Στη Στατιστική, όταν αναφερόμαστε στη μεταβλητότητα εννοούμε τη μεταβλητότητα των δεδομένων. Ωστόσο, η μεταβλητότητα δεν προκύπτει εξ αρχής ως δεδομένα. Παρατηρώντας γύρω μας, διακρίνουμε ανθρώπους, κτίρια, δέντρα, φως και πολλά άλλα στοιχεία. Επιπλέον, παρατηρούμε έντονη μεταβλητότητα: κανένα ζεύγος ανθρώπων ή δέντρων δεν είναι απολύτως πανομοιότυπο. Οι στατιστικολόγοι επιδιώκουν να εκφράσουν αυτή τη μεταβλητότητα μέσω αριθμών, και από εκεί θα ξεκινήσουμε. (Στη συνέχεια, θα εξετάσουμε την προέλευση αυτών των αριθμών.)
Είναι σημαντικό να σημειωθεί ότι δεν χαρακτηρίζονται όλες οι ομάδες αριθμών από μεταβλητότητα. Για παράδειγμα, ας εξετάσουμε την εξής ακολουθία: 2, 2, 2, 2, 2, 2, 2, 2, 2. Στην περίπτωση αυτή, η χρήση στατιστικών μεθόδων δεν είναι απαραίτητη, καθώς απουσιάζει η μεταβλητότητα. Η απλή παρατήρηση των αριθμών αρκεί για να τους περιγράψουμε συνοπτικά: «Εννέα φορές ο αριθμός δύο». Αν υποθέσουμε ότι τίθεται το ερώτημα «Ποιος αριθμός αντιπροσωπεύει καλύτερα αυτή την κατανομή;», η απάντηση θα ήταν σχεδόν σίγουρα: «Ο αριθμός 2».
Αντίθετα, ας εξετάσουμε την ακόλουθη ομάδα αριθμών: 2, 1, 3, 3, 2, 3, 1, 2, 1. Σε αυτή την περίπτωση, μια σύντομη περιγραφή είναι πιο δύσκολη υπόθεση. Φανταστείτε την πρόκληση που θα συνεπαγόταν η ανάλυση εκατοντάδων ή χιλιάδων αριθμών.
Αναγνώριση Μοτίβων στους Αριθμούς
Με την πάροδο του χρόνου, οι στατιστικολόγοι έχουν αναπτύξει διάφορες ιδέες και διαδικασίες για να διευκολύνουν την κατανόηση των δεσμών αριθμών. Ακολουθεί ένα απλό παράδειγμα. Αρχικά, επιχειρήστε να δημιουργήσετε ένα διάνυσμα για την αποθήκευση των αριθμών 2, 1, 3, 3, 2, 3, 1, 2, 1.
Στο πλαίσιο που ακολουθεί, δίνεται ο κώδικας για τη δημιουργία ενός διανύσματος που περιέχει εννέα φορές τον αριθμό 2. Αυτό το διάνυσμα αποθηκεύεται σε ένα αντικείμενο της R με το όνομα bunch_of_2s. Έπειτα, γράψτε κώδικα για τη δημιουργία ενός άλλου διανύσματος με το όνομα bunch_of_123s που θα περιέχει τους αριθμούς 2, 1, 3, 3, 2, 3, 1, 2, 1. (Υπόδειξη: χρησιμοποιήστε τη συνάρτηση c().) Στη συνέχεια, προσθέστε κώδικα για να εμφανίσετε τα δύο διανύσματα, ώστε να επιβεβαιώσετε ότι περιέχουν τους επιθυμητούς αριθμούς. Εκτελέστε τον κώδικα (Run Code).
Ας ταξινομήσουμε τώρα τους αριθμούς στο bunch_of_123s σε αύξουσα σειρά, χρησιμοποιώντας τη συνάρτηση sort().
Αν παρατηρήσουμε τους ταξινομημένους αριθμούς στο bunch_of_123s, γίνεται ευκολότερη η αναγνώριση ενός μοτίβου στη μεταβλητότητα: οι αριθμοί 1, 2 και 3 εμφανίζονται με την ίδια συχνότητα. Άρα η απλή ταξινόμηση των αριθμών διευκολύνει την αναγνώριση ενός μοτίβου!
Εάν κατανοείτε αυτό το παράδειγμα, έχετε μόλις κατακτήσει την πρώτη σας στατιστική μέθοδο! Αν και μπορεί να φαίνεται απλή, σε μεγαλύτερα σύνολα δεδομένων (με περισσότερους από εννέα αριθμούς), τα πλεονεκτήματα της ταξινόμησης των αριθμών γίνονται άμεσα εμφανή.
Πίνακες Συχνοτήτων
Μπορούμε επίσης να αναπαραστήσουμε το ίδιο μοτίβο σε έναν πίνακα συχνοτήτων χρησιμοποιώντας την εντολή table().
Πατήστε το Run Code και παρατηρήστε το αποτέλεσμα.
Τι νομίζετε ότι δείχνει η πρώτη σειρά αριθμών στην έξοδο της συνάρτησης table();
Επεξήγηση
Στην έξοδο της συνάρτησης table(), η πρώτη σειρά δείχνει τις μοναδικές τιμές (τους διαφορετικούς αριθμούς) που υπάρχουν στο διάνυσμα. Για παράδειγμα, αν έχουμε το διάνυσμα c(1, 2, 1, 3, 2, 1), η πρώτη σειρά θα δείξει: 1, 2, 3 (τους μοναδικούς αριθμούς που εμφανίζονται).
Τι δείχνει η δεύτερη σειρά αριθμών;
Επεξήγηση
Η δεύτερη σειρά στην έξοδο της table() δείχνει τη συχνότητα κάθε τιμής - δηλαδή πόσες φορές εμφανίζεται κάθε αριθμός στο διάνυσμα. Συνεχίζοντας το παράδειγμα c(1, 2, 1, 3, 2, 1), η δεύτερη σειρά θα δείξει: 3, 2, 1 (το 1 εμφανίζεται 3 φορές, το 2 εμφανίζεται 2 φορές, και το 3 εμφανίζεται 1 φορά).
Ακολουθεί ο κώδικας για τη δημιουργία του διανύσματος με το όνομα bunch_of_2s. Ας εκτελέσουμε τη συνάρτηση table() στο bunch_of_2s.
Είτε το πιστεύετε είτε όχι, μόλις μάθατε μια δεύτερη στατιστική μέθοδο: τους πίνακες συχνοτήτων (οι οποίοι δημιουργούνται στην R μέσω της συνάρτησης table()). Καθώς εμβαθύνετε στη στατιστική, θα συναντήσετε πολλές παρόμοιες μεθόδους. Στην ουσία, όλες αυτές αποτελούν παραλλαγές λίγων βασικών ιδεών. Καθώς προχωράτε και ενισχύετε τις στατιστικές σας δεξιότητες, θα σας βοηθήσουμε να αποκτήσετε μια καλή γενική εικόνα.
3.2 Από τους Αριθμούς στα Δεδομένα
Παρότι μπορούμε να εφαρμόσουμε στατιστικές μεθόδους σε οποιοδήποτε σύνολο αριθμών και, σε ορισμένες περιπτώσεις, να επινοήσουμε αριθμούς για σκοπούς ανάλυσης (όπως θα δούμε παρακάτω), συνήθως επιδιώκουμε να αναλύσουμε αριθμούς που αντικατοπτρίζουν πτυχές του πραγματικού κόσμου. Αυτούς τους αριθμούς τους ονομάζουμε δεδομένα (data).
Μέτρηση και Δειγματοληψία
Τα δεδομένα προκύπτουν από δύο θεμελιώδεις διαδικασίες στη στατιστική: τη μέτρηση και τη δειγματοληψία. Η μέτρηση είναι η διαδικασία κατά την οποία αναπαριστούμε ένα χαρακτηριστικό ενός αντικειμένου με έναν αριθμό ή το κατατάσσουμε σε μια κατηγορία. Για παράδειγμα, παρόλο που δεν υπάρχουν δύο πανομοιότυποι άνθρωποι, μπορούμε να επιλέξουμε ένα χαρακτηριστικό τους, όπως το ύψος, και να το μετρήσουμε (σε εκατοστά, για παράδειγμα).
Δύο άτομα με ακριβώς το ίδιο ύψος μπορεί να διαφέρουν σημαντικά σε άλλα χαρακτηριστικά. Ωστόσο, μπορούμε να αποδώσουμε σε κάθε άτομο έναν αριθμό που αντιπροσωπεύει το ύψος του και να θεωρήσουμε ότι, τουλάχιστον ως προς αυτό το χαρακτηριστικό, είναι όμοιοι. Αυτή η απλοποίηση μπορεί να είναι ενοχλητική, καθώς κανείς δεν επιθυμεί να αναχθεί σε έναν αριθμό που αντιπροσωπεύει μόνο ένα χαρακτηριστικό. Παρόλα αυτά, η μέτρηση χαρακτηριστικών, ακόμη και των ανθρώπων, μπορεί να αποδειχθεί χρήσιμη σε ορισμένες περιπτώσεις.
Όταν τα αντικείμενα που μελετάμε (γνωστά και ως παρατηρήσεις, υποκείμενα, περιπτώσεις ή στατιστικές μονάδες) είναι άνθρωποι, η δειγματοληψία είναι η διαδικασία επιλογής των αντικειμένων που θα συμπεριληφθούν στη μελέτη, δεδομένου ότι είναι πρακτικά αδύνατο να μελετηθούν όλοι οι άνθρωποι. Οι άνθρωποι αποτελούν ένα παράδειγμα αντικειμένων, αλλά τα αντικείμενα μπορεί να είναι χώρες, οικογένειες, διαδρομές ποδηλάτου ή ποντίκια – οποιοδήποτε σύνολο στοιχείων από το οποίο μπορούμε να λάβουμε ένα δείγμα και να πραγματοποιήσουμε μετρήσεις για να παράγουμε δεδομένα. Στην ουσία, αναλύουμε δεδομένα και εφαρμόζουμε στατιστικές μεθόδους για να κατανοήσουμε τη μεταβλητότητα. Επομένως, είναι απαραίτητο να κάνουμε μετρήσεις σε περισσότερα από ένα αντικείμενα – σε ένα δείγμα αντικειμένων (sample).
H Προέλευση των Δεδομένων
Η διαδικασία επιλογής ενός δείγματος αντικειμένων και οι μετρήσεις που εφαρμόζονται σε αυτό το δείγμα καθορίζονται συνήθως από ένα συγκεκριμένο ερευνητικό ερώτημα, αν και όχι πάντα. Για παράδειγμα, μπορούμε να μετρήσουμε το ύψος ενός δείγματος ανθρώπων για να σχεδιάσουμε το ύψος μιας πόρτας, διασφαλίζοντας ότι ελάχιστοι θα χτυπήσουν το κεφάλι τους κατά τη διέλευση. Ωστόσο, ιδιαίτερα στην ψηφιακή εποχή, συχνά συναντάμε δεδομένα που συλλέχθηκαν χωρίς συγκεκριμένο σκοπό ή για σκοπούς διαφορετικούς από τους δικούς μας. Σε αυτές τις περιπτώσεις, μπορεί να διατυπώσουμε εκ των υστέρων ένα ερώτημα που θα μπορούσαμε να απαντήσουμε με αυτά τα δεδομένα. Επομένως, οι ερευνητές άλλοτε ξεκινούν με ένα ερώτημα και αναζητούν ή συλλέγουν δεδομένα για να το απαντήσουν και άλλοτε ξεκινούν με δεδομένα και αναζητούνένα ερώτημα ή έναν σκοπό που αυτά τα δεδομένα θα μπορούσαν να εξυπηρετήσουν.
Δύο διαφορετικοί ερευνητές μπορεί να συλλέξουν παρόμοια δεδομένα, αλλά για διαφορετικούς σκοπούς.
Για παράδειγμα, ένα νοσοκομείο και μια ιστοσελίδα γνωριμιών μπορεί να συλλέγουν δεδομένα για το ύψος και το βάρος (ασθενών και χρηστών, αντίστοιχα). Ποιοι θα μπορούσαν να είναι οι σκοποί τους;
Τα νοσοκομεία επιδιώκουν να βελτιώσουν την υγεία και να θεραπεύσουν τους ασθενείς. Επομένως, ένα νοσοκομείο μπορεί να παρακολουθεί το βάρος, καθώς σχετίζεται με άλλους δείκτες υγείας ή επειδή οι αλλαγές στο βάρος μπορεί να υποδηλώνουν βελτίωση ή επιδείνωση της κατάστασης. Μια ιστοσελίδα γνωριμιών, από την άλλη, μπορεί να ενδιαφέρεται για το πώς οι άνθρωποι χρησιμοποιούν αυτά τα χαρακτηριστικά για να αποφασίσουν αν θα αλληλεπιδράσουν με ένα άλλο άτομο.
Ένα νοσοκομείο είναι πιθανό να μετρήσει αντικειμενικά το ύψος και το βάρος χρησιμοποιώντας ζυγαριά, μεζούρα ή χάρακα. Αντίθετα, μια ιστοσελίδα γνωριμιών πιθανότατα θα ζητήσει από τους χρήστες να αναφέρουν το ύψος και το βάρος τους. Οι μετρήσεις του νοσοκομείου είναι συνεπώς πιο πιθανό να είναι ακριβείς σε σχέση με τις μετρήσεις που συλλέγονται από μια ιστοσελίδα γνωριμιών!
Επιπλέον, τα άτομα σε αυτά τα δύο δείγματα μπορεί να διαφέρουν σημαντικά. Τα δεδομένα του νοσοκομείου προέρχονται συνήθως από ασθενείς, καθώς αυτοί είναι πιο πιθανό να επισκεφθούν ένα νοσοκομείο. Μπορεί επίσης να είναι μεγαλύτερης ηλικίας, καθώς η πιθανότητα ασθένειας αυξάνεται με την ηλικία. Το δείγμα της ιστοσελίδας γνωριμιών, αντιθέτως, μπορεί να είναι νεότερο και πιο υγιές.
Ένα νοσοκομείο αποφασίζει να συλλέξει το ύψος και το βάρος των ασθενών του. Σκεφτείτε μερικά ενδιαφέροντα ερευνητικά ερωτήματα που θα μπορούσαν να διατυπωθούν σε αυτήν την περίπτωση.
Μια ιστοσελίδα γνωριμιών αποφασίζει να συλλέξει το ύψος και το βάρος των επισκεπτών της. Σκεφτείτε μερικά ενδιαφέροντα ερευνητικά ερωτήματα που θα μπορούσαν να διατυπωθούν σε αυτή την περίπτωση.
Οργάνωση Δεδομένων σε Πλαίσιο Δεδομένων
Στη στατιστική, τα δεδομένα συνήθως οργανώνονται σε πίνακες με γραμμές και στήλες. Ακολουθεί ένα απλό παράδειγμα ενός συνόλου δεδομένων που έχει οργανωθεί με αυτόν τον τρόπο:
Method Age PreScore PostScore
1 Traditional 20 68 72
2 Traditional 19 75 78
3 Interactive 21 66 82
4 Interactive 18 71 89
5 Traditional 20 73 74
6 Interactive 19 69 85
Οι γραμμές αντιπροσωπεύουν τα αντικείμενα (ή τις παρατηρήσεις) που επιλέχθηκαν στο δείγμα. Στο συγκεκριμένο παράδειγμα, οι γραμμές αντιστοιχούν σε φοιτητές που συμμετείχαν σε μια μελέτη. Υπάρχουν έξι γραμμές, που σημαίνει ότι το σύνολο δεδομένων περιλαμβάνει έξι φοιτητές. Ανάλογα με τη μελέτη, οι γραμμές μπορεί να αναφέρονται σε φοιτητές, εκπαιδευτικούς, σχολεία, τάξεις – είναι οι παρατηρήσεις που επιλέγονται στο πλαίσιο της μελέτης.
Οι στήλες αντιπροσωπεύουν τις μεταβλητές, δηλαδή τα χαρακτηριστικά κάθε αντικειμένου που μετρήθηκε. Στη συγκεκριμένη μελέτη, οι φοιτητές χωρίστηκαν σε δύο ομάδες: μία ομάδα διδάχθηκε με την παραδοσιακή μέθοδο (traditional) και μία άλλη με μια διαδραστική μέθοδο διδασκαλίας (interactive). Επομένως, μία από τις μεταβλητές είναι η Method – δηλαδή, ποια διδακτική μέθοδος χρησιμοποιήθηκε. Άλλες μεταβλητές περιλαμβάνουν την ηλικία του φοιτητή (Age), την ακαδημαϊκή του επίδοση πριν από την έναρξη της διδασκαλίας (PreScore) και την επίδοσή του στο μετά το πέρας της διδασκαλίας (PostScore, μετρημένη τέσσερις εβδομάδες αργότερα). Επομένως, οι τιμές σε κάθε γραμμή αντιπροσωπεύουν τις τιμές της συγκεκριμένης παρατήρησης σε καθεμία από τις μεταβλητές που μετρήθηκαν.
Ποια από τα παρακάτω στοιχεία είναι τιμές μεταβλητών και ποια είναι μεταβλητές;
Στοιχείο
Τιμή
Μεταβλητή
Κανένα
Α. Μέθοδος
☐
☐
☐
Β. PreScore
☐
☐
☐
Γ. 45
☐
☐
☐
Δ. Traditional
☐
☐
☐
Ε. Interactive
☐
☐
☐
ΣΤ. 135.8
☐
☐
☐
Απάντηση
Μεταβλητές: - Α. Method (μεταβλητή που περιγράφει τη μέθοδο διδασκαλίας) - Β. PreScore (μεταβλητή βαθμολογίας)
Τιμές: - Γ. 45 (συγκεκριμένος αριθμός/μέτρηση) - Δ. Traditional (συγκεκριμένη κατηγορία - μέθοδος διδασκαλίας) - Ε. Interactive (συγκεκριμένη κατηγορία - μέθοδος διδασκαλίας) - ΣΤ. 135.8 (συγκεκριμένος αριθμός/μέτρηση)
Θυμηθείτε: Οι μεταβλητές είναι τα χαρακτηριστικά που μετράμε (π.χ. ύψος, φύλο), ενώ οι τιμές είναι οι συγκεκριμένοι αριθμοί ή κατηγορίες που παίρνουν αυτές οι μεταβλητές.
Στο παρακάτω τμήμα ενός συνόλου δεδομένων, υπάρχουν τέσσερις διαφορετικές ηλικίες: 18, 19, 20, 21. Αυτό σημαίνει ότι υπάρχουν τέσσερις μεταβλητές για την ηλικία;
Method Age PreScore PostScore
1 Traditional 20 68 72
2 Interactive 19 75 78
3 Interactive 21 66 82
4 Interactive 18 71 89
5 Traditional 20 73 74
6 Traditional 19 69 85
Επεξήγηση
Όχι, δεν υπάρχουν τέσσερις μεταβλητές για την ηλικία. Υπάρχει μία μόνο μεταβλητή που ονομάζεται ‘Age’ (Ηλικία). Οι αριθμοί 18, 19, 20 και 21 είναι οι τιμές που παίρνει αυτή η μεταβλητή για τους έξι διαφορετικούς φοιτητές στο δείγμα.
Θυμηθείτε τη διαφορά: - Μεταβλητή: Το χαρακτηριστικό που μετράμε (π.χ. Age, Method, PreScore) - Τιμές: Οι συγκεκριμένοι αριθμοί ή κατηγορίες για κάθε παρατήρηση
Η Age είναι μία μεταβλητή που περιέχει διαφορετικές τιμές για διαφορετικά άτομα. Εδώ βλέπουμε τέσσερις διαφορετικές τιμές της Age για τους έξι φοιτητές του δείγματος.
Υπάρχουν τέσσερις μεταβλητές (Method, Age, επίδοση στην αρχή της μελέτης με το όνομα PreScore και επίδοση στο τέλος της μελέτης με το όνομα PostScore), οι οποίες αντιστοιχούν στις τέσσερις στήλες του πίνακα.
Τα δεδομένα σε γραμμές και στήλες αποθηκεύονται σε αντικείμενα της R που ονομάζονται πλαίσια δεδομένων (data frames). Τα πλαίσια δεδομένων περιλαμβάνουν τις γραμμές και τις στήλες που περιέχουν τα δεδομένα, καθώς και επιπλέον πληροφορίες, οι οποίες μπορούν να θεωρηθούν ως μεταδεδομένα. Τα μεταδεδομένα περιλαμβάνουν, για παράδειγμα, τα ονόματα των μεταβλητών (οι επικεφαλίδες στην κορυφή κάθε στήλης) και τον αριθμό γραμμής. Αυτό σημαίνει ότι οι επικεφαλίδες δεν «προσμετρώνται» ως γραμμή στο πλαίσιο δεδομένων, όπως ακριβώς οι αριθμοί των γραμμών (1 έως 6) δεν «προσμετρώνται» ως μεταβλητή.
3.3 Παράδειγμα Πλαισίου Δεδομένων: TeachingMethods
Τα δεδομένα που εξετάστηκαν στην προηγούμενη ενότητα επιλέχθηκαν από ένα πλαίσιο δεδομένων με το όνομα TeachingMethods. Το εν λόγω πλαίσιο δεδομένων προέρχεται από μια μελέτη που διερεύνησε την αποτελεσματικότητα δύο διαφορετικών μεθόδων διδασκαλίας (παραδοσιακής και διαδραστικής) στην ακαδημαϊκή επίδοση και τα κίνητρα 80 φοιτητών και φοιτητριών ενός Τμήματος Ψυχολογίας. Οι συμμετέχοντες κατανεμήθηκαν τυχαία σε δύο ομάδες διδασκαλίας και συλλέχθηκαν δεδομένα για 11 διαφορετικές μεταβλητές, οι οποίες θα περιγραφούν σταδιακά στη συνέχεια.
Ένα πλαίσιο δεδομένων αποτελεί ένα είδος αντικειμένου στην R και, όπως συμβαίνει με κάθε αντικείμενο, η πληκτρολόγηση του ονόματός του εμφανίζει το σύνολο του περιεχομένου του.
Για να δείτε το περιεχόμενο, πληκτρολογήστε το όνομα του πλαισίου δεδομένων TeachingMethods και, στη συνέχεια, επιλέξτε Run Code.
Χρειάστηκε να μετακινηθείτε προς τα κάτω στη σελίδα για να εμφανιστεί ολόκληρο το αποτέλεσμα. Αυτό είναι συνηθισμένο όταν εργαζόμαστε με πραγματικά δεδομένα, τα οποία συχνά περιλαμβάνουν πληθώρα μεταβλητών και τιμών. Επιπλέον, συνήθως λαμβάνεται δείγμα από πολλά αντικείμενα, καθένα με τις δικές του τιμές σε διαφορετικές μεταβλητές. Ως αποτέλεσμα, η πολυπλοκότητα αυξάνεται ραγδαία.
Η εξέταση ολόκληρου του πλαισίου δεδομένων ενδέχεται να είναι χρονοβόρα. Για τον σκοπό αυτό, η συνάρτηση head() εμφανίζει μόνο τις πρώτες γραμμές ενός πλαισίου δεδομένων. Επιλέξτε Run Code για να δείτε το αποτέλεσμα της εντολής head(TeachingMethods).
Η συνάρτηση head() εμφανίζει τις πρώτες έξι γραμμές του πλαισίου δεδομένων με τη μορφή γραμμών και στηλών.
Επιπλέον, για μια συνοπτική παρουσίαση του περιεχομένου ενός πλαισίου δεδομένων, η συνάρτηση str() εμφανίζει τη συνολική του δομή, συμπεριλαμβανομένου του αριθμού των αντικειμένων, του αριθμού των μεταβλητών, των ονομάτων των μεταβλητών και άλλων σχετικών πληροφοριών. Η συνάρτηση str() χρησιμοποιείται συχνά κατά την πρώτη μας επαφή με ένα νέο πλαίσιο δεδομένων, για να γίνει αντιληπτή η δομή του.
Εκτελέστε (Run Code) τη συνάρτηση str() στο TeachingMethods και εξετάστε τα αποτελέσματα.
Παρατηρήστε τη χρήση του συμβόλου $ πριν από το όνομα κάθε μεταβλητής. Στην R, το σύμβολο $ χρησιμοποιείται συχνά για να δηλώσει ότι το στοιχείο που ακολουθεί είναι το όνομα μιας μεταβλητής. Για παράδειγμα, για να απομονώσετε τη μεταβλητή Age στο πλαίσιο δεδομένων TeachingMethods, θα χρησιμοποιούσατε την έκφραση TeachingMethods$Age. Η R υποστηρίζει διαφορετικούς τύπους μεταβλητών, όπως int, num και Factor. Περισσότερες πληροφορίες σχετικά με αυτούς θα παρουσιαστούν σε επόμενη ενότητα.
Εφαρμόστε το σύμβολο $ για να εμφανίσετε μόνο τη μεταβλητή Age (κλικ στο Run Code).
Το αποτέλεσμα της εντολής TeachingMethods$Age είναι μια σειρά αριθμών (ηλικιών).
Όταν η R καλείται να εμφανίσει μια μεμονωμένη μεταβλητή, όπως η Age, εμφανίζει τις τιμές των παρατηρήσεων στη μεταβλητή σε μια μόνο γραμμή. Όταν οι τιμές της μεταβλητής είναι πολλές και δεν χωρούν στο πλάτος της οθόνης, η R συνεχίζει την εμφάνισή τους από κάτω. Στην πρώτη γραμμή του παραπάνω αποτελέσματος, υπάρχουν 25 ηλικίες (σύρετε με το ποντίκι προς τα δεξιά για να τις δείτε). Το [26] υποδηλώνει ότι η επόμενη γραμμή ξεκινά με την 26η παρατήρηση.
Αντίθετα, όταν η R καλείται να εμφανίσει πολλές μεταβλητές, χρησιμοποιεί τη μορφή πίνακα γραμμών και στηλών, όπου οι γραμμές αντιστοιχούν στις παρατηρήσεις (αντικείμενα) και οι στήλες στις μεταβλητές.
3.4 Πίνακες Συχνοτήτων και Ταξινόμηση Πλαισίων Δεδομένων
Χρήση της table() για Δημιουργία Πινάκων Συχνοτήτων
Η συνάρτηση table() μπορεί να χρησιμοποιηθεί για τη δημιουργία ενός πίνακα συχνοτήτων (frequency table) για τη μεταβλητή Age (Ηλικία) στο πλαίσιο δεδομένων TeachingMethods. Ο πίνακας αυτός θα εμφανίσει τον αριθμό των φοιτητών που έχουν κάθε διαφορετική τιμή της ηλικίας.
Θα μπορούσαμε επίσης να δημιουργήσουμε τον πίνακα συχνοτήτων με χρήση της συνάρτησης with(), η οποία επιτρέπει την αναφορά σε μεταβλητές ενός πλαισίου δεδομένων χωρίς να χρειάζεται να χρησιμοποιήσουμε το σύμβολο $ κάθε φορά. Έτσι, μπορούμε να γράψουμε:
Στα παραπάνω αποτελέσματα, οι αριθμοί (17, 18, 19 κ.λπ.) αντιπροσωπεύουν τις ηλικίες των φοιτητών, ενώ οι αριθμοί που βρίσκονται κάτω από αυτές υποδεικνύουν τη συχνότητα εμφάνισης κάθε τιμής της ηλικίας στο πλαίσιο δεδομένων. Για παράδειγμα, επτά άτομα είναι 17 ετών, δεκατρία άτομα είναι 18 ετών και είκοσι άτομα είναι 19 ετών.
Τι παρατηρείτε σχετικά με την κατανομή της ηλικίας των φοιτητών στο πλαίσιο δεδομένων TeachingMethods;
Επεξήγηση
Εξετάζοντας την κατανομή της ηλικίας στα δεδομένα TeachingMethods, παρατηρούμε ότι:
Η ηλικία των φοιτητών κυμαίνεται από 17 έως 22 έτη (εύρος 6 ετών)
Οι ηλικίες 19 και 20 ετών εμφανίζονται με την ίδια συχνότητα (περισσότερο από τις άλλες ηλικίες)
Δεν είναι όλοι της ίδιας ηλικίας (υπάρχει μεταβλητότητα)
Δεν κυριαρχεί η ηλικία των 17 ετών
Δεν υπάρχουν περισσότεροι φοιτητές 22 ετών από ότι 18 ετών
Αυτή η παρατήρηση δείχνει τη σημασία του να εξετάζουμε την κατανομή των δεδομένων μας για να καταλαβαίνουμε καλύτερα τα χαρακτηριστικά του δείγματός μας.
Αντίστοιχα, μπορούμε να δημιουργήσουμε έναν πίνακα συχνοτήτων για τη μεταβλητή Method (Μέθοδος διδασκαλίας) στο πλαίσιο δεδομένων TeachingMethods. Αυτό θα μας δείξει πόσοι φοιτητές ανήκουν σε κάθε ομάδα μεθόδου διδασκαλίας.
Το αποτέλεσμα της table() φανερώνει ότι 40 άτομα βρίσκονταν στην ομάδα «Διαδραστική» (Interactive) και 40 στην ομάδα «Παραδοσιακή» (Traditional).
Χρήση της arrange() για Ταξινόμηση Πλαισίου Δεδομένων
Ας εξετάσουμε τις μεταβλητές Age (Ηλικία, σε έτη, κατά την έναρξη της μελέτης) και PreScore (αρχική επίδοση, πριν την έναρξη της μελέτης) στο πλαίσιο δεδομένων TeachingMethods.
Ενδεχομένως να επιθυμούμε την ταξινόμηση ολόκληρου του πλαισίου δεδομένων TeachingMethods με βάση την Age. Η συνάρτηση sort() δεν είναι κατάλληλη, καθώς δέχεται μόνο διανύσματα και όχι πλαίσια δεδομένων. Για την ταξινόμηση ενός ολόκληρου πλαισίου δεδομένων, χρησιμοποιείται η συνάρτηση arrange().
Η arrange() λειτουργεί παρόμοια με τη sort(), αλλά απαιτεί τον προσδιορισμό τόσο του ονόματος του πλαισίου δεδομένων όσο και του ονόματος της μεταβλητής που θα χρησιμοποιηθεί για την ταξινόμηση των γραμμών.
Αξίζει να σημειωθεί ότι η χρήση της arrange() για ταξινόμηση με βάση μια μεταβλητή (π.χ., Age) αλλάζει τη σειρά των γραμμών (στη συγκεκριμένη περίπτωση, των ατόμων), διατηρώντας όμως το περιεχόμενο κάθε γραμμής αμετάβλητο.
Η συνάρτηση arrange() θα εμφανίσει το σύνολο δεδομένων ταξινομημένο κατά Age. Αλλά αν τώρα δοκιμάσετε να εμφανίσετε ξανά το TeachingMethods, δεν θα είναι ταξινομημένο κατά Age. Γιατί;
Επεξήγηση
Στην R, οι περισσότερες συναρτήσεις δεν τροποποιούν το αρχικό αντικείμενο - απλώς επιστρέφουν ένα νέο αποτέλεσμα. Η arrange() δημιουργεί ένα ταξινομημένο αντίγραφο των δεδομένων, αλλά το αρχικό TeachingMethods παραμένει αμετάβλητο.
Για να διατηρήσουμε τις αλλαγές, πρέπει να αποθηκεύσουμε το αποτέλεσμα:
# Αυτό μόνο εμφανίζει το ταξινομημένο αποτέλεσμαarrange(TeachingMethods, Age)# Αυτό αποθηκεύει το ταξινομημένο αποτέλεσμαTeachingMethods <-arrange(TeachingMethods, Age)
Αυτή η τακτική προστατεύει τα αρχικά δεδομένα από τυχαίες αλλαγές και μας επιτρέπει να αποφασίσουμε πότε θέλουμε να κρατήσουμε τις τροποποιήσεις.
Για να διατηρηθεί η νέα ταξινόμηση, το αποτέλεσμα πρέπει να ανατεθεί σε ένα αντικείμενο της R. Αυτό μπορεί να γίνει είτε στο υπάρχον αντικείμενο (TeachingMethods), είτε σε ένα νέο αντικείμενο (π.χ., Teaching2, TM2, TM_arrange ή οποιοδήποτε άλλο όνομα). Η ανάθεση στο υπάρχον αντικείμενο θα αντικαταστήσει τα περιεχόμενά του με τη νέα ταξινόμηση. Γενικά, συνιστάται η αποθήκευση ενός τροποποιημένου πλαισίου δεδομένων σε ένα νέο αντικείμενο R, ώστε να υπάρχει η δυνατότητα επιστροφής στην αρχική εκδοχή των δεδομένων.
Ας χρησιμοποιήσουμε τον τελεστή ανάθεσης (<-) για να αναθέσουμε το ταξινομημένο πλαίσιο δεδομένων στο αντικείμενο TM_arrange. Προσπαθήστε να επεξεργαστείτε τον ακόλουθο κώδικα για να αποθηκεύσετε την ταξινομημένη εκδοχή του TeachingMethods κατά Age στο TM_arrange. Στη συνέχεια, εμφανίστε τις πρώτες έξι γραμμές του TM_arrange χρησιμοποιώντας τη συνάρτηση head().
Ταξινόμηση Πλαισίου Δεδομένων σε Φθίνουσα Σειρά
Η συνάρτηση arrange() μπορεί επίσης να ταξινομήσει τις τιμές σε φθίνουσα σειρά, χρησιμοποιώντας τη συνάρτηση desc() γύρω από το όνομα της μεταβλητής.
Προσπαθήστε να ταξινομήσετε το TeachingMethods κατά PreScore (επίδοση στην αρχή της μελέτης) σε φθίνουσα σειρά. Αποθηκεύστε το αποτέλεσμα στο αντικείμενο TM_desc. Εμφανίστε μερικές γραμμές του TM_desc για να ελέγξετε το αποτέλεσμα.
3.5 Μέτρηση
Η μέτρηση είναι η διαδικασία μετατροπής της μεταβλητότητας του πραγματικού κόσμου σε δεδομένα. Κατά τη μέτρηση, αντιστοιχίζουμε αριθμούς ή κατηγορίες σε ένα δείγμα παρατηρήσεων, προκειμένου να αναπαραστήσουμε ένα χαρακτηριστικό στο οποίο οι παρατηρήσεις διαφέρουν.
Για να γίνει αυτό πιο συγκεκριμένο, ας εξετάσουμε μερικές μετρήσεις σε ένα πλαίσιο δεδομένων με την ονομασία Fingers (Δάχτυλα). Ένα δείγμα φοιτητών συμπλήρωσε ένα ερωτηματολόγιο το οποίο περιλάμβανε ορισμένες δημογραφικού τύπου ερωτήσεις. Επιπλέον, τους ζητήθηκε να μετρήσουν το μήκος κάθε δαχτύλου στο δεξί τους χέρι.
Θα παρατηρήσετε ότι η προσπάθεια να εμφανιστεί ολόκληρος ο πίνακας δεδομένων μπορεί να είναι αρκετά δυσχερής, ειδικά για μεγαλύτερα σύνολα δεδομένων.
Η εντολή head() εμφανίζει τις πρώτες έξι γραμμές ενός πίνακα δεδομένων. Αν επιθυμείτε να δείτε διαφορετικό αριθμό γραμμών, μπορείτε απλώς να προσθέσετε έναν αριθμό στο τέλος, όπως εδώ:
Ας εξετάσουμε τον φοιτητή 1, τα δεδομένα του οποίου βρίσκονται στη γραμμή 1. Τι πιστεύετε ότι σημαίνει το 7 στη στήλη FamilyMembers; Τι σημαίνει το 2 στη στήλη Gender; Τι σημαίνει το 179.070 στη στήλη Height;
Μια λογική σκέψη είναι ότι το 7 στη στήλη FamilyMembers σημαίνει ότι ο φοιτητής έχει 7 μέλη οικογένειας, το 2 στη στήλη Gender είναι κωδικός για το φύλο (πιθανώς 1=άνδρας, 2=γυναίκα), και το 179.070 στη στήλη Height είναι το ύψος του σε εκατοστά.
Σημειώστε ότι για να απαντήσετε σε αυτές τις ερωτήσεις, πρέπει να γνωρίζετε πληροφορίες σχετικά με τον τρόπο μέτρησης αυτών των μεταβλητών. Πρέπει να γνωρίζετε: Το Height (Ύψος) μετρήθηκε σε εκατοστά; Ποιος κωδικός αντιστοιχεί σε ποιο Gender (Φύλο); Το FamilyMembers (Μέλη Οικογένειας) συμπεριλαμβάνει και το άτομο που απαντά στην ερώτηση;
Θα αναφερθούμε εκτενώς παρακάτω στο τι σημαίνουν οι μετρήσεις. Πριν συνεχίσουμε, όμως, ας εξετάσουμε έναν ακόμη τρόπο για να αποκτήσουμε μια γρήγορη επισκόπηση ενός πίνακα δεδομένων.
Υπάρχει μια εντολή παρόμοια με την head(), που ονομάζεται tail(). Τι πιστεύετε ότι μπορεί να εμφανίσει αυτή η εντολή;
Επεξήγηση
Η συνάρτηση tail() είναι το αντίθετο της head() και εμφανίζει τις τελευταίες γραμμές ενός συνόλου δεδομένων.
Σύγκριση των δύο συναρτήσεων: - head(): Εμφανίζει τις πρώτες 6 γραμμές (προεπιλογή) - tail(): Εμφανίζει τις τελευταίες 6 γραμμές (προεπιλογή)
Παραδείγματα χρήσης:
head(TeachingMethods) # Πρώτες 6 γραμμέςtail(TeachingMethods) # Τελευταίες 6 γραμμέςhead(TeachingMethods, 3) # Πρώτες 3 γραμμέςtail(TeachingMethods, 3) # Τελευταίες 3 γραμμές
Και οι δύο συναρτήσεις είναι χρήσιμες για να εξερευνήσουμε γρήγορα τα δεδομένα μας χωρίς να εμφανίσουμε ολόκληρο το σύνολο δεδομένων.
3.6 Ποσοτικές και Ποιοτικές Μεταβλητές
Οι μεταβλητές διακρίνονται σε δύο βασικά είδη: ποσοτικές (quantitative) και ποιοτικές (qualitative). Οι ποιοτικές ονομάζονται και κατηγορικές (categorical).
Οι μεταβλητές FamilyMembers και Height (σε εκατοστά, στο συγκεκριμένο παράδειγμα) αποτελούν παραδείγματα ποσοτικών μεταβλητών. Οι τιμές που αποδίδονται σε αυτές αντιπροσωπεύουν μια ποσότητα (π.χ., εκατοστά για το ύψος). Έτσι, γνωρίζουμε ότι ένα άτομο με μεγαλύτερη τιμή (π.χ., 185) είναι ψηλότερο από ένα άτομο με μικρότερη τιμή (π.χ., 180). Επιπλέον, η διαφορά μεταξύ των τιμών υποδεικνύει ακριβώς πόσο ψηλότερο είναι το ένα άτομο σε σχέση με το άλλο.
Οι ποιοτικές μεταβλητές διαφέρουν σημαντικά από τις ποσοτικές. Η μεταβλητή Gender στο συγκεκριμένο σύνολο δεδομένων είναι ένα παράδειγμα ποιοτικής μεταβλητής. Οι φοιτητές αυτοπροσδιορίστηκαν ως άνδρες, γυναίκες ή άλλο. Για τους σκοπούς της ανάλυσης, μπορούμε να κωδικοποιήσουμε κάθε άτομο ως εξής: 1 για γυναίκα, 2 για άνδρα και 3 για άλλο. Οι συγκεκριμένοι αριθμοί που χρησιμοποιούμε είναι αυθαίρετοι· θα μπορούσαμε εξίσου καλά να αντιστοιχίσουμε το 1 στην κατηγορία «άλλο», το 2 στη «γυναίκα» και το 3 στον «άνδρα». Οι αριθμοί αυτοί δεν εκφράζουν ποσότητα, αλλά απλώς υποδεικνύουν την κατηγορία στην οποία ανήκει η κάθε παρατήρηση. Για παράδειγμα, το 2 στη στήλη FamilyMembers εκφράζει ποσότητα, αλλά το 2 στη στήλη Gender θεωρείται κατηγορία.
Θα ήταν εντάξει αν, σε ένα άλλο σύνολο δεδομένων, αποφασίζαμε να κωδικοποιήσουμε τους άνδρες ως «20», τις γυναίκες ως «10» και το άλλο ως «15»;
Επεξήγηση
Ναι, θα ήταν εντάξει να χρησιμοποιήσουμε οποιουσδήποτε αριθμούς για να κωδικοποιήσουμε ποιοτικές μεταβλητές όπως το φύλο.
Σημαντικά σημεία:
Οι αριθμοί που χρησιμοποιούμε για ποιοτικές μεταβλητές είναι αυθαίρετοι
Δεν έχουν μαθηματική σημασία - είναι απλώς ετικέτες
Το 20 δεν είναι “μεγαλύτερο” από το 10 για τη μεταβλητή φύλο
Θα μπορούσαμε εξίσου να χρησιμοποιήσουμε 1, 2, 3 ή 100, 200, 300
Προσοχή: Πρέπει να θυμόμαστε τι σημαίνει κάθε αριθμός και να το καταγράψουμε σωστά στα μεταδεδομένα μας. Το στατιστικό λογισμικό θα επεξεργαστεί τους αριθμούς, αλλά μόνο εμείς γνωρίζουμε τι αντιπροσωπεύουν πραγματικά.
Καλή πρακτική: Να χρησιμοποιούμε συνεπή και λογική κωδικοποίηση (π.χ. 1, 2, 3) για ευκολία.
Παρόλο που χρησιμοποιούμε τους όρους «ποσοτικές» και «ποιοτικές» μεταβλητές, άλλοι συγγραφείς ενδέχεται να χρησιμοποιούν διαφορετική ορολογία. Ωστόσο, η έννοια παραμένει ουσιαστικά η ίδια, επομένως δεν είναι απαραίτητο να εμμένετε αποκλειστικά σε αυτούς τους όρους. Ακολουθούν ορισμένα συνώνυμα για τους όρους «ποσοτική μεταβλητή» και «ποιοτική μεταβλητή» που μπορεί να συναντήσετε:
Ποσοτική Μεταβλητή
Ποιοτική Μεταβλητή
Αριθμητική μεταβλητή
Κατηγορική μεταβλητή
Συνεχής μεταβλητή
Ονομαστική μεταβλητή
Για κάθε μια από τις παρακάτω μεταβλητές, επιλέξτε αν είναι ποσοτική ή ποιοτική:
8. GradePredict (Βαθμολογία σε μια κλίμακα από 0.0 έως 4.0)
9. FamilyMembers (Αριθμός μελών της οικογένειας εξαιρουμένου του εαυτού)
Ποσοτικές και Ποιοτικές Μεταβλητές στην R
Στην R, οι ποσοτικές μεταβλητές αναπαρίστανται πάντα ως αριθμητικές μεταβλητές (τύπος αντικειμένου num). Οι ποιοτικές μεταβλητές, από την άλλη, μπορεί να είναι είτε αριθμητικές είτε μεταβλητές χαρακτήρων (τύπος αντικειμένου chr), ανάλογα με τις τιμές που περιέχουν. Για παράδειγμα, αν κωδικοποιούσαμε τη μεταβλητή Gender με τους αριθμούς 1 και 2 (για άνδρα και γυναίκα αντίστοιχα), θα μπορούσαμε να αποθηκεύσουμε τις τιμές σε μια αριθμητική μεταβλητή στην R (τύπου num). Εναλλακτικά, αν θέλαμε να χρησιμοποιήσουμε τις κατηγορίες “male” και “female” για τη μεταβλητή Gender, η R θα την αναπαριστούσε ως μεταβλητή χαρακτήρων (τύπου chr). Ανεξάρτητα από τον τύπο αντικειμένου που χρησιμοποιείται στην R, από την οπτική του ερευνητή, η μεταβλητή παραμένει ποιοτική.
Η R δεν μπορεί πάντα να αναγνωρίσει αυτόματα αν μια μεταβλητή είναι ποσοτική ή ποιοτική. Ένας αριθμός μπορεί να χρησιμοποιηθεί για την κωδικοποίηση μιας ποιοτικής μεταβλητής (π.χ., 1 για άνδρες και 2 για γυναίκες), ή μπορεί να αντιπροσωπεύει μια πραγματική ποσοτική μέτρηση (1 αδερφός/η ή 2 αδέλφια). Η R προσπαθεί να συμπεράνει τον τύπο της μεταβλητής, αλλά ενδέχεται να κάνει λάθος.
Για το λόγο αυτό, υπάρχει η δυνατότητα να ορίσετε ρητά αν μια μεταβλητή είναι ποιοτική, χρησιμοποιώντας τη συνάρτηση factor(). Μια μεταβλητή τύπου Factor στην R είναι πάντα ποιοτική. Στο πλαίσιο δεδομένων Fingers, η μεταβλητή Gender είναι κωδικοποιημένη ως 1 ή 2. Για να υποδείξουμε στην R ότι είναι ποιοτική, χρησιμοποιούμε την εντολή factor(Fingers$Gender). Είναι σημαντικό να θυμόμαστε ότι πρέπει να αποθηκεύσουμε το αποτέλεσμα της εντολής πίσω στο πλαίσιο δεδομένων Fingers, αν θέλουμε η R να το απομνημονεύσει. Ο παρακάτω κώδικας μετατρέπει τη μεταβλητή Gender σε Factor και αντικαθιστά την παλιά αριθμητική εκδοχή με τη νέα:
Επίσης, μπορούμε να μετατρέψουμε μια μεταβλητή τύπου Factor ξανά σε αριθμητική μεταβλητή με τη συνάρτηση as.numeric().
Αν τα 1 και 2 στη στήλη Gender ήταν αριθμοί, θα μπορούσαμε να τα αθροίσουμε χρησιμοποιώντας τον κώδικα sum(Fingers$Gender). Όμως, αν δηλώσουμε στην R ότι η μεταβλητή Gender είναι Factor, θα θεωρήσει ότι τα 1 και 2 αναφέρονται σε κατηγορίες και δεν θα επιχειρήσει να τα αθροίσει.
Στο παρακάτω πλαίσιο εφαρμόστε τη συνάρτηση sum() για να υπολογίσετε το άθροισμα της μεταβλητής Gender, όπου οι γυναίκες κωδικοποιούνται ως 1 και οι άνδρες ως 2.
Παρόλο που είναι τεχνικά δυνατό να αθροιστούν αυτές οι τιμές, είναι στατιστικά αδόκιμο, καθώς τα 1 και 2 αντιπροσωπεύουν κατηγορίες. Το άθροισμα 202 δεν έχει ουσιαστική ερμηνεία.
Ανάλογα με τους στόχους της ανάλυσης, μπορεί να είναι χρήσιμο να χειριστείτε μια μεταβλητή με αριθμητικές τιμές τόσο ως ποσοτική όσο και ως ποσοτική. Σε αυτή την περίπτωση, συνιστάται η δημιουργία δύο αντιγράφων της μεταβλητής: ένα αριθμητικό (num) και ένα Factor.
Για παράδειγμα, οι κλίμακες τύπου Likert (ερωτήσεις όπου καλείστε να βαθμολογήσετε κάτι σε μια κλίμακα 5 ή 7 βαθμίδων) μπορούν να αντιμετωπιστούν ως ποσοτικές μεταβλητές σε ορισμένες περιπτώσεις και ως ποιοτικές σε άλλες. Στο πλαίσιο δεδομένων Fingers, η μεταβλητή Interest αντιπροσωπεύει την απάντηση που έδωσαν οι φοιτητές στην ερώτηση «πόσο ενδιαφέρον είναι το μάθημα της στατιστικής», σε μια κλίμακα 3 βαθμίδων από 1 (καθόλου ενδιαφέρον - no interest) έως 3 (πολύ ενδιαφέρον - very interested).
Αν θέλετε να υπολογίσετε το μέσο όρο της μεταβλητής, τότε απαιτείται η μεταβλητή να είναι δηλωμένη ως αριθμητική (num). Αν, όμως, θέλετε να συγκρίνετε την ομάδα των ατόμων που έδωσαν την απάντηση 1 με εκείνους που έδωσαν την απάντηση 3, είναι απαραίτητο η Interest να δηλωθεί στην R ως Factor.
Αν δημιουργήσατε σωστά τη νέα μεταβλητή με την Fingers$InterestFactor <- as.factor(Fingers$Interest) και την εκτελέσατε, δεν εμφανίστηκε κάποιο μήνυμα. Αυτό συμβαίνει επειδή η απλή δημιουργία μιας νέας μεταβλητής δεν προκαλεί αυτόματα την εμφάνιση αποτελεσμάτων. Όταν δεν εμφανίζεται τίποτα μπορεί να έχετε την εντύπωση ότι κάνατε κάτι λάθος, αλλά απλώς δεν έχετε δώσει στην R εντολή να εμφανίσει κάτι.
Η εντολή str() εμφανίζει τον τύπο κάθε μεταβλητής σε ένα πλαίσιο δεδομένων. Στον κώδικα που γράψατε, δώσατε στην R εντολή να δημιουργήσει μια νέα μεταβλητή τύπου Factor, την Fingers$InterestFactor, που βασίζεται στην αριθμητική μεταβλητή Fingers$Interest. Για να ελέγξετε αν η μετατροπή ήταν επιτυχής, μπορείτε να πληκτρολογήσετε str(Fingers) στο παρακάτω πλαίσιο κώδικα.
Το αποτέλεσμα θα δείξει ότι το πλαίσιο δεδομένων Fingers περιλαμβάνει πλέον μια νέα μεταβλητή, την Fingers$InterestFactor, και θα επιβεβαιώσει ότι αυτή η νέα μεταβλητή είναι τύπου Factor.
Παρατηρήστε ότι οι δύο μεταβλητές, Interest και InterestFactor, είναι διαφορετικού τύπου. Η Interest επισημαίνεται ως αριθμητική (num), αλλά η InterestFactor επισημαίνεται τώρα ως Factor w/ 3 levels "1","2","3". Τα τρία επίπεδα (levels) αντιπροσωπεύουν τις διαφορετικές τιμές (ή κατηγορίες) αυτής της ποιοτικής μεταβλητής.
Αν θέλατε να μάθετε πόσοι φοιτητές υπάρχουν στο πλαίσιο δεδομένων Fingers, ποια ή ποιες από τις παρακάτω εντολές θα μπορούσε να σας βοηθήσει;
Επεξήγηση
Όλες οι παραπάνω εντολές θα μπορούσαν να σας βοηθήσουν να μάθετε πόσοι φοιτητές υπάρχουν:
Fingers: Εμφανίζει όλο το πλαίσιο δεδομένων, από όπου μπορείτε να μετρήσετε τις γραμμές
tail(Fingers): Εμφανίζει τις τελευταίες γραμμές και δείχνει τον αριθμό της τελευταίας γραμμής
str(Fingers): Δείχνει τη δομή των δεδομένων, συμπεριλαμβανομένου του αριθμού των παρατηρήσεων (obs.)
Επιπλέον χρήσιμες εντολές: - nrow(Fingers): Δίνει τον ακριβή αριθμό των γραμμών - dim(Fingers): Δίνει το μέγεθος του πλαισίου δεδομένων (γραμμές x στήλες)
3.7 Μεταβλητές και Τιμές Μεταβλητών
Είναι σημαντικό να γίνεται διάκριση μεταξύ της μεταβλητής (π.χ., Ύψος, Φύλο ή Μέλη Οικογένειας) και της τιμής της μεταβλητής που αποδίδεται σε κάθε παρατήρηση του δείγματος (π.χ., 180 για το ύψος σε εκατοστά ή 2 για την κωδικοποίηση του γυναικείου φύλου). Μια μεταβλητή μπορεί να λάβει πολλαπλές διαφορετικές τιμές.
Ο ελάχιστος αριθμός μοναδικών τιμών που μπορεί να λάβει μια μεταβλητή είναι δύο: η παρουσία (1) ή η απουσία (0) ενός συγκεκριμένου χαρακτηριστικού. Για παράδειγμα, μια μεταβλητή μπορεί να κωδικοποιηθεί ως 1 εάν κάποιος είναι απόφοιτος πανεπιστημίου, ή 0 εάν δεν είναι. Αν μια μεταβλητή μπορούσε να λάβει μόνο μία πιθανή τιμή, δεν θα υπήρχε μεταβλητότητα και, επομένως, δεν θα ήταν πραγματική μεταβλητή (αλλά σταθερά). Ωστόσο, οι ποσοτικές μεταβλητές μπορούν να λάβουν θεωρητικά άπειρο αριθμό πιθανών τιμών.
Κατά την κωδικοποίηση των τιμών μιας μεταβλητής με αριθμητικές τιμές, είναι απαραίτητο να λαμβάνεται υπόψη η σημασία των αριθμών. Η τιμή 2 έχει πολύ διαφορετικό νόημα εάν αντιπροσωπεύει το φύλο ενός ατόμου (π.χ., άνδρας) από ό,τι εάν αντιπροσωπεύει το ύψος του σε εκατοστά (πολύ κοντός!). Όταν χρησιμοποιείται στατιστικό λογισμικό για την ανάλυση δεδομένων, το λογισμικό επεξεργάζεται τους αριθμούς, αλλά δεν γνωρίζει την πραγματική τους σημασία. Αυτή η γνώση έγκειται αποκλειστικά στον ερευνητή.
Ας εξετάσουμε τη μεταβλητή Gender στο σύνολο δεδομένων Fingers. Όπως προαναφέρθηκε, για να έχουμε πρόσβαση στις τιμές μίας μόνο μεταβλητής, προσδιορίζεται πρώτα το πλαίσιο δεδομένων προέλευσης (Fingers) και στη συνέχεια χρησιμοποιείται το σύμβολο "$" πριν από το όνομα της μεταβλητής (Gender).
Σε αυτό το αποτέλεσμα, ποια είναι η μεταβλητή;
Στο ίδιο αποτέλεσμα, ποιες είναι οι τιμές;
Σφάλμα Μέτρησης
Οι φοιτητές μέτρησαν τους δικούς τους αντίχειρες για να καταλήξουν στις μετρήσεις που βρίσκονται στο πλαίσιο δεδομένων Fingers. Αν κάθε φοιτητής ζητούσε τώρα από έναν φίλο του να μετρήσει εκ νέου τον αντίχειρά του, πιστεύετε ότι ο φίλος του θα έβγαζε ακριβώς την ίδια μέτρηση; Γιατί ή γιατί όχι;
Για να ολοκληρωθεί η εισαγωγή μας στην έννοια της μέτρησης, είναι σημαντικό να επισημανθεί ότι οι μετρήσεις συνήθως εμπεριέχουν σφάλμα. Για παράδειγμα, ας υποθέσουμε ότι δύο άτομα μετρούν τον ίδιο αντίχειρα. Το ένα άτομο υποστηρίζει ότι το μήκος του αντίχειρα είναι 56mm, ενώ το άλλο υποστηρίζει ότι είναι 57mm. Ποια είναι η σωστή μέτρηση; 56 ή 57mm; Το πραγματικό μήκος είναι πιθανότατα κάπου ανάμεσα σε αυτές τις δύο τιμές. Αυτή η απόκλιση ονομάζεται σφάλμα μέτρησης και αναφέρεται στο γεγονός ότι οι μετρήσεις ενδέχεται να αποκλίνουν ελαφρώς, θετικά ή αρνητικά, από την πραγματική τιμή.
Το σφάλμα μέτρησης διαφέρει από μια λανθασμένη μέτρηση. Για παράδειγμα, εάν ένας φοιτητής μετρήσει τον αντίχειρα σε εκατοστά αντί για χιλιοστά, αυτό θα ήταν ένα λάθος στη μέτρηση. Ωστόσο, το σφάλμα μέτρησης είναι διαφορετικό. Ακόμη και όταν καταβληθεί κάθε δυνατή προσπάθεια για ακριβή μέτρηση, είναι πολύ πιθανό να υπάρξει μια μικρή απόκλιση από την πραγματικότητα. Οι περισσότερες μετρήσεις εμπεριέχουν κάποιο βαθμό σφάλματος μέτρησης.
Το σφάλμα μέτρησης μπορεί να προκύψει για διάφορους λόγους. Ορισμένοι μετρούν το μήκος του αντίχειρα συμπεριλαμβάνοντας το πλάτος της πτυχής μεταξύ του αντίχειρα και της παλάμης (όπως στο σχήμα παρακάτω), ενώ άλλοι όχι. Επίσης, ένας φοιτητής μπορεί να χρησιμοποιήσει έναν άκαμπτο χάρακα, ενώ ένας άλλος μια μεζούρα. Ακόμη και ο φωτισμός του δωματίου μπορεί να διαφέρει για τους δύο φοιτητές.
Σχήμα 3.1: Εικόνα χεριού με γραμμές μέτρησης
Ορισμένες μετρήσεις περιέχουν περισσότερο σφάλμα από άλλες. Το ύψος και το μήκος του αντίχειρα είναι σχετικά εύκολο να μετρηθούν, αλλά τι γίνεται με τη μέτρηση αφηρημένων εννοιών όπως η κατάθλιψη, η νοημοσύνη ή η υγεία; Αυτά είναι σημαντικά χαρακτηριστικά, αλλά η μέτρησή τους μπορεί να είναι ιδιαίτερα δύσκολη. Όσο πιο δύσκολο είναι να μετρηθεί κάτι, τόσο περισσότερο σφάλμα μέτρησης αναμένεται να περιέχει.
Ακόμη και αν μια μέτρηση περιέχει σφάλμα, αυτό δεν σημαίνει απαραίτητα ότι είναι μεροληπτική. Το σφάλμα απλώς υποδηλώνει ότι υπάρχει μεταβλητότητα στη μέτρηση, ακόμη και όταν είναι γνωστό ότι το αντικείμενο που μετράται δεν παρουσιάζει μεταβλητότητα. Εάν 10 άτομα λάβουν διαφορετικές μετρήσεις του αντίχειρα του ίδιου ατόμου, οι μετρήσεις είναι που διαφέρουν, όχι το μήκος του αντίχειρα του ατόμου. Η μέτρηση θεωρείται αμερόληπτη (unbiased) εάν το σφάλμα είναι εξίσου πιθανό να είναι προς τα πάνω ή προς τα κάτω ανάμεσα σε διαφορετικές μετρήσεις του ίδιου χαρακτηριστικού, εξισσοροπώντας έτσι το σφάλμα γύρω από την πραγματική τιμή.
Ωστόσο, η μέτρηση μπορεί επίσης να είναι μεροληπτική (biased). Μια μεροληπτική μέτρηση είναι συστηματικά προς τα πάνω ή προς τα κάτω. Δηλαδή, το σφάλμα δεν μεταβάλλεται τυχαία γύρω από την πραγματική τιμή, αλλά ωθεί τη μέτρηση προς μία συγκεκριμένη κατεύθυνση. Για παράδειγμα, εάν τα 10 άτομα που μετρούν τον ίδιο αντίχειρα στρογγυλοποιούν το αποτέλεσμα προς τα πάνω στο επόμενο χιλιοστό, όλες οι μετρήσεις θα είναι ελαφρώς μεγαλύτερες από το πραγματικό μήκος του αντίχειρα. Αντίθετα, στο αμερόληπτο σφάλμα, ορισμένοι στρογγυλοποιούν προς τα κάτω, ορισμένοι προς τα πάνω και ορισμένοι δεν στρογγυλοποιούν καθόλου. Παρόλο που αυτές οι μετρήσεις θα περιείχαν επίσης σφάλμα, αυτό θα θεωρούνταν αμερόληπτο. Το αν το σφάλμα είναι ή δεν είναι μεροληπτικό είναι κάτι που πρέπει να λαμβάνεται υπόψη κατά την ανάλυση των δεδομένων που προκύπτουν από τις μετρήσεις.
3.8 Δειγματοληψία από έναν Πληθυσμό
Η μετατροπή της μεταβλητότητας του πραγματικού κόσμου σε δεδομένα κατάλληλα προς ανάλυση απαιτεί τη συμμετοχή μας σε δύο θεμελιώδεις διαδικασίες: τη μέτρηση (measurement) και τη δειγματοληψία (sampling). Έχοντας αναφερθεί εκτενώς στη μέτρηση, θα επικεντρωθούμε στη δειγματοληψία.
Ένα σχέδιο δειγματοληψίας βασίζεται σε δύο κρίσιμες αποφάσεις. Πρώτον, οφείλουμε να καθορίσουμε τις παρατηρήσεις που θα συμπεριληφθούν στο σύνολο των παρατηρήσεων προς μέτρηση. Ενώ αυτό μπορεί να φαίνεται απλό, στην πραγματικότητα δεν είναι. Καθορίζοντας ποιες παρατηρήσεις θα συμπεριληφθούν, ουσιαστικά δηλώνουμε ότι αυτές οι παρατηρήσεις αποτελούν παραδείγματα της ίδιας κατηγορίας πραγμάτων. Αυτή η κατηγορία παρατηρήσεων αναφέρεται ως πληθυσμός (population). Δεδομένου του μεγάλου συνήθως μεγέθους του πληθυσμού, μια μελέτη περιορίζεται συνήθως σε ένα δείγμα του πληθυσμού.
Για παράδειγμα, ας υποθέσουμε ότι επιθυμούμε να διεξάγουμε μια μελέτη για άτομα εθισμένα στα τυχερά παιχνίδια, με σκοπό την κατανόηση των αποτελεσματικότερων τρόπων υποστήριξής τους για την αντιμετώπιση του εθισμού τους. Ποιοι θεωρούνται εθισμένοι στα τυχερά παιχνίδια; Ένα άτομο που στοιχηματίζει σε αθλητικά γεγονότα το μεγαλύτερο μέρος της ημέρας και σε καθημερινή βάση σαφώς θα συμπεριλαμβανόταν στον πληθυσμό. Τι γίνεται όμως με κάποιο άτομο που στοιχηματίζει περιστασιακά; Ή με κάποιο άτομο που έχει ήδη χάσει μια περιουσία και δεν έχει πλέον τη δυνατότητα να στοιχηματίσει; Όπως γίνεται αντιληπτό, η κατανόησή μας για τους εθισμένους στα τυχερά παιχνίδια επηρεάζεται άμεσα από τον τρόπο με τον οποίο ορίζουμε τον «εθισμό στα τυχερά παιχνίδια».
Δεύτερον, οφείλουμε να καθορίσουμε τον τρόπο επιλογής των παρατηρήσεων από τον καθορισμένο πληθυσμό που θα επιλεγούν και θα μετρηθούν. Οι περισσότερες στατιστικές μέθοδοι που θα εξετάσουμε σε αυτό το μάθημα προϋποθέτουν ότι το δείγμα έχει επιλεγεί τυχαία και ανεξάρτητα από τον καθορισμένο πληθυσμό.
Τυχαία Δειγματοληψία
Για να θεωρηθεί ένα δείγμα τυχαία επιλεγμένο (random), κάθε μέλος του πληθυσμού πρέπει να έχει την ίδια πιθανότητα να επιλεγεί για συμμετοχή στη μελέτη. Στην πράξη, η επίτευξη αυτού του στόχου είναι δύσκολη. Ωστόσο, ακόμη και αν δεν είναι δυνατή η λήψη ενός αμιγώς τυχαίου δείγματος, πρέπει τουλάχιστον να επιδιώξουμε να κάνουμε ό,τι μπορούμε για να διασφαλίσουμε ότι το δείγμα μας είναι αντιπροσωπευτικό του πληθυσμού που στοχεύουμε να μελετήσουμε.
Για παράδειγμα, ας υποθέσουμε ότι θέλουμε να αξιολογήσουμε πώς άτομα από διαφορετικές χώρες βαθμολογούν τα συναισθήματά τους σχετικά με την ευημερία που νιώθουν. Ποια άτομα πρέπει να συμπεριλάβουμε στη μελέτη; Άτομα από αστικές ή αγροτικές περιοχές; Άτομα με χαμηλό ή υψηλό εισόδημα; Ποιες ηλικίες; Παρόλο που η επιλογή ενός αμιγώς τυχαίου δείγματος από τον πληθυσμό μπορεί να είναι περίπλοκη, χρειάζεται να διασφαλίσουμε ότι υπάρχει επαρκής εκπροσώπηση ατόμων από διαφορετικές ηλικιακές ομάδες, διαφορετικό κοινωνικοοικονομικό επίπεδο και διαφορετικές γεωγραφικές περιοχές, ώστε να εξασφαλιστεί η αντιπροσωπευτικότητα εντός της κάθε χώρας.
Ανεξαρτησία Δειγματοληψίας
Η έννοια της ανεξαρτησίας (independence) συνδέεται στενά με την τυχαιότητα. Στο πλαίσιο της δειγματοληψίας, η ανεξαρτησία σημαίνει ότι η επιλογή μιας παρατήρησης (π.χ., ενός ατόμου, ενός αυτοκινήτου, μιας οικογένειας) για μια μελέτη δεν επηρεάζει την επιλογή μιας άλλης παρατήρησης. Δηλαδή, εάν επιλεγούν δύο παρατηρήσεις, η επιλογή τους γίνεται ανεξάρτητα και αποκλειστικά με τυχαίο τρόπο.
Όπως και η τυχαιότητα, η υπόθεση της ανεξαρτησίας συχνά παραβιάζεται στην πράξη. Για παράδειγμα, μπορεί να είναι πρακτικό να συμπεριληφθούν σε μια μελέτη δύο παιδιά από την ίδια οικογένεια – φανταστείτε το χρόνο που θα εξοικονομούσατε αποφεύγοντας την αναζήτηση ενός ακόμη παιδιού, επιλεγμένου ανεξάρτητα και τυχαία!
Ωστόσο, αυτό δημιουργεί ένα πρόβλημα: εάν δύο παιδιά προέρχονται από την ίδια οικογένεια, είναι πιθανό να είναι παρόμοια μεταξύ τους σε οποιαδήποτε μεταβλητή μελετάμε, ή τουλάχιστον πιο παρόμοια από ό,τι θα ήταν ένα τυχαία επιλεγμένο ζεύγος παιδιών. Αυτή η απουσία ανεξαρτησίας στη δειγματοληψία θα μπορούσε να οδηγήσει σε εσφαλμένα συμπεράσματα από την ανάλυση των δεδομένων.
Μεταβλητότητα Δειγματοληψίας
Κάθε δείγμα που λαμβάνουμε από τον πληθυσμό –ιδίως εάν πρόκειται για μικρά δείγματα– θα παρουσιάζει διαφοροποιήσεις. Δηλαδή, τα δείγματα θα διαφέρουν μεταξύ τους. Επιπλέον, κανένα δείγμα δεν θα είναι απολύτως αντιπροσωπευτικό του πληθυσμού. Αυτή η μεταβλητότητα αναφέρεται ως μεταβλητότητα δειγματοληψίας ή σφάλμα δειγματοληψίας (sampling error). Όπως και το σφάλμα μέτρησης, το σφάλμα δειγματοληψίας μπορεί να είναι είτε μεροληπτικό είτε αμερόληπτο.
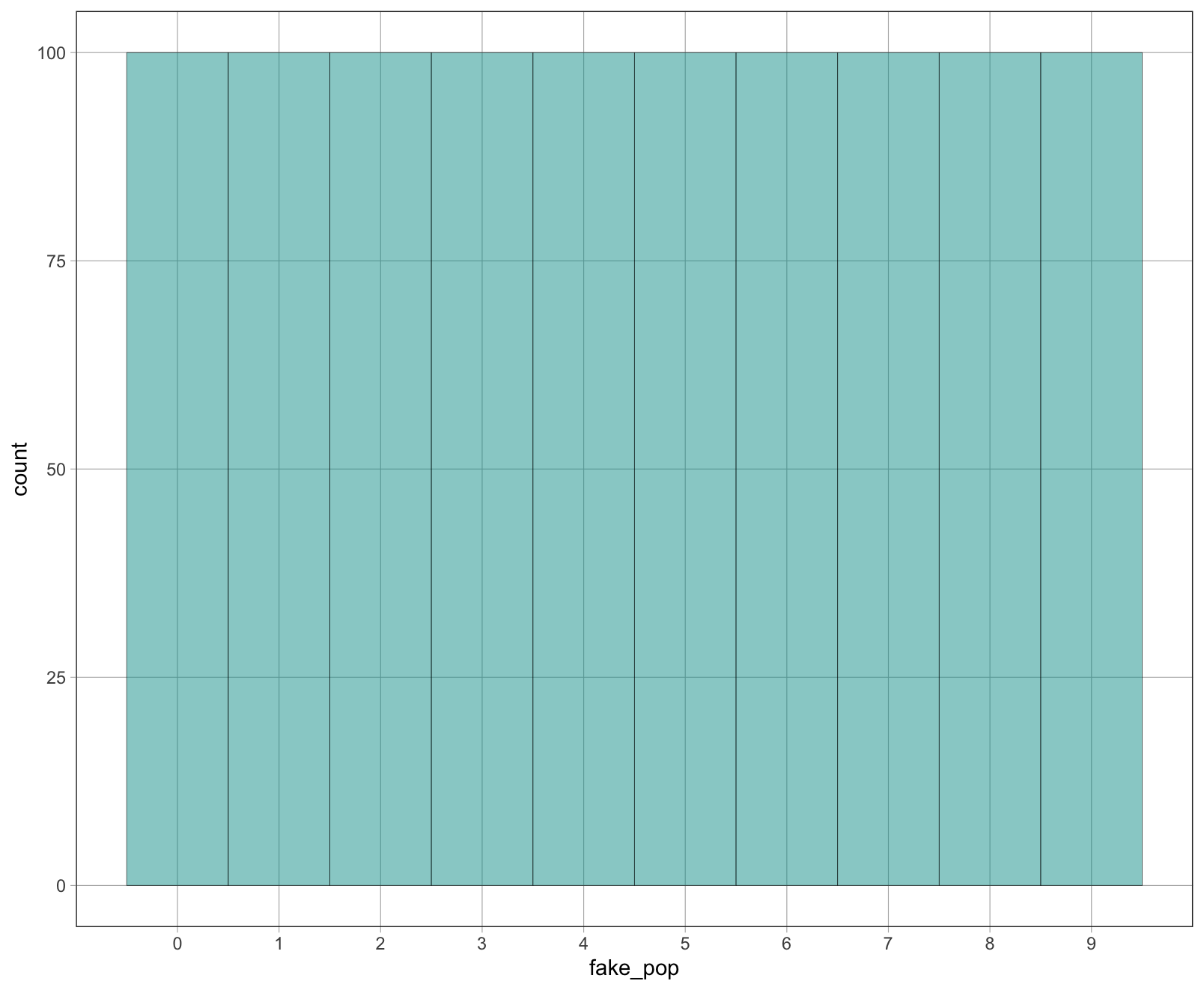
Για παράδειγμα, έχουμε δημιουργήσει ένα διάνυσμα με το όνομα fake_pop (για έναν ψεύτικο πληθυσμό), το οποίο περιέχει 100 μηδενικά, 100 άσους, 100 δυάρια, 100 τριάρια, και ούτω καθεξής για τους αριθμούς από το 0 έως το 9. Ακολουθεί ένα διάγραμμα που απεικονίζει ότι υπάρχουν 100 από κάθε ψηφίο σε αυτόν τον ψεύτικο πληθυσμό.
Σχήμα 3.2: Ένα ιστόγραμμα της κατανομής των αριθμών στο fake_pop. Η κατανομή είναι ομοιόμορφη.
Ας λάβουμε τώρα ένα τυχαίο δείγμα 10 αριθμών από το διάνυσμα fake_pop και ας αποθηκεύσουμε το αποτέλεσμα σε ένα διάνυσμα με το όνομα random_sample. Η R παρέχει μια συνάρτηση γι’ αυτό, που ονομάζεται sample().
Πιστεύετε ότι το ιστόγραμμα του τυχαίου δείγματος των 10 ατόμων θα μοιάζει ακριβώς με το ιστόγραμμα ολόκληρου του πληθυσμού; Γιατί ή γιατί όχι;
Εκτελέστε τον παρακάτω κώδικα για να λάβετε ένα τυχαίο δείγμα 10 αριθμών από το fake_pop και αποθηκεύστε το στο random_sample. Έχουμε επίσης συμπεριλάβει κώδικα για τη δημιουργία ενός ιστογράμματος, αλλά δεν χρειάζεται να ανησυχείτε για αυτό το μέρος. Θα δημιουργήσουμε ιστογράμματα μαζί στο Κεφάλαιο 3.
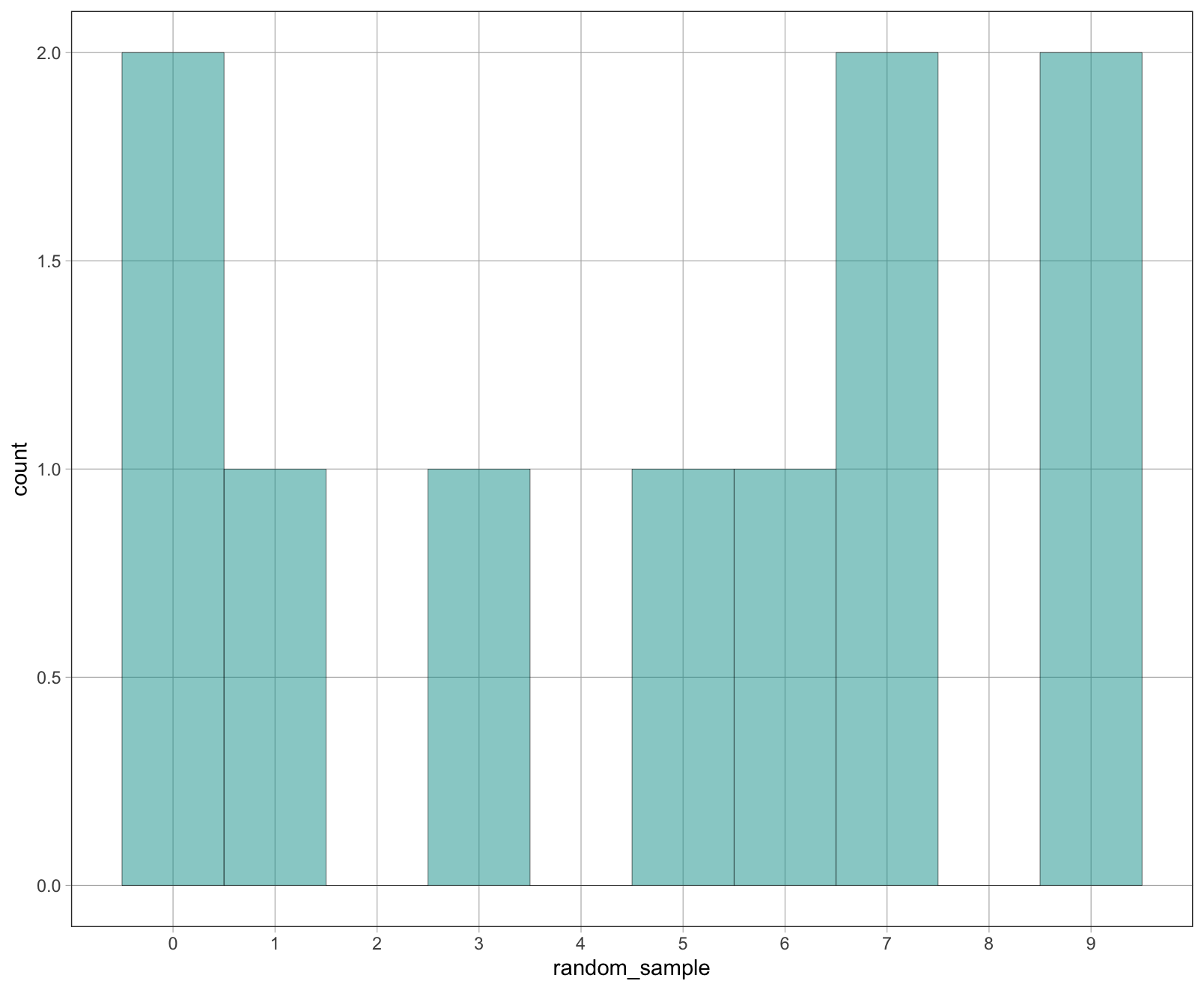
Μπορείτε να εκτελέσετε τον παραπάνω κώδικα μερικές φορές για να δείτε το ιστόγραμμα για διαφορετικά τυχαία δείγματα. Θα παρατηρήσετε ότι αυτά τα δείγματα διαφέρουν τόσο μεταξύ τους όσο και από τον πληθυσμό από τον οποίο προήλθαν. Παρακάτω απεικονίζουμε ένα παράδειγμα τυχαίου δείγματος 10 αριθμών από το fake_pop.
Σχήμα 3.3: Ένα ιστόγραμμα της κατανομής των αριθμών ενός τυχαίου δείγματος που αντλήθηκε από το fake_pop. Η κατανομή δεν είναι ομοιόμορφα κατανεμημένη.
Γιατί αυτό το τυχαίο δείγμα δεν μοιάζει με τον πληθυσμό από τον οποίο προήλθε;
Παρατηρήστε ότι ακόμη και ένα τυχαίο δείγμα δεν θα «μοιάζει» ακριβώς με τον πληθυσμό από τον οποίο προήλθε. Αυτή είναι η θεμελιώδης ιδέα της μεταβλητότητας δειγματοληψίας και τη συναντάμε συχνά στη στατιστική.
Η μεροληψία στο πλαίσιο της δειγματοληψίας σημαίνει ότι ορισμένα μέλη του πληθυσμού έχουν μεγαλύτερη πιθανότητα από άλλα να συμπεριληφθούν στο δείγμα, ενώ δεν υπάρχουν περισσότερα από αυτά τα μέλη στον πληθυσμό. Αυτό παραβιάζει τις προϋποθέσεις ενός ανεξάρτητου, τυχαίου δείγματος.
Όπως είδαμε στο παραπάνω παράδειγμα, λόγω της μεταβλητότητας δειγματοληψίας, κανένα δείγμα δεν θα αντιπροσωπεύει τέλεια τον πληθυσμό. Ωστόσο, εάν επιλέγουμε ανεξάρτητα, τυχαία δείγματα, μπορούμε τουλάχιστον να γνωρίζουμε ότι το δείγμα μας είναι αμερόληπτο –δεν είναι πιο πιθανό να είναι λανθασμένο προς μια συγκεκριμένη κατεύθυνση παρά προς μια άλλη. Έτσι, παρόλο που τα τυχαία δείγματά μας δεν θα μοιάζουν ακριβώς με τον πληθυσμό, θα είναι αμερόληπτα, καθώς δεν είναι πιο πιθανό να είναι λανθασμένα με έναν συστηματικό τρόπο (π.χ., δειγματοληψία μόνο ζυγών αριθμών ή μεγάλων αριθμών).
Στην πράξη, η επίτευξη τέλειας τυχαίας δειγματοληψίας είναι συχνά δύσκολη λόγω πρακτικών περιορισμών, γι’ αυτό οι ερευνητές χρησιμοποιούν εναλλακτικές μεθόδους πιθανοτικής δειγματοληψίας, όπως η στρωματοποιημένη δειγματοληψία (stratified sampling), η συστηματική δειγματοληψία (systematic sampling), και η δειγματοληψία κατά συστάδες (cluster sampling), οι οποίες μπορεί να είναι πιο εφικτό να πραγματοποιηθούν ενώ παραμένουν στατιστικά έγκυρες.
3.9 Η Δομή των Δεδομένων
Τα δεδομένα εμφανίζονται σε ποικίλες μορφές. Όταν συλλέγετε δεδομένα, μπορεί να ξεκινήσετε με αριθμούς καταγεγραμμένους σε χαρτί. Εναλλακτικά, ενδέχεται να λάβετε ένα αρχείο υπολογιστή που περιέχει αριθμητικά και κειμενικά δεδομένα διαφόρων τύπων, όπου κάθε στοιχείο αντιστοιχεί στην τιμή μιας παρατήρησης του δείγματος σε μια μεταβλητή ενδιαφέροντος.
Ανεξάρτητα από την αρχική μορφή των δεδομένων, είναι απαραίτητη η οργάνωση και η μορφοποίησή τους, ώστε να διευκολύνεται η ανάλυσή τους με λογισμικό στατιστικής επεξεργασίας. Αν και δεν υπάρχει ένας μοναδικός τρόπος οργάνωσης των δεδομένων, η χρήση της προσέγγισης των «τακτοποιημένων δεδομένων» (tidy data) είναι η πλέον ενδεδειγμένη και συνιστάται. Η κατανόηση των τακτοποιημένων δεδομένων διευκολύνει την κατανόηση της οργάνωσης πολλών συνόλων δεδομένων, διευκολύνοντας τη συνεργασία μεταξύ ερευνητών και την ανάλυση δεδομένων από διαφορετικές πηγές.
Ο στατιστικολόγος Hadley Wickham εισήγαγε την έννοια των τακτοποιημένων δεδομένων (tidy data), η οποία αφορά στην οργάνωση των δεδομένων σε ορθογώνιους πίνακες με γραμμές και στήλες, σύμφωνα με τις ακόλουθες αρχές:
Κάθε στήλη αντιπροσωπεύει μια μεταβλητή.
Κάθε γραμμή αντιπροσωπεύει μια παρατήρηση (ή υποκείμενο/αντικείμενο/περίπτωση) στην οποία αντιστοιχεί μια μέτρηση).
Διαφορετικά είδη παρατηρήσεων αποθηκεύονται σε ξεχωριστό πίνακα.
Όπως είδαμε, ορθογώνιοι πίνακες αυτού του είδους αναπαρίστανται στην R με τη χρήση του πλαισίου δεδομένων (data frame). Οι στήλες αντιστοιχούν στις μεταβλητές και περιέχουν τα αποτελέσματα των μετρήσεων. Οι γραμμές αντιστοιχούν στις παρατηρήσεις που συμπεριλήφθηκαν στο δείγμα. Τα πλαίσια δεδομένων επιτρέπουν την αποθήκευση επιπλέον πληροφοριών, όπως οι επικεφαλίδες των στηλών (δηλαδή, τα ονόματα των μεταβλητών), στον ίδιο πίνακα με τις πραγματικές τιμές των δεδομένων.
Η τελευταία αρχή υποδεικνύει ότι διαφορετικά είδη παρατηρήσεων που σχηματίζουν τις γραμμές δεν πρέπει να συμπεριλαμβάνονται στον ίδιο πίνακα. Για παράδειγμα, δεν θα συνδυάζατε γραμμές φοιτητών με γραμμές αυτοκινήτων, χωρών ή ζευγαριών. Εάν έχετε ένα μείγμα ειδών παρατηρήσεων (π.χ., φοιτητές, οικογένειες, χώρες), κάθε είδος πρέπει να αποθηκεύεται σε διαφορετικό πίνακα.
Gender
RaceEthnic
FamilyMembers
SSLast
Year
Job
1
male
Asian
7
NA
3
Not Working
2
female
Asian
5
7
2
Not Working
3
female
Latino
2
2
2
Part-time Job
4
male
Asian
4
9
2
Part-time Job
5
female
Asian
3
8
3
Part-time Job
6
female
White
8
7
3
Part-time Job
Στο πλαίσιο δεδομένων Fingers, μέρος του οποίου εμφανίζεται παραπάνω, τι αντιπροσωπεύουν οι στήλες;
Τι αντιπροσωπεύουν οι γραμμές;
Επιλογή Μεταβλητών με την select()
Σε ορισμένες περιπτώσεις, είναι επιθυμητή η εστίαση της ανάλυσης σε ένα υποσύνολο των μεταβλητών ενός πλαισίου δεδομένων. Για παράδειγμα, μπορεί να επιθυμείτε να εξετάσετε μόνο τις μεταβλητές Gender και Thumb στο πλαίσιο δεδομένων Fingers. Η αναγνωσιμότητα των αποτελεσμάτων βελτιώνεται όταν επιλέγεται μικρότερος αριθμός μεταβλητών.
Η συνάρτηση select() επιτρέπει την επιλογή ενός υποσυνόλου των μεταβλητών. Κατά τη χρήση της select(), πρέπει να καθορίσετε το πλαίσιο δεδομένων και τις μεταβλητές που θα επιλεγούν από αυτό.
select(Fingers, Gender, Thumb)
Κάντε μια πρόβλεψη. Ποιο πιστεύετε ότι θα είναι το αποτέλεσμα αν εκτελέσετε τον παραπάνω κώδικα;
Ενδέχεται να χρειαστεί να μετακινηθείτε πάνω-κάτω για να δείτε ολόκληρο το αποτέλεσμα, καθώς η συνάρτηση select() εμφανίζει όλες τις τιμές των επιλεγμένων μεταβλητών. Η select() επιστρέφει ένα νέο πλαίσιο δεδομένων με το επιλεγμένο υποσύνολο στηλών.
Για να δείτε μόνο μερικές γραμμές από μερικές μεταβλητές, μπορείτε να συνδυάσετε τις συναρτήσεις head() και select(), ως εξής: head(select(Fingers, Gender, Thumb))
Επιλογή Παρατηρήσεων με την filter()
Η συνάρτηση select() επιτρέπει την επιλογή ενός υποσυνόλου μεταβλητών, ενώ η filter() επιτρέπει την επιλογή ενός υποσυνόλου παρατηρήσεων. Για παράδειγμα, το πρώτο άτομο στο πλαίσιο δεδομένων Fingers έχει αντίχειρα μήκους 66mm. Είναι το μοναδικό άτομο με αντίχειρα 66mm; Ας εξετάσουμε όλους τους φοιτητές με μήκος αντίχειρα 66mm.
Θα μπορούσαμε να χρησιμοποιήσουμε τη συνάρτηση select() για να επιλέξουμε μόνο τους φοιτητές του πλαισίου δεδομένων Fingers που έχουν μήκος αντίχειρα 66mm;
Ενώ η select() επιλέγει ένα υποσύνολο των μεταβλητών (ή στηλών του πλαισίου δεδομένων), για την εξαγωγή ενός υποσυνόλου των παρατηρήσεων (ή γραμμών του πλαισίου δεδομένων) χρησιμοποιείται η συνάρτηση filter(). Αυτή η συνάρτηση φιλτράρει το πλαίσιο δεδομένων, ώστε να εμφανίσει μόνο τις παρατηρήσεις που πληρούν συγκεκριμένα κριτήρια. Ο παρακάτω κώδικας επιστρέφει μόνο τις παρατηρήσεις όπου το μήκος του αντίχειρα είναι 66 mm:
Κάντε μια πρόβλεψη. Ποιο πιστεύετε ότι θα είναι το αποτέλεσμα αν εκτελέσετε αυτόν τον κώδικα;
Τι μπορείτε να δείτε σε αυτό το αποτέλεσμα;
Όπως η select(), η συνάρτηση filter() επιστρέφει ένα πλαίσιο δεδομένων. Στην περίπτωση αυτή, το πλαίσιο δεδομένων έχει μόνο δύο γραμμές, επειδή μόνο δύο φοιτητές στο πλαίσιο δεδομένων Fingers είχαν αντίχειρες μήκους 66mm.
Ποιο θα είναι το αποτέλεσμα της εκτέλεσης αυτού του κώδικα;select(Fingers, Gender, Thumb, Index, Middle, Ring, Pinkie)
Επεξήγηση
Η συνάρτηση select()επιλέγει στήλες (μεταβλητές) από ένα πλαίσιο δεδομένων. Στο παράδειγμα:
Το αρχικό Fingers έχει πολλές στήλες (Gender, RaceEthnic, FamilyMembers, κ.λπ.)
Η select() θα κρατήσει μόνο τις 5 καθορισμένες στήλες: Gender, Thumb, Index, Middle, Ring, Pinkie
Όλες οι γραμμές (παρατηρήσεις/φοιτητές) θα παραμείνουν
Το αποτέλεσμα είναι πλαίσιο δεδομένων με λιγότερες στήλες αλλά τον ίδιο αριθμό γραμμών
save(): Αυτή αποθηκεύει αντικείμενα σε αρχεία (.RData), όχι σε μεταβλητές
==: Αυτός είναι τελεστής σύγκρισης (“ίσον με”), όχι ανάθεσης
“Δεν μπορείτε να αποθηκεύσετε”: Λάθος - μπορούμε πάντα να αποθηκεύουμε αποτελέσματα
Θυμηθείτε:<- για ανάθεση, == για σύγκριση!
Παρατηρήσεις, Μεταβλητές και Τιμές Μεταβλητών
Συχνά οι φοιτητές δυσκολεύονται να διακρίνουν τις παρατηρήσεις (π.χ., φοιτητές, που βρίσκονται στις γραμμές), τις μεταβλητές (π.χ., Thumb ή Gender, που βρίσκονται στις στήλες) και τις τιμές που μπορεί να λάβει μια μεταβλητή (π.χ., 66 ή male, που βρίσκονται στα κελιά του πίνακα). Είναι χρήσιμο να εξετάζετε τις γραμμές και τις στήλες ενός πλαισίου δεδομένων όταν αναφέρεστε σε παρατηρήσεις και μεταβλητές, αντίστοιχα. Εάν τα δεδομένα είναι τακτοποιημένα, οι γραμμές αντιπροσωπεύουν πάντα παρατηρήσεις και οι στήλες, μεταβλητές.
Σε αυτό το μάθημα τα περισσότερα από τα δεδομένα θα είναι σε «τακτοποιημένη» μορφή. Έχετε ήδη εξοικειωθεί με αυτή τη μορφή. Ωστόσο, τα πραγματικά δεδομένα δεν είναι πάντα τακτοποιημένα. Ενδέχεται να χρειαστεί να μετατρέψετε ένα μη-τακτοποιημένο σύνολο δεδομένων σε τακτοποιημένο.
3.10 Ελλείπουσες Τιμές
Μετά την οργάνωση των δεδομένων σε τακτοποιημένη μορφή, είναι δυνατή η χρήση εντολών της R για τη στατιστική τους επεξεργασία. Στην ενότητα αυτή, θα εξετάσουμε τη διαχείριση των ελλειπουσών τιμών, ενώ στην επόμενη ενότητα θα παρουσιάσουμε τη δημιουργία νέων μεταβλητών και την αλλαγή της κωδικοποίησης υπαρχουσών.
Αναγνώριση Ελλειπουσών Τιμών
Κατά τη συλλογή των δεδομένων είναι σύνηθες να προκύπτουν ελλείπουσες τιμές (missing values). Στην R, οι ελλείπουσες τιμές αναπαρίστανται με την τιμή NA (not available – μη διαθέσιμη), επιτρέποντας στο χρήστη να αποφασίσει τον τρόπο διαχείρισής τους κατά την ανάλυση. Εάν στο σύνολο δεδομένων χρησιμοποιείται κάποιος άλλος τρόπος για την αναπαράσταση των ελλειπουσών τιμών (π.χ., η τιμή -999), είναι απαραίτητη η επανακωδικοποίηση αυτών των τιμών σε NA για να τις διαχειριστείτε σωστά στην R.
Στο πλαίσιο δεδομένων Fingers, ας εξετάσουμε το τελευταίο ψηφίο των Αριθμών Φορολογικού Μητρώου (ΑΦΜ) των φοιτητών (SSLast). Αρχικά, ταξινομήστε το πλαίσιο δεδομένων Fingers κατά αύξουσα σειρά των τιμών της μεταβλητής SSLast. Παρακάτω παρουσιάζεται κώδικας που εμφανίζει μόνο τη μεταβλητή SSLast από το πλαίσιο δεδομένων Fingers (υπενθυμίζεται ότι για να έχουμε πρόσβαση σε μια μεταβλητή ενός πλαισίου δεδομένων χρησιμοποιούμε το σύμβολο $).
Ποιες από τις παρακάτω δηλώσεις είναι αληθείς για την SSLast; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Εξετάζοντας τη μεταβλητή SSLast (τελευταίο ψηφίο ΑΦΜ):
Σωστές απαντήσεις (Α, Δ):
Α. Ελλείπουσες τιμές με NA ✓ - Το NA είναι ο τυπικός τρόποςγια να δηλωθούν ελλείπουσες τιμές στην R - Μερικοί φοιτητές δεν είχαν ΑΦΜ ή δεν θέλησαν να το μοιραστούν
Δ. Μερικοί φοιτητές εισήγαγαν τα τελευταία τέσσερα ψηφία ✓
Η οδηγία ήταν για το τελευταίο ψηφίο (0-9)
Αριθμοί όπως 7549, 6346 δείχνουν ότι δεν ακολουθήθηκε η οδηγία
Λάθος απαντήσεις:
Β & Γ: Δεν βλέπουμε 0 ή 999 ως κωδικούς ελλειπουσών τιμών
Όταν μεταφέρουμε δεδομένα στην R από άλλα λογισμικά, τα κενά (blanks) μετατρέπονται αυτόματα στην ειδική τιμή NA για μη διαθέσιμες ή ελλείπουσες τιμές. Φυσικά, υπάρχει η δυνατότητα αφαίρεσης των γραμμών (παρατηρήσεων) που περιέχουν ελλείπουσες τιμές από μια συγκεκριμένη ανάλυση ή ακόμη και από το πλαίσιο δεδομένων συνολικά.
Αφαίρεση Γραμμών με Ελλείπουσες Τιμές
Μια επιλογή είναι η δημιουργία ενός νέου πλαισίου δεδομένων που δεν περιέχει καθόλου ελλείπουσες τιμές. Η συνάρτηση na.omit() αφαιρεί όλες τις γραμμές στις οποίες οποιαδήποτε μεταβλητή έχει την τιμή NA:
Ένα πιθανό μειονέκτημα της χρήσης της συνάρτησης na.omit() είναι ότι αφαιρεί γραμμές που περιέχουν NA σε οποιαδήποτε μεταβλητή, και όχι μόνο σε μια συγκεκριμένη μεταβλητή ενδιαφέροντος (π.χ., την SSLast). Αυτό μπορεί να οδηγήσει στην αφαίρεση περισσότερων γραμμών από όσες αναμένονται.
Για να αφαιρεθούν μόνο οι γραμμές που περιέχουν NA στη μεταβλητή SSLast, είναι απαραίτητη η αναγνώριση αυτών των γραμμών. Στη συνέχεια, χρησιμοποιείται η συνάρτηση filter() για να συμπεριληφθούν μόνο οι γραμμές που δεν έχουν κωδικοποιηθεί ως NA για τη μεταβλητή SSLast.
Προσοχή: Η τιμή NA αποτελεί ειδική τιμή στην R και δεν είναι ισοδύναμη με τη συμβολοσειρά κειμένου "NA". Η ειδική συνάρτηση is.na() μπορεί να χρησιμοποιηθεί για την αναγνώριση των ελλειπουσών τιμών.
Κάντε μια πρόβλεψη: Αν ένας φοιτητής έχει τιμή NA στην SSLast, τι θα επέστρεφε η συνάρτηση is.na(Fingers$SSLast) για αυτόν τον φοιτητή;
Επεξήγηση
Η συνάρτηση is.na()ελέγχει αν μια τιμή είναι ελλείπουσα (NA):
# Αν έχουμε τις τιμές: c(5, NA, 7, NA, 2)is.na(c(5, NA, 7, NA, 2))# Επιστρέφει: FALSE TRUE FALSE TRUE FALSE
Στην περίπτωσή μας: - Ο φοιτητής έχει NA στην SSLast
Άρα η is.na() θα επιστρέψει TRUE για αυτόν το φοιτητή
Θυμηθείτε:is.na() = “Είναι αυτή η τιμή ελλείπουσα;”
Στην συγκεκριμένη περίπτωση, είναι πιο χρήσιμο να εντοπιστούν οι γραμμές όπου η μεταβλητή SSLast δεν είναι NA, αντί για εκείνες όπου είναι. Για να διατηρηθούν μόνο αυτές οι γραμμές, μπορεί να χρησιμοποιηθεί η συνάρτηση filter():
Αυτός ο κώδικας επιστρέφει ένα πλαίσιο δεδομένων που περιλαμβάνει μόνο τις παρατηρήσεις για τις οποίες η μεταβλητή SSLast δεν είναι NA. Αξίζει να υπενθυμιστεί ότι η συνάρτηση filter() επιλέγει με συμπερίληψη, και όχι με αποκλεισμό.
Όπως συμβαίνει με οποιαδήποτε λειτουργία στην R, το φιλτραρισμένο πλαίσιο δεδομένων είναι προσωρινό, εκτός αν αποθηκευτεί σε ένα αντικείμενο R. Αποθηκεύστε τα δεδομένα χωρίς τις ελλείπουσες τιμές στη μεταβλητή SSLast σε ένα νέο πλαίσιο δεδομένων με το όνομα Fingers_subset.
Ωστόσο, σημειώστε ότι η αφαίρεση παρατηρήσεων με ελλείπουσες τιμές ενδέχεται να εισάγει μεροληψία στο δείγμα.
Στην περίπτωση του πλαισίου δεδομένων Fingers_subset, τι είδους μεροληψία θα μπορούσαμε να προκαλέσουμε αν αφαιρέσουμε όλους τους φοιτητές με ελλείπουσες τιμές στο τελευταίο ψηφίο του ΑΜΚΑ τους;
3.11 Δημιουργία και Επανακωδικοποίηση Μεταβλητών
Σύνθεση Μεταβλητών
Συχνά, για τη μέτρηση ορισμένων χαρακτηριστικών χρησιμοποιούνται περισσότερες από μία μεταβλητές, καθώς καμία μεμονωμένη μεταβλητή δεν είναι επαρκής για τη μέτρησή τους. Για παράδειγμα, η μέτρηση της σχολικής επίδοσης με βάση την επίδοση σε ένα μόνο σχολικό μάθημα είναι συνήθως ανεπαρκής. Όταν υπάρχουν διαθέσιμες πολλές μεταβλητές, μπορούν να συνδυαστούν σε μια ενιαία μεταβλητή. Στην περίπτωση της σχολικής επίδοσης, ένας αντιπροσωπευτικός σύνθετος δείκτης θα μπορούσε να είναι ο μέσος όρος της βαθμολογίας σε όλα τα μαθήματα του σχολείου.
Η δημιουργία νέων μεταβλητών που συνοψίζουν τις τιμές άλλων μεταβλητών είναι συνηθισμένη πρακτική. Στο σύνολο δεδομένων Fingers, για παράδειγμα, υπάρχει μια μέτρηση για το μήκος κάθε δαχτύλου (αντίχειρας, δείκτης, μέσος, παράμεσος, μικρός) για κάθε άτομο. Κάθε άτομο αντιστοιχεί σε μια γραμμή και το μήκος κάθε δαχτύλου σε διαφορετικές στήλες.
Ενώ για ορισμένους σκοπούς μπορεί να είναι απαραίτητη η εξέταση του μήκους των δαχτύλων ξεχωριστά, μπορεί επίσης να είναι χρήσιμη η δημιουργία μιας νέας μεταβλητής βάσει των επιμέρους μηκών. Για παράδειγμα, στους περισσότερους ανθρώπους, ο δείκτης είναι μικρότερος από τον παράμεσο. Μπορούμε, επομένως, να δημιουργήσουμε μια νέα μεταβλητή με την ονομασία RingLonger που υποδεικνύει εάν ο παράμεσος ενός ατόμου είναι μακρύτερος από το δείκτη του. Αυτή η νέα μεταβλητή μπορεί να προστεθεί στο πλαίσιο δεδομένων Fingers ως νέα στήλη.
Από την εξέταση του παραπάνω κώδικα, τι είδους τιμές περιλαμβάνει η μεταβλητή RingLonger;
Επεξήγηση
Η μεταβλητή RingLonger δημιουργείται με τον κώδικα:
RingLonger <- Ring > Index
Σωστή απάντηση: Λογικές τιμές (Boolean) - TRUE ή FALSE ✓
Γιατί η μεταβλητή είναι λογική (Boolean):
Ο τελεστής > κάνει σύγκριση
Οι συγκρίσεις στην R επιστρέφουν λογικές τιμές (TRUE/FALSE)
Ring > Index ελέγχει αν το μήκος του παραμέσου είναι μεγαλύτερο από του δείκτη
Αποτελέσματα:
Αν παράμεσος > δείκτης → TRUE
Αν παράμεσος ≤ δείκτης → FALSE
Γιατί όχι τα άλλα:
Αριθμητικές τιμές: Δεν υπολογίζουμε διαφορές, κάνουμε σύγκριση
Τιμές χαρακτήρα: Δεν επιστρέφουμε κείμενο όπως “ring” ή “index”
Είδη τελεστών στην R ανά είδος μεταβλητής:
>, <, == → λογικές (TRUE/FALSE)
+, -, * → αριθμητικές
Τι σημαίνει η τιμή TRUE στο αποτέλεσμα της παραπάνω εντολής;
Επεξήγηση
Η μεταβλητή RingLonger δημιουργήθηκε με:
RingLonger <- Ring > Index
Σωστή απάντηση: Ο παράμεσος είναι μεγαλύτερος από τον δείκτη ✓
Ερμηνεία του κώδικα:
Ring > Index ελέγχει: “Είναι το μήκος του παραμέσου μεγαλύτερο από το μήκος του δείκτη;”
Α: Δεν συγκρίνουμε με όλα τα δάχτυλα, μόνο με τον δείκτη
Γ: Αυτό θα ήταν Index > Ring, όχι Ring > Index
Δ: Αυτό δεν σχετίζεται με τη σύγκριση μηκών
Θυμηθείτε: Η τιμή TRUE αντιστοιχεί στη συνθήκη που ελέγχθηκε!
Ας μετρήσουμε τον αριθμό των ατόμων με μακρύτερο παράμεσο από δείκτη.
Ερμηνεύστε τον πίνακα συχνοτήτων που προέκυψε παραπάνω. Τι σημαίνει «TRUE - 89» και «FALSE - 68»;
Επιπλέον, για τη δημιουργία νέων μεταβλητών μπορούν να χρησιμοποιηθούν αριθμητικοί τελεστές. Για παράδειγμα, ο λόγος του μήκους του δείκτη προς το μήκος του παράμεσου (Index προς Ring) χρησιμοποιείται συχνά στην ιατρική έρευνα ως ένας πρόχειρος δείκτης προγεννητικής έκθεσης σε τεστοστερόνη. Ο τελεστής διαίρεσης, /, μπορεί να χρησιμοποιηθεί για τη δημιουργία αυτής της νέας μεταβλητής.
Πώς θα αναπαρασταθεί αυτή η μεταβλητή σε ένα τακτοποιημένο πλαίσιο δεδομένων;
Επεξήγηση
Στα τακτοποιημένα δεδομένα (tidy data), οι αρχές του Hadley Wickham είναι:
Κάθε στήλη = μια μεταβλητή
Κάθε γραμμή = μια παρατήρηση
Κάθε κελί = μια τιμή
Σωστή απάντηση: Νέα στήλη στο ίδιο πλαίσιο δεδομένων ✓
Γιατί αυτή είναι η σωστή προσέγγιση: - Η IndexRingRatio είναι μια νέα μεταβλητή για τα ίδια υποκείμενα (φοιτητές) - Κάθε μεταβλητή πρέπει να είναι σε δική της στήλη - Επειδή μετράμε τα ίδια υποκείμενα, μένουμε στο ίδιο πλαίσιο δεδομένων
Γ: Δεν χρειάζεται νέο πλαίσιο δεδομένων για τα ίδια υποκείμενα
Δ: Δεν αντικαθιστούμε τις αρχικές μεταβλητές - τις κρατάμε όλες
Μετά τη δημιουργία νέων μεταβλητών ή την εκτέλεση οποιασδήποτε άλλης ενέργειας στην R, είναι σημαντικό να ελέγχεται ότι το αποτέλεσμα είναι αυτό που αναμενόταν. Η συνάρτηση head() μπορεί να χρησιμοποιηθεί για αυτόν τον σκοπό. Εμφανίστε τις πρώτες έξι γραμμές του Fingers. Χρησιμοποιήστε τη συνάρτηση select() για να εμφανίσετε τις μεταβλητές Index, Ring και IndexRingRatio. Εξετάζοντας τις τιμές του δείκτη και του παράμεσου για ορισμένους φοιτητές, μπορείτε να διαπιστώσετε αν η μεταβλητή IndexRingRatio αντιπροσωπεύει αυτό που υποτίθεται ότι αντιπροσωπεύει.
Επιπλέον, μπορεί να είναι χρήσιμος ο υπολογισμός του μέσου μήκους των δαχτύλων, αθροίζοντας τις τιμές των Thumb, Index, Middle, Ring και Pinkie και διαιρώντας το αποτέλεσμα με το 5. Να προσθέσετε τη μεταβλητή AvgFinger στο Fingers που κάνει αυτόν τον υπολογισμό. Επίσης, εμφανίστε τις πρώτες λίγες γραμμές του πλαισίου δεδομένων Fingers, ώστε να ελέγξετε την ορθότητα των υπολογισμών σας.
Επανακωδικοποίηση Μεταβλητών
Σε ορισμένες περιπτώσεις, είναι επιθυμητή η αλλαγή του τρόπου κωδικοποίησης μιας μεταβλητής. Για παράδειγμα, η μεταβλητή Job έχει τρεις τιμές, Not Working για μη απασχόληση, Part-time Job για μερική απασχόληση και Full-time Job για πλήρη απασχόληση. Ας υποθέσουμε ότι επιθυμείτε να επανακωδικοποιήσετε την πλήρη απασχόληση ως 100 (επειδή αντιπροσωπεύει 100% απασχόληση) αντί για Full-time Job, τη μερική ως 50 αντί για Part-time Job και την ανεργία ως 0 αντί για Not Working. Η συνάρτηση recode() μπορεί να χρησιμοποιηθεί ως εξής:
Σημειώστε ότι στη συνάρτηση recode(), η παλιά τιμή πρέπει να περικλείεται σε εισαγωγικά. Η νέα τιμή μπορεί να είναι σε εισαγωγικά (αν είναι τιμή χαρακτήρα) ή όχι (αν είναι αριθμητική).
Όπως πάντα, όταν πραγματοποιούμε μια ενέργεια, είναι χρήσιμο να αποθηκεύουμε το αποτέλεσμα. Αποθηκεύστε την επανακωδικοποιημένη εκδοχή της μεταβλητής Job ως JobRecode, μια νέα μεταβλητή στο πλαίσιο δεδομένων Fingers. Εμφανίστε μερικές παρατηρήσεις των μεταβλητών Job και JobRecode για να επιβεβαιώσετε ότι η επανακωδικοποίηση πραγματοποιήθηκε σωστά.
Ανακεφαλαίωση
Η ανάλυση δεδομένων ξεκινά με τη μετατροπή της μεταβλητότητας του πραγματικού κόσμου σε αριθμούς. Η διαδικασία συλλογής δεδομένων ξεκινά με τη δειγματοληψία και ακολουθεί στη συνέχεια η μέτρηση. Τα δεδομένα οργανώνονται σε στήλες και γραμμές, όπου οι στήλες αντιστοιχούν στις μεταβλητές που έχουν μετρηθεί (π.χ., Thumb) και οι γραμμές αντιστοιχούν στις παρατηρήσεις στις οποίες εφαρμόστηκε η μέτρηση (π.χ., φοιτητές). Κάθε κελί του πίνακα περιέχει μία τιμή, η οποία αντιστοιχεί στη μέτρηση για τη συγκεκριμένη γραμμή και στήλη (π.χ., το μήκος του αντίχειρα ενός φοιτητή).
Πριν από την ανάλυση των δεδομένων, συχνά απαιτείται η προεπεξεργασία ή η τακτοποίησή τους με διάφορους τρόπους. Μπορεί να χρειάζεται να δημιουργηθούν σύνθετες μεταβλητές, να φιλτραριστούν οι ελλείπουσες τιμές, να επανακωδικοποιηθούν οι τιμές μεταβλητών κ.ο.κ.
Είναι σημαντικό να μη χάνεται ο στόχος: η μεταβλητότητα στα δεδομένα μας είναι σημαντική επειδή μας ενδιαφέρει η μεταβλητότητα στον πραγματικό κόσμο. Υπάρχει ένας ευρύτερος πληθυσμός από τον οποίο προέρχεται το δείγμα μας. Εδώ ανακύπτει το βασικό πρόβλημα με τα δεδομένα: δεν αντικατοπτρίζουν πάντα με ακρίβεια την πραγματικότητα από την οποία προήλθαν. Ένα σημαντικό μέρος της στατιστικής επιστήμης ασχολείται με την κατανόηση και την αντιμετώπιση αυτού του προβλήματος.
3.12 Ερωτήσεις Επανάληψης Κεφαλαίου 3
1. Ποια από τα παρακάτω ισχύουν για τα στατιστικά δεδομένα;
Επεξήγηση
Σωστή απάντηση: Όλα τα παραπάνω ✓
Τα στατιστικά δεδομένα έχουν τα εξής βασικά χαρακτηριστικά:
Α. Βασίζονται σε δείγμα ✓ - Συνήθως συλλέγονται από ένα υποσύνολο του πληθυσμού, δηλαδή ένα δείγμα - Σπανίως έχουμε πρόσβαση σε ολόκληρο τον πληθυσμό
Β. Προκύπτουν μέσω μέτρησης ✓ - Μετατρέπουμε παρατηρήσιμα χαρακτηριστικά σε μετρήσιμα δεδομένα (π.χ. αριθμούς, κατηγορίες) - Π.χ. το ύψος μετριέται σε εκατοστά, το φύλο καταγράφεται ως κατηγορία
Γ. Αντιπροσωπεύουν τον κόσμο ✓ - Τα δεδομένα περιγράφουν και εξηγούν φαινόμενα του πραγματικού κόσμου - Αποτελούν τη βάση για τη στατιστική ερμηνεία και συμπερασματολογία
Συμπέρασμα: Τα δεδομένα είναι το σημείο επαφής ανάμεσα στον κόσμο και τη στατιστική ανάλυση.
2. Αν σας πουν ότι υπάρχει σφάλμα μέτρησης στον τρόπο που καταγράφηκε μια από τις μεταβλητές σας, ποιο από τα παρακάτω θα μπορούσε να είναι αληθές;
Επεξήγηση
Σωστή απάντηση: Και τα δύο παραπάνω ✓
Το σφάλμα μέτρησης μπορεί να είναι είτε μεροληπτικό είτε αμερόληπτο:
Αμερόληπτο σφάλμα μέτρησης: - Οι μετρήσεις διαφέρουν τυχαία γύρω από την πραγματική τιμή - Ίδια πιθανότητα να είναι πολύ υψηλές ή πολύ χαμηλές - Παράδειγμα: Διαφορετικοί ερευνητές που μετρούν το μήκος του ίδιου αντικείμενου με ελαφρώς διαφορετικά αποτελέσματα
Μεροληπτικό σφάλμα μέτρησης: - Οι μετρήσεις είναι συστηματικά πολύ υψηλές ή πολύ χαμηλές - Το σφάλμα ωθεί τις μετρήσεις προς μια συγκεκριμένη κατεύθυνση - Παράδειγμα: Όταν όλοι οι ερευνητές στρογγυλοποιούν προς τα πάνω
Βασικό σημείο: Το γεγονός ότι υπάρχει σφάλμα μέτρησης δεν μας λέει αυτόματα αν είναι μεροληπτικό ή όχι. Χρειαζόμαστε περισσότερες πληροφορίες για να το καθορίσουμε!
Συμπέρασμα: Το σφάλμα μέτρησης μπορεί να είναι οτιδήποτε από τα δύο.
3. Τι ισχύει για τη μεταβλητότητα δειγματοληψίας;
Επεξήγηση
Σωστή απάντηση: Κανένα δείγμα δεν αντικατοπτρίζει τέλεια τον πληθυσμό ✓
Τι είναι η μεταβλητότητα δειγματοληψίας: - Η αναπόφευκτη διαφορά μεταξύ δειγμάτων και του πληθυσμού - Συμβαίνει ακόμη και με τέλεια τυχαία δειγματοληψία - Κάθε δείγμα θα είναι ελαφρώς διαφορετικό από τον πληθυσμό
Γιατί η Γ είναι σωστή: Ακόμη και με τον καλύτερο δυνατό τρόπο δειγματοληψίας, η τυχαιότητα εγγυάται ότι το δείγμα δεν θα είναι 100% αντιπροσωπευτικό.
Γιατί οι άλλες είναι λάθος:
Α. “Σπάνια την συναντάμε στην πράξη” ✗ - Την συναντάμε πάντα όταν χρησιμοποιούμε δείγματα - Είναι θεμελιώδης έννοια στη στατιστική
Β. “Οδηγεί σε μεροληψία” ✗ - Η μεταβλητότητα δειγματοληψίας είναι τυχαία, όχι μεροληπτική - Δεν ωθεί συστηματικά τις τιμές προς μια κατεύθυνση - Μεροληψία = συστηματικό σφάλμα, μεταβλητότητα = τυχαίο σφάλμα
Βασική διαφορά: Μεροληψία vs. Μεταβλητότητα - Μεροληψία: Συστηματικό σφάλμα προς μια κατεύθυνση - Μεταβλητότητα: Τυχαίες διαφορές που εξισορροπούνται
4. Τα παρακάτω δεδομένα προέρχονται από μια μελέτη για τα επίπεδα υδραργύρου σε λίμνες της Ελλάδας. Οι ερευνητές ανέλυσαν δείγματα νερού (συλλεγμένα σε τυποποιημένους δοκιμαστικούς σωλήνες) από κάθε λίμνη. Η μελέτη συμπεριέλαβε 42 λίμνες και τα δεδομένα καταγράφηκαν σε ένα πλαίσιο δεδομένων με όνομα GreekLakes. Κάθε γραμμή αντιστοιχεί σε μία λίμνη και περιλαμβάνει το μέσο όρο υδραργύρου των δειγμάτων. Ποια εντολή της R παρήγαγε το παρακάτω αποτέλεσμα;
sort(): Ταξινομεί τιμές, δεν εμφανίζει πλαίσια δεδομένων
5. Η μελέτη συμπεριέλαβε 42 λίμνες στην Ελλάδα. Πού βρίσκεται αυτή η πληροφορία στο πλαίσιο δεδομένων;
Επεξήγηση
Σωστή απάντηση: Ο αριθμός των γραμμών στο πλαίσιο δεδομένων δεδομένων ✓
Κατανόηση της δομής των δεδομένων: - Κάθε γραμμή = μία παρατήρηση (στην περίπτωσή μας, μία λίμνη) - Κάθε στήλη = μία μεταβλητή (π.χ. Alkalinity, pH, AvgMercury)
Στη μελέτη των λιμνών: - Μελετήθηκαν 42 λίμνες - Κάθε λίμνη αντιπροσωπεύεται από μία γραμμή - Άρα το πλαίσιο δεδομένων έχει 42 γραμμές
Α. “Τιμές στο πλαίσιο δεδομένων”: Το 42 δεν εμφανίζεται ως τιμή κάπου μέσα στα δεδομένα
Β. “Αριθμός μεταβλητών”: Οι μεταβλητές είναι τα χαρακτηριστικά που μετρήθηκαν (pH, Alkalinity, κ.λπ.)
Δ. “Αριθμός στηλών”: Οι στήλες αντιπροσωπεύουν μεταβλητές, όχι λίμνες
Θυμηθείτε: Στα τακτοποιημένα δεδομένα, γραμμές = παρατηρήσεις, στήλες = μεταβλητές!
6. Οι γραμμές σε αυτό το πλαίσιο δεδομένων αντιπροσωπεύουν _____ και οι στήλες αντιπροσωπεύουν _____.
Επεξήγηση
Σωστή απάντηση: λίμνες· χαρακτηριστικά της κάθε λίμνης ✓
Ανάλυση της δομής των δεδομένων:
Γραμμές = Λίμνες: - Κάθε γραμμή αντιπροσωπεύει μία λίμνη - Παραδείγματα: Τριχωνίδα, Βεγορίτιδα, Κερκίνη κ.λπ. - Συνολικά 42 γραμμές για 42 λίμνες
Στήλες = Χαρακτηριστικά των Λιμνών: - Lake: Όνομα λίμνης - Alkalinity: Αλκαλικότητα της λίμνης - pH: Επίπεδο pH της λίμνης - AvgMercury: Μέσος όρος υδραργύρου στη λίμνη - NumSamples: Αριθμός δειγμάτων που λήφθηκαν από τη λίμνη
Βασικό σημείο από το κείμενο: “Όλα τα δείγματα για κάθε λίμνη συνδυάζονται σε μία γραμμή”
Γιατί όχι οι άλλες:
Β. “Σωλήνες δοκιμής”: Τα αποτελέσματα από τους σωλήνες συνδυάστηκαν - δεν έχουμε ξεχωριστές γραμμές για τα αποτελέσματα από κάθε σωλήνα δοκιμής
Γ. “Επίπεδο υδραργύρου”: Το επίπεδο υδραργύρου είναι μία μεταβλητή (στήλη), όχι παρατήρηση (γραμμή)
Αρχή των Τακτοποιημένων Δεδομένων: Γραμμές = Παρατηρήσεις (λίμνες), Στήλες = Μεταβλητές (χαρακτηριστικά)
7. Αν θέλατε να δείτε μια σύνοψη του πλαισίου δεδομένων σας—μια λίστα των μεταβλητών σας, αν είναι αριθμητικές (num) ή Factor, και ούτω καθεξής—ποια εντολή θα χρησιμοποιούσατε;
Τι κάνει η str() (structure): - Δείχνει τη δομή του πλαισίου δεδομένων - Παρουσιάζει όλες τις μεταβλητές (ονόματα στηλών) - Εμφανίζει τον τύπο κάθε μεταβλητής (num, chr, Factor, κ.λπ.) - Εμφανίζει τον αριθμό παρατηρήσεων και μεταβλητών - Εμφανίζει τις πρώτες λίγες τιμές κάθε μεταβλητής
str(GreekLakes)'data.frame':42 obs. of 11 variables:$ ID : int 123456...$ Lake : chr "Τριχωνίδα""Βεγορίτιδα""Κερκίνη"...$ Alkalinity : num 5.93.5116.039.4...$ pH : num 6.15.19.16.9...$ AvgMercury : num 1.231.330.040.44...$ AgeData : Factor w/2 levels "0","1":211...
Γιατί όχι οι άλλες:
table(): Μετράει συχνότητες, δεν δίνει σύνοψη της δομής
c(): Δημιουργεί διανύσματα, δεν εξετάζει πλαίσια δεδομένων
sort(): Ταξινομεί τιμές, δεν εμφανίζει τη δομή των δεδομένων
Χρήσιμες παρόμοιες συναρτήσεις: - glimpse() (από το πακέτο dplyr): Παρόμοια με την str() - summary(): Στατιστικοί δείκτες για κάθε μεταβλητή
8. Κοιτάξτε τον παρακάτω πίνακα. Ποια από τα παρακάτω είναι παραδείγματα στατιστικής μονάδας (ή παρατήρησης), μεταβλητής και τιμής μεταβλητής, αντίστοιχα;
1. Στατιστική μονάδα/Περίπτωση = Βόλβη - Η στατιστική μονάδα είναι η παρατήρηση που μελετάμε - Στη μελέτη αυτή, κάθε λίμνη είναι μια στατιστική μονάδα - Η Βόλβη είναι το όνομα μιας συγκεκριμένης λίμνης (γραμμή 2) - Άλλα παραδείγματα: Πλαστήρα, Μόρνου, Κορώνεια
2. Μεταβλητή = AvgMercury - Η μεταβλητή είναι το χαρακτηριστικό που μετράμε - Το AvgMercury είναι μια στήλη που αντιπροσωπεύει το μέσο επίπεδο υδραργύρου - Άλλα παραδείγματα μεταβλητών: pH, Alkalinity, Calcium
3. Τιμή = 1.33 - Η τιμή είναι η συγκεκριμένη μέτρηση για μια στατιστική μονάδα σε μια μεταβλητή - Το 1.33 είναι η τιμή του AvgMercury για τη λίμνη Βόλβη - Βρίσκεται στο κελί στη διασταύρωση γραμμής και στήλης
9. Ποιες από τις παρακάτω είναι ποσοτικές μεταβλητές στο GreekLakes; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Σωστές απαντήσεις: Α, Γ, Δ ✓
Ποσοτικές μεταβλητές:
Α. NumSamples ✓ - Αριθμός δειγμάτων - αριθμητική ποσότητα - Μπορούμε να υπολογίσουμε μέσο όρο, άθροισμα κ.λπ.
Γ. MinMercury ✓ - Ελάχιστο επίπεδο υδραργύρου - συνεχής αριθμητική μέτρηση - Έχει μαθηματικό νόημα (μπορούμε να αφαιρέσουμε, να διαιρέσουμε κ.λπ.)
Δ. pH ✓ - Επίπεδο οξύτητας - συνεχής αριθμητική κλίμακα - Οι διαφορές στο pH έχουν ποσοτικό νόημα
Ποιοτική μεταβλητή:
Β. Lake ✗ - Όνομα λίμνης - ποιοτική μεταβλητή - Δεν έχει αριθμητικό/ποσοτικό νόημα - Δεν μπορούμε να υπολογίσουμε μέσο όρο ονομάτων!
Θυμηθείτε: - Ποσοτικές: Μετρήσεις με αριθμητικό νόημα - Ποιοτικές: Κατηγορίες ή ετικέτες
10. Με ποια εντολή θα βρίσκατε τον συνολικό αριθμό δειγμάτων νερού (ή σωλήνων δοκιμής) που συλλέχθηκαν από όλες τις λίμνες στη μελέτη σας;
Επεξήγηση
Σωστή απάντηση: sum(GreekLakes$NumSamples) ✓
Τι χρειαζόμαστε: - Να αθροίσουμε όλες τις τιμές στη στήλη NumSamples - Κάθε λίμνη έχει έναν αριθμό δειγμάτων (π.χ. Annie = 7, Allifator = 5) - Θέλουμε το συνολικό άθροισμα όλων αυτών των αριθμών
Α. table(GreekLakes$NumSamples) - Η table()μετράει συχνότητες, δεν αθροίζει τιμές - Θα έδειχνε πόσες λίμνες έχουν 5 δείγματα, πόσες έχουν 7, κ.λπ. - Δεν δίνει το συνολικό άθροισμα
Β. arrange(GreekLakes, NumSamples) - Η arrange()ταξινομεί τις γραμμές κατά NumSamples - Δεν υπολογίζει άθροισμα
Δ. sample(sum, GreekLakes) - Λάθος σύνταξη - η sample() δεν λειτουργεί έτσι - Η sample() επιλέγει τυχαίες τιμές
Θυμηθείτε:sum() για άθροισμα, table() για μέτρηση συχνοτήτων!
11. Με ποια εντολή θα ταξινομούσατε το πλαίσιο δεδομένων κατά μέσο επίπεδο υδραργύρου, με την πιο μολυσμένη λίμνη να εμφανίζεται πρώτη στη λίστα; Αποθηκεύστε το αποτέλεσμα πίσω στο GreekLakes.
1. Χρήση της arrange() για ταξινόμηση: - Η arrange() ταξινομεί γραμμές ενός πλαισίου δεδομένων - Σύνταξη: arrange(dataframe, variable)
2. Χρήση της desc() για φθίνουσα σειρά: - Η desc(AvgMercury) ταξινομεί από τη μεγαλύτερη στη μικρότερη τιμή - Έτσι η πιο μολυσμένη λίμνη (υψηλότερα επίπεδα υδραργύρου) εμφανίζεται πρώτη
3. Αποθήκευση με <-: - Το <- αποθηκεύει το αποτέλεσμα πίσω στο GreekLakes - Αντικαθιστά την παλιά ταξινόμηση με τη νέα
Α. table(): Μετράει συχνότητες, δεν ταξινομεί Β. sum(): Υπολογίζει άθροισμα, δεν ταξινομεί Δ. sample(): Επιλέγει τυχαία, δεν ταξινομεί
12. Σας έχει ανατεθεί να κάνετε μια μελέτη όλων των λιμνών με μέσα επίπεδα υδραργύρου άνω του 1. Θέλετε να αποθηκεύσετε τα δεδομένα των λιμνών που πληρούν αυτό το κριτήριο σε ένα νέο πλαίσιο δεδομένων που ονομάζεται HighMercury. Τι λάθος έχει ο παρακάτω κώδικας;
1. Λάθος όνομα πλαισίου δεδομένων: - Γραμμένο: greeklakes (όλα μικρά) - Σωστό: GreekLakes (με κεφαλαία G και L)
2. Λάθος όνομα μεταβλητής: - Γραμμένο: avgmercury (όλα μικρά) - Σωστό: AvgMercury (με κεφαλαία A και M)
Σωστός κώδικας:
HighMercury <-filter(GreekLakes, AvgMercury >1)
Γιατί όχι οι άλλες:
Α. “Δεν ονοματίζει σωστά το νέο πλαίσιο δεδομένων”: Λάθος - Το HighMercury <- είναι σωστό για τη δημιουργία νέου πλαισίου δεδομένων
Β. “Λείπουν εισαγωγικά γύρω από το 1”: Λάθος - Το 1 είναι αριθμός, όχι κείμενο - δεν χρειάζεται εισαγωγικά - Εισαγωγικά χρησιμοποιούνται για χαρακτήρες: "κείμενο"
Δ. “Τίποτα”: Λάθος - Υπάρχουν σαφή λάθη στη χρήση κεφαλαίων/μικρών που θα προκαλέσουν σφάλμα
Σημαντικό: Η R είναι case-sensitive - διακρίνει κεφαλαία από μικρά γράμματα!
13. Αν θέλετε να δείτε γρήγορα το όνομα της λίμνης με το χαμηλότερο μέσο επίπεδο υδραργύρου, ποια εντολή R θα εκτελούσατε;
Πώς λειτουργεί η arrange(): - Ταξινομεί το πλαίσιο δεδομένων κατά AvgMercury σε αύξουσα σειρά - Η λίμνη με το χαμηλότερο επίπεδο υδραργύρου θα εμφανιστεί πρώτη - Βλέπουμε το όνομα της λίμνης στη στήλη Lake
Α. str(GreekLakes) - Δείχνει τη δομή των δεδομένων (τύπους μεταβλητών) - Δεν δείχνει ποια λίμνη έχει τη χαμηλότερη τιμή
Β. table(GreekLakes$AvgMercury) - Η table()μετράει συχνότητες - Δεν ταξινομεί ούτε βρίσκει την ελάχιστη τιμή
Δ. arrange(GreekLakes) - Λάθος σύνταξη - λείπει η μεταβλητή ταξινόμησης - Δεν θα εκτελεστεί καθόλου
Εναλλακτικά: Θα μπορούσατε να προσθέσετε head(arrange(GreekLakes, AvgMercury), 1) για να δείτε μόνο την πρώτη γραμμή!
14. Θέλετε να δείτε τις πρώτες 10 γραμμές του GreekLakes, οπότε εκτελείτε head(GreekLakes). Δεν σας δίνει αυτό που θέλατε. Γιατί όχι;
Επεξήγηση
Σωστή απάντηση: Α - Δεν υποδείξατε ότι θέλατε να δείτε 10 γραμμές ✓
Το πρόβλημα:
Προεπιλογή της head(): - Η head() εμφανίζει τις πρώτες 6 γραμμές ως προεπιλογή - Εσείς θέλατε 10 γραμμές, αλλά δεν το καθορίσατε
Τι έκανε ο κώδικάς σας:
head(FloridaLakes) # Έδειξε μόνο 6 γραμμές
Τι έπρεπε να κάνετε:
head(FloridaLakes, 10) # Για να δείτε 10 γραμμές
Σύνταξη της head(): - head(data) → Πρώτες 6 γραμμές (προεπιλογή) - head(data, n) → Πρώτες n γραμμές
Παραδείγματα:
head(GreekLakes, 3) # Πρώτες 3 γραμμέςhead(GreekLakes, 15) # Πρώτες 15 γραμμέςhead(GreekLakes, 1) # Μόνο η πρώτη γραμμή
Γιατί όχι οι άλλες:
Β. “Περίεργο αίτημα”: Λάθος - είναι πολύ συνηθισμένο να θέλουμε διαφορετικό αριθμό γραμμών
Γ. “Μόνο σε διανύσματα”: Λάθος - η head() λειτουργεί τέλεια με πλαίσια δεδομένων
Δ. “Εμφανίζει ονόματα μεταβλητών”: Λάθος - εμφανίζει τα δεδομένα, όχι μόνο τα ονόματα
Βασικό μάθημα: Πάντα να καθορίζετε τον αριθμό γραμμών αν θέλετε κάτι διαφορετικό από την προεπιλογή!
15. Εκτελείτε την παρακάτω εντολή: RandomLakes <- sample(GreekLakes, 10). Ποιο θα είναι το αποτέλεσμα;
Επεξήγηση
Σωστή απάντηση: Νέο πλαίσιο δεδομένων από το GreekLakes ✓
Ανάλυση της εντολής:
1. Η συνάρτηση sample(): - Επιλέγει τυχαίο υποσύνολο από ένα σύνολο δεδομένων - Σύνταξη: sample(data_frame, number_of_rows)
2. Οι παράμετροι: - GreekLakes: Το υπάρχον πλαίσιο δεδομένων (42 λίμνες) - 10: Ο αριθμός γραμμών που θα επιλεγούν τυχαία
3. Ο τελεστής <-: - Αποθηκεύει το αποτέλεσμα στη νέα μεταβλητή RandomLakes - Δεν εμφανίζει αυτόματα - απλώς δημιουργεί το νέο αντικείμενο
Αποτέλεσμα:
# Το RandomLakes θα περιέχει:# - 10 γραμμές (λίμνες) επιλεγμένες τυχαία# - Όλες τις στήλες από το αρχικό GreekLakes# - Π.χ. μπορεί να περιλαμβάνει: Βόλβη, Πλαστήρα, Μόρνου κ.λπ.
Γιατί όχι οι άλλες:
Α. “Εμφανίζεται”: Ο τελεστής <- αποθηκεύει, δεν εμφανίζει
Β. “Από τον πληθυσμό”: Λάθος - επιλέγει από το υπάρχον σύνολο δεδομένων, όχι από τον γενικό πληθυσμό
Σημαντικό: Η sample() λειτουργεί με τα δεδομένα που έχουμε ήδη, όχι με νέα δεδομένα από τον πληθυσμό!
16. Ας υποθέσουμε ότι θέλετε να φιλτράρετε τα δεδομένα σας έτσι ώστε να ΜΗΝ συμπεριλάβετε λίμνες που έχουν ελλείπουσες τιμές στη μεταβλητή Chlorophyll. Ποια γραμμή κώδικα θα το κάνει αυτό;
1. Κατανόηση του στόχου: - Θέλουμε να κρατήσουμε λίμνες που ΕΧΟΥΝ δεδομένα για Chlorophyll - Θέλουμε να αποκλείσουμε λίμνες που δεν έχουν δεδομένα (NA)
2. Πώς λειτουργεί η is.na(): - is.na(Chlorophyll) επιστρέφει TRUE αν η τιμή είναι ελλείπουσα (NA) - is.na(Chlorophyll) επιστρέφει FALSE αν η τιμή υπάρχει
3. Η συνθήκη φιλτραρίσματος: - is.na(Chlorophyll) == FALSE σημαίνει “η τιμή ΔΕΝ είναι ελλείπουσα” - Άρα κρατάμε μόνο γραμμές όπου η Chlorophyll έχει τιμή
Παράδειγμα:
# Πριν το φιλτράρισμα:Lake ChlorophyllΒόλβη 3.2# Έχει τιμή - θα κρατηθείΖάζαρη 128.3# Έχει τιμή - θα κρατηθείΖηρού NA# Λείπει - θα αφαιρεθεί# Μετά το φιλτράρισμα - μόνο Βόλβη και Ζάζαρη
Γιατί όχι οι άλλες:
Β & Δ. Σύγκριση με “0”: Το 0 είναι αριθμός, όχι ελλείπουσα τιμή
Γ. Chlorophyll == "NA": Το NA είναι ειδικός τύπος δεδομένων όχι κείμενο για να μπει σε εισαγωγικά ως “ΝΑ”
Εναλλακτική σύνταξη:filter(GreekLakes, !is.na(Chlorophyll)) - το ! σημαίνει “όχι”
17. Αν θέλατε να γενικεύσετε τα αποτελέσματα για όλες τις λίμνες στην Ελλάδα, αλλά συμπεριλάβατε στη μελέτη σας μόνο λίμνες σε ακτίνα 100 km από το ερευνητικό κέντρο, τι θα έπρεπε να σας ανησυχεί; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Σωστές απαντήσεις: Α και Γ ✓
Το πρόβλημα: - Στόχος: Γενίκευση για όλες τις λίμνες της Ελλάδα - Πραγματικότητα: Μελέτη μόνο λιμνών σε 100 km ακτίνα από το ερευνητικό κέντρο
Α. Το δείγμα δεν είναι τυχαίο ✓ - Τυχαίο δείγμα: Κάθε λίμνη στην Ελλάδα έχει ίση πιθανότητα επιλογής - Πραγματικότητα: Μόνο λίμνες κοντά στο ερευνητικό κέντρο έχουν πιθανότητα επιλογής - Συνέπεια: Γεωγραφική μεροληψία στο δείγμα
Γ. Το δείγμα μπορεί να μην αντιπροσωπεύει τον πληθυσμό ✓ - Παράδειγμα προβλημάτων: - Λίμνες κοντά σε αστικές περιοχές vs. απομονωμένες λίμνες - Διαφορετικά κλιματικά χαρακτηριστικά π.χ. Βόρεια vs. Νότιας Ελλάδα - Διαφορετικά επίπεδα μόλυνσης κοντά σε πόλεις - Συνέπεια: Τα συμπεράσματα μπορεί να μην ισχύουν για όλη την ελληνική επικράτεια
Γιατί όχι οι άλλες:
Β. “Δεν θα έχει μεταβλητότητα”: Λάθος - Ακόμη και σε 100 km ακτίνα, οι λίμνες θα διαφέρουν σε pH, υδράργυρο, κ.λπ. - Η γεωγραφική εγγύτητα δεν εξαλείφει τη μεταβλητότητα
Δ. “Δεν είναι βολικά επιλεγμένο”: - Αντίθετα, είναι πολύ βολικά επιλεγμένο για τους ερευνητές (κοντινές λίμνες) - Το πρόβλημα είναι η αντιπροσωπευτικότητα, του δείγματος όχι η ευκολία επιλογής του