο ΜΟΝΤΕΛΟ, θα μπορούμε να μειώνουμε το ποσό του ΣΦΑΛΜΑΤΟΣ που παραμένει ανεξήγητο.
Τιμές Κατοικιών στο Smallville
Ας εξετάσουμε ένα νέο σύνολο δεδομένων που αναφέρεται στις πωλήσεις 32 κατοικιών σε μια πόλη που θα αποκαλούμε Smallville. Το πλαίσιο δεδομένων Smallville περιλαμβάνει τέσσερις μεταβλητές για κάθε πώληση κατοικίας:
-
PriceK— Τιμή πώλησης της κατοικίας σε χιλιάδες δολάρια. -
Neighborhood— Σε ποια γειτονιά βρίσκεται η κατοικία (ποιοτική μεταβλητή με δύο κατηγορίες,DowntownήEastside). -
HomeSizeK— Εμβαδόν της κατοικίας σε τετραγωνικά πόδια, σε χιλιάδες. -
HasFireplace— Αν η κατοικία διαθέτει τζάκι ή όχι (ποιοτική μεταβλητή με δύο κατηγορίες, 1 ή 0).
Θα ξεκινήσουμε με δύο μοντέλα που προβλέπουν την τιμή πώλησης: το μοντέλο της γειτονιάς (Neighborhood) και το μοντέλο του μεγέθους της κατοικίας (HomeSizeK):
PriceK = Neighborhood + Άλλα Πράγματα
PriceK = HomeSizeK + Άλλα Πράγματα
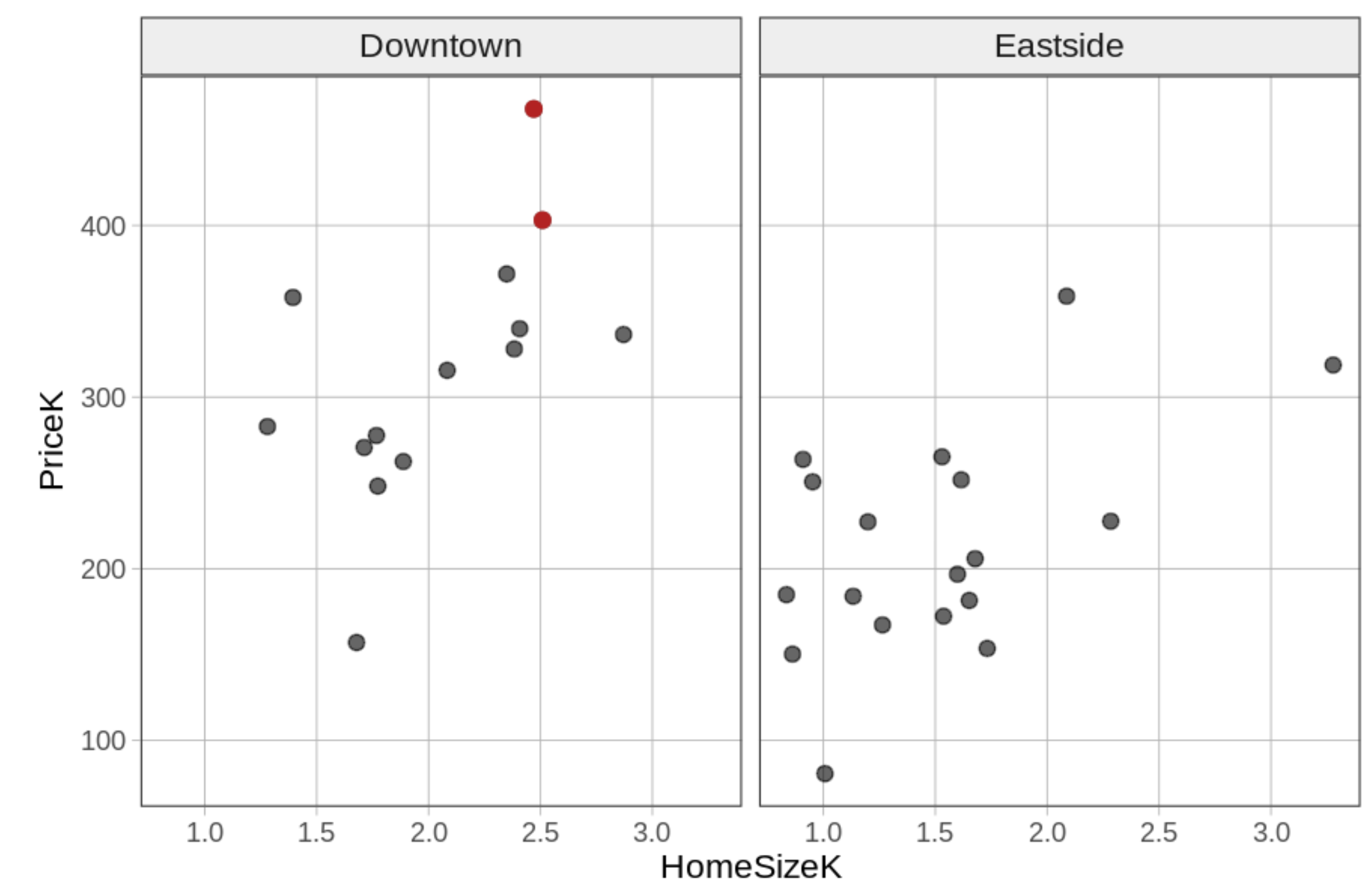
Τα δύο μοντέλα μίας ανεξάρτητης μεταβλητής φαίνονται στα παρακάτω διαγράμματα.
 **Παρατηρήστε ότι αυτές οι κατοικίες στο Smallville προέρχονται από δύο διαφορετικές γειτονιές: Downtown και Eastside. Οι κατοικίες διαφέρουν επίσης σε μέγεθος — κάποιες είναι μικρότερες από 1000 τετραγωνικά πόδια (ή 1K) και άλλες φτάνουν τα 3000 τετραγωνικά πόδια.
**Παρατηρήστε ότι αυτές οι κατοικίες στο Smallville προέρχονται από δύο διαφορετικές γειτονιές: Downtown και Eastside. Οι κατοικίες διαφέρουν επίσης σε μέγεθος — κάποιες είναι μικρότερες από 1000 τετραγωνικά πόδια (ή 1K) και άλλες φτάνουν τα 3000 τετραγωνικά πόδια.
Ποια από τα παρακάτω είναι σωστά με βάση τα διαγράμματα; (Επιλέξτε όλες τις σωστές απαντήσεις.)**
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β, Γ και Ε.
Β: Αν και οι δύο κατανομές επικαλύπτονται, ο μέσος όρος στη γειτονιά Downtown είναι υψηλότερος από αυτόν στην Eastside, οπότε το μοντέλο θα προέβλεπε υψηλότερη τιμή για μια κατοικία στην Downtown.
Γ και Ε: Και τα δύο περιγράφουν τη θετική συσχέτιση μεταξύ μεγέθους και τιμής — μεγαλύτερη κατοικία → υψηλότερη προβλεπόμενη τιμή.
Α: Λάθος — οι δύο κατανομές επικαλύπτονται, οπότε υπάρχουν κατοικίες στην Eastside που είναι ακριβότερες από κάποιες κατοικίες στην Downtown.
Δ: Λάθος — αντίθετη κατεύθυνση σχέσης.
Και τα δύο μοντέλα με μία ανεξάρτητη μεταβλητή φαίνεται να εξηγούν κάποιο μέρος της διακύμανσης των τιμών των κατοικιών — η γνώση του σε ποια γειτονιά βρίσκεται μια κατοικία μάς βοηθά να κάνουμε καλύτερη πρόβλεψη για την τιμή της, όπως και η γνώση του μεγέθους της. Κανένα μοντέλο, ωστόσο, δεν εξηγεί ολόκληρη τη διακύμανση της τιμής κατοικίας. Υπάρχει ακόμα αρκετό ανεξήγητο σφάλμα (αυτό που έχουμε ονομάσει «Άλλα Πράγματα»).
Θα μπορούσαμε απλώς να επιλέξουμε το μοντέλο με μία ανεξάρτητη μεταβλητή που είναι καλύτερο από τα δύο. Γράψτε κώδικα για να δημιουργήσετε τους πίνακες ANOVA από αυτά τα δύο μοντέλα (τα έχουμε ήδη αποθηκεύσει ως Neighborhood_model και HomeSizeK_model) για να δείτε ποιο εξηγεί τη μεγαλύτερη διακύμανση στην PriceK.
Analysis of Variance Table (Type III SS)
Model: PriceK ~ Neighborhood
SS df MS F PRE p
----- --------------- | ---------- -- --------- ------ ------ -----
Model (error reduced) | 82399.351 1 82399.351 16.842 0.3595 .0003
Error (from model) | 146778.142 30 4892.605
----- --------------- | ---------- -- --------- ------ ------ -----
Total (empty model) | 229177.493 31 7392.822Analysis of Variance Table (Type III SS)
Model: PriceK ~ HomeSizeK
SS df MS F PRE p
----- --------------- | ---------- -- --------- ------ ------ -----
Model (error reduced) | 96644.769 1 96644.769 21.876 0.4217 .0001
Error (from model) | 132532.724 30 4417.757
----- --------------- | ---------- -- --------- ------ ------ -----
Total (empty model) | 229177.493 31 7392.822Όπως φαίνεται, το καλύτερο μοντέλο θα ήταν αυτό του μεγέθους της κατοικίας. Σε σύγκριση με το κενό μοντέλο, το μοντέλο του μεγέθους της κατοικίας οδήγησε σε μια τιμή PRE (Proportional Reduction in Error — Αναλογική Μείωση Σφάλματος) ίση με 0.42 (ή 42%), σε σύγκριση με μια τιμή PRE ίση με 0.36 (ή 36%) για το μοντέλο της γειτονιάς. Επομένως, οι προβλέψεις από το μοντέλο του μεγέθους της κατοικίας είναι πιο ακριβείς.
Αλλά είναι δυνατόν να πετύχουμε ακόμα υψηλότερη τιμή PRE αν συμπεριλάβουμε και τις δύο ανεξάρτητες μεταβλητές ταυτόχρονα στο μοντέλο; Ένας άλλος τρόπος να θέσουμε αυτό το ερώτημα είναι: θα μπορούσε κάποιο μέρος του σφάλματος που απομένει μετά την προσαρμογή του μοντέλου της HomeSizeK να μειωθεί περαιτέρω προσθέτοντας τη Neighborhood στο ίδιο μοντέλο; Ή, αν γνωρίζαμε τόσο το μέγεθος όσο και τη γειτονιά μιας κατοικίας, θα μπορούσαμε να κάνουμε καλύτερη πρόβλεψη για την τιμή της από ό,τι αν γνωρίζαμε μόνο το ένα ή μόνο το άλλο;
Θα μπορούσαμε να αναπαραστήσουμε αυτή την ιδέα ως εξής:
PriceK = HomeSizeK + Neighborhood + Άλλα Πράγματα
14.3 Οπτικοποίηση του μοντέλου Price = Home Size + Neighborhood
Ας εξετάσουμε αυτή την ιδέα διαγραμματικά. Θα ξεκινήσουμε με ένα διάγραμμα του μοντέλου του μεγέθους της κατοικίας, αναπαριστώντας τη σχέση ανάμεσα στη μεταβλητή PriceK και τη μεταβλητή HomeSizeK, με τον κώδικα gf_point(PriceK ~ HomeSizeK, data = Smallville). Στη συνέχεια θα εξετάσουμε κάποιους τρόπους με τους οποίους θα μπορούσαμε να οπτικοποιήσουμε την επίδραση της μεταβλητής Neighborhood λαμβάνοντας υπόψη ταυτόχρονα την επίδραση της HomeSizeK.
Χρήση Διαιρεμένων Διαγραμμάτων
Ορίστε το διάγραμμα διασποράς της PriceK σε σχέση με τη HomeSizeK για τις 32 κατοικίες στο Smallville.
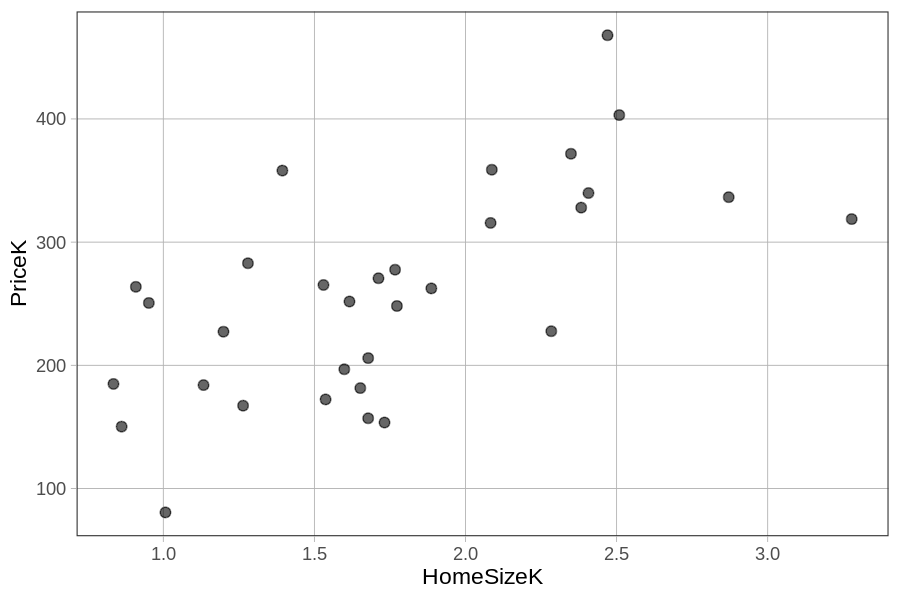
Ένας τρόπος να παρουσιάσουμε τη μεταβλητή Neighborhood στο ίδιο διάγραμμα είναι να φτιάξουμε ένα διάγραμμα διασποράς για κάθε διαφορετική γειτονιά. Μπορούμε να το κάνουμε αυτό προσθέτοντας την εντολή gf_facet_grid(. ~ Neighborhood).
Παρατηρήστε ότι για να βάλουμε τα διαγράμματα δίπλα-δίπλα (δηλαδή κατά μήκος του άξονα x), βάζουμε τη μεταβλητή μετά το σύμβολο ~: . ~ Neighborhood.
Εκτελέστε το παρακάτω τμήμα κώδικα για να βάλετε τα δύο διαγράμματα διασποράς δίπλα-δίπλα, ένα για κάθε γειτονιά:
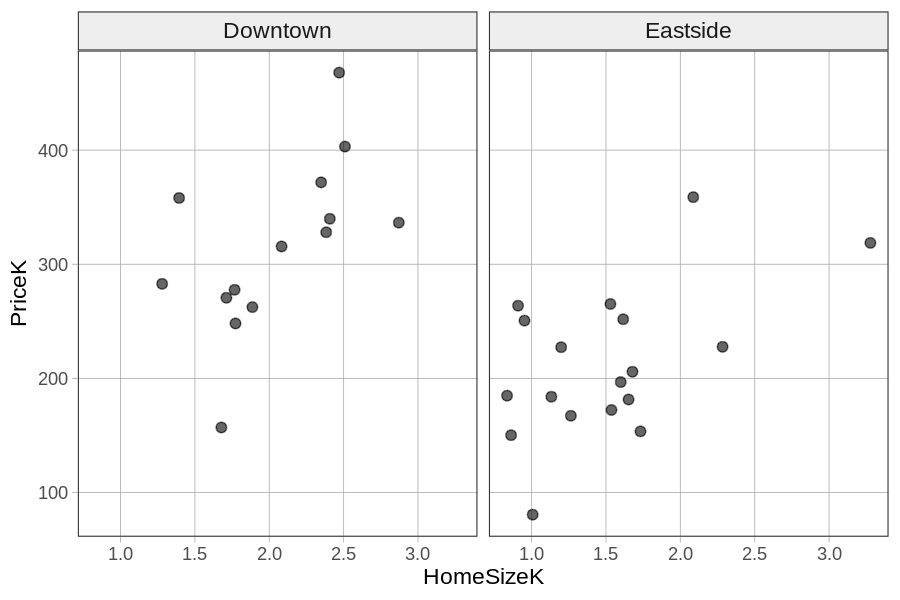
Τώρα που μπορούμε να δούμε τόσο τη Neighborhood όσο και τη HomeSizeK σε σχέση με την τιμή κατοικίας, μπορούμε να καταλήξουμε σε πιο καλύτερα συμπεράσματα.
Με βάση το παραπάνω διάγραμμα, ποια από τις παρακάτω κατοικίες θα προβλέπατε ότι έχει την υψηλότερη τιμή;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Με βάση το διάγραμμα, παρατηρούμε δύο πράγματα: (1) οι κατοικίες στο Downtown τείνουν να έχουν υψηλότερες τιμές από τις κατοικίες στο Eastside, και (2) οι μεγαλύτερες κατοικίες τείνουν να έχουν υψηλότερες τιμές. Μια μεγάλη κατοικία στο Downtown συνδυάζει και τους δύο παράγοντες που σχετίζονται με υψηλές τιμές, οπότε θα προβλέπαμε ότι θα έχει την υψηλότερη τιμή. Οι απαντήσεις Α και Β λαμβάνουν υπόψη μόνο έναν από τους δύο παράγοντες, ενώ η Γ αναφέρεται σε μεγάλο μέγεθος κατοικίας στη χαμηλότερου κόστους γειτονιά.
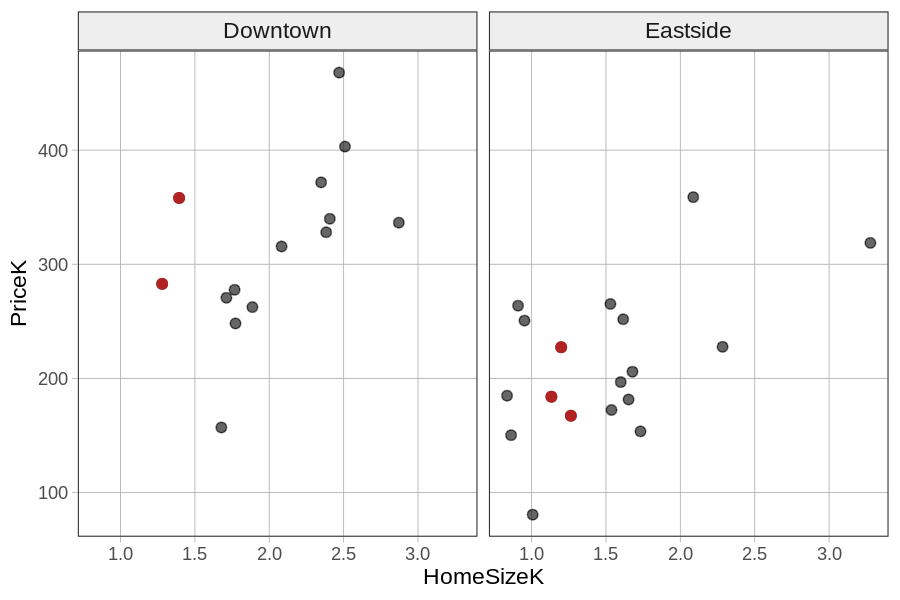
Με βάση αυτά τα διαγράμματα, μπορείτε να διαπιστώσετε ότι αν συνδυάσουμε όσα γνωρίζουμε για τη γειτονιά και για το μεγέθος της κατοικίας θα βελτιώναμε τις προβλέψεις μας. Ένας τρόπος να το δείτε αυτό είναι να κοιτάξετε, εντός της κάθε γειτονιάς, τις τιμές των κατοικιών με μέγεθος μεταξύ 1000 και 1500 τετραγωνικών ποδιών (δηλαδή HomeSizeK μεταξύ 1.0 και 1.5). Τα έχουμε χρωματίσει με κόκκινο στο παρακάτω διάγραμμα. Μπορείτε έτσι να δείτε ότι για κατοικίες ίδιου μεγέθους, οι τιμές είναι υψηλότερες στο Downtown από το Eastside.
Χρήση Χρώματος
Μια άλλη προσέγγιση για την προσθήκη της γειτονιάς στο διάγραμμα διασποράς της PriceK σε σχέση με τη HomeSizeK είναι να χρησιμοποιήσουμε διαφορετικά χρώματα για τις κατοικίες που βρίσκονται σε διαφορετικές γειτονιές. Μπορείτε να το κάνετε αυτό προσθέτοντας το όρισμα color = ~ Neighborhood στην εντολή για το διάγραμμα διασποράς. (Το σύμβολο ~ δείχνει στην R ότι η Neighborhood είναι μεταβλητή.) Δοκιμάστε το στο παρακάτω τμήμα κώδικα.
Εμείς χρησιμοποιήσαμε τον παρακάτω κώδικα (προσθέτοντας και την ευθεία παλινδρόμησης) για να πάρουμε το παρακάτω διάγραμμα.
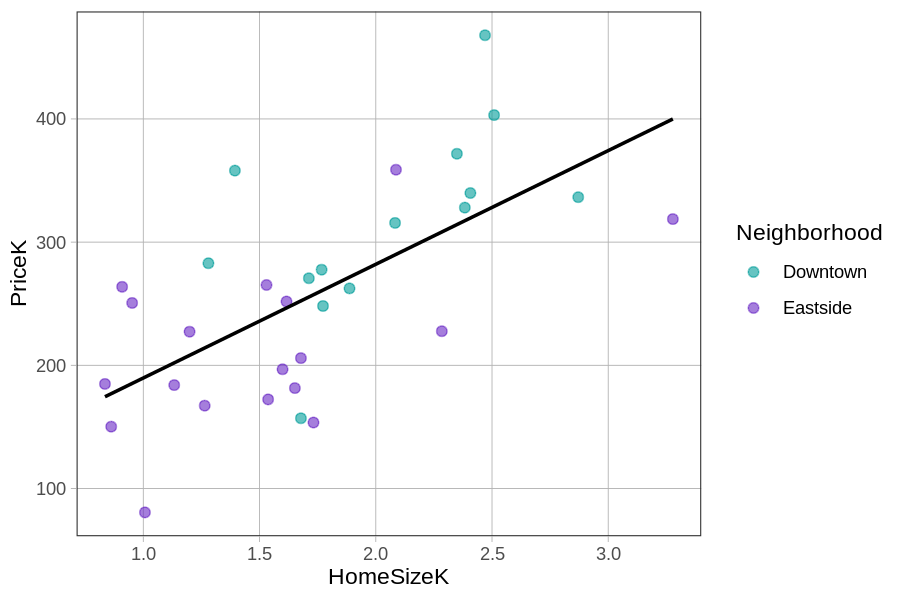 Η προσθήκη της ευθείας παλινδρόμησης μας διευκολύνει να δούμε τα σφάλματα (ή τα υπόλοιπα) του μοντέλου της
Η προσθήκη της ευθείας παλινδρόμησης μας διευκολύνει να δούμε τα σφάλματα (ή τα υπόλοιπα) του μοντέλου της HomeSizeK. Παρατηρήστε ότι τα κυανοπράσινα σημεία (κατοικίες στο Downtown) βρίσκονται κυρίως πάνω από την ευθεία παλινδρόμησης (δηλαδή έχουν θετικά υπόλοιπα στο το μοντέλο της HomeSizeK), ενώ τα μωβ σημεία (από το Eastside) βρίσκονται κυρίως κάτω από την ευθεία (αρνητικά υπόλοιπα).
Αυτό δείχνει ότι οι κατοικίες στο Downtown είναι γενικά ακριβότερες από ό,τι θα προέβλεπε το μοντέλο του μεγέθους της κατοικίας, ενώ στο Eastside είναι φθηνότερες. Αυτό το μοτίβο είναι μια ένδειξη ότι η προσθήκη της Neighborhood στο μοντέλο θα εξηγήσει επιπλέον διακύμανση στην PriceK, πέρα από αυτή που εξηγείται μόνο από την HomeSizeK.
14.4 Ορισμός και Προσαρμογή ενός Πολυμεταβλητού Μοντέλου
Μπορούμε να δούμε από τις διαγραμματικές αναπαραστάσεις των δεδομένων ότι ένα μοντέλο που περιλαμβάνει τόσο τη Neighborhood όσο και τη HomeSizeK μπορεί να μας βοηθήσει να κάνουμε καλύτερες προβλέψεις της PriceK απ’ ό,τι ένα μοντέλο που περιλαμβάνει μόνο μία από αυτές τις μεταβλητές. Μπορούμε να γράψουμε αυτό το μοντέλο δύο ανεξάρτητων μεταβλητών με μια λεκτική εξίσωση:
\(PriceK = Neighborhood + HomeSizeK + \text{Σφάλμα}\).
Ας δούμε τώρα πώς θα ορίζαμε και θα προσαρμόζαμε ένα τέτοιο μοντέλο.
Ορισμός ενός Πολυμεταβλητού Μοντέλου σε Σημειογραφία GLM
Μέχρι τώρα, ορίσαμε ένα μοντέλο με μία ανεξάρτητη και μία εξαρτημένη μεταβλητή ως εξής:
\[Y_i = b_0 + b_1 X_i + e_i\]
Ποια εξίσωση νομίζετε ότι θα χρησιμοποιήσουμε για να οριστεί ένα μοντέλο που περιλαμβάνει τόσο τη HomeSizeK όσο και τη Neighborhood ως ανεξάρτητες μεταβλητές;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Σε ένα μοντέλο με δύο ανεξάρτητες μεταβλητές (\(X_1\) και \(X_2\)), η καθεμία με το δικό της συντελεστή (\(b_1\) και \(b_2\)). Έτσι το μοντέλο γίνεται \(Y_i = b_0 + b_1 X_{1i} + b_2 X_{2i} + e_i\), όπου το \(X_{1i}\) θα μπορούσε να είναι η μεταβλητή HomeSizeK της κατοικίας \(i\) και το \(X_{2i}\) η μεταβλητή Neighborhood.
Η απάντηση Α είναι το μοντέλο με μία ανεξάρτητη μεταβλητή — δεν επαρκεί. Η Γ είναι ένα μοντέλο με τρεις ανεξάρτητες μεταβλητές, που είναι περισσότερες από όσες χρειαζόμαστε. Οι Δ και Ε είναι μοντέλα με μία ανεξάρτητη μεταβλητή, απλώς με συγκεκριμένα ονόματα μεταβλητών αντί για την αφηρημένη σημειογραφία \(X\) και \(Y\).
Επομένως, επεκτείνοντας τη σημειογραφία που χρησιμοποιήσαμε για το μοντέλο με μία ανεξάρτητη μεταβλητή, θα ορίσουμε το μοντέλο δύο ανεξάρτητων μεταβλητών ως εξής:
\[Y_i = b_0 + b_1 X_{1i} + b_2 X_{2i} + e_i\]
Αν και η παραπάνω εξίσωση μπορεί να φαίνεται πιο περίπλοκη, αν την εξετάσετε προσεκτικά μπορείτε να δείτε ότι είναι παρόμοια με το μοντέλο μίας ανεξάρτητης μεταβλητής. Το \(Y_i\) εξακολουθεί να αντιπροσωπεύει την εξαρτημένη μεταβλητή PriceK, και το \(e_i\), στο τέλος, εξακολουθεί να αντιπροσωπεύει το σφάλμα κάθε τιμής στα δεδομένα από την τιμή πρόβλεψης του μοντέλου. Επιπλέον, εξακολουθεί να έχει τη βασική δομή: ΔΕΔΟΜΕΝΑ = ΜΟΝΤΕΛΟ + ΣΦΑΛΜΑ.
Ποιο μέρος της σημειογραφίας GLM για το μοντέλο δύο ανεξάρτητων μεταβλητών αντιπροσωπεύει το μέρος του ΜΟΝΤΕΛΟΥ στη λεκτική εξίσωση ΔΕΔΟΜΕΝΑ = ΜΟΝΤΕΛΟ + ΣΦΑΛΜΑ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το ΜΟΝΤΕΛΟ στην εξίσωση ΔΕΔΟΜΕΝΑ = ΜΟΝΤΕΛΟ + ΣΦΑΛΜΑ είναι όλα όσα παράγουν την τιμή πρόβλεψης — δηλαδή ο σταθερός όρος \(b_0\) συν τη συνεισφορά κάθε ανεξάρτητης μεταβλητής. Αυτό είναι το \(b_0 + b_1 X_{1i} + b_2 X_{2i}\).
Η απάντηση Β παραλείπει τον σταθερό όρο \(b_0\), ο οποίος είναι μέρος του μοντέλου. Η Γ περιλαμβάνει το \(e_i\) (σφάλμα), το οποίο είναι το ΣΦΑΛΜΑ της εξίσωσης, όχι το ΜΟΝΤΕΛΟ.
Ας αναλύσουμε περισσότερο το ΜΟΝΤΕΛΟ της εξίσωσης. Ενώ προηγουμένως είχαμε μόνο ένα \(X\) στο μοντέλο, τώρα έχουμε δύο (\(X_1\) και \(X_2\)). Κάθε \(X\) αντιπροσωπεύει μία ανεξάρτητη μεταβλητή. Επειδή οι τιμές τους ποικίλλουν μεταξύ των παρατηρήσεων, έχουν το δείκτη \(i\). Για να ξεχωρίσουμε το ένα \(X\) από το άλλο, σημειώνουμε το ένα με το δείκτη 1 και το άλλο με το δείκτη 2. Το πρώτο από αυτά θα αντιπροσωπεύει τη μεταβλητή Neighborhood, το δεύτερο, τη μεταβλητή HomeSizeK, αν και το ποιο \(X\) αντιστοιχεί σε ποια μεταβλητή δεν έχει σημασία.
Παρατηρήστε επίσης ότι με το επιπλέον \(X\) προσθέτουμε στο μοντέλο και έναν νέο συντελεστή ή εκτίμηση παραμέτρου: το \(b_2\). Είπαμε προηγουμένως ότι το κενό μοντέλο είναι ένα μοντέλο μίας παραμέτρου, επειδή εκτιμούμε μόνο μία παράμετρο, το \(b_0\). Ένα μοντέλο μίας ανεξάρτητης μεταβλητής (π.χ. το μοντέλο του μεγέθους της κατοικίας) είναι ένα μοντέλο δύο παραμέτρων: έχει τόσο μια τιμή \(b_0\) όσο και μια τιμή \(b_1\).
Πόσες παραμέτρους εκτιμούμε στο πολυμεταβλητό μοντέλο (το μοντέλο που περιλαμβάνει τόσο τη Neighborhood όσο και τη HomeSizeK ως ανεξάρτητες μεταβλητές);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Στο πολυμεταβλητό μοντέλο \(Y_i = b_0 + b_1 X_{1i} + b_2 X_{2i} + e_i\) εκτιμούμε τρεις παραμέτρους:
- \(b_0\) — ο σταθερός όρος (intercept).
-
\(b_1\) — ο συντελεστής για τη
Neighborhood. -
\(b_2\) — ο συντελεστής για τη
HomeSizeK.
Το \(e_i\) δεν είναι παράμετρος που εκτιμούμε — είναι το υπόλοιπο για κάθε παρατήρηση, που υπολογίζεται μετά την προσαρμογή του μοντέλου. Γενικά, ο αριθμός των παραμέτρων σε ένα μοντέλο ισούται με 1 (ο σταθερός όρος) + ο αριθμός των ανεξάρτητων μεταβλητών. Για 2 ανεξάρτητες μεταβλητές: \(1 + 2 = 3\) παράμετροι.
Αυτό το πολυμεταβλητό μοντέλο είναι ένα μοντέλο τριών παραμέτρων: \(b_0\), \(b_1\) και \(b_2\).
Μπορούμε επίσης να γράψουμε το μοντέλο αντικαθιστώντας τα \(X\) με τα ονόματα των μεταβλητών:
\[PriceK_i = b_0 + b_1 Neighborhood_i + b_2 HomeSizeK_i + e_i\]
Προσαρμογή ενός Πολυμεταβλητού Μοντέλου
Έχοντας ορίσει τη βασική δομή του μοντέλου, στη συνέχεια θέλουμε να προσαρμόσουμε το μοντέλο, που σημαίνει να βρούμε τις βέλτιστες εκτιμήσεις παραμέτρων (δηλαδή τις τιμές των \(b_0\), \(b_1\) και \(b_2\)). Με τον όρο «βέλτιστες» εννοούμε τις εκτιμήσεις παραμέτρων που μειώνουν το σφάλμα γύρω από τις προβλέψεις του μοντέλου όσο το δυνατόν περισσότερο.
Αν και υπάρχουν αρκετοί αλγεβρικοί τρόποι να εκτιμηθούν οι τιμές των παραμέτρων, μπορείτε να φανταστείτε τον υπολογιστή να δοκιμάζει κάθε πιθανό συνδυασμό τριών αριθμών για να βρει το σύνολο που οδηγεί στο χαμηλότερο Άθροισμα Τετραγώνων των Σφαλμάτων (SS).
Αυτό μοιάζει λίγο σαν να «μαγειρεύουμε» τις τιμές πρόβλεψης του μοντέλου, όπου για να τις πάρουμε χρειάζεται να προσθέσουμε κάτι από τη μεταβλητή \(X_1\) (HomeSizeK) και κάτι από τη μεταβλητή \(X_2\) (Neighborhood). Με άλλα λόγια, οι βέλτιστες εκτιμήσεις μάς δείχνουν πόσο από κάθε μία μεταβλητή πρέπει να προσθέσουμε για να πάρουμε την καλύτερη δυνατή πρόβλεψη της PriceK.
Προηγουμένως, χρησιμοποιήσαμε για να προσαρμόσουμε το μοντέλο μίας ανεξάρτητης μεταβλητής (
Neighborhood) τηςPriceKτον παρακάτω κώδικα:lm(PriceK ~ Neighborhood, data = Smallville). Ποιος νομίζετε ότι θα ήταν ο κώδικας για την προσαρμογή του μοντέλου δύο ανεξάρτητων μεταβλητών που περιλαμβάνει τόσο τηNeighborhoodόσο και τηHomeSizeKγια την πρόβλεψη των τιμών πώλησης;
Χρησιμοποιήστε τη συνάρτηση lm() στο παρακάτω πλαίσιο κώδικα για να λάβετε τις βέλτιστες εκτιμήσεις παραμέτρων για το μοντέλο με δύο ανεξάρτητες μεταβλητές.
Call:
lm(formula = PriceK ~ Neighborhood + HomeSizeK, data = Smallville)
Coefficients:
(Intercept) NeighborhoodEastside HomeSizeK
177.25 -66.22 67.85Με κάποιον τρόπο, αυτά τα αποτελέσματα μας είναι οικεία. Ας προσπαθήσουμε να καταλάβουμε τι σημαίνουν αυτές οι εκτιμήσεις παραμέτρων.
Χρησιμοποιήσαμε την lm() για να προσαρμόσουμε αυτό το μοντέλο: \(Y_i = b_0 + b_1 X_{1i} + b_2 X_{2i} + e_i\). Αντιστοιχίστε τις τιμές των παραμέτρων του πολυμεταβλητού μοντέλου με το αντίστοιχο σύμβολο GLM.
| Εκτίμηση | Αντιστοιχεί σε |
|---|---|
| 67.85 |
\(b_2\) (συντελεστής της HomeSizeK, δηλαδή του \(X_{2i}\)) |
| 177.25 | \(b_0\) (σταθερός όρος / intercept) |
| −66.22 |
\(b_1\) (συντελεστής της NeighborhoodEastside, δηλαδή του \(X_{1i}\)) |
ΣημείωσηΕπεξήγηση
Στα αποτελέσματα της lm():
- Το
(Intercept)είναι ο σταθερός όρος, οπότε 177.25 = \(b_0\). - Το
NeighborhoodEastsideείναι ο συντελεστής για τηNeighborhood(κωδικοποιημένη ως ψευδομεταβλητή 0/1), οπότε −66.22 = \(b_1\), που πολλαπλασιάζεται με το \(X_{1i}\). - Το
HomeSizeKείναι ο συντελεστής για τηHomeSizeK, οπότε 67.85 = \(b_2\), που πολλαπλασιάζεται με το \(X_{2i}\).
Επομένως, με βάση τα αποτελέσματα της lm(PriceK ~ Neighborhood + HomeSizeK, data = Smallville), μπορούμε να γράψουμε το μοντέλο μας σε σημειογραφία GLM ως εξής:
\[Y_i = 177.25 + (-66.22) X_{1i} + 67.85 X_{2i}\]
Όπως και με το μοντέλο μίας ανεξάρτητης μεταβλητής, η R κωδικοποιεί τη Neighborhood, μια ποιοτική μεταβλητή, ως ψευδομεταβλητή (0/1) και της δίνει το όνομα NeighborhoodEastside, δηλαδή με 1 αν η κατοικία βρίσκεται στο Eastside, και 0 αν δεν βρίσκεται στο Eastside.
Μπορούμε επίσης να γράψουμε το μοντέλο ως εξής (κάτι που θα μας βοηθήσει να θυμόμαστε πώς είναι κωδικοποιημένη η Neighborhood):
\[PriceK_i = 177.25 + (-66.22) NeighborhoodEastside_i + 67.85 HomeSizeK_i\]
14.5 Ερμηνεία των Εκτιμήσεων Παραμέτρων ενός Πολυμεταβλητού Μοντέλου
Χρήση των Εκτιμήσεων Παραμέτρων για να Κάνουμε Προβλέψεις
Χρησιμοποιούμε τις εκτιμήσεις παραμέτρων για να κάνουμε προβλέψεις με τον ίδιο τρόπο όπως πριν, αλλά αυτή τη φορά κάνουμε την πρόβλεψή μας με βάση δύο μεταβλητές: σε ποια γειτονιά βρίσκεται μια κατοικία (Neighborhood) και το μέγεθος της κατοικίας (HomeSizeK).
Δίνεται ξανά εδώ το προσαρμοσμένο μοντέλο:
\[PriceK_i = 177.25 + (-66.22) NeighborhoodEastside_i + 67.85 HomeSizeK_i\]
Το 177.25 (η τιμή του \(b_0\)) είναι η πρόβλεψη του μοντέλου για την τιμή της κατοικίας όταν:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Ο σταθερός όρος (\(b_0\)) είναι η τιμή πρόβλεψης της \(Y\) όταν όλες οι ανεξάρτητες μεταβλητές είναι ίσες με 0. Στο μοντέλο μας, αυτό σημαίνει όταν η NeighborhoodEastside = 0 (δηλαδή η κατοικία δεν βρίσκεται στο Eastside, άρα είναι στο Downtown) και η HomeSizeK = 0 (μηδενικά τετραγωνικά πόδια — που είναι, φυσικά, μη ρεαλιστικό αλλά μαθηματικά απαραίτητο για την ερμηνεία του σταθερού όρου). Οι Β και Γ αναφέρουν μόνο μία από τις δύο συνθήκες.
Η τιμή −66.22 είναι η ποσότητα που προσθέτει το μοντέλο στην τιμή πρόβλεψης όταν:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η NeighborhoodEastside είναι μια ψευδομεταβλητή που λαμβάνει την τιμή 1 αν η κατοικία βρίσκεται στο Eastside και 0 αν δεν βρίσκεται. Όταν η τιμή είναι 1, ο όρος \(-66.22 \times 1 = -66.22\) προστίθεται στην τιμή πρόβλεψης — που σημαίνει ότι αφαιρούμε 66.22 χιλιάδες δολάρια από τη τιμή πρόβλεψης. Όταν η τιμή είναι 0 (η κατοικία είναι στο Downtown), ο όρος \(-66.22 \times 0 = 0\), οπότε δεν επηρεάζει την τιμή πρόβλεψης. Η Γ αφορά τη HomeSizeK, που είναι διαφορετική ανεξάρτητη μεταβλητή.
Η τιμή 67.85 είναι αυτό που προσθέτει το μοντέλο στην τιμή πρόβλεψης όταν:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Ο συντελεστής 67.85 είναι η κλίση της ευθείας παλινδρόμησης για τη HomeSizeK — μας δείχνει πόσο αυξάνεται η τιμή πρόβλεψης της PriceK για κάθε αύξηση μίας μονάδας στη HomeSizeK (δηλαδή για κάθε επιπλέον 1000 τετραγωνικά πόδια). Αν, για παράδειγμα, η HomeSizeK = 2, τότε το μοντέλο προσθέτει \(67.85 \times 2 = 135.7\) χιλιάδες δολάρια στην τιμή πρόβλεψης. Η απάντηση Α θα ίσχυε για τον σταθερό όρο, όχι για την κλίση. Η Β δεν έχει νόημα — η Neighborhood είναι ποιοτική μεταβλητή με μόνο δύο τιμές (Downtown ή Eastside), όχι μια συνεχής ποσοτική μεταβλητή.
Χρησιμοποιούμε τις εκτιμήσεις παραμέτρων για να κάνουμε προβλέψεις από το πολυμεταβλητό μοντέλο με τον ίδιο τρόπο όπως κάναμε για τα μοντέλα με μία ανεξάρτητη μεταβλητή: κάθε συντελεστής (εκτός από το \(b_0\)) πολλαπλασιάζεται με την αντίστοιχη μεταβλητή του (π.χ. \(X_{1i}\) ή \(X_{2i}\)). Ας προσπαθήσουμε τώρα να καταλάβουμε πώς είναι κωδικοποιημένες οι μεταβλητές στο πολυμεταβλητό μοντέλο, ώστε να παράγονται προβλέψεις.
Η \(X_{1i}\) είναι κωδικοποιημένη ως ψευδομεταβλητή, ενώ η \(X_{2i}\) δεν είναι. Γιατί η R αντιμετωπίζει αυτές τις μεταβλητές διαφορετικά; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Γ και Δ.
Η R κωδικοποιεί ως ψευδομεταβλητές (0/1) μόνο τις ποιοτικές μεταβλητές, επειδή χρειάζονται να μετατραπούν σε αριθμητική μορφή για να χρησιμοποιηθούν σε ένα γραμμικό μοντέλο. Οι ποσοτικές μεταβλητές (όπως η HomeSizeK) είναι ήδη αριθμητικές, οπότε χρησιμοποιούνται απευθείας. Η απάντηση Α είναι λάθος — η σειρά δεν έχει σημασία· αυτό που έχει σημασία είναι ο τύπος της μεταβλητής. Η Β είναι λάθος — η R δεν κάνει κρίσεις περί «σημαντικότητας», αλλά απλώς εφαρμόζει στατιστικές διαδικασίες με βάση τον τύπο της μεταβλητής.
Το μέρος του ΜΟΝΤΕΛΟΥ στην εξίσωση GLM είναι μια συνάρτηση (για να χρησιμοποιήσουμε έναν όρο από τα μαθηματικά), η οποία όπως είδαμε μοιάζει ως εξής:
\[PriceK_i = 177.25 + (-66.22) NeighborhoodEastside_i + 67.85 HomeSizeK_i\]
Ποιος από τους παρακάτω υπολογισμούς θα μας έδινε την τιμή πρόβλεψης μιας κατοικίας στο Eastside με μέγεθος 1.599 χιλιάδες τετραγωνικά πόδια;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Για μια κατοικία στο Eastside, η NeighborhoodEastside = 1. Για μια κατοικία μεγέθους 1.599 χιλιάδων τετραγωνικών ποδιών, η HomeSizeK = 1.599. Αντικαθιστώντας αυτές τις τιμές στην εξίσωση: \(177.25 + (-66.22)(1) + 67.85(1.599) \approx 177.25 - 66.22 + 108.49 \approx 219.52\) χιλιάδες δολάρια.
Η Α θα ίσχυε για μια κατοικία στο Downtown με μέγεθος 0 τετραγωνικά πόδια. Η Β θα ίσχυε για μια κατοικία στο Downtown με μέγεθος 1.599 χιλιάδες τετραγωνικά πόδια. Η Γ θα ίσχυε για μια κατοικία στο Eastside με μέγεθος 0 τετραγωνικά πόδια.
Το μοντέλο, το οποίο είναι μια συνάρτηση, παράγει μια τιμή πρόβλεψης κατοικίας (σε χιλιάδες δολάρια) ξεκινώντας με το σταθερό όρο (\(b_0\), που είναι 177.25), στη συνέχεια αφαιρώντας 66.22 αν η κατοικία βρίσκεται στο Eastside, και έπειτα προσθέτοντας 67.85 για κάθε 1000 τετραγωνικά πόδια επιπλέον χώρου στην κατοικία.
Ερμηνεία των Εκτιμήσεων Παραμέτρων
Ο τρόπος ερμηνείας των εκτιμήσεων παραμέτρων (τιμών των συντελεστών) σε ένα πολυμεταβλητό μοντέλο είναι παρόμοιος με αυτόν που χρησιμοποιήσαμε στα μοντέλα με μία ανεξάρτητη μεταβλητή. Αλλά θα δούμε ότι οι τιμές των συντελεστών στο πολυμεταβλητό μοντέλο δεν είναι ίδιες με αυτές που θα παίρναμε αν προσαρμόζαμε κάθε μοντέλο μίας μεταβλητής ξεχωριστά. Αυτό συμβαίνει επειδή οι συντελεστές \(b_0\), \(b_1\) κ.ο.κ. έχουν ελαφρώς διαφορετική σημασία στο πολυμεταβλητό μοντέλο από ό,τι στα μοντέλα μία ανεξάρτητη μεταβλητή.
Εκτελέσαμε τη συνάρτηση lm() για τρία διαφορετικά μοντέλα: το μοντέλο της Neighborhood, το μοντέλο της HomeSizeK και το πολυμεταβλητό μοντέλο (που περιλαμβάνει ταυτόχρονα και τις δύο ανεξάρτητες μεταβλητές). Οι τρεις εξισώσεις με τις τιμές των συντελεστών δίνονται παρακάτω:
Μοντέλο της Neighborhood:
\[PriceK_i = 315.7 + (-102.3) NeighborhoodEastside_i\]
Μοντέλο της HomeSizeK:
\[PriceK_i = 97.47 + 92.28 HomeSizeK_i\]
Πολυμεταβλητό Μοντέλο:
\[PriceK_i = 177.25 + (-66.22) NeighborhoodEastside_i + 67.85 HomeSizeK_i\]
Περιμένατε οι τιμές των συντελεστών να είναι ίδιες ή διαφορετικές ανάμεσα σε αυτά τα τρία μοντέλα; Γιατί ναι ή γιατί όχι;
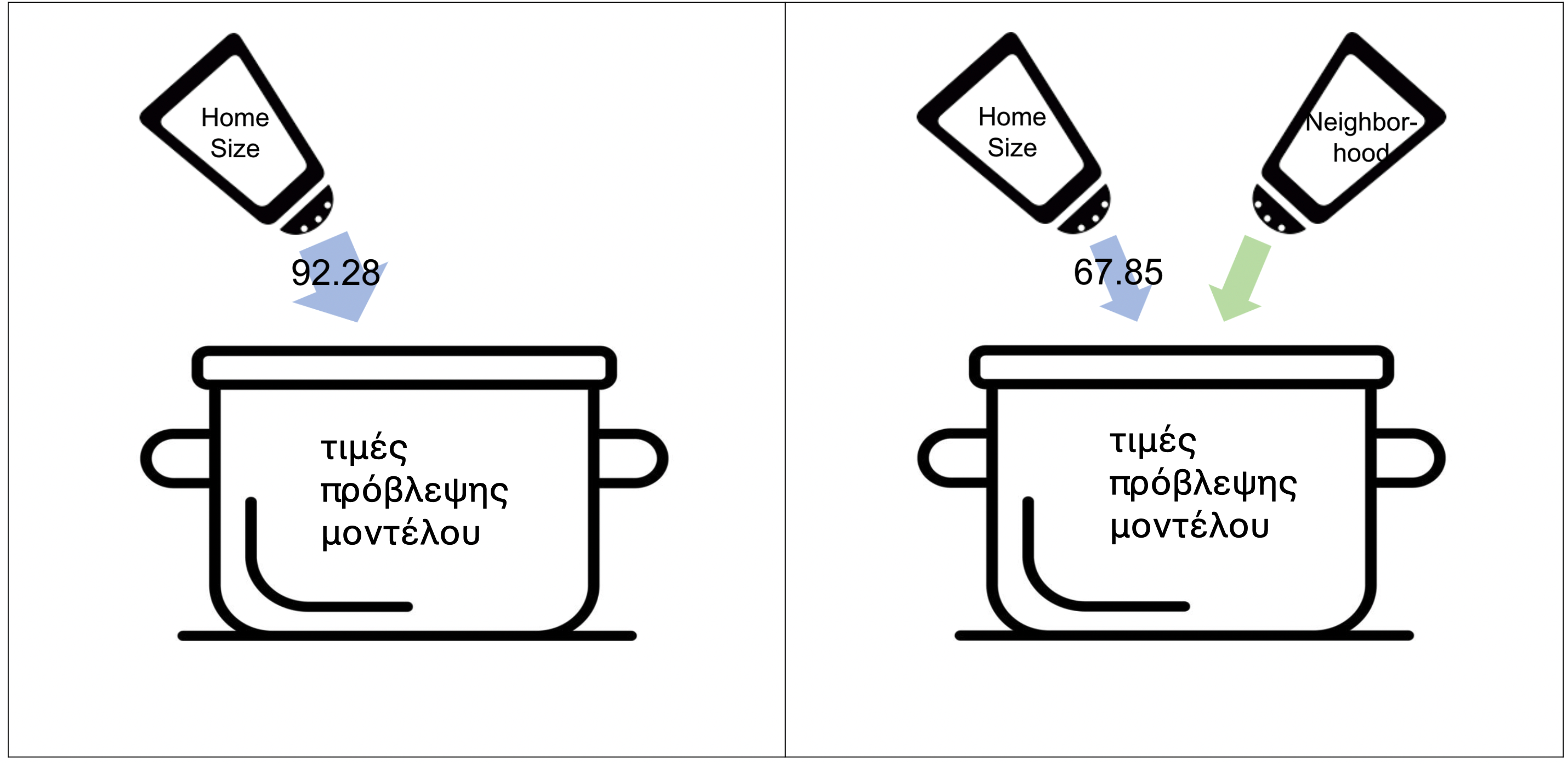
Στο μοντέλο με δύο ανεξάρτητες μεταβλητές, η τιμή κάθε κατοικίας υποτίθεται ότι είναι συνάρτηση τόσο της Neighborhood όσο και της HomeSizeK. Αλλά αυτά τα δύο δεν είναι ανεξάρτητα το ένα από το άλλο. Για να εξηγήσουμε τι εννοούμε, ρίξτε μια ματιά στο παρακάτω διαιρεμένο ιστόγραμμα. Το έχετε ξαναδεί, αλλά αυτή τη φορά χρωματίσαμε δύο από τις κατοικίες με κόκκινο χρώμα.
 Αυτές οι δύο κατοικίες συμβαίνει να είναι οι δύο πιο ακριβές κατοικίες στο πλαίσιο δεδομένων
Αυτές οι δύο κατοικίες συμβαίνει να είναι οι δύο πιο ακριβές κατοικίες στο πλαίσιο δεδομένων Smallville. Αλλά τι τις κάνει ακριβές; Είναι η γειτονιά στην οποία βρίσκονται, ή είναι το γεγονός ότι ανήκουν ανάμεσα στις μεγαλύτερες σε μέγεθος κατοίκιες του πλαισίου δεδομένων; Η απάντηση είναι ότι μάλλον ισχύουν και τα δύο, σε κάποιο βαθμό.
Επειδή οι δύο μεταβλητές (Neighborhood και HomeSizeK) συσχετίζονται μεταξύ τους (δηλαδή το Downtown τείνει να έχει μεγαλύτερες σε μέγεθος κατοικίες από το Eastside), η τιμή \(b_1 = 92.28\) στο μοντέλο με τη μία μόνο ανεξάρτητη μεταβλητή (την HomeSizeK), περιλαμβάνει και ένα μέρος που στην πραγματικότητα μπορεί να οφείλεται στη Neighborhood.
Όταν προσθέτουμε τη Neighborhood στο μοντέλο (δημιουργώντας ένα πολυμεταβλητό μοντέλο), η R παίρνει ένα μέρος της τιμής του συντελεστή που αρχικά αποδιδόταν εξ ολοκλήρου στη HomeSizeK και το αποδίδει στη Neighborhood. Παρατηρήστε την τιμή του συντελεστή της HomeSizeK στα παρακάτω μοντέλα:
Μοντέλο της HomeSizeK:
\[PriceK_i = 97.47 + \boxed{92.28} \, HomeSizeK_i\]
Πολυμεταβλητό Μοντέλο:
\[PriceK_i = 177.25 + (-66.22) \, NeighborhoodEastside_i + \boxed{67.85} \, HomeSizeK_i\]
Επειδή η τιμή του συντελεστή για τη HomeSizeK στο πολυμεταβλητό μοντέλο «γνωρίζει» ότι η Neighborhood βρίσκεται επίσης στο μοντέλο, είναι μικρότερη στο πολυμεταβλητό μοντέλο σε σχέση με το μοντέλο με μία ανεξάρτητη μεταβλητή.
Επιστρέφοντας στην αναλογία της μαγειρικής, στο μοντέλο με μία ανεξάρτητη μεταβλητή (HomeSizeK), το μέγεθος της κατοικίας ήταν το μοναδικό υλικό στο «μαγείρεμα» των τιμών πρόβλεψης. Αλλά στο μοντέλο που περιλαμβάνει τόσο τη HomeSizeK όσο και τη Neighborhood, η μεταβλητή της γειτονιάς θα προσθέσει λίγο από αυτό που προηγουμένως πρόσθετε το μέγεθος της κατοικίας. Επειδή οι εκτιμήσεις των παραμέτρων αντιστοιχούν στις συνεισφορές κάθε μεταβλητής στο μοντέλο, μερικές φορές ονομάζονται και «βάρη» (weights).
Πώς ονομάζονται τα \(b\) (\(b_1\), \(b_2\) κ.ο.κ.) που βρίσκονται μπροστά από τα X;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Οι αριθμοί που πολλαπλασιάζονται με τις ανεξάρτητες μεταβλητές (\(b_1\), \(b_2\), κλπ.) ονομάζονται συντελεστές (coefficients) — ή ισοδύναμα, εκτιμήσεις παραμέτρων ή «βάρη» (weights). Η απάντηση Α (μεταβλητές) αναφέρεται στις ίδιες τις μεταβλητές (\(X_1\), \(X_2\)). Η Γ (σταθεροί όροι) αναφέρεται μόνο στο \(b_0\), όχι στους συντελεστές των ανεξάρτητων μεταβλητών. Η Δ (δεδομένα) είναι οι παρατηρούμενες τιμές, όχι οι εκτιμήσεις του μοντέλου.
Στο μοντέλο με μία ανεξάρτητη μεταβλητή, τα \(b\) ονομάζονται συντελεστές παλινδρόμησης (regression coefficients): μας δείχνουν πόσο να προσθέσουμε στην τιμή πρόβλεψης της \(Y\) για κάθε αύξηση 1 μονάδας στη \(X\). Στα μοντέλα με πολλές ανεξάρτητες μεταβλητές, θα ονομάζουμε τα \(b\) μερικούς συντελεστές παλινδρόμησης (partial regression coefficients), επειδή το πόσο προσθέτουν στην τιμή πρόβλεψης (θετικό ή αρνητικό) εξαρτάται από τις άλλες ανεξάρτητες μεταβλητές που υπάρχουν στο μοντέλο. Ένας άλλος τρόπος να το εκφράσουμε αυτό είναι ότι το \(b\) μάς δείχνει την επίδραση μίας ανεξάρτητης μεταβλητής «αφού λάβουμε υπόψη μας / ελέγξουμε» (controlling for) την επίδραση όλων των άλλων ανεξάρτητων μεταβλητών του μοντέλου.
Χρησιμοποιώντας την ίδια λογική, πώς θα πρέπει να ερμηνεύσουμε την τιμή του \(b\) για τη HomeSizeK; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Γ.
Και οι δύο διατυπώσεις (Β και Γ) δείχνουν το ίδιο πράγμα με διαφορετικό τρόπο: ο μερικός συντελεστής παλινδρόμησης για τη HomeSizeK αντιπροσωπεύει την επίδρασή της στην τιμή πρόβλεψης αφού έχει ληφθεί υπόψη η επίδραση της Neighborhood — δηλαδή την πρόσθετη επίδραση πέρα από αυτή που εξηγείται ήδη από τη Neighborhood.
Η απάντηση Α είναι λανθασμένη επειδή περιγράφει την επίδραση της Neighborhood, όχι της HomeSizeK. Η Δ είναι λανθασμένη: όπως είδαμε, ο συντελεστής για τη HomeSizeK είναι 92.28 στο μοντέλο με μία ανεξάρτητη μεταβλητή αλλά μόνο 67.85 στο πολυμεταβλητό μοντέλο — αυτές οι τιμές διαφέρουν επειδή στο πολυμεταβλητό μοντέλο μέρος της επίδρασης που πριν αποδιδόταν στη HomeSizeK τώρα αποδίδεται στη Neighborhood.
14.6 Προβλέψεις από το Πολυμεταβλητό Μοντέλο
Ο στόχος της κατασκευής ενός πολυμεταβλητού μοντέλου είναι να μας βοηθήσει να κάνουμε καλύτερες προβλέψεις από εκείνες που θα μπορούσαμε με ένα μοντέλο μίας μόνο ανεξάρτητης μεταβλητής (και με τον όρο «καλύτερες» εννοούμε προβλέψεις με μικρότερο σφάλμα).
Αφού προσαρμόσουμε το πολυμεταβλητό μοντέλο στα δεδομένα, είναι χρήσιμο να εξετάσουμε τις τιμές πρόβλεψης και τα υπόλοιπα του μοντέλου. Όπως ακριβώς κάναμε και για τα μοντέλα μίας ανεξάρτητης μεταβλητής, μπορούμε να χρησιμοποιήσουμε τις συναρτήσεις predict() και resid() της R για να πάρουμε τις τιμές πρόβλεψης του μοντέλου και τα σφάλματα αυτών των προβλέψεων για κάθε κατοικία στο πλαίσιο δεδομένων.
Παρακάτω βλέπετε το πολυμεταβλητό μοντέλο με το οποίο εργαζόμαστε μέχρι τώρα. Η R θα χρησιμοποιήσει ένα μέρος του για να υπολογίσει τις τιμές πρόβλεψης και ένα άλλο μέρος του για να υπολογίσει τα υπόλοιπα.
\[\text{PriceK}_i = \underbrace{b_0 + b_1 \text{NeighborhoodEastside}_i + b_2 \text{HomeSizeK}_i}_{\texttt{predict(model)}} + \underbrace{e_i}_{\texttt{resid(model)}}\]
Προβλέψεις από το Πολυμεταβλητό Μοντέλο
Σε αυτή την ενότητα θα πάρουμε τις τιμές πρόβλεψης από το βέλτιστα προσαρμοσμένο πολυμεταβλητό μοντέλο μας και, στη συνέχεια, θα τις αναπαραστήσουμε διαγραμματικά προκειμένου να αναζητήσουμε μοτίβα.
Αν αναπαραστήσουμε σε διάγραμμα διασποράς τις τιμές πρόβλεψης της PriceK από το πολυμεταβλητό μοντέλο στον άξονα y και την HomeSizeK στον άξονα x, πώς νομίζετε ότι θα έμοιαζε; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Δ.
Στο πολυμεταβλητό μοντέλο, ο συντελεστής \(b_2\) της HomeSizeK είναι θετικός — άρα καθώς αυξάνεται το μέγεθος της κατοικίας, αυξάνεται και η τιμή κατοικίας (Α). Επίσης, ο συντελεστής \(b_1\) της NeighborhoodEastside είναι θετικός, που σημαίνει ότι οι κατοικίες στο Eastside προβλέπεται να είναι ακριβότερες από τις αντίστοιχες κατοικίες στο Downtown (Δ). Άρα, οι τιμές πρόβλεψης που αντιστοιχούν στις κατοικίες στο Downtown θα βρίσκονται γενικά χαμηλότερα από τις τιμές πρόβλεψης που αντιστοιχούν στις κατοικίες στο Eastside. Οι απαντήσεις Β και Γ έχουν την αντίστροφη κατεύθυνση και δεν συμβαδίζουν με τα δεδομένα.
Γράψτε κώδικα για να αποθηκεύσετε το πολυμεταβλητό μοντέλο ως multi_model. Έχουμε προσθέσει για εσάς κώδικα που θα τοποθετήσει τις τιμές πρόβλεψης του μοντέλου (ως μαύρα τρίγωνα) επάνω στο διάγραμμα διασποράς.
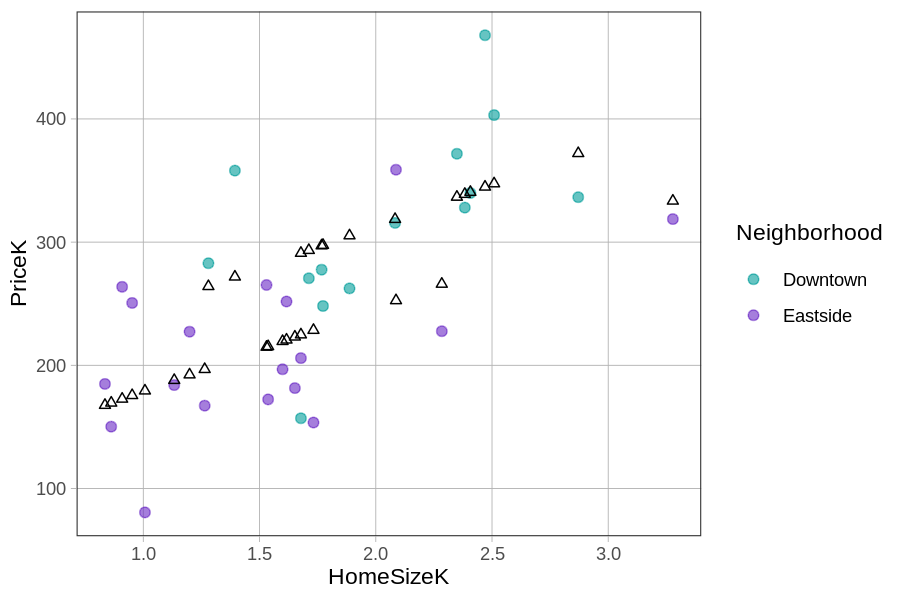 Αν συνδέσουμε μεταξύ τους τα μαύρα τρίγωνα, μοιάζουν με δύο παράλληλες ευθείες. Αυτό μπορεί να γίνει με τη συνάρτηση
Αν συνδέσουμε μεταξύ τους τα μαύρα τρίγωνα, μοιάζουν με δύο παράλληλες ευθείες. Αυτό μπορεί να γίνει με τη συνάρτηση gf_model() και φαίνεται στο παρακάτω διάγραμμα.
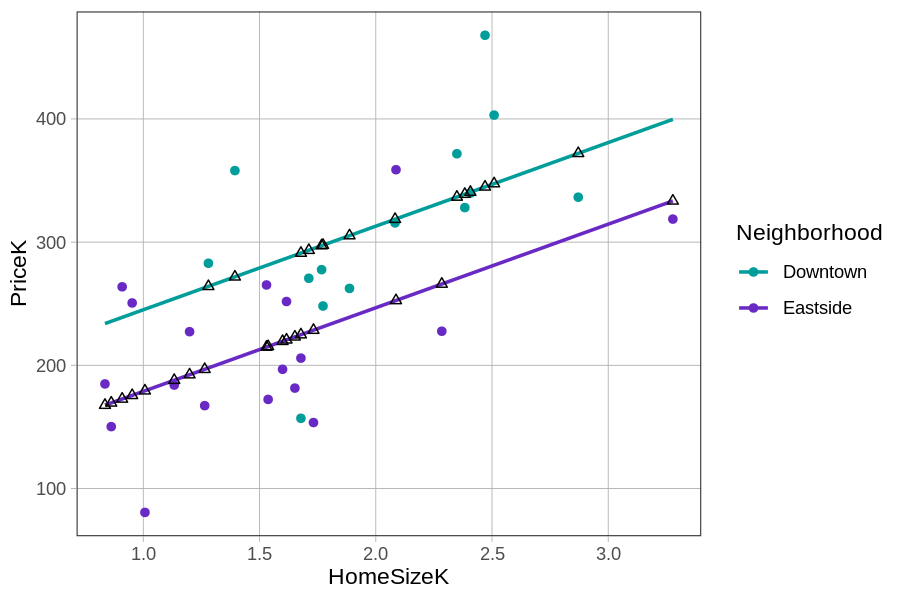 Όπως φαίνεται, οι τιμές πρόβλεψης από αυτό το συγκεκριμένο πολυμεταβλητό μοντέλο, με μία ποιοτική και μία ποσοτική ανεξάρτητη μεταβλητή, μπορούν να αναπαρασταθούν διαγραμματικά ως δύο παράλληλες ευθείες: μία για τις κατοικίες στο Downtown και μία για τις κατοικίες στο Eastside. Είναι ενδιαφέρον ότι η εξίσωση του GLM (Γενικού Γραμμικού Μοντέλου) ουσιαστικά περιείχε δύο παράλληλες ευθείες από την αρχή! Ας σας δείξουμε τι εννοούμε.
Όπως φαίνεται, οι τιμές πρόβλεψης από αυτό το συγκεκριμένο πολυμεταβλητό μοντέλο, με μία ποιοτική και μία ποσοτική ανεξάρτητη μεταβλητή, μπορούν να αναπαρασταθούν διαγραμματικά ως δύο παράλληλες ευθείες: μία για τις κατοικίες στο Downtown και μία για τις κατοικίες στο Eastside. Είναι ενδιαφέρον ότι η εξίσωση του GLM (Γενικού Γραμμικού Μοντέλου) ουσιαστικά περιείχε δύο παράλληλες ευθείες από την αρχή! Ας σας δείξουμε τι εννοούμε.
Αν ξεκινήσουμε από το προσαρμοσμένο πολυμεταβλητό μοντέλο (\(\text{PriceK}_i = 177.25 + -66.22 \text{NeighborhoodEastside}_i + 67.85 \text{HomeSizeK}_i\)), μπορούμε να το ξαναγράψουμε ως δύο ξεχωριστές γραμμικές εξισώσεις: μία για τις κατοικίες στο Downtown και μία για τις κατοικίες στο Eastside.
Για τις κατοικίες στο Downtown, το μοντέλο μπορεί να ξαναγραφεί ως εξής:
\[\text{PriceK}_i = 177.25 + \boxed{-66.22(0)} + 67.85 \text{HomeSizeK}_i\]
Επειδή για τις κατοικίες στο Downtown ισχύει \(\text{NeighborhoodEastside}_i = 0\), ο δεύτερος όρος μηδενίζεται, και προκύπτει η ακόλουθη εξίσωση για την πρόβλεψη των τιμών των κατοικιών στο Downtown:
\[\text{PriceK}_i = 177.25 + 67.85 \text{HomeSizeK}_i\]
Για τις κατοικίες στο Eastside, ο δεύτερος όρος δεν μηδενίζεται, επειδή στο Eastside ισχύει \(\text{NeighborhoodEastside}_i = 1\):
\[\text{PriceK}_i = 177.25 + \boxed{-66.22(1)} + 67.85 \text{HomeSizeK}_i\]
Συνδυάζοντας τους πρώτους δύο όρους (δηλαδή, \(177.25 + -66.22\)), προκύπτει η εξής εξίσωση για τις κατοικίες στο Eastside:
\[\text{PriceK}_i = 111.03 + 67.85 \text{HomeSizeK}_i\]
Οι δύο αυτές εξισώσεις — μία για το Downtown και μία για το Eastside — αναπαριστούν ευθείες γραμμές. Και οι δύο έχουν κλίση και σταθερό όρο.
- Κατοικίες στο Downtown: \(\text{PriceK}_i = 177.25 + 67.85 \text{HomeSizeK}_i\)
- Κατοικίες στο Eastside: \(\text{PriceK}_i = 111.03 + 67.85 \text{HomeSizeK}_i\)
Τι έχουν κοινό αυτές οι δύο ευθείες;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Και οι δύο εξισώσεις έχουν τον ίδιο συντελεστή για την HomeSizeK (67.85) — δηλαδή την ίδια κλίση. Αυτό σημαίνει ότι σε κάθε γειτονιά, μια αύξηση κατά 1.000 τετραγωνικά πόδια στο μέγεθος της κατοικίας προβλέπει την ίδια αύξηση στην τιμή ($67.850). Οι σταθεροί όροι όμως διαφέρουν (177.25 για το Downtown, 111.03 για το Eastside) — γι’ αυτό οι δύο ευθείες είναι παράλληλες αλλά μετατοπισμένες κάθετα.
Παρακάτω βλέπετε το ίδιο διάγραμμα, αλλά αυτή τη φορά με τον άξονα x (που αναπαριστά τη μεταβλητή HomeSizeK) να εκτείνεται από 0 έως 3 χιλιάδες τετραγωνικά πόδια.
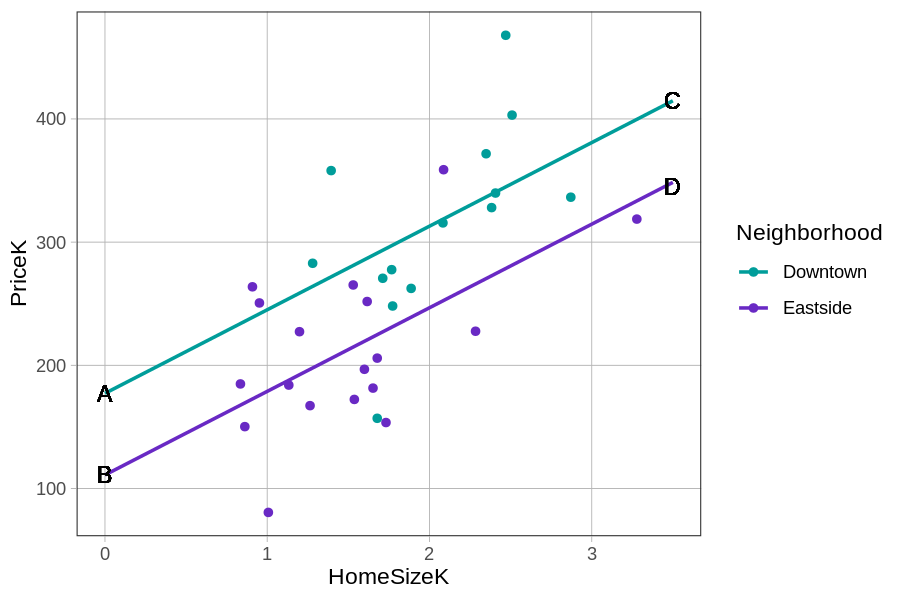
Ποια εξίσωση αντιστοιχεί στην ευθεία στο επάνω μέρος (αυτή που εκτείνεται από το Α έως το C);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η ευθεία στο επάνω μέρος αναπαριστά τις κατοικίες στο Downtown, τα οποία έχουν υψηλότερες τιμές πρόβλεψης για οποιοδήποτε δεδομένο μέγεθος κατοικίας. Στο διάγραμμα, στο σημείο Α (όπου HomeSizeK = 0), η ευθεία τέμνει τον άξονα y γύρω στο 177 — που ταιριάζει με τον σταθερό όρο 177.25 της εξίσωσης για το Downtown. Η απάντηση Α (με σταθερό όρο 111.03) αντιστοιχεί στην κάτω ευθεία (Eastside).
Ποιο γράμμα στο διάγραμμα αναπαριστά τον σταθερό όρο (y-intercept) για τις κατοικίες στο Downtown;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Ο σταθερός όρος (y-intercept) είναι η τιμή της εξαρτημένης μεταβλητής όταν η ανεξάρτητη ισούται με 0 — δηλαδή το σημείο όπου η ευθεία τέμνει τον άξονα y. Στο διάγραμμα, η ευθεία του Downtown τέμνει τον άξονα y (στο HomeSizeK = 0) στο σημείο Α, που βρίσκεται γύρω στην τιμή 177 — η οποία αντιστοιχεί στον σταθερό όρο 177.25 της εξίσωσης για τις κατοικίες στο Downtown. Τα σημεία C και D είναι στο δεξί άκρο του διαγράμματος (HomeSizeK = 3), και το σημείο Β είναι ο σταθερός όρος για το Eastside (γύρω στο 111).
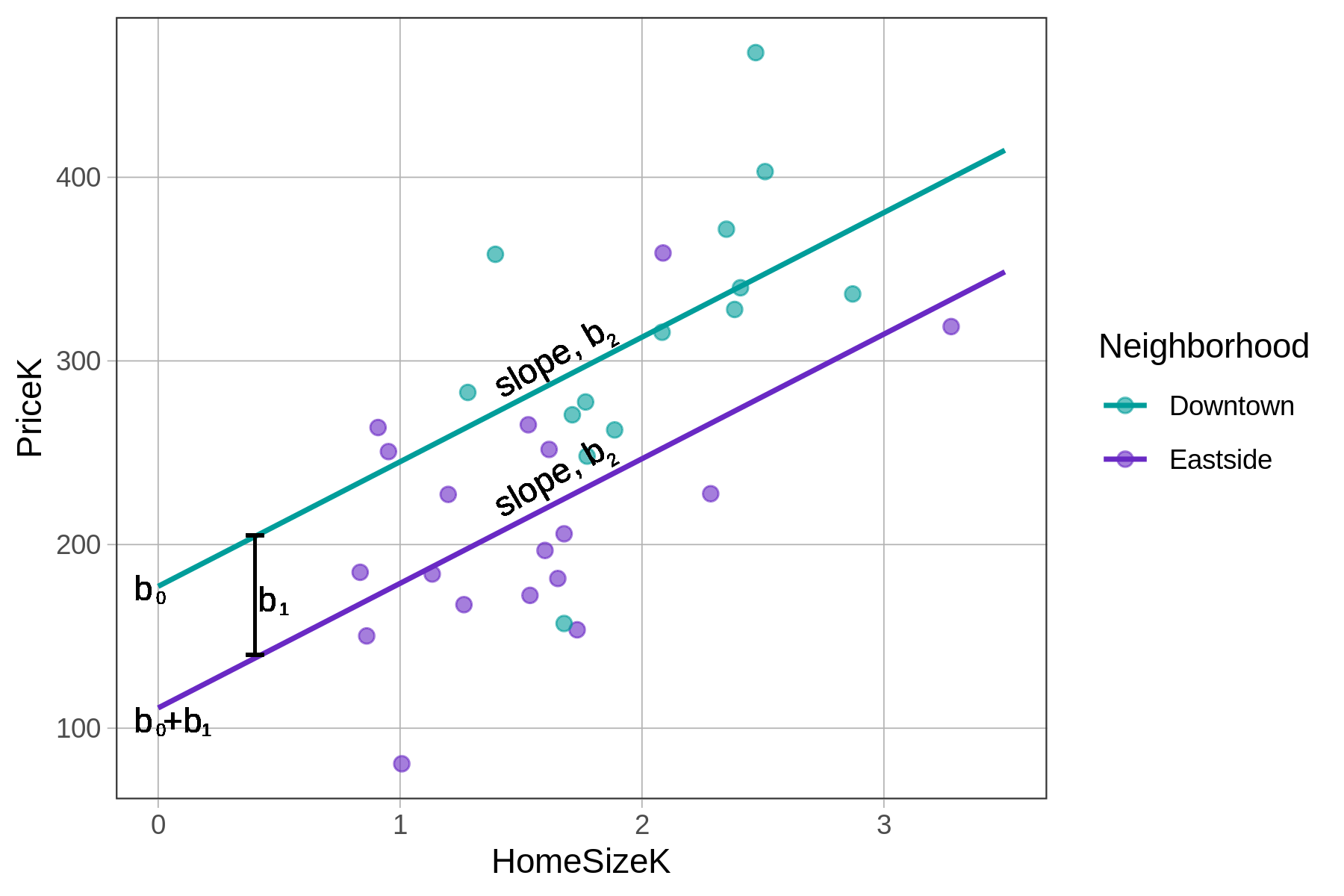
Αυτές οι δύο ευθείες έχουν την ίδια κλίση (γι’ αυτό είναι παράλληλες), αλλά διαφορετικούς σταθερούς όρους (177 έναντι 111). Το τμήμα της πολυμεταβλητής εξίσωσης που σημειώνεται με αγκύλη παρακάτω είναι αυτό που ορίζει τους δύο διαφορετικούς σταθερούς όρους.
\[\text{PriceK}_i = \underbrace{b_0 + b_1 \text{NeighborhoodEastside}_i}_{\text{y-intercept}} + b_2 \text{HomeSizeK}_i\]
Παρόλο που αυτό το πολυμεταβλητό μοντέλο είναι μία μεγάλη εξίσωση, περιέχει στην πραγματικότητα δύο ξεχωριστές εξισώσεις παλινδρόμησης με την ίδια κλίση, μία για κάθε γειτονιά.
Σύνοψη
Συνοψίζοντας, υπάρχουν δύο ισοδύναμοι τρόποι να ερμηνεύσουμε τις εκτιμήσεις των παραμέτρων \(b_0\), \(b_1\) και \(b_2\). Η μία ερμηνεία εστιάζει στον τρόπο με τον οποίο οι τιμές προβλέψης του μοντέλου για τις τιμές των κατοικιών μεταβάλλονται ανάλογα με τις μεταβλητές:
- \(b_0\) είναι η τιμή πρόβλεψης για μια κατοικία στο Downtown με μέγεθος 0 τετραγωνικά πόδια.
- \(b_1\) είναι αυτό που προστίθεται στην τιμή πρόβλεψης για μια κατοικία στο Eastside.
- \(b_2\) είναι αυτό που προστίθεται στην τιμή πρόβλεψης για κάθε επιπλέον μονάδα μεγέθους κατοικίας (κάθε 1.000 τετραγωνικά πόδια).
Η άλλη ερμηνεία εστιάζει στο τι σημαίνουν αυτοί οι αριθμοί σε σχέση με τις ευθείες που αναπαριστούν το πολυμεταβλητό μοντέλο:
- \(b_0\) είναι ο σταθερός όρος (y-intercept) της ευθείας για το Downtown.
- \(b_1\) είναι η απόσταση μεταξύ των δύο ευθειών, η οποία παραμένει σταθερή για όλες τις τιμές του μεγέθους της κατοικίας.
- \(b_2\) είναι η κλίση των δύο ευθειών.
14.7 Χρήση των Υπολοίπων και των Αθροισμάτων Τετραγώνων για τη Μέτρηση του Σφάλματος γύρω από το Πολυμεταβλητό Μοντέλο
Στα περισσότερα ζητήματα, οι έννοιες που αναπτύξαμε για τα μοντέλα μίας ανεξάρτητης μεταβλητής εφαρμόζονται και στα μοντέλα πολλαπλών ανεξάρτητων μεταβλητών. Σε κάθε περίπτωση, το μοντέλο παράγει μια τιμή πρόβλεψης για την εξαρτημένη μεταβλητή για κάθε παρατήρηση στο πλαίσιο δεδομένων. Αφαιρώντας την τιμή πρόβλεψης του μοντέλου από την παρατηρούμενη τιμή, προκύπτει το υπόλοιπο, το οποίο μας δείχνει πόσο εσφαλμένη είναι η πρόβλεψη του μοντέλου (θετική ή αρνητική) για κάθε παρατήρηση.
Αν υψώσουμε στο τετράγωνο και έπειτα αθροίσουμε όλα τα υπόλοιπα, θα προκύψει το SS Error του μοντέλου, το οποίο μας δίνει μια αίσθηση του πόσο καλά προσαρμόζεται το μοντέλο στα δεδομένα. Χρησιμοποιώντας αυτό το SS Error, μπορούμε στη συνέχεια να συγκρίνουμε το πολυμεταβλητό μοντέλο με άλλα μοντέλα, ξεκινώντας από το κενό μοντέλο. Για να αξιολογήσουμε πόσο καλά προσαρμόζεται ένα μοντέλο στα δεδομένα, θα θέτουμε συνεχώς το ερώτημα: Πόσο μειώνει το ένα μοντέλο το σφάλμα σε σχέση με κάποιο άλλο;
Υπόλοιπα από το Πολυμεταβλητό Μοντέλο
Το σφάλμα από το πολυμεταβλητό μοντέλο υπολογίζεται με τον ίδιο ακριβώς τρόπο όπως και για τα άλλα μοντέλα που έχουμε εξετάσει. Κάθε μοντέλο παράγει μια πρόβλεψη για παρατήρηση, και επειδή οι προβλέψεις έχουν συνήθως σφάλμα, μπορούμε να χρησιμοποιήσουμε τη διαφορά μεταξύ της τιμής πρόβλεψης και της πραγματικής τιμής για να υπολογίσουμε ένα υπόλοιπο (σφάλμα) για κάθε παρατήρηση.
Ας δούμε ξανά το διάγραμμα διασποράς της PriceK με την HomeSizeK, με τις κατοικίες σε κάθε γειτονιά να αναπαρίστανται με διαφορετικό χρώμα. Ας εστιάσουμε τώρα σε μία συγκεκριμένη κατοικία στο Downtown που πωλήθηκε για λίγο πάνω από $400K (το τιρκουάζ σημείο στο επάνω μέρος).
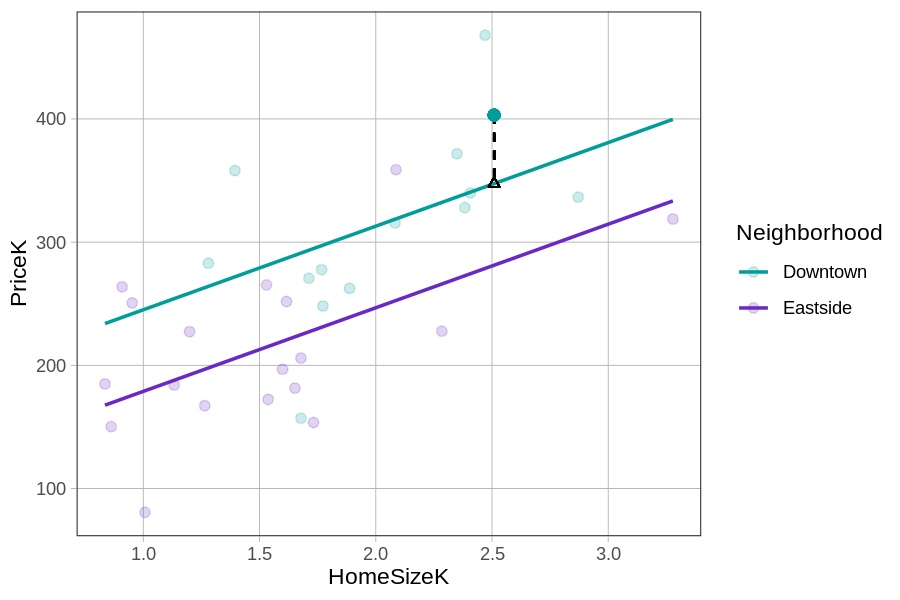
Ποιο μέρος του διαγράμματος αναπαριστά την τιμή πρόβλεψης του πολυμεταβλητού μοντέλου για την PriceK αυτής της κατοικίας;
\[PriceK_i = 177.25 -66.22 NeighborhoodEastside_i + 67.85 HomeSizeK_i\]
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Η τιμή πρόβλεψης του μοντέλου για κάθε παρατήρηση είναι το σημείο επάνω στην ευθεία που αντιστοιχεί στην τιμή της ανεξάρτητης μεταβλητής. Για την κατοικία στο Downtown, η τιμή πρόβλεψης βρίσκεται επάνω στην επάνω τιρκουάζ ευθεία (την ευθεία για το Downtown) στο ύψος της αντίστοιχης τιμής PriceK — αυτό αναπαρίσταται από το τρίγωνο. Η απάντηση Α αναφέρεται στην παρατηρούμενη τιμή (\(Y_i\)), όχι στην τιμή πρόβλεψης. Η Β αναφέρεται στο υπόλοιπο. Η Γ αναπαριστά ολόκληρο το μοντέλο, όχι την τιμή πρόβλεψης για μια συγκεκριμένη κατοικία.
Ποιο μέρος του διαγράμματος αναπαριστά το υπόλοιπο (σφάλμα) της τιμής αυτής της κατοικίας από την τιμή πρόβλεψης του μοντέλου;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το υπόλοιπο (\(e_i\)) είναι η κάθετη απόσταση μεταξύ της παρατηρούμενης τιμής (σημείου) και της τιμής πρόβλεψης (τρίγωνο επάνω στην ευθεία) — δηλαδή το μήκος της διακεκομμένης κάθετης γραμμής που τα συνδέει. Η απάντηση Α είναι η ίδια η παρατηρούμενη τιμή (\(Y_i\)), όχι το υπόλοιπο. Η Γ αναπαριστά τον συντελεστή της γειτονιάς (την επίδραση της Neighborhood), όχι το υπόλοιπο μιας συγκεκριμένης παρατήρησης. Η Δ αναπαριστά την τιμή πρόβλεψης.
Χρησιμοποιώντας τις συναρτήσεις predict() και resid(), μπορούμε να πάρουμε και να αποθηκεύσουμε τις προβλέψεις και τα υπόλοιπα του πολυμεταβλητού μοντέλου στο πλαίσιο δεδομένων Smallville.
Παρακάτω παρουσιάζονται οι τιμές πρόβλεψης και υπολοίπου για την κατοικία που αναπαρίσταται από το τιρκουάζ σημείο (παραπάνω):
PriceK multi_predict multi_resid
403.101 347.4862 55.6148Η πραγματική τιμή της κατοικίας ισούται με την τιμή πρόβλεψης + το υπόλοιπο (δηλαδή, \(403.101 = 347.4862 + 55.6148\)). Επειδή η πραγματική τιμή της κατοικίας είναι μεγαλύτερη από την τιμή πρόβλεψης του μοντέλου, το υπόλοιπο είναι θετικό. Επιστρέφοντας στην εξίσωση ΔΕΔΟΜΕΝΑ = ΜΟΝΤΕΛΟ + ΣΦΑΛΜΑ, μπορείτε να δείτε ποιο μέρος της παρακάτω εξίσωσης αναπαριστά την πραγματική τιμή αυτής της κατοικίας (403K), την τιμή πρόβλεψης του μοντέλου (347K) και το υπόλοιπο (56K).
\[\underbrace{403}_{\text{ΔΕΔΟΜΕΝΑ}} = \underbrace{347}_{\text{ΜΟΝΤΕΛΟ}} + \underbrace{56}_{\text{ΣΦΑΛΜΑ}}\] \[\underbrace{\text{PriceK}_i}_{403\text{K}} = \underbrace{b_0 + b_1 \text{NeighborhoodEastside}_i + b_2 \text{HomeSizeK}_i}_{347\text{K}} + \underbrace{e_i}_{56\text{K}}\]
Θα συναντούμε αυτό το μοτίβο (ΔΕΔΟΜΕΝΑ = ΜΟΝΤΕΛΟ + ΣΦΑΛΜΑ) ανεξάρτητα από το πόσο σύνθετο ή απλό είναι το μοντέλο. Όλα τα μοντέλα παράγουν προβλέψεις, και αυτές οι προβλέψεις έχουν κάποιο υπολειπόμενο σφάλμα. Παρακάτω δείχνουμε πώς τα υπόλοιπα για τα ίδια 6 σημεία δεδομένων εξαρτώνται από το ποιο μοντέλο (πολυμεταβλητό ή κενό) χρησιμοποιείται για τον υπολογισμό των προβλέψεων.
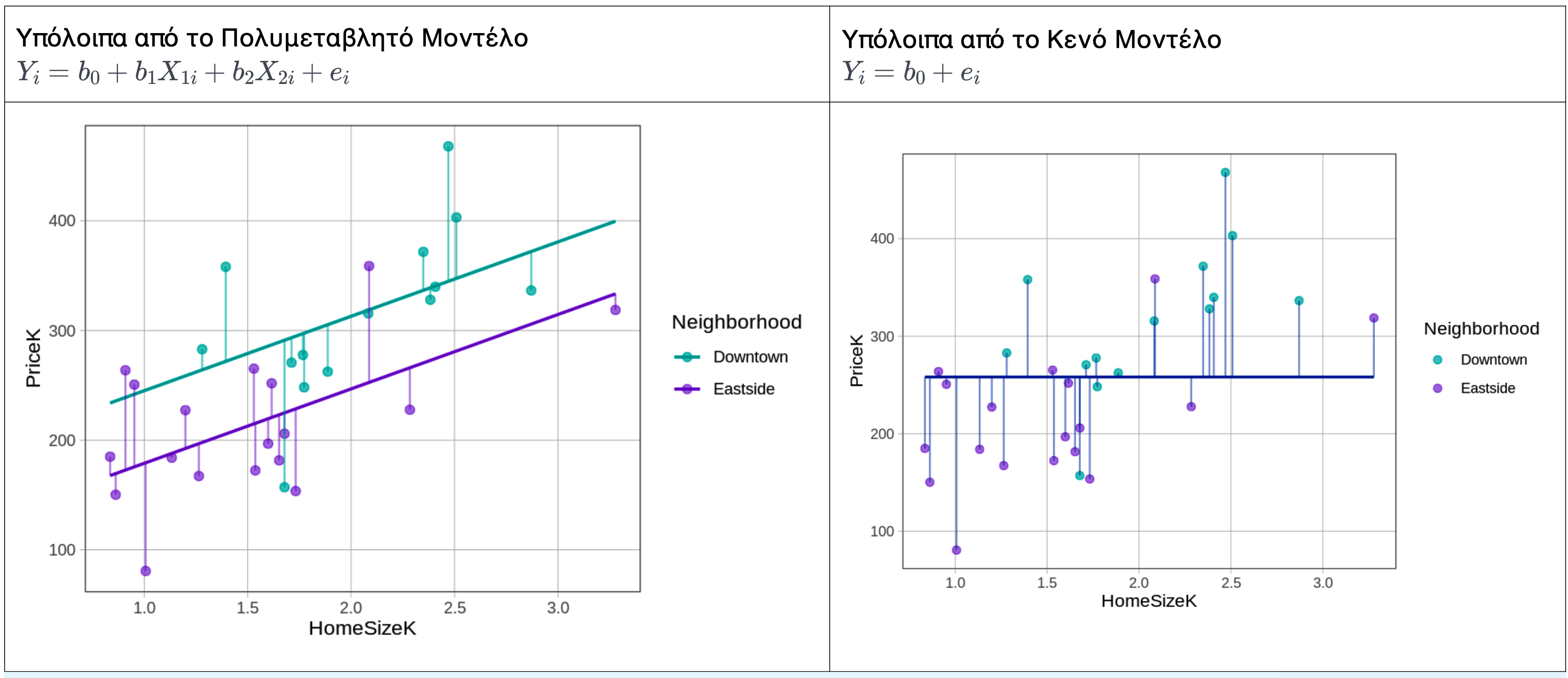
Ποια υπόλοιπα είναι γενικά μικρότερα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το πολυμεταβλητό μοντέλο χρησιμοποιεί δύο ανεξάρτητες μεταβλητές (γειτονιά και μέγεθος κατοικίας) για να προβλέψει την τιμή, ενώ το κενό μοντέλο προβλέπει την ίδια τιμή (τον συνολικό μέσο όρο) για κάθε κατοικία ανεξαρτήτως. Επειδή το πολυμεταβλητό μοντέλο εκμεταλλεύεται περισσότερες πληροφορίες, οι προβλέψεις του είναι πιο κοντά στις πραγματικές τιμές, και συνεπώς τα υπόλοιπα είναι γενικά μικρότερα.
Ποια από τα παρακάτω είναι αληθή; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Β και Ε.
Το κενό μοντέλο προβλέπει την ίδια τιμή (τον συνολικό μέσο όρο της PriceK) για όλες τις κατοικίες, ανεξάρτητα από οποιαδήποτε χαρακτηριστικά τους — άρα οι προβλέψεις του δεν εξαρτώνται ούτε από τη γειτονιά (Α) ούτε από το μέγεθος (Β). Αντίθετα, το πολυμεταβλητό μοντέλο χρησιμοποιεί και τις δύο μεταβλητές για να παράγει προβλέψεις, οπότε οι προβλέψεις του αλλάζουν τόσο με τη γειτονιά όσο και με το μέγεθος — γι’ αυτό οι απαντήσεις Γ και Δ είναι λάθος. Τέλος, εφόσον τα δύο μοντέλα παράγουν διαφορετικές προβλέψεις, η ίδια ακριβώς κατοικία θα έχει διαφορετική τιμή κατοικίας ανάλογα με το ποιο μοντέλο χρησιμοποιείται (Ε).
Χρήση του Πίνακα ANOVA για τη Σύγκριση του Πολυμεταβλητού με το Κενό Μοντέλο
Μπορεί να πιστεύουμε ότι το πολυμεταβλητό μας μοντέλο είναι καλύτερο, αλλά πόσο καλύτερο είναι; Για να αρχίσουμε να απαντάμε σε αυτό το ερώτημα, ας ξεκινήσουμε συγκρίνοντας το άθροισμα τετραγώνων των σφαλμάτων από το νέο μας μοντέλο με το αντίστοιχο από το κενό μοντέλο.
Έχουμε ήδη χρησιμοποιήσει τη συνάρτηση supernova() για να δημιουργήσουμε πίνακες ANOVA που περιέχουν τα SS που είναι χρήσιμα για τη σύγκριση μοντέλων. Στο παρακάτω πλαίσιο κώδικα, έχουμε προσαρμόσει το πολυμεταβλητό μοντέλο και το έχουμε αποθηκεύσει ως multi_model. Προσθέστε κώδικα για να δημιουργήσετε την έξοδο της supernova() για το μοντέλο μας.
Analysis of Variance Table (Type III SS)
Model: PriceK ~ Neighborhood + HomeSizeK
SS df MS F PRE p
------------ --------------- | ---------- -- --------- ------ ------ -----
Model (error reduced) | 124403.028 2 62201.514 17.216 0.5428 .0000
Neighborhood | 27758.259 1 27758.259 7.683 0.2094 .0096
HomeSizeK | 42003.677 1 42003.677 11.626 0.2862 .0019
Error (from model) | 104774.465 29 3612.913
------------ --------------- | ---------- -- --------- ------ ------ -----
Total (empty model) | 229177.493 31 7392.822Ίσως παρατηρήσετε αμέσως ότι αυτός ο πίνακας ANOVA έχει περισσότερες γραμμές από εκείνους για το μοντέλο της Neignborhood ή το μοντέλο της HomeSizeK. Μην ανησυχείτε για αυτές τις νέες γραμμές προς το παρόν — απλώς αναζητήστε τα SS Total, SS Error και SS Model. Έχουν την ίδια σημασία όπως και στα μοντέλα μίας ανεξάρτητης μεταβλητής.
SS Total
Όπως και πριν, ισχύει ότι \(SS\,Total = SS\,Model + SS\,Error\) (που είναι η εκδοχή της εξίσωσης ΔΕΔΟΜΕΝΑ = ΜΟΝΤΕΛΟ + ΣΦΑΛΜΑ σε αθροίσματα τετραγώνων). Χρησιμοποιήστε το παρακάτω πλαίσιο κώδικα για να επιβεβαιώσετε (με απλή αριθμητική) ότι το \(SS\,Model + SS\,Error\) ισούται πράγματι με το \(SS\,Total\), χρησιμοποιώντας τις απαραίτητες τιμές από τον παραπάνω πίνακα ANOVA.
Το SS Total (η τελευταία γραμμή του πίνακα ANOVA) μας λέει πόση συνολική διακύμανση, μετρημένη σε άθροισμα τετραγώνων, υπάρχει στην εξαρτημένη μεταβλητή. Μπορείτε να δείτε ότι το SS Total είναι περίπου 229.177.
Πώς υπολογίζεται το SS Total;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το SS Total αφορά αποκλειστικά την εξαρτημένη μεταβλητή — εδώ, την PriceK. Υπολογίζεται υψώνοντας στο τετράγωνο και αθροίζοντας τα υπόλοιπα από το κενό μοντέλο. Ανεξάρτητα από το ποιες ανεξάρτητες μεταβλητές προσθέτετε στο μοντέλο σας, το SS Total (η τελευταία γραμμή του πίνακα ANOVA) παραμένει πάντα το ίδιο, αρκεί η εξαρτημένη μεταβλητή να είναι η ίδια. Το κενό μοντέλο μιας εξαρτημένης μεταβλητής δεν εξαρτάται από καμία ανεξάρτητη μεταβλητή.
SS Error και SS Model
Πώς υπολογίζεται το SS Error για το πολυμεταβλητό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το SS Error είναι το γενικό όνομα που δίνουμε στο άθροισμα των τετραγωνισμένων υπολοίπων που παραμένουν μετά την προσαρμογή ενός σύνθετου μοντέλου (με τον όρο «σύνθετο» εννοούμε απλώς ένα μοντέλο πιο σύνθετο από το κενό). Επειδή ισχύει \(SS\,Total = SS\,Model + SS\,Error\), όσο μικρότερο είναι το SS Error, τόσο μεγαλύτερο γίνεται το SS Model — που σημαίνει ότι περισσότερη διακύμανση εξηγείται από το μοντέλο, ή ισοδύναμα, ότι περισσότερο σφάλμα έχει μειωθεί από το μοντέλο.
Όταν παίρνουμε τα υπόλοιπα από οποιοδήποτε σύνθετο μοντέλο μάς ενδιαφέρει, τα υψώνουμε στο τετράγωνο και τα αθροίζουμε, τι λαμβάνουμε;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Από τον ορισμό, το άθροισμα των τετραγωνισμένων υπολοίπων από ένα σύνθετο μοντέλο είναι το SS Error — η διακύμανση που παραμένει ανεξήγητη μετά την προσαρμογή του μοντέλου. Το SS Model υπολογίζεται διαφορετικά (μετράει πόσο καλύτερες είναι οι προβλέψεις του σύνθετου μοντέλου σε σύγκριση με το κενό). Το SS Total βασίζεται στα υπόλοιπα από το κενό μοντέλο, όχι από το σύνθετο. Η supernova() είναι η συνάρτηση της R που υπολογίζει αυτά τα αθροίσματα, δεν είναι αυτή καθαυτή ένα μέγεθος.
Αν το πολυμεταβλητό μοντέλο εξηγεί καλύτερα τη διακύμανση στην PriceK σε σχέση με κάποιο άλλο μοντέλο, τι θα περιμέναμε να δούμε; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Δ.
Ένα μοντέλο που εξηγεί καλύτερα τη διακύμανση παράγει προβλέψεις πιο κοντά στις πραγματικές τιμές, οπότε τα υπόλοιπα — και συνεπώς το SS Error — είναι μικρότερα (Α). Επειδή ισχύει \(SS\,Total = SS\,Model + SS\,Error\) και το SS Total παραμένει σταθερό, μικρότερο SS Error σημαίνει αυτόματα μεγαλύτερο SS Model (Δ). Η απάντηση Γ είναι λάθος: το SS Total δεν αλλάζει ανάμεσα σε μοντέλα — εξαρτάται μόνο από την εξαρτημένη μεταβλητή.
Μπορούμε να εφαρμόσουμε τις έννοιες του SS Model και του SS Error σε οποιοδήποτε μοντέλο, από εκείνα με μία μόνο ανεξάρτητη μεταβλητή έως αυτά με πολλές ανεξάρτητες μεταβλητές.
14.8 Χρήση Διαγραμμάτων Venn για την Εννοιολογική Κατανόηση των Αθροισμάτων Τετραγώνων, PRE και F
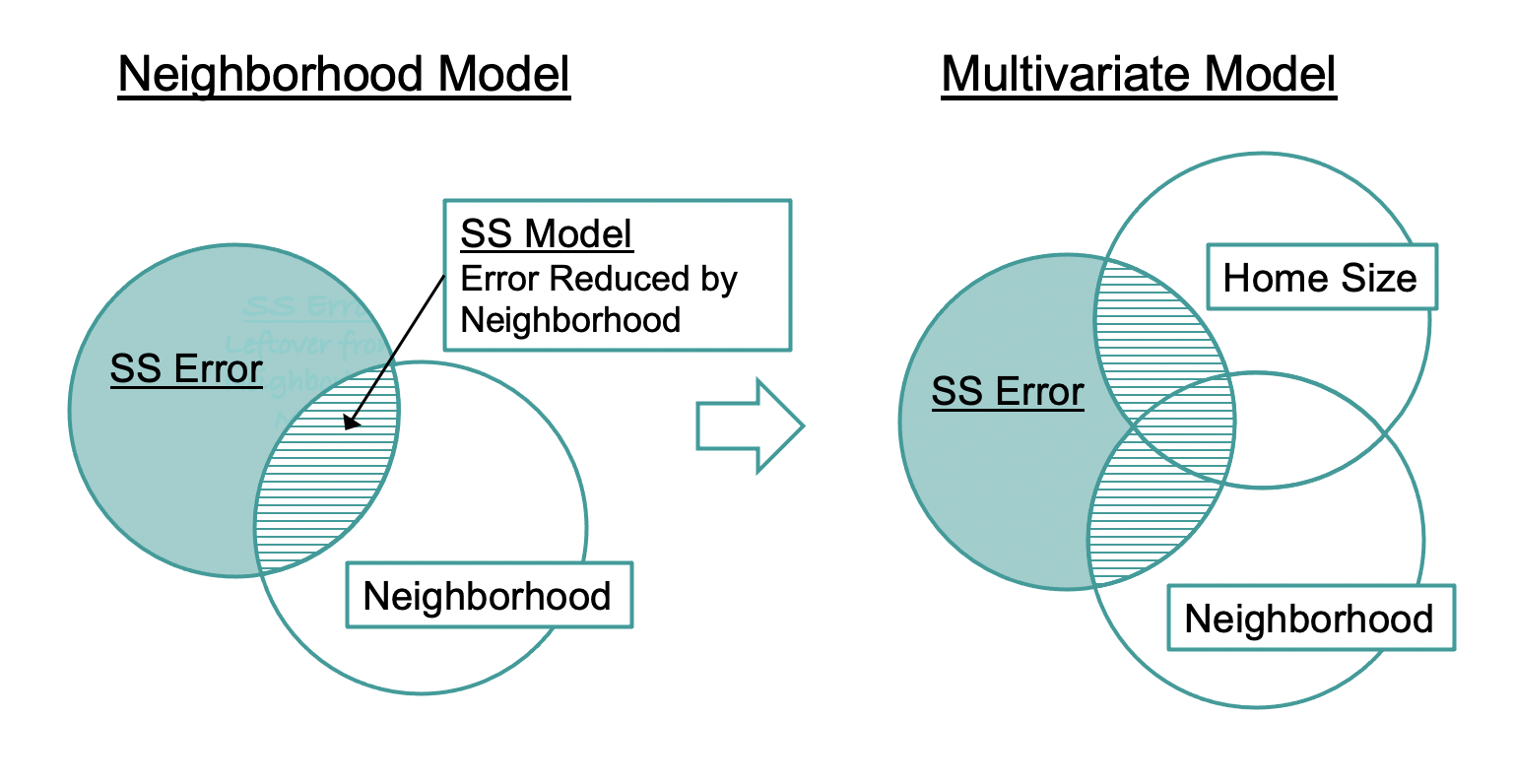
Τα διαγράμματα Venn είναι ένας χρήσιμος τρόπος για να μας βοηθήσουν να κατανοήσουμε τα αθροίσματα τετραγώνων στα πολυμεταβλητά μοντέλα. Το κενό μοντέλο της PriceK, που φαίνεται αριστερά στην παρακάτω εικόνα, μπορεί να αναπαρασταθεί με έναν μόνο κύκλο. Αυτός είναι το SS Total. Όταν προσθέτουμε μια ανεξάρτητη μεταβλητή στο μοντέλο (π.χ. την Neighborhood, όπως φαίνεται δεξιά), μειώνεται ένα μέρος αυτού του συνολικού σφάλματος. Αυτή η μείωση του σφάλματος (δηλαδή το SS Model) αναπαρίσταται από την περιοχή επικάλυψης μεταξύ των δύο κύκλων, που είναι γραμμοσκιασμένη.

Τι μας δείχνει το SS Model στο διάγραμμα Venn για το μοντέλο της Neighborhood;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η επικάλυψη μεταξύ των δύο κύκλων (η γραμμοσκιασμένη περιοχή) αναπαριστά το SS Model — το μέρος της συνολικής διακύμανσης της PriceK που εξηγείται από την Neighborhood. Επειδή η επικάλυψη δεν είναι μηδενική, ένα μέρος της διακύμανσης εξηγείται από τη μεταβλητή· επειδή δεν καλύπτει ολόκληρο τον κύκλο της PriceK, υπάρχει διακύμανση που παραμένει ανεξήγητη (το SS Error).
Ας οπτικοποιήσουμε τώρα τι συμβαίνει όταν προσθέτουμε τη μεταβλητή HomeSizeK στο μοντέλο (βλ. παρακάτω εικόνα). Η προσθήκη της HomeSizeK μειώνει περαιτέρω το σφάλμα, πέρα από αυτό που έχει ήδη μειώσει η Neighborhood.
Ποια είναι η διαφορά στο SS Error (το συμπαγές τιρκουάζ τμήμα) μεταξύ του μοντέλου της Neighborhood και του πολυμεταβλητού μοντέλου;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η προσθήκη μιας δεύτερης ανεξάρτητης μεταβλητής (HomeSizeK) επιτρέπει στο μοντέλο να εξηγήσει περισσότερη διακύμανση στην PriceK. Στο διάγραμμα Venn, το συμπαγές τιρκουάζ τμήμα (το SS Error — η ανεξήγητη διακύμανση) είναι μικρότερο στο πολυμεταβλητό μοντέλο επειδή τώρα και η HomeSizeK επικαλύπτεται με τον κύκλο της PriceK, αφαιρώντας επιπλέον σφάλμα από αυτό που είχε ήδη μειώσει η Neighborhood.
Ποια είναι η διαφορά στο SS Model (το γραμμοσκιασμένο τμήμα) μεταξύ αυτών των δύο μοντέλων, του μοντέλου της Neighborhood και του πολυμεταβλητού μοντέλου;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Επειδή ισχύει \(SS\,Total = SS\,Model + SS\,Error\) και το SS Total παραμένει το ίδιο (εξαρτάται μόνο από την εξαρτημένη μεταβλητή), όταν το SS Error μειώνεται, το SS Model αυτόματα αυξάνεται κατά την ίδια ποσότητα. Το πολυμεταβλητό μοντέλο εξηγεί περισσότερη διακύμανση συνολικά (από Neighborhood και HomeSizeK μαζί) σε σχέση με το μοντέλο που χρησιμοποιεί μόνο την Neighborhood.
Καθώς το SS Error μικραίνει, το SS Model μεγαλώνει. (Επειδή ισχύει \(SS\,Total = SS\,Model + SS\,Error\), όταν το ένα μεγαλώνει, το άλλο πρέπει να μικραίνει ώστε να αθροίζουν στο ίδιο SS Total.) Το SS Model — η ποσότητα της διακύμανσης που εξηγείται από το μοντέλο (αναπαρίσταται από τις τρεις γραμμοσκιασμένες περιοχές) — είναι μεγαλύτερο για το πολυμεταβλητό μοντέλο σε σχέση με το μοντέλο μίας ανεξάρτητης μεταβλητής (που περιλαμβάνει μόνο την Neighborhood).

Στο παραπάνω διάγραμμα Venn, έχουμε επισημάνει τις τρεις γραμμοσκιασμένες περιοχές ως A, B, C και την τιρκουάζ περιοχή ως D.
Ποια από αυτές τις περιοχές αντιστοιχεί στο SS Error του πίνακα ANOVA (104.774);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: D.
Το SS Error είναι η διακύμανση της PriceK που παραμένει ανεξήγητη από το πολυμεταβλητό μοντέλο. Στο διάγραμμα Venn, αυτό αντιστοιχεί στο τμήμα του κύκλου της PriceK που δεν επικαλύπτεται με κανέναν από τους κύκλους των ανεξάρτητων μεταβλητών — δηλαδή στην περιοχή D, που είναι χρωματισμένη με τιρκουάζ.
Ποια περιοχή ή περιοχές αναπαριστούν το SS Model (124403);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: (Α + Β + C).
Το SS Model αναπαριστά τη συνολική διακύμανση τηςPriceK που εξηγείται από το πολυμεταβλητό μοντέλο — δηλαδή όλη τη γραμμοσκιασμένη περιοχή επικάλυψης του κύκλου της PriceK με οποιαδήποτε από τις ανεξάρτητες μεταβλητές. Αυτή περιλαμβάνει τη διακύμανση που εξηγείται μόνο από την HomeSizeK (περιοχή Α), τη διακύμανση που εξηγείται μόνο από την Neighborhood (περιοχή C), καθώς και τη διακύμανση που εξηγείται και από τις δύο (περιοχή Β).
Ποια περιοχή ή περιοχές αναπαριστούν το SS Total (229177);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α + Β + C + D.
Το SS Total περιλαμβάνει όλη τη διακύμανση της PriceK — τόσο τη διακύμανση που εξηγείται από το μοντέλο (SS Model = Α + Β + C) όσο και τη διακύμανση που παραμένει ανεξήγητη (SS Error = D). Άρα SS Total = ολόκληρος ο κύκλος της PriceK = Α + Β + C + D, που επιβεβαιώνει την εξίσωση \(SS\,Total = SS\,Model + SS\,Error\).
Το SS Model, δηλαδή το σφάλμα που μειώνεται από το πολυμεταβλητό μοντέλο, αναπαρίσταται από τη συνολική επιφάνεια των περιοχών Α, Β και C. Ένα μέρος του σφάλματος μειώνεται αποκλειστικά από την HomeSizeK (περιοχή Α), ένα μέρος μειώνεται αποκλειστικά από την Neighborhood (περιοχή C), και ένα μέρος μειώνεται και από τις δύο μαζί (περιοχή Β)!
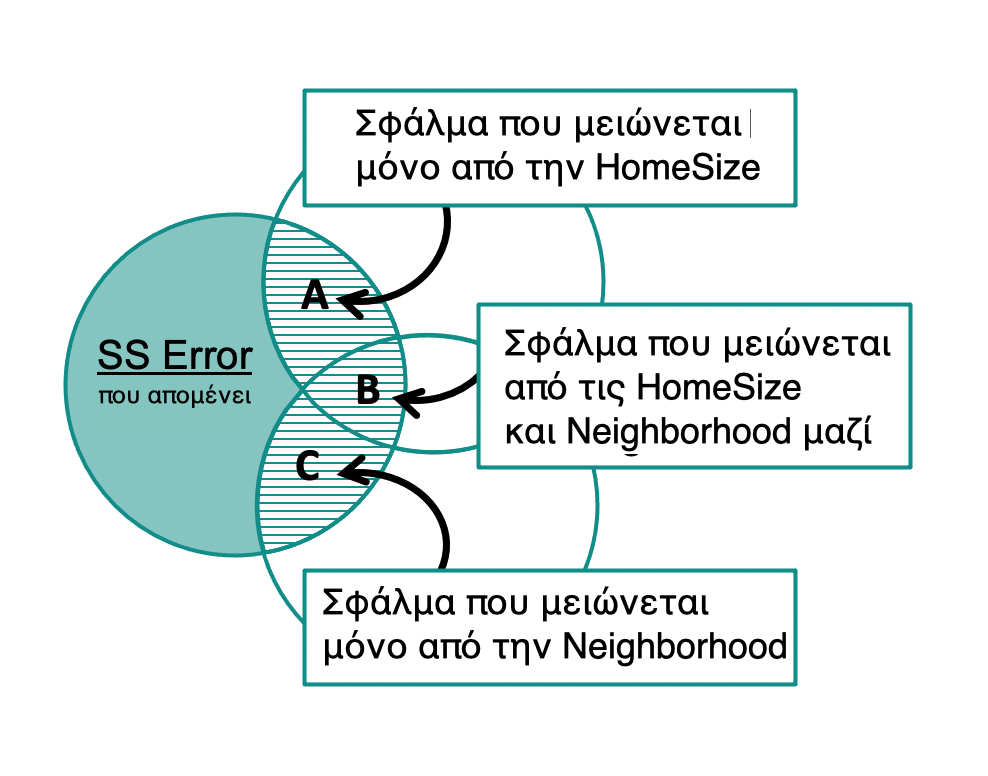 Αν η μεταβλητή
Αν η μεταβλητή HomeSizeK δεν είχε συμπεριληφθεί στο πολυμεταβλητό μοντέλο, θα μπορούσε η Neighborhood να εξηγήσει το σφάλμα που αναπαρίσταται από την περιοχή Α;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η περιοχή Α αναπαριστά τη διακύμανση που εξηγείται μόνο από την HomeSizeK — δηλαδή το τμήμα του κύκλου της PriceK που επικαλύπτεται με τον κύκλο της HomeSizeK αλλά όχι με τον κύκλο της Neighborhood. Αν η HomeSizeK δεν ήταν στο μοντέλο, αυτή η διακύμανση δεν θα μπορούσε να εξηγηθεί από την Neighborhood, επειδή η Neighborhood δεν επικαλύπτεται με αυτή την περιοχή.
Αν η HomeSizeK δεν είχε συμπεριληφθεί στο πολυμεταβλητό μοντέλο, θα μπορούσε η Neighborhood να εξηγήσει το σφάλμα που αναπαρίσταται από την περιοχή Β;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η περιοχή Β αναπαριστά τη διακύμανση στην PriceK που μπορεί να εξηγηθεί και από την HomeSizeK και από την Neighborhood — βρίσκεται στην επικάλυψη και των τριών κύκλων. Επομένως, ακόμη και χωρίς την HomeSizeK στο μοντέλο, η Neighborhood από μόνη της θα μπορούσε να εξηγήσει αυτή την περιοχή.
Αν φτιάχναμε ένα μοντέλο μίας μόνο ανεξάρτητης μεταβλητής χρησιμοποιώντας την HomeSizeK για να προβλέψουμε την PriceK, ποιο μέρος του παραπάνω διαγράμματος Venn θα αναπαριστούσε το SS Model;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το SS Model ενός μοντέλου μίας ανεξάρτητης μεταβλητής αναπαριστά όλη τη διακύμανση που μπορεί να εξηγήσει αυτή η μεταβλητή από μόνη της — όχι μόνο τη μοναδική της συνεισφορά. Στο διάγραμμα Venn, αυτό αντιστοιχεί σε ολόκληρη την περιοχή επικάλυψης του κύκλου της HomeSizeK με τον κύκλο της PriceK: τόσο το μέρος που εξηγείται μόνο από την HomeSizeK (περιοχή Α) όσο και το μέρος που μοιράζεται με την Neighborhood (περιοχή Β).
Η περιοχή Β υπάρχει επειδή το μέγεθος της κατοικίας και η γειτονιά συσχετίζονται μεταξύ τους. Όπως οι εκτιμήσεις των παραμέτρων έπρεπε να προσαρμοστούν ώστε να ληφθεί υπόψη αυτό το γεγονός, έτσι και το άθροισμα τετραγώνων πρέπει να προσαρμοστεί. Θα αναφερθούμε περισσότερο σε αυτό παρακάτω, αλλά προς το παρόν αξίζει να σημειώσουμε μία συνέπεια αυτού του γεγονότος: Το SS Model του πολυμεταβλητού μοντέλου δεν προκύπτει με απλή πρόσθεση των τιμών SS Model που λαμβάνονται από την προσαρμογή των δύο μοντέλων μίας ανεξάρτητης μεταβλητής χωριστά (γειτονιά και μέγεθος κατοικίας). Αν τα προσθέταμε χωριστά, θα μετρούσαμε την περιοχή Β δύο φορές, και έτσι θα υπερεκτιμούσαμε το SS Model του πολυμεταβλητού μοντέλου.
Χρήση του PRE για τη Σύγκριση του Πολυμεταβλητού με το Κενό Μοντέλο
Ξεκινήσαμε με τα υπόλοιπα, έπειτα τα υψώσαμε στο τετράγωνο και τα αθροίσαμε για να πάρουμε τα αθροίσματα τετραγώνων. Αλλά τα αθροίσματα τετραγώνων από μόνα τους έχουν περιορισμένη χρησιμότητα. Το πολυμεταβλητό μοντέλο, για παράδειγμα, παρήγαγε ένα SS Model ίσο με 124403. Παρόλο που αυτό φαίνεται σαν μια μεγάλη μείωση του σφάλματος, στην πραγματικότητα δεν μπορούμε να εκτιμήσουμε πόσο μεγάλη είναι, εκτός αν τη συγκρίνουμε με το SS Total.
Model: PriceK ~ Neighborhood + HomeSizeK
SS df MS F PRE p
------------ --------------- | ---------- -- --------- ------ ------ -----
Model (error reduced) | 124403.028 2 62201.514 17.216 0.5428 .0000
Neighborhood | 27758.259 1 27758.259 7.683 0.2094 .0096
HomeSizeK | 42003.677 1 42003.677 11.626 0.2862 .0019
Error (from model) | 104774.465 29 3612.913
------------ --------------- | ---------- -- --------- ------ ------ -----
Total (empty model) | 229177.493 31 7392.822Όπως κάναμε και με τα μοντέλα μίας ανεξάρτητης μεταβλητής, μπορούμε να χρησιμοποιήσουμε το PRE, ή την Αναλογική Μείωση του Σφάλματος (Proportional Reduction in Error), ως έναν πιο εύκολα ερμηνεύσιμο δείκτη του πόσο καλά προσαρμόζεται το μοντέλο μας στα δεδομένα. Το PRE στη γραμμή Model (error reduced) του πίνακα ANOVA μάς λέει την αναλογία του συνολικού σφάλματος του κενού μοντέλου που μειώνεται από το συνολικό πολυμεταβλητό μοντέλο. Μπορούμε να δούμε ότι για το μοντέλο που περιλαμβάνει και την Neighborhood και την HomeSizeK, το PRE είναι 0.54.
Με βάση όσα γνωρίζετε για το PRE, πώς έχει υπολογιστεί αυτό το PRE για το πολυμεταβλητό μοντέλο; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Γ.
Το PRE είναι η αναλογία του συνολικού σφάλματος (SS Total) που μειώνεται από το μοντέλο. Αυτό μπορεί να υπολογιστεί ισοδύναμα με δύο τρόπους: είτε ως \(SS\,Model / SS\,Total\) (Β), είτε ως \((SS\,Total - SS\,Error) / SS\,Total\) (Γ) — αφού \(SS\,Model = SS\,Total - SS\,Error\). Η απάντηση Α δίνει την αναλογία του σφάλματος που παραμένει ανεξήγητη, που είναι το αντίθετο του PRE (ισούται με \(1 - PRE\)).
Πώς θα ερμηνεύατε το PRE για το πολυμεταβλητό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το PRE μετρά πόσο από το συνολικό σφάλμα (SS Total, που προέρχεται από το κενό μοντέλο) μειώνεται όταν προσαρμόζουμε το πολυμεταβλητό μοντέλο. Η απάντηση Β δεν έχει νόημα — το κενό μοντέλο δεν μπορεί να «μειώσει» το SS Total αφού ίσα-ίσα το SS Total ορίζεται από το ίδιο το κενό μοντέλο. Η Γ συγχέει το SS Total με το SS Error: ο παρονομαστής στον τύπο του PRE είναι το SS Total, όχι το SS Error.
Χρήση του F για τη Σύγκριση του Πολυμεταβλητού με το Κενό Μοντέλο
Από το PRE, βλέπουμε ότι το πολυμεταβλητό μοντέλο έχει το σφάλμα κατά 54% σε σύγκριση με το κενό μοντέλο. Αυτό είναι ένα τεράστιο PRE! Πρέπει όμως να θυμηθούμε ότι αυτό το μοντέλο είναι επίσης πολύ πιο σύνθετο από το κενό. Άξιζε αυτή η μείωση του σφάλματος τους βαθμούς ελευθερίας που ξοδέψαμε; Όπως και πριν, θα χρησιμοποιήσουμε το πηλίκο F, το οποίο λαμβάνει υπόψη τους βαθμούς ελευθερίας, για να μας βοηθήσει να βγάλουμε αυτό το συμπέρασμα.
Ας ξεκινήσουμε εξετάζοντας πόσοι βαθμοί ελευθερίας χρησιμοποιούνται από το πολυμεταβλητό μοντέλο σε σύγκριση με το κενό μοντέλο.
| PriceK = Neighborhood + HomeSizeK + Σφάλμα | PriceK = Μέσος Όρος + Σφάλμα |
|---|---|
| \(Y_i = b_0 + b_1 X_{1i} + b_2 X_{2i} + e_i\) | \(Y_i = b_0 + e_i\) |
Στον παραπάνω πίνακα, το πολυμεταβλητό μοντέλο φαίνεται αριστερά (τόσο ως λεκτική εξίσωση όσο και σε σημειογραφία GLM, και το κενό μοντέλο φαίνεται στα δεξιά.
Πόσες παράμετροι εκτιμώνται στο κενό μοντέλο;
ΣημείωσηΑπάντηση
1 παράμετρος — μόνο το \(b_0\) (ο μέσος όρος της εξαρτημένης μεταβλητής).
Πόσες παράμετροι εκτιμώνται στο πολυμεταβλητό μοντέλο;
ΣημείωσηΑπάντηση
3 παράμετροι — τα \(b_0\), \(b_1\) (για την Neighborhood) και \(b_2\) (για την HomeSizeK).
Πόσες περισσότερες παράμετροι εκτιμώνται από το πολυμεταβλητό μοντέλο σε σύγκριση με το κενό μοντέλο;
ΣημείωσηΑπάντηση
2 περισσότερες παράμετροι (\(3 - 1 = 2\)). Αυτές οι 2 επιπλέον παράμετροι είναι και οι 2 βαθμοί ελευθερίας που χρησιμοποιεί το πολυμεταβλητό μοντέλο σε σχέση με το κενό.
Μπορείτε να δείτε στον πίνακα ANOVA του πολυμεταβλητού μοντέλου ότι ο αριθμός των παραμέτρων που εκτιμώνται και οι αριθμοί στη στήλη df (βαθμοί ελευθερίας) σχετίζονται μεταξύ τους. Η εκτίμηση του κενού μοντέλου κοστίζει ένα βαθμό ελευθερίας, γι’ αυτό και το df Total (31) είναι κατά ένα μικρότερο από το μέγεθος του δείγματος (32 κατοικίες). Το df Model είναι 2 επειδή το πολυμεταβλητό μοντέλο εκτιμά δύο επιπλέον παραμέτρους σε σχέση με το κενό μοντέλο. Μετά την προσαρμογή του πολυμεταβλητού μοντέλου, μας μένουν 29 βαθμοί ελευθερίας, που εμφανίζονται στον πίνακα ANOVA ως df Error.
Model: PriceK ~ Neighborhood + HomeSizeK
SS df MS F PRE p
------------ --------------- | ---------- -- --------- ------ ------ -----
Model (error reduced) | 124403.028 2 62201.514 17.216 0.5428 .0000
Neighborhood | 27758.259 1 27758.259 7.683 0.2094 .0096
HomeSizeK | 42003.677 1 42003.677 11.626 0.2862 .0019
Error (from model) | 104774.465 29 3612.913
------------ --------------- | ---------- -- --------- ------ ------ -----
Total (empty model) | 229177.493 31 7392.822Ενώ το PRE βασίζεται στα SS, το στατιστικό \(F\) βασίζεται στο μέσο άθροισμα τετραγώνων (MS, mean square), το οποίο προκύπτει διαιρώντας το SS με τους βαθμούς ελευθερίας που ξοδεύτηκαν. Με αυτόν τον τρόπο, λαμβάνεται υπόψη η πολυπλοκότητα του μοντέλου και το πόσοι βαθμοί ελευθερίας χρησιμοποιήθηκαν για την εκτίμηση των παραμέτρων. Υπενθυμίζουμε ότι το \(F\) είναι η μείωση του σφάλματος ανά βαθμό ελευθερίας που ξοδεύτηκε (MS Model) διά το σφάλμα που απομένει ανά βαθμό ελευθερίας που απομένει (MS Error).
\[F = \frac{MS\,Model}{MS\,Error} = \frac{SS\,Model / df\,Model}{SS\,Error / df\,Error}\] Ποιοι αριθμοί διαιρέθηκαν για να υπολογιστεί η τιμή \(F\) που είναι επισημασμένη στη γραμμή Model παραπάνω;
ΣημείωσηΑπάντηση
\(F = MS\,Model / MS\,Error = 62201.514 / 3612.913 = 17.216\)
Δηλαδή το MS Model (62201,514) διαιρείται με το MS Error (3612,913). Ισοδύναμα, αυτό προκύπτει από τη διαίρεση των αντίστοιχων αθροισμάτων τετραγώνων με τους βαθμούς ελευθερίας τους: \((124403.028 / 2) \div (104774.465 / 29) = 17.216\).
Ποια από τις ακόλουθες είναι η σωστή ερμηνεία της τιμής \(F\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Το στατιστικό \(F\) δεν εκφράζει αριθμό παρατηρήσεων ούτε ποσοστό. Είναι ένας λόγος: το μέσο σφάλμα που μειώνεται ανά βαθμό ελευθερίας που ξοδεύεται (MS Model) προς το μέσο σφάλμα που απομένει ανά βαθμό ελευθερίας που απομένει (MS Error). Όταν αυτό το πηλίκο είναι μεγάλο (όπως εδώ, 17), σημαίνει ότι κάθε βαθμός ελευθερίας που χρησιμοποιήθηκε για την προσθήκη παραμέτρων στο μοντέλο μείωσε πολύ περισσότερο σφάλμα από όσο θα έκανε αν απλώς συνεχίζαμε να εξηγούμε το εναπομένον σφάλμα.
Οι απαντήσεις Α έως Γ συγχέουν το \(F\) με άλλες έννοιες: η Α συγχέει το \(F\) με αριθμό παρατηρήσεων, ενώ οι Β και Γ συγχέουν το \(F\) με ποσοστό μείωσης του σφάλματος (που είναι το PRE — εδώ 0.54 ή 54%, όχι 17%).
Αυτή η σχετικά μεγάλη τιμή \(F\) μάς δείχνει ότι αυτό το πολυμεταβλητό μοντέλο είναι μια αρκετά καλή «επένδυση» σε σύγκριση με το κενό μοντέλο. Είχαμε μεγάλο κέρδος για τα όσα ξοδέψαμε — δηλαδή σημαντική μείωση του σφάλματος για τους βαθμούς ελευθερίας που καταναλώθηκαν.
14.9 Η Λογική της Στατιστικής Συμπερασματολογίας με το Πολυμεταβλητό Μοντέλο
Τόσο το \(F\) όσο και το PRE μας προσφέρουν τρόπους να αξιολογήσουμε, με έναν μόνο αριθμό, πόσο καλά προσαρμόζεται το πολυμεταβλητό μοντέλο στα δεδομένα μας σε σύγκριση με το κενό μοντέλο. Μάθαμε, σε αυτή την περίπτωση, ότι το 54% της διακύμανσης στην PriceK μπορεί να εξηγηθεί από το πολυμεταβλητό μοντέλο μας, χρησιμοποιώντας και τη γειτονιά και το μέγεθος της κατοικίας ως ανεξάρτητες μεταβλητές.
Όμως το πραγματικό μας ενδιαφέρον δεν είναι για το τι ισχύει στα δεδομένα μας, αλλά για το τι ισχύει στη Διαδικασία Παραγωγής Δεδομένων (ΔΠΔ). Ένας σημαντικός λόγος για τον οποίο τα δεδομένα και η ΔΠΔ μπορεί να διαφέρουν είναι η δειγματοληπτική μεταβλητότητα: δείγματα από την ίδια ΔΠΔ θα διαφέρουν το ένα από το άλλο μόνο και μόνο λόγω τυχαιότητας. Η «στατιστική συμπερασματολογία» αναφέρεται στη διαδικασία με την οποία, χρησιμοποιώντας δειγματοληπτικές κατανομές, συμπεραίνουμε τι ισχύει στη ΔΠΔ με βάση τα μοντέλα μας τα οποία βασίζονται στα δεδομένα.
Σε αυτό το βιβλίο έχουμε ακολουθήσει δύο προσεγγίσεις στη συμπερασματολογία: τη σύγκριση μοντέλων, όπου προσπαθούμε να αποφασίσουμε ποιο από δύο μοντέλα είναι καλύτερο μοντέλο της ΔΠΔ· και τα διαστήματα εμπιστοσύνης, όπου προσπαθούμε να εκτιμήσουμε ποια θα μπορούσε να είναι η πραγματική παράμετρος με βάση τη συγκεκριμένη εκτίμηση που έχουμε δημιουργήσει από τα δεδομένα μας. Ας δούμε πώς βρίσκουν εφαρμογή και οι δύο στο πλαίσιο των πολυμεταβλητών μοντέλων.
Η Λογική της Σύγκρισης Μοντέλων
Στη σύγκριση μοντέλων, συγκρίνουμε ένα πιο σύνθετο μοντέλο της ΔΠΔ με ένα πιο απλό. Προηγουμένως συγκρίναμε ένα μοντέλο μίας ανεξάρτητης μεταβλητής (πιο σύνθετο) με το κενό μοντέλο (πιο απλό). Μπορούμε να χρησιμοποιήσουμε την ίδια προσέγγιση για να συγκρίνουμε το πολυμεταβλητό μοντέλο της ΔΠΔ με το κενό μοντέλο. Κατασκευάζεται μια δειγματοληπτική κατανομή του \(F\) με βάση την υπόθεση ότι το κενό μοντέλο είναι αληθές, και στη συνέχεια το δειγματικό \(F\) που προκύπτει από την προσαρμογή του πολυμεταβλητού μοντέλου στα δεδομένα αξιολογείται στο πλαίσιο αυτής της δειγματοληπτικής κατανομής.
Αν η τιμή του \(F\) κριθεί απίθανο να έχει παραχθεί από το κενό μοντέλο, το κενό μοντέλο απορρίπτεται υπέρ του πολυμεταβλητού. Αν η τιμή \(F\) κριθεί όχι απίθανο να έχει παραχθεί από το κενό μοντέλο, το κενό μοντέλο δεν απορρίπτεται. Ας δούμε αυτή τη διαδικασία με περισσότερες λεπτομέρειες παρακάτω.
Στην περίπτωση του πολυμεταβλητού μοντέλου της PriceK, αυτά είναι τα δύο μοντέλα που συγκρίνονται:
- Σύνθετο: \(Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \epsilon_i\)
- Απλό: \(Y_i = \beta_0 + \epsilon_i\)
Σημειώστε ότι στη σύγκριση μοντέλων, συγκρίνουμε πάντα δύο μοντέλα, ένα σύνθετο και ένα απλό. Όμως οι όροι «σύνθετο» και «απλό» είναι σχετικοί. Στην περίπτωση των μοντέλων μίας ανεξάρτητης μεταβλητής, το σύνθετο μοντέλο δεν είναι τόσο σύνθετο όσο το πολυμεταβλητό, αν και είναι ακόμα πιο σύνθετο από το κενό μοντέλο. Το κενό μοντέλο, ωστόσο, είναι το πιο απλό από τα απλά μοντέλα.
Κατασκευή Δειγματοληπτικής Κατανομής του F Υποθέτοντας το Κενό Μοντέλο
Προηγουμένως, με τα μοντέλα μίας ανεξάρτητης μεταβλητής, είχαμε μόνο μία ανεξάρτητη μεταβλητή (π.χ. την Neighborhood) στο μοντέλο μας. Συγκρίναμε το μοντέλο της Neighborhood με το κενό μοντέλο, το οποίο υπέθετε ότι δεν υπήρχε σχέση στη ΔΠΔ μεταξύ της εξαρτημένης μεταβλητής (PriceK) και της ανεξάρτητης (Neighborhood). Οποιαδήποτε τέτοια σχέση στα δεδομένα, λοιπόν, υποτίθεται ότι ήταν εξ ολοκλήρου αποτέλεσμα τυχαιότητας.
Στον παρακάτω πίνακα, έχουμε γράψει τη σημειογραφία GLM για το μοντέλο της Neighborhood και για το κενό μοντέλο της ΔΠΔ, καθώς και ένα απόσπασμα κώδικα R που αναπαριστά αυτές τις δύο ΔΠΔ.
Μοντέλο της Neighborhood στη ΔΠΔ |
Κενό μοντέλο στη ΔΠΔ |
|---|---|
| \(Y_i = \beta_0 + \beta_1 X_i + \epsilon_i\) | \(Y_i = \beta_0 + 0 \cdot X_i + \epsilon_i\) |
PriceK ~ Neighborhood |
shuffle(PriceK) ~ Neighborhood |
Παρατηρήστε ότι συμπεριλάβαμε τον όρο \(X_i\) στην αναπαράσταση του κενού μοντέλου, αλλά αντικαταστήσαμε το \(\beta_1\) με 0. Αυτός είναι ένας τρόπος να υποδείξουμε ότι δεν γράψαμε απλώς ένα μοντέλο χωρίς την Neighborhood, αλλά ένα μοντέλο στο οποίο η επίδραση της Neighborhood είναι περιορισμένη να είναι 0. Μιμηθήκαμε αυτή τη ΔΠΔ στη R χρησιμοποιώντας τη συνάρτηση shuffle() πριν από την PriceK. Τώρα δεν υπάρχει σχέση (εκτός από τυχαία σχέση) μεταξύ της PriceK και της Neighborhood.
Ποιο από τα παρακάτω τμήμα κώδικα R νομίζετε ότι θα δημιουργούσε μια δειγματοληπτική κατανομή του \(F\) για τη σύγκριση του πολυμεταβλητού μοντέλου με το κενό μοντέλο της ΔΠΔ — δηλαδή ένα μοντέλο στο οποίο και η Neighborhood και η HomeSizeK είναι περιορισμένες να είναι 0, και στο οποίο οποιαδήποτε διακύμανση στο \(F\) μπορεί να υποτεθεί ότι οφείλεται αποκλειστικά σε τυχαία δειγματοληπτική διακύμανση;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Ε.
Για να προσομοιώσουμε ένα κενό μοντέλο της ΔΠΔ — όπου καμία από τις δύο ανεξάρτητες μεταβλητές δεν έχει πραγματική σχέση με την εξαρτημένη — πρέπει να σπάσουμε όλες τις σχέσεις της εξαρτημένης μεταβλητής με τις ανεξάρτητες. Αυτό επιτυγχάνεται ανακατεύοντας την PriceK σε σχέση με και τις δύο ανεξάρτητες μεταβλητές ταυτόχρονα — δηλαδή με την εντολή shuffle(PriceK) ~ Neighborhood + HomeSize (Ε).
Οι απαντήσεις Α και Β ανακατεύουν μόνο σε σχέση με τη μία ανεξάρτητη μεταβλητή — δεν αναπαριστούν το πλήρες πολυμεταβλητό μοντέλο. Οι Γ και Δ ανακατεύουν μία από τις ανεξάρτητες μεταβλητές αντί για την εξαρτημένη — αυτό σπάει τη σχέση μόνο με τη μία ανεξάρτητη, ενώ διατηρεί την άλλη σχέση άθικτη, οπότε δεν αντιστοιχεί στο πλήρες κενό μοντέλο.
Χρησιμοποιώντας τη σημειογραφία GLM, πώς θα μπορούσαμε να αναπαραστήσουμε το κενό μοντέλο της ΔΠΔ που θέλουμε να συγκρίνουμε με το πολυμεταβλητό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Στο κενό μοντέλο που αντιστοιχεί στο πολυμεταβλητό μοντέλο, υποθέτουμε ότι και οι δύο ανεξάρτητες μεταβλητές δεν έχουν πραγματική επίδραση στην εξαρτημένη — δηλαδή ότι \(\beta_1 = 0\) και \(\beta_2 = 0\). Επομένως, και οι δύο όροι κλίσης γίνονται μηδέν. Παρόλα αυτά, διατηρούμε το \(\beta_0\) — που αντιπροσωπεύει τον μέσο όρο της ΔΠΔ — επειδή το κενό μοντέλο εξακολουθεί να προβλέπει αυτόν τον μέσο όρο για όλες τις παρατηρήσεις.
Η απάντηση Α περιγράφει το μοντέλο μίας ανεξάρτητης μεταβλητής, όχι το κενό μοντέλο που αντιστοιχεί στο πολυμεταβλητό. Η Β έχει συντακτικό λάθος (\(\beta_1\) εμφανίζεται δύο φορές) και δεν είναι το κενό μοντέλο. Οι Δ και Ε αντικαθιστούν εσφαλμένα και το \(\beta_0\) με 0 — αλλά το \(\beta_0\) είναι ο πληθυσμιακός μέσος όρος, ο οποίος δεν είναι 0.
Στον παρακάτω πίνακα, έχουμε γράψει τη σημειογραφία GLM για το πολυμεταβλητό και το κενό μοντέλο της ΔΠΔ (μαζί με ένα απόσπασμα κώδικα R).
| Πολυμεταβλητό μοντέλο της ΔΠΔ | Κενό μοντέλο αυτής της ΔΠΔ |
|---|---|
| \(Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \epsilon_i\) | \(Y_i = \beta_0 + (0) X_{1i} + (0) X_{2i} + \epsilon_i\) |
PriceK ~ Neighborhood + HomeSizeK |
shuffle(PriceK) ~ Neighborhood + HomeSizeK |
Με τα μοντέλα μίας ανεξάρτητης μεταβλητής μπορούσαμε να ανακατέψουμε είτε την εξαρτημένη είτε την ανεξάρτητη μεταβλητή· το αποτέλεσμα θα ήταν το ίδιο. Με τα πολυμεταβλητά μοντέλα, ανακατεύουμε μόνο την εξαρτημένη μεταβλητή, επειδή θέλουμε να αφήσουμε άθικτη τη σχέση μεταξύ της Neighborhood και της HomeSizeK, ενώ ταυτόχρονα να σπάσουμε τη σχέση και των δύο μεταβλητών με την PriceK.
Μπορούμε να χρησιμοποιήσουμε αυτή την τυχαία ΔΠΔ για να δημιουργήσουμε μια δειγματοληπτική κατανομή τιμών \(F\), και στη συνέχεια να συγκρίνουμε τη δειγματική τιμή \(F\) που λαμβάνουμε από την προσαρμογή του πολυμεταβλητού μοντέλου στα δεδομένα μας με αυτή τη δειγματοληπτική κατανομή.
Αν η δειγματική τιμή \(F\) είναι απίθανο να προέρχεται από τη ΔΠΔ που αναπαρίσταται από το κενό μοντέλο, τι θα πρέπει να σκεφτούμε για το κενό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Αν η δειγματική τιμή \(F\) είναι απίθανο να έχει παραχθεί από το κενό μοντέλο, αυτό αποτελεί ένδειξη ότι το κενό μοντέλο δεν περιγράφει καλά τη ΔΠΔ που πραγματικά παρήγαγε τα δεδομένα μας. Αυτή είναι η λογική του ελέγχου μηδενικής υπόθεσης: αν τα δεδομένα φαίνονται απίθανα υπό το κενό μοντέλο, το απορρίπτουμε υπέρ του πιο σύνθετου μοντέλου (στην προκειμένη, του πολυμεταβλητού).
Μπορούμε να υπολογίσουμε μια τιμή \(p\) που θα μας πει πόσο πιθανό θα ήταν μια τιμή \(F\) τόσο ακραία όσο αυτή που παρατηρήσαμε να έχει προέλθει από μια ΔΠΔ στην οποία ισχύει το κενό μοντέλο. Αν είναι απίθανο (και μπορούμε να ορίσουμε ως «απίθανο» μια τιμή μικρότερη από 0.05 ή 5%), τότε μπορούμε να απορρίψουμε το κενό μοντέλο υπέρ του πολυμεταβλητού μοντέλου μας.
Παρατηρήστε ότι αυτή είναι ακριβώς η ίδια λογική που χρησιμοποιήσαμε για τα μοντέλα μίας ανεξάρτητης μεταβλητής. Η μόνη διαφορά είναι ότι το τυχαίο ανακάτεμα της εξαρτημένης μεταβλητής τώρα σπάει τη σχέση της με πολλαπλές ανεξάρτητες μεταβλητές αντί για μία μόνο.
Παρακάτω έχουμε γράψει κώδικα για να υπολογίσουμε τη δειγματική τιμή f() για το πολυμεταβλητό μοντέλο. Τροποποιήστε τον κώδικα ώστε να ανακατεύει (shuffle()) την εξαρτημένη μεταβλητή.
Εκτελέστε τον παραπάνω κώδικα που μόλις τροποποιήσατε μερικές ακόμη φορές για να δείτε τι είδους τιμές \(F\) παράγονται τυχαία από το κενό μοντέλο. Πώς συγκρίνεται η δειγματική τιμή \(F\), η οποία ήταν λίγο πάνω από 17, με αυτές τις τυχαία παραγόμενες τιμές \(F\);
Από λίγες μόνο επαναλήψεις του τυχαίου ανακατέματος, φαίνεται ότι θα ήταν σπάνιο για μια ΔΠΔ στην οποία ισχύει το κενό μοντέλο να παράγει μια τιμή \(F\) τόσο μεγάλη όσο το 17. Μπορεί να είναι δυνατό, αλλά δεν φαίνεται πιθανό. Έχουμε όμως κοιτάξει μόνο λίγες τιμές \(F\). Ας δούμε τι άλλο μπορούμε να μάθουμε δημιουργώντας μια δειγματοληπτική κατανομή 1.000 τιμών \(F\) μετά από τυχαίο ανακάτεμα.
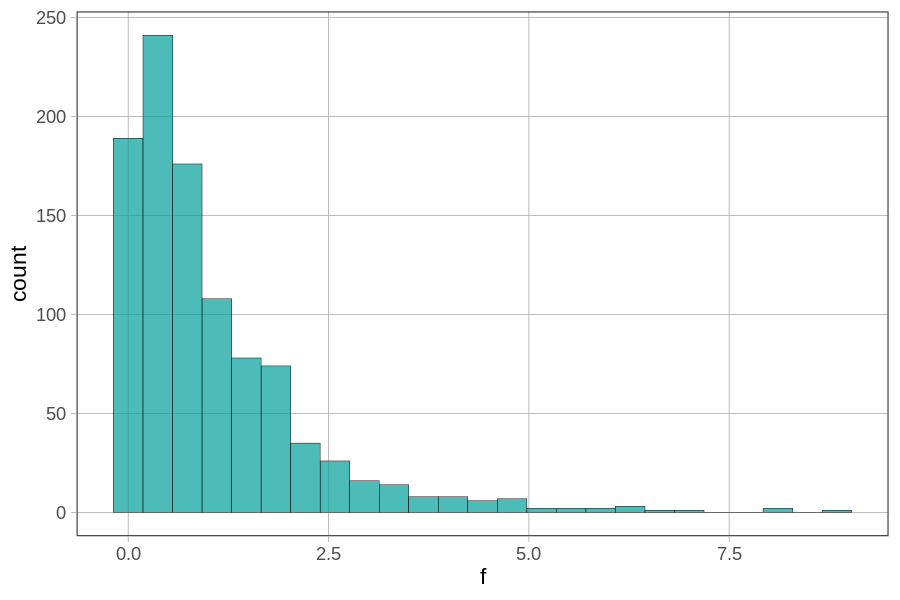
Παρατηρήστε ότι η δειγματοληπτική κατανομή έχει κάτω όριο το 0 και είναι ασύμμετρη, με μακριά ουρά προς τα δεξιά. Μπορούμε να δούμε από την κλίμακα του άξονα x ότι καμία από τις 1.000 τυχαία παραγόμενες τιμές \(F\) δεν ήταν τόσο μεγάλη όσο η δειγματική \(F = 17\). Η μεγαλύτερη τιμή, στην πραγματικότητα, φαίνεται να είναι γύρω στο 8.
14.10 Χρήση της Δειγματοληπτικής Κατανομής του F
Παρακάτω βλέπετε την ίδια δειγματοληπτική κατανομή, αλλά αυτή τη φορά με τον άξονα x να εκτείνεται πολύ περισσότερο.

Πού θα έπεφτε η δειγματική τιμή \(F\) (17) στην παραπάνω δειγματοληπτική κατανομή; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Β.
Κοιτάζοντας τον άξονα x (που αναπαριστά τις τιμές του f), βλέπουμε ότι η δειγματική μας τιμή \(F = 17\) βρίσκεται πολύ μακριά από τον όγκο των \(F\) της δειγματοληπτικής κατανομής (που είναι κυρίως μεταξύ του 0 και του 5). Βρίσκεται στην ακραία δεξιά ουρά (Α), και σαφώς εντός της απίθανης περιοχής (Β) — επειδή καμία από τις 1.000 τιμές \(F\) μετά από τυχαίο ανακάτεμα δεν έφτασε ούτε καν στο 10.
Τι θα πρέπει να περιμένουμε ότι θα είναι η τιμή \(p\) (η πιθανότητα το κενό μοντέλο να παράγει μια τιμή \(F\) πιο ακραία από τη δειγματική μας τιμή \(F\));
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η τιμή \(p\) είναι η αναλογία τιμών \(F\) στη δειγματοληπτική κατανομή που είναι τόσο ή πιο ακραίες από τη δειγματική μας \(F\). Επειδή η δειγματική τιμή \(F = 17\) είναι μεγαλύτερη από όλες τις 1.000 τιμές \(F\) που παρήγαγε το ανακάτεμα, σχεδόν καμία (ή καμία) τιμή στη δειγματοληπτική κατανομή δεν είναι τόσο ακραία — οπότε η τιμή \(p\) είναι πάρα πολύ κοντά στο 0. Οι άλλες απαντήσεις δεν έχουν νόημα: η πιθανότητα δεν μπορεί να πάρει αρνητική τιμή (Α), η τιμή 0.05 (Γ) είναι το επίπεδο σημαντικότητας — όχι αυτή που περιμένουμε όταν η \(F\) είναι τόσο ακραία, και οι Δ και Ε συγχέουν την τιμή \(p\) με το ίδιο το στατιστικό \(F\).
Ας υπολογίσουμε την τιμή \(p\) από την ανακατεμένη δειγματοληπτική κατανομή του \(F\) χρησιμοποιώντας τη συνάρτηση tally(). Θα πρέπει να προκύψει παρόμοιος αριθμός με την τιμή \(p\) που βρίσκεται στη γραμμή Model του πίνακα ANOVA.
TRUE FALSE
0 1Εύρεση της Τιμής \(p\) στον Πίνακα ANOVA
Αν ελέγξουμε τον πίνακα ANOVA (που παρουσιάζεται παρακάτω), η τιμή που λάβαμε από την tally() (0) αντιστοιχεί στην πρώτη γραμμή της στήλης \(p\).
Model: PriceK ~ Neighborhood + HomeSizeK
SS df MS F PRE p
------------ --------------- | ---------- -- --------- ------ ------ -----
Model (error reduced) | 124403.028 2 62201.514 17.216 0.5428 .0000
Neighborhood | 27758.259 1 27758.259 7.683 0.2094 .0096
HomeSizeK | 42003.677 1 42003.677 11.626 0.2862 .0019
Error (from model) | 104774.465 29 3612.913
------------ --------------- | ---------- -- --------- ------ ------ -----
Total (empty model) | 229177.493 31 7392.822Ίσως παρατηρήσατε ότι υπάρχουν αρκετές διαφορετικές τιμές \(p\) σε αυτόν τον πίνακα ANOVA — γιατί θα κοιτάξουμε την τιμή \(p\) που βρίσκεται στην πρώτη γραμμή; Η γραμμή Model αντιστοιχεί στη σύγκριση μεταξύ του πολυμεταβλητού και του κενού μοντέλου. Οι άλλες δύο τιμές \(p\) (που βρίσκονται στις γραμμές Neighborhood και HomeSizeK) αναπαριστούν συγκρίσεις μεταξύ του μοντέλου με και χωρίς τη συγκεκριμένη μεταβλητή. Θα εμβαθύνουμε σε αυτές τις συγκρίσεις μοντέλων στο επόμενο κεφάλαιο.
Από την τιμή \(p\) της γραμμής Model, βλέπουμε ότι η δειγματική μας τιμή \(F\) είναι πολύ απίθανο να έχει παραχθεί από το κενό μοντέλο της ΔΠΔ. Η τιμή \(p\) είναι τόσο μικρή που θα λέγαμε ότι \(p < 0.001\).
Τι σημαίνει αυτή η τιμή \(p\) για το πολυμεταβλητό μοντέλο της ΔΠΔ (όπου χρησιμοποιούμε και την Neighborhood και την HomeSizeK για να προβλέψουμε την τιμή κατοικίας);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Μια μικρή τιμή \(p\) μάς λέει ότι θα ήταν σπάνιο να παρατηρήσουμε μια δειγματική τιμή \(F\) τόσο μεγάλη όσο η δική μας, αν το κενό μοντέλο ίσχυε στη ΔΠΔ. Έτσι, απορρίπτουμε το κενό μοντέλο υπέρ του πολυμεταβλητού. Η απάντηση Α συγχέει την τιμή \(p\): δεν είναι η πιθανότητα να είναι σωστό το πολυμεταβλητό μοντέλο, είναι η πιθανότητα να παρατηρήσουμε τα δεδομένα μας αν ίσχυε το κενό μοντέλο. Η Γ συγχέει την τιμή \(p\) με σύγκριση μεταξύ άλλων μοντέλων. Η Δ είναι ακριβώς το αντίθετο της σωστής ερμηνείας — μικρή τιμή \(p\) σημαίνει ότι απορρίπτουμε το κενό μοντέλο.
Αυτή η μικρή τιμή \(p\) υποδηλώνει ότι το κενό μοντέλο είναι απίθανο να παράγει ένα \(F\) τόσο ακραίο όσο αυτό που προσαρμόστηκε από το πολυμεταβλητό μοντέλο μας. Επομένως, απορρίπτουμε το κενό μοντέλο (στο οποίο και το \(\beta_1\) για την Neighborhood και το \(\beta_2\) για την HomeSizeK ισούνται με 0) υπέρ του πολυμεταβλητού μοντέλου (στο οποίο οι τιμές των \(\beta_1\) και \(\beta_2\) δεν είναι 0).
Διαστήματα Εμπιστοσύνης για το Πολυμεταβλητό Μοντέλο
Μόνο με τα δεδομένα του δείγματος και τη δύναμη της προσομοίωσης, καταφέραμε να αποκλείσουμε το κενό μοντέλο ως μοντέλο της ΔΠΔ. Έχοντας συμπεράνει ότι τα \(\beta_1\) και \(\beta_2\) δεν είναι και τα δύο 0, ίσως αναρωτιόμαστε: ποιες είναι οι πραγματικές τιμές τους;
Εδώ έρχονται στο προσκήνιο τα διαστήματα εμπιστοσύνης, που αποκαλούνται επίσης και διαδικασία εκτίμησης παραμέτρων. Όπως και πριν, μπορούμε να χρησιμοποιήσουμε την confint() για να εκτιμήσουμε τις χαμηλότερες και υψηλότερες τιμές των \(\beta\) που θα μπορούσαν εύλογα να παράγουν το δείγμα μας. Δοκιμάστε το στο παρακάτω πλαίσιο κώδικα.
2.5 % 97.5 %
(Intercept) 87.95358 266.54808
NeighborhoodEastside -115.07739 -17.35826
HomeSizeK 27.15159 108.54819Μπορούμε να ερμηνεύσουμε αυτά τα διαστήματα εμπιστοσύνης με τον ίδιο τρόπο όπως και πριν. Φανταζόμαστε πολλές διαφορετικές πιθανές εναλλακτικές τιμές του \(\beta_1\) που θα μπορούσαν, με 95% βεβαιότητα, να παρήγαγαν το δειγματικό \(b_1\). Μπορούμε επίσης να κάνουμε το ίδιο για το \(\beta_2\) και οποιαδήποτε άλλο \(\beta\) μπορεί να υπάρχει στο σύνθετο μοντέλο μας.
Ας εστιάσουμε την προσοχή μας στις τιμές −115 και −17 (στρογγυλοποιημένες) στη γραμμή NeighborhoodEastside. Τι σημαίνουν αυτοί οι αριθμοί; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Β.
Το διάστημα εμπιστοσύνης στη γραμμή NeighborhoodEastside αφορά την παράμετρο \(\beta_1\) — δηλαδή τη μέση διαφορά στην τιμή μιας κατοικίας στο Eastside σε σύγκριση με μια ίδιου μεγέθους κατοικία στο Downtown (Α και Β λένε το ίδιο πράγμα με διαφορετικό τρόπο). Το αρνητικό πρόσημο σημαίνει ότι, για ίδιο μέγεθος, μια κατοικία στο Eastside πωλείται φθηνότερα από μία στο Downtown κατά 17 έως 115 χιλιάδες δολάρια.
Οι απαντήσεις Γ και Δ αποτελούν δύο πολύ συνηθισμένες παρανοήσεις των διαστημάτων εμπιστοσύνης:
Η απάντηση Γ συγχέει το ΔΕ μιας παραμέτρου με το εύρος των ατομικών τιμών. Το ΔΕ για το \(\beta_1\) δεν μας λέει τίποτα για το πού πέφτουν οι τιμές μεμονωμένων κατοικιών — αναφέρεται στην πραγματική τιμή μιας παραμέτρου του πληθυσμού. Για παράδειγμα, οι αριθμοί −115 και −17 είναι αρνητικοί, αλλά καμία πραγματική τιμή κατοικίας δεν είναι αρνητική. Αυτό από μόνο του δείχνει ότι το διάστημα δεν αφορά τις τιμές των ίδιων των κατοικιών.
Η απάντηση Δ συγχέει το \(\beta_1\) (μια διαφορά μεταξύ δύο ομάδων) με τη μέση τιμή της μίας ομάδας. Το \(\beta_1\) μετράει πόσο διαφέρει η τιμή μιας κατοικίας στο Eastside από μια αντίστοιχη κατοικία στο Downtown — δεν είναι ο μέσος όρος των τιμών στο Eastside. Και πάλι, το αρνητικό πρόσημο των αριθμών αποκαλύπτει το σφάλμα: ο μέσος όρος τιμών μιας γειτονιάς δεν μπορεί να είναι αρνητικός.
2.5 % 97.5 %
(Intercept) 87.95358 266.54808
NeighborhoodEastside -115.07739 -17.35826
HomeSizeK 27.15159 108.54819Τώρα ας δούμε το διάστημα από 27 έως 109 στη γραμμή HomeSizeK των αποτελεσματων της confint(). Τι σημαίνουν αυτοί οι αριθμοί;
ΣημείωσηΑπάντηση
Έχουμε 95% βεβαιότητα ότι η πραγματική τιμή του \(\beta_2\) — δηλαδή η αύξηση στην τιμή της κατοικίας στη ΔΠΔ ανά επιπλέον 1.000 τετραγωνικά πόδια μεγέθους — βρίσκεται μεταξύ 27 και 109 χιλιάδων δολαρίων.
Έχουμε προηγουμένως ορίσει το πολυμεταβλητό μοντέλο μας ως \(Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \epsilon_i\). Τα διαστήματα εμπιστοσύνης μάς λένε ένα εύρος πιθανών τιμών για τα \(\beta_0\), \(\beta_1\) και \(\beta_2\).
Ας κάνουμε μια σύνδεση με τον έλεγχο υποθέσεων. Παρατηρήστε ότι τα διαστήματα εμπιστοσύνης για το \(\beta_1\) (−115 έως −17) και για το \(\beta_2\) (27 έως 109) δεν περιλαμβάνουν το 0. Τι σημαίνει αυτό; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Β.
Όταν ένα διάστημα εμπιστοσύνης δεν περιλαμβάνει το 0, σημαίνει ότι μπορούμε να απορρίψουμε την περίπτωση η αντίστοιχη παράμετρος να είναι μηδέν στη ΔΠΔ (Α) — δηλαδή ότι η μεταβλητή πραγματικά εξηγεί κάποια διακύμανση στην εξαρτημένη μεταβλητή (Β). Η απάντηση Γ είναι λάθος: τα διαστήματα εμπιστοσύνης δεν μας λένε ότι μία συγκεκριμένη τιμή είναι σωστή, μας δίνουν ένα εύρος εύλογων τιμών. Η Δ συγχέει την παράμετρο με τον μέσο όρο της ΔΠΔ.
Επειδή αυτά τα διαστήματα εμπιστοσύνης δεν περιλαμβάνουν το 0, είμαστε 95% βέβαιοι ότι υπάρχει κάποια επίδραση της Neighborhood και της HomeSizeK στην PriceK στη ΔΠΔ. Το γεγονός ότι το 0 δεν περιλαμβάνεται στα διαστήματα μάς λέει ότι υπάρχει κάποια συνεισφορά των αντίστοιχων μεταβλητών, και τα ίδια τα διαστήματα εμπιστοσύνης υποδηλώνουν ένα εύρος για το πόσο μεγάλη μπορεί να είναι αυτή η συνεισφορά.