12 Κεφάλαιο: Σύγκριση Μοντέλων
Οι στατιστικοί, όπως οι καλλιτέχνες, έχουν την κακή συνήθεια να ερωτεύονται τα μοντέλα τους.
— George Box
12.1 Πέρα από τη δειγματοληπτική κατανομή του \(b_1\)
Στο προηγούμενο κεφάλαιο είδαμε πώς να χρησιμοποιούμε τη δειγματοληπτική κατανομή του \(b_1\) για να αξιολογήσουμε το κενό μοντέλο. Χρησιμοποιώντας τη συνάρτηση shuffle(), κατασκευάσαμε μια δειγματοληπτική κατανομή για έναν κόσμο στον οποίο το κενό μοντέλο ισχύει στη ΔΠΔ, δηλαδή \(\beta_1 = 0\). Χρησιμοποιήσαμε την κατανομή αυτή για να υπολογίσουμε την τιμή \(p\): την πιθανότητα να έχει προκύψει στην τύχη η τιμή \(b_1\) του δείγματός μας, ή μια ακόμα πιο ακραία τιμή, αν υποθέσουμε ότι ισχύει το κενό μοντέλο. Με βάση την τιμής \(p\) και το επίπεδο σημαντικότητας που είχαμε ορίσει (δηλ. \(\alpha = 0.05\)), αποφασίσαμε αν θα απορρίψουμε ή όχι το κενό μοντέλο της ΔΠΔ.
Όπως ίσως υποψιάζεστε, η δειγματοληπτική κατανομή του \(b_1\) είναι μόνο μία από τις πολλές δειγματοληπτικές κατανομές που θα μπορούσαμε να κατασκευάσουμε. Χρησιμοποιώντας την ίδια προσέγγιση που αναπτύξαμε με το \(b_1\), θα μπορούσαμε να κατασκευάσουμε μια δειγματοληπτική κατανομή για το \(b_0\), τη διάμεσο, την τυπική απόκλιση και πολλά άλλα στατιστικά. Οποιοδήποτε στατιστικό μέτρο μπορούμε να υπολογίσουμε από ένα δείγμα θα μεταβάλλεται με κάθε νέο δείγμα — γι’ αυτό μπορούμε να θεωρήσουμε οποιοδήποτε στατιστικό ως προερχόμενο από μια δειγματοληπτική κατανομή.
Σε αυτό το κεφάλαιο θα επεκτείνουμε την κατανόησή μας για την τυχαιοποίηση πέρα από τη δειγματοληπτική κατανομή του \(b_1\). Θα εστιάσουμε στις δειγματοληπτικές κατανομές του δείκτη PRE και του πηλίκου F. Η δειγματοληπτική κατανομή του πηλίκου F, ειδικότερα, χρησιμοποιείται ευρέως για τη σύγκριση μοντέλων και είναι πιο γενικεύσιμη σε πολλές περιπτώσεις σε σχέση με τη δειγματοληπτική κατανομή του \(b_1\).
Ανασκόπηση των Δεικτών PRE και F
Τόσο το PRE όσο και το F είναι δείκτες σύγκρισης δύο μοντέλων: ενός που περιλαμβάνει μια ανεξάρτητη μεταβλητή (ένα πιο σύνθετο μοντέλο) με ένα που δεν την περιλαμβάνει (το κενό μοντέλο). Ας χρησιμοποιήσουμε και πάλι ως παράδειγμα το πείραμα με τα φιλοδωρήματα για να θυμηθούμε τι είναι το PRE και το F και τι σημαίνουν. Οι ερευνητές ήθελαν να διαπιστώσουν την επίδραση του χαμογελαστού προσώπου στα φιλοδωρήματα: Θα δίνουν υψηλότερα φιλοδωρήματα τα τραπέζια που τυχαία είχαν λάβει ένα χαμογελαστό πρόσωπο επάνω στο λογαριασμό τους σε σχέση με αυτά που δεν είχαν;
Μπορούμε να διατυπώσουμε εκ νέου αυτό το ερώτημα ως σύγκριση δύο μοντέλων: το κενό μοντέλο, στο οποίο ο γενικός μέσος όρος χρησιμοποιείται για την πρόβλεψη του ποσοστού φιλοδωρήματος· και το μοντέλο δύο ομάδων, στο οποίο για την πρόβλεψη του ποσοτού φιλοδωρήματος χρησιμοποιούνται οι μέσοι όροι των δύο ομάδων (με και χωρίς χαμογελαστό πρόσωπο).
Αυτά τα δύο μοντέλα μπορούν να αναπαρασταθούν σε σημειογραφία Γενικού Γραμμικού Μοντέλου ως εξής:
\[\text{Tips}_i = \beta_0 + \beta_1 X_i + \epsilon_i \quad \text{(το μοντέλο δύο ομάδων)}\]
\[\text{Tips}_i = \beta_0 + \epsilon_i \quad \text{(το κενό μοντέλο)}\]
Σημειώστε ότι το μοντέλο δύο ομάδων, στην περίπτωση αυτή, θα αναφέρεται ως «σύνθετο μοντέλο» και το κενό μοντέλο ως «απλό μοντέλο». Οι όροι σύνθετο και απλό είναι σχετικοί. Όταν συγκρίνουμε δύο μοντέλα, το ένα είναι γενικά πιο σύνθετο από το άλλο· το απλό μοντέλο όμως δεν θα είναι πάντα αναγκαστικά το κενό μοντέλο (αν και στην προκειμένη περίπτωση είναι).
Το PRE, ή Αναλογική Μείωση του Σφάλματος, είναι η αναλογία της συνολικής διακύμανσης της εξαρτημένης μεταβλητής που εξηγείται από τη χρήση του πιο σύνθετου μοντέλου έναντι του απλού. Με άλλα λόγια, το PRE είναι η αναλογία του Συνολικού Αθροίσματος Τετραγώνων που μειώνεται χάρη στο σύνθετο μοντέλο σε σχέση με το κενό. (Αυτό είναι απλώς μια ανακεφαλαίωση όσων μάθατε σε προηγούμενα κεφάλαια.)
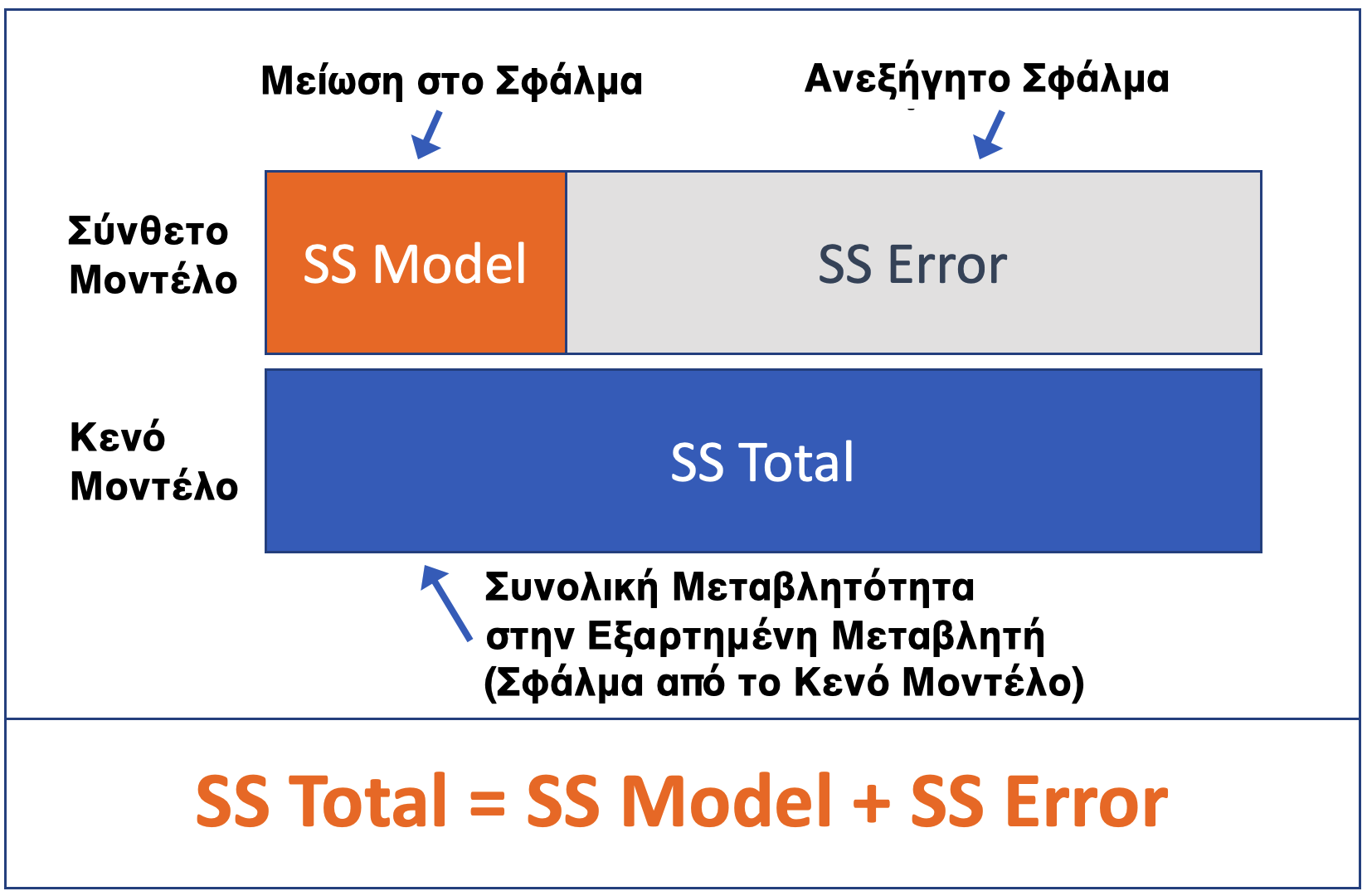 Το F είναι το πηλίκο δύο διακυμάνσεων (ή Μέσων Τετραγώνων): το MS Model διαιρεμένο με το MS Error. Το F σχετίζεται στενά με το PRE, αλλά λαμβάνει υπόψη τον αριθμό των βαθμών ελευθερίας που χρησιμοποιήθηκαν για την προσαρμογή του σύνθετου μοντέλου. Τόσο το PRE όσο και το F αποτελούν τρόπους ποσοτικοποίησης της έντασης της σχέσης μεταξύ της ανεξάρτητης και της εξαρτημένης μεταβλητής. Μπορείτε να σκεφτείτε το F ως μέτρο της έντασης μιας σχέσης (όπως το PRE) ανά παράμετρο που περιλαμβάνεται στο μοντέλο.
Το F είναι το πηλίκο δύο διακυμάνσεων (ή Μέσων Τετραγώνων): το MS Model διαιρεμένο με το MS Error. Το F σχετίζεται στενά με το PRE, αλλά λαμβάνει υπόψη τον αριθμό των βαθμών ελευθερίας που χρησιμοποιήθηκαν για την προσαρμογή του σύνθετου μοντέλου. Τόσο το PRE όσο και το F αποτελούν τρόπους ποσοτικοποίησης της έντασης της σχέσης μεταξύ της ανεξάρτητης και της εξαρτημένης μεταβλητής. Μπορείτε να σκεφτείτε το F ως μέτρο της έντασης μιας σχέσης (όπως το PRE) ανά παράμετρο που περιλαμβάνεται στο μοντέλο.
Αν και γενικά τα πιο σύνθετα μοντέλα εξηγούν περισσότερο σφάλμα (δηλ. έχουν μεγαλύτερο PRE), το F εξισορροπεί την ερμηνεία μεγαλύτερου μέρους της διακύμανσης με την αποφυγή σπατάλης βαθμών ελευθερίας. Έτσι, το F μας δίνει έναν λογικό τρόπο σύγκρισης μοντέλων που χρησιμοποιούν πολλές παραμέτρους (π.χ. \(\beta_0, \beta_1, \beta_2, \ldots\)) με το κενό μοντέλο που χρησιμοποιεί μόνο 1.
Μπορούμε να λάβουμε τόσο το PRE όσο και το F από τον πίνακα ANOVA που παράγεται από τη συνάρτηση supernova(). Χρησιμοποιήστε το παρακάτω πλαίσιο κώδικα για να προσαρμόσετε το Condition_model στα δεδομένα του πειράματος των φιλοδωρημάτων και στη συνέχεια να δημιουργήσετε τον πίνακα ANOVA.
Ο πίνακας ANOVA μας δείχνει ότι το PRE για το Condition_model είναι 0.07. Τι σημαίνει αυτό;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Το 0.07 του αθροίσματος τετραγώνων του κενού μοντέλου εξηγείται από τη μεταβλητή Condition.
Το PRE μετρά την αναλογική μείωση του σφάλματος: πόσο από το SS Total (δηλ. το σφάλμα του κενού μοντέλου) εξαλείφεται όταν προσθέσουμε την ανεξάρτητη μεταβλητή. Δεν είναι πιθανότητα (Α), ούτε αναφέρεται στο SS του σύνθετου μοντέλου (Δ).
Ποιους δύο αριθμούς θα διαιρούσατε για να υπολογίσετε το PRE; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Δ — και οι δύο εκφράσεις είναι ισοδύναμες, αφού SS Model = SS Total − SS Error.
\[\text{PRE} = \frac{\text{SS Model}}{\text{SS Total}} = \frac{\text{SS Total} - \text{SS Error}}{\text{SS Total}}\]
Με ποιον τρόπο το F μοιάζει με το PRE; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Β και Δ.
Το F και το PRE μοιάζουν ως προς τα εξής: και τα δύο ποσοτικοποιούν πόσο καλύτερα το σύνθετο μοντέλο εξηγεί τη διακύμανση σε σχέση με το κενό (Α και Β), και και τα δύο είναι στατιστικά δείγματος που θα μεταβάλλονταν από δείγμα σε δείγμα, άρα έχουν κατανομή δειγματοληψίας (Δ).
Το Γ είναι λάθος: το PRE είναι αδιάστατο (κυμαίνεται από 0 έως 1), ενώ το F δεν έχει άνω όριο και δεν εκφράζεται στις ίδιες μονάδες.
Από τον πίνακα ANOVA βλέπουμε ότι η προσθήκη της μεταβλητής Condition στο μοντέλο οδηγεί σε PRE = 0.07. Αυτό σημαίνει ότι το 0.07 του σφάλματος του κενού μοντέλου μειώνεται — δηλαδή εξηγείται — από το σύνθετο μοντέλο.
Το ότι το PRE είναι μεγαλύτερο από 0 δεν αποτελεί έκπληξη, ωστόσο. Το PRE θα ήταν ίσο με 0 μόνο αν δεν υπήρχε καμία διαφορά στους μέσους όρους μεταξύ των δύο ομάδων στο δείγμα (δηλαδή αν \(\bar{Y}_{\text{smiley}} = \bar{Y}_{\text{control}}\)). Σε εκείνη την περίπτωση, το να γνωρίζουμε σε ποια ομάδα ανήκε ένα τραπέζι (Χαμογελαστό Πρόσωπο ή Ελέγχου) δεν θα πρόσθετε καμία προβλεπτική αξία, και άρα θα οδηγούσε σε μηδενική μείωση του σφάλματος.
Όμως ακόμα και αν δεν υπήρχε καμία επίδραση του χαμογελαστού προσώπου στη ΔΠΔ, σπάνια θα λαμβάναμε ένα δείγμα χωρίς καμία απολύτως διαφορά μέσων όρων μεταξύ των ομάδων. Λόγω της τυχαίας δειγματοληπτικής διακύμανσης, ακόμα και όταν δύο ομάδες προέρχονται από την ίδια ΔΠΔ και τον ίδιο πληθυσμό, θα ήταν σπάνιο να λάβουμε δύο πανομοιότυπους μέσους όρους (διαφορά ίση με 0).
Αν η τιμή \(b_1\) του δείγματος μας \(= 0\), το PRE:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Το PRE θα ήταν επίσης 0.
Αν \(b_1 = 0\), το σύνθετο μοντέλο δεν προσφέρει καμία βελτίωση έναντι του κενού μοντέλου — οι προβλέψεις του είναι πανομοιότυπες. Άρα το SS Model = 0, και επομένως:
\[\text{PRE} = \frac{\text{SS Model}}{\text{SS Total}} = \frac{0}{\text{SS Total}} = 0\]
12.2 Η Δειγματοληπτική Κατανομή του PRE
Όπως η εύρεση μιας διαφοράς μεταξύ των δύο μέσων όρων (π.χ. 6.05) δεν αποκλείει από μόνη της το ενδεχόμενο η πραγματική διαφορά στη ΔΠΔ να είναι 0, το ίδιο ισχύει και για το PRE. Το μοντέλο δύο ομάδων για τη μεταβλητή Tip μειώνει το σφάλμα κατά 0.07 στα δεδομένα. Αλλά αυτό δεν αποκλείει το ενδεχόμενο το πραγματικό PRE στη ΔΠΔ να είναι 0.
Το PRE που βασίζεται στα δεδομένα του δείγματος μας λέει:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το PRE υπολογίζεται από τα δεδομένα του δείγματος — συγκρίνει το σφάλμα του σύνθετου μοντέλου (\(b_0 + b_1 X_i\)) με το σφάλμα του κενού μοντέλου (\(b_0\)) στο δείγμα. Δεν μας λέει τίποτα άμεσα για τη ΔΠΔ (Α), ούτε συγκρίνει μοντέλα δείγματος με μοντέλα ΔΠΔ (Γ).
Αν το πραγματικό PRE στη ΔΠΔ είναι 0:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Το PRE δεν μπορεί ποτέ να είναι αρνητικό (άρα το Α και το Β είναι λάθος). Αν το πραγματικό PRE στη ΔΠΔ είναι 0, τα δειγματικά PRE θα συγκεντρώνονται κοντά στο 0 λόγω τυχαίας δειγματοληπτικής διακύμανσης — δεν θα ήταν κοντά στο 1 (Δ).
Αν δεν υπάρχει διαφορά μεταξύ των ομάδων στη ΔΠΔ, τότε κανένα μέρος από το σφάλμα του κενού μοντέλου δεν θα μειωνόταν από το μοντέλο δύο ομάδων που περιλαμβάνει τη μεταβλητή Condition. Δηλαδή, αν \(\beta_1 = 0\), τότε και η πραγματική τιμή του PRE στη ΔΠΔ θα ήταν επίσης 0. Το ένα απορρέει από το άλλο.
Ακόμα και αν το πραγματικό PRE στη ΔΠΔ είναι 0, το PRE που υπολογίζεται από την προσαρμογή ενός μοντέλου σε ένα δείγμα δεδομένων δεν θα είναι απαραίτητα 0. Θα μεταβάλλεται λόγω τυχαίας δειγματοληπτικής διακύμανσης. Όπως και πριν, το ερώτημα για το πόσο θα μπορούσε να μεταβληθεί είναι κάτι που μπορούμε να απαντήσουμε κατασκευάζοντας μια κατανομή δειγματοληψίας του PRE βάσει του κενού μοντέλου.
Αν το PRE του δείγματος πέσει στην απίθανη περιοχή, πιθανότατα θα αποφασίσουμε να απορρίψουμε το κενό μοντέλο και να υιοθετήσουμε το σύνθετο. Αν όμως το PRE του δείγματος πέσει στην περιοχή του .95 που δεν είναι απίθανη, μπορεί να αποφασίσουμε να μην απορρίψουμε το κενό μοντέλο, καθώς τα δεδομένα που συλλέξαμε θα κρίνονταν συμβατά με μια ΔΠΔ στην οποία το PRE είναι 0.
Είναι σημαντικό να σημειωθεί ότι το ερώτημα που θέτουμε χρησιμοποιώντας την κατανομή δειγματοληψίας του PRE είναι το ίδιο με αυτό που θέταμε χρησιμοποιώντας την κατανομή δειγματοληψίας του \(b_1\): και στις δύο περιπτώσεις θέλουμε να γνωρίζουμε πόσο πιθανό είναι το στατιστικό του δείγματος που παρατηρήσαμε να προέκυπτε τυχαία, υποθέτοντας ότι το κενό μοντέλο είναι αληθές.
Ποιες από τις παρακάτω είναι τρόποι να πούμε “πιστεύουμε ότι δεν υπάρχει επίδραση του χαμογελαστού προσώπου στη ΔΠΔ”; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Β, Γ και ΣΤ — όλες εκφράζουν την ίδια ιδέα με διαφορετικούς τρόπους.
Το να πιστεύουμε ότι δεν υπάρχει επίδραση σημαίνει ότι το κενό μοντέλο ισχύει στη ΔΠΔ (Α), δηλαδή \(\beta_1 = 0\) (Β), άρα και το πραγματικό PRE = 0 (Γ), και επομένως δεν απορρίπτουμε το κενό μοντέλο (ΣΤ). Το Δ δεν έχει νόημα αφού PRE και \(\beta_1\) δεν είναι το ίδιο πράγμα, και το Ε είναι το αντίθετο από αυτό που θέλουμε να πούμε.
Το να λέμε ότι το πραγματικό PRE = 0 είναι απλώς ένας ακόμα τρόπος να αναφερόμαστε στο κενό μοντέλο της ΔΠΔ. Είναι το ίδιο με το να λέμε ότι δεν υπάρχει επίδραση του χαμογελαστού προσώπου, ή ότι \(\beta_1 = 0\). Η χρήση της δειγματοληπτικής κατανομής του PRE θα πρέπει, επομένως, να οδηγεί σε παρόμοια αποτελέσματα με τη χρήση της δειγματοληπτικής κατανομής δειγματοληψίας του \(b_1\). Ας κατασκευάσουμε μια δειγματοληπτική κατανομή και ας διαπιστώσουμε αν συμβαίνει αυτό!
Κατασκευή της Δειγματοληπτικής Κατανομής του PRE
Ας φέρουμε πίσω μια εικόνα από το προηγούμενο κεφάλαιο για να θυμηθούμε πώς χρησιμοποιήσαμε τη shuffle() για να δημιουργήσουμε μια δειγματοληπτική κατανομή του \(b_1\) υποθέτοντας \(\beta_1 = 0\). Δείχνοντάς μας την κατανομή των πιθανών τιμών \(b_1\) που θα μπορούσε να έχει παράγει το κενό μοντέλο της ΔΠΔ, η κατανομή αυτή ήταν ένα πλαίσιο μέσα στο οποίο μπορούσαμε να ερμηνεύσουμε την παρατηρηθείσα διαφορά μέσων όρων μεταξύ των συνθηκών με και χωρίς χαμογελαστό πρόσωπο (6.05).
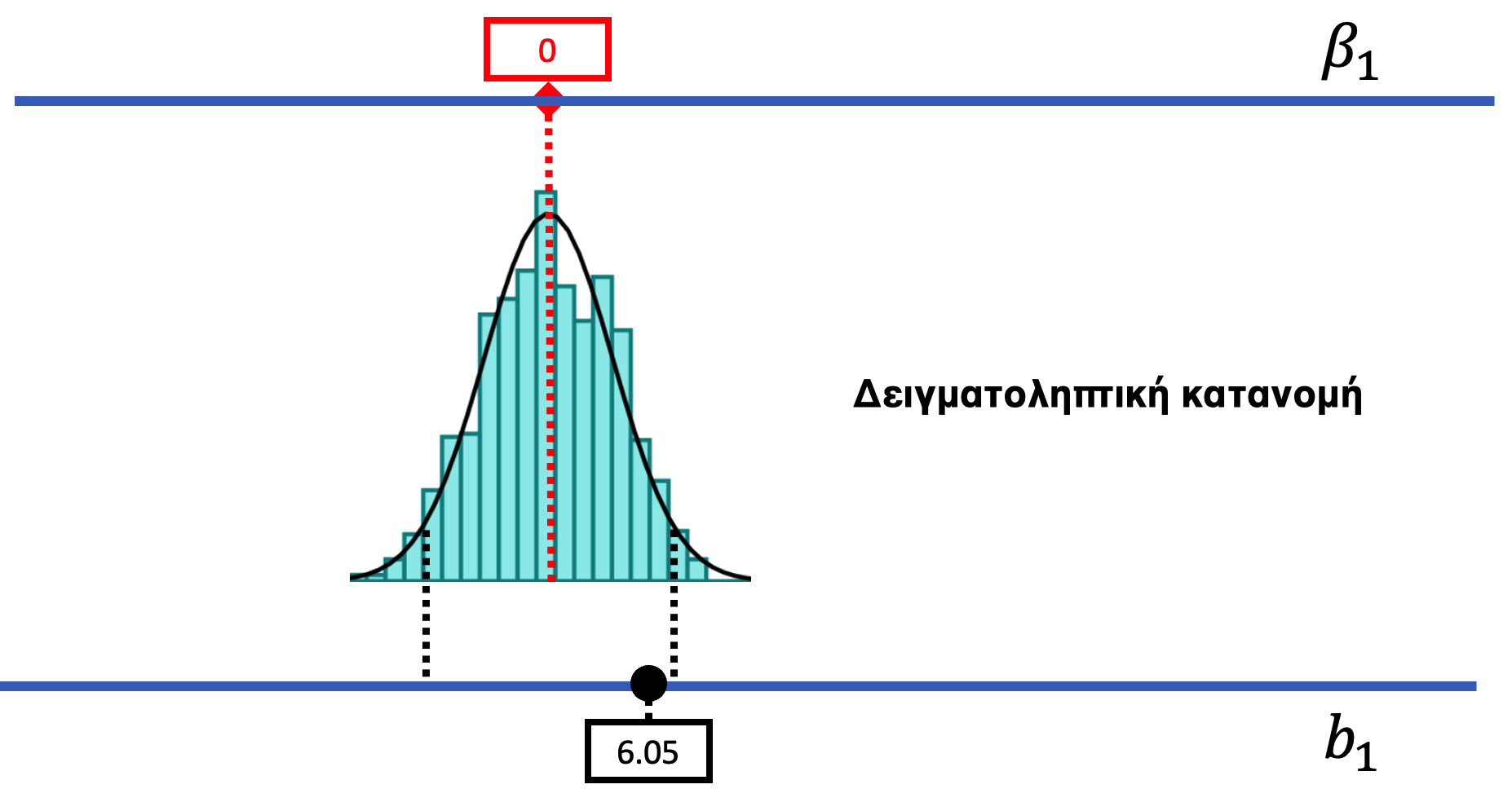
Μπορούμε να χρησιμοποιήσουμε την ίδια προσέγγιση για να δημιουργήσουμε την κατανομή δειγματοληψίας του PRE. Θα ξεκινήσουμε χρησιμοποιώντας τη shuffle() για να τυχαιοποιήσουμε τη σχέση μεταξύ Condition και Tip, και στη συνέχεια, αντί να υπολογίσουμε το \(b_1\), θα υπολογίσουμε το PRE για το ανακατεμένο δείγμα. Χρησιμοποιώντας τη shuffle() προσομοιώνουμε έναν κόσμο στον οποίο το κενό μοντέλο είναι αληθές και όπου κάθε τραπέζι θα έδινε το ίδιο φιλοδώρημα ανεξάρτητα από τη συνθήκη στην οποία είχε ανατεθεί.
Η παρακάτω γραμμή κώδικα R θα (1) ανακατέψει τις τιμές του Tip, (2) δημιουργήσει ένα μοντέλο του ανακατεμένου Tip χρησιμοποιώντας τη Condition ως ανεξάρτητη μεταβλητή, και στη συνέχεια (3) υπολογίσει το PRE του μοντέλου. Κάνει όλα αυτά για ένα μόνο ανακατεμένο (ή τυχαιοποιημένο) σύνολο δεδομένων.
Τροποποιήστε τον κώδικα στο παρακάτω πλαίσιο για να δημιουργήσετε 10 τιμές PRE μετά από τυχαίο ανακάτεμα.
pre
1 0.1122759121
2 0.0014887642
3 0.0062726047
4 0.0284102391
5 0.0056457566
6 0.0006969561
7 0.0545399059
8 0.0404193284
9 0.0356684799
10 0.0034682844Μπορούμε να διαπιστώσουμε ότι η καθαρά τυχαία ΔΠΔ, στην οποία δεν υπάρχει επίδραση του χαμογελαστού προσώπου στο ποσοστό φιλοδωρήματος (Tip), παράγει μια ποικιλία τιμών PRE.
Γιατί οι 10 τιμές PRE είναι όλες διαφορετικές μεταξύ τους;
ΣημείωσηΕπεξήγηση
Κάθε κλήση της συνάρτησης shuffle() δημιουργεί ένα διαφορετικό τυχαίο ανακάτεμα των τιμών της Tip. Επομένως, κάθε φορά υπολογίζεται μια διαφορετική τιμή PRE — αυτή είναι ακριβώς η τυχαία δειγματοληπτική μεταβλητότητα.
Γιατί το PRE = 0.07 του πειράματος των φιλοδωρημάτων δεν περιλαμβάνεται στις 10 τιμές PRE;
ΣημείωσηΕπεξήγηση
Τα 10 PRE προέρχονται από τυχαία ανακατεμένα δεδομένα που προσομοιώνουν έναν κόσμο όπου το κενό μοντέλο είναι αληθές (\(\beta_1 = 0\)). Το PRE = 0.07 υπολογίστηκε από τα πραγματικά, μη ανακατεμένα δεδομένα του πειράματος — είναι το στατιστικό του δείγματός μας που θέλουμε να αξιολογήσουμε έναντι της δειγματοληπτικής κατανομής, όχι μέρος αυτής.
Ας επεκτείνουμε τον παραπάνω κώδικα για να δημιουργήσουμε μια δειγματοληπτική κατανομή 1000 τιμών PRE, να τις αποθηκεύσουμε σε ένα νέο πλαίσιο δεδομένων που θα ονομάσουμε sdoPRE (από το sampling distribution of PRE), και στη συνέχεια να εμφανίσουμε τις πρώτες έξι γραμμές του πλαισίου δεδομένων.
pre
1 0.002577500
2 0.013398877
3 0.043751521
4 0.021976798
5 0.003006396
6 0.014355646Εξέταση της Δειγματοληπτικής Κατανομής του PRE
Η διαδικασία που χρησιμοποιήσαμε για να δημιουργήσουμε τη δειγματοληπτική κατανομή των τιμών PRE είναι παρόμοια με αυτή που χρησιμοποιήσαμε στο προηγούμενο κεφάλαιο για να δημιουργήσουμε μια δειγματοληπτική κατανομή των τιμών \(b_1\). Και στις δύο περιπτώσεις χρησιμοποιήσαμε τη συνάρτηση shuffle() για να προσομοιώσουμε το κενό μοντέλο της ΔΠΔ.
Μοιάζει η δειγματοληπτική κατανομή των τιμών PRE με την αντίστοιχη κατανομή των τιμών \(b_1\); Ας το διαπιστώσουμε! Χρησιμοποιήστε το παρακάτω πλαίσιο κώδικα για να φτιάξετε ένα ιστόγραμμα της τυχαία παραγόμενης μεταβλητής pre στο πλαίσιο δεδομένων sdoPRE.

Είναι ενδιαφέρον ότι η δειγματοληπτική κατανομή του PRE έχει πολύ διαφορετικό σχήμα από την αντίστοιχη κατανομή του \(b_1\). Στο παρακάτω διάγραμμα παραθέτουμε τις δύο κατανομές δίπλα-δίπλα για σκοπούς σύγκρισης.

Περιγράψτε τις διαφορές μεταξύ αυτών των δύο κατανομών δειγματοληψίας.*
ΣημείωσηΕπεξήγηση
Η δειγματοληπτική κατανομή του \(b_1\) είναι συμμετρική και έχει μορφή καμπάνας με κέντρο στο 0, καθώς και δύο ουρές. Η δειγματοληπτική κατανομή του PRE αντίθετα είναι ασύμμετρη με μία μόνο ουρά προς τα δεξιά, με κέντρο κοντά στο 0 και όλες τις τιμές να είναι μη αρνητικές.
Γιατί πιστεύετε ότι η δειγματοληπτική κατανομή του \(b_1\) έχει δύο ουρές, ενώ η δειγματοληπτική κατανομή του PRE έχει μόνο μία;*
ΣημείωσηΕπεξήγηση
Το \(b_1\) μπορεί να είναι θετικό ή αρνητικό — ένα τυχαίο ανακάτεμα μπορεί να δώσει είτε θετική είτε αρνητική κλίση, άρα η κατανομή εκτείνεται και προς τις δύο κατευθύνσεις. Το PRE όμως είναι πάντα μη αρνητικό (κυμαίνεται από 0 έως 1), επειδή είναι αναλογία τετραγώνων τόσο οι αρνητικές όσο και οι θετικές τιμές \(b_1\) θα αντιστοιχούν σε θετικές τιμές PRE. Γι’ αυτό η κατανομή του PRE έχει μόνο μία ουρά προς τα δεξιά.
Ποιες από τις παρακάτω δηλώσεις είναι αληθείς για τη δειγματοληπτική κατανομή του PRE; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Β.
Η δειγματοληπτική κατανομή του PRE είναι ασύμμετρη με μία ουρά — άρα δεν είναι κανονική (Α) και δεν μπορεί να μοντελοποιηθεί από την κατανομή \(t\) (Β).
Το Γ είναι λάθος: η κατανομή παράγεται κανονικά από το κενό μοντέλο μέσω της shuffle() — απλώς το PRE, ως αναλογία τετραγώνων, έχει από τη φύση του ασύμμετρη κατανομή.
Το Δ είναι επίσης λάθος: μια δειγματοληπτική κατανομή δεν χρειάζεται να είναι κανονική για να είναι έγκυρη.
Η δειγματοληπτική κατανομή του \(b_1\) έχει δύο ουρές επειδή η διαφορά μεταξύ των δύο ομάδων μπορεί να είναι θετική ή αρνητική: το χαμογελαστό πρόσωπο θα μπορούσε να οδηγήσει σε υψηλότερο ποσοστό φιλοδωρήματος, ή θα μπορούσε να οδηγήσει σε μικρότερο. Και τα δύο είναι πιθανά (αν και οι ερευνητές αναμφίβολα ανέμεναν ότι θα οδηγούσε σε υψηλότερο).
Το PRE όμως είναι διαφορετικό: το σύνθετο μοντέλο μπορεί να μην εξηγεί καθόλου σφάλμα από το κενό μοντέλο (0) ή να εξηγεί ολόκληρο το σφάλμα του κενού μοντέλου (1.0). Δεν μπορεί όμως να εξηγεί λιγότερο από 0 σφάλμα. Επειδή το PRE είναι αναλογία, έχει ένα σαφές κάτω όριο στο 0 και ένα σαφές άνω όριο στο 1.
Υποθέτοντας ότι το κενό μοντέλο είναι αληθές, το μόνο μέρος όπου ένα ακραίο PRE μπορεί να βρεθεί είναι στην άνω ουρά της κατανομής — γι’ αυτό υπάρχει μόνο μία ουρά στη δειγματοληπτική κατανομή των τιμών PRE. Μια ακραία θετική επίδραση του χαμογελαστού προσώπου ή μια ακραία αρνητική επίδραση είναι το ίδιο για το PRE: και οι δύο τιμές θα βρίσκονταν στην άνω ουρά της δειγματοληπτικής κατανομής του PRE.
12.3 Δειγματοληπτική Κατανομή του F
Μέχρι τώρα κατασκευάσαμε και εξετάσαμε τη δειγματοληπτική κατανομή του PRE για να εξετάσουμε τη διακύμανση στις τιμές PRE που θα μπορούσε να παράγει το κενό μοντέλο στο πλαίσιο του πειράματος των φιλοδωρημάτων. Μπορούμε να χρησιμοποιήσουμε την ίδια μέθοδο για να κατασκευάσουμε τη δειγματοληπτική κατανομή του F υπό το κενό μοντέλο.
Στην πραγματικότητα, η δειγματοληπτική κατανομή του F είναι ένα από τα πιο συνηθισμένα εργαλεία για τη σύγκριση ενός σύνθετου μοντέλου με το κενό μοντέλο (δηλαδή, για τη διεξαγωγή Ελέγχων Σημαντικότητας της Μηδενικής Υπόθεσης). Είναι τόσο δημοφιλής, μάλιστα, που έχει το δικό του όνομα: στατιστικός έλεγχος F (F-test). Για αυτόν τον λόγο, θα αφιερώσουμε λίγο χρόνο για να εξετάσουμε τη δειγματοληπτική κατανομή του F.
Ανασκόπηση του Πηλίκου F
Ας θυμηθούμε πρώτα πώς υπολογίζεται το πηλίκο F για ένα μοντέλο (το οποίο είναι ένα στατιστικό δείγματος). Εμφανίζεται στον πίνακα της supernova(). Αλλά όπως έχουμε μια συνάρτηση R για τον άμεσο υπολογισμό του PRE ενός μοντέλου, έχουμε επίσης μία για τον υπολογισμό του F: τη συνάρτηση f(). Η παρακάτω γραμμή κώδικα υπολογίζει το πηλίκο F του δείγματος που προκύπτει από την προσαρμογή του μοντέλου της Condition στα δεδομένα του πειράματος των φιλοδωρημάτων.
3.3049725526482Ποιους δύο αριθμούς θα διαιρούσατε για να υπολογίσετε το πηλίκο F;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — MS Model / MS Error.
Το πηλίκο F είναι ο λόγος δύο Μέσων Αθροισμάτων Τετραγώνων (Mean Squares), όχι Αθροισμάτων Τετραγώνων (SS). Κάθε MS υπολογίζεται διαιρώντας το αντίστοιχο SS με τους βαθμούς ελευθερίας του:
\[F = \frac{MS_{\text{Model}}}{MS_{\text{Error}}} = \frac{SS_{\text{Model}} / df_{\text{Model}}}{SS_{\text{Error}} / df_{\text{Error}}}\]
Πώς διαφέρει το F από το PRE; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Γ και Δ.
Το F διαφέρει από το PRE σε τρία βασικά σημεία: χρησιμοποιεί Μέσους Όρους Αθροισμάτων Τετραγώνων αντί για Αθροίσματα Τετραγώνων (Α), δεν έχει άνω όριο όπως το PRE που περιορίζεται μεταξύ του 0 και του 1 (Γ), και λαμβάνει υπόψη τους βαθμούς ελευθερίας διαιρώντας με αυτούς (Δ). Και τα δύο όμως υπολογίζονται από τα δεδομένα του δείγματος, και κανένα δεν μπορεί να είναι αρνητικό.
Το πηλίκο F, όπως και το PRE, είναι ένα στατιστικό δείγματος που μας λέει κάτι για το πόσο καλά το μοντέλο μας προσαρμόζεται στα δεδομένα. Γενικά, όσο υψηλότερο είναι το PRE και όσο υψηλότερο είναι το F, τόσο καλύτερα το μοντέλο μας εξηγεί τη διακύμανση στην εξαρτημένη μεταβλητή. Όμως ενώ το PRE συνεχίζει να αυξάνεται καθώς προστίθενται περισσότερες ανεξάρτητες μεταβλητές στο μοντέλο, το F προσαρμόζεται βάσει του αριθμού των βαθμών ελευθερίας που χρησιμοποιούνται για την επεξήγηση περισσότερης διακύμανσης.
Ως υπενθύμιση, έχουμε μάθει δύο τύπους για τον υπολογισμό του πηλίκου F:
\[F = \frac{MS_{\text{Model}}}{MS_{\text{Error}}} = \frac{PRE/df_{\text{model}}}{(1-PRE)/df_{\text{error}}}\]
Ο πρώτος τύπος (λόγος δύο διακυμάνσεων, ή MS) είναι αυτός που χρησιμοποιείται πιο συχνά για τον υπολογισμό του F. Ο δεύτερος όμως (με το PRE) μας βοηθά να κατανοήσουμε τη σχέση μεταξύ PRE και F.
Ο αριθμητής (\(PRE/df_{\text{model}}\)) είναι το PRE (η αναλογία της διακύμανσης που εξηγείται) ανά βαθμό ελευθερίας που χρησιμοποιείται στο μοντέλο· ο παρονομαστής (\((1-PRE)/df_{\text{error}}\)) είναι η αναλογία διακύμανσης που παραμένει ανεξήγητη ανά εναπομείναντα βαθμό ελευθερίας. Το F = 3.30 μπορεί να ερμηνευθεί, επομένως, ως το πόσες φορές πιο ισχυρή είναι η παράμετρος στο μοντέλο μας ως ανεξάρτητη μεταβλητή σε σχέση με οποιαδήποτε άλλη παράμετρο που θα μπορούσε να είχε προστεθεί στο μοντέλο.
Χρήση της shuffle() για την Κατασκευή Δειγματοληπτικής Κατανομής του F
Έχοντας τη συνάρτηση f(), μπορούμε να χρησιμοποιήσουμε την ίδια προσέγγιση που χρησιμοποιήσαμε για το PRE για να κατασκευάσουμε τη δειγματοληπτική κατανομή του F με την παραδοχή ότι ισχύει το κενό μοντέλο. Θα χρησιμοποιήσουμε τη συνάρτηση shuffle() για να προσομοιώσουμε μια ΔΠΔ στην οποία η μόνη διαφορά μεταξύ των ομάδων οφείλεται στην τυχαιοποίηση, και στη συνέχεια θα χρησιμοποιήσουμε τη συνάρτηση f() για να βρούμε το F για τα ανακατεμένα δεδομένα. Θα επαναλάβουμε αυτή τη διαδικασία πολλές φορές για να δημιουργήσουμε τη δειγματοληπτική κατανομή.
Ο παρακάτω κώδικας τυχαιοποιεί τα δεδομένα του TipExperiment 1.000 φορές και υπολογίζει τις τιμές PRE:
Ποιο μέρος θα αντικαθιστούσατε για να δημιουργήσετε μια δειγματοληπτική κατανομή του F;
ΣημείωσηΕπεξήγηση
Χρησιμοποιήστε το παρακάτω τμήμα κώδικα για να αποθηκεύσετε 1.000 τυχαία παραγόμενες τιμές του πηλίκου F σε ένα πλαίσιο δεδομένων που θα ονομάσετε sdof (ακρωνύμιο για τη δειγματοληπτική κατανομή του F). Έχουμε ήδη προσθέσει μια γραμμή κώδικα που θα εμφανίσει αυτή την κατανομή σε ένα ιστόγραμμα.

Τι παρατηρείτε στις παραπάνω δειγματοληπτικές κατανομές των PRE και F; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Δ.
Και οι δύο κατανομές είναι ασύμμετρες με μία ουρά προς τα δεξιά και επικρατούσα τιμή κοντά στο 0 (Α και Δ). Η κλίμακα του άξονα x είναι διαφορετική — το PRE κυμαίνεται από 0 έως 1, ενώ το F δεν έχει άνω όριο (το Β είναι λάθος). Οι μέσοι όρους τους δεν είναι παρόμοιοι για τον ίδιο λόγο (το Γ είναι λάθος).
Τα σχήματα των δειγματοληπτικών κατανομών του PRE και του F είναι παρόμοια. Κανένα από αυτά τα στατιστικά δείγματος δεν μπορεί να είναι αρνητικό. Το αποτέλεσμα είτε μιας μεγάλης θετικής είτε μιας μεγάλης αρνητικής επίδρασης του χαμογελαστού προσώπου στο ποσοστό φιλοδωρήματος (Tip) θα έδινε και στις δύο περιπτώσεις ακραίες τιμές F στην άνω ουρά της κατανομής.
Και οι δύο αυτές δειγματοληπτικές κατανομές βασίζονται στην υπόθεση ότι το κενό μοντέλο ισχύει στη ΔΠΔ. Έχουμε ήδη αναπτύξει την ιδέα ότι αν δεν υπάρχει επίδραση του χαμογελαστού προσώπου στη ΔΠΔ (δηλαδή, το κενό μοντέλο είναι αληθές), τότε το PRE στη ΔΠΔ θα ήταν ίσο με 0. Αυτό σημαίνει ότι το να γνωρίζουμε σε ποια συνθήκη ανήκει ένα τραπέζι εξηγεί κυριολεκτικά το 0% της διακύμανσης στην Tip, που είναι το ίδιο με το να λέμε \(\beta_1 = 0\).
Αλλά ποια θα ήταν η αναμενόμενη τιμή του F αν το κενό μοντέλο ήταν αληθές; Το F είναι μια πιο δύσκολη έννοια να κατανοηθεί, οπότε δεν θα το αναπτύξουμε πλήρως εδώ. Αλλά αν το κενό μοντέλο ήταν αληθές, δηλαδή αν το PRE ήταν κυριολεκτικά 0, τότε η αναμενόμενη τιμή του F θα ήταν 1. Η διακύμανση που εκτιμάται με βάση τις προβλέψεις του μοντέλου θα ήταν περίπου ίση με τη διακύμανση που εκτιμάται βάσει του σφάλματος εντός των ομάδων.
Για να επιβεβαιώσετε ότι αυτό ισχύει, μπορείτε να χρησιμοποιήσετε το παρακάτω παράθυρο κώδικα για να υπολογίσετε τον μέσο όρο του f για τη δειγματοληπτική κατανομή του F. Επειδή η δειγματοληπτική κατανομή μας, την οποία δημιουργήσαμε χρησιμοποιώντας τη shuffle(), υποθέτει ότι το κενό μοντέλο είναι αληθές, ο μέσος όρος όλων των F που παράγαμε θα πρέπει να είναι περίπου ίσος με 1.
Επειδή η δειγματοληπτική κατανομή του F είναι πιο συνηθισμένη και παρόμοια με τη δειγματοληπτική κατανομή του PRE, θα εστιάσουμε από εδώ και στο εξής στη χρήση της κατανομής του F. Ωστόσο, να γνωρίζετε ότι όλα όσα αναφέρουμε στις επόμενες ενότητες ισχύουν επίσης και για τα PRE.
12.4 Χρήση της Δειγματοληπτικής Κατανομής του F
Αφότου κατασκευάσαμε μια δειγματοληπτική κατανομή του F, ας τη χρησιμοποιήσουμε για να αξιολογήσουμε το κενό μοντέλο της Tip. Η προσέγγισή μας θα είναι παρόμοια με αυτή που χρησιμοποιήσαμε στο προηγούμενο κεφάλαιο βάσει της δειγματοληπτικής κατανομής του \(b_1\). Πρώτα κατασκευάζουμε μια δειγματοληπτική κατανομή του F υποθέτοντας ότι το κενό μοντέλο είναι αληθές (π.χ. με τη shuffle()), και στη συνέχεια εξετάζουμε πόσο πιθανό θα ήταν να παρατηρήσουμε τυχαία την τιμή F του δείγματος, αν το κενό μοντέλο ήταν αληθές.
Επειδή όμως η δειγματοληπτική κατανομή του F έχει σαφώς διαφορετικό σχήμα από τη δειγματοληπτική κατανομή του \(b_1\), θα χρειαστεί να αναθεωρήσουμε τη μέθοδό μας για την εύρεση αυτής της πιθανότητας.
 Με βάση την παραπάνω δειγματοληπτική κατανομή των τιμών F που παράγονται από το κενό μοντέλο (στο οποίο δεν υπάρχει επίδραση του χαμογελαστού προσώπου στα φιλοδωρήματα), ποιες τιμές F θα μας έκαναν να αμφιβάλλουμε ότι το F του δείγματος παράχθηκε από το κενό μοντέλο;
Με βάση την παραπάνω δειγματοληπτική κατανομή των τιμών F που παράγονται από το κενό μοντέλο (στο οποίο δεν υπάρχει επίδραση του χαμογελαστού προσώπου στα φιλοδωρήματα), ποιες τιμές F θα μας έκαναν να αμφιβάλλουμε ότι το F του δείγματος παράχθηκε από το κενό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — Τιμές F στο δεξί άκρο της δειγματοληπτικής κατανομής.
Επειδή το F δεν μπορεί να είναι αρνητικό και μια μεγάλη επίδραση (θετική ή αρνητική) οδηγεί πάντα σε μεγάλη τιμή F, η απίθανη περιοχή βρίσκεται μόνο στην άνω ουρά. Ένα πολύ μικρό F σημαίνει απλώς ότι το μοντέλο δεν εξηγεί σχεδόν τίποτα — κάτι απόλυτα αναμενόμενο αν το κενό μοντέλο είναι αληθές. Σε αντίθεση με τη δειγματοληπτική κατανομή του \(b_1\) που έχει δύο ουρές, εδώ ελέγχουμε μόνο τη μία.
Δείγματα με εξαιρετικά υψηλές τιμές F (π.χ. F ίσο με 8 ή 12) είναι απίθανο να παραχθούν από μια τυχαία ΔΠΔ. Αντίθετα, χαμηλές τιμές F είναι πολύ συνηθισμένες από μια καθαρά τυχαία ΔΠΔ. Μόνο υψηλές τιμές F — αυτές στην άνω ουρά — θα μας έκαναν να αμφιβάλλουμε ότι το κενό μοντέλο παρήγαγε τα δεδομένα μας.
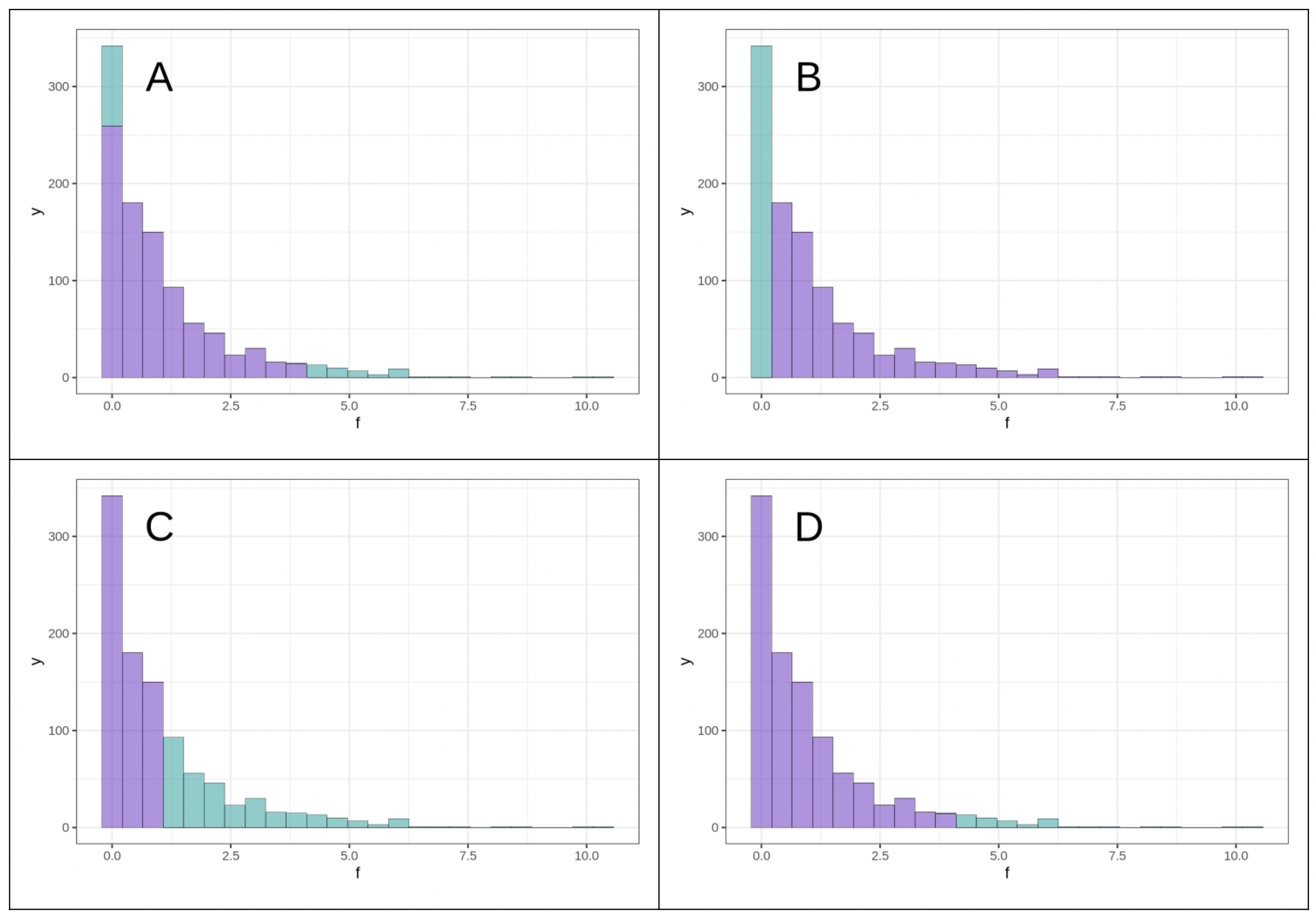
Αν ορίσουμε \(\alpha = 0.05\), αποφασίζοντας να θεωρήσουμε ως απίθανο το πιο ακραίο 5% των τιμών F, ποιο από τα παραπάνω διαγράμματα αναπαριστά αυτές τις απίθανες τιμές F στη δειγματοληπτική κατανομή;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: D.
Επειδή η δειγματοληπτική κατανομή του F έχει μόνο μία ουρά (προς τα δεξιά), η απίθανη περιοχή με \(\alpha = 0.05\) βρίσκεται αποκλειστικά στην άνω ουρά — δηλαδή το πιο ακραίο 5% των υψηλότερων τιμών F. Το διάγραμμα D αναπαριστά σωστά αυτή την περιοχή χρωματισμένη στην άνω ουρά μόνο. Το διάγραμμα Α χρωματίζει και τις δύο ουρές, το Γ χρωματίζει πολύ μεγάλη περιοχή, και το Β χρωματίζει περιοχή στην στις χαμηλές τιμές του F.
Με τη δειγματοληπτική κατανομή του F, χρειάζεται να κοιτάξουμε μόνο μία ουρά της κατανομής. Γνωρίζουμε ότι το πηλίκο F δεν μπορεί ποτέ να είναι μικρότερο από 0. Θέλουμε απλώς να γνωρίζουμε πόσο πιθανό είναι να λάβουμε ένα F τόσο υψηλό όσο αυτό που παρατηρήσαμε.
Μπορούμε να χρησιμοποιήσουμε μια συνάρτηση που ονομάζεται lower() για να χρωματίσουμε το κατώτερο 0.95 (ή 95%) μιας δειγματοληπτικής κατανομής με διαφορετικό χρώμα από την άνω ουρά 0.05, προσθέτοντας αυτό το όρισμα σε ένα ιστόγραμμα: fill = ~lower(f, .95). Δοκιμάστε να εκτελέσετε τον κώδικα στο παρακάτω πλαίσιο κώδικα.
Χρησιμοποιήσαμε προηγουμένως μια παρόμοια συνάρτηση που ονομάζεται middle(), ενώ υπάρχει επίσης μια σχετική συνάρτηση που ονομάζεται upper().
Ερμηνεία του Δειγματικού F από το Πείραμα των Φιλοδωρημάτων
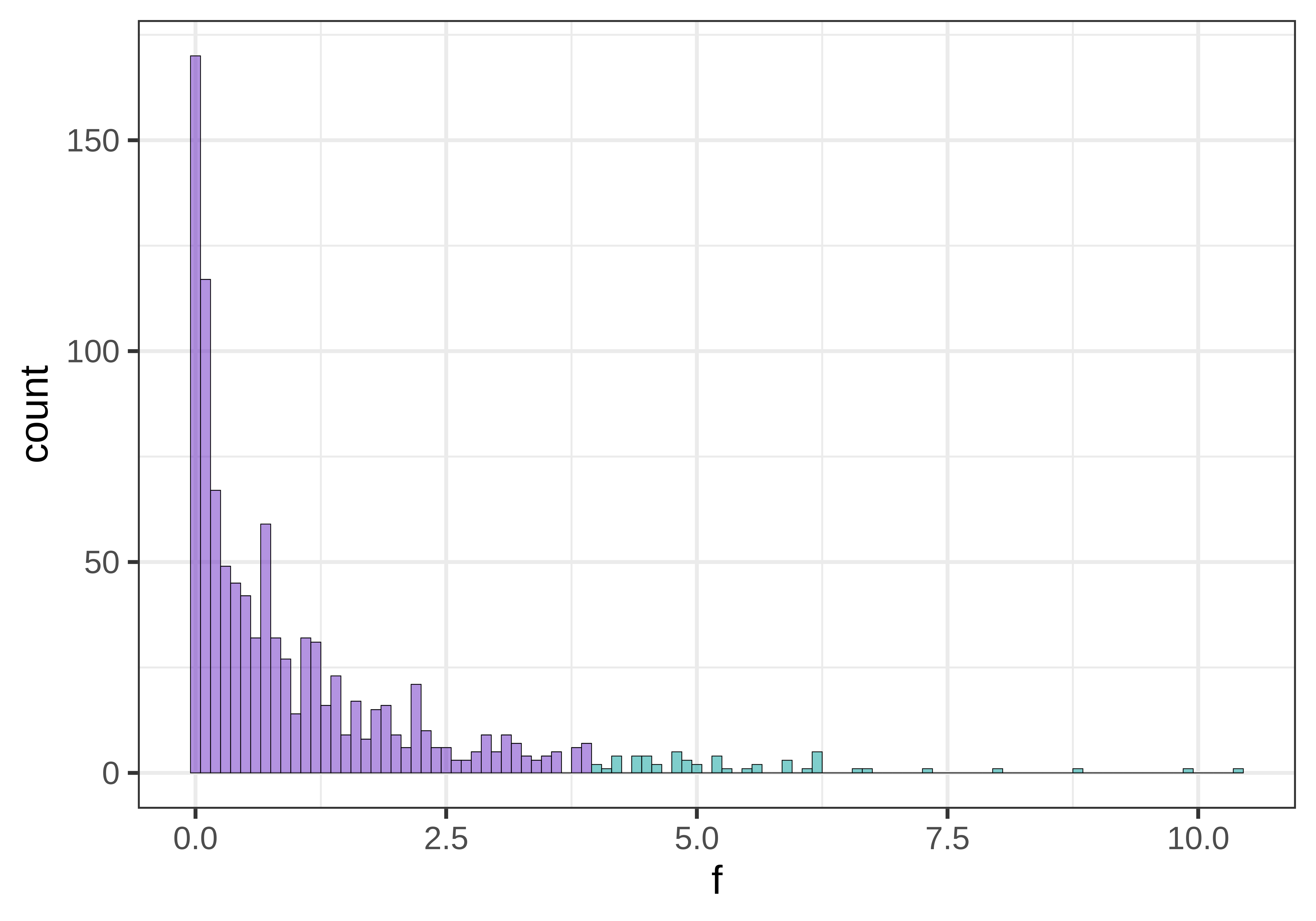
Το παραπάνω διάγραμμα δείχνει τη δειγματοληπτική κατανομή των τιμών F με το πιο ακραίο 5% των τιμών χρωματισμένο με διαφορετικό χρώμα. Για \(\alpha = 0.05\), θα αποκαλούμε αυτές τις τιμές «απίθανες». Στη μελέτη των φιλοδωρημάτων, οι ερευνητές παρατήρησαν τιμή F = 3.30 για το μοντέλο της Condition. Η τιμή αυτή ανήκει στις απίθανες ή στις μη απίθανες τιμές της δειγματοληπτικής κατανομής;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Μη απίθανες.
Η τιμή F = 3.30 δεν βρίσκεται στο ακραίο 5% της άνω ουράς της δειγματοληπτικής κατανομής, άρα δεν θεωρείται απίθανη για \(\alpha = 0.05\).
Φανταστείτε μια αναπαράσταση της τιμής \(p\) (την πιθανότητα να παραχθεί από το κενό μοντέλο μια τιμή F ίση με 3.30 ή μεγαλύτερη). Ποια από τις παρακάτω περιγραφές ταιριάζει καλύτερα με αυτό που θα βλέπατε στο διάγραμμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η τιμή \(p\) είναι η πιθανότητα να παρατηρήσουμε F ≥ 3.30 αν το κενό μοντέλο είναι αληθές — δηλαδή η αναλογία των τυχαία παραγόμενων τιμών F που υπερβαίνουν το F του δείγματός μας. Οπτικά, αυτό αντιστοιχεί στην περιοχή της άνω ουράς του ιστογράμματος που βρίσκεται δεξιά από το 3.30.
Στο παρακάτω διάγραμμα έχουμε προσθέσει μια διακεκομμένη γραμμή για να δείξουμε το επίπεδο σημαντικότητας \(\alpha\) (το σημείο που χωρίζει τις απίθανες τιμές F — δηλαδή το 5% των μεγαλύτερων τιμών F που παράγονται από το κενό μοντέλο, χρωματισμένες με ανοιχτό πράσινο — από αυτές που θεωρούνται μη απίθανες). Έχουμε επίσης προσθέσει μια μαύρη κουκκίδα για να δείξουμε πού βρίσκεται η τιμή F του δείγματος από το πείραμα των φιλοδωρημάτων. Επειδή η τιμή F του δείγματος βρίσκεται στη μη απίθανη περιοχή της δειγματοληπτικής κατανομής, θα αποφασίσουμε να μην απορρίψουμε το κενό μοντέλο με βάση τα αποτελέσματα του πειράματος.

Μπορούμε να χρωματίσουμε το ίδιο διάγραμμα λίγο διαφορετικά για να αναπαραστήσουμε την τιμή \(p\) για την πραγματική τιμή F που βρέθηκε στο πείραμα φιλοδωρημάτων. Στο παρακάτω διάγραμμα, η τιμή \(p\) αναπαρίσταται με μωβ χρώμα: όλες οι τυχαία παραγόμενες τιμές F από το κενό μοντέλο που είναι μεγαλύτερες ή ίσες με το παρατηρούμενο F του δείγματος (3.30). Έχουμε αφήσει τη διακεκομμένη γραμμή για να δείξουμε το επίπεδο σημαντικότητας \(\alpha = 0.05\).

Μπορούμε να δούμε από το διάγραμμα ότι η τιμή \(p\) (μωβ περιοχή) θα είναι μεγαλύτερη από 0.05 (που αναπαρίσταται από τη διακεκομμένη γραμμή), κάτι που είναι ένας άλλος τρόπος να φανεί ότι το παρατηρούμενο F δεν βρίσκεται στην απίθανη περιοχή της δειγματοληπτικής κατανομής.
12.5 Υπολογισμός της Τιμής \(p\) από τη Δειγματοληπτική Κατανομή του F
Για να υπολογίσουμε την ακριβή τιμή \(p\), μπορούμε να χρησιμοποιήσουμε τη συνάρτηση tally(), χρησιμοποιώντας την αναλογία των 1.000 προσομοιωμένων τιμών F που είναι τόσο ακραίες ή πιο ακραίες από το παρατηρηθέν F, ως εκτίμηση της πιθανότητας να παραχθεί ένα τέτοιο F αν το κενό μοντέλο είναι αληθές.
TRUE FALSE
0.081 0.919Η προκύπτουσα τιμή \(p\) (περίπου 0.08) είναι μεγαλύτερη από το επίπεδο σημαντικότητας \(\alpha = 0.05\), που σημαίνει ότι η τιμή F του δείγματος δεν βρίσκεται στην περιοχή που έχουμε ορίσει ως απίθανη. (Σημειώστε ότι η εκτίμησή σας για την τιμή \(p\) μπορεί να διαφέρει ελαφρώς από τη δική μας, καθώς η κάθε μία βασίζεται σε διαφορετικό σύνολο 1.000 τυχαία παραγόμενων τιμών F.)
Βάσει αυτής της τιμής \(p\), τι θα συμπεραίνατε για το κενό μοντέλο; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Ε.
Η τιμή \(p = 0.08\) σημαίνει ότι, αν το κενό μοντέλο ήταν αληθές (δηλ. δεν υπάρχει επίδραση), θα παρατηρούσαμε F ≥ 3.30 περίπου το 8% των φορών τυχαία. Επειδή 0.08 > 0.05, δεν απορρίπτουμε το κενό μοντέλο (Ε). Το Α και το Γ είναι λάθος γιατί η δειγματοληπτική κατανομή κατασκευάζεται υπό την υπόθεση ότι δεν υπάρχει καμία επίδραση — θετική ή αρνητική.
Βάσει αυτής της τιμής \(p\), πιθανότατα δεν θα απορρίπταμε το κενό μοντέλο της Tip. Είναι πιθανό ακόμα και αν το κενό μοντέλο είναι αληθές (δηλαδή \(\beta_1 = 0\) και \(PRE = 0\)), να παρατηρούσαμε τυχαία μια τιμή F τόσο υψηλή όσο αυτή που πράγματι παρατηρήσαμε (3.30).
Τι αντιπροσωπεύει γενικά η τιμή \(p\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η τιμή \(p\) είναι η πιθανότητα να παρατηρήσουμε ένα στατιστικό τόσο ακραίο ή πιο ακραίο από αυτό του δείγματός μας, υποθέτοντας ότι το κενό μοντέλο είναι αληθές. Το Β περιγράφει το PRE και το Γ τον λόγο F.
Αν το F του δείγματός μας ήταν υψηλότερο, τι θα περιμένατε για την τιμή \(p\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Όσο υψηλότερο είναι το F του δείγματος, τόσο λιγότερες τυχαία παραγόμενες τιμές F το υπερβαίνουν — άρα η τιμή \(p\) μειώνεται.
Αν η τιμή \(p\) είναι πολύ χαμηλή (π.χ. .001), τι σημαίνει αυτό; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Γ και Δ.
Μια πολύ χαμηλή τιμή \(p\) σημαίνει ότι το παρατηρηθέν στατιστικό είναι σπάνιο υπό το κενό μοντέλο — η τυχαιοποίηση σπάνια παράγει τιμές τόσο ακραίες (Γ), άρα το κενό μοντέλο της ΔΠΔ θα δυσκολευόταν να παράγει τέτοια αποτελέσματα (Δ). Δεν αφορά την πιθανότητα του σύνθετου μοντέλου (Α και Ε), ούτε έχει σχέση με τη χρήση της shuffle() (Β).
Αν μια τιμή \(p\) είναι πολύ υψηλή, τι σημαίνει αυτό;
Έχουμε τώρα χρησιμοποιήσει τη shuffle() για να κατασκευάσουμε δειγματοληπτικές κατανομές για τρία στατιστικά δείγματος: \(b_1\), PRE και F. Χρησιμοποιώντας τη shuffle(), προσομοιώναμε μια ΔΠΔ στην οποία το κενό μοντέλο είναι αληθές, δηλαδή ότι το αν σχεδιαστεί ή όχι χαμογελαστό πρόσωπο στον λογαριασμό δεν επηρεάζει το ποσό που δίνει φιλοδώρημα ένα τραπέζι. Η διακύμανση που βλέπουμε στις δειγματοληπτικές κατανομές θεωρείται ότι οφείλεται στην τυχαία δειγματοληπτική διακύμανση.
Αν και και οι δύο δειγματοληπτικές κατανομές υποθέτουν ότι το κενό μοντέλο είναι αληθές (δηλ. \(\beta_1 = 0\)), τα σχήματά τους είναι αρκετά διαφορετικά (βλ. παρακάτω σχήμα). Η δειγματοληπτική κατανομή του \(b_1\) είναι περίπου κανονική ως προς το σχήμα, ενώ αυτή του F έχει ένα έντονα ασύμμετρο σχήμα, με μια μακριά ουρά προς τα δεξιά. Η περιοχή απόρριψης που ορίζεται από το α χωρίζεται μεταξύ δύο ουρών για τη δειγματοληπτική κατανομή του \(b_1\), αλλά βρίσκεται εξ ολοκλήρου στην άνω ουρά της δειγματοληπτικής κατανομής του F.
![]() Αφού κατασκευάσαμε τη δειγματοληπτική κατανομή, τη χρησιμοποιήσαμε για να εντάξουμε το παρατηρηθέν στατιστικό δείγματος σε ένα πλαίσιο. Συγκεκριμένα, μας επέτρεψε να ρωτήσουμε πόσο πιθανό θα ήταν να επιλέξουμε ένα δείγμα με στατιστικό — είτε \(b_1\), PRE ή F — τόσο ακραίο ή πιο ακραίο από το στατιστικό που παρατηρήθηκε στο δείγμα. Η απάντηση σε αυτό το ερώτημα είναι η τιμή \(p\).
Αφού κατασκευάσαμε τη δειγματοληπτική κατανομή, τη χρησιμοποιήσαμε για να εντάξουμε το παρατηρηθέν στατιστικό δείγματος σε ένα πλαίσιο. Συγκεκριμένα, μας επέτρεψε να ρωτήσουμε πόσο πιθανό θα ήταν να επιλέξουμε ένα δείγμα με στατιστικό — είτε \(b_1\), PRE ή F — τόσο ακραίο ή πιο ακραίο από το στατιστικό που παρατηρήθηκε στο δείγμα. Η απάντηση σε αυτό το ερώτημα είναι η τιμή \(p\).
Η τιμή \(p\) είναι η πιθανότητα να λάβουμε μια εκτίμηση παραμέτρου τόσο ακραία ή πιο ακραία από την εκτίμηση του δείγματος, με την παραδοχή ότι το κενό μοντέλο είναι αληθές. Η τιμή \(p\) υπολογίζεται βάσει της δειγματοληπτικής κατανομής της εκτίμησης της παραμέτρου υπό το κενό μοντέλο.
Μπορούμε να χρησιμοποιήσουμε την τιμή \(p\) για να αποφασίσουμε, με βάση το επίπεδο σημαντικότητας \(\alpha = 0.05\), αν το παρατηρούμενο στατιστικό του δείγματος θα ήταν απίθανο ή όχι με την παραδοχή ότι το κενό μοντέλο είναι αληθές. Αν το κρίνουμε απίθανο (δηλ. \(p < 0.05\)), τότε πιθανότατα θα αποφασίσουμε να απορρίψουμε το κενό μοντέλο υπέρ του πιο σύνθετου μοντέλου. Αν όμως η τιμή \(p\) είναι μεγαλύτερη από \(0.05\) — όπως συμβαίνει για το μοντέλο της Condition της Tip — πιθανότατα θα αποφασίσουμε να μην απορρίψουμε το κενό μοντέλο προς το παρόν, σε αναμονή πιο ισχυρών ενδείξεων.
12.6 Η Κατανομή F: Ένα Μαθηματικό Μοντέλο της Δειγματοληπτικής Κατανομής του F
Μέχρι τώρα χρησιμοποιήσαμε τυχαιοποίηση (shuffle()) για να δημιουργήσουμε μια δειγματοληπτική κατανομή του F. Ωστόσο, ακριβώς όπως οι στατιστικοί ανέπτυξαν μαθηματικά μοντέλα της δειγματοληπτικής κατανομής του \(b_1\) (π.χ. την κατανομή \(t\)), έχουν επίσης αναπτύξει ένα μαθηματικό μοντέλο της δειγματοληπτικής κατανομής του F. Αυτό το μαθηματικό μοντέλο ονομάζεται κατανομή F.
Με τον ίδιο τρόπο που η μαθηματική κατανομή \(t\) μπορεί να χρησιμοποιηθεί ως μια ιδεατή προσέγγιση για τη μοντελοποίηση δειγματοληπτικών κατανομών του \(b_1\), η κατανομή F είναι ένα μαθηματικό μοντέλο που προσαρμόζεται στη δειγματοληπτική κατανομή του F (και επίσης στη δειγματοληπτική κατανομή του PRE).
Στο παρακάτω διάγραμμα δείχνουμε δύο εκδοχές της δειγματοληπτικής κατανομής του F που υποθέτουν και οι δύο μια ΔΠΔ χωρίς επίδραση της Condition (δηλ. το κενό μοντέλο). Στα αριστερά, μοντελοποιούμε την τυχαιοποιημένη δειγματοληπτική κατανομή χρησιμοποιώντας τη συνάρτηση shuffle(), και στα δεξιά χρησιμοποιώντας τη μαθηματική κατανομή F, όπου η περιοχή που βρίσκεται πάνω από την τιμή F του δείγματός μας αναπαρίσταται με τη μωβ ουρά.
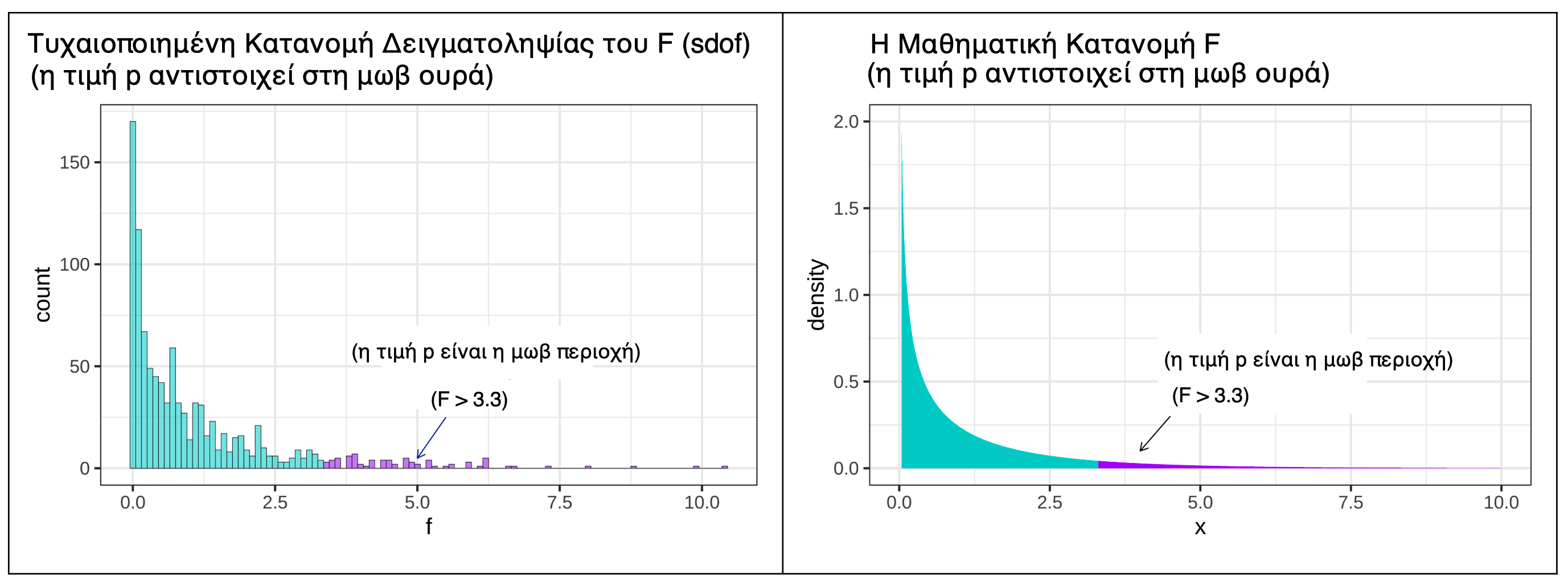
Παρατηρήστε ότι τα σχήματα είναι σχεδόν ίδια. Η μαθηματική κατανομή F φαίνεται να είναι μια εξομαλυμένη εκδοχή της τυχαιοποιημένης δειγματοληπτικής κατανομής του F, και η τιμή \(p\) που υπολογίζεται με βάση την τυχαιοποιημένη δειγματοληπτική κατανομή θα είναι πολύ παρόμοια με την τιμή \(p\) που υπολογίζεται με βάση τη μαθηματική κατανομή F.
Ακριβώς όπως το σχήμα της κατανομής \(t\) αλλάζει ελαφρώς ανάλογα με το μέγεθος του δείγματος ή τους βαθμούς ελευθερίας, το σχήμα της κατανομής F επίσης μεταβάλλεται ανάλογα με τους βαθμούς ελευθερίας. Αλλά επειδή το F υπολογίζεται ως το πηλίκο MS Model προς MS Error, πρέπει να ορίσουμε δύο διαφορετικούς βαθμούς ελευθερίας για να λάβουμε το σχήμα της κατανομής F: τους df για το MS Model (1 στον παρακάτω πίνακα ANOVA)· και τους df για το MS Error, που είναι 42.
Analysis of Variance Table (Type III SS)
Model: Tip ~ Condition
SS df MS F PRE p
----- --------------- | -------- -- ------- ----- ------ -----
Model (error reduced) | 402.023 1 402.023 3.305 0.0729 .0762
Error (from model) | 5108.955 42 121.642
----- --------------- | -------- -- ------- ----- ------ -----
Total (empty model) | 5510.977 43 128.162Η συνάρτηση xpf() μας δίνει έναν τρόπο υπολογισμού της τιμής \(p\) χρησιμοποιώντας τη μαθηματική κατανομή F. Απαιτεί να εισάγουμε τρία ορίσματα: την τιμή F του δείγματος, το df Model (που ονομάζεται df1) και το df Error (που ονομάζεται df2). Δοκιμάστε το στο παρακάτω πλαίσιο κώδικα με τις τιμές των df1 και df2 να προέρχονται από τον παραπάνω πίνακα ANOVA.
Μας αρέσει η συνάρτηση xpf() επειδή εμφανίζει ένα διάγραμμα της κατανομής F και χρωματίζει την περιοχή της ουράς που αντιπροσωπεύει την τιμή \(p\). Επίσης αναφέρει την τιμή \(p\) στο υπόμνημα του διαγράμματος. Παρατηρήστε στο διάγραμμα που εμφανίζεται όταν εκτελείται την παραπάνω γραμμή κώδικα ότι η τιμή \(p\) για το μοντέλο της Condition στο πείραμα των φιλοδωρημάτων είναι 0.0762. Αυτή είναι η ίδια τιμή που αναφέρεται στον πίνακα ANOVA — κάτι που δεν είναι σύμπτωση: η συνάρτηση supernova() χρησιμοποιεί τη μαθηματική κατανομή F για τον υπολογισμό της τιμής \(p\).
Τι αντιπροσωπεύει ολόκληρη η μαθηματική κατανομή F; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Ε.
Η μαθηματική κατανομή F είναι ένα θεωρητικό μοντέλο που περιγράφει όλες τις τιμές F που θα μπορούσαν να προκύψουν αν το κενό μοντέλο ήταν αληθές (Α και Ε). Σε αντίθεση με τη shuffle(), δεν βασίζεται στα συγκεκριμένα δεδομένα μας (Β λάθος). Δεν αντιπροσωπεύει την μεμονωμένη τιμή F του δείγματος (Γ) ούτε την κατανομή του πληθυσμού (Δ).
Τι αντιπροσωπεύει η περιοχή της τιμής \(p\) της κατανομής F (η ουρά στα δεξιά);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η ουρά της μαθηματικής κατανομής F αντιπροσωπεύει την πιθανότητα να παρατηρήσουμε F ≥ 3.305 αν το κενό μοντέλο είναι αληθές — αυτή είναι η τιμή \(p\). Δεν σχετίζεται με πραγματική επίδραση (Α, Β), ούτε με τιμές από τη συνάρτηση shuffle() (Δ).
12.7 Κατανομή F και Κατανομή \(t\)
Σχήματα της Κατανομής F
Το σχήμα της κατανομής F αλλάζει αρκετά ανάλογα με τις τιμές των βαθμών ελευθερίας (df1 και df2). Για να το αναπαραστήσουμε διαγραμματικά, κοιτάξτε τα παρακάτω διαγράμματα. Στα αριστερά, έχουμε απεικονίσει τρεις κατανομές F που έχουν την ίδια τιμή df1 (δηλ. df1 = 2) αλλά διαφέρουν ως προς την τιμή του df2 (2, 12, 1000). Στα δεξιά, έχουμε κρατήσει το df2 σταθερό στο 1000 και έχουμε μεταβάλει το df1 (1, 5, 30).

Πώς μεταβάλλεται το σχήμα της κατανομής F με διαφορετικές τιμές του df2;
Πώς μεταβάλλεται το σχήμα της κατανομής F με διαφορετικές τιμές του df1;
Όταν το df1 (δηλ. το df Model) παραμένει σταθερό (αριστερό πάνελ του σχήματος), αυτό σημαίνει ότι ο αριθμός των παραμέτρων που εκτιμώνται για το μοντέλο παραμένει σταθερός. Για το μοντέλο τριών ομάδων, df1 = 2 — το 2 αντιστοιχεί στον αριθμό των παραμέτρων που εκτιμώνται πέρα από αυτήν του κενού μοντέλου. Μπορούμε να δούμε ότι η αλλαγή του μεγέθους του δείγματος, και άρα των τιμών του df2 (δηλ. του df Error), έχει μόνο μικρή επίδραση στο σχήμα της κατανομής F όταν το df1 παραμένει σταθερό. Ακόμα και με df2 = 12 (μπλε γραμμή), είναι πολύ παρόμοιο με την κατανομή F όπου df2 = 1000 (μαύρη γραμμή). Μόλις το df2 υπερβεί το 30 περίπου, το σχήμα δεν αλλάζει σχεδόν καθόλου.
Η αλλαγή του αριθμού των εκτιμώμενων παραμέτρων του μοντέλου (df Model), αντίθετα, έχει πιο σημαντική επίδραση στο σχήμα της κατανομής F. Στο δεξί πάνελ του παραπάνω σχήματος, όπου κρατάμε το μέγεθος του δείγματος σταθερό σε ένα αρκετά μεγάλο df2 = 1000, η αύξηση του αριθμού παραμέτρων (df1) από 1 σε 5 σε 30 οδηγεί σε μεγάλη διαφορά στο σχήμα. Καθώς ο αριθμός των παραμέτρων αυξάνεται, π.χ. έως 30, η κατανομή F αρχίζει να μοιάζει σχεδόν κανονική.
Η Κατανομή F και η Κατανομή \(t\) είναι στην Πραγματικότητα Ίδιες
Έχουμε ως τώρα χρησιμοποιήσει ένα μαθηματικό μοντέλο για τη δειγματοληπτική κατανομή του \(b_1\) (την κατανομή \(t\)) και ένα άλλο για τη δειγματοληπτική κατανομή του PRE και του F (την κατανομή F). Αλλά διαπιστώσαμε ότι στη μελέτη των φιλοδωρημάτων, είτε χρησιμοποιήσουμε την \(t\) είτε την F, η τιμή \(p\) είναι ακριβώς ίδια (ίση με .0762).
Ο λόγος είναι ότι στην ουσία η κατανομή F και η κατανομή \(t\) είναι η ίδια κατανομή! Αν πάρετε τυχαία τιμές από μια κατανομή \(t\) και στη συνέχεια υψώσετε κάθε μία στο τετράγωνο, θα λάβετε ακριβώς μια κατανομή F!
Στο παρακάτω διάγραμμα αριστερά δείχνουμε την κατανομή 1.000 τιμών \(b_1\) που δημιουργήσαμε χρησιμοποιώντας τη συνάρτηση shuffle(). Γνωρίζουμε από το προηγούμενο κεφάλαιο ότι αυτή η κατανομή μοντελοποιείται καλά από την κατανομή \(t\). Στη συνέχεια υψώσαμε στο τετράγωνο καθεμία από τις 1.000 τιμές \(b_1\) και σχεδιάσαμε την κατανομή των 1.000 b1_squared (b1 στο τετράγωνo). Όπως μπορείτε να δείτε, τώρα μοιάζει με την κατανομή F.

Στην περίπτωση του μοντέλου της Condition, μπορούμε να υπολογίσουμε το στατιστικό \(t\) χρησιμοποιώντας τη συνάρτηση t.test(), και το στατιστικό F χρησιμοποιώντας τη supernova().
data: Tip by Condition
t = -1.818, df = 42, p-value = 0.0762Analysis of Variance Table (Type III SS)
Model: Tip ~ Condition
SS df MS F PRE p
----- --------------- | -------- -- ------- ----- ------ -----
Model (error reduced) | 402.023 1 402.023 3.305 0.0729 .0762
Error (from model) | 5108.955 42 121.642
----- --------------- | -------- -- ------- ----- ------ -----
Total (empty model) | 5510.977 43 128.162Παρατηρήστε δύο πράγματα. Πρώτον, η τιμή \(p\) είναι ακριβώς ίδια για τον \(t\) έλεγχο δύο δειγμάτων και για τη σύγκριση μοντέλων με το F: 0.0762. Δεύτερον, παρατηρήστε τις τιμές του \(t\) (−1.818) και του F (3.305). Μαντέψτε τι θα παίρνατε αν υψώνατε το −1.818 στο τετράγωνο; Ναι, 3.305.
Αντί να προσπαθείτε να σκεφτείτε πώς αυτές οι μέθοδοι διαφέρουν μεταξύ τους (π.χ. έλεγχος F έναντι ελέγχου \(t\), ή έλεγχος τυχαιοποίησης έναντι μαθηματικών συναρτήσεων), θέλουμε προς το παρόν να εκτιμήσετε πόσο παρόμοιες είναι μεταξύ τους. Όλες μας βοηθούν να εντοπίσουμε τις εκτιμήσεις των παραμέτρων μας σε κατανομές άλλων εκτιμήσεων που θα μπορούσαν να έχουν παραχθεί από το κενό μοντέλο.
12.8 Χρήση του F για τον Έλεγχο ενός Μοντέλου Παλινδρόμησης
Όπως είδαμε, μπορούμε να χρησιμοποιήσουμε δειγματοληπτικές κατανομές του \(b_1\) ή του F για να συγκρίνουμε το κενό μοντέλο με ένα μοντέλο δύο ομάδων. Αποδεικνύεται ότι μπορούμε να κάνουμε το ίδιο και για μοντέλα παλινδρόμησης. Προηγουμένως, χρησιμοποιήσαμε μια δειγματοληπτική κατανομή του \(b_1\) για να ελέγξουμε μια υπόθεση για το \(\beta_1\) σε ένα μοντέλο παλινδρόμησης. Τώρα ας χρησιμοποιήσουμε την κατανομή F για να δούμε πώς συγκρίνεται το πηλίκο F ενός μοντέλου παλινδρόμησης με τις τιμές F που παράγονται από το κενό μοντέλο της ΔΠΔ.
Χρήση της Ποιότητας Φαγητού για την Πρόβλεψη του Ποσοστού Φιλοδωρήματος
Στο προηγούμενο κεφάλαιο δημιουργήσαμε ένα μοντέλο παλινδρόμησης που χρησιμοποιούσε τη μέση βαθμολογία κάθε τραπεζιού για την ποιότητα φαγητού (FoodQuality) για να προβλέψει την εξαρτημένη μεταβλητή Tip. Ενδιαφερόμασταν να εξετάσουμε το μοντέλο: Tip = FoodQuality + Άλλα πράγματα. Για να θυμηθούμε αυτό το παράδειγμα, εδώ είναι ένα διάγραμμα διασποράς των δεδομένων καθώς και το βέλτιστο μοντέλο παλινδρόμησης που απεικονίζεται ως μπλε γραμμή.

Χρησιμοποιώντας τη συνάρτηση lm(), προσαρμόσαμε το μοντέλο παλινδρόμησης και βρήκαμε τις βέλτιστες εκτιμήσεις παραμέτρων:
Call:
lm(formula = Tip ~ FoodQuality, data = TipExperiment)
Coefficients:
(Intercept) FoodQuality
10.1076 0.3776 Η βέλτιστη εκτίμηση του \(b_1\) ήταν 0.38, που σημαίνει ότι για κάθε αύξηση μιας μονάδας στην FoodQuality, το Tip αυξανόταν κατά μέσο όρο κατά 0.38 ποσοστιαίες μονάδες. Αυτή είναι η κλίση της ευθείας παλινδρόμησης. Αλλά ενώ αυτή είναι η βέλτιστη εκτίμηση της κλίσης με βάση τα δεδομένα, είναι πιθανό να έχει παραχθεί από το κενό μοντέλο, στο οποίο η πραγματική κλίση στη ΔΠΔ είναι 0;
Στο προηγούμενο κεφάλαιο θέσαμε αυτό το ερώτημα χρησιμοποιώντας τη δειγματοληπτική κατανομή του \(b_1\). Αλλά μπορούμε να θέσουμε το ίδιο ερώτημα χρησιμοποιώντας τη δειγματοληπτική κατανομή του F. Ας ξεκινήσουμε βρίσκοντας το F για το μοντέλο της FoodQuality. Μπορείτε να το κάνετε αυτό στο παρακάτωπλαίσιο κώδικα χρησιμοποιώντας τη συνάρτηση f().
4.42776650396444Η τιμή του πηλίκου F για το μοντέλο FoodQuality είναι 4.43, που υποδηλώνει ότι η διακύμανση που εξηγείται από το μοντέλο είναι 4.43 φορές μεγαλύτερη από τη διακύμανση που παραμένει ανεξήγητη. Είναι σαφές ότι το μοντέλο της FoodQuality εξηγεί περισσότερη διακύμανση από το κενό μοντέλο στα δεδομένα.
Αλλά είναι πιθανό η τιμή F του δείγματος να έχει παραχθεί από μια ΔΠΔ στην οποία δεν υπάρχει επίδραση της FoodQuality στην Tip; Για να απαντήσουμε σε αυτό το ερώτημα θα χρειαστούμε τη δειγματοληπτική κατανομή του F που παράγεται υπό το κενό μοντέλο στο οποίο η πραγματική κλίση της ευθείας παλινδρόμησης στη ΔΠΔ είναι 0.
Κατασκευή της Δειγματοληπτικής Κατανομής του F
Ακολουθώντας την ίδια προσέγγιση που χρησιμοποιήσαμε για τα μοντέλα ομάδων, μπορούμε να χρησιμοποιήσουμε τη συνάρτηση shuffle() για να προσομοιώσουμε πολλά δείγματα από μια ΔΠΔ στην οποία δεν υπάρχει επίδραση της FoodQuality στην Tip, να προσαρμόσουμε το μοντέλο της FoodQuality σε κάθε τυχαιοποιημένο δείγμα, και στη συνέχεια να υπολογίσουμε την αντίστοιχη τιμή του F για κάθε τυχαιοποιημένο δείγμα.
Εκτελέστε τον παρακάτω κώδικα για να δημιουργήσετε μια τυχαιοποιημένη δειγματοληπτική κατανομή 1.000 τιμών F (που θα ονομάζεται sdof) υπό την υπόθεση ότι η FoodQuality δεν έχει καμία σχέση με την Tip. Εμφανίστε τις πρώτες έξι γραμμές του sdof.
Εκτελέστε τον παρακάτω κώδικα για να κατασκευάσετε ένα ιστόγραμμα των τυχαιοποιημένων τιμών F.
Όπως μπορείτε να δείτε στο ιστόγραμμα, η δειγματοληπτική κατανομή του F που κατασκευάστηκε με βάση την υπόθεση ότι το κενό μοντέλο είναι αληθές συνεχίζει να έχει το σχήμα της κατανομής F, ακόμα και αν το μοντέλο είναι μοντέλο παλινδρόμησης και όχι μοντέλο ομάδων.
Απλώς κοιτάζοντας τη δειγματοληπτική κατανομή του F, πόσες από τις 1.000 τυχαιοποιημένες τιμές F ήταν τόσο μεγάλες ή μεγαλύτερες από το F του δείγματός μας (4.43);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Από το ιστόγραμμα, το τυρκουάζ τμήμα (FALSE στο υπόμνημα) αντιστοιχεί στο πιο ακραίο 5% της κατανομής. Η τιμή F = 4.43 βρίσκεται περίπου στο όριο αυτής της περιοχής, άρα περίπου το 5% των τυχαιοποιημένων F είναι τόσο μεγάλες ή μεγαλύτερες από τη δειγματική.
Με βάση αυτό το διάγραμμα, ποια θα ήταν η εκτίμησή σας για την τιμή \(p\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — περίπου 0.04.
Η τιμή F = 4.43 βρίσκεται μέσα στην τυρκουάζ περιοχή του ιστογράμματος, δηλαδή στο πιο ακραίο 5%. Η τιμή \(p\) άρα είναι λίγο μικρότερη από 0.05, περίπου στο 0.04.
Χρησιμοποιήστε το παρακάτω τμήμα κώδικα και τη συνάρτηση tally() για να βρείτε πόσες (ή ποια αναλογία) από τις 1.000 τιμές F ήταν μεγαλύτερες από την τιμή F του δείγματος (4.43).
f > sample_f
TRUE FALSE
41 969Μόνο 41 από τις 1.000 τυχαιοποιημένες τιμές F (στη δική μας τυχαιοποιημένη κατανομή· η δική σας μπορεί να διαφέρει ελαφρώς) ήταν τόσο μεγάλες όσο η τιμή F του δείγματός μας (4.43). Με βάση αυτό, θα εκτιμούσαμε την τιμή \(p\) ως ίση με 0.041. Και πράγματι, αυτό είναι πολύ κοντά στην τιμή \(p\) που λαμβάνουμε στον πίνακα ANOVA για το μοντέλο παλινδρόμησης (που αναπαράγεται παρακάτω), η οποία υπολογίζεται χρησιμοποιώντας τη μαθηματική κατανομή F.
Analysis of Variance Table (Type III SS)
Model: Tip ~ FoodQuality
SS df MS F PRE p
----- --------------- | -------- -- ------- ----- ----- -----
Model (error reduced) | 525.576 1 525.576 4.428 .0954 .0414
Error (from model) | 4985.401 42 118.700
----- --------------- | -------- -- ------- ----- ----- -----
Total (empty model) | 5510.977 43 128.162Επομένως, είναι απίθανο (πιθανότητα περίπου 4%), αλλά όχι αδύνατο, η τιμή F που προκύπτει από το μοντέλο της FoodQuality να είχε προκύψει στην τύχη αν το κενό μοντέλο ήταν αληθές.
Προκαλεί η FoodQuality Αύξηση στην Tip;
Φαίνεται να υπάρχει μια σχέση μεταξύ της μέσης βαθμολογίας ποιότητας φαγητού και του ποσοστού φιλοδωρήματος που αφήνει ένα τραπέζι. Και η τιμή \(p = 0.041\) υποδηλώνει ότι η παρατηρηθείσα σχέση θα ήταν απίθανο να εμφανιζόταν στα δεδομένα αν το κενό μοντέλο ήταν αληθές. Αλλά πρέπει η χαμηλή τιμή \(p\) να μας οδηγήσει στο συμπέρασμα ότι η υψηλότερη ποιότητα φαγητού πράγματι προκάλεσε την αύξηση στην Tip;
Υπενθυμίζουμε ότι αιτιότητα δεν μπορεί να συναχθεί αποκλειστικά με βάση τα αποτελεσμάτα της στατιστικής ανάλυσης· πρέπει επίσης να λαμβάνουμε υπόψη το ερευνητικό σχέδιο.
Ποιο είδος ερευνητικού σχεδίου είναι καλύτερο για την εξακρίβωση αιτιώδους σχέσης μεταξύ της ανεξάρτητης και της εξαρτημένης μεταβλητής;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Πειραματικές μελέτες.
Μόνο οι πειραματικές μελέτες με τυχαία ανάθεση επιτρέπουν την εξαγωγή αιτιωδών συμπερασμάτων, επειδή η τυχαιοποίηση εξαλείφει συστηματικές διαφορές μεταξύ των ομάδων στις οποίες θα μπορούσες να οφείλεται η σχέση. Στις μελέτες συσχέτισης (Δ), η παρατηρηθείσα σχέση μπορεί να οφείλεται σε τρίτες μεταβλητές (συγχυτικές) που δεν ελέγχουν οι ερευνητές.
Όταν διερευνήσαμε την επίδραση του χαμογελαστού προσώπου στο ποσοστό φιλοδρήματος (Tip), είχαμε το πλεονέκτημα της τυχαίας ανάθεσης: κάθε τραπέζι στο εστιατόριο αναθέτηκε τυχαία σε μια συνθήκη (Condition), είτε να λάβει χαμογελαστό πρόσωπο είτε όχι. Αυτό σήμαινε ότι οποιεσδήποτε διαφορές στα φιλοδωρήματα θα μπορούσαν να αποδοθούν είτε στην Condition (το μοναδικό πράγμα που οι ερευνητές μετέβαλαν) είτε στην τύχη. Μια χαμηλή τιμή \(p\) θα οδηγούσε στο συμπέρασμα ότι το χαμογελαστό πρόσωπο στον λογαριασμό οδήγησε σε υψηλότερα φιλοδωρήματα, επειδή θα καθιστούσε απίθανο αυτό να έχει συμβεί λόγω τυχαιότητας.
Η ανάλυση της σχέσης μεταξύ της FoodQuality και της Tip είναι διαφορετική, επειδή αυτή η μελέτη χρησιμοποίησε σχέδιο συσχέτισης, όπου οι ερευνητές μέτρησαν την FoodQuality χωρίς να αναθέτουν τυχαία τα τραπέζια σε επίπεδά της. Χωρίς τυχαία ανάθεση, άλλοι παράγοντες που δεν μετρήθηκαν από τους ερευνητές θα μπορούσαν να έχουν επηρεάσει τόσο την FoodQuality όσο και την Tip. Για παράδειγμα, αν τα τραπέζια με υψηλότερες βαθμολογίες ποιότητας φαγητού γιόρταζαν κάποια ειδική περίσταση, αυτό θα μπορούσε να είχε επηρεάσει τόσο τα φιλοδωρήματα όσο και την αντιληπτή ποιότητα φαγητού.
Ακόμα και σε μια μελέτη συσχέτισης, μια χαμηλή τιμή \(p\) μπορεί να βοηθήσει να αποκλειστεί η τυχαιότητα ως η μοναδική αιτία της διακύμανσης στα φιλοδωρήματα. Αλλά δεν μπορεί να μας πει ότι η μεταβλητή FoodQuality είναι και η αιτία της διακύμανσης στην Tip. Το παρατηρούμενο αποτέλεσμα θα μπορούσε να οφείλεται στην FoodQuality ή σε άλλες αμέτρητες μεταβλητές, οπότε μια χαμηλή τιμή \(p\) δεν υποδηλώνει απαραίτητα αιτιώδη σχέση. Μια χαμηλή τιμή \(p\) στο πλαίσιο μιας μελέτης συσχέτισης μπορεί να αποκλείσει το κενό μοντέλο της ΔΠΔ, αλλά αφήνει ανοιχτά πολλά άλλα μοντέλα που θα μπορούσαν να έχουν προκαλέσει αυτό το μοτίβο της διακύμανσης στα φιλοδωρήματα.
Ας εξετάσουμε το αγαπημένο μας παράδειγμα σε αυτό το βιβλίο, για την εξήγηση της διακύμανσης του μήκους αντίχειρα (Thumb) από το φύλο φοιτητή (Sex). Δίνεται εδώ ο πίνακας ANOVA για να τον εξετάσετε.
Analysis of Variance Table (Type III SS)
Model: Thumb ~ Sex
SS df MS F PRE p
----- --------------- | --------- --- -------- ------ ------ -----
Model (error reduced) | 1334.203 1 1334.203 19.609 0.1123 .0000
Error (from model) | 10546.008 155 68.039
----- --------------- | --------- --- -------- ------ ------ -----
Total (empty model) | 11880.211 156 76.155Τι μπορούμε να συμπεράνουμε από αυτή τη σύγκριση μοντέλων;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η τιμή \(p\) είναι πολύ μικρή (< 0.05), άρα απορρίπτουμε το κενό μοντέλο και υιοθετούμε το σύνθετο. Ωστόσο, επειδή πρόκειται για μελέτη συσχέτισης (χωρίς τυχαία ανάθεση των υποκειμένων σε συνθήκες), δεν μπορούμε να συμπεράνουμε αιτιώδη σχέση — μόνο ότι το φύλο είναι χρήσιμο για την εξήγηση ή την πρόβλεψη του μήκους του αντίχειρα.
12.9 Σφάλμα Τύπου Ι και Σφάλμα Τύπου ΙΙ
Έχουμε αναφέρει σε προηγούμενο κεφάλαιο ότι τα στατιστικά μοντέλα είναι πάντα λανθασμένα. Όταν συγκρίνουμε δύο μοντέλα (π.χ. το μοντέλο της Condition με το κενό μοντέλο), προσπαθούμε τελικά να επιλέξουμε αυτό που θα είναι λιγότερο λανθασμένο με βάση τα δεδομένα που έχουμε. Καταλήγουμε να παίρνουμε μια απόφαση για το ποια πιστεύουμε ότι είναι η πραγματική ΔΠΔ. Αλλά η απόφασή μας μπορεί να είναι λανθασμένη. Δεν θα γνωρίζουμε ποτέ αν είναι σωστή ή λανθασμένη, επειδή δεν γνωρίζουμε ποτέ ποια είναι η πραγματική ΔΠΔ που παρήγαγε τα δεδομένα μας.
Όχι μόνο μπορεί να κάνουμε λάθος, αλλά ίσως σας προβληματίσει το να μάθετε ότι υπάρχουν τουλάχιστον δύο διαφορετικοί τρόποι να κάνετε λάθος όταν συγκρίνετε ένα σύνθετο μοντέλο με το κενό μοντέλο. Οι στατιστικοί αναφέρονται σε αυτούς τους διαφορετικούς τύπους σφαλμάτων ως Σφάλμα Τύπου Ι (Type I Error) και Σφάλμα Τύπου ΙΙ (Type II Error). Όπως θα δούμε, είναι πολύ δύσκολο να αποφύγετε στη μελέτη σας να κάνετε είτε το ένα είτε το άλλο από αυτά τα είδη σφαλμάτων.
Σφάλμα Τύπου Ι (Όταν Απορρίπτουμε το Κενό Μοντέλο ενώ Είναι Αληθές)
Όταν έχουμε αποφασίσει να απορρίψουμε το κενό μοντέλο, μπορεί να έχουμε δίκιο ή να κάνουμε λάθος. Μπορεί να έχουμε κάνει τη σωστή επιλογή αν το κενό μοντέλο πράγματι δεν ισχύει στη ΔΠΔ. Αλλά αν το κενό μοντέλο είναι στην πραγματικότητα αληθές στη ΔΠΔ, η απόρριψη του κενού μοντέλου θα αποτελούσε ένα Σφάλμα Τύπου Ι.
Μπορούμε ποτέ να γνωρίζουμε ποια είναι η πραγματική ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Όλα τα στατιστικά που υπολογίζουμε (\(b_1\), F, τιμή \(p\)) προέρχονται από δεδομένα δείγματος και περιέχουν δειγματοληπτική μεταβλητότητα. Κανένα από αυτά δεν μας αποκαλύπτει την πραγματική ΔΠΔ — μπορούμε μόνο να κάνουμε εκτιμήσεις και να λαμβάνουμε αποφάσεις με κάποια αβεβαιότητα.

Ας εξετάσουμε ένα παράδειγμα χρησιμοποιώντας το παραπάνω σχήμα. Αν υιοθετήσουμε \(\alpha = 0.05\), τότε το όριο για την απόρριψη του κενού μοντέλου θα ήταν F περίπου 4 (ανάλογα με τους βαθμούς ελευθερίας κ.λπ.). Στην παραπάνω εικόνα, η τιμή F του δείγματος για το βέλτιστο μοντέλο υπολογίστηκε ίση με 4.50.
Με αυτές τις πληροφορίες στη διάθεσή μας, τι πρέπει να αποφασίσουμε σε αυτή την περίπτωση;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η τιμή F = 4.50 υπερβαίνει το όριο για \(\alpha = 0.05\) (περίπου F = 4), άρα η τιμή F του δείγματος βρίσκεται στην απίθανη περιοχή. Βάσει του επιπέδου σημαντικότητας που έχουμε ορίσει, απορρίπτουμε το κενό μοντέλο.
Ποιο από τα παρακάτω ισχύει σε αυτή την περίπτωση;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Ακόμα και όταν απορρίπτουμε σωστά το κενό μοντέλο με βάση το \(\alpha\) που έχουμε προκαθορίσει, δεν μπορούμε με βεβαιότητα να γνωρίζουμε ότι η απόφασή μας είναι σωστή — το κενό μοντέλο μπορεί τελικά να είναι αληθές στη ΔΠΔ και η τιμή F = 4.50 να έχει προκύψει τυχαία. Αυτό είναι ακριβώς το Σφάλμα Τύπου Ι: η απόρριψη ενός κενού μοντέλου που είναι στην πραγματικότητα αληθές.
Επειδή η τιμή F = 4.50 του δείγματος ξεπερνούσε το όριο με βάση το \(\alpha\), θα απορρίπταμε το κενό μοντέλο. Αλλά αν το κενό μοντέλο ήταν στην πραγματικότητα αληθές στη ΔΠΔ, θα είχαμε κάνει Σφάλμα Τύπου Ι.
Σφάλμα Τύπου ΙΙ (Όταν Δεν Απορρίπτουμε το Κενό Μοντέλο ενώ Είναι Ψευδές)
Κάνουμε Σφάλμα Τύπου Ι μόνο όταν απορρίπτουμε το κενό μοντέλο ενώ είναι αληθές. Είμαστε, ωστόσο, ασφαλείς όσο δεν απορρίπτουμε το κενό μοντέλο; Δυστυχώς όχι — το να μην απορρίπτουμε το κενό μοντέλο αφήνει ανοιχτή την πιθανότητα ενός άλλου είδους σφάλματος, του Σφάλματος Τύπου ΙΙ, που μπορεί να συμβεί μόνο όταν αποφασίζουμε να μην απορρίψουμε το κενό μοντέλο ενώ είναι ψευδές. Πώς θα μπορούσαμε να κάνουμε λάθος αν αποφασίσουμε να παραμείνουμε στο κενό μοντέλο της ΔΠΔ (δηλ. να μην το απορρίψουμε);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το Σφάλμα Τύπου ΙΙ συμβαίνει όταν δεν απορρίπτουμε το κενό μοντέλο ενώ στην πραγματικότητα δεν είναι αυτό που ισχύει στη ΔΠΔ (δηλ. \(\beta_1 \neq 0\)). Με άλλα λόγια, «μας ξέφυγε» μια πραγματική επίδραση.
 Αν και δεν θα γνωρίζουμε ποτέ την πραγματική ΔΠΔ, κάθε φορά που δεν απορρίπτουμε το κενό μοντέλο, πρέπει να αναγνωρίζουμε την πιθανότητα Σφάλματος Τύπου ΙΙ. Ας εξετάσουμε μια περίπτωση, που απεικονίζεται παρακάτω, όπου το F του δείγματος είναι 3.50. Το επίπεδο σημαντικότητας \(\alpha\) παραμένει ίσο με 0.05.
Αν και δεν θα γνωρίζουμε ποτέ την πραγματική ΔΠΔ, κάθε φορά που δεν απορρίπτουμε το κενό μοντέλο, πρέπει να αναγνωρίζουμε την πιθανότητα Σφάλματος Τύπου ΙΙ. Ας εξετάσουμε μια περίπτωση, που απεικονίζεται παρακάτω, όπου το F του δείγματος είναι 3.50. Το επίπεδο σημαντικότητας \(\alpha\) παραμένει ίσο με 0.05.
Τι πρέπει να αποφασίσουμε σε αυτή την περίπτωση;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η τιμή F = 3.50 είναι κάτω από το όριο \(\alpha = 0.05\) (περίπου F = 4), άρα δεν βρίσκεται στην απίθανη περιοχή. Βάσει του επιπέδου σημαντικότητας που έχουμε ορίσει, δεν απορρίπτουμε το κενό μοντέλο.
Τι πρέπει να αποδεχόμαστε σε αυτή την περίπτωση; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Δ.
Όταν δεν απορρίπτουμε το κενό μοντέλο, αποκλείουμε εξ ορισμού το Σφάλμα Τύπου Ι (Β). Ωστόσο, αν το κενό μοντέλο δεν είναι αληθές στη ΔΠΔ και εμείς δεν το απορρίψαμε, έχουμε κάνει Σφάλμα Τύπου ΙΙ (Δ). Επειδή η τιμή F του δείγματος βρίσκεται τώρα κάτω από το όριο του 0.05, αποφασίζουμε να μην απορρίψουμε το κενό μοντέλο. Αν έχουμε κάνει λάθος ή όχι εξαρτάται από το τι είναι πραγματικά αληθές στη ΔΠΔ (κάτι που δεν γνωρίζουμε).
Μείωση της Πιθανότητας Διάπραξης Σφάλματος
Μπορούμε να μειώσουμε την πιθανότητα διάπραξης Σφάλματος Τύπου Ι κάνοντας πιο δύσκολη την απόρριψη του κενού μοντέλου. Μπορούμε να το επιτύχουμε αυτό αλλάζοντας το όριο για το επίπεδο σημαντικότητας \(\alpha\). Για παράδειγμα, τα παρακάτω σχήματα δείχνουν τι συμβαίνει όταν μετακινούμε το επίπεδο σημαντικότητας \(\alpha\) από το 0.05 (αριστερό πάνελ) στο 0.01 (δεξί πάνελ).

Με βάση την τιμή F = 4.5 του δείγματος, σε ποια από τις παρακάτω περιπτώσεις θα απορρίπταμε το κενό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Με \(\alpha = 0.05\), το όριο είναι περίπου στο F = 4, και το F = 4.50 το ξεπερνά — άρα απορρίπτουμε το κενό μοντέλο. Με \(\alpha = 0.01\), το όριο μετακινείται περίπου στο F = 7, και το F = 4.50 δεν το ξεπερνά πλέον — άρα δεν απορρίπτουμε το κενό μοντέλο.
Πότε μπορούμε να κάνουμε Σφάλμα Τύπου Ι;
Με \(\alpha = 0.05\), η τιμή F του δείγματος θεωρήθηκε απίθανο να προήλθε από το κενό μοντέλο της ΔΠΔ. Αλλά με \(\alpha = 0.01\), η ίδια τιμή F του δείγματος δεν θεωρείται πλέον απίθανη — δεν βρίσκεται στα άκρα. Ενώ στο σχήμα αριστερά θα απορρίπταμε το κενό μοντέλο, στο σχήμα δεξιά δεν θα το απορρίπταμε. Ορίζοντας το \(\alpha = 0.01\), έχουμε κάνει πιο δύσκολη την απόρριψη του κενού μοντέλου, και άρα πιο δύσκολο το να κάνουμε Σφάλμα Τύπου Ι (υποθέτοντας ότι το κενό μοντέλο είναι αληθές).
Αν θέλουμε να αποφύγουμε το Σφάλμα Τύπου Ι, το πιο απλό που μπορούμε να κάνουμε είναι να ορίσουμε το \(\alpha\) μας σε μια πολύ μικρή τιμή, κάτι που κάνει πολύ δύσκολη την απόρριψη του κενού μοντέλου. Αλλά δυστυχώς η μείωση του \(\alpha\) αυξάνει στην πραγματικότητα την πιθανότητα Σφάλματος Τύπου ΙΙ. Αν το κενό μοντέλο δεν είναι αληθές, θα θέλαμε να το απορρίψουμε. Μη απορρίπτοντάς το όταν δεν είναι ψευδές, έχουμε κάνει Σφάλμα Τύπου ΙΙ.
Ας σκεφτούμε την αντίθετη περίπτωση. Αν ορίζαμε \(\alpha = 0.25\) (κάνοντας πολύ εύκολη την απόρριψη του κενού μοντέλου), τι θα συμβεί στην πιθανότητα Σφάλματος Τύπου Ι;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Με \(\alpha = 0.25\), απορρίπτουμε το κενό μοντέλο πολύ πιο εύκολα — αλλά αυτό σημαίνει ότι θα απορρίπτουμε συχνότερα και όταν το κενό μοντέλο είναι αληθές, αυξάνοντας έτσι την πιθανότητα Σφάλματος Τύπου Ι.
Σύνοψη Σφάλματος Τύπου Ι και Τύπου ΙΙ
Αυτές είναι δύσκολες έννοιες για να τις έχετε για πολύ στο μυαλό σας. Μην ανησυχείτε αν σας μπερδεύουν — και οι πιο ειδικοί στη στατιστικοί μπερδεύονται κατά καιρούς. Για να βοηθήσουμε, έχουμε δημιουργήσει έναν πίνακα που συνοψίζει τις έννοιες του Σφάλματος Τύπου Ι και Τύπου ΙΙ.
| Τι ισχύει πραγματικά | ||
|---|---|---|
| Μοντέλο που υιοθετούμε με βάση τα δεδομένα | Κενό μοντέλο (\(\beta_1 = 0\)) | Σύνθετο μοντέλο (\(\beta_1 \neq 0\)) |
| Κενό μοντέλο | Σωστή απόφαση! | Σφάλμα Τύπου ΙΙ |
| Σύνθετο μοντέλο (Απόρριψη κενού) | Σφάλμα Τύπου Ι | Σωστή απόφαση! |
12.10 Χρήση του F για τη Σύγκριση Πολλαπλών Ομάδων
Μέχρι τώρα έχουμε χρησιμοποιήσει τόσο τη δειγματοληπτική κατανομή του \(b_1\) όσο και τη δειγματοληπτική κατανομή του F για να συγκρίνουμε ένα σύνθετο μοντέλο της ΔΠΔ (είτε μοντέλο δύο ομάδων είτε μοντέλο παλινδρόμησης) με το κενό μοντέλο. Και οι δύο προσεγγίσεις δίνουν παρόμοια αποτελέσματα, οδηγώντας σε μια τιμή \(p\) που υποδηλώνει την πιθανότητα το \(b_1\) ή το F του δείγματος να έχουν παραχθεί αν το κενό μοντέλο είναι αληθές.
Εκεί όμως που η κατανομή F πραγματικά υπερέχει είναι στη σύγκριση πιο σύνθετων μοντέλων (δηλ. αυτών με περισσότερες παραμέτρους που εκτιμώνται) με το κενό μοντέλο. Ας πάρουμε, για παράδειγμα, ένα μοντέλο τριών ομάδων, που θα μπορούσαμε να αναπαραστήσουμε ως εξής:
\[Y_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \epsilon_i\]
Τώρα έχουμε δύο επιπλέον παραμέτρους σε σχέση με το κενό μοντέλο: \(\beta_1\) και \(\beta_2\). Το \(\beta_1\) είναι η διαφορά από την πρώτη ομάδα στη δεύτερη, ενώ το \(\beta_2\) είναι η διαφορά από την πρώτη ομάδα στην τρίτη. Θα μπορούσαμε, θεωρητικά, να υπολογίσουμε μια τιμή \(p\) για κάθε μία από τις εκτιμήσεις παραμέτρων (\(\beta_1\) και \(\beta_2\)), αλλά αυτές οι τιμές \(p\) θα ήταν δύσκολο να ερμηνευτούν. Τι θα λέγαμε αν η μία ήταν χαμηλή και η άλλη υψηλή; Τι θα σήμαινε αυτό για το συνολικό μοντέλο;
Το πηλίκο F, και η αντίστοιχη δειγματοληπτική κατανομή του, μας δίνει μια κομψή λύση σε αυτό το πρόβλημα. Αντί να εξετάζουμε το \(\beta_1\) ή το \(\beta_2\) χωριστά, το στατιστικό F συγκρίνει ολόκληρο το σύνθετο μοντέλο με το κενό μοντέλο. Αυτό όμως θα αλλάξει τον τρόπο που ερμηνεύουμε τα αποτελέσματα του ελέγχου F. Ας το δούμε αυτό στην πράξη χρησιμοποιώντας τον έλεγχο F με ένα μοντέλο τριών ομάδων.
Μια Μελέτη που Συγκρίνει την Αποτελεσματικότητα Τριών Μαθηματικών Παιχνιδιών
Το πλαίσιο δεδομένων game_data περιέχει τα δεδομένα μιας μικρής μελέτης που συγκρίνει την αποτελεσματικότητα τριών διαφορετικών ηλεκτρονικών μαθηματικών παιχνιδιών σε ένα δείγμα 105 μαθητών της πέμπτης τάξης. Και τα τρία παιχνίδια εστίαζαν στο ίδιο θέμα και είχαν πανομοιότυπους μαθησιακούς στόχους, και κανένας μαθητής δεν είχε προηγούμενες γνώσεις γύρω από το θέμα.
Οι μαθητές αναθέτηκαν τυχαία για να παίξουν ένα από τα τρία μαθηματικά παιχνίδια, τα οποία θα αποκαλούμε Α, Β και C. Κάθε μαθητής έπαιξε το παιχνίδι που του αναθέτηκε για συνολικά 10 ώρες κατανεμημένες σε μια εβδομάδα. Στο τέλος της εβδομάδας, τα μαθησιακά αποτελέσματα αξιολογήθηκαν με ένα κοινό τεστ 30 ερωτήσεων. Το ερευνητικό ερώτημα ήταν: Ήταν κάποια παιχνίδια πιο αποτελεσματικά από άλλα; Παρήγαγαν τα τρία παιχνίδια διαφορετικά μαθησιακά αποτελέσματα;
Το πλαίσιο δεδομένων game_data περιλαμβάνει 105 μαθητές και δύο μεταβλητές:
-
game— το παιχνίδι στο οποίο αναθέτηκε τυχαία ο μαθητής, κωδικοποιημένο ως Α, Β ή C -
outcome— η βαθμολογία κάθε μαθητή στο τεστ
Ας συγκρίνουμε τη μεταβλητή outcome στα τρία παιχνίδια, χρησιμοποιώντας τόσο τη συνάρτηση gf_boxplot() όσο και τη συνάρτηση favstats().
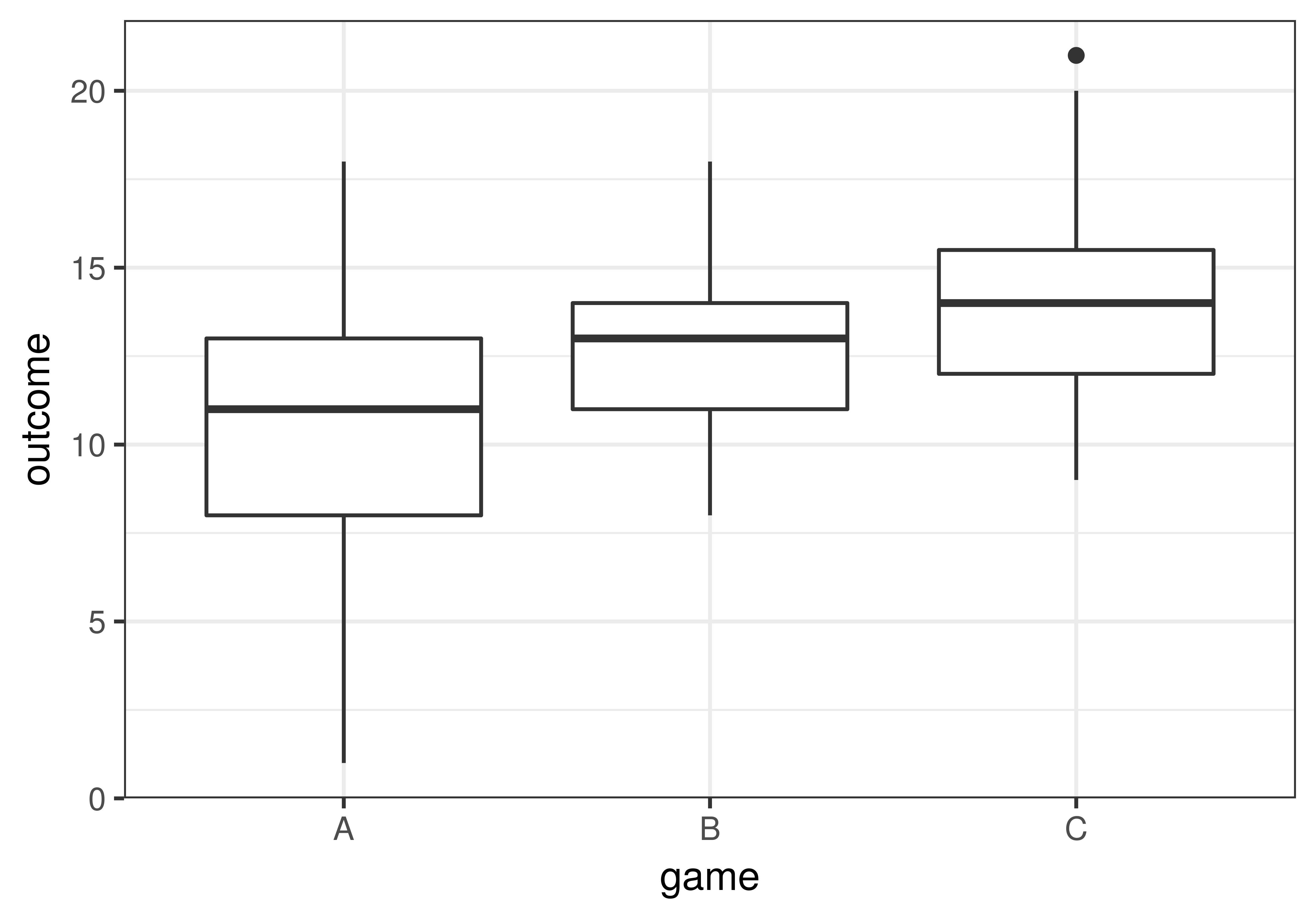
game min Q1 median Q3 max mean sd n missing
1 A 1 8 11 13.0 18 10.48571 3.641036 35 0
2 B 8 11 13 14.0 18 12.57143 2.512155 35 0
3 C 9 12 14 15.5 21 14.11429 2.897985 35 0Από τα boxplot και τα αποτελέσματα της favstats(), ποια ομάδα φαίνεται να είχε χαμηλότερη βαθμολογία;
Μπορείτε να διαπιστώσετε από τα boxplot ότι οι μαθητές που έπαιξαν το παιχνίδι Α φαίνεται να έχουν χειρότερα αποτελεσματα, κατά μέσο όρο, από αυτούς που έπαιξαν το παιχνίδι C.
Υπάρχουν, ωστόσο, μαθητές που έπαιξαν το παιχνίδι Α και έχουν καλύτερα αποτελέσματα από μαθητές που έπαιξαν το παιχνίδι C;
ΣημείωσηΕπεξήγηση
Ναι — από το boxplot φαίνεται ότι υπάρχει επικάλυψη μεταξύ των κατανομών, άρα μερικοί μαθητές του Α είχαν υψηλότερες βαθμολογίες από μερικούς μαθητές του C.
Φαίνεται τόσο από τη favstats() όσο και από τα boxplot ότι οι μαθητές του παιχνιδιού C είχαν γενικά τα καλύτερα αποτελέσματα και οι μαθητές του Α τα χειρότερα. Οι μαθητές του Β βρίσκονται ανάμεσα στις άλλες δύο ομάδες. Φαίνεται επίσης ότι τα αποτελέσματα των μαθητών που έπαιξαν το παιχνίδι Α ποίκιλαν περισσότερο από αυτά των μαθητών των άλλων δύο ομάδων.
Μόνο από τα boxplot, θα συμπεραίνατε ότι το παιχνίδι C είναι πιο αποτελεσματικό από τα παιχνίδια Α και Β;
Αν και φαίνεται από τα boxplot ότι οι μαθητές του παιχνιδιού C είχαν καλύερα αποτελέσματα από αυτούς του Α, αυτό δεν σημαίνει απαραίτητα ότι το παιχνίδι C είναι πιο αποτελεσματικό στη ΔΠΔ. Είναι πιθανό η διαφορά που παρατηρήθηκε στο δείγμα να είναι απλώς αποτέλεσμα τυχαίας δειγματοληπτικής διακύμανσης: ίσως το παιχνίδι C έτυχε να έχει μια πιο ικανή ομάδα μαθητών.
Τώρα γνωρίζετε πώς να αναδιατυπώσετε αυτό το ερώτημα ως σύγκριση μοντέλων. Ποιο μοντέλο θέλουμε να υιοθετήσουμε ως καλύτερη εκτίμηση για τη ΔΠΔ; Το κενό μοντέλο, στο οποίο και τα τρία παιχνίδια είναι εξίσου αποτελεσματικά, ή το μοντέλο τριών ομάδων στο οποίο τα τρία παιχνίδια δεν είναι εξίσου αποτελεσματικά; Δίνονται τα δύο μοντέλα σε σημειογραφία GLM:
Μοντέλο της game: \[\text{outcome}_i = \beta_0 + \beta_1 X_{1i} + \beta_2 X_{2i} + \epsilon_i\]
Κενό μοντέλο: \[\text{outcome}_i = \beta_0 + \epsilon_i\]
Προσαρμόστε το μοντέλο παιχνιδιού στο παρακάτω παράθυρο κώδικα.
Call:
lm(formula = outcome ~ game, data = game_data)
Coefficients:
(Intercept) gameB gameC
10.486 2.086 3.629 Ερμηνεύστε τη σημασία των συμβόλων στην παρακάτω εξίσωση.
\[Y_i = 10.486 + 2.086X_{1i} + 3.628X_{2i} + e_i\]
Τι είναι το \(Y_i\);
Τι είναι το 10.486;
Τι είναι το 2.086;
Τι είναι το 3.629;
Τι είναι το \(e_i\);
ΣημείωσηΕπεξήγηση
- \(Y_i\): Η βαθμολογία κάθε μαθητή στο τεστ.
- 10.486: Ο μέσος όρος της ομάδας Α (η ομάδα αναφοράς), δηλαδή \(b_0\).
- 2.086: Η διαφορά μεταξύ του μέσου της ομάδας Β και του μέσου της ομάδας Α (\(b_1\)). Άρα μέσος Β = 10.486 + 2.086 = 12.572.
- 3.629: Η διαφορά μεταξύ του μέσου της ομάδας C και του μέσου της ομάδας Α (\(b_2\)). Άρα μέσος C = 10.486 + 3.629 = 14.115.
- \(e_i\): Το σφάλμα — η διαφορά μεταξύ της πραγματικής βαθμολογίας του μαθητή και της τιμής πρόβλεψης του μοντέλου.
\[Y_i = 10.486 + 2.086X_{1i} + 3.629X_{2i} + e_i\]
Ερμηνεύστε τα \(X_{1i}\) και \(X_{2i}\).
ΣημείωσηΕπεξήγηση
Το \(X_{1i}\) είναι μια δυαδική μεταβλητή (0 ή 1) που υποδηλώνει αν ο μαθητής \(i\) έπαιξε το παιχνίδι Β: παίρνει τιμή 1 αν ο μαθητής έπαιξε το Β και 0 αν έπαιξε οποιοδήποτε άλλο. Ομοίως, το \(X_{2i}\) παίρνει τιμή 1 αν ο μαθητής έπαιξε το παιχνίδι C και 0 αν έπαιξε οποιοδήποτε άλλο. Όταν και τα δύο είναι 0, ο μαθητής ανήκει στην ομάδα αναφοράς, δηλαδή έπαιξε το παιχνίδι Α.
Στο επόμενο πλαίσιο κώδικα, εκτελέστε τη συνάρτηση supernova() στο game_model για να δείτε πώς συγκρίνεται με το κενό μοντέλο.
Analysis of Variance Table (Type III SS)
Model: outcome ~ game
SS df MS F PRE p
----- --------------- | -------- --- ------- ------ ------ -----
Model (error reduced) | 232.133 2 116.067 12.451 0.1962 .0000
Error (from model) | 950.857 102 9.322
----- --------------- | -------- --- ------- ------ ------ -----
Total (empty model) | 1182.990 104 11.375Πόσες ανεξάρτητες μεταβλητές υπάρχουν στο μοντέλο της
game;
Πόσες παράμετροι εκτιμώνται στο μοντέλο της
game;
Ποιο από τα παρακάτω σας λέει πόσες επιπλέον παράμετροι χρησιμοποιούνται στο μοντέλο της game σε σχέση με το κενό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — df Model.
Το df Model = 2, που σημαίνει ότι το μοντέλο game χρησιμοποιεί 2 επιπλέον παραμέτρους σε σχέση με το κενό μοντέλο (\(b_1\) και \(b_2\)).
Ο πίνακας ANOVA δείχνει F = 12.451. Τι σημαίνει αυτό για τη σύγκριση των μοντέλων; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Δ και Ε.
Το F = MS Model / MS Error = 12.451, άρα το MS Model είναι 12.451 φορές μεγαλύτερο από το MS Error (Α). Αυτό αντιστοιχεί στη διακύμανση που εξηγείται από το μοντέλο σε σχέση με την διακύμανση που απομένει (Δ). Επίσης, χρησιμοποιώντας τον τύπο \(F = \frac{PRE/df_{\text{model}}}{(1-PRE)/df_{\text{error}}}\), το F αντικατοπτρίζει το PRE ανά παράμετρο (Ε). Το Β είναι λάθος (το F χρησιμοποιεί MS, όχι SS) και το Γ περιγράφει το PRE (≈ 0.196), όχι το F.
Χρήση της Δειγματοληπτικής Κατανομής του F για Σύγκριση των Δύο Μοντέλων
Μπορούμε να δούμε από τον πίνακα ANOVA ότι το μοντέλο της game αξιοποιεί τόσο αποτελεσματικά τις επιπλέον εκτιμήσεις παραμέτρων, ώστε η διακύμανση που ερμηνεύεται από το σύνθετο μοντέλο είναι περισσότερο από 12 φορές μεγαλύτερη από αυτήν που παραμένει ανεξήγητη. Αλλά αρκεί μια υψηλή τιμή F για να απορρίψουμε το κενό μοντέλο της ΔΠΔ υπέρ του σύνθετου μοντέλου;
Για να απορρίψουμε το κενό μοντέλο, θέλουμε να γνωρίζουμε την πιθανότητα ένα στατιστικό F τόσο ακραίο όσο το παρατηρούμενο F (12.45) να μπορούσε να έχει παραχθεί από το κενό μοντέλο — αυτό που έχουμε ονομάσει τιμή \(p\). Αν η πιθανότητα είναι χαμηλή (π.χ. μικρότερη από 0.05), τότε θα μπορούσαμε να απορρίψουμε το κενό μοντέλο υπέρ του πιο σύνθετου μοντέλου (δηλ. του μοντέλου της game). Αυτό είναι που επίσης λέγεται και «απόρριψη της μηδενικής υπόθεσης».
Υπό το κενό μοντέλο, η πραγματική διαφορά μεταξύ των 3 ομάδων είναι ίση με 0. Με άλλα λόγια, τα τρία παιχνίδια είναι εξίσου αποτελεσματικά.
Για να υπολογίσουμε την τιμή \(p\), χρειάζεται να δημιουργήσουμε μια δειγματοληπτική κατανομή του F από το κενό μοντέλο της ΔΠΔ. Μπορούμε να χρησιμοποιήσουμε τυχαιοποίηση (π.χ. την shuffle()) αλλά μπορούμε επίσης να χρησιμοποιήσουμε τη μαθηματική κατανομή F. Ελπίζουμε να σας έχουμε πείσει μέχρι τώρα ότι και οι δύο οδηγούν σε περίπου παρόμοια αποτελέσματα. Ας επιλέξουμε τη δεύτερη επιλογή και να χρησιμοποιήσουμε την κατανομή F (που είναι αυτή που χρησιμοποιεί η supernova() για τον υπολογισμό της τιμής \(p\)).
Analysis of Variance Table (Type III SS)
Model: outcome ~ game
SS df MS F PRE p
----- --------------- | -------- --- ------- ------ ------ -----
Model (error reduced) | 232.133 2 116.067 12.451 0.1962 .0000
Error (from model) | 950.857 102 9.322
----- --------------- | -------- --- ------- ------ ------ -----
Total (empty model) | 1182.990 104 11.375Η τιμή \(p\) \(0.0000\) αντιπροσωπεύει μια πολύ, πολύ χαμηλή πιθανότητα (\(p < .0001\)) να παρατηρήσουμε τιμή F μεγαλύτερη από την τιμή F του δείγματός μας (12.45), αν δεν υπήρχε διαφορά στην αποτελεσματικότητα μεταξύ των παιχνιδιών. Σημειώστε ότι η φράση «καμία διαφορά μεταξύ των τριών ομάδων» σημαίνει επίσης ότι μεταξύ όλων των ζευγών παιχνιδιών (Α με Β, Β με C, Α με C), η πραγματική διαφορά θα ήταν 0. Με βάση αυτό το αποτέλεσμα, θα απορρίπταμε το κενό μοντέλο και θα υιοθετούσαμε το πιο σύνθετο μοντέλο στο οποίο η πραγματική διαφορά μεταξύ των παιχνιδιών στην αποτελεσματικότητά τους δεν είναι ίση με 0.
Ερμηνεία του F για πολλαπλές ομάδες
Μια χαμηλή τιμή \(p\) (π.χ. μικρότερη από 0.05 ή 0.01), που συνδέεται πάντα με υψηλό πηλίκο F, σημαίνει ότι η πιθανότητα τα δεδομένα μας να έχουν παραχθεί από το κενό μοντέλο είναι πολύ χαμηλή, και έτσι θα απορρίπταμε το κενό μοντέλο.
Αν απορρίψουμε το κενό μοντέλο, τι συνεπάγεται αυτό;
Αν τα τρία παιχνίδια δεν είναι εξίσου αποτελεσματικά, σημαίνει αυτό ότι και τα τρία παιχνίδια διαφέρουν μεταξύ τους;
Αν απορρίψουμε το κενό μοντέλο βάσει του πηλίκου F και της τιμής \(p\), αυτό εγγυάται ότι το μοντέλο της game είναι αληθές στη ΔΠΔ;
ΣημείωσηΕπεξήγηση
Η απόρριψη του κενού μοντέλου δεν σημαίνει ότι το εναλλακτικό μοντέλο (αυτό που προσαρμόζεται καλύτερα στα δεδομένα μας) είναι αληθές. Το σύνθετο μοντέλο είναι απλώς ένα από τα πιθανά μοντέλα που είναι συμβατά με τα δεδομένα μας.
Στην περίπτωση ενός μοντέλου δύο ομάδων, όπως αυτό που χρησιμοποιήσαμε για να συγκρίνουμε το ποσοστό φιλοδωρήματος μεταξύ των ομάδων με και χωρίς χαμογελαστό πρόσωπο, η ερμηνεία μιας χαμηλής τιμής \(p\) θα ήταν απλή: η παρατηρηθείσα διαφορά μεταξύ των δύο ομάδων είναι απίθανο να έχει προκύψει από έναν κόσμο στον οποίο η πραγματική διαφορά μεταξύ των ομάδων (στη ΔΠΔ) είναι ίση με 0. Αυτό εννοούμε όταν λέμε ότι η διαφορά μεταξύ δύο ομάδων είναι στατιστικά σημαντική. Πιστεύουμε ότι η διαφορά είναι πραγματική στη ΔΠΔ.
Με ένα μοντέλο τριών ομάδων, ωστόσο, η ερμηνεία μιας χαμηλής τιμής \(p\) είναι λίγο πιο περίπλοκη. Σημαίνει ότι μπορούμε να είμαστε σίγουροι ότι το κενό μοντέλο (όπου οι τρεις ομάδες είναι ίσες μεταξύ τους) δεν είναι καλό μοντέλο της ΔΠΔ που παρήγαγε το δείγμα μας και ότι το μοντέλο της game είναι σημαντικά καλύτερο. Η χαμηλή τιμή \(p\) μας λέει ότι τα τρία παιχνίδια έχουν πιθανότητα μικρότερη από 0.05 να παράγουν τα ίδια μαθησιακά αποτελέσματα στη ΔΠΔ.
Η απόρριψη του κενού μοντέλου δεν μας λέει, ωστόσο, ποια από τα τρία παιχνίδια διαφέρουν σημαντικά μεταξύ τους και ποια μπορεί να μη διαφέρουν. To συνολικό F μας επιτρέπει να συγκρίνουμε μόνο το σύνθετο μοντέλο ως σύνολο με το κενό μοντέλο. Αν θέλουμε να γνωρίζουμε ποια παιχνίδια διαφέρουν από ποια άλλα, θα χρειαστούμε μια νέα τεχνική: τις πολλαπλές συγκρίσεις κατά ζεύγη (multiple pairwise comparisons).
12.11 Συγκρίσεις Κατά Ζεύγη
Μπορεί να είναι αρκετό να γνωρίζουμε ότι το σύνθετο μοντέλο, δηλαδή αυτό που περιλαμβάνει τη μεταβλητή game, είναι σημαντικά καλύτερο από το κενό μοντέλο. Αλλά μερικές φορές θέλουμε να γνωρίζουμε περισσότερα. Θέλουμε να γνωρίζουμε ποια από τα τρία παιχνίδια, συγκεκριμένα, είναι πιο αποτελεσματικά στη ΔΠΔ, και ποια φαίνονται απλώς πιο αποτελεσματικά λόγω δειγματοληπτικής διακύμανσης.
Στα δεδομένα μας (παρουσιάζουμε ξανά τα τρία boxplot παρακάτω), φαίνεται ότι οι μαθητές του παιχνιδιού Γ είχαν καλύτερη βαθμολογία από αυτούς του Β, που με τη σειρά τους είχαν καλύτερη από αυτούς του Α. Αλλά τέτοιες διαφορές θα μπορούσαν να οφείλονται σε δειγματοληπτική διακύμανση και όχι σε πραγματικές διαφορές στη ΔΠΔ. Αν ισχυριζόμασταν ότι υπάρχει διαφορά στη ΔΠΔ ενώ στην πραγματικότητα ήταν απλώς μια διαφορά που οφείλεται σε δειγματοληπτική διακύμανση, θα μας είχε ξεγελάσει η τύχη (δηλ. θα είχαμε κάνει Σφάλμα Τύπου Ι).
Κοιτάξτε προσεκτικά τα αποτελέσματα αυτής της μελέτης. Ποιες δύο ομάδες φαίνονται λιγότερο διαφορετικές μεταξύ τους; (Ένας άλλος τρόπος να θέσετε αυτό το ερώτημα είναι: Ποιες δύο ομάδες θα μπορούσαν να μας παραπλανήσουν ώστε να κάνουμε Σφάλμα Τύπου Ι;)
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β με C.
Από τα boxplot, τα παιχνίδια Β και C έχουν τους πιο κοντινούς μέσους όρους (12.57 και 14.11 αντίστοιχα) και μεγάλη επικάλυψη στις κατανομές τους. Αυτά τα δύο παιχνίδια είναι πιο πιθανό να μας παραπλανήσουν ώστε να συμπεράνουμε ότι υπάρχει πραγματική διαφορά στη ΔΠΔ όταν στην πραγματικότητα η διαφορά μπορεί να οφείλεται μόνο σε δειγματοληπτική διακύμανση.
Για να καταλάβουμε ποιες ομάδες διαφέρουν μεταξύ τους στη ΔΠΔ, μπορούμε να κάνουμε τρεις συγκρίσεις μοντέλων, καθεμία σχεδιασμένη να ελέγχει τη διαφορά μεταξύ ενός από τα πιθανά ζεύγη των τριών παιχνιδιών: Α με Β, Β με C και Α με C. Οι τρεις αυτές συγκρίσεις μοντέλων θα ήταν:
- ένα μοντέλο στο οποίο το Α και το Β διαφέρουν σε σχέση με ένα στο οποίο είναι ίδια (το κενό μοντέλο)·
- ένα μοντέλο στο οποίο το Β και το C διαφέρουν σε σχέση με το κενό μοντέλο· και
- ένα μοντέλο στο οποίο το Α και το C διαφέρουν σε σχέση με το κενό μοντέλο.
Τα μοντέλα για τις τρεις συγκρίσεις κατά ζέυγη θα αναπαρίστανται με τον ίδιο τρόπο σε σημειογραφία GLM:
Μοντέλο που συγκρίνει δύο παιχνίδια: \[\text{outcome}_i = \beta_0 + \beta_1 X_i + \epsilon_i\]
Έναντι του κενού μοντέλου: \[\text{outcome}_i = \beta_0 + \epsilon_i\]
Με άλλα λόγια, θα κάναμε τρεις ξεχωριστές συγκρίσεις δύο ομάδων, όπου η \(X_i\) κωδικοποιείται ως 0 ή 1 ανάλογα με το ποια από τα δύο παιχνίδια συγκρίνονται. Κάθε σύγκριση θα δώσει ένα ξεχωριστό στατιστικό F, το οποίο θα μπορούσαμε να ερμηνεύσουμε χρησιμοποιώντας την κατάλληλη κατανομή F.
Η Συνάρτηση pairwise()
Ένας βολικός τρόπος για να υλοποιήσουμε αυτές τις συγκρίσεις μοντέλων κατά ζεύγη είναι χρησιμοποιώντας τη συνάρτηση pairwise() από το πακέτο supernova της R. Προηγουμένως, αποθηκεύσαμε το μοντέλο τριών ομάδων της game που προβλέπει την outcome σε ένα αντικείμενο R που ονομάζεται game_model. Μπορούμε να εκτελέσουμε τον παρακάτω κώδικα για να λάβουμε τις συγκρίσεις κατά ζεύγη.
Η συνάρτηση pairwise() παράγει το παρακάτω αποτελέσμα:
Model: outcome ~ game
Levels: 3
Family-wise error-rate: 0.143
group_1 group_2 diff pooled_se t df lower upper p_val
<chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 B A 2.086 0.516 4.041 102 1.229 2.942 .0001
2 C A 3.629 0.516 7.031 102 2.772 4.485 .0000
3 C B 1.543 0.516 2.990 102 0.686 2.400 .0035Ο μέσος όρος της ομάδας Α ήταν 10.486 και ο μέσος όρος της ομάδας Β ήταν 12.571. Πού βλέπετε αυτή τη διαφορά μέσων όρων στο παραπάνω αποτέλεσμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η πρώτη γραμμή συγκρίνει τις ομάδες Β και Α, και η τιμή diff = 2.086 είναι ακριβώς η διαφορά των μέσων όρων: 12.571 − 10.486 = 2.086.
Αν δεν υπήρχε διαφορά μεταξύ των μέσων όρων των ομάδων Α και Β, ποια θα ήταν η τιμή του diff;
Παρατηρήστε ότι στον πίνακα των συγκρίσεων κατά ζεύγη υπάρχει μια στήλη που ονομάζεται p_val στο τέλος. Αυτή είναι η ίδια τιμή \(p\) που έχουμε μάθει: η πιθανότητα να παραχθεί ένα στατιστικό (στην προκειμένη περίπτωση \(b_1\), η διαφορά μέσων όρων) πιο ακραίο από αυτό του δείγματός μας, αν το κενό μοντέλο είναι αληθές.
Σύμφωνα με τη στήλη p_val, ποιες από τις διαφορές μέσων όρων είναι απίθανο να έχουν παραχθεί αν δεν υπήρχε διαφορά στη ΔΠΔ; Υποθέστε ότι ο ορισμός μας για το «απίθανο» είναι μικρότερο από 0.05. (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Όλες — Α και Β, Α και C, Β και C.
Και οι τρεις τιμές \(p\) είναι μικρότερες από 0.05 (0.0001, <0.0001 και 0.0035 αντίστοιχα), άρα και οι τρεις διαφορές μέσων όρων θεωρούνται απίθανες υπό το κενό μοντέλο.
Σύμφωνα με αυτές τις τιμές \(p\), ποιες ομάδες θα συμπεραίναμε ότι διαφέρουν μεταξύ τους στη ΔΠΔ; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Όλες — Α και Β, Α και C, Β και C.
Επειδή και οι τρεις τιμές \(p\) είναι κάτω από 0.05, απορρίπτουμε το κενό μοντέλο για κάθε ζεύγος και συμπεραίνουμε ότι και τα τρία παιχνίδια διαφέρουν σημαντικά μεταξύ τους στη ΔΠΔ.
Σύμφωνα με αυτές τις μεμονωμένες συγκρίσεις κατά ζεύγη, φαίνεται ότι και οι τρεις ομάδες διαφέρουν μεταξύ τους! Αλλά τώρα που κάνουμε 3 «ελέγχους» σημαντικότητας αντί για έναν μόνο συνολικό έλεγχο F του μοντέλου τριών ομάδων, έχουμε δημιουργήσει ένα νέο πρόβλημα: το πρόβλημα των πολλαπλών συγκρίσεων ή των πολλαπλών ελέγχων υποθέσεων.
12.12 Το Πρόβλημα των Πολλαπλών Συγκρίσεων
Το πρόβλημα των πολλαπλών συγκρίσεων ή πολλαπλών ελέγχων είναι το εξής: όταν κάνουμε ένα έλεγχο F, ορίζουμε ένα επίπεδο σημαντικότητας \(\alpha\) για να καθορίσουμε ποιες τιμές του F θα θεωρούνται «απίθανες». Το κριτήριο \(\alpha\) υποδηλώνει την ποσότητα Σφάλματος Τύπου Ι που μπορούμε να ανεχτούμε. Ορίζοντας το \(\alpha = 0.05\), λέμε ότι αν λάβουμε μια τιμή F που έχει πιθανότητα μικρότερη από 0.05 να προέρχεται από το κενό μοντέλο, είμαστε εντάξει να απορρίψουμε το κενό μοντέλο, ακόμα και αν υπάρχει πιθανότητα 0.05 να κάνουμε λάθος.
Αλλά κοιτάξτε αυτή τη γραμμή που εμφανίζεται πάνω από τον πίνακα στα αποτελέσματα της pairwise():
Family-wise error-rate: 0.143Τι σημαίνει αυτό; Ορίσαμε ως αποδεκτή πιθανότητα να διαπράξουμε Σφάλμα Τύπου Ι το 0.05 (5%), αλλά αυτό το αποτέλεσμα μας λέει ότι τελικά έχουμε αποδεχθεί πιθανότητα Σφάλματος Τύπου Ι ίση με 0.14 (14%). Αυτό είναι σχεδόν 3 φορές μεγαλύτερο από το Σφάλμα Τύπου Ι που είχαμε ορίσει εξαρχής.
Ας θυμηθούμε, τι είναι το Σφάλμα Τύπου Ι;
Τι σημαίνει ότι η πιθανότητα Σφάλματος Τύπου Ι είναι 0.14; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Γ και Δ — και οι δύο εκφράζουν την ίδια ιδέα.
Ένα Σφάλμα Τύπου Ι ίσο με 0.14 σημαίνει ότι αν επαναλαμβάναμε αυτή τη μελέτη πολλές φορές σε έναν κόσμο όπου το κενό μοντέλο είναι αληθές, θα απορρίπταμε εσφαλμένα το κενό μοντέλο περίπου στο 14% των φορών — πολύ περισσότερο από το 5% που είχαμε ορίσει ως κριτήριό μας.
Αν ορίσουμε το αποδεκτό Σφάλμα Τύπου Ι στο 0.05 (δηλαδή, ορίσουμε το 5% των λιγότερο πιθανών τιμών F ως «απίθανες») και κάνουμε πολλούς ελέγχους F, θα κάνουμε Σφάλμα Τύπου Ι, κατά μέσο όρο, μία κάθε 20 φορές (δηλ. το 0.05 των φορών), απορρίπτοντας το κενό μοντέλο όταν, στην πραγματικότητα, το κενό μοντέλο είναι αληθές. Από την άλλη πλευρά, αυτό σημαίνει ότι αποφεύγουμε το Σφάλμα Τύπου Ι το 0.95 των φορών.
Αυτό είναι αποδεκτό αν σκοπεύουμε να κάνουμε μόνο έναν έλεγχο F (π.χ. μία σύγκριση δύο ομάδων). Αλλά αν κάνουμε τρεις ελέγχους F ταυτόχρονα (όπως κάνουμε όταν κάνουμε συγκρίσεις τριών ομάδων κατά ζεύγη), θέλουμε να επιτύχουμε πιθανότητα 0.95 αποφυγής Σφάλματος Τύπου Ι και στους τρεις ελέγχους F συνολικά, όχι μόνο στον κάθε έναν ξεχωριστά.
Μπορείτε να το σκεφτείτε αυτό αναλογικά με τη ρίψη ενός νομίσματος. Αν ρίξετε ένα νόμισμα μία φορά, η πιθανότητα να έρθει κορώνα είναι 0.50. Αλλά αν ρίξετε ένα νόμισμα τρεις συνεχόμενες φορές, η πιθανότητα να έρθουν και τα τρία κορώνα είναι πολύ μικρότερη από 0.50. Ομοίως, αν κάνετε έναν έλεγχο F, η πιθανότητα αποφυγής Σφάλματος Τύπου Ι είναι 0.95. Αλλά αν κάνετε τρεις ελέγχους F (π.χ. τρεις συγκρίσεις κατά ζεύγη), η πιθανότητα αποφυγής Σφάλματος Τύπου Ι είναι πολύ μικρότερη από 0.95.
Πόσο μικρότερη είναι από 0.95; Αν η πιθανότητα ένας έλεγχος να μην είναι λανθασμένος είναι 0.95, η πιθανότητα κανένας από τους τρεις ελέγχους να μην είναι λανθασμένος θα ήταν \(0.95^3 = 0.857\). Επομένως, η πιθανότητα οποιοσδήποτε από τους τρεις ελέγχους να είναι λανθασμένος είναι \(1 - 0.857 = 0.143\), που είναι αυτό που το αποτέλεσμα της συνάρτησης pairwise() αναφέρει ως family-wise error rate ή ρυθμό σφάλματος οικογένειας συγκρίσεων. Αυτό σημαίνει ότι η πιθανότητα Σφάλματος Τύπου Ι σε οποιαδήποτε από τις τρεις συγκρίσεις είναι 0.143 (που είναι πολύ υψηλότερη από το 0.05).
Διόρθωση του Ρυθμού Σφάλματος Οικογένειας Συγκρίσεων
Υπάρχουν αρκετοί τρόποι διόρθωσης του προβλήματος των πολλαπλών συγκρίσεων. Ο απλούστερος ονομάζεται διόρθωση κατά Bonferroni, από τον κύριο που την πρότεινε. Αν θέλουμε να διατηρήσουμε πιθανότητα να μην κάνουμε Σφάλμα Τύπου Ι ίση με 0.95 σε καμία από τις συγκρίσεις μας, θα πολλαπλασιάσουμε απλώς την τιμή \(p\) κάθε ελέγχου επί τον αριθμό των συγκρίσεων (σε αυτή την περίπτωση, 3) πριν τη συγκρίνουμε με το κριτήριο \(\alpha\).
Η συνάρτηση pairwise() μπορεί να κάνει αυτή τη διόρθωση με το όρισμα correction = "Bonferroni".
Η διόρθωση κατά Bonferroni είναι απλή, αλλά μερικοί πιστεύουν ότι είναι υπερβολικά συντηρητική — με άλλα λόγια, ότι προσπαθεί υπερβολικά να μας προστατεύσει από το Σφάλμα Τύπου Ι. Η διορθωμένη τιμή \(p\) μπορεί να γίνει πολύ μεγάλη αν ο αριθμός των ταυτόχρονων συγκρίσεων αυξηθεί. Αν και αυτό μειώνει την πιθανότητα Σφάλματος Τύπου Ι, αυξάνει την πιθανότητα Σφάλματος Τύπου ΙΙ, δηλαδή του να μην εντοπίσουμε μια διαφορά όταν αυτή υπάρχει.
Η μέθοδος HSD του Tukey
Ένας άλλος τρόπος διόρθωσης της τιμής \(p\) είναι να χρησιμοποιήσουμε τη μέθοδο HSD (Honestly Significant Difference) του Tukey, ή Tukey’s HSD για συντομία. Αυτή η μέθοδος προσπαθεί να επιτύχει πιο ισορροπημένο συμβιβασμό μεταξύ δύο προτεραιοτήτων: τη μείωση της πιθανότητας Σφάλματος Τύπου Ι χωρίς να αυξάνει υπερβολικά την πιθανότητα Σφάλματος Τύπου ΙΙ.
Η διαδικασία επινοήθηκε από έναν στατιστικό που ονομαζόταν John Tukey. Χωρίς να μπούμε σε λεπτομέρειες (που είναι πιο σύνθετες από τη διόρθωση Bonferroni), αρκεί να πούμε ότι στη μέθοδο Tukey HSD, όπως και στην Bonferroni, οι τιμές \(p\) αναπροσαρμόζονται προς τα πάνω για να διατηρήσουν το σφάλμα σε ένα καθορισμένο επίπεδο (π.χ. 0.05). Συνήθως, όμως, η αναπροσαρμογή δεν είναι τόσο ακραία όσο με τη μέθοδο Bonferroni.
Η συνάρτηση pairwise() που χρησιμοποιήσαμε παραπάνω μπορεί να χρησιμοποιηθεί για να παράγει διορθωμένες τιμές \(p\) βάσει του Tukey’s HSD. Στην πραγματικότητα, επειδή αυτή είναι μια δημοφιλής μέθοδος, οι τιμές \(p\) διορθωμένες με Tukey HSD είναι η προεπιλεγμένη μέθοδος της συνάρτησης:
Θα μπορούσαμε επίσης να προσθέσουμε το όρισμα correction = "Tukey" για να λάβουμε τιμές \(p\) διορθωμένες με τη μέθοδο του Tukey.
Στο παρακάτω πλαίσιο κώδικα, εκτελέστε τη συνάρτηση pairwise() για το game_model δύο φορές, μία χωρίς διόρθωση ("none") και μία με τη διόρθωση Tukey. Συγκρίνετε τα δύο αποτελέσματα και παρατηρήστε τι συμβαίνει στις τιμές \(p\).
── Pairwise t-tests ────────────────────────────────────────────────────────────
Model: outcome ~ game
Levels: 3
Family-wise error-rate: 0.143
group_1 group_2 diff pooled_se t df lower upper p_val
<chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 B A 2.086 0.516 4.041 102 1.229 2.942 .0001
2 C A 3.629 0.516 7.031 102 2.772 4.485 .0000
3 C B 1.543 0.516 2.990 102 0.686 2.400 .0035── Tukey's Honestly Significant Differences ────────────────────────────────────
Model: outcome ~ game
Levels: 3
Family-wise error-rate: 0.05
group_1 group_2 diff pooled_se q df lower upper p_adj
<chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 B A 2.086 0.516 4.041 102 0.350 3.822 .0142
2 C A 3.629 0.516 7.031 102 1.893 5.364 .0000
3 C B 1.543 0.516 2.990 102 -0.193 3.279 .0920Τι παρατηρείτε για τις τιμές \(p\) που εμφανίζονται στα μη διορθωμένα αποτελέσματα σε σχέση τα αποτελέσματα που διορθώθηκαν κατά Tukey HSD;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η διόρθωση κατά Tukey αναπροσαρμόζει τις τιμές \(p\) προς τα πάνω για να ελέγξει το ρυθμό σφάλματος. Για παράδειγμα, για τη σύγκριση Β με C η τιμή \(p\) αλλάζει από 0.0035 (μη διορθωμένη) σε 0.0920 (Tukey) — αρκετά ώστε να μην είναι πλέον στατιστικά σημαντική σε επίπεδο σημαντικότηας \(\alpha = 0.05\).
Εντοπίστε τις τιμές του family-wise error-rate στα δύο αποτελέσματα. Γιατί διαφέρουν;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Χωρίς διόρθωση, το family-wise error-rate αυξάνεται στο 0.143 επειδή κάθε ξεχωριστός έλεγχος (σύγκριση) έχει πιθανότητα Σφάλματος Τύπου Ι ίση με 0.05. Η μέθοδος Tukey’s HSD αναπροσαρμόζει τις τιμές \(p\) ώστε το συνολικό family-wise error-rate να παραμείνει στο 0.05 — δηλαδή να υπάρχει μόνο 5% πιθανότητα να κάνουμε οποιοδήποτε Σφάλμα Τύπου Ι σε όλες τις συγκρίσεις μαζί.
Στις συγκρίσεις Tukey HSD κατά ζεύγη, οι τιμές \(p\) αναπροσαρμόστηκαν προς τα πάνω για να διατηρηθεί το family-wise error-rate στο 0.05.
Ρίξτε μια πιο προσεκτική ματιά στη σύγκριση των παιχνιδιών Β και C στα μη διορθωμένα αποτελέσματα.
group_1 group_2 diff pooled_se t df lower upper p_val
3 C B 1.543 0.516 2.990 102 0.686 2.400 .0035Αυτή η σύγκριση θεωρήθηκε «απίθανο να έχει παραχθεί από το κενό μοντέλο» (δηλ. \(p\) μικρότερη από 0.05). Η μη διορθωμένη σύγκριση θα κατέληγε στο συμπέρασμα ότι τα παιχνίδια Β και C διαφέρουν σημαντικά. Αλλά μετά τη διόρθωση με τη μέθοδο Tukey HSD (που φαίνεται παρακάτω), η τιμή \(p\) δεν είναι πλέον μικρότερη από 0.05. Άρα, τα παιχνίδια Β και C δεν διαφέρουν σημαντικά.
group_1 group_2 diff pooled_se t df lower upper p_val
3 C B 1.543 0.516 2.990 102 -0.193 3.279 .092012.13 Ο Έλεγχος Ανεξαρτησίας \(\chi^2\)
Μέχρι τώρα έχουμε δει μοντέλα στα οποία η εξαρτημένη μεταβλητή είναι ποσοτική. Συγκεκριμένα,όταν η ανεξάρτητη μεταβλητή ήταν ποιοτική (κατηγορική) χρησιμοποιήσαμε τα μοντέλα ομάδων, ενώ όταν η ανεξάρτητη μεταβλητή ήταν ποσοτική χρησιμοποιήσαμε τα μοντέλα παλινδρόμησης. Αλλά και στις δύο περιπτώσεις, η εξαρτημένη μεταβλητή ήταν ποσοτική.
Υπάρχουν, όμως, και άλλα μοντέλα που έχουν αναπτυχθεί για να εφαρμοστούν σε περιπτώσεις που η εξαρτημένη μεταβλητή είναι ποιοτική. Δεν θα καλύψουμε τα περισσότερα από αυτά τα μοντέλα σε αυτό το βιβλίο, αλλά θα σταθούμε για λίγο σε ένα τέτοιο μοντέλο: το μοντέλο που είναι γνωστό ως έλεγχος ανεξαρτησίας \(\chi^2\).
Απολαμβάνουν οι Μαθητές το Ένα Παιχνίδι Περισσότερο από το Άλλο;
Ας επιστρέψουμε στο πλαίσιο δεδομένων game_data. Θυμηθείτε ότι αυτό το σύνολο δεδομένων περιλαμβάνει τις βαθμολογίες σε ένα τεστ 105 μαθητών πέμπτης τάξης που αναθέτηκαν τυχαία να παίξουν ένα από τρία διαφορετικά μαθηματικά παιχνίδια: Α, Β ή C. Στην προηγούμενη ανάλυσή μας διαπιστώσαμε ότι οι μαθητές είχαν καλύτερα αποτελέσματα όταν έπαιξαν το παιχνίδι C σε σχέση με τα άλλα δύο παιχνίδια.
Αλλά πόσο τους άρεσε να παίζουν το κάθε παιχνίδι; Αν οι μαθητές έμαθαν περισσότερα παίζοντας το παιχνίδι C, αλλά δεν τους άρεσε να το παίζουν, μπορεί τελικά να μην είναι ο καλύτερος τύπος παιχνιδιού μακροπρόθεσμα, γιατί μπορεί να χάσουν το ενδιαφέρον τους για το παιχνίδι.
Υπάρχει, λοιπόν, άλλη μια μεταβλητή στο σύνολο δεδομένων που μπορεί να μας βοηθήσει να απαντήσουμε σε αυτό το ερώτημα. Αφού έπαιξε το παιχνίδι, κάθε μαθητής ρωτήθηκε: «Θα ήθελες να ξαναπαίξεις αυτό το παιχνίδι;» Οι μαθητές μπορούσαν να απαντήσουν είτε με ένα «ναι» (yes) είτε με ένα «όχι» (no), και οι απαντήσεις τους αποθηκεύονται στη μεταβλητή play_again. Θα μπορούσαμε να εξετάσουμε την υπόθεση ότι η διακύμανση στον τρόπο με τον οποίο οι μαθητές απάντησαν στην ερώτηση αυτή (μεταβλητή play_again) θα μπορούσε να εξηγηθεί από το παιχνίδι που έπαιξαν (game). Δίνεται εδώ μια λεκτική εξίσωση για αυτή την υπόθεση:
\[\text{play again} = \text{game} + \text{σφάλμα}\]
Δίνεται επίσης παρακάτω ένας πίνακας που δείχνει τις συχνότητες των μαθητών που απάντησαν yes ή no αφού έπαιξαν το κάθε παιχνίδι. Για να πάρουμε τον πίνακα εκτελέσαμε την παρακάτω γραμμή κώδικα:
game
play_again A B C
no 16 11 19
yes 19 24 16Για παράδειγμα, 16 από τους 35 μαθητές που έπαιξαν το παιχνίδι Α απάντησαν ότι δεν θα ήθελαν να το ξαναπαίξουν (no), ενώ 19 μαθητές απάντησαν θετικά (yes). Εξετάζοντας τον πίνακα αναλυτικά, φαίνεται ότι οι ανησυχίες μας μπορεί, στην πραγματικότητα, να επιβεβαιωθούν: Αν και οι μαθητές έχουν καλύτερα αποτελέσματα αν παίξουν το παιχνίδι C, αυτό είναι το μόνο από τα τρία παιχνίδια μετά από το οποίο η πλειοψηφία των μαθητών (19 από τους 35) απάντησε «Όχι», στο αν θα ήθελαν να το ξαναπαίξουν.
Αναμενόμενες Συχνότητες Υπό το Κενό Μοντέλο
Φυσικά, οι διαφορές που βλέπουμε στον πίνακα μεταξύ των παιχνιδιών ως προς το αν οι μαθητές θέλουν να τα ξαναπαίξουν θα μπορούσαν να είναι απλώς αποτέλεσμα δειγματοληπτικής διακύμανσης. Όπως και πριν, θέλουμε να ορίσουμε το κενό (ή μηδενικό) μοντέλο, και στη συνέχεια να δούμε αν, μόνο με τυχαιότητα, θα μπορούσαμε να έχουμε λάβει παρόμοια αποτελέσματα με αυτά που λάβαμε.
Για να ορίσουμε το κενό μοντέλο, πρέπει να σκεφτούμε πώς θα έμοιαζε αυτός ο πίνακας συνάφειας αν δεν υπήρχε σχέση μεταξύ των μεταβλητών play_again και game. Ακριβώς όπως το κενό μοντέλο μιας διαφοράς μέσων όρων μεταξύ δύο ομάδων θα σήμαινε διαφορά ίση με 0, το κενό μοντέλο για δύο μη συσχετισμένες ποιοτικές μεταβλητές θα προέβλεπε ότι οι αναλογίες γραμμών και στηλών θα ήταν ίδιες σε όλα τα κελιά του πίνακα.
Δίνεται εδώ ξανά ο πίνακας συνάφειάς μας, αυτή τη φορά με τα σύνολα γραμμών και στηλών:
play_again A B C Total
no 16 11 19 46
yes 19 24 16 59
Total 35 35 35 105Ποιος από τους παρακάτω υπολογισμούς θα μας έδειχνε τη συνολική αναλογία των απαντήσεων no στο δείγμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — 46/105.
Το 46 είναι ο συνολικός αριθμός μαθητών που απάντησαν no (ανεξάρτητα από παιχνίδι), και το 105 είναι ο συνολικός αριθμός μαθητών. Άρα 46/105 ≈ 0.438 είναι η συνολική αναλογία no. Οι άλλες επιλογές υπολογίζουν την αναλογία no μόνο για μία συγκεκριμένη ομάδα παιχνιδιού.
Αν το παιχνίδι που έπαιξε κάποιος δεν έχει καμία επίδραση στο αν θέλει να παίξει ξανά, θα αναμέναμε ότι το 0.438 των μαθητών θα απαντούσε no και εντός του κάθε παιχνιδιού.
Επειδή το παιχνίδι Α παίχτηκε από 35 μαθητές, το 0.438 του 35 είναι 15.33 μαθητές. Αυτός είναι ο αναμενόμενος αριθμός μαθητών που έπαιξαν το παιχνίδι Α και θα είχαν απαντήσει no αν το παιχνίδι που έπαιξαν δεν είχε καμία επίδραση στην απάντησή τους.
Αυτή η προσέγγιση για τον υπολογισμό των αναμενόμενων συχνοτήτων για κάθε κελί υπό το κενό μοντέλο (χωρίς επίδραση της game) μπορεί να συνοψιστεί με αυτόν τον τύπο:
\[\text{Αναμενόμενη Συχνότητα σε Κελί} = \frac{\text{Σύνολο Γραμμής}}{\text{Συνολικός Αριθμός Παρατηρήσεων}} \times \text{Σύνολο Στήλης}\]
Μπορούμε να εκφράσουμε τον ίδιο τύπο ως εξής:
\[\text{Αναμενόμενη Συχνότητα σε Κελί} = \frac{\text{Σύνολο Γραμμής} \times \text{Σύνολο Στήλης}}{\text{Συνολικός Αριθμός Παρατηρήσεων}}\]
Μπορούμε τώρα να συμπληρώσουμε τον πλήρη πίνακα αναμενόμενων συχνοτήτων:
| play_again | Παρατ. Α | Παρατ. Β | Παρατ. Γ | Παρατ. Σύνολο | Αναμ. Α | Αναμ. Β | Αναμ. Γ | Αναμ. Σύνολο |
|---|---|---|---|---|---|---|---|---|
| no | 16 | 11 | 19 | 46 | 15.33 | 15.33 | 15.33 | 46 |
| yes | 19 | 24 | 16 | 59 | 19.67 | 19.67 | 19.67 | 59 |
| Σύνολο | 35 | 35 | 35 | 105 | 35 | 35 | 35 | 105 |
Στον πίνακα, το «Παρατ.» είναι συντομογραφία για «Παρατηρούμενη» συχνότητα και το «Αναμ.» για «Αναμενόμενη».
Γιατί οι αναμενόμενες συχνότητες για όσους απάντησαν no είναι ίδιες για τα παιχνίδια Α, Β και C;
ΣημείωσηΕπεξήγηση
Επειδή υπό το κενό μοντέλο υποθέτουμε ότι το παιχνίδι δεν έχει καμία επίδραση στο αν κάποιος θέλει να το ξαναπαίξει. Άρα η αναλογία των no (46/105 = 0.438) εφαρμόζεται ομοιόμορφα σε κάθε ομάδα παιχνιδιού, και επειδή κάθε ομάδα έχει τον ίδιο αριθμό μαθητών (35), οι αναμενόμενες συχνότητες είναι ίδιες.
Υπάρχουν μερικά πράγματα που αξίζει να παρατηρήσουμε σε αυτούς τους πίνακες παρατηρούμενων και αναμενόμενων συχνοτήτων. Πρώτον, τα σύνολα για κάθε γραμμή και στήλη είναι ίδια και στους δύο πίνακες. Η πραγματική έναντι της αναμενόμενης συχνότητας μαθητών σε κάθε ομάδα παιχνιδιού είναι η ίδια. Η πραγματική έναντι της αναμενόμενης συχνότητας μαθητών που απάντησαν no είναι επίσης η ίδια.
Αυτό που είναι διαφορετικό, όμως, είναι ότι δεν υπάρχει πλέον καμία σχέση μεταξύ των δύο μεταβλητών. Ανεξάρτητα από το παιχνίδι που έπαιξαν οι μαθητές, αν το κενό μοντέλο είναι αληθές, 15.33 περίπου από αυτούς θα αναμένονταν να απαντήσουν no και 19.67 yes.
Το Στατιστικό \(\chi^2\)
Το στατιστικό \(\chi^2\) (χι-τετράγωνο) είναι ένα στατιστικό δείγματος σχεδιασμένο να δείχνει πόσο αποκλίνει η παρατηρούμενη κατανομή των συχνοτήτων από την αναμενόμενη κατανομή, αν δεχτούμε ότι ισχύει το κενό μοντέλο. Είναι ένα μέτρο σφάλματος, και αν το εξετάσετε προσεκτικά θα διαπιστώσετε ότι είναι κάτι παρόμοιο με το άθροισμα τετραγώνων των σφαλμάτων. Αυτή τη φορά, ωστόσο, οι τιμές πρόβλεψης δεν αφορούν μεμονωμένες παρατηρήσεις (π.χ. μαθητές) αλλά τις συχνότητες των κελιών του πίνακα.
\[\chi^2 = \sum \frac{(\text{Παρατηρούμενη} - \text{Αναμενόμενη})^2}{\text{Αναμενόμενη}}\]
Αν ξεκινήσουμε από το πρώτο κελί (παιχνίδι Α, no) βλέπουμε ότι η παρατηρούμενη συχνότητα είναι 16. Η αναμενόμενη συχνότητα, υποθέτοντας ότι το κενό μοντέλο ισχύει στη ΔΠΔ, είναι 15.33. Το 16 μείον το 15.33 δίνει 0.67, και το 0.67 στο τετράγωνο είναι 0.4489. Αν προσθέσουμε αυτές τις τετραγωνικές διαφορές για όλα τα 6 κελιά του πίνακα θα λάβουμε την τιμή του στατιστικού \(\chi^2\).
Αν οι παρατηρούμενες συχνότητες ήταν ακριβώς ίδιες με τις αναμενόμενες, ποια θα ήταν η τιμή του στατιστικού \(\chi^2\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — 0.
Αν οι παρατηρούμενες συχνότητες ήταν ακριβώς ίσες με τις αναμενόμενες, κάθε διαφορά (Παρατηρούμενη − Αναμενόμενη) θα ήταν 0, άρα και το άθροισμα των τετραγώνων τους θα ήταν 0. Η τιμή \(\chi^2 = 0\) σημαίνει τέλεια συμφωνία με το κενό μοντέλο.
Η Δειγματοληπτική Κατανομή του Στατιστικού \(\chi^2\)
Το \(\chi^2\) είναι ένα στατιστικό δείγματος, και όπως άλλα στατιστικά δείγματος, θα έχει μια δειγματοληπτική κατανομή. Η δειγματοληπτική κατανομή του \(\chi^2\) έχει σχήμα παρόμοιο με τη δειγματοληπτική κατανομή του F, και όπως η δειγματοληπτική κατανομή του F, το σχήμα της εξαρτάται από τους βαθμούς ελευθερίας, που υπολογίζονται με βάση το αριθμό στηλών και γραμμών στον πίνακα.
Ο πίνακας που εξετάζαμε τυχαίνει να έχει 2 βαθμούς ελευθερίας (το γιατί δεν θα το εξετάσουμε εδώ). Η μαθηματική κατανομή \(\chi^2\) για 2 βαθμούς ελευθερίας μοιάζει ως εξής:

Αυτή η κατανομή \(\chi^2\) είναι μια κατανομή πιθανότητας. Καθώς η τιμή του \(\chi^2\) μεγαλώνει, η πιθανότητα να έχει παραχθεί από το κενό μοντέλο θα μικραίνει.
Υπολογισμός του \(\chi^2\) και της Τιμής \(p\) στην R
Για να υπολογίσουμε το στατιστικό \(\chi^2\) στην R μπορούμε να χρησιμοποιήσουμε τη συνάρτηση xchisq.test(). Ας τη δοκιμάσουμε για το συγκεκριμένο παράδειγμα.
Η εκτέλεση αυτού του κώδικα παράγει το παρακάτω αποτέλεσμα:
Pearson's Chi-squared test
data: x
X-squared = 3.7915, df = 2, p-value = 0.1502
16 11 19
(15.33) (15.33) (15.33)
[0.029] [1.225] [0.877]
< 0.17> <-1.11> < 0.94>
19 24 16
(19.67) (19.67) (19.67)
[0.023] [0.955] [0.684]
<-0.15> < 0.98> <-0.83>
key:
observed
(expected)
[contribution to X-squared]
<Pearson residual>Το στατιστικό \(\chi^2\) για τον πίνακα συνάφειας play_again ανά game είναι ίσο με 3.7915. Η τιμή \(p\) είναι 0.1502. Ποια από τις παρακάτω είναι η σωστή ερμηνεία της τιμής \(p\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η τιμή \(p = 0.15\) σημαίνει ότι, αν το κενό μοντέλο είναι αληθές (δηλ. δεν υπάρχει σχέση μεταξύ game και play_again στη ΔΠΔ), θα παρατηρούσαμε μια τιμή \(\chi^2\) τόσο μεγάλη ή μεγαλύτερη από 3.79 περίπου το 15% των φορών τυχαία.
Εδώ δεν θα απορρίψουμε το κενό μοντέλο (ότι δεν υπάρχει επίδραση του παιχνιδιού) επειδή υπάρχει πιθανότητα 0.15 (15%) να παρατηρήσουμε έναν πίνακα συνάφειας όπως αυτόν που παρατηρήσαμε στο δείγμα μας ακόμη κι αν δεν υπήρχε καμία επίδραση στη ΔΠΔ.
12.14 Ασκήσεις Επανάληψης Κεφαλαίου 12
Το παρακάτω πλαίσιο δεδομένων ονομάζεται collegegrads. Αυτά τα δεδομένα χρησιμοποιήθηκαν για τη συγγραφή ενός επιστημονικού άρθρου σχετικά με τις μελλοντικές οικονομικές απολαβές αποφοίτων διαφορετικών ειδικοτήτων στις ΗΠΑ.
Περιλαμβάνει 173 γραμμές που αντιπροσωπεύουν διαφορετικές ειδικότητες (πτυχία):
-
major— Περιγραφή πτυχίου (ειδικότητας) -
major_category— Κατηγορία πτυχίου -
engineering— TRUE/FALSE, είναι αυτό πτυχίου μηχανικού; -
STEM— TRUE/FALSE, είναι αυτό πτυχίο STEM (επιστήμη, τεχνολογία, μηχανική, μαθηματικά); -
totalgrads— Συνολικός αριθμός ατόμων με αυτό το πτυχίο σε χιλιάδες -
employed_fulltime— Απασχολούμενοι 35 ώρες ή περισσότερο -
unemployment_rate— Άνεργοι / (Άνεργοι + Απασχολούμενοι) -
p25th_income— 25ο εκατοστημόριο αποδοχών σε χιλιάδες δολάρια (ετήσιος μισθός) -
median_income— Διάμεσες αποδοχές πλήρους απασχόλησης, εργαζομένων όλο το χρόνο σε χιλιάδες δολάρια (ετήσιος μισθός) -
p75th_income— 75ο εκατοστημόριο αποδοχών σε χιλιάδες δολάρια (ετήσιος μισθός)
1. Ποια είναι η μονάδα παρατήρησης στο πλαίσιο δεδομένων collegegrads; (Δηλαδή, τι αντιπροσωπεύουν οι γραμμές;)
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — Πανεπιστημιακά πτυχία (ειδικότητες).
Κάθε γραμμή του πίνακα δεδομένων αντιπροσωπεύει ένα διαφορετικό πτυχίο (π.χ. Μηχανικού, Βιολόγου, Οικονομολόγου), όχι μεμονωμένους αποφοίτους ή φοιτητές.
2. Ένας ερευνητής αναρωτιέται αν οι ειδικότητες STEM έχουν υψηλότερο διάμεσο εισόδημα από τις μη-STEM ειδικότητες. Ποια λεκτική εξίσωση αντιπροσωπεύει καλύτερα αυτή τη σχέση;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — median_income = STEM + other stuff.
Η εξαρτημένη μεταβλητή (αυτή που θέλουμε να προβλέψουμε) είναι το median_income (διάμεσος εισοδήματος), και η ανεξάρτητη μεταβλητή είναι το STEM (TRUE/FALSE ανάλογα με το αν η ειδικότητα είναι STEM ή όχι). Το Γ είναι λάθος γιατί χρησιμοποιεί τη μεταβλητή της ειδικότητας (major) αντί για τη μεταβλητή STEM.
3. Τι μπορείτε να συμπεράνετε από το παραπάνω διάγραμμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Από το διαιρεμένο ιστόγραμμα φαίνεται ότι το πάνελ FALSE (μη-STEM ειδικότητες) έχει πολύ περισσότερες ειδικότητες (υψηλότερες συχνότητες) από το πάνελ TRUE (STEM ειδικότητες). Το Α είναι λάθος γιατί τα δεδομένα αφορούν ειδικότητες, όχι μεμονωμένα άτομα. Το Β είναι λάθος — οι STEM ειδικότητες φαίνονται πιο διεσπαρμένες. Το Δ είναι λάθος γιατί υπάρχει επικάλυψη μεταξύ των δύο κατανομών, οπότε δεν ισχύει αυτό για όλες τις ειδικότητες.
4. Τι σημαίνει να «προσαρμόσουμε» ένα μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η «προσαρμογή» ενός μοντέλου σημαίνει την εύρεση των τιμών των παραμέτρων (π.χ. \(b_0\), \(b_1\)) που ελαχιστοποιούν το άθροισμα τετραγώνων των σφαλμάτων (SS Error) — δηλαδή φέρνουν τις προβλέψεις του μοντέλου όσο το δυνατόν πιο κοντά στις πραγματικές τιμές των δεδομένων.
5. Γράψτε κώδικα για να προσαρμόσετε το παρακάτω μοντέλο: median_income = STEM + other stuff. Ποια είναι η πρόβλεψη του μοντέλου για τις διάμεσες αποδοχές των μη-STEM ειδικοτήτων;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — 35.62.
Το \(b_0\) (σταθερός όρος) είναι η πρόβλεψη για την ομάδα αναφοράς, που είναι οι μη-STEM ειδικότητες (STEM = FALSE). Άρα η τιμή πρόβλεψης για την ομάδα μη-STEM είναι 35.62 χιλιάδες δολάρια.
6. Ποια είναι η πρόβλεψη του μοντέλου (median_income = STEM + other stuff) για τις διάμεσες αποδοχές των STEM ειδικοτήτων;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — 35.62 + 12.24 = 47.86 χιλιάδες δολάρια.
Για τις STEM ειδικότητες (STEM = TRUE), η τιμή πρόβλεψης είναι \(b_0 + b_1 = 35.62 + 12.24 = 47.86\). Το \(b_1\) = 12.24 είναι η διαφορά μεταξύ των μέσων όρων των STEM και μη-STEM ειδικοτήτων.
7. Με βάση το \(b_1\) = 12.24 του μοντέλου, τι γνωρίζετε για το PRE;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Αφού \(b_1 \neq 0\), το σύνθετο μοντέλο εξηγεί κάποια διακύμανση επιπλέον σε σύγκριση με το κενό μοντέλο, άρα το PRE του δείγματος δεν θα είναι ίσο με 0. Ωστόσο, δεν μπορούμε να γνωρίζουμε τι ισχύει στη ΔΠΔ (Β) — μόνο ότι στο δείγμα εξηγείται κάποια διακύμανση .
8. Με βάση τις εκτιμήσεις των παραμέτρων του μοντέλου, τι μπορείτε να πείτε για τη σχέση μεταξύ του διάμεσου εισοδήματος και των STEM/μη-STEM ειδικοτήτων στη ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Οι εκτιμήσεις παραμέτρων (\(b_0\), \(b_1\)) είναι στατιστικά δείγματος — περιγράφουν τα δεδομένα μας, όχι τη ΔΠΔ. Για να συμπεράνουμε κάτι για τη ΔΠΔ χρειαζόμαστε την τιμή \(p\) ή ένα διάστημα εμπιστοσύνης (βλ. επόμενο Κεφάλαιο) που να λαμβάνει υπόψη τη δειγματοληπτική διακύμανση.
9. Γράψτε κώδικα για να παράγετε έναν πίνακα ANOVA για το μοντέλο median_income = STEM + other stuff. Τι σημαίνει το PRE = 0.2668;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η τιμή PRE = 0.2668 σημαίνει ότι το μοντέλο της STEM εξηγεί περίπου το 26.68% της συνολικής διακύμανσης στην median_income — δηλαδή το 26.68% του SS Total μειώνεται όταν προσθέτουμε τη μεταβλητή STEM στο μοντέλο.
10. Τι ισχύει για τα στατιστικά δείγματος \(F\), \(PRE\) και \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Και τα τρία (\(F\), \(PRE\), \(b_1\)) είναι στατιστικά δείγματος που μεταβάλλονται από δείγμα σε δείγμα, άρα το καθένα έχει τη δική του δειγματοληπτική κατανομή. Το Α είναι λάθος γιατί η αναμενόμενη τιμή του \(F\) υπό το κενό μοντέλο είναι 1 (όχι 0). Το Γ είναι λάθος γιατί το \(b_1\) δεν μπορεί να χρησιμοποιηθεί για την αξιολόγηση μοντέλων τριών ή περισσότερων ομάδων. Το Δ είναι λάθος γιατί το \(F\) και το \(PRE\) μοντελοποιούνται με την κατανομή F, όχι την \(t\).
11. Δίνεται ο παρακάτω κώδικας για να υπολογίσουμε μια μεμονωμένη τιμή του στατιστικού F μετά από τυχαιοποίηση (και αποδυνάμωση της σχέσης μεταξύ median_income και STEM):
Ποιο μοντέλο του πραγματικού κόσμου προσομοιώνουμε όταν ανακατεύουμε τα δεδομένα με αυτόν τον τρόπο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η shuffle() τυχαιοποιεί τις τιμές της median_income ανεξάρτητα από την STEM, προσομοιώνοντας έτσι έναν κόσμο όπου το κενό μοντέλο είναι αληθές — δηλαδή δεν υπάρχει καμία σχέση μεταξύ τύπου ειδικότητας και αποδοχών στη ΔΠΔ (\(\beta_1 = 0\)).
12. Πώς θα αναπαριστούσατε το μοντέλο median_income = STEM + other stuff σε σημειογραφία GLM;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — \(Y_i = \beta_0 + \beta_1 X_i + e_i\).
Το STEM είναι μια δυαδική ανεξάρτητη μεταβλητή (TRUE/FALSE), άρα χρειαζόμαστε μία μόνο παράμετρο \(\beta_1\) πέρα από τον σταθερό όρο. Το Α είναι το κενό μοντέλο, το Γ χρησιμοποιείται για τρεις ή περισσότερες ομάδες, και το Δ δεν έχει σταθερό όρο (\(b_0\)).
13. Αυτός ο κώδικας δημιουργεί μια δειγματοληπτική κατανομή των τυχαιοποιημένων τιμών F:
Εξετάστε τον παρακάτω πίνακα ANOVA για το μοντέλο median_income = STEM + other stuff. Πώς θα ερμηνεύατε την τιμή F = 62.223 του δείγματος βάσει της τυχαιοποημένης δειγματοληπτικής κατανομής;
Analysis of Variance Table (Type III SS)
Model: median_income ~ STEM
SS df MS F PRE p
----- --------------- | --------- --- -------- ------ ----- -----
Model (error reduced) | 6037.417 1 6037.417 62.223 .2668 .0000
Error (from model) | 16591.775 171 97.028
----- --------------- | --------- --- -------- ------ ----- -----
Total (empty model) | 22629.192 172 131.565
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — Και τα δύο παραπάνω.
Το F = 62.223 είναι εξαιρετικά μεγάλο σε σχέση με τις τιμές F που παράγονται από τυχαιοποίηση (που κυμαίνονται συνήθως κοντά στο 0-5), άρα βρίσκεται πολύ μακριά από όλες τις τιμές της δειγματοληπτικής κατανομής (Α). Επιπλέον, η τιμή \(p < 0.0001\) επιβεβαιώνει ότι είναι εξαιρετικά απίθανο να έχει παραχθεί από το κενό μοντέλο (Β).
14. Αν χρησιμοποιούσαμε τη συνάρτηση xpf() για να δημιουργήσουμε μια δειγματοληπτική κατανομή του F για να αξιολογήσουμε το μοντέλο, τι θα περιμένατε να δείτε; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Γ.
Η xpf() χρησιμοποιεί τη μαθηματική κατανομή F (όχι τυχαιοποίηση), άρα παράγει μια εξομαλυμένη θεωρητική καμπύλη αντί για ιστόγραμμα (Β). Επειδή η τιμή F = 62.223 είναι εξαιρετικά μεγάλο, η τιμή \(p\) θα είναι πολύ μικρή — δηλαδή πολύ χαμηλή πιθανότητα να παρατηρήσουμε τέτοια τιμή F υπό το κενό μοντέλο (Γ). Το Α είναι λάθος γιατί η μαθηματική κατανομή δεν είναι ταυτόσημη με τη δειγματοληπτική που παίρνουμε από την shuffle(), αλλά πολύ παρόμοια.
15. Με βάση τον παρακάτω πίνακα ANOVA, ποιο είδος σφάλματος διακινδυνεύουμε να κάνουμε;
Analysis of Variance Table (Type III SS)
Model: median_income ~ STEM
SS df MS F PRE p
----- --------------- | --------- --- -------- ------ ----- -----
Model (error reduced) | 6037.417 1 6037.417 62.223 .2668 .0000
Error (from model) | 16591.775 171 97.028
----- --------------- | --------- --- -------- ------ ----- -----
Total (empty model) | 22629.192 172 131.565
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Σφάλμα Τύπου Ι.
Επειδή η τιμή \(p < 0.0001 < 0.05\), απορρίπτουμε το κενό μοντέλο. Κάθε φορά που απορρίπτουμε το κενό μοντέλο, διακινδυνεύουμε να κάνουμε Σφάλμα Τύπου Ι — την πιθανότητα να απορρίψαμε εσφαλμένα ένα κενό μοντέλο που είναι στην πραγματικότητα αληθές. Το Σφάλμα Τύπου ΙΙ μπορεί να συμβεί μόνο όταν δεν απορρίπτουμε το κενό μοντέλο.
Το κοινό λατρεύει τις ταινίες στις οποίες η γη καταστρέφεται και ένας ήρωας τελικά σώζει τον κόσμο. Αλλά πόσο φοβούνται πραγματικά οι άνθρωποι τις φυσικές καταστροφές;
Το 2015, όταν κυκλοφόρησε η ταινία San Andreas, που αναφέρεται σε μια υποθετική μεγάλη καταστροφή από σεισμό, μια ιστοσελίδα έτρεξε μια δημοσκόπηση σχετικά με τους φόβους των συμμετεχόντων, την εμπειρία τους και τις γνώσεις τους για τους σεισμούς.
Το πλαίσιο δεδομένων san_andreas αποτελείται από 978 απαντημένα ερωτηματολόγια στις παρακάτω ερωτήσεις-μεταβλητές:
-
worry_general— Γενικά, πόσο ανησυχείτε για τους σεισμούς; (μετρημένο σε κλίμακα 5 βαθμίδων από 1 έως 5, με το 5 να σημαίνει μεγαλύτερη ανησυχία) -
worry_bigone— Πόσο ανησυχείτε για έναν τεράστιο, καταστροφικό σεισμό; (κλίμακα 5 βαθμίδων από 1 έως 5, με το 5 να σημαίνει περισσότερη ανησυχία) -
will_occur— Πιστεύετε ότι ένας τέραστιος σεισμός θα συμβεί στη διάρκεια της ζωής σας; (true = ναι, false = όχι) -
experience— Έχετε βιώσει ποτέ σεισμό; (όχι· ναι, μικρούς· ναι, μεγάλους) -
prepared— Έχετε εσείς ή κάποιος στο νοικοκυριό σας λάβει προφυλάξεις για σεισμό (συσκευάσει κιτ επιβίωσης σεισμού, ετοιμάσει σχέδιο εκκένωσης κ.λπ.); (true = ναι, false = όχι) -
fam_san_andreas— Τι γνωρίζετε για το ρήγμα San Andreas; (κλίμακα 5 βαθμίδων από “τίποτα” έως “πάρα πολλά”) -
fam_yellowstone— Τι γνωρίζετε για το Υπερηφαίστειο Yellowstone; (κλίμακα 5 βαθμίδων από “τίποτα” έως “πάρα πολλά”) -
female— Φύλο (true = γυναίκα· false = άνδρας) -
region— Περιοχή ΗΠΑ (περιοχή των Ηνωμένων Πολιτειών στην οποία ζει ο συμμετέχων) -
age— Ηλικία (σε έτη) -
income— Συνολικό οικογενειακό εισόδημα (σε χιλιάδες δολάρια)
1. Μια ερευνήτρια ενδιαφέρεται να εξετάσει τα επίπεδα ανησυχίας των συμμετεχόντων στην παραπάνω έρευνα σχετικά με την πιθανότητα ενός μεγάλου καταστροφικού σεισμού. Η ερευνήτρια κατασκεύασε αρχικά το παρακάτω ιστόγραμμα:
Με βάση το παραπάνω ιστόγραμμα, ποια από τις παρακάτω δηλώσεις είναι αληθής;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Από το ιστόγραμμα φαίνεται ότι οι περισσότεροι συμμετέχοντες είχαν χαμηλές τιμές (1 και 2) στην κλίμακα ανησυχίας, που αντιστοιχούν σε χαμηλά επίπεδα. Μόνο μια μικρή μειοψηφία σημείωσε τιμές 4 ή 5.
2. Η ερευνήτρια υποθέτει ότι οι συμμετέχοντες που ανησυχούν περισσότερο για το ενδεχόμενο να συμβεί ένας τεράστιος καταστροφικός σεισμός θα πιστεύουν ότι αυτός θα συμβεί στη διάρκεια της ζωής τους. Για να εξετάσει αυτήν την υπόθεση κατασκεύασε ένα διαιρεμένο ιστόγραμμα με τον παρακάτω κώδικα:
Τι δείχνει το ιστόγραμμα για τη σχέση μεταξύ των δύο μεταβλητών; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Β.
Από τα ιστογράμματα φαίνεται ότι το πάνελ FALSE (δεν πιστεύουν) έχει υψηλότερες συχνότητες συνολικά (Α). Δηλαδή, αυτοί που δεν πιστεόυν ότι ένας μεγάλος, καταστροφικός σεισμός θα συμβεί στη διάρκεια της ζωής τους είναι περισσότεροι από αυτούς που πιστεύουν ότι θα συμβεί. Επίσης, η κατανομή του πάνελ TRUE (πιστεύουν) είναι πιο επίπεδη και έχει περισσότερες τιμές από το πάνελ FALSE στα υψηλά επίπεδα ανησυχίας (4 και 5), υποδηλώνοντας ότι αυτή η ομάδα ανησυχεί γενικά περισσότερο ότι ο καταστροφικός σεισμός θα συμβεί κατά τη διάρκεια της ζωής τους (Β).
3. Ας προσαρμόσουμε ένα μοντέλο σε αυτά τα δεδομένα. Εκτελέστε τον παρακάτω κώδικα για να βρείτε τις εκτιμήσεις παραμέτρων για το μοντέλο στο οποίο η μεταβλητή will_occur εξηγεί τη διακύμανση στη μεταβλητή worry_bigone.
Ποια είναι η σωστή ερμηνεία του σταθερού όρου (1.86) στο occur_model;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Ο σταθερός όρος (\(b_0\)) αντιπροσωπεύει την τιμή πρόβλεψης του μοντέλου για την ομάδα αναφοράς. Στη R, για δυαδικές μεταβλητές TRUE/FALSE, η ομάδα αναφοράς είναι συνήθως το FALSE — δηλαδή οι συμμετέχοντες που δεν πιστεύουν ότι ένας μεγάλος, καταστροφικός σεισμός θα συμβεί στη διάρκεια της ζωής τους.
4. Ο παρακάτω κώδικας και το διάγραμμα που δημιουργείται δείχνουν τη σχέση μεταξύ της πεποίθησης των συμμετεχόντων για εμφάνιση ενός μεγάλου, καταστροφικού σεισμού στη διάρκεια της ζωής τους και του πόσο ανησυχούν για τέτοιο σεισμό.
Πώς θα αναπαριστούσατε την τιμή πρόβλεψης του κενού μοντέλου στα παραπάνω boxplot;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το κενό μοντέλο προβλέπει την ίδια τιμή για όλες τις παρατηρήσεις ανεξάρτητα από την ομάδα — δηλαδή τον γενικό μέσο της worry_bigone. Αυτό μπορεί να αναπαρταθεί ως μία οριζόντια γραμμή στον γενικό μέσο όρο, η οποία διατρέχει και τα δύο boxplots.
5. Παρακάτω δίνεται ο πίνακας ANOVA για το occur_model.
Analysis of Variance Table (Type III SS)
Model: worry_bigone ~ will_occur
SS df MS F PRE p
----- --------------- | -------- --- ------- ------- ----- -----
Model (error reduced) | 162.550 1 162.550 135.788 .1221 .0000
Error (from model) | 1168.357 976 1.197
----- --------------- | -------- --- ------- ------- ----- -----
Total (empty model) | 1330.908 977 1.362Αν επαναλαμβάναμε αυτή τη μελέτη με διαφορετικό δείγμα συμμετεχόντων, ποιο από αυτά τα στατιστικά ΔΕΝ θα άλλαζε;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — οι βαθμοί ελευθερίας (df).
Οι βαθμοί ελευθερίας εξαρτώνται από τον αριθμό των παρατηρήσεων (\(n\)) και τον αριθμό των παραμέτρων του μοντέλου — όχι από τις συγκεκριμένες τιμές των δεδομένων. Αν χρησιμοποιήσουμε το ίδιο μέγεθος δείγματος και το ίδιο μοντέλο, οι df θα παραμείνουν ίδιοι. Αντίθετα, το \(F\), το SS Total και το PRE θα μεταβάλλονται με κάθε νέο δείγμα λόγω δειγματοληπτικής διακύμανσης.
6. Με βάση τον πίνακα ANOVA για το occur_model, τι θα συμπεραίνατε; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Β και Δ.
Η τιμή \(p < 0.0001 < 0.05\), άρα απορρίπτουμε το κενό μοντέλο (Α) και η τιμή F = 135.788 είναι εξαιρετικά απίθανο να έχει παραχθεί τυχαία (Β). Το PRE = 0.1221 σημαίνει ότι περίπου το 12% της διακύμανσης στην worry_bigone εξηγείται από την will_occur (Δ). Το Γ είναι λάθος — αφού απορρίπτουμε το κενό μοντέλο, το \(b_1\) δεν θεωρείται πιθανό να έχει παραχθεί από αυτό.
7. Ο παρακάτω κώδικας υπολογίζει το PRE για το occur_model:
Πώς θα μπορούσαμε να τροποποιήσουμε τον κώδικα για να βρούμε μια τιμή PRE που παράγεται υπό την υπόθεση ότι δεν υπάρχει σχέση μεταξύ worry_bigone και will_occur στη ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Η shuffle(worry_bigone) τυχαιοποιεί τις τιμές της εξαρτημένης μεταβλητής, διαλύοντας οποιαδήποτε πραγματική σχέση με την will_occur. Αυτό προσομοιώνει έναν κόσμο στον οποίο το κενό μοντέλο είναι αληθές.
8. Αν δεν υπήρχε καμία σχέση μεταξύ worry_bigone και will_occur στη ΔΠΔ, ποια θα ήταν η πραγματική τιμή του \(\beta_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Αν το κενό μοντέλο είναι αληθές (\(\beta_1 = 0\)), οι δύο ομάδες έχουν τον ίδιο πληθυσμιακό μέσο όρο, άρα δεν υπάρχει διαφορά μεταξύ τους.
9. Αν η τιμή PRE στη ΔΠΔ ήταν ίση με 0, ποια θα ήταν η τιμή του \(\beta_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — 0.
Αν PRE = 0, το σύνθετο μοντέλο δεν εξηγεί καθόλου επιπλέον διακύμανση σε σχέση με το κενό μοντέλο, που σημαίνει ότι \(b_1 = 0\) και άρα \(\beta_1 = 0\).
10. Ο παρακάτω κώδικας παράγει μια δειγματοληπτική κατανομή PRE και την αποθηκεύει ως sdoPRE.
Γιατί η κατανομή έχει κορυφή γύρω στο 0;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η shuffle() τυχαιοποιεί τη σχέση μεταξύ will_occur και worry_bigone, προσομοιώνοντας έναν κόσμο όπου \(\beta_1 = 0\). Υπό αυτή την υπόθεση, τα παραγόμενα PRE αναμένεται να είναι κοντά στο 0 — γιατί η ανεξάρτητη μεταβλητή δεν εξηγεί κανένα μέρος της διακύμανσης της εξαρτημένης μεταβλητής, παρά μόνο τυχαίο θόρυβο.
11. Τι είδους τιμές αποτελούν την κατανομή sdoPRE;
12. Η τιμή PRE του occur_model είναι 0.1221. Πώς ερμηνεύετε την τιμή αυτή σε σχέση με τη δειγματοληπτική κατανομή, sdoPRE;
ΣημείωσηΕπεξήγηση
Η τιμή PRE = 0.1221 είναι πολύ μεγαλύτερη από όλες τις τιμές PRE στη δειγματοληπτική κατανομή sdoPRE (που κυμαίνονται γύρω στο 0). Άρα είναι εξαιρετικά απίθανο να έχει παραχθεί τυχαία από το κενό μοντέλο.
13. Αν χρησιμοποιούσαμε τη συνάρτηση shuffle() για να δημιουργήσουμε μια δειγματοληπτική κατανομή του \(b_1\) για να αξιολογήσουμε το occur_model, πώς θα διέφερε αυτή από τη δειγματοληπτική κατανομή του PRE;
ΣημείωσηΕπεξήγηση
Η δειγματοληπτική κατανομή του \(b_1\) είναι συμμετρική και κανονικόμορφη (μοντελοποιείται από την κατανομή \(t\)), ενώ η κατανομή του PRE είναι ασύμμετρη με μία ουρά στα δεξιά. Ωστόσο, και οι δύο οδηγούν στα ίδια συμπεράσματα για το μοντέλο.
14. Η ερευνήτρια αναρωτιέται αν η προηγούμενη εμπειρία των συμμετεχόντων από σεισμούς (experience) θα προβλέπει καλύτερα το πόσο ανησυχούν για μεγάλο σεισμό (worry_bigone).
Ποια είναι η τιμή πρόβλεψης του exp_model για κάποιον που έχει βιώσει μεγάλους σεισμούς;
ΣημείωσηΕπεξήγηση
Η ομάδα αναφοράς είναι το «Όχι» (καμία εμπειρία από σεισμούς), με \(b_0\) = 1.9658. Για την ομάδα «Ναι, μεγάλους», η τιμή πρόβλεψης είναι \(b_0 + b_2\) = 1.9658 + 0.6496. Η τιμή 0.3017 αντιστοιχεί στη διαφορά ανάμεσα στο «Όχι» και στο «Ναι, μικρούς» (\(b_0 + b_1)\).
15. Ο παρακάτω κώδικας είναι μια διαγραμματική αναπαράσταση του μοντέλου exp_model.
Σε ποιο συμπέρασμα μπορείτε να καταλήξετε από το παραπάνω διάγραμμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — \(b_2 \neq 0\).
Από το διάγραμμα μπορούμε να δούμε ότι οι κόκκινες γραμμές (οι μέσοι όροι που προβλέπει το μοντέλο) διαφέρουν μεταξύ των τριών ομάδων, άρα οι εκτιμήσεις \(b_1\) και \(b_2\) δεν είναι 0. Ωστόσο, από το διάγραμμα μπορούμε να δούμε μόνο τα στατιστικά του δείγματος (\(b_1\), \(b_2\)) — όχι τις παραμέτρους της ΔΠΔ (\(\beta_1\), \(\beta_2\)). Για να συμπεράνουμε κάτι για τη ΔΠΔ χρειάζεται να κάνουμε ελέγξουμε τη στατιστική σημαντικότητα των \(b_1\) και \(b_2\).
16. Παρακάτω δίνεται ο πίνακας ANOVA για το exp_model. Τι από τα παρακάτω μπορείτε να συμπεράνετε;
Analysis of Variance Table (Type III SS)
Model: worry_bigone ~ experience
SS df MS F PRE p
----- --------------- | -------- --- ------ ------ ----- -----
Model (error reduced) | 48.102 2 24.051 18.280 .0361 .0000
Error (from model) | 1282.806 975 1.316
----- --------------- | -------- --- ------ ------ ----- -----
Total (empty model) | 1330.908 977 1.362
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η τιμή \(p < 0.0001 < 0.05\) υποδηλώνει ότι απορρίπτουμε το κενό μοντέλο — οι τρεις ομάδες δεν φαίνεται να έχουν τον ίδιο μέσο όρο στη ΔΠΔ. Ωστόσο, η συνολική τιμή του ελέγχου F δεν μας λέει ποιες συγκεκριμένες ομάδες διαφέρουν — για αυτό χρειάζεται να κάνουμε συγκρίσεις κατά ζεύγη.
17. Εκτελέστε τον παρακάτω κώδικα για να κάνετε συγκρίσεις κατά ζεύγη για το exp_model. Τι επιτυγχάνει η σύγκριση κατά ζεύγη;
18. Ποιες από τις τρεις ομάδες της experience διαφέρουν σημαντικά μεταξύ τους ως προς τις βαθμολογίες της worry_bigone;
ΣημείωσηΕπεξήγηση
Με βάση τα αποτελέσματα της μέθοδου Tukey HSD, όλες οι διαφορές των ομάδων κατά ζεύγη είναι στατιστικά σημαντικές (\(p < 0.05\)).
19. Παρατηρήστε ότι στα αποτελέσματα των συγκρίσεων κατά ζεύγη αναφέρεται “Family-wise error-rate: 0.05”. Τι σημαίνει αυτό;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το family-wise error rate αναφέρεται στη συνολική πιθανότητα να κάνουμε Σφάλμα Τύπου Ι σε ολόκληρη την «οικογένεια» των τριών ελέγχων. Η διόρθωση με τη μέθοδο Tukey HSD διασφαλίζει ότι αυτή η συνολική πιθανότητα παραμένει στο 0.05.
20. Η ερευνήτρια αναρωτιέται αν το exp_model εξηγεί περισσότερη διακύμανση στη worry_bigone από το occur_model. Οι πίνακες ANOVA και για τα δύο μοντέλα παρουσιάζονται παρακάτω.
Analysis of Variance Table (Type III SS)
Model: worry_bigone ~ will_occur
SS df MS F PRE p
----- --------------- | -------- --- ------- ------- ----- -----
Model (error reduced) | 162.550 1 162.550 135.788 .1221 .0000
Error (from model) | 1168.357 976 1.197
----- --------------- | -------- --- ------- ------- ----- -----
Total (empty model) | 1330.908 977 1.362Analysis of Variance Table (Type III SS)
Model: worry_bigone ~ experience
SS df MS F PRE p
----- --------------- | -------- --- ------ ------ ----- -----
Model (error reduced) | 48.102 2 24.051 18.280 .0361 .0000
Error (from model) | 1282.806 975 1.316
----- --------------- | -------- --- ------ ------ ----- -----
Total (empty model) | 1330.908 977 1.362Με βάση τους πίνακες ANOVA, ποιο μοντέλο εξηγεί περισσότερη διακύμανση στη worry_bigone;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το PRE του occur_model είναι 0.1221, ενώ το PRE του exp_model είναι μόνο 0.0361. Άρα το occur_model (που χρησιμοποιεί το will_occur ως ανεξάρτητη μεταβλητή) εξηγεί πολύ περισσότερη διακύμανση στη worry_bigone — περίπου 12% έναντι 4% για το exp_model.