Θεωρητικά, δεν υπάρχει καμία διαφορά μεταξύ θεωρίας και πράξης. Αλλά στην πράξη, υπάρχει.
— Yogi Berra
4.1 Η Έννοια της Κατανομής
Έχοντας στη διάθεσή μας ένα οργανωμένο σύνολο δεδομένων, το επόμενο βήμα στην ανάλυση είναι η εξέταση της μεταβλητότητας των μετρήσεων. Αυτό οδηγεί στην κατανόηση μιας από τις θεμελιώδεις έννοιες της στατιστικής, την έννοια της κατανομής (distribution). Ο Wild (2006) ορίζει την κατανομή ως «το μοτίβο της μεταβλητότητας σε μια μεταβλητή ή σύνολο μεταβλητών». Η κατανομή λειτουργεί ως ένας «φακός» μέσω του οποίου εξετάζεται η μεταβλητότητα στα δεδομένα (βλ. εικόνα προσαρμοσμένη από Wild, 2006).
Σχήμα 4.1: Κατανόηση της Στατιστικής Μεταβλητότητας
Η κατανόηση της έννοιας της κατανομής απαιτεί αφαιρετική σκέψη υψηλού επιπέδου. Για την κατανόησή της είναι απαραίτητη η μετάβαση από την εστίαση στις μεμονωμένες παρατηρήσεις του συνόλου δεδομένων (π.χ., τα 20 άτομα του δείγματος) στην εστίαση, αρχικά, σε ένα χαρακτηριστικό στο οποίο οι παρατηρήσεις διαφέρουν και, τελικά, στο μοτίβο της μεταβλητότητας αυτού του χαρακτηριστικού σε ολόκληρο το δείγμα.
Σημειώνεται ότι δεν μπορεί να θεωρηθεί κατανομή οποιοδήποτε σύνολο τιμών. Οι τιμές πρέπει να είναι μετρήσεις του ίδιου χαρακτηριστικού. Για παράδειγμα, αν υπάρχουν μετρήσεις του ύψους και του βάρους 20 ατόμων, δεν είναι δυνατόν οι τιμές του ύψους και του βάρους να αποτελέσουν συνδυαστικά μία ενιαία κατανομή. Ωστόσο, μπορεί να εξεταστεί η κατανομή του ύψους και η κατανομή του βάρους ξεχωριστά.
Ακόμη και ένα μικρό σύνολο δεδομένων περιλαμβάνει συνήθως μεγάλο αριθμό διαφορετικών τιμών και σημαντική μεταβλητότητα. Η έννοια της κατανομής μας επιτρέπει να δούμε πέρα από τις μεμονωμένες τιμές των δεδομένων και να εστιάσουμε στα χαρακτηριστικά που ορίζουν την κατανομή ως σύνολο. Με αυτόν τον τρόπο, η έννοια της κατανομής μας επιτρέπει να δούμε το σύνολο ως μεγαλύτερο από το άθροισμα των μερών του, δηλαδή το «δάσος», και όχι μόνο τα «δέντρα».
Τα χαρακτηριστικά ενός δάσους δεν είναι ορατά σε ένα μόνο δέντρο. Για παράδειγμα, η μέτρηση του ύψους ενός ατόμου δεν αποκαλύπτει τα χαρακτηριστικά της κατανομής του ύψους σε ένα σύνολο ατόμων. Μπορεί να είναι γνωστό το ύψος ενός συγκεκριμένου ατόμου, αλλά με μια μεμονωμένη μέτρηση δεν είναι γνωστό το ελάχιστο, το μέγιστο ή το μέσο ύψος των ατόμων σε ολόκληρο το δείγμα. Στατιστικοί δείκτες, όπως ο μέσος όρος, δεν αποτελούν από μόνοι τους κατανομή, αλλά χαρακτηριστικά μιας κατανομής, τα οποία δεν αφορούν σε μεμονωμένα άτομα.
Ας αναπτύξουμε περαιτέρω αυτή την αναλογία μεταξύ μεμονωμένων μετρήσεων και κατανομής. Ποιες από τις παρακάτω οντότητες αποτελούν κατανομές (δηλ., «δάση»); Ποιες είναι μεμονωμένα στοιχεία (δηλ., «δέντρα»);
Οντότητα
Κατανομή
Μεμονωμένο Στοιχείο
Α. Ύψη 100 φοιτητών
☐
☐
Β. Μήκος αντίχειρα ενός φοιτητή
☐
☐
Γ. Συνολική έκταση της Φινλανδίας
☐
☐
Δ. Η ιστορία της ζωής ενός κηπουρού
☐
☐
Ε. Όλα τα μήκη αντίχειρα ενός δείγματος φοιτητών
☐
☐
ΣΤ. Η ηλικία, το βάρος και το ύψος μιας δασκάλας
☐
☐
Ζ. Τα ποσοστά ανεργίας στις χώρες των Βαλκανίων
☐
☐
Απάντηση
Κατανομές (“Δάση” - Συλλογές μετρήσεων): - Α. Ύψη 100 φοιτητών ✓ - Ε. Όλα τα μήκη αντίχειρα ενός δείγματος φοιτητών ✓ - Ζ. Τα ποσοστά ανεργίας στις χώρες των Βαλκανίων ✓
Μεμονωμένα στοιχεία (“Δέντρα” - Μεμονωμένες μετρήσεις): - Β. Μήκος αντίχειρα ενός φοιτητή ✓ - Γ. Συνολική έκταση της Φινλανδίας ✓ - Δ. Η ιστορία ζωής της ζωής ενός κηπουρού ✓ - ΣΤ. Η ηλικία, το βάρος και το ύψος μιας δασκάλας ✓
Κλειδί για κατανόηση:
Κατανομή = Συλλογή πολλών τιμών - Περιέχει μεταβλητότητα - διαφορετικές τιμές - Μπορούμε να εξετάσουμε μοτίβα, πρότυπα, κεντρικές τάσεις - Παράδειγμα: Τα ύψη 100 φοιτητών θα ποικίλλουν
Μεμονωμένο στοιχείο = Μία μόνο τιμή ή στοιχείο - Δεν έχει μεταβλητότητα (είναι μία συγκεκριμένη τιμή) - Δεν μπορούμε να κάνουμε στατιστική ανάλυση - Παράδειγμα: Το ύψος του Γιάννη είναι 175 cm
Ειδικές περιπτώσεις: - Γ. Η έκταση της Φινλανδίας είναι μία σταθερή τιμή - Δ. Η ιστορία ζωής ενός κηπουρού είναι μία αφήγηση - ΣΤ. Αν και αναφέρεται σε 3 μεταβλητές, είναι για ένα άτομο - άρα μεμονωμένο στοιχείο
Ποιες από τις παρακάτω είναι ιδιότητες του «δάσους»; Ποιες είναι ιδιότητες του «δέντρου»;
Οντότητα
Δάσος
Δέντρο
Α. Ύψος ενός φοιτητή
☐
☐
Β. Έκταση γης μιας χώρας
☐
☐
Γ. Μέση ανεργία όλων των χωρών των Βαλκανίων
☐
☐
Δ. Ελάχιστο ύψος σε ένα δείγμα φοιτητών
☐
☐
Ε. Καταμέτρηση του αριθμού φοιτητών που είναι ψηλότεροι από μια συγκεκριμένη τιμή
☐
☐
Απάντηση
Ιδιότητες «Δάσους» (Κατανομής): - Γ.. Μέση ανεργία όλων των χωρών των Βαλκανίων ✓ - Δ. Ελάχιστο ύψος σε ένα δείγμα φοιτητών ✓ - Ε. Καταμέτρηση του αριθμού φοιτητών που είναι ψηλότεροι από μια συγκεκριμένη τιμή ✓
Ιδιότητες «Δέντρου» (Μεμονωμένου στοιχείου): - Α. Ύψος ενός φοιτητή ✓ - Β. Έκταση γης μιας χώρας ✓
Λογική της κατηγοριοποίησης:
“Δάσος” = Περιγραφικά στατιστικά της κατανομής - Περιγράφουν ολόκληρη την κατανομή τιμών - Προκύπτουν από πολλές μετρήσεις (ένα δείγμα ή πληθυσμό) - Παραδείγματα: μέσος όρος, διάμεσος, ελάχιστο, μέγιστο, συχνότητα εμφάνισης τιμής
«Δέντρο» = Μεμονωμένες τιμές - Μία συγκεκριμένη μέτρηση για ένα συγκεκριμένο στοιχείο - Δεν αναφέρεται σε μια κατανομή - είναι μόνο μία τιμή - Παραδείγματα: το ύψος του Γιάννη, η έκταση της Ελλάδας
Κλειδί για κατανόηση: - Γ. Μέση ανεργία = στατιστικό που περιγράφει ολόκληρη κατανομή - Δ. Ελάχιστο ύψος = στατιστικό που περιγράφει το κάτω άκρο κατανομής - Ε. Καταμέτρηση = περιγραφή της συχνότητας εμφάνισης τιμών στην κατανομή - Α. Ύψος ενός φοιτητή = μία συγκεκριμένη τιμή - Β. Έκταση μιας χώρας = μία συγκεκριμένη τιμή
Η έννοια της κατανομής είναι περίπλοκη, οι περισσότεροι άνθρωποι δεν την κατανοούν αμέσως. Αν τη βρίσκετε δύσκολη ή ασαφή, αυτό είναι απολύτως φυσιολογικό. Θα συνεχίσουμε να εμβαθύνουμε στην κατανόηση και να εμπλουτίζουμε την οπτική μας για αυτή τη σημαντική έννοια στην πορεία.
4.2 Ιστογράμματα
Η στατιστική περιλαμβάνει μια σειρά εργαλείων για τη διερεύνηση κατανομών. Πολλά από αυτά τα εργαλεία είναι εποπτικά, όπως ιστογράμματα, ραβδογράμματα, διαγράμματα διασποράς, διαγράμματα boxplot, κ.λπ. Η ικανότητα χρήσης αυτών των εργαλείων για την εξέταση κατανομών αποτελεί σημαντικό μέρος της εργαλειοθήκης ενός αναλυτή δεδομένων, ικανότητα που μπορεί να καλλιεργηθεί μέσω αυτού του μαθήματος.
Θα ξεκινήσουμε με τα ιστογράμματα, ένα από τα πιο ισχυρά εργαλεία που διαθέτουμε για τη μελέτη κατανομών. Για να κατανοήσουμε τη λειτουργία τους, θα δημιουργήσουμε μια μεταβλητή και θα την αποθηκεύσουμε σε ένα διάνυσμα με το όνομα outcome. Ο κώδικας που χρησιμοποιήθηκε για τη δημιουργία του outcome παρουσιάζεται παρακάτω και περιλαμβάνει μόνο 5 αριθμητικές τιμές. Θα εξετάσουμε πώς αυτή η απλή κατανομή μπορεί να απεικονιστεί με ένα ιστόγραμμα.
Υπάρχουν πολλοί τρόποι για τη δημιουργία ιστογραμμάτων στην R. Θα χρησιμοποιήσουμε το πακέτο ggformula για τα διαγράμματά μας. Το ggformula είναι μια παράξενη ονομασία, η οποία επιλέχθηκε από τους δημιουργούς του πακέτου. Συνεπώς, πολλές από τις εντολές του ggformula θα ξεκινούν με gf_. Το “g” προέρχεται από το “gg” και το “f” από το “formula”. Θα ξεκινήσουμε με τη δημιουργία ενός ιστογράμματος χρησιμοποιώντας την εντολή gf_histogram().
Ο κώδικας για τη δημιουργία ιστογράμματος του διανύσματος outcome είναι:
gf_histogram(~outcome)
Παρατηρήστε το σύμβολο ~ (περισπωμένη ή tilde). Το σύμβολο αυτό βρίσκεται συνήθως αριστερά του 1 ή του Ζ στα περισσότερα πληκτρολόγια. Το διάνυσμα (ή μεταβλητή) outcome τοποθετείται μετά την περισπωμένη. Δοκιμάστε να εκτελέσετε τον παρακάτω κώδικα.
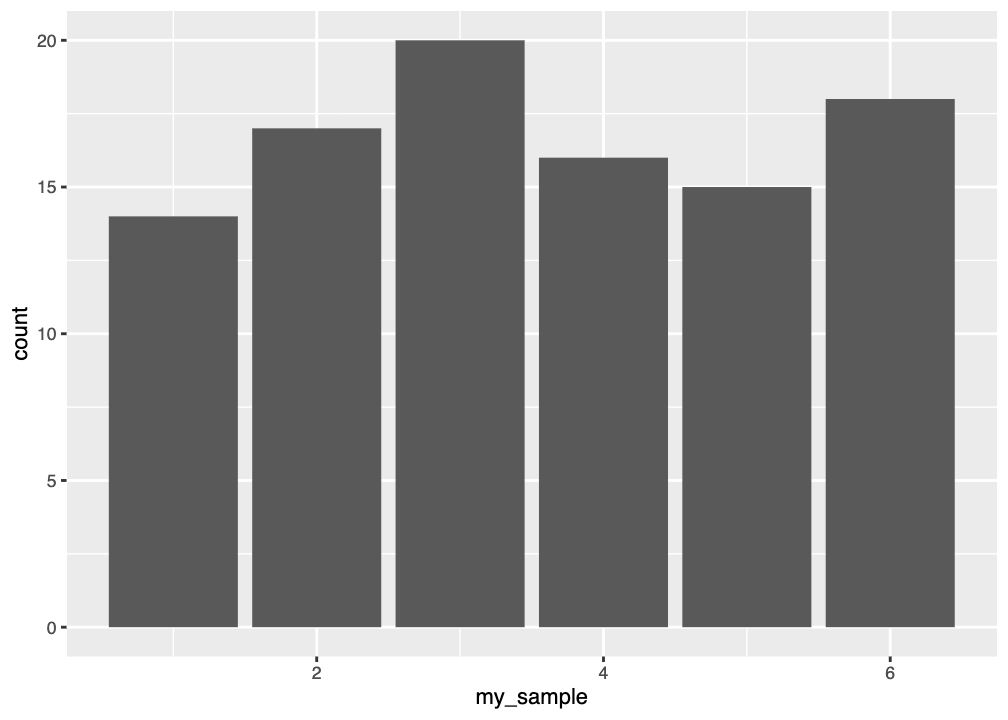
Ο άξονας x του ιστογράμματος (με τον τίτλο “outcome”) αντιστοιχεί στο εύρος των πιθανών τιμών της μεταβλητής (σε αυτή την περίπτωση, από 1 έως 5). Η μεταβλητή στον άξονα x ενός ιστογράμματος είναι πάντα ποσοτική, δηλαδή μετρημένη σε συνεχή κλίμακα.
Ο άξονας y (με τον τίτλο “Count”) αντιστοιχεί στη συχνότητα εμφάνισης των τιμών της μεταβλητής. Στη συγκεκριμένη περίπτωση, η τιμή 1 εμφανίζεται μία φορά, η τιμή 2 μία φορά, η τιμή 3 μία φορά, η τιμή 4 μία φορά και η τιμή 5 μία φορά. Το ύψος των ράβδων σε ένα ιστόγραμμα αντιπροσωπεύει τον αριθμό των παρατηρήσεων που εμπίπτουν σε ένα συγκεκριμένο διάστημα τιμών της μεταβλητής. Τα όρια των διαστημάτων καθορίζονται συνήθως με τη διαίρεση όλου του εύρους των τιμών σε διαστήματα ίσου εύρους.
Το παραπάνω ιστόγραμμα εμφανίζει κενά μεταξύ των ράβδων, διότι, εξ ορισμού, η συνάρτηση gf_histogram() επιχειρεί να δημιουργήσει 30 διαστήματα τιμών, ή bins (στην πραγματικότητα, κατάφερε να δημιουργήσει 27). Ωστόσο, δεδομένου ότι έχουμε μόνο πέντε πιθανές τιμές στη μεταβλητή outcome, πολλά από αυτά τα διαστήματα τιμών είναι κενά.
Ας γράψουμε κώδικα για να υποδείξουμε στην gf_histogram() να δημιουργήσει μόνο 5 διαστήματα τιμών (δεδομένου ότι έχουμε μόνο 5 αριθμούς) ώστε να εξαλειφθούν τα κενά μεταξύ των ράβδων:
Ας προσθέσουμε άλλη μία τιμή στο διάνυσμα outcome. Προσπαθήστε να εκτελέσετε τον παρακάτω κώδικα.
Η νέα τιμή (3.2) τοποθετήθηκε στη ράβδο που αντιστοιχεί στην τιμή 3, η οποία αντιπροσωπεύει το διάστημα 2.5 έως 3.5. Το ύψος αυτής της ράβδου (που είναι τώρα 2) δείχνει τη συχνότητα των παρατηρήσεων που εμπίπτουν σε αυτό το διάστημα (και το 3 και το 3.2 βρίσκονται σε αυτό το διάστημα τιμών). Παρακάτω, έχουν προστεθεί ετικέτες στο ιστόγραμμα για να φανεί ποιες τιμές της μεταβλητής outcome εμπίπτουν σε κάθε διάστημα.
Αν προσθέταμε μια ακόμη τιμή στη μεταβλητή, το 3.7, σε ποια ράβδο θα άνηκε;
Επεξήγηση
4 είναι η σωστή απάντηση. Η τιμή 3.7 θα άνηκε στη ράβδο που αντιστοιχεί στο 4.
Όπως εξηγείται στο κείμενο, το διάστημα με τιμή 3 αντιπροσωπεύει το εύρος 2.5 έως 3.5. Ομοίως, το διάστημα με τιμή 4 αντιπροσωπεύει το εύρος 3.5 έως 4.5.
2: Αυτή η ράβδος καλύπτει το εύρος 1.5-2.5, οπότε το 3.7 δεν εμπίπτει εδώ
3: Αυτή η ράβδος καλύπτει το εύρος 2.5-3.5, οπότε το 3.7 δεν εμπίπτει εδώ
4: Αυτή η ράβδος καλύπτει το εύρος 3.5-4.5, οπότε το 3.7 εμπίπτει εδώ
5: Αυτή η ράβδος καλύπτει το εύρος 4.5-5.5, οπότε το 3.7 δεν εμπίπτει εδώ
Προσθέστε την τιμή 3.7 στις τιμές της outcome. Εκτελέστε τον κώδικα για να δείτε πώς θα διαμορφωθεί το ιστόγραμμα.
Η νέα τιμή, 3.7, προστέθηκε στο διάστημα τιμών με κέντρο το 4, το οποίο φαίνεται να κυμαίνεται από το 3.5 έως το 4.5.
Παρακάτω, έχουν προστεθεί ξανά οι ετικέτες στον άξονα x για να εμφανιστούν τα όρια των διαστημάτων τιμών αντί των κέντρων τους. Εάν εξετάσετε προσεκτικά τον άξονα x, θα παρατηρήσετε ότι το διάστημα τιμών που έφερε προηγουμένως την ετικέτα 4, στην πραγματικότητα κυμαίνεται από 3.5 έως 4.5.
Warning: package 'ggplot2' was built under R version 4.5.2
Είναι επίσης δυνατή η προσαρμογή του εύρους ή του μεγέθους των διαστημάτων (binwidth). Μπορούμε να προσθέσουμε την binwidth (όπως την bins) ως παράμετρο στη συνάρτηση gf_histogram(). Ακολουθεί ένα παράδειγμα:
gf_histogram(~outcome, binwidth =4)
Το παραπάνω ιστόγραμμα δημιουργήθηκε με binwidth = 4. Γιατί υπάρχουν μόνο δύο ράβδοι;
Επεξήγηση
Χρειάζονται δύο ράβδοι με εύρος 4 για να συμπεριλάβουν όλες τις τιμές της μεταβλητής. Αυτή είναι η σωστή απάντηση.
Τα δεδομένα μας περιέχουν τις τιμές: 1, 2, 3, 3.2, 3.7, 4, 5. Το εύρος των τιμών είναι από 1 έως 5.
Με binwidth = 4, η R δημιουργεί διαστήματα εύρους 4 μονάδων. Βάσει του ιστογράμματος: - Πρώτη ράβδος (διάστημα (-2, 2]: περιλαμβάνει τις τιμές 1, 2 → ύψος = 2 - Δεύτερη ράβδος (διάστημα (2, 6]: περιλαμβάνει τις τιμές 3, 3.2, 3.7, 4, 5 → ύψος = 5
Η συνάρτηση gf_histogram() επιλέγει αυτόματα τα όρια των διαστημάτων (-2, 2, 6) για να δημιουργήσει συμμετρικά διαστήματα εύρους 4 που να καλύπτουν όλες τις τιμές. Σημειώνεται ότι είναι μια ευρέως διαδεδομένη σύμβαση τα διαστήματα τιμών στο ιστόγραμμα να είναι της μορφής (a, b] - ανοικτό αριστερά, κλειστό δεξιά, δηλαδή το αριστερό άκρο δεν περιλαμβάνεται στο διάστημα, ενώ το δεξιό άκρο περιλαμβάνεται στο διάστημα. Επομένως, ένα διάστημα εύρους 4 δεν μπορεί να συμπεριλάβει ταυτόχρονα τις δύο ακραίες τιμές 1 και 5.
Οι άλλες επιλογές είναι λάθος: - Α: Δεν υπάρχει κανόνας για άρτιο αριθμό ράβδων - Β: Δεν υπάρχει τέτοια σχέση μεταξύ εύρους και αριθμού ράβδων - Δ: Δεν είναι λάθος - είναι το αναμενόμενο αποτέλεσμα
Υπάρχουν δύο ράβδοι στο ιστόγραμμα επειδή δώσαμε την εντολή στην gf_histogram() να ορίσει το binwidth σε 4, και οι αριθμοί από 1 έως 5 δεν χωρούν σε ένα μόνο διάστημα εύρους 4 (βλ. και την Επεξήγηση της προηγούμενης ερώτησης). Η συνάρτηση δεν είχε άλλη επιλογή παρά να δημιουργήσει ένα δεύτερο διάστημα τιμών. Το πρώτο διάστημα τιμών κυμαίνεται από -2 έως 2 ή (-2, 2] και υπάρχουν μόνο δύο τιμές από το μικρό μας σύνολο τιμών που ανήκουν σε αυτό το διάστημα. Όλες οι άλλες τιμές ανήκουν στο διάστημα από 2 έως 6 ή [2, 6].
Ενδεχομένως να προκαλεί έκπληξη ότι η κλίμακα του άξονα x κυμαίνεται από το -2 έως το +6. Εξάλλου, καμία από τις τιμές μας δεν ήταν αρνητική. Η συνάρτηση έδωσε αυτό το αποτέλεσμα επειδή της αναθέσαμε κάτι δύσκολο. Έπρεπε να συμπεριλάβει στο ιστόγραμμα αριθμούς από το 1 έως το 5 και απαιτήσαμε το διάστημα να έχει εύρος (binwidth) 4. Επειδή δεν χωρούσαν όλες οι τιμές μας σε ένα μόνο διάστημα τιμών εύρους 4, χρειάστηκε να δημιουργήσει δύο διαστήματα τιμών ίσου εύρους.
4.3 Οπτικοποίηση Δεδομένων με Ιστογράμματα
Αν και μια απλή μεταβλητή, όπως η outcome παραπάνω, μπορεί να βοηθήσει στην κατανόηση της βασικής αρχής του ιστογράμματος, δεν αναδεικνύει πλήρως τη χρησιμότητά του. Τα ιστογράμματα είναι ιδιαίτερα χρήσιμα όταν επιχειρούμε να κατανοήσουμε κατανομές σε πραγματικά σύνολα δεδομένων με πολλές τιμές. Ας εξετάσουμε λοιπόν μερικά ιστογράμματα πραγματικών δεδομένων για να αξιολογήσουμε την αποτελεσματικότητά τους.
Σχήμα 4.2
Ποιος άξονας αντιπροσωπεύει τη μεταβλητή σε αυτά τα ιστογράμματα;
Επεξήγηση
άξονας x (οριζόντιος) είναι η σωστή απάντηση.
Όπως εξηγείται στο κείμενο: “Ο άξονας x του ιστογράμματος (με τον τίτλο ‘outcome’) αντιστοιχεί στο εύρος των πιθανών τιμών της μεταβλητής (σε αυτή την περίπτωση, από 1 έως 5). Η μεταβλητή στον άξονα x ενός ιστογράμματος είναι πάντα ποσοτική, δηλαδή μετρημένη σε συνεχή κλίμακα.”
Αντίθετα, ο άξονας y (κάθετος) αναπαριστά τη συχνότητα ή τον αριθμό των παρατηρήσεων (Count) που εμπίπτουν σε κάθε διάστημα τιμών, όχι τη μεταβλητή καθαυτή.
Σε όλα τα ιστογράμματα: - άξονας x: Οι τιμές της μεταβλητής που μελετάμε - άξονας y: Η συχνότητα εμφάνισης αυτών των τιμών
Ένα ιστόγραμμα απεικονίζει την κατανομή του μήκους του αντίχειρα (Thumb) στο σύνολο δεδομένων Fingers. Τα μήκη των αντίχειρων αναπαρίστανται στον άξονα x και η συχνότητα στον άξονα y.
Ο άξονας x ενός ιστογράμματος αντιστοιχεί στο εύρος των πιθανών τιμών των μεταβλητών που εξετάζονται. Στα παραδείγματα που προηγήθηκαν (δεξιόστροφα από πάνω αριστερά) απεικονίζονται: το μαθηματικό άγχος ενός δείγματος φοιτητών σε μια κλίμακα από 1 (χαμηλό) έως 5 (πολύ υψηλό), τα μήκη αντίχειρων του δείγματος φοιτητών σε χιλιοστά, το προσδόκιμο ζωής των πολιτών διαφόρων χωρών σε έτη και οι πληθυσμοί χωρών σε εκατομμύρια.
Αν ο άξονας x αντιπροσωπεύει τη μεταβλητή, τι αντιπροσωπεύει ο άξονας y σε αυτά τα ιστογράμματα;
Επεξήγηση
Συχνότητα (ή πλήθος) είναι η σωστή απάντηση.
Όπως εξηγείται στο κείμενο: “Ο άξονας y (με τον τίτλο ‘Count’) αντιστοιχεί στη συχνότητα εμφάνισης των τιμών της μεταβλητής.”
Ο άξονας y σε ένα ιστόγραμμα δείχνει πάντα: - Πόσες παρατηρήσεις εμπίπτουν σε κάθε διάστημα/κατηγορία - Τη συχνότητα ή το πλήθος των παρατηρήσεων σε κάθε εύρος - Όχι τις τιμές της μεταβλητής (αυτές βρίσκονται στον άξονα x)
Γιατί οι άλλες επιλογές είναι λάθος: - Β: Οι τιμές της μεταβλητής εμφανίζονται στον άξονα x, όχι στον άξονα y - Γ: Αν και τα ιστογράμματα μπορούν να δείχνουν ποσοστά (σχετικές συχνότητες), η προεπιλογή και πιο συνηθισμένη μορφή δείχνει απλό πλήθος/απόλυτες συχνότητες - Δ: Ο άξονας y δεν δείχνει την τιμή για ένα συγκεκριμένο άτομο, αλλά πόσα άτομα έχουν παρόμοιες τιμές
Το ύψος κάθε ράβδου σε ένα ιστόγραμμα δείχνει πόσες παρατηρήσεις εμπίπτουν σε αυτό το συγκεκριμένο εύρος τιμών, που είναι η συχνότητα ή το πλήθος.
Όλες αυτές οι μεταβλητές βρίσκονται σε πλαίσια δεδομένων (data frames). Για να δημιουργήσετε ένα βασικό ιστόγραμμα του μήκους του αντίχειρα (μεταβλητή Thumb) από το πλαίσιο δεδομένων Fingers χρησιμοποιώντας τη συνάρτηση gf_histogram(), ως εξής:
gf_histogram(~Thumb, data =Fingers)
Επειδή η μεταβλητή βρίσκεται πλέον σε ένα πλαίσιο δεδομένων, είναι απαραίτητο να καθορίσετε τόσο τη μεταβλητή (Thumb) όσο και το πλαίσιο δεδομένων (Fingers), ώστε η R να μπορέσει να εντοπίσει τη μεταβλητή. Στην περίπτωση των διανυσμάτων, αρκούσε η δήλωση του ονόματος του διανύσματος (π.χ., outcome).
Πειραματιστείτε με τον παρακάτω κώδικα για να δημιουργήσετε ένα ιστόγραμμα του μήκους αντίχειρα.
Παρατηρήστε ότι η μεταβλητή “Thumb” τοποθετείται μετά το σύμβολο ~, το οποίο ονομάζεται περισπωμένη ή tilde. Στην R συναντάμε συχνά τη σύνταξη y ~ x, όπου ό,τι προηγείται του ~ σχεδιάζεται στον άξονα y και ό,τι έπεται στον άξονα x. Ένα ιστόγραμμα αποτελεί ειδική περίπτωση, όπου ο άξονας y αναπαριστά μόνο τη συχνότητα των τιμών της μεταβλητής στον άξονα x, και όχι μια διαφορετική μεταβλητή. Γι’ αυτό και δεν υπάρχει όνομα μεταβλητής πριν το ~.
Αν θέλαμε να τοποθετήσουμε στον άξονα x μια άλλη μεταβλητή, όπως η MathAnxious (μια μέτρηση άγχους για τα μαθηματικά), ποια από τις παρακάτω εντολές θα ήταν η σωστή;
Επεξήγηση
gf_histogram(~ MathAnxious, data = Fingers) είναι η σωστή απάντηση.
Στη συνάρτηση gf_histogram() του πακέτου ggformula: - Η μεταβλητή που θέλουμε στον άξονα x τοποθετείται μετά από το σύμβολο ~ (tilde) - Το data = dataset καθορίζει από ποιο σύνολο δεδομένων προέρχεται η μεταβλητή
Η σύνταξη ~ μεταβλητή χρησιμοποιείται συχνά στις συναρτήσεις της R, όπου: - Το ~ διαχωρίζει τις μεταβλητές - Η μεταβλητή στα δεξιά του ~ εμφανίζεται στον άξονα x - Για τη δημιουργία ιστογράμματος δεν υπάρχει μεταβλητή στα αριστερά του ~
Οι άλλες επιλογές είναι λάθος: - Α: Η μεταβλητή πρέπει να βρίσκεται μετά από το ~, όχι πριν - Γ: Λάθος σύνταξη - το σύνολο δεδομένων δεν ορίζεται στην αρχή της συνάρτησης - Δ: Εντελώς λάθος σύνταξη
Σε ορισμένες περιπτώσεις μπορεί να επιθυμούμε να αλλάξουμε τα χρώματα στο ιστόγραμμα. Μπορούμε να τροποποιήσουμε το χρώμα γεμίσματος των ράβδων προσθέτοντας την παράμετρο fill και ορίζοντας το επιθυμητό χρώμα ράβδου σε εισαγωγικά (π.χ., “red”, “black”, “pink”). Μπορείτε να βρείτε μια λίστα με τα διαθέσιμα χρώματα στην R [εδώ] (PDF, 214KB).
Επιπλέον, μπορείτε να τροποποιήσετε το χρώμα των περιγραμμάτων γύρω από τις ράβδους χρησιμοποιώντας την παράμετρο color. Για να αυξήσετε το πάχος των ράβδων, προσθέστε την παράμετρο linewidth και ορίστε μια αριθμητική τιμή. Ακολουθεί ένα παράδειγμα:
Μπορούμε να βελτιώσουμε περαιτέρω ένα ιστογράμμα με την προσθήκη τίτλων και υπότιτλων. Για να το επιτύχουμε αυτό, απαιτείται ο συνδυασμός δύο συναρτήσεων: της gf_histogram() και της gf_labs() (η συνάρτηση που προσθέτει τους τίτλους). Για να συνδέσουμε συναρτήσεις μεταξύ τους στην R, χρησιμοποιούμε τον τελεστή διοχέτευσης (pipe operator) %>%, ο οποίος τοποθετείται στο τέλος μιας γραμμής κώδικα. Ο παρακάτω κώδικας προσθέτει έναν τίτλο σε ένα ιστόγραμμα.
Σε ορισμένες περιπτώσεις, ενδέχεται να θελήσετε να τροποποιήσετε τους τίτλους των αξόνων σε ένα ιστόγραμμα. Για παράδειγμα, θα μπορούσαμε να ονομάσουμε τον άξονα x «Μήκος Αντίχειρα (mm)» αντί για «Thumb». (Εάν δεν καθορίσετε τίτλο, η R απλώς χρησιμοποιεί το όνομα της μεταβλητής, δηλαδή “Thumb”.) Ακολουθεί ο κώδικας για την αλλαγή του τίτλου του άξονα x.
Τώρα, αλλάξτε τον τίτλο του άξονα y (σε κάτι που να έχει νόημα) τροποποιώντας τον ακόλουθο κώδικα.
Κάθε φορά που δημιουργείτε ιστογράμματα, μπορείτε να πειραματιστείτε ελεύθερα με τις διαφορετικές παραμέτρους σχετικά με το χρώμα, το γέμισμα ή τους τίτλους (και μην ξεχνάτε ότι μπορείτε να ορίσετε τον αριθμό των διαστημάτων, bins, ή το εύρος τους, binwidths).
Ιστογράμματα και Διαγράμματα Πυκνότητας Πιθανότητας
Τα ιστογράμματα σχετικής συχνότητας απεικονίζουν στον άξονα y την αναλογία (proportion) εμφάνισης των τιμών, αντί για την απόλυτη συχνότητα. Στα διαγράμματα που ακολουθούν, παρουσιάζουμε την κατανομή του απλού διανύσματος outcome με 7 τιμές (1, 2, 3, 3.2, 3.7, 4, 5) χρησιμοποιώντας στην κλίμακα του άξονα y τόσο συχνότητες (ιστόγραμμα στα αριστερά) όσο και αναλογίες ή σχετικές συχνότητες (ιστόγραμμα στα δεξιά). Σημειώνεται ότι αν οι σχετικές συχνότητες πολλαπλασιαστούν με το 100 τότε μετατρέπονται σε ποσοστά επί τοις εκατό (%).
Να συγκρίνετε και να αντιπαραβάλετε το ιστόγραμμα απόλυτης συχνότητας με το ιστόγραμμα σχετικής συγχνότητας. Σε τι μοιάζουν και σε τι διαφέρουν;
Επεξήγηση
Μοιάζουν στο σχήμα και στη θέση των ράβδων αλλά διαφέρουν στις τιμές του άξονα y είναι η σωστή απάντηση.
Ομοιότητες: - Ίδιο σχήμα κατανομής: Και στα δύο ιστογράμματα οι ράβδοι έχουν την ίδια σχετική διάταξη - Ίδια θέση ράβδων: Οι ράβδοι βρίσκονται στις ίδιες θέσεις στον άξονα x - Ίδιες αναλογίες: Η αναλογία των υψών των ράβδων παραμένει η ίδια - Ίδιος άξονας x: Οι τιμές της μεταβλητής outcome είναι ίδιες
Διαφορές: - Άξονας y - Κλίμακα: Το πρώτο ιστόγραμμα δείχνει απόλυτες συχνότητες (0-2), ενώ το δεύτερο σχετικές συχνότητες/αναλογίες (0-0.3) - Άξονας y - Ερμηνεία: Στο πρώτο διαβάζουμε ‘πόσες παρατηρήσεις’, στο δεύτερο ‘τι ποσοστό των παρατηρήσεων’ - Άξονας y - Άθροισμα: Στο πρώτο το άθροισμα των υψών = 7 (συνολικές παρατηρήσεις), στο δεύτερο = 1.0 (100%)
Γιατί οι άλλες επιλογές είναι λάθος: - Α: Ο άξονας x είναι ίδιος και στα δύο ιστογράμματα - Γ: Το σχήμα είναι ίδιο, όχι διαφορετικό - Δ: Υπάρχει μια σημαντική διαφορά (η κλίμακα του άξονα y)
Τα ιστογράμματα σχετικής συχνότητας είναι χρήσιμα επειδή μας επιτρέπουν να συγκρίνουμε πιο εύκολα κατανομές για δείγματα διαφορετικού μεγέθους. Αν ένα δείγμα 10 ατόμων περιλαμβάνει 5 χορτοφάγους και 5 μη χορτοφάγους, θα μπορούσαμε να πούμε ότι 0,5 (ή 50%) του δείγματος είναι χορτοφάγοι. Αν πάρουμε ένα δείγμα 100 ατόμων και οι 50 είναι χορτοφάγοι, η αναλογία παραμένει 0,5. Η χρήση της αναλογίας στην κλίμακα του άξονα y μας βοηθάει να διαπιστώσουμε ότι οι δύο κατανομές είναι παρόμοιες.
Ο πιο συνηθισμένος τρόπος, ωστόσο, για να αναπαραστήσουμε τη σχετική συχνότητα σε ένα ιστόγραμμα, είναι να χρησιμοποιήσουμε κλίμακα πυκνότητας πιθανότητας (probability density) αντί για κλίμακα αναλογίας. Η πυκνότητα διαφέρει από την απλή αναλογία με έναν σημαντικό τρόπο:
Αναλογία: Το ύψος της ράβδου δείχνει το ποσοστό των παρατηρήσεων Πυκνότητα πιθανότητας: Η περιοχή (εμβαδόν) της ράβδου δείχνει το ποσοστό των παρατηρήσεων
Η μαθηματική σχέση που συνδέει τις δύο έννοιες είναι:
Xρησιμοποιούμε την πυκνότητα πιθανότητας αντί της αναλογίας διότι (α) ανεξάρτητα από το εύρος διαστήματος που επιλέγουμε, η συνολική περιοχή κάτω από το ιστόγραμμα είναι πάντα ίση με 1, (β) συνδέεται θεωρητικά με τις κατανομές πιθανότητας που μελετάμε στη στατιστική και θα δούμε σε επόμενα κεφάλαια, και (γ) επιτρέπει τη σύγκριση ιστογραμμάτων με διαφορετικά εύρη διαστημάτων, καθώς η πυκνότητα πιθανότητας παραμένει συγκρίσιμη. Σημειώνεται ότι στην ειδική περίπτωση που το εύρος διαστήματος είναι ίσο με 1 η πυκνότητα είναι ακριβώς ίση με την αναλογία, επειδή διαιρούμε με το 1.
Για να δημιουργήσετε ιστογράμματα πυκνότητας πιθανότητας αντί για ιστογράμματα συχνότητας, μπορείτε να χρησιμοποιήσετε την ελαφρώς τροποποιημένη συνάρτηση, gf_dhistogram() (το επιπλέον d σημαίνει density). Εκτελέστε τον παρακάτω κώδικα για να δημιουργήσετε ένα βασικό ιστόγραμμα συχνότητας της μεταβλητής Age από το TeachingMethods. Στη συνέχεια προσθέστε το d σε αυτή τη γραμμή κώδικα για να δημιουργήσετε ένα ιστόγραμμα πυκνότητας πιθανότητας της ίδιας μεταβλητής (αλλάξτε τον τίτλο και το χρώμα γεμίσματος για να το διακρίνετε).
Σχήμα 4.3
Ποια είναι η διαφορά μεταξύ του ιστογράμματος πυκνότητας πιθανότητας και του ιστογράμματος συχνότητας που φαίνονται παραπάνω;
Επεξήγηση
Ο άξονας y είναι η σωστή απάντηση.
Η βασική διαφορά μεταξύ του ιστογράμματος πυκνότητας πιθανότητας και του ιστογράμματος συχνότητας είναι αυτό που αναπαριστά ο άξονας y:
Ιστόγραμμα συχνότητας: - άξονας y: Απόλυτη συχνότητα παρατηρήσεων (Count/Frequency) - Δείχνει πόσες φορές εμφανίζεται κάθε τιμή ή διάστημα τιμών
Ιστόγραμμα πυκνότητας πιθανότητας: - άξονας y: Πυκνότητα πιθανότητας (Density) - Δείχνει την αναλογία των παρατηρήσεων σε κάθε διάστημα διαιρεμένη με το πλάτος του διαστήματος - Το συνολικό εμβαδόν κάτω από την καμπύλη είναι 1
Οι άλλες επιλογές είναι λάθος: - Α: Ο άξονας x παραμένει ίδιος (η μεταβλητή που μελετάμε) - Γ: Το σχήμα της κατανομής παραμένει το ίδιο, αλλάζει μόνο η κλίμακα - Δ: Υπάρχει σημαντική διαφορά στην κλίμακα του άξονα y
Όπως μπορείτε να δείτε, τα σχήματα των δύο ιστογραμμάτων φαίνονται πανομοιότυπα. Αυτό βγάζει νόημα, επειδή οι παρατηρήσεις και τα διαστήματα τιμών είναι ίδια. Το μόνο διαφορετικό είναι η κλίμακα μέτρησης του άξονα y. Αριστερά, βρίσκεται η συχνότητα (ή αριθμός ατόμων)· δεξιά, βρίσκεται η πυκνότητα πιθανότητας (παρόμοια με την αναλογία ατόμων).
Προς το παρόν, εξετάζουμε μόνο μία κατανομή κάθε φορά οπότε το ιστόγραμμα πυκνότητας πιθανότητας φαίνεται να είναι κατά βάση το ίδιο με το ιστόγραμμα συχνότητας. Αργότερα, όταν αρχίσουμε να συγκρίνουμε πολλαπλές ομάδες τιμών, μπορεί να φαίνονται διαφορετικά.
4.4 Σχήμα, Κέντρο, Διασπορά και Ακραίες Τιμές
Ένα από τα πρώτα βήματα στην ανάλυση δεδομένων είναι η διερεύνηση των κατανομών των μεταβλητών. Παραλείποντας αυτό το στάδιο και προχωρώντας απευθείας στην εφαρμογή σύνθετων στατιστικών μεθόδων, αναλαμβάνετε σημαντικό ρίσκο. Τα ιστογράμματα αποτελούν ένα βασικό εργαλείο για την εξέταση των κατανομών, αλλά θα εξετάσουμε και άλλα εργαλεία. Πριν από αυτό, ας δούμε τι μπορούμε να συμπεράνουμε από τα ιστογράμματα.
Κατά τη διερεύνηση της κατανομής μιας μεταβλητής, εστιάζουμε συνήθως σε τέσσερα χαρακτηριστικά: το σχήμα (μορφή), το κέντρο, τη διασπορά και τις ακραίες τιμές.
Ακραίες Τιμές
Ας ξεκινήσουμε με τον ορισμό των ακραίων τιμών. Θα ανατρέξουμε στο σύνολο δεδομένων Fingers, όπου καταγράψαμε το μήκος του αντίχειρα σε ένα δείγμα φοιτητών (μεταξύ άλλων μεταβλητών). Αυτή τη φορά, θα χρησιμοποιήσουμε μια προγενέστερη, «ακατέργαστη» έκδοση του συνόλου δεδομένων, την FingersMessy.
Το Fingers είναι μια καθαρισμένη έκδοση του FingersMessy. Παρατηρώντας το ιστόγραμμα της μεταβλητής Thumb στο FingersMessy, γίνεται φανερό τι απαιτούσε καθαρισμό στα αρχικά δεδομένα.
Κατά την εκτέλεση της παραπάνω εντολής για τη δημιουργία του ιστογράμματος, ενδέχεται να εμφανίστηκε μια προειδοποίηση, όπως:
Warning: Removed 1 row containing non-finite outside the scale range (stat_bin()).
Αυτό οφείλεται στην ύπαρξη μιας ελλείπουσας τιμής (NA) στο σύνολο δεδομένων και δεν είναι ανησυχητικό.
Ενώ τα περισσότερα μήκη αντίχειρων των φοιτητών φαίνεται να συγκεντρώνονται γύρω από ένα σημείο λίγο κάτω από τα 60mm, υπάρχει μια μικρότερη ομάδα με πολύ μικρότερους αντίχειρες—περίπου το ένα δέκατο του μεγέθους! Αυτό δεν συμφωνεί με τις φυσικές ιδιότητες των ανθρώπων. Δεν υπάρχουν δύο διακριτές ομάδες ανθρώπων, αυτοί με κανονικούς και αυτοί με εξαιρετικά μικρούς αντίχειρες. Η κατανομή του μήκους αντίχειρα αναμένεται να είναι συνεχής (χωρίς κενά), με τους περισσότερους ανθρώπους να έχουν αντίχειρες μεσαίου μεγέθους, και τους λιγότερους να έχουν ελαφρώς μεγαλύτερους ή μικρότερους. Αυτό είναι το νόημα της «αναζήτησης ακραίων τιμών».
Γιατί, όμως, εμφανίστηκαν αυτές οι ακραίες τιμές; Πιθανόν, ορισμένοι φοιτητές να μην ακολούθησαν τις οδηγίες των ερευνητών και να μέτρησαν τους αντίχειρές τους σε εκατοστά (ή ίσως και σε ίντσες) αντί για χιλιοστά. Αυτή είναι μια εύλογη εξήγηση· οι συμμετέχοντες σε έρευνες δεν ακολουθούν πάντα τις οδηγίες.
Το σημαντικό είναι ότι, αν δεν είχαμε εξετάσει την κατανομή της μεταβλητής, δεν θα είχαμε εντοπίσει αυτή την ανωμαλία και θα μπορούσαμε να καταλήξουμε σε εσφαλμένα συμπεράσματα.
Αν η υπόθεσή μας είναι σωστή, ότι κάποιοι φοιτητές ανέφεραν το μήκος του αντίχειρά τους σε εκατοστά αντί για χιλιοστά, τι είδους σφάλμα θα ήταν αυτό;
Επεξήγηση
Συστηματικό σφάλμα μέτρησης είναι η σωστή απάντηση.
Αν οι φοιτητές μέτρησαν τους αντίχειρές τους σε εκατοστά αντί για χιλιοστά, αυτό αποτελεί συστηματικό σφάλμα μέτρησης. Αυτό το είδος σφάλματος χαρακτηρίζεται από τα εξής:
Το σφάλμα δεν είναι τυχαίο αλλά ακολουθεί ένα συγκεκριμένο (συστηματικό) μοτίβο (π.χ. η πραγματική τιμή δια 10, λόγω χρήσης εκατοστών αντί χιλιοστών. Οι συμμετέχοντες ενδέχεται να μην ακολούθησαν σωστά τις οδηγίες που δόθηκαν.)
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Σφάλμα δειγματοληψίας: Αναφέρεται στη διαφορά μεταξύ του δείγματος και του πληθυσμού, όχι σε λάθη στη μέτρηση μεμονωμένων παρατηρήσεων.
Γ - Ελλείπουσες τιμές: Δεν πρόκειται για ελλείπουσες τιμές καθώς έχουμε τιμές - απλώς είναι εσφαλμένες λόγω λάθους μονάδας μέτρησης.
Δ - Τυχαίο σφάλμα μέτρησης: Το τυχαίο σφάλμα είναι απρόβλεπτο και κατανέμεται τυχαία γύρω από την πραγματική τιμή. Εδώ όμως βλέπουμε ένα συστηματικό μοτίβο όπου συγκεκριμένες μετρήσεις είναι συστηματικά μικρότερες.
Κλειδί για κατανόηση: Το συστηματικό σφάλμα μέτρησης δημιουργεί μεροληψία στα δεδομένα και είναι πιο προβληματικό από το τυχαίο σφάλμα. Αυτός είναι ο λόγος που πρέπει πάντα να εξετάζουμε τις κατανομές των μεταβλητών μας για να εντοπίσουμε τέτοιου είδους προβλήματα.
Σχήματα Κατανομών
Δεν είναι απαραίτητο όλες οι ακραίες τιμές να οφείλονται σε σφάλματα, ούτε να είναι προβληματικές (θα δούμε τέτοιες περιπτώσεις σε επόμενη ενότητα). Όταν, όμως, οι ακραίες τιμές είναι προβληματικές, είναι απαραίτητο να τις διαχειριστούμε. Στην προκειμένη περίπτωση, επιλέξαμε να φιλτράρουμε τα δεδομένα, διατηρώντας μόνο τις μετρήσεις από φοιτητές με μήκος αντίχειρα τουλάχιστον 20mm, εξαλείφοντας έτσι τις εξαιρετικά μικρές τιμές. (Επιπλέον, αφαιρέσαμε ορισμένες εξαιρετικά μεγάλες τιμές, αποκλείοντας περιπτώσεις με μήκος αντίχειρα άνω των 100mm). Το φιλτραρισμένο αυτό σύνολο δεδομένων αποθηκεύτηκε με το όνομα Fingers, και είναι το σύνολο δεδομένων που χρησιμοποιήθηκε στο προηγούμενο κεφάλαιο. θα το χρησιμοποιήσουμε ξανά παρακάτω.
Πέρα από τις ακραίες τιμές, τα υπόλοιπα χαρακτηριστικά των κατανομών που μας ενδιαφέρουν είναι το σχήμα, το κέντρο και η διασπορά. Κάθε ένα από αυτά τα χαρακτηριστικά παρέχει σημαντικές πληροφορίες για τη μεταβλητή που εξετάζουμε. Ας χρησιμοποιήσουμε ξανά το σύνολο δεδομένων Fingers, το οποίο δεν περιέχει πλέον προβληματικές τιμές, και ας δημιουργήσουμε ένα ιστόγραμμα για τη μεταβλητή Thumb.
Δημιουργήστε ένα ιστόγραμμα πυκνότητας πιθανότητας της μεταβλητής Thumb (μήκος αντίχειρα).
Παρατηρήστε το ιστόγραμμα. Για να αξιολογήσετε το σχήμα της κατανομής, προσπαθήστε να εστιάσετε στο γενικό σχήμα του ιστογράμματος, σαν να ήταν ένα συμπαγές, ομαλό αντικείμενο, αντί για ένα σύνολο από λεπτές ράβδους. Αυτό θα σας βοηθήσει να κατανοήσετε το γενικό σχήμα της κατανομής.
Η R μπορεί να βοηθήσει στην οπτικοποίηση του σχήματος, προβάλλοντας ένα εξομαλυμένο σχήμα πάνω από το ιστόγραμμα, το οποίο ονομάζεται εξομαλυμένη καμπύλη πυκνότητας πιθανότητας. Για να τη δούμε, θα προσθέσουμε τη συνάρτηση gf_density() στο ιστόγραμμά μας, όπως φαίνεται στον κώδικα που ακολουθεί.
Σημειώστε ότι όταν προσθέτουμε την gf_density() στο διάγραμμα με τη χρήση του τελεστή %>%, δεν είναι απαραίτητο να καθορίσουμε τις παραμέτρους μέσα στις παρενθέσεις της συνάρτησης. Η R χρησιμοποιεί αυτόματα τις ίδιες παραμέτρους από την προηγούμενη εντολή.
Οι στατιστικολόγοι περιγράφουν το σχήμα των κατανομών χρησιμοποιώντας ορισμένα βασικά χαρακτηριστικά. Οι κατανομές μπορεί να είναι συμμετρικές ή ασύμμετρες, όπως στο παρακάτω διάγραμμα. Στην περίπτωση των ασύμμετρων κατανομών, αυτές μπορεί να είναι ασύμμετρες προς τα αριστερά (η ουρά της κατανομής εκτείνεται προς τα αριστερά) ή ασύμμετρες προς τα δεξιά (η ουρά της κατανομής εκτείνεται προς τα δεξιά).
Σχήμα 4.4
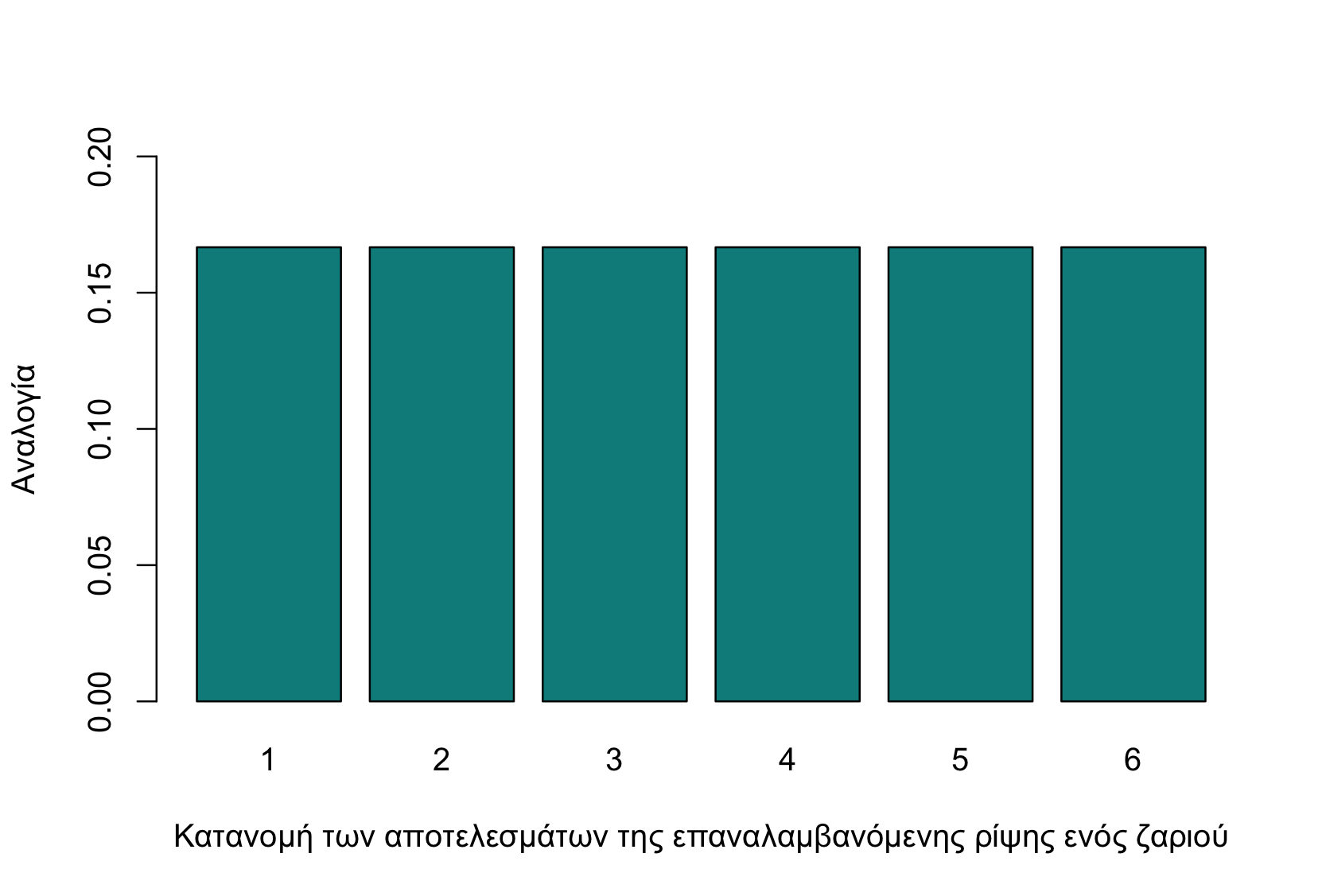
Οι κατανομές μπορεί επίσης να είναι ομοιόμορφες, υποδηλώνοντας ότι ο αριθμός των παρατηρήσεων είναι περίπου ο ίδιος για όλες τις πιθανές τιμές. Ακολουθούν παραδείγματα περίπου ομοιόμορφων κατανομών.
Σχήμα 4.5
Οι κατανομές διακρίνονται σε μονοκόρυφες, όπου οι περισσότερες τιμές συγκεντρώνονται γύρω από μία τιμή της μεταβλητής, και δικόρυφες, όπου υπάρχουν δύο διακριτές ομάδες τιμών γύρω από δύο τιμές της μεταβλητής, με λιγότερες τιμές να βρίσκονται ανάμεσα σε αυτές τις ομάδες (βλ. παρακάτω διάγραμμα).
Σχήμα 4.6
Οι κατανομές με σχήμα καμπάνας (μονοκόρυφες, περίπου συμμετρικές, με τις περισσότερες τιμές να συγκεντρώνονται κυρίως στο κέντρο και με τις υπόλοιπες τιμές να απέχουν από το κέντρο) ονομάζονται συχνά κανονικές κατανομές.
Σχήμα 4.7
Συνήθως, το σχήμα των κατανομών δεν είναι λείο και έχει διακυμάνσεις, γι’ αυτό και οι παραπάνω χαρακτηρισμοί (ομοιόμορφη, κανονική, συμμετρική κ.ο.κ.) συνοδεύονται από τη λέξη «περίπου». Έτσι, ακόμη και αν μια κατανομή δεν έχει ακριβώς τον ίδιο αριθμό παρατηρήσεων σε όλες τις πιθανές τιμές—αλλά έχει περίπου τον ίδιο αριθμό—θα μπορούσαμε να την ονομάσουμε περίπου ομοιόμορφη.
Αν παρατηρήσετε το διάγραμμα πυκνότητας πιθανότητας του μήκους του αντίχειρα που ακολουθεί, θα διακρίνετε δύο εξογκώματα (ή κορυφές) κοντά στο μέσο του εύρους των τιμών. Κάποιοι θα μπορούσαν να τη θεωρήσουν ως δικόρυφη κατανομή. Ωστόσο, οι στατιστικολόγοι θα την κατέτασσαν ως περίπου μονοκόρυφη και περίπου κανονική, επειδή τα εξογκώματα είναι αρκετά μικρά και βρίσκονται κοντά μεταξύ τους.
Σχήμα 4.8
Κέντρο και Διασπορά
Σε μια μονοκόρυφη κατανομή, είναι συχνά χρήσιμο να επισημάνουμε που βρίσκεται το κέντρο της. Όταν οι παρατηρήσεις συγκεντρώνονται γύρω από το κέντρο, η κεντρική αυτή τιμή μπορεί να αποτελέσει μια περιεκτική σύνοψη του δείγματος, επιτρέποντας διατυπώσεις όπως: «Οι περισσότεροι αντίχειρες στο δείγμα μας έχουν μήκος περίπου 60mm».
Η διασπορά αναφέρεται στο πόσο διασκορπισμένη ή «απλωμένη» είναι η κατανομή. Μπορεί επίσης να θεωρηθεί ως ένας τρόπος χαρακτηρισμού της μεταβλητότητας που υπάρχει στο δείγμα σε μια συγκεκριμένη μεταβλητή. Η δήλωση ότι το μεγαλύτερο μέρος του δείγματός μας έχει μήκος αντίχειρα περίπου 60mm έχει διαφορετική σημασία αν το εύρος τιμών κυμαίνεται από 50 έως 70 mm, σε σύγκριση με ένα εύρος τιμών από 2 έως 200mm.
Σχήμα 4.9
Πώς θα χαρακτηρίζατε την παραπάνω κατανομή όσον αφορά το κέντρο, το σχήμα, τη διασπορά και τυχόν προβληματικές ακραίες τιμές;
Επεξήγηση
Κέντρο περίπου στα 30-35 έτη, δικόρυφη κατανομή, μεσαία διασπορά, δεν φαίνεται να υπάρχουν προβληματικές ακραίες τιμές είναι η σωστή απάντηση.
Ανάλυση των χαρακτηριστικών της κατανομής:
Κέντρο: Το κέντρο της κατανομής βρίσκεται στην περιοχή 30-35 ετών. Σχήμα: Η κατανομή είναι δικόρυφη - έχει δύο κορυφές: - Κύρια κορυφή γύρω στα 29-30 έτη (συχνότητα 8) - Δεύτερη κορυφή γύρω στα 38-39 έτη (συχνότητα 7) - Υπάρχει μια «κοιλάδα» μεταξύ των δύο κορυφών γύρω στα 32-36 έτη
Διασπορά: Η διασπορά είναι μεσαία - οι τιμές εκτείνονται από περίπου 18 έως 62 έτη, που είναι εύλογο εύρος για ηλικίες.
Ακραίες τιμές: Δεν φαίνεται να υπάρχουν προβληματικές ακραίες τιμές - όλες οι ηλικίες είναι εντός λογικών ορίων και δεν υπάρχουν απομονωμένες τιμές μακριά από το κέντρο της κατανομής.
Γιατί οι άλλες επιλογές είναι λάθος:
Α: Η κατανομή δεν είναι συμμετρική - είναι δικόρυφη, και το κέντρο δεν είναι στα 40.
Γ: Η κατανομή δεν είναι ασύμμετρη προς τα δεξιά - είναι δικόρυφη, το κέντρο δεν είναι στα 25, και δεν φαίνεται να υπάρχουν προβληματικές ακραίες τιμές.
Δ: Η κατανομή δεν είναι ομοιόμορφη - έχει ξεκάθαρες κορυφές και κοιλάδες, και το κέντρο δεν είναι στα 45.
Πρακτική σημασία: Η δικόρυφη κατανομή ηλικιών μπορεί να υποδηλώνει ότι το δείγμα περιλαμβάνει δύο διαφορετικές ομάδες - π.χ. νεαρούς ενήλικες (25-32 ετών) και άτομα μεσαίας ηλικίας (35-42 ετών).
Eκτελέστε τον παρακάτω κώδικα για να δείτε το ιστόγραμμα.
Μόνο με βάση το παραπάνω ιστόγραμμα, πώς θα χαρακτηρίζατε αυτή την κατανομή; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Μονοκόρυφη και Ασύμμετρη είναι οι σωστές απαντήσεις.
Ανάλυση των χαρακτηριστικών:
✓ Μονοκόρυφη: Η κατανομή έχει μία ξεκάθαρη κορυφή γύρω στα 72-75 έτη. Δεν υπάρχουν πολλαπλές κορυφές.
✗ Δικόρυφη: Αν και υπάρχουν δύο ξεχωριστές κορυφές, αυτές βρίσκονται πολύ κοντά μεταξύ τους και δεν θα μπορούσε κανείς να υποθέσει ότι πρόκειται για διαφορετικές υποομάδες.
✗ Συμμετρική: Η κατανομή δεν είναι συμμετρική. Υπάρχει ξεκάθαρη ασυμμετρία.
✓ Ασύμμετρη: Η κατανομή έχει ασυμμετρία στα αριστερά: - Ο κύριος όγκος των δεδομένων βρίσκεται στις υψηλότερες τιμές (δεξιά πλευρά) - Υπάρχει μια “ουρά” που εκτείνεται προς τις χαμηλότερες τιμές (αριστερή πλευρά) - Η αριστερή πλευρά της κατανομής είναι πιο “τεντωμένη” από τη δεξιά
Πώς να αναγνωρίζετε την ασυμμετρία: - Ασυμμετρία στα αριστερά: Η ουρά εκτείνεται προς τα αριστερά (χαμηλότερες τιμές) - Ασυμμετρία στα δεξιά: Η ουρά εκτείνεται προς τα δεξιά (υψηλότερες τιμές) - Συμμετρική: Η κατανομή είναι ισορροπημένη και στις δύο πλευρές
Παράδειγμα: Το προσδόκιμο ζωής τείνει να έχει αυτό το μοτίβο παγκοσμίως - οι περισσότερες χώρες έχουν υψηλό προσδόκιμο ζωής, αλλά μερικές έχουν σημαντικά χαμηλότερο, δημιουργώντας την ουρά προς τα αριστερά.
Eκτελέστε τον παρακάτω κώδικα για να δείτε το ιστόγραμμα.
Πώς θα χαρακτηρίζατε την κατανομή του παραπάνω ιστογράμματος; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Μονοκόρυφη και Ασύμμετρη είναι οι σωστές απαντήσεις.
Ανάλυση των χαρακτηριστικών:
✓ Μονοκόρυφη: Η κατανομή έχει μία ξεκάθαρη κορυφή στις πολύ χαμηλές τιμές πληθυσμού (κοντά στο 0). Η συντριπτική πλειονότητα των παρατηρήσεων συγκεντρώνεται σε αυτή την περιοχή.
✗ Δικόρυφη: Δεν υπάρχουν δύο ξεκάθαρες κορυφές. Υπάρχει μόνο μία κύρια κορυφή στις χαμηλές τιμές και μερικές απομονωμένες παρατηρήσεις σε υψηλότερες τιμές.
✗ Συμμετρική: Η κατανομή είναι εξαιρετικά ασύμμετρη. Δεν υπάρχει ισορροπία μεταξύ αριστερής και δεξιάς πλευράς.
✓ Ασύμμετρη: Η κατανομή έχει έντονη ασυμμετρία στα δεξιά: - Ο κύριος όγκος των δεδομένων βρίσκεται στις χαμηλές τιμές (αριστερή πλευρά) - Υπάρχει μια μακριά “ουρά” που εκτείνεται προς τις υψηλότερες τιμές (δεξιά πλευρά) - Υπάρχουν λίγες ακραίες τιμές στις υψηλές τιμές του πληθυσμού (γύρω στα 1000 και 1200)
Χαρακτηριστικά αυτού του τύπου κατανομής: - Πολλές μικρές τιμές: Οι περισσότερες χώρες έχουν χαμηλό πληθυσμό - Λίγες μεγάλες τιμές: Μερικές χώρες έχουν πολύ υψηλό πληθυσμό - Τυπική για δημογραφικά δεδομένα: Αυτό το μοτίβο είναι συνηθισμένο σε κατανομές πληθυσμού χωρών
Ποια από τις παρακάτω μεταβλητές θα είχε πιθανότατα παρόμοιο σχήμα κατανομής με αυτή του πληθυσμού χωρών που είδατε παραπάνω; Υποθέστε ότι οι μεταβλητές αναφέρονται σε μια χώρα όπως η Ελλάδα
Επεξήγηση
Ετήσιο εισόδημα νοικοκυριών σε μια χώρα είναι η σωστή απάντηση.
Γιατί το εισόδημα έχει παρόμοια κατανομή με τον πληθυσμό:
Κοινά χαρακτηριστικά: - Μονοκόρυφη κατανομή με κορυφή στις χαμηλές τιμές - Έντονη ασυμμετρία προς τα δεξιά - Πολλές χαμηλές τιμές: Οι περισσότεροι έχουν χαμηλά προς μέτρια εισοδήματα - Λίγες εξαιρετικά υψηλές τιμές: Μικρό ποσοστό έχει πολύ υψηλά εισοδήματα (πλούσιοι) - Παρουσία ακραίων τιμών: Εξαιρετικά πλούσια άτομα αποτελούν ακραίες τιμές - Φυσικό κάτω όριο: Το εισόδημα δεν μπορεί να είναι αρνητικό
Γιατί οι άλλες επιλογές είναι λάθος:
✗ Ύψος ενηλίκων ανδρών: Ακολουθεί περίπου κανονική κατανομή (καμπάνα): - Συμμετρική γύρω από το κέντρο (π.χ. 175cm) - Λίγοι πολύ ψηλοί ή πολύ κοντοί - Δεν έχει το σχήμα της δεξιά ασύμμετρης κατανομής
✗ Βαθμολογίες σε εξετάσεις: Συνήθως κανονική ή ελαφρώς αριστερόστροφη: - Οι περισσότεροι βαθμοί συγκεντρώνονται γύρω από το κέντρο - Περιορισμένο εύρος (0-100) - Συνήθως δεν αναμένουμε ακραίες τιμές
✗ Ηλικία συνταξιοδότησης: Στενό εύρος τιμών: - Συγκεντρώνεται γύρω από συνηθισμένες ηλικίες συνταξιοδότησης (60-67 ετών) - Δεν έχει μακριά ουρά προς τα δεξιά - Περιορισμένη διασπορά
Άλλα παραδείγματα μεταβλητών με παρόμοια κατανομή: - Μέγεθος επιχειρήσεων (αριθμός εργαζομένων) - Τιμές ακινήτων μιας πόλης - Μέγεθος αρχείων υπολογιστή - Πωλήσεις προϊόντων
4.5 Η Σύνοψη των Πέντε Αριθμών
Μέχρι στιγμής, χρησιμοποιούσαμε τα ιστογράμματα ως το κύριο εργαλείο για την εξέταση κατανομών. Ωστόσο, τα ιστογράμματα δεν είναι το μοναδικό διαθέσιμο εργαλείο. Σε αυτή την ενότητα θα παρουσιάσουμε επιπλέον εργαλεία για την ανάλυση κατανομών ποσοτικών μεταβλητών. Στη συνέχεια του κεφαλαίου, θα εξετάσουμε επίσης εργαλεία για την ανάλυση κατανομών ποιοτικών μεταβλητών.
Επανεξέταση της Ταξινόμησης και Ελάχιστου/Μέγιστου/Διάμεσου
Στο προηγούμενο κεφάλαιο, παρουσιάσαμε την ιδέα της ταξινόμησης των τιμών μιας ποσοτικής μεταβλητής σε αύξουσα ή φθίνουσα σειρά. Πριν ταξινομήσουμε τους αριθμούς, ήταν δύσκολο να παρατηρήσουμε κάποιο μοτίβο στα δεδομένα. Η απλή ανάγνωση των αριθμών δεν επέτρεπε την εξαγωγή συμπερασμάτων σχετικά με την κατανομή.
Μετά την ταξινόμηση, αναδεικνύονται ορισμένα χαρακτηριστικά της κατανομής. Για παράδειγμα, ακόμη και σε μια εκτενή λίστα αριθμών, η ταξινόμηση επιτρέπει την άμεση αναγνώριση του ελάχιστου και του μέγιστου. Αυτή η πληροφορία, δεν είναι άμεσα ορατή σε μια μη ταξινομημένη λίστα.
Για να το δείξουμε αυτό, εξετάζουμε τη μεταβλητή Weight (Βάρος) στο πλαίσιο δεδομένων Fingers. Θα γράψουμε κώδικα για την ταξινόμηση των φοιτητών με βάση το βάρος τους, από το μικρότερο στο μεγαλύτερο, και στη συνέχεια θα προκύψει το ελάχιστο και το μέγιστο βάρος τους.
Σημειώνεται ότι για την ταξινόμηση μπορεί επίσης να χρησιμοποιηθεί η συνάρτηση arrange(), αλλά αυτή ταξινομεί ολόκληρο το πλαίσιο δεδομένων. Επειδή επιθυμούμε μόνο την εμφάνιση των ταξινομημένων βαρών στη σειρά, χρησιμοποιούμε τη συνάρτηση sort() στο διάνυσμα Fingers$Weight.
Μετά την ταξινόμηση, διαπιστώνουμε ότι το ελάχιστο βάρος είναι περίπου 43 κιλά και το μέγιστο περίπου 150 κιλά. Εκτός από την γνώση του ελάχιστου και μέγιστου βάρους, είναι χρήσιμο να προσδιορίσουμε την τιμή που βρίσκεται ακριβώς στο μέσο της κατανομής. Εάν υπάρχουν 157 φοιτητές, αναζητούμε το βάρος του 79ου φοιτητή, καθώς υπάρχουν 78 βάρη μικρότερα και 78 βάρη μεγαλύτερα από αυτό. Αυτός ο μεσαίος αριθμός ονομάζεται διάμεσος.
Με βάση τα ταξινομημένα δεδομένα βάρους των 157 φοιτητών που φαίνονται παραπάνω, ποια είναι η διάμεσος (median);
Επεξήγηση
61.68851 είναι η σωστή απάντηση.
Πώς βρίσκουμε τη διάμεσο:
Η διάμεσος είναι η τιμή που βρίσκεται ακριβώς στο μέσο μιας ταξινομημένης λίστας δεδομένων.
Βήμα 1: Προσδιορισμός της θέσης - Συνολικός αριθμός παρατηρήσεων: n = 157 - Επειδή το n είναι περιττός, η διάμεσος είναι η τιμή στη θέση: (n + 1) ÷ 2 - Θέση διαμέσου = (157 + 1) ÷ 2 = 158 ÷ 2 = 79η θέση
Βήμα 2: Εντοπισμός της 79ης τιμής Κοιτάζοντας τη ταξινομημένη λίστα: - Θέση 78: 61.23492 - Θέση 79: 61.68851 ← Αυτή είναι η διάμεσος - Θέση 80: 62.14210
Επαλήθευση: - 78 τιμές είναι μικρότερες από 61.68851 - 78 τιμές είναι μεγαλύτερες από 61.68851 - Η διάμεσος χωρίζει τα δεδομένα σε δύο ίσα μέρη
Γιατί οι άλλες επιλογές είναι λάθος:
Α - 58.96696: Αυτή είναι μια τιμή γύρω στη θέση 65-70, όχι στη 79η
Β - 60.32774: Αυτή είναι μια τιμή γύρω στη θέση 75-76, όχι στη 79η
Δ - 62.14210: Αυτή είναι η τιμή στη θέση 80, όχι στη 79η
Σημαντική σημείωση: Αν το n ήταν άρτιος (π.χ. 156), τότε η διάμεσος θα ήταν ο μέσος όρος των δύο μεσαίων τιμών: - Θα παίρναμε τις τιμές στις θέσεις 78 και 79 - Διάμεσος = (61.23492 + 61.68851) ÷ 2 = 61.46172
Πρακτική σημασία: Η διάμεσος (61.69 kg) μας λέει ότι το μισό από τους φοιτητές ζυγίζει λιγότερο από 61.69 kg και το άλλο μισό ζυγίζει περισσότερο.
Αριθμοί όπως το ελάχιστο (min), η διάμεσος και το μέγιστο (max) είναι χρήσιμοι για την κατανόηση μιας κατανομής. Μπορούν να θεωρηθούν ως μια συνοπτική περιγραφή της κατανομής με τρεις αριθμούς. Στη συνέχεια, θα αναφερθούμε στην σύνοψη των πέντε αριθμών.
Η συνάρτηση favstats() (αγαπημένα στατιστικά), που περιλαμβάνεται στο πακέτο mosaic, συνοψίζει γρήγορα αυτές τις τιμές. Μπορείτε να εκτελέσετε τον παρακάτω κώδικα για να δείτε τα στατιστικά αυτά για το βάρος (Weight).
Η συνάρτηση favstats() παράγει πολλούς επιπλέον αριθμούς, αλλά προς το παρόν εστιάζουμε στα min, median και max. Η σύγκριση της διάμεσου του βάρους με το ελάχιστο και το μέγιστο επιτρέπει την εξαγωγή συμπερασμάτων σχετικά με το σχήμα της κατανομής.
Δεδομένων των περιγραφικών στατιστικών για το βάρος: ελάχιστο = 43.09, διάμεσος = 61.69, μέγιστο = 149.69, το γεγονός ότι η διάμεσος (61.69) είναι πιο κοντά στο ελάχιστο (43.09) παρά στο μέγιστο (149.69) τι θεωρείται ότι υποδηλώνει για την κατανομή;
Επεξήγηση
Μπορεί να είναι ασύμμετρη δεξιά είναι η σωστή απάντηση.
Ανάλυση:
Εξετάζουμε τις αποστάσεις της διαμέσου από τα άκρα:
Ελάχιστο: 43.09
Διάμεσος: 61.69
Μέγιστο: 149.69
Υπολογισμός αποστάσεων: - Απόσταση από ελάχιστο: 61.69 - 43.09 = 18.60 - Απόσταση από μέγιστο: 149.69 - 61.69 = 88.00
Παρατήρηση: Η διάμεσος είναι σημαντικά πιο κοντά στο ελάχιστο από ό,τι στο μέγιστο!
Τι σημαίνει αυτό:
Ένδειξη ασυμμετρίας στα δεξιά: Όταν η διάμεσος βρίσκεται πιο κοντά στο ελάχιστο από ό,τι στο μέγιστο, αυτό υποδηλώνει ασυμμετρία στα δεξιά ή θετική ασυμμετρία:
Η πλειονότητα των δεδομένων των τιμών συγκεντρώνεται στις χαμηλότερες τιμές
Υπάρχει μια “ουρά” που εκτείνεται προς τις υψηλότερες τιμές (δεξιά)
Ορισμένες ακραίες υψηλές τιμές “έλκουν” το μέγιστο μακριά από τη διάμεσο
Επιπλέον ενδείξεις από τα στατιστικά: - Μέσος όρος (65.43) > Διάμεσος (61.69): Αυτό είναι χαρακτηριστικό ασυμμετρίας στα δεξιά - Μεγάλη τυπική απόκλιση (16.88): Υποδηλώνει μεγάλη διασπορά, συνηθισμένη σε κατανομές με ασυμμετρία
Γιατί οι άλλες επιλογές είναι λάθος:
Α (Συμμετρική): Σε μια συμμετρική κατανομή, η διάμεσος θα βρισκόταν περίπου στο μέσο μεταξύ του ελάχιστου και του μέγιστου.
Γ (Ασυμμετρία στα αριστερά): Σε αυτή την περίπτωση, η διάμεσος θα ήταν πιο κοντά στο μέγιστο.
Δ (Δικόρυφη): Η θέση της διάμεσου δεν παρέχει πληροφορίες σχετικά με τον αριθμό των κορυφών.
Πρακτική σημασία: Η ασυμμετρία στα δεξιά για το βάρος είναι συνηθισμένη – οι περισσότεροι άνθρωποι έχουν κανονικό βάρος, αλλά ορισμένοι έχουν σημαντικά υψηλότερο βάρος, δημιουργώντας την ουρά προς τα δεξιά.
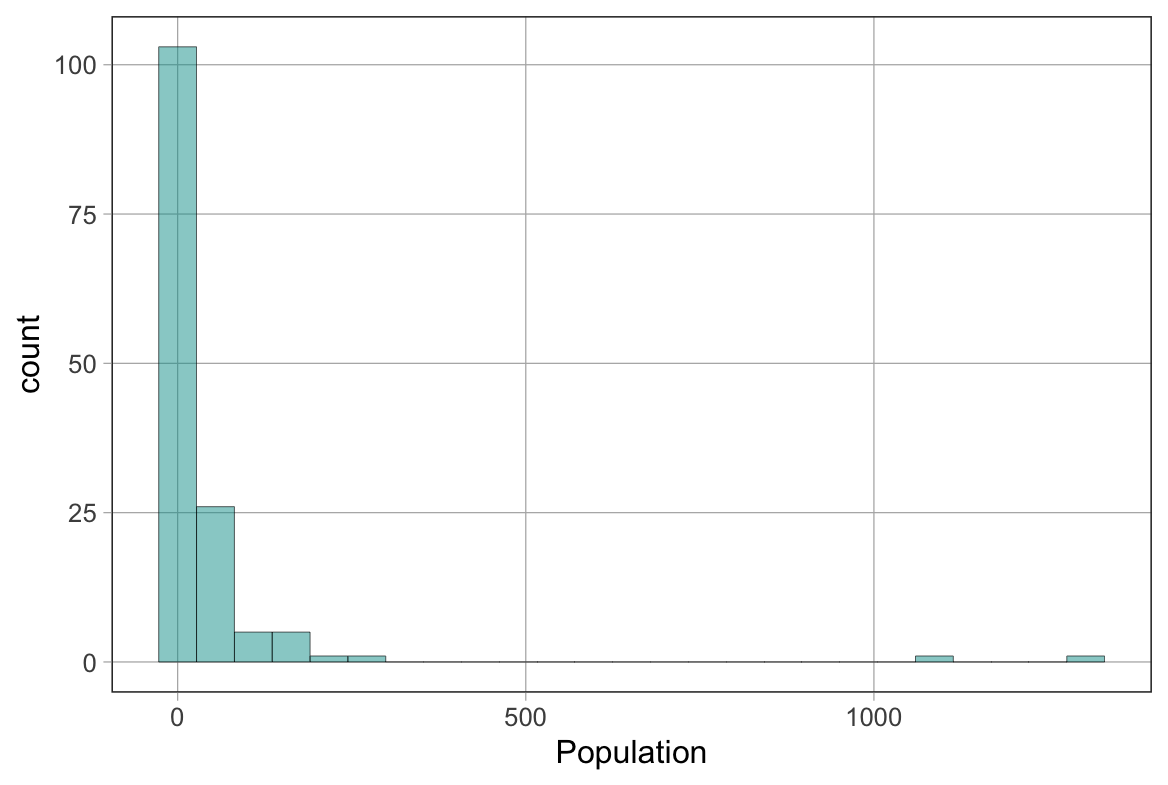
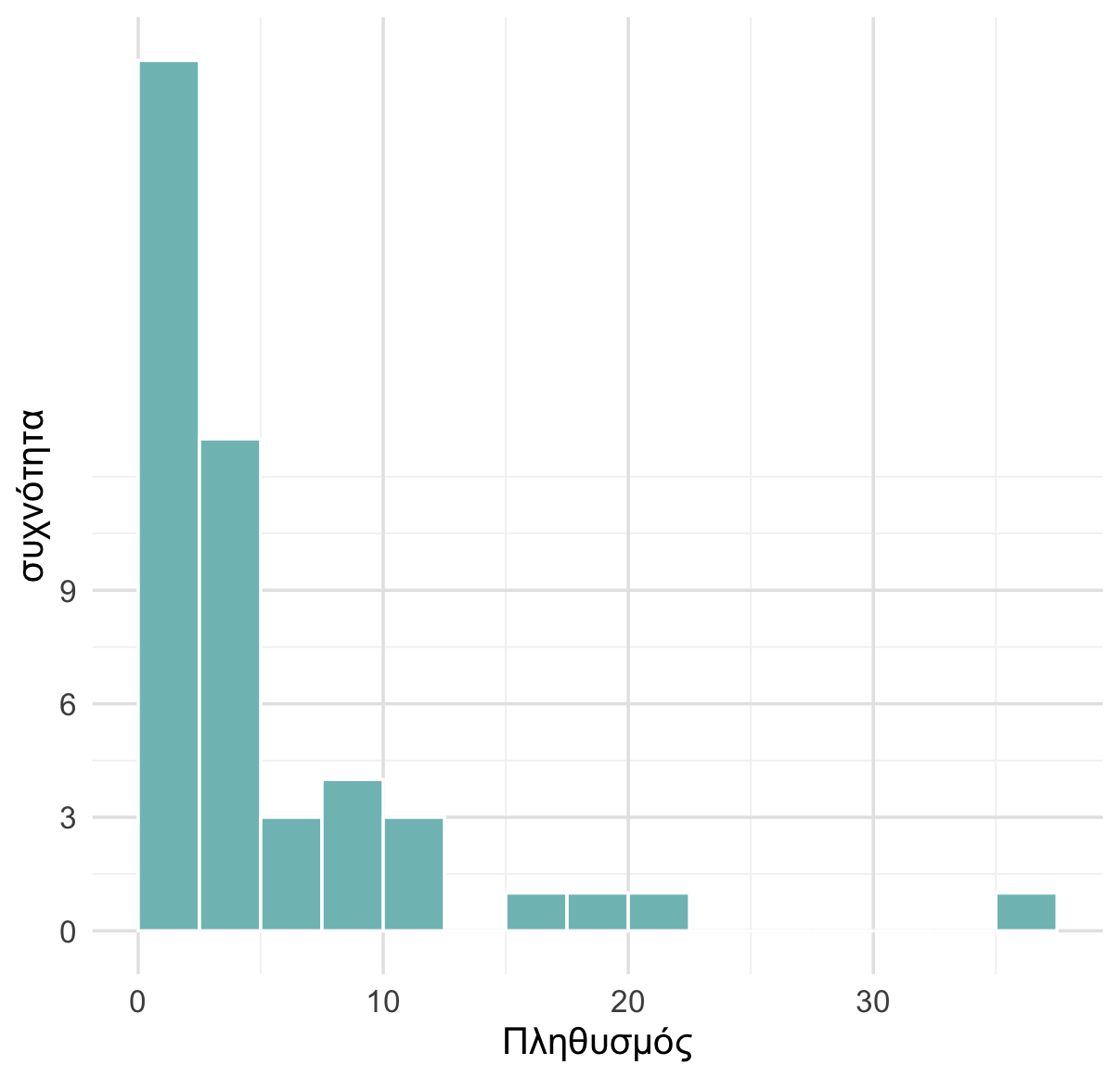
Προσπαθήστε να γράψετε κώδικα για να εξαγάγετε τα favstats() για τη μεταβλητή Population (Πληθυσμός) για τις χώρες στο πλαίσιο δεδομένων Happy.
Παρατηρήστε την τιμή του max. Μισό λεπτό! Αυτό σημαίνει ότι η χώρα με τον μέγιστο πληθυσμό έχει μόνο 1.304 άτομα; ΥΠΟΔΕΙΞΗ: Μπορεί να βοηθήσει η επανεξέταση της δομής του συνόλου δεδομένων:
Country - Όνομα χώρας
Region - 1 = Λατινική Αμερική, 2 = Δυτικά έθνη, 3 = Μέση Ανατολή, 4 = Υποσαχάρια Αφρική, 5 = Νότια Ασία, 6 = Ανατολική Ασία, 7 = πρώην Κομμουνιστικές χώρες.
Happiness - Βαθμολογία σε κλίμακα 0-10 για το μέσο επίπεδο ευτυχίας (10 είναι το ανώτερο)
LifeExpectancy - Μέσο προσδόκιμο ζωής (σε έτη)
Footprint - Οικολογικό αποτύπωμα, που είναι ένα μέτρο του (κατά κεφαλήν) οικολογικού αντικτύπου
HLY - Happy Life Years συνδυάζει το προσδόκιμο ζωής με την ευημερία
HPI - Happy Planet Index (κλίμακα ευημερίας 0-100)
Σύμφωνα με την περιγραφή των δεδομένων, η μεταβλητή πληθυσμός χώρας (Population) μετριέται σε εκατομμύρια.
Αυτό σημαίνει: - Αν η μέγιστη τιμή είναι 1.304, αυτό αντιπροσωπεύει 1.304 εκατομμύρια άτομα - 1.304 εκατομμύρια = 1.304.000.000 άτομα (πάνω από 1,3 δισεκατομμύρια!) - Αυτό είναι λογικό και αντιστοιχεί στον πληθυσμό της Κίνας, που είναι η πολυπληθέστερη χώρα του κόσμου
Γενικό δίδαγμα:Πάντα ελέγχετε τις μονάδες μέτρησης! Όταν αναλύετε δεδομένα, είναι κρίσιμο να κατανοήσετε: - Σε τι μονάδες είναι εκφρασμένη κάθε μεταβλητή - Αν έχει γίνει μετατροπή μονάδων (π.χ. εκατομμύρια, χιλιάδες, ποσοστά) - Αν οι τιμές έχουν νόημα στον πραγματικό κόσμο
Παραδείγματα άλλων συνηθισμένων μονάδων: - Οικονομικά δεδομένα: συχνά σε χιλιάδες ή εκατομμύρια δολάρια - Πληθυσμιακά δεδομένα: συχνά σε χιλιάδες ή εκατομμύρια άτομα - Αποστάσεις: μπορεί να είναι σε χιλιόμετρα, μίλια, χιλιοστά κ.λπ.
Αυτός είναι ένας από τους λόγους που η εξερεύνηση και ο έλεγχος των δεδομένων είναι τόσο σημαντικός πριν από οποιαδήποτε ανάλυση!
Στην περίπτωση του πληθυσμού, η διάμεσος (10 εκατομμύρια άτομα) είναι πολύ πιο κοντά στον ελάχιστο πληθυσμό (απόσταση περίπου 10 εκατομμυρίων) παρά στον μέγιστο πληθυσμό (απόσταση άνω των 1.290 εκατομμυρίων). Τι υποδηλώνει αυτό για το σχήμα της κατανομής;
Επεξήγηση
Είναι πιθανώς ασύμμετρη είναι η σωστή απάντηση.
Ανάλυση της πληροφορίας:
Ας εξετάσουμε τις αποστάσεις της διαμέσου από τα άκρα:
Ελάχιστος πληθυσμός: ~0.3 εκατομμύρια (300.000 άτομα)
Διάμεσος πληθυσμός: 10 εκατομμύρια
Μέγιστος πληθυσμός: ~1.304 εκατομμύρια (1,3 δισεκατομμύρια)
Υπολογισμός αποστάσεων: - Απόσταση από ελάχιστο: 10 - 0.3 = 9.7 εκατομμύρια - Απόσταση από μέγιστο: 1.304 - 10 = 1.294 εκατομμύρια
Παρατήρηση: Η διάμεσος είναι πολύ πιο κοντά στο ελάχιστο (περίπου 133 φορές πιο κοντά!).
Τι σημαίνει αυτό:
Έντονη ασυμμετρία στα δεξιά:
Οι περισσότερες χώρες έχουν σχετικά μικρό πληθυσμό (κάτω από 10-20 εκατομμύρια)
Λίγες χώρες έχουν πολύ μεγάλο πληθυσμό (π.χ. Κίνα, Ινδία με >1 δισεκατομμύριο)
Αυτές οι λίγες “γιγαντιαίες” χώρες δημιουργούν τη μακριά ουρά προς τα δεξιά
Χαρακτηριστικά της ασυμμετρίας στα δεξιά: - Κύριος όγκος των δεδομένων: Συγκεντρωμένος στις χαμηλότερες τιμές (μικρότερος πληθυσμός) - Μακριά ουρά: Εκτείνεται προς τις υψηλότερες τιμές (μεγαλύτερος πληθυσμός) - Ακραίες τιμές: Λίγες χώρες με εξαιρετικά μεγάλο πληθυσμό
Γιατί οι άλλες επιλογές είναι λάθος:
Α (Διώροφη): Η τεράστια απόσταση μεταξύ διαμέσου και μεγίστου δεν υποδηλώνει δύο κορυφές, αλλά μια μακριά ουρά.
Γ (Συμμετρική): Σε συμμετρική κατανομή, η διάμεσος θα ήταν περίπου στη μέση μεταξύ ελαχίστου και μεγίστου. Εδώ υπάρχει τεράστια ασυμμετρία.
Πραγματικότητα: Η κατανομή του πληθυσμού των χωρών είναι ένα κλασικό παράδειγμα έντονης ασυμμετρίας στα δεξιά - οι περισσότερες χώρες είναι μικρές, αλλά λίγες “υπερδυνάμεις” όπως η Κίνα και η Ινδία έχουν τεράστιο πληθυσμό.
Δημιουργήστε ένα ιστόγραμμα της μεταβλητής Population για να δείτε αν η διαίσθησή σας για το σχήμα αυτής της κατανομής είναι σωστή αντί να κοιτάξετε τα min/median/max .
Αν είχατε μια άλλη μεταβλητή για την οποία η διάμεσος ήταν πολύ πιο μακριά από το ελάχιστο και πολύ πιο κοντά στο μέγιστο, πώς θα περιμένατε να μοιάζει η κατανομή;
Επεξήγηση
Θα ήταν πιθανώς ασύμμετρη είναι η σωστή απάντηση.
Ανάλυση του σεναρίου:
Αν η διάμεσος είναι: - Πολύ πιο μακριά από το ελάχιστο - Πολύ πιο κοντά στο μέγιστο
Αυτό υποδηλώνει ασυμμετρία στα αριστερά (ή αρνητική ασυμμετρία).
Σύγκριση των δύο τύπων ασυμμετρίας:
Ασυμμετρία στα δεξιά - όπως ο πληθυσμός: - Διάμεσος κοντά στο ελάχιστο, μακριά από το μέγιστο - Κύριος όγκος των δεδομένων στις χαμηλές τιμές - Μακριά ουρά προς τις υψηλές τιμές - Παράδειγμα: εισόδημα, πληθυσμός χωρών
Ασυμμετρία στα αριστερά - το σενάριο της ερώτησης: - Διάμεσος κοντά στο μέγιστο, μακριά από το ελάχιστο - Κύριος όγκος των δεδομένων στις υψηλές τιμές - Μακριά ουρά προς τις χαμηλές τιμές - Παράδειγμα: προσδόκιμο ζωής, βαθμολογίες σε εύκολο τεστ
Γιατί οι άλλες επιλογές είναι λάθος:
Α (Δικόρυφη): Η θέση της διαμέσου σε σχέση με τα άκρα δεν υποδηλώνει πολλαπλές κορυφές, αλλά ασυμμετρία.
Γ (Συμμετρική): Σε συμμετρική κατανομή, η διάμεσος θα ήταν περίπου στη μέση μεταξύ ελαχίστου και μεγίστου, όχι κοντά στο ένα άκρο.
Πρακτικά παραδείγματα ασυμμετρίας στα αριστερά: - Ηλικία θανάτου: Οι περισσότεροι άνθρωποι ζουν μέχρι μεγάλη ηλικία, λίγοι πεθαίνουν νωρίς - Βαθμολογίες σε εύκολο τεστ: Οι περισσότεροι παίρνουν υψηλούς βαθμούς, λίγοι αποτυγχάνουν - Ποιότητα ζωής σε αναπτυγμένες χώρες: Οι περισσότεροι έχουν καλή ποιότητα ζωής
Κλειδί για κατανόηση: Η θέση της διαμέσου σε σχέση με τα άκρα είναι ένας γρήγορος τρόπος να εντοπίσετε το είδος της ασυμμετρίας!
4.6 Τεταρτημόρια και η Σύνοψη των Πέντε Αριθμών
Μια εναλλακτική προσέγγιση για την κατανόηση της διαδικασίας είναι η εξής: ας υποθέσουμε ότι όλες οι παρατηρήσεις μας είναι ταξινομημένες και διατεταγμένες κατά μήκος μιας ευθείας, με βάση τις τιμές τους σε μια ποσοτική μεταβλητή.
Σχήμα 4.10
Στην παρακάτω εικόνα έχουμε τοποθετήσει μερικές πορτοκαλί κάθετες γραμμές για να δείξουμε το ελάχιστο (minimum, ή ελάχιστη τιμή), τη διάμεσο (median, ή μεσαία τιμή) και το μέγιστο (maximum, η μέγιστη τιμή). Η κατανομή χωρίζεται σε δύο ομάδες με ίσο αριθμό παρατηρήσεων, διαχωρισμένες στη διάμεσο.
Στην εικόνα που ακολουθεί, έχουν τοποθετηθεί κάθετες πορτοκαλί γραμμές για να υποδείξουν το ελάχιστο (min), τη διάμεσο ή μεσαία τιμή (median) και το μέγιστο (max). Η κατανομή χωρίζεται σε δύο ομάδες με ίσο αριθμό παρατηρήσεων, οι οποίες διαχωρίζονται από τη διάμεσο.
Επισημαίνεται ότι σε περίπτωση άρτιου αριθμού παρατηρήσεων (π.χ., στο παρόν παράδειγμα όπου υπάρχουν οκτώ), δεν υφίσταται «μεσαία τιμή». Σε αυτήν την περίπτωση, η διάμεσος υπολογίζεται ως το ημιάθροισμα των δύο μεσαίων τιμών της μεταβλητής.
Κάθε μία από αυτές τις ομάδες ίσου μεγέθους μπορεί να θεωρηθεί ως ένα μισό, και σχεδιάζουμε ένα ορθογώνιο περίγραμμα γύρω από κάθε μισό των τιμών, όπως φαίνεται παρακάτω. (Μπορείτε να μετρήσετε τις τιμές και να διαπιστώσετε ότι υπάρχουν 8 σε κάθε μισό.)
Διαιρώντας εκ νέου κάθε μισό σε δύο ίσα μέρη, προκύπτουν τα τεταρτημόρια, καθένα από τα οποία περιέχει ίσο αριθμό παρατηρήσεων. Η διαδικασία αυτή αντιστοιχεί στην ταξινόμηση ενός μεγάλου διανύσματος τιμών μιας μεταβλητής και στη συνέχεια στον διαχωρισμό του σε τέσσερις ομάδες ίσου μεγέθους.
Σχήμα 4.11
Κάθε ορθογώνιο αντιπροσωπεύει ένα τεταρτημόριο. Το αριστερότερο ορθογώνιο, που περιλαμβάνει το χαμηλότερο 25% των τιμών, ονομάζεται πρώτο τεταρτημόριο (ή κάτω τεταρτημόριο). Το επόμενο ορθογώνιο, μέχρι τη διάμεσο, ονομάζεται δεύτερο τεταρτημόριο. Τα δύο ορθογώνια πέρα από τη διάμεσο, στο άνω μισό της κατανομής, ονομάζονται τρίτο τεταρτημόριο και τέταρτο τεταρτημόριο (ή άνω τεταρτημόριο), αντίστοιχα.
Σχήμα 4.12
Σε ποια στατιστικά αντιστοιχούν τα γράμματα A έως F στην παραπάνω εικόνα;
Τα τεταρτημόρια είναι ίσου μεγέθους. Τι είναι «ίσο» στα τεταρτημόρια;
Επεξήγηση
Το καθένα έχει τον ίδιο αριθμό παρατηρήσεων είναι η σωστή απάντηση.
Θεμελιώδης αρχή των τεταρτημορίων:
Τα τεταρτημόρια ορίζονται με βάση το πλήθος των παρατηρήσεων, όχι με βάση τις τιμές της μεταβλητής.
Τι είναι ίσο: - Κάθε τεταρτημόριο περιέχει ακριβώς το 25% των παρατηρήσεων - Αν έχουμε 100 παρατηρήσεις, κάθε τεταρτημόριο έχει 25 παρατηρήσεις - Αν έχουμε 80 παρατηρήσεις, κάθε τεταρτημόριο έχει 20 παρατηρήσεις
Θυμηθείτε: Τα τεταρτημόρια χωρίζουν τα δεδομένα, όχι την κλίμακα μέτρησης!
Είναι σημαντικό να τονιστεί ότι η ισότητα μεταξύ των τεσσάρων τεταρτημορίων έγκειται στον αριθμό των παρατηρήσεων που περιλαμβάνονται σε κάθε ένα. Κάθε τεταρτημόριο περιέχει το ένα τέταρτο του συνόλου των παρατηρήσεων, ανεξάρτητα από τις ακριβείς τιμές της μεταβλητής.
Για να προσδιοριστεί η θέση έναρξης και λήξης ενός τεταρτημορίου στην κλίμακα μέτρησης, οι στατιστικολόγοι έχουν ονομάσει κάθε σημείο-κατώφλι (οι πορτοκαλί γραμμές) ως Q0, Q1, Q2, Q3 και Q4. Η «σύνοψη των πέντε αριθμών» αναφέρεται σε αυτούς τους πέντε αριθμούς. Το Q2 είναι απλώς μια εναλλακτική ονομασία για τη διάμεσο, ενώ τα Q0 και Q4 αντιστοιχούν στο ελάχιστο και το μέγιστο, αντίστοιχα. Το Q1 μπορεί να γίνει αντιληπτό ως η διάμεσος του κάτω μισού της κατανομής, ενώ το Q3 ως η διάμεσος του άνω μισού της κατανομής.
Σχήμα 4.13
Η συνάρτηση favstats() παρέχει μια συνοπτική παρουσίαση των πέντε αριθμών (ελάχιστο, Q1, διάμεσος, Q3, μέγιστο), καθώς και του μέσου όρου, της τυπικής απόκλισης, του n (πλήθος παρατηρήσεων) και των ελλειπουσών τιμών. Στο συγκεκριμένο παράδειγμα, οι ελλείπουσες τιμές αντιστοιχούν στον αριθμό των φοιτητών για τους οποίους δεν υπάρχει τιμή βάρους. Στα επόμενα κεφάλαια θα αναφερθούμε εκτενέστερα στον μέσο όρο και την τυπική απόκλιση.¹
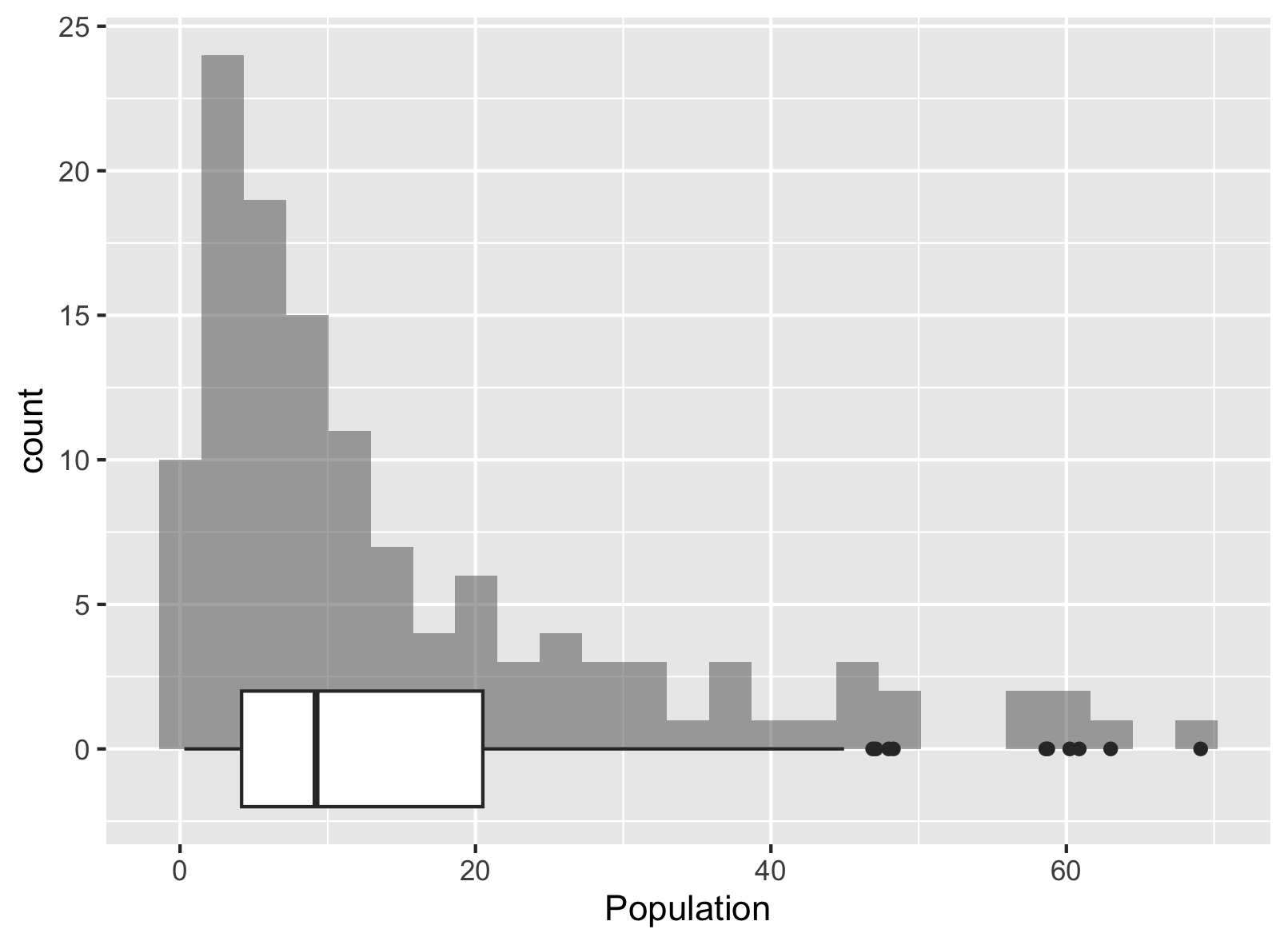
Στην ακόλουθη εικόνα, απεικονίζεται η σύνοψη των πέντε αριθμών για το βάρος (Weight) σε μια αριθμογραμμή. (Δεν απεικονίζονται και οι 157 τιμές, καθώς θα δημιουργούσαν υπερβολικά μεγάλο αριθμό κουκκίδων.)
Η σύνοψη των πέντε αριθμών καταδεικνύει ότι, στην συγκεκριμένη κατανομή, τα τρία πρώτα τεταρτημόρια έχουν παρόμοιο εύρος (περίπου 7-11 μονάδες), ενώ το τέταρτο (ανώτερο) τεταρτημόριο είναι σημαντικά ευρύτερο (περίπου 78 μονάδες). Αυτό υποδηλώνει ότι το ανώτερο 25% των δεδομένων εμφανίζει μεγάλη διασπορά στην κλίμακα μέτρησης του βάρους. Είναι σημαντικό να τονιστεί ότι από το παραπάνω διάγραμμα δεν είναι δυνατόν να γνωρίζουμε την κατανομή των δεδομένων εντός κάθε τεταρτημορίου, δηλαδή αν η κατανομή είναι ομοιόμορφη ή όχι μεταξύ των οριακών σημείων των τεταρτημορίων.
Εύρος και Ενδοτεταρτημοριακό Εύρος
Η διαφορά μεταξύ της μέγιστης και της ελάχιστης τιμής ορίζει το εύρος, ένα απλό μέτρο της διασποράς των τιμών σε μια κατανομή. Χρησιμοποιώντας τα αποτελέσματα της συνάρτησης favstats() που παρουσιάστηκαν παραπάνω, υπολογίστε το εύρος του βάρους (Weight) χρησιμοποιώντας την R ως αριθμομηχανή.
Το αποτέλεσμα θα πρέπει να είναι περίπου 106.
Σε κατανομές όπως ο πληθυσμός των χωρών (Population), το εύρος μπορεί να οδηγήσει σε παραπλανητικά συμπεράσματα.
Το εύρος φαίνεται να είναι περίπου 1.304,2 εκατομμύρια. Όπως είδαμε όμως στο ιστόγραμμα, αυτό οφείλεται στην ύπαρξη μιας ή δύο χωρών με πολύ μεγάλο πληθυσμό, δημιουργώντας σημαντικά κενά στην κατανομή. Σε τέτοιες περιπτώσεις, είναι χρήσιμο να υπολογίσουμε το εύρος μόνο για το μεσαίο 50% των τιμών. Αυτό ονομάζεται ενδοτεταρτημοριακό εύρος (Interquartile Range) και συμβολίζεται με IQR.
Μεταξύ ποιων δύο σημείων βλέπουμε το μεσαίο 0,50 των τιμών;
Επεξήγηση
Μεταξύ Q1 και Q3 είναι η σωστή απάντηση.
Κατανόηση των τεταρτημορίων:
Όταν τα δεδομένα χωρίζονται σε τεταρτημόρια, κάθε τμήμα περιέχει το 25% των παρατηρήσεων:
Κατανομή των δεδομένων: - Q0 έως Q1: Κάτω 25% (1ο τεταρτημόριο) - Q1 έως Q2: Επόμενο 25% (2ο τεταρτημόριο) - Q2 έως Q3: Επόμενο 25% (3ο τεταρτημόριο) - Q3 έως Q4: Πάνω 25% (4ο τεταρτημόριο)
Το μεσαίο 50%: Το μεσαίο 50% των τιμών περιλαμβάνει: - 2ο τεταρτημόριο (Q1 έως Q2): 25% - 3ο τεταρτημόριο (Q2 έως Q3): 25% - Συνολικά: Q1 έως Q3 = 50%
Α - Μεταξύ Q0 και Q2: Αυτό είναι το κάτω 50% των τιμών - Περιλαμβάνει το 1ο και 2ο τεταρτημόριο - Όχι το “μεσαίο” 50%
Γ - Μεταξύ Q2 και Q4: Αυτό είναι το πάνω 50% των τιμών - Περιλαμβάνει το 3ο και 4ο τεταρτημόριο - Όχι το “μεσαίο” 50%
Δ - Μεταξύ Q0 και Q4: Αυτό είναι το σύνολο των δεδομένων (100%) - Από το ελάχιστο έως το μέγιστο - Όχι μόνο το 50%
Πρακτική σημασία: Το διάστημα Q1 έως Q3 (το IQR) είναι σημαντικό επειδή: - Αντιπροσωπεύει τις «τυπικές» τιμές (αποκλείει ακραίες τιμές) - Είναι ανθεκτικό στις ακραίες τιμές - Χρησιμοποιείται για τον εντοπισμό ακραίων τιμών - Δείχνει τη διασπορά του “κεντρικού” τμήματος των δεδομένων
Ποιος είναι ο τύπος για την εύρεση του IQR;
Επεξήγηση
Q3 - Q1 είναι η σωστή απάντηση.
Ορισμός του IQR:
Το Ενδοτεταρτημοριακό Εύρος (Interquartile Range - IQR) είναι το εύρος που περιέχει το μεσαίο 50% των δεδομένων.
Τύπος: IQR = Q3 - Q1
Τι αντιπροσωπεύει: - Q1 (1ο τεταρτημόριο): Η τιμή κάτω από την οποία βρίσκεται το 25% των παρατηρήσεων με τις μικρότερες τιμές - Q3 (3ο τεταρτημόριο): Η τιμή πάνω από την οποία βρίσκεται το 25% των παρατηρήσεων με τις υψηλότερες τιμές - IQR: Η απόσταση μεταξύ Q1 και Q3, που περιέχει το μεσαίο 50% των παρατηρήσεων
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Q4 - Q0: Αυτός είναι ο τύπος για το συνολικό εύρος (Range) - Q0 = ελάχιστη τιμή (minimum) - Q4 = μέγιστη τιμή (maximum) - Range = Maximum - Minimum = Q4 - Q0
Β - Q1 + Q2 + Q3: Αυτό δεν είναι κάποιος γνωστός στατιστικός δείκτης - Η πρόσθεση των τεταρτημοριακών σημείων δεν έχει στατιστική σημασία
Δ - Q2 - Q0: Αυτό θα έδινε το εύρος από το ελάχιστο έως τη διάμεσο - Q2 = διάμεσος (median) - Αυτό περιλαμβάνει μόνο το κάτω 50% των δεδομένων
Πρακτικό παράδειγμα: Αν Q1 = 4.455 και Q3 = 31.225 (όπως στον πληθυσμό των χωρών): IQR = Q3 - Q1 = 31.225 - 4.455 = 26.77 εκατομμύρια
Χρησιμοποιήστε τη σύνοψη των πέντε αριθμών για τη μεταβλητή Population για να βρείτε το IQR. Μπορείτε να χρησιμοποιήσετε την R ως αριθμομηχανή.
Το αποτέλεσμα θα πρέπει να είναι ίσο με 26.77.
Το ενδοτεταρτημοριακό εύρος αποτελεί χρήσιμο μέτρο για να προσδιορίσουμε αν μια τιμή στα δεδομένα μας πρέπει να θεωρηθεί ακραία τιμή. Οι ακραίες τιμές θέτουν τους ερευνητές ενώπιον μιας δύσκολης απόφασης: πρέπει να εξαιρεθεί η τιμή από την ανάλυση, λόγω της μεγάλης επιρροής που θα έχει στο συμπέρασμα, ή πρέπει να συμπεριληφθεί, δεδομένου ότι αποτελεί μια πραγματική τιμή;
Για παράδειγμα, η Κίνα είναι μια χώρα με πολύ μεγάλο πληθυσμό και αποτελεί ακραία τιμή στο σύνολο δεδομένων Happy, με πληθυσμό άνω των 1.300 εκατομμυρίων ατόμων (ή 1,3 δισεκατομμύρια). Εάν δεν υπήρχε, η εικόνα που θα είχαμε για την κατανομή του πληθυσμού σε όλες τις χώρες θα ήταν πολύ διαφορετική. Θα έπρεπε να την εξαιρέσουμε ως ακραία τιμή;
Η απάντηση εξαρτάται από τους στόχους της ανάλυσης. Αν επιδιώκουμε να κατανοήσουμε τον συνολικό πληθυσμό του πλανήτη, θα ήταν αδιανόητο να εξαιρέσουμε την Κίνα, δεδομένου του μεγάλου αριθμού ανθρώπων που ζουν εκεί. Αν όμως επιδιώκουμε να αποκτήσουμε μια αίσθηση του πόσοι άνθρωποι ζουν σε μια τυπική χώρα, ίσως θα ήταν πιο λογικό να εξαιρέσουμε την Κίνα.
Σε αυτή την περίπτωση, τι γίνεται με τη δεύτερη πιο πολυπληθή χώρα, την Ινδία; Θα έπρεπε να εξαιρεθεί και αυτή; Τι γίνεται με την τρίτη πιο πολυπληθή χώρα, τις ΗΠΑ, ή την τέταρτη, την Ινδονησία; Πώς αποφασίζουμε ποια τιμή είναι προβληματική ακραία τιμή; Η διαδικασία αυτή φαίνεται να εμπεριέχει υποκειμενικότητα.
Δεν υπάρχει μια μοναδική σωστή προσέγγιση. Ο προσδιορισμός του τι συνιστά «ακραία τιμή» εξαρτάται ουσιαστικά από τους στόχους της ανάλυσης των δεδομένων. Ωστόσο, η κοινότητα των στατιστικολόγων έχει καταλήξει σε έναν κοινά αποδεκτό κανόνα για να βοηθήσει στον εντοπισμό πιθανών ακραίων τιμών. Οποιαδήποτε παρατήρηση είναι μεγαλύτερη από Q3 + 1.5 × IQR θεωρείται υψηλή ακραία τιμή, ενώ οποιαδήποτε παρατήρηση είναι μικρότερη από Q1 - 1.5 × IQR θεωρείται χαμηλή ακραία τιμή.
Δεδομένου ότι το IQR της μεταβλητής Population είναι περίπου 27 εκατομμύρια και το Q3 είναι περίπου 31 εκατομμύρια, ποιες από τις παρακάτω χώρες θα μπορούσαν να θεωρηθούν υψηλές ακραίες τιμές; (Αυτό δεν χρειάζεται πολύ ακριβείς υπολογισμούς.) Σημειώστε όλα όσα ισχύουν.
Επεξήγηση
Κίνα, 1304.50 εκατομμύρια και Ινδία, 1094.58 εκατομμύρια είναι οι σωστές απαντήσεις.
Υπολογισμός του ορίου για μεγάλες ακραίες τιμές:
Σύμφωνα με τον κανόνα των ακραίων τιμών, μια παρατήρηση θεωρείται μεγάλη ακραία τιμή αν:
Τιμή > Q3 + 1.5 × IQR
Δεδομένα: - Q3 = 31 εκατομμύρια - IQR = 27 εκατομμύρια
✓ Κίνα: 1304.50 εκατομμύρια 1304.50 > 71.5 → ΝΑΙ, ακραία τιμή
✓ Ινδία: 1094.58 εκατομμύρια 1094.58 > 71.5 → ΝΑΙ, ακραία τιμή
✗ ΗΠΑ: 296.51 εκατομμύρια 296.51 > 71.5 → ΝΑΙ, ακραία τιμή (αλλά λιγότερο ακραία)
✗ Ινδονησία: 220.56 εκατομμύρια 220.56 > 71.5 → ΝΑΙ, ακραία τιμή (αλλά λιγότερο ακραία)
Διόρθωση: Στην πραγματικότητα, όλες οι τέσσερις χώρες είναι ακραίες τιμές επειδή όλες υπερβαίνουν το όριο των 71.5 εκατομμυρίων. Ωστόσο, η Κίνα και η Ινδία είναι πολύ πιο ακραίες τιμές:
Σύγκριση των ακραίων τιμών: - Κίνα: 1304.50 ÷ 71.5 = 18.3 φορές πάνω από το όριο - Ινδία: 1094.58 ÷ 71.5 = 15.3 φορές πάνω από το όριο - ΗΠΑ: 296.51 ÷ 71.5 = 4.1 φορές πάνω από το όριο - Ινδονησία: 220.56 ÷ 71.5 = 3.1 φορές πάνω από το όριο
Πρακτική σημασία: Η Κίνα και η Ινδία είναι οι δύο “υπερδυνάμεις” του πληθυσμού που διαστρεβλώνουν σημαντικά την κατανομή του παγκόσμιου πληθυσμού, γι’ αυτό συχνά αναφέρονται ως οι κύριες ακραίες τιμές σε αυτό το πλαίσιο δεδομένων.
¹Υπάρχουν διάφοροι τρόποι υπολογισμού του Q1 και του Q3. Για τον λόγο αυτό, το Q1 που προκύπτει από τον χειροκίνητο υπολογισμό της διαμέσου του κάτω μισού των τιμών μπορεί να μην αντιστοιχεί στο Q1 που υπολογίζει η R. Η R προσφέρει εννέα διαφορετικές επιλογές για τον υπολογισμό του Q1 και του Q3. Η συνάρτηση favstats() χρησιμοποιεί την ευρύτερα διαδεδομένη μέθοδο (η R αναφέρεται σε αυτή τη μέθοδο ως type=7) και αυτή θα χρησιμοποιείται κατά κύριο λόγο.
4.7 Boxplot και η Σύνοψη των Πέντε Αριθμών
Η σύνοψη των πέντε αριθμών παρέχει μια συνοπτική εικόνα της κατανομής μιας ποσοτικής μεταβλητής. Τα boxplot (επίσης γνωστά ως θηκογράμματα ή διαγράμματα κουτιού) αποτελούν έναν τρόπο οπτικοποίησης της σύνοψης των πέντε αριθμών. Για παράδειγμα, το boxplot που ακολουθεί απεικονίζει την κατανομή μιας υποθετικής μεταβλητής (π.χ., του ύψους ενός δείγματος ανθρώπων σε εκατοστά).
Σχήμα 4.14
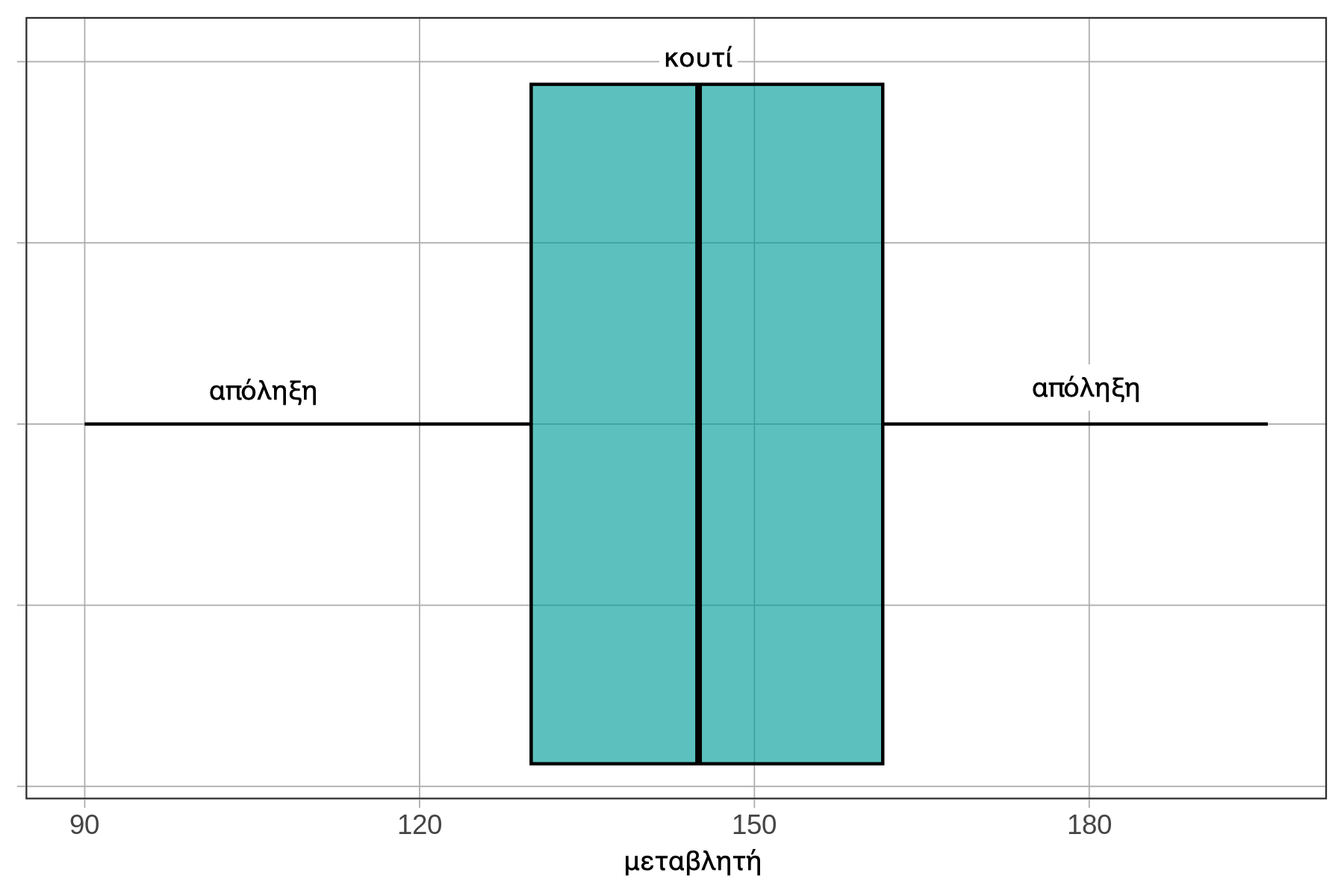
Ένα boxplot αποτελείται από τα ακόλουθα μέρη: Ένα ορθογώνιο κουτί στο κέντρο (στην περίπτωση αυτή χρώματος τιρκουάζ), το οποίο χωρίζεται (με μια κάθετη γραμμή) σε δύο μέρη, ένα αριστερό και ένα δεξί. Επιπλέον, υπάρχουν οριζόντιες γραμμές, οι οποίες ονομάζονται απολήξεις ή «μουστάκια», που εκτείνονται σε κάθε πλευρά του κουτιού.
Το παραπάνω boxplot έχει οριζόντιο προσανατολισμό. (Στη συνέχεια θα δούμε και boxplot με κάθετο προσανατολισμό.) Ο άξονας x δείχνει την κλίμακα μέτρησης της μεταβλητής, η οποία εκτείνεται περίπου από 90 έως 200 εκατοστά. Ο άξονας y δεν έχει σημασία σε αυτό το διάγραμμα, και για τον λόγο αυτό έχει αφαιρεθεί.
Στο ίδιο boxplot παρακάτω, έχουν επισημανθεί οι θέσεις της ελάχιστης τιμής (min), του πρώτου τεταρτημορίου (Q1), της διαμέσου, του τρίτου τεταρτημορίου (Q3) και της μέγιστης (max) τιμής. Κατ’ αυτόν τον τρόπο, είναι δυνατή η ανάγνωση της σύνοψης των πέντε αριθμών από το boxplot.
Σχήμα 4.15
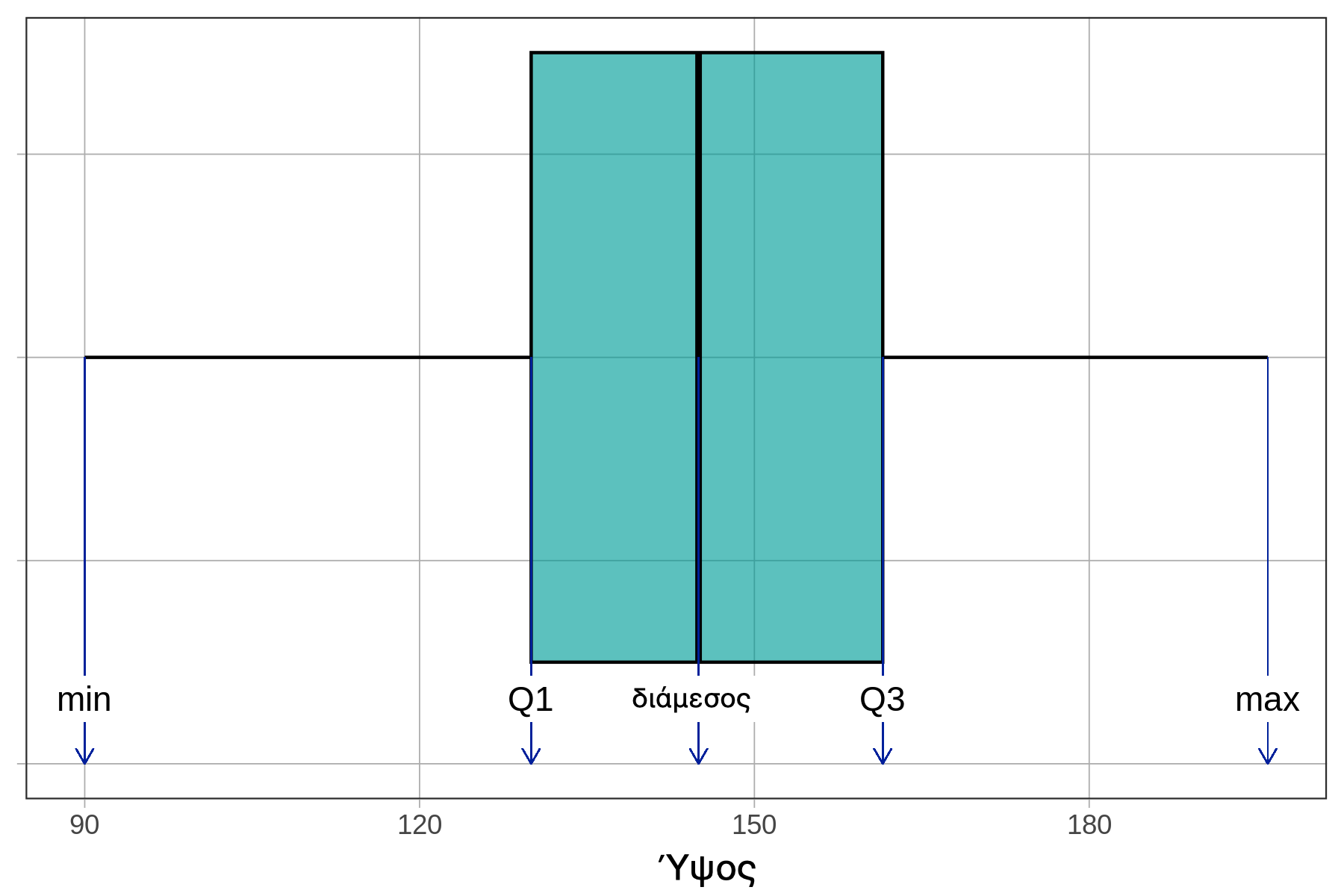
Εκτιμήστε τις τιμές της σύνοψης των πέντε αριθμών από το παραπάνω boxplot.
Min, το αριστερό άκρο της αριστερής απόληξης:
Q1, το αριστερό άκρο του κουτιού:
Διάμεσος, η γραμμή που χωρίζει το κουτί σε δύο μέρη:
Q3, το δεξί άκρο του κουτιού:
Max, το δεξί άκρο της δεξιάς απόληξης:
IQR, το οριζόντιο εύρος του κουτιού:
Επεξήγηση
Ανάγνωση ενός Boxplot:
Ένα boxplot (διάγραμμα κουτιού) παρουσιάζει οπτικά τη σύνοψη των πέντε αριθμών:
Στοιχεία του Boxplot: - Αριστερή απόληξη: Εκτείνεται από το ελάχιστο έως το Q1 - Κουτί: Εκτείνεται από Q1 έως Q3 (περιέχει το μεσαίο 50% των παρατηρήσεων) - Γραμμή εντός του κουτιού: Δείχνει τη διάμεσο (Q2) - Δεξιά απόληξη: Εκτείνεται από Q3 έως το μέγιστο
Σύνοψη των Πέντε Αριθμών: - Minimum (Ελάχιστο): ~90 - το αριστερό άκρο της αριστερής απόληξης - Q1 (1ο τεταρτημόριο): ~130 - η αριστερή άκρη του κουτιού - Median (Διάμεσος): ~145 - η γραμμή μέσα στο κουτί - Q3 (3ο τεταρτημόριο): ~160 - το δεξί άκρο του κουτιού - Maximum (Μέγιστο): ~195 - το δεξί άκρο της δεξιάς απόληξης
Υπολογισμός IQR: IQR = Q3 - Q1 = 160 - 130 = 30
Το IQR αντιπροσωπεύει το εύρος του μεσαίου 50% των παρατηρήσεων και αντιστοιχεί στο οριζόντιο πλάτος του κουτιού στο boxplot.
Πρακτική σημασία: - Το κουτί δείχνει πού συγκεντρώνεται το μεσαίο 50% των δεδομένων - Οι απολήξεις δείχνουν τη διασπορά των δεδομένων προς τα άκρα - Η θέση της διαμέσου μέσα στο κουτί δείχνει αν υπάρχει ασυμμετρία στην κατανομή
Θα περιέχουν πάντα τα δύο μέρη του κουτιού σε ένα boxplot περίπου τον ίδιο αριθμό παρατηρήσεων; Γιατί ναι ή γιατί όχι;
Επεξήγηση
Ναι, επειδή κάθε μισό του κουτιού αντιπροσωπεύει ακριβώς το 25% των παρατηρήσεων (2ο και 3ο τεταρτημόριο αντίστοιχα), οπότε περιέχουν τον ίδιο αριθμό παρατηρήσεων είναι η σωστή απάντηση.
Θεμελιώδης αρχή των boxplot:
Τα όρια του κουτιού στο boxplot κατασκευάζονται με βάση τον αριθμό των παρατηρήσεων, όχι με βάση το εύρος των τιμών ή το εμβαδόν.
Δομή του κουτιού: - Αριστερό μισό: Από το 1ο τεταρτημόριο (Q1) έως τη διάμεσο (Q2) → 2ο τεταρτημόριο = 25% των παρατηρήσεων. - Δεξιό μισό: Από τη διάμεσο (Q2) έως το 3ο τεταρτημόριο (Q3) → 3ο τεταρτημόριο = 25% των παρατηρήσεων.
Γιατί ο αριθμός των παρατηρήσεων είναι ίδιος: Επειδή κάθε μισό του κουτιού περιέχει ακριβώς το 25% των παρατηρήσεων, ο αριθμός των παρατηρήσεων είναι πάντα ίδιος, ανεξάρτητα από: - Τη θέση της διαμέσου μέσα στο κουτί. - Το εύρος των τιμών σε κάθε τεταρτημόριο. - Το σχήμα της κατανομής (συμμετρική ή ασύμμετρη).
Σημείωση για το εύρος και το εμβαδόν: Το εύρος κάθε μισού (η απόσταση από Q1 έως Q2 ή Q2 έως Q3) μπορεί να διαφέρει, καθώς εξαρτάται από το εύρος των τιμών σε κάθε τεταρτημόριο, ιδιαίτερα σε ασύμμετρες κατανομές. Άρα το εμβαδόν κάθε μισού εξαρτάται από το εύρος του. Ωστόσο, η ερώτηση αφορά τον αριθμό των παρατηρήσεων, όχι το εμβαδόν.
Γιατί οι άλλες επιλογές είναι λάθος:
Α: Ελλιπής - ενώ το κουτί αντιπροσωπεύει το μεσαίο 50%, η εξήγηση δεν διευκρινίζει ότι κάθε μισό περιέχει ακριβώς το 25% των παρατηρήσεων.
Β: Λάθος - η θέση της διαμέσου ή η διασπορά των τιμών δεν επηρεάζει τον αριθμό των παρατηρήσεων σε κάθε μισό, που είναι πάντα 25% του συνόλου.
Δ: Λάθος - το εύρος (ή το εμβαδόν) δεν σχετίζεται με τον αριθμό των παρατηρήσεων. Το εύρος ανάμεσα στα Q1, Q2, Q3 μπορεί να διαφέρει, αλλά ο αριθμός των παρατηρήσεων παραμένει ο ίδιος.
Βασικό δίδαγμα: Σε ένα boxplot, κάθε μισό του κουτιού περιέχει ίδιο αριθμό παρατηρήσεων (25%), αν και το εύρος ή το εμβαδόν μπορεί να διαφέρει ανάλογα με την κατανομή των τιμών.
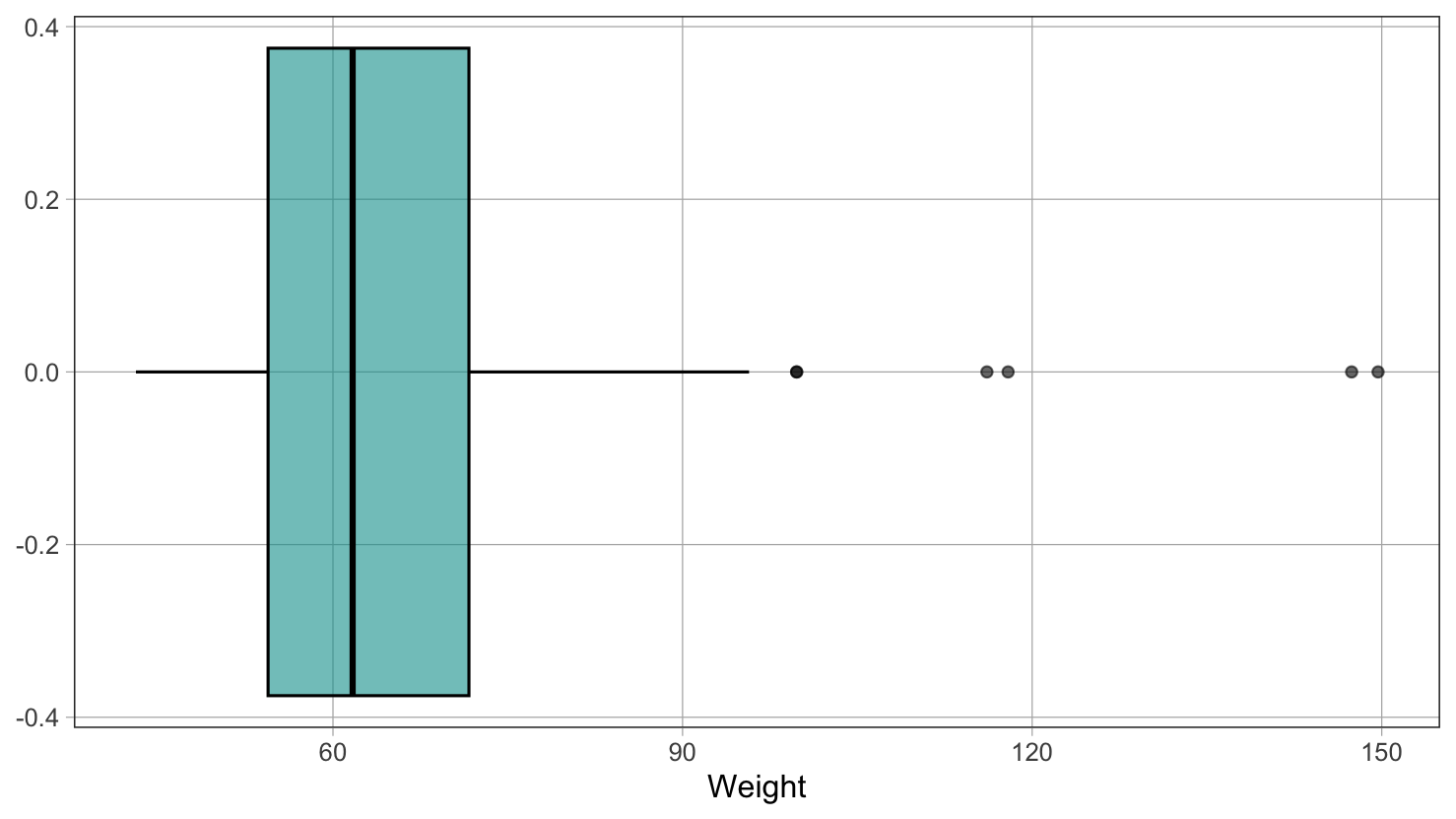
Στην παραπάνω υποθετική κατανομή του ύψους δεν υπάρχουν ακραίες τιμές (οι οποίες ορίζονται ως τιμές που απέχουν περισσότερο από 1,5 φορά το ενδοτεταρτημοριακό εύρος (IQR) πάνω από το Q3 ή κάτω από το Q1). Οι απολήξεις καταλήγουν απλώς στη μέγιστη και την ελάχιστη τιμή της μεταβλητής, αντίστοιχα. Όταν, όμως, υπάρχουν ακραίες τιμές, αυτές αναπαρίστανται ως κουκκίδες αριστερά ή δεξιά των απολήξεων. Στην περίπτωση αυτή, οι απολήξεις καταλήγουν στις θέσεις Q1 - 1.5 × IQR και Q3 + 1.5 × IQR. Ακολουθεί ένα παράδειγμα μεταβλητής με ακραίες τιμές.
Εμφανίζονται ξανά τα στατιστικά της συνάρτησης favstats() για τη μεταβλητή Weight (βάρος φοιτητή) από το πλαίσιο δεδομένων Fingers. Το αντίστοιχο boxplot παρουσιάζεται παρακάτω (στη συνέχεια θα παρουσιαστεί ο τρόπος δημιουργίας του με την R).
Σχήμα 4.16
Παρατηρήστε τις κουκκίδες που βρίσκονται μετά το δεξί άκρο της δεξιάς απόληξης. Αυτές οι τιμές είναι μεγαλύτερες από Q3 + 1.5 × IQR = 71.67 + 1.5 × (71.67 - 54.43) = 71.67 + 1.5 × 17.24 = 71.67 + 25.86 = 97.53. Παρατηρήστε ότι η δεξιά απόληξη καταλήγει στην τιμή 97.53, δηλαδή στην τιμή που βρίσκεται στη θέση Q3 + 1.5 × IQR. Οποιαδήποτε τιμή μεγαλύτερη από αυτήν, θεωρείται ακραία τιμή.
Δημιουργία του Δικού σας Boxplot
Ο κώδικας που ακολουθεί παρουσιάζει τον τρόπο δημιουργίας του παραπάνω boxplot. Εκτελέστε τον κώδικα για να επιβεβαιώσετε τη λειτουργία του. Σημειώστε ότι η προσθήκη του ~ πριν από το Weight έχει ως αποτέλεσμα το boxplot να έχει οριζόντιο προσανατολισμό, με τη μεταβλητή Weight στον άξονα x.
Τροποποιήστε τώρα τον κώδικα για να δημιουργήσετε ένα διάγραμμα κουτιού για τη μεταβλητή Happiness (σκορ Ευτυχίας των πολιτών από διαφορετικές χώρες) που βρίσκεται στο πλαίσιο δεδομένων Happy.
Παρατηρήστε ότι η σύνταξη της συνάρτησης gf_boxplot() είναι ακριβώς η ίδια με αυτή της gf_histogram(). Δοκιμάστε να αλλάξετε τον παραπάνω κώδικα για να δημιουργήσετε ένα ιστόγραμμα αντί για boxplot. Συγκρίνετε το boxplot με το ιστόγραμμα. Μπορείτε να διακρίνετε πώς η ίδια κατανομή αναπαρίσταται από αυτούς τους δύο τύπους γραφημάτων;
Προβολή Boxplot σε Ιστόγραμμα
Η σύγκριση boxplot και ιστογράμματος μιας μεταβλητής είναι ευκολότερη όταν το ένα προβάλλεται πάνω στο άλλο. Μπορείτε να προβάλλετε ένα boxplot σε ένα ιστόγραμμα της ίδιας μεταβλητής χρησιμοποιώντας τον τελεστή %>%. Σημειώστε ότι δεν χρειάζεται να συμπεριλάβετε καμία παράμετρο σε παρενθέσεις για τη συνάρτηση gf_boxplot(), καθώς οι τιμές των παραμέτρων της συνάρτησης gf_histogram() μεταφέρονται στην επόμενη συνάρτηση.
Είναι κάπως δύσκολο να διακρίνουμε το προκαθορισμένο boxplot πάνω στο ιστόγραμμα. Για καλύτερο αποτέλεσμα, μπορούν να προστεθούν παράμετροι όπως οι fill και width για την αλλαγή των χαρακτηριστικών του διαγράμματος.
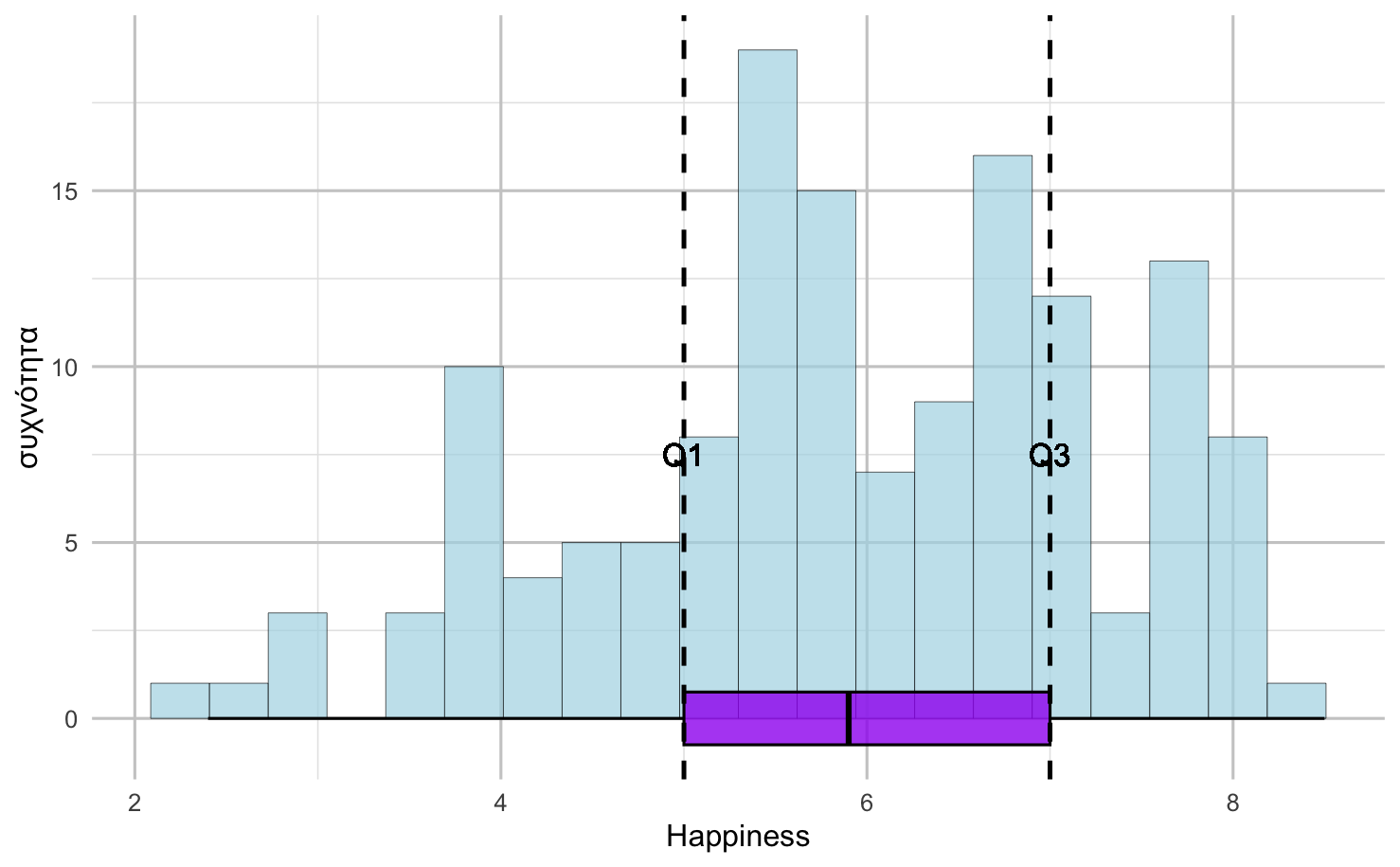
Παρατηρήστε το ιστόγραμμα με το boxplot που εμφανίζονται παρακάτω. Αυτή τη φορά, έχουν προστεθεί διακεκομμένες γραμμές στα Q1 και Q3 (τις απολήξεις του κουτιού).
Σχήμα 4.17
Αν το παραπάνω ιστόγραμμα αντιπροσωπεύει το 100% της κατανομής της μεταβλητής Happiness, τι ποσοστό της κατανομής βρίσκεται μεταξύ των διακεκομμένων γραμμών;
Επεξήγηση
Το 50% της κατανομής είναι η σωστή απάντηση.
Κατανόηση των τεταρτημορίων:
Οι διακεκομμένες γραμμές στο διάγραμμα αντιπροσωπεύουν το Q1 και το Q3 (1ο και 3ο τεταρτημόριο).
Ορισμός των τεταρτημορίων: - Q1: Η τιμή κάτω από την οποία βρίσκεται το 25% των παρατηρήσεων - Q3: Η τιμή κάτω από την οποία βρίσκεται το 75% των παρατηρήσεων
Το διάστημα μεταξύ Q1 και Q3: - Περιέχει όλες τις παρατηρήσεις από το 25ο έως το 75ο εκατοστημόριο - 75% - 25% = το 50% των παρατητήσεων - Αυτό είναι το Ενδοτεταρτημοριακό Εύρος (IQR)
Οπτική επαλήθευση: Στο boxplot (το μωβ κουτί κάτω από το ιστόγραμμα): - Το κουτί εκτείνεται από Q1 έως Q3 - Το κουτί πάντα περιέχει το μεσαίο 50% των παρατηρήσεων - Οι διακεκομμένες γραμμές δείχνουν ακριβώς τα όρια αυτού του κουτιού
Γιατί οι άλλες επιλογές είναι λάθος:
Α - 25%: Αυτό θα ήταν μόνο ένα τεταρτημόριο (π.χ. από Q1 έως τη διάμεσο)
Γ - 75%: Αυτό θα ήταν από το ελάχιστο έως Q3, όχι μεταξύ Q1 και Q3
Δ - Αδύνατον να προσδιοριστεί: Λάθος! Τα τεταρτημόρια ορίζονται με βάση ποσοστά, όχι απόλυτους αριθμούς. Ανεξάρτητα από το μέγεθος του δείγματος, το διάστημα Q1-Q3 πάντα περιέχει το 50% των παρατηρήσεων.
Βασική αρχή: Τα τεταρτημόρια είναι θέσεις εκατοστημορίων που διαιρούν τα δεδομένα σε τέσσερα ίσα μέρη του 25% το καθένα. Το μεσαίο 50% βρίσκεται πάντα μεταξύ Q1 και Q3.
Υπάρχουν πολλοί τρόποι για να προσαρμόσετε τη θέση και την εμφάνιση του boxplot πάνω στο ιστόγραμμα. Εκτελέστε τον κώδικα που ακολουθεί και, στη συνέχεια, δοκιμάστε να αλλάξετε μερικές από τις τιμές των παραμέτρων. Εξετάστε τι συμβαίνει αν αλλάξετε την παράμετρο width από 1 σε διαφορετικό αριθμό. Προβλέψτε τι θα συμβεί αν αλλάξετε τον αριθμό πριν από το ~ Happiness στην gf_boxplot(). Στον παρακάτω κώδικα έχει τεθεί ίσος με 6. Τι νομίζετε ότι θα συμβεί αν τον θέσετε ίσο με έναν αρνητικό αριθμό;
Η Συνάρτηση ntile()
Έχοντας πλέον εξοικειωθεί με τα τεταρτημόρια και τη σύνοψη των πέντε αριθμών, υπάρχει μια ακόμη συνάρτηση της R που είναι συχνά χρήσιμη: η ntile(). Αυτή η συνάρτηση ταξινομεί τις τιμές μιας ποσοτικής μεταβλητής και στη συνέχεια τις χωρίζει σε έναν αριθμό ομάδων (\(n\)) ίσου μεγέθους. Για παράδειγμα, αν επιθυμούμε τη δημιουργία τεσσάρων ομάδων ίσου μεγέθους, το \(n\) είναι ίσο με 4. Όταν το \(n\) είναι 4, οι ομάδες μας είναι τα τεταρτημόρια!
Ακολουθεί ένα παράδειγμα χρήσης αυτής της συνάρτησης:
Ο κώδικας ntile(Happy$Happiness, 4) ταξινομεί τις τιμές της μεταβλητής Happiness, τις κατανέμει σε τέσσερις ομάδες ίσου μεγέθους (τεταρτημόρια) και επιστρέφει έναν αριθμό από 1 έως 4, ο οποίος υποδεικνύει σε ποιο τεταρτημόριο ανήκει κάθε τιμή (π.χ., 1, 4, 3, 2, 4, 4, κλπ.). Ο τελεστής ανάθεσης (<-) χρησιμοποιείται για την αποθήκευση αυτών των αριθμών σε μια νέα μεταβλητή με όνομα HappyQuartile στο πλαίσιο δεδομένων Happy.
Ακολουθεί ένα τυχαίο δείγμα 10 παρατηρήσεων από το πλαίσιο δεδομένων, για τις μεταβλητές Country, HappyQuartile και Happiness.
Country
HappyQuartile
Happiness
Albania
2
5.5
Algeria
2
5.6
Angola
1
4.3
Argentina
4
7.1
Armenia
1
5.0
Australia
4
7.9
Austria
4
7.8
Azerbaijan
2
5.3
Bangladesh
2
5.3
Belarus
2
5.8
Παρατηρούμε ότι η Αρμενία έχει καταταχθεί στην ομάδα 1, καθώς η τιμή της βρίσκεται στο πρώτο τεταρτημόριο του δείκτη ευτυχίας. Οι δύο υψηλότερες τιμές (7.9 και 7.8 για την Αυστραλία και την Αυστρία, αντίστοιχα) έχουν καταταχθεί στην ομάδα 4.
Στη συνέχεια, χρησιμοποιούμε τη νέα μεταβλητή για να χρωματίσουμε τις στήλες του ιστογράμματος της Happiness ανάλογα με το τεταρτημόριο στο οποίο ανήκουν. Πριν χρησιμοποιήσουμε τις τιμές των ομάδων που προέκυψαν από την ntile() ως είσοδο στην παράμετρο fill =, απαιτείται η μετατροπή της νέας μεταβλητής σε μεταβλητή τύπου factor. Αυτό γίνεται ως εξής:
Εξετάστε και εκτελέστε τον παρακάτω κώδικα για να δείτε πώς χρωματίζονται οι στήλες του ιστογράμματος με βάση τις τιμές που ανήκουν στα τέσσερα τεταρτημόρια.
Ποιες από τις παρακάτω γραμμές κώδικα είναι σωστή για την ομαδοποίηση της μεταβλητής Height από το πλαίσιο δεδομένων Fingers με βάση τα τεταρτημόρια;
Βήμα 1: Fingers$HeightQuartile <- ntile(Fingers$Height, 4) - Χρησιμοποιεί τη συνάρτηση ntile() στη μεταβλητή Height - Χωρίζει τις τιμές του ύψους σε 4 ομάδες ίσου μεγέθους (τεταρτημόρια) - Αποθηκεύει τους αριθμούς 1-4 στη νέα μεταβλητή HeightQuartile
Βήμα 2: Fingers$HeightQuartile <- factor(Fingers$HeightQuartile) - Μετατρέπει τη μεταβλητή HeightQuartile από αριθμητική σε factor - Αυτό είναι απαραίτητο για να χρησιμοποιηθεί στην παράμετρο fill = του ιστογράμματος
Η πρώτη γραμμή προσπαθεί να χρησιμοποιήσει την HeightQuartile πριν δημιουργηθεί
Η δεύτερη γραμμή μετατρέπει την αρχική μεταβλητή Height σε factor, όχι τα τεταρτημόρια
Βασική αρχή: Πρώτα δημιουργούμε τα τεταρτημόρια με ntile(), μετά τα μετατρέπουμε σε factor για γραφική αναπαράσταση.
Συμπληρώστε τον παρακάτω κώδικα για να δημιουργήσετε το τελικό διάγραμμα:
Ακραίες Τιμές στο Boxplot
Συμπληρώστε τον παρακάτω κώδικα για να δημιουργήσετε το boxplot για τη μεταβλητή Population (πληθυσμός χωρών) από το πλαίσιο δεδομένων Happy.
Το παραπάνω είναι ένα παράξενο boxplot. Δύσκολα διακρίνεται το κουτί — είναι συμπιεσμένο στην αριστερή πλευρά. Υπάρχουν όλες αυτές οι κουκκίδες δεξιά από την απόληξη.
Οι κουκκίδες (σημεία) που εμφανίζονται πιο μακριά από μια απόληξη στο boxplot αποτελούν ακραίες τιμές. Εάν εμφανίζονται δεξιά από τη δεξιά απόληξη, σημαίνει ότι η R έχει ελέγξει και διαπίστωσε ότι αυτές οι τιμές είναι μεγαλύτερες από Q3 + 1.5 × IQR. Εάν εμφανίζονται αριστερά από την αριστερή απόληξη, σημαίνει ότι η R διαπίστωσε ότι αυτές οι τιμές είναι μικρότερες από Q1 - 1.5 × IQR. Όταν υπάρχουν ακραίες τιμές, η αντίστοιχη απόληξη καταλήγει στη μέγιστη ή την ελάχιστη τιμή που δεν θεωρείται ακραία.
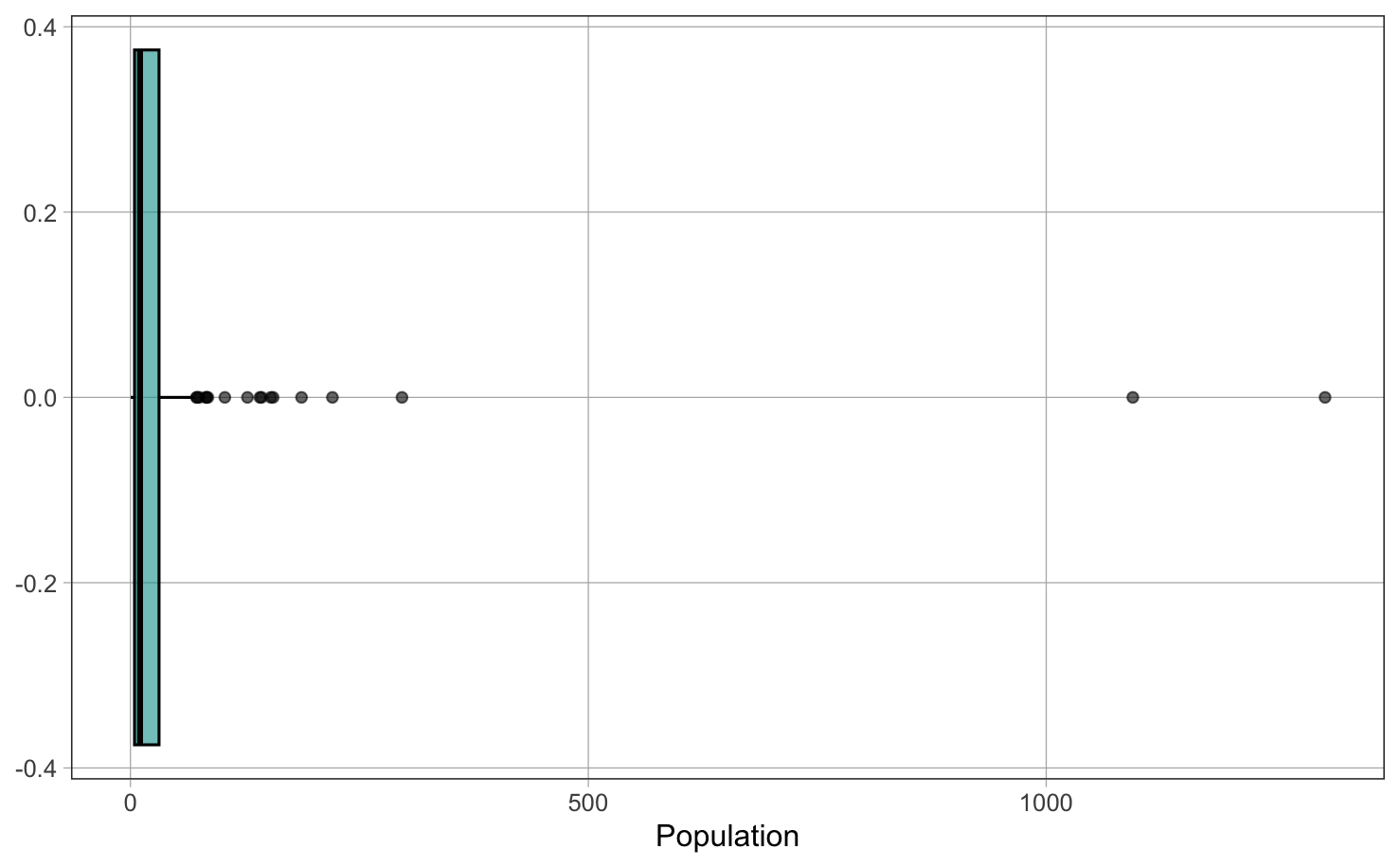
Στο παραπάνω boxplot της μεταβλητής Population, παρατηρείτε ακραίες τιμές που είναι πολύ μικρές ή πολύ μεγάλες;
Επεξήγηση
Πολύ μεγάλες είναι η σωστή απάντηση.
Ανάλυση του boxplot:
Στην κατανομή του πληθυσμού των χωρών, οι ακραίες τιμές εμφανίζονται κυρίως στο δεξί άκρο του boxplot, που σημαίνει ότι είναι πολύ μεγάλες τιμές.
Γιατί συμβαίνει αυτό:
Φυσικά όρια πληθυσμού: - Ο πληθυσμός μιας χώρας δεν μπορεί να είναι αρνητικός - Υπάρχει ένα φυσικό κάτω όριο κοντά στο μηδέν - Δεν υπάρχει ανώτατο όριο - μερικές χώρες μπορούν να έχουν εξαιρετικά μεγάλο πληθυσμό
Κατανομή παγκόσμιου πληθυσμού: - Οι περισσότερες χώρες έχουν σχετικά μικρό πληθυσμό (λιγότερο από 50 εκατομμύρια) - Λίγες χώρες έχουν πολύ μεγάλο πληθυσμό: - Κίνα: ~1.3 δισεκατομμύρια - Ινδία: ~1.1 δισεκατομμύρια - ΗΠΑ: ~300 εκατομμύρια - Ινδονησία: ~220 εκατομμύρια
Τι δείχνει το boxplot: - Κουτί: Περιέχει το μεσαίο 50% των χωρών (πιθανώς 2-30 εκατομμύρια κάτοικοι) - Αριστερή απόληξη: Εκτείνεται προς τις μικρότερες χώρες αλλά δεν μπορεί να πάει κάτω από το 0 - Δεξιά απόληξη: Εκτείνεται προς τις μεγαλύτερες χώρες - Ακραίες τιμές δεξιά: Οι “υπερδυνάμεις” του πληθυσμού που ξεπερνούν κατά πολύ τη “τυπική” χώρα
Είδος κατανομής: Αυτό είναι ένα κλασικό παράδειγμα κατανομής με ασυμμετρία στα δεξιά: - Κύριος όγκος δεδομένων στις χαμηλές τιμές - Μακριά “ουρά” προς τις υψηλές τιμές - Ακραίες τιμές στο δεξί άκρο (μεγάλες τιμές) - Καθόλου ακραίες τιμές στο αριστερό άκρο (μικρές τιμές)
Πρακτικά παραδείγματα άλλων παρόμοιων κατανομών: - Εισόδημα πολιτών μιας χώρας (λίγα άτομα με πολύ υψηλό εισόδημα) - Μέγεθος επιχειρήσεων ενός κλάδου (λίγες πολύ μεγάλες επιχειρήσεις, π.χ. πολυεθνικές)
Υπάρχουν πολλές χώρες με μεγάλες ακραίες τιμές πληθυσμού. Δεν αποτελεί έκπληξη το γεγονός ότι το ιστόγραμμα του πληθυσμού (βλ. παρακάτω) κατέταξε τόσες πολλές χώρες στο ίδιο διάστημα τιμών! Εξαιτίας της ανάγκης τοποθέτησης των χωρών με ακραίες τιμές στο ίδιο διάστημα, οι υπόλοιπες χώρες συμπιέζονται στο κατώτερο άκρο της κλίμακας του πληθυσμού. Αυτό δημιουργεί την εντύπωση ότι οι περισσότερες χώρες έχουν πληθυσμό 0 εκατομμυρίων κατοίκων (κάτι που φυσικά δεν ισχύει).
Αφαίρεση των Ακραίων Τιμών για Σαφέστερη Απεικόνιση της Υπόλοιπης Κατανομής
Σε μια κατανομή όπως αυτή, ενδέχεται να επιθυμούμε να αποκλείσουμε τις ακραίες τιμές από το ιστόγραμμα προκειμένου να αποκτήσουμε σαφέστερη εικόνα της κατανομής του πληθυσμού των περισσότερων χωρών, χωρίς να είναι συμπιεσμένοι στο διάγραμμα εξαιτίας των μεγαλύτερων χωρών. Για να επιτευχθεί αυτό, πρέπει πρώτα να εντοπίσουμε το σημείο στην κλίμακα πληθυσμού άνω του οποίου θα θεωρούσαμε μια χώρα ως ακραία τιμή.
Αν θέλαμε να υπολογίσουμε το ανώτερο όριο για τις ακραίες τιμές (δηλ., την τιμή πέραν της οποίας ένα σημείο θεωρείται ακραία τιμή), ποιοι αριθμοί πρέπει να αντικατασταθούν εδώ:
upper_boundary <- [ ] + 1.5 * ([ ] - [ ])
Επεξήγηση
Q3 (31.225) + 1.5 * (Q3 (31.225) - Q1 (4.455)) είναι η σωστή απάντηση.
Τύπος για το ανώτερο όριο ακραίων τιμών:
upper_boundary <- Q3 + 1.5 * (Q3 - Q1)
ή ισοδύναμα:
upper_boundary <- Q3 + 1.5 * IQR
Αντικατάσταση των τιμών: - Πρώτο κενό: Q3 = 31.225 - Δεύτερο κενό: Q3 = 31.225
- Τρίτο κενό: Q1 = 4.455
Παραδείγματα ακραίων τιμών σε αυτό το σύνολο: Χώρες με πληθυσμό > 71.38 εκατομμύρια: - Κίνα (1304.5 εκατ.) ✓ Ακραία τιμή - Ινδία (~1095 εκατ.) ✓ Ακραία τιμή
- ΗΠΑ (296.5 εκατ.) ✓ Ακραία τιμή - Ινδονησία (220.6 εκατ.) ✓ Ακραία τιμή
Στο ακόλουθο παράθυρο κώδικα, χρησιμοποιήστε τη συνάρτηση filter() για να αποθηκεύσετε μια νέα εκδοχή του πλαισίου δεδομένων που περιλαμβάνει μόνο χώρες από το πλαίσιο δεδομένων Happy με πληθυσμούς μικρότερους από αυτό το ανώτερο όριο. Ονομάστε αυτή τη νέα έκδοση του πλαισίου δεδομένων SmallerCountries. Στη συνέχεια, εκτελέστε τον κώδικα για να δημιουργήσετε το ιστόγραμμα του πληθυσμού που περιλαμβάνει μόνο αυτές τις χώρες.
Πρόκειται για ένα πολύ διαφορετικό ιστόγραμμα από εκείνο που περιελάμβανε τις ακραίες τιμές. Τώρα μπορούμε να αντιληφθούμε τον τρόπο με τον οποίο οι χώρες που προηγουμένως ομαδοποιούνταν σε ένα διάστημα τιμών στο κατώτερο τμήμα της κατανομής πραγματικά διαφέρουν ως προς το μέγεθος του πληθυσμού τους. Παρατηρήστε επίσης ότι η κλίμακα του άξονα x έχει αλλάξει από 0 σε 1.500 (εκατομμύρια) σε 0 έως 70.
Σκεφτείτε το εξής: Αν δημιουργούσαμε ένα boxplot για να δείξουμε την κατανομή της μεταβλητής Population μόνο για τις χώρες στο SmallerCountries, πώς θα έμοιαζε;
Γιατί πιστεύετε ότι θα συμβεί αυτό;
Επεξήγηση
Θα είχε ένα ευρύτερο κουτί στα αριστερά (κάτω από τη διάμεσο) είναι η σωστή απάντηση.
Γιατί θα συμβεί αυτό:
Φύση των “μικρότερων χωρών”: Όταν αναφερόμαστε σε “SmallerCountries”, μιλάμε για χώρες με σχετικά χαμηλό πληθυσμό. Αυτό σημαίνει ότι: - Η πλειονότητα των τιμών θα είναι συγκεντρωμένη στο κάτω μέρος της κλίμακας - Θα υπάρχουν λίγες χώρες με υψηλότερο πληθυσμό που θα δημιουργούν “ουρά” προς τα πάνω
Ασυμμετρία προς τα δεξιά (Right-skewed distribution): Οι κατανομές πληθυσμών συνήθως είναι ασύμμετρες προς τα δεξιά γιατί: - Πολλές χώρες έχουν σχετικά μικρούς πληθυσμούς - Λίγες χώρες έχουν πολύ μεγάλους πληθυσμούς - Ακόμη και στις “μικρότερες” χώρες, υπάρχει αυτό το μοτίβο
Τι σημαίνει αυτό για το boxplot: Σε μια ασύμμετρη προς τα δεξιά κατανομή: - Q1 έως διάμεσος: Μικρότερη απόσταση (πιο συμπαγές κάτω μισό) - Διάμεσος έως Q3: Μεγαλύτερη απόσταση (πιο διασκορπισμένο πάνω μισό) - Αποτέλεσμα: Το κουτί θα είναι ευρύτερο στο κάτω μέρος (αριστερά από τη διάμεσο)
Παράδειγμα: Αν οι “μικρότερες χώρες” έχουν πληθυσμούς: - Q1: 2 εκατομμύρια - Διάμεσος: 4 εκατομμύρια
- Q3: 8 εκατομμύρια
Παρατηρήστε: - Q1 → Διάμεσος: 2 εκατομμύρια διαφορά - Διάμεσος → Q3: 4 εκατομμύρια διαφορά - Το κάτω μισό του κουτιού είναι πιο “συμπιεσμένο”
Γενική αρχή: Σε ασύμμετρες κατανομές, το κουτί του boxplot είναι ευρύτερο στην πλευρά προς την οποία “τραβάει” η ουρά της κατανομής. Επειδή οι πληθυσμοί έχουν μακριά ουρά προς τα πάνω (δεξιά), το κουτί θα είναι ευρύτερο προς τα κάτω (αριστερά).
Ας δημιουργήσουμε εκ νέου το boxplot της μεταβλητής Population μόνο για τις χώρες στο πλαίσιο δεδομένων SmallerCountries για να δούμε πώς φαίνεται. Τροποποιήστε τον παρακάτω κώδικα για να δημιουργήσετε το boxplot.
Μισό λεπτό! Δεν αφαιρέσαμε τις ακραίες τιμές όταν δημιουργήσαμε το πλαίσιο δεδομένων SmallerCountries; Γιατί υπάρχουν ακόμα ακραίες τιμές στο παραπάνω boxplot;
Παρατηρήστε ότι αυτό το boxplot έχει μεγαλύτερο κουτί στα δεξιά από ό,τι στα αριστερά. Πώς αναπαρίσταται αυτό το χαρακτηριστικό στο ιστόγραμμα της ίδιας μεταβλητής;
Επεξήγηση
Το ιστόγραμμα έχει ασυμμετρία στα δεξιά (μακρύτερη ουρά στα δεξιά) είναι η σωστή απάντηση.
Σχέση boxplot - ιστόγραμμα:
Όταν ένα boxplot έχει μεγαλύτερο κουτί στα δεξιά, αυτό σημαίνει ότι:
Η απόσταση από τη διάμεσο έως το Q3 είναι μεγαλύτερη από την απόσταση διάμεσο-Q1
Το 3ο τεταρτημόριο έχει μεγαλύτερη διασπορά από το 2ο τεταρτημόριο
Οι τιμές πάνω από τη διάμεσο είναι πιο διασκορπισμένες
Αυτό μεταφράζεται στο ιστόγραμμα ως:
Κύριος όγκος των δεδομένων συγκεντρωμένος στις χαμηλότερες τιμές (αριστερά)
Μακριά ουρά που εκτείνεται προς τις υψηλότερες τιμές (δεξιά)
Ασυμμετρία στα δεξιά (positive skew)
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Ασυμμετρία στα αριστερά: Αυτό θα συνέβαινε αν το κουτί ήταν μεγαλύτερο στα αριστερά
Γ - Συμμετρικό: Αυτό θα συνέβαινε αν τα δύο μέρη του κουτιού ήταν ίσα
Κλειδί για κατανόηση: Η κατεύθυνση του μεγαλύτερου τμήματος του κουτιού δείχνει προς ποια κατεύθυνση υπάρχει μεγαλύτερη διασπορά, που αντιστοιχεί στην κατεύθυνση της ουράς του ιστογράμματος.
Για να επαληθεύσουμε τη διαίσθησή μας σχετικά με τη σχέση μεταξύ ιστογράμματος και boxplot, δοκιμάστε να συνδέσετε (με τον τελεστή διοχέτευσης, %>%) τον κώδικα για το boxplot απευθείας με το ιστόγραμμα της μεταβλητής Population από το πλαίσιο δεδομένων SmallerCountries. Μπορείτε επίσης να τροποποιήσετε τις παραμέτρους fill ή width για να κάνετε το boxplot περισσότερο ορατό.
Ορίσαμε την παράμετρο fill ίση με “white” και την παράμετρο width ίση με 4 για πάρουμε το σωστό αποτελέσμα. Η κατανομή με ασυμμετρία στα δεξιά που παρατηρούμε στο ιστόγραμμα αναπαρίσταται στο boxplot με μεγαλύτερο κουτί προς τα δεξιά και μακρύτερη απόληξη στα δεξιά. Οι ακραίες τιμές στο ιστόγραμμα αναπαρίστανται ως «ουρά» και στο boxplot ως «κουκκίδες».
4.8 Διερεύνηση της Μεταβλητότητας σε Ποιοτικές Μεταβλητές
Μέχρι τώρα έχουμε επικεντρωθεί στην εξέταση των κατανομών ποσοτικών μεταβλητών. Η μέθοδος εξέτασης μιας κατανομής διαφέρει, ωστόσο, ανάλογα με το αν είναι ποσοτική ή ποιοτική.
Τι παρατηρείτε σχετικά με το σχήμα, το κέντρο, την διασπορά και τις ακραίες τιμές στην κατανομή του παραπάνω ιστογράμματος;
Αν και ίσως μπήκατε στον πειρασμό να χαρακτηρίσετε την παραπάνω κατανομή «περίπου συμμετρική» ή «περίπου κανονική», δεν είναι λίγο περίεργο να πούμε ότι το κέντρο αυτής της κατανομής είναι η τιμή «Asian/Ασιάτης»; Ποιο είναι το εύρος της κατανομής; Είναι το «Other/Άλλο» μείον το «African American/Αφροαμερικάνος»; Κάτι δεν φαίνεται να πηγαίνει καλά με αυτήν την περιγραφή!
Μέχρι τώρα έχουμε χρησιμοποιήσει ιστογράμματα για να εξετάσουμε την κατανομή μιας μεταβλητής. Αλλά τα ιστογράμματα δεν είναι κατάλληλα αν η μεταβλητή είναι ποιοτική. Και αν η R αναγνωρίζει ότι μια μεταβλητή είναι ποιοτική (αν, για παράδειγμα, την έχετε καθορίσει ως παράγοντα/factor), δεν θα εμφανίσει καν το ιστόγραμμα, και θα εμφανίσει ένα μήνυμα σφάλματος.
Ραβδογράμματα
Όταν μια μεταβλητή είναι ποιοτική (ονομάζεται και κατηγορική) μπορείτε να οπτικοποιήσετε την κατανομή της με ένα ραβδόγραμμα. Το ραβδόγραμμα μοιάζει με το ιστόγραμμα, αλλά είναι ένα διαφορετικό διάγραμμα. Δεν υπάρχουν διαστήματα τιμών, για παράδειγμα, σε ένα ραβδόγραμμα. Ο αριθμός των ράβδων στο ραβδόγραμμα θα ισούται πάντα με τον αριθμό των κατηγοριών της μεταβλητής σας (ονομάζονται και επίπεδα/levels της μεταβλητής).
Ας εξετάσουμε λοιπόν ποιοτικές μεταβλητές όπως το Gender (Φύλο) και η RaceEthnic (Φυλετική Προέλευση) από το πλαίσιο δεδομένων Fingers. Επειδή η μεταβλητή Gender έχει δύο κατηγορίες/επίπεδα σε αυτό το πλαίσιο δεδομένων (άνδρας/γυναίκα), περιμένουμε να δούμε δύο ράβδους.
Ορίστε ο κώδικας για τη δημιουργία του ραβδογράμματος της μεταβλητής Gender:
gf_bar(~Gender, data =Fingers)
Παρατηρήστε ότι ο άξονας y (με τον τίτλο “Count”) αντιστοιχεί στη συχνότητα εμφάνισης κάθε κατηγορίας/επιπέδου της μεταβλητής. Σε αυτή την περίπτωση, πρόκειται για τη συχνότητα εμφάνισης των κατηγοριών female και male.
Στο παρακάτω παράθυρο κώδικα χρησιμοποιήστε τη συνάρτηση gf_bar() για να δημιουργήσετε το ραβδόγραμμα της μεταβλητής RaceEthnic (φυλετική προέλευση).
Μπορείτε να αλλάξετε το πλάτος των ράβδων με την παράμετρο width και ορίζοντάς την σε κάποιον αριθμό μεταξύ του 0 και του 1.
Να συγκρίνετε και να αντιπαραβάλλετε τα ραβδογράμματα και τα ιστογράμματα. Να εστιάσετε συγκεκριμένα στον άξονα x, τον άξονα y και το είδος της μεταβλητής. Σε τι μοιάζουν και σε τι διαφέρουν;
Είδαμε παραπάνω τις παραμέτρους color και fill για την gf_histogram(). Οι ίδιες παράμετροι μπορούν να οριστούν και για την gf_bar(). Δοκιμάστε να να αλλάξετε τις τιμές τους.
Η συνάρτηση gf_bar() θα εμφανίσει τις απόλυτες συχνότητες εμφάνισης των κατηγοριών στον άξονα y, αλλά μπορείτε να δημιουργήσετε ραβδογράμματα ποσοστών με την gf_percents() ή αναλογιών με την gf_props().
Σχήμα, Κέντρο και Διασπορά
Η οπτικοποίηση των κατανομών των κατηγορικών μεταβλητών είναι εξίσου σημαντική με την οπτικοποίηση των κατανομών των ποσοτικών μεταβλητών. Ωστόσο, τα χαρακτηριστικά που πρέπει να εξετάσουμε διαφέρουν λιγάκι.
Το σχήμα της κατανομής δεν έχει νόημα για μια κατηγορική μεταβλητή. Με μια απλή αναδιάταξη των ράβδων το σχήμα αλλάζει. Επομένως, δεν δίνουμε ιδιαίτερη προσοχή στο σχήμα της κατανομής μιας κατηγορικής μεταβλητής.
Ωστόσο, τόσο το κέντρο όσο και η διασπορά αξίζει να εξεταστούν. Κατά κάποιο τρόπο, το κέντρο είναι πιο εύκολο να προσδιοριστεί σε μια κατηγορική μεταβλητή από ό,τι σε μια ποσοτική μεταβλητή. Η κατηγορία με τη μεγαλύτερη συχνότητα εμφάνισης είναι το κέντρο· είναι εκεί που βρίσκονται οι περισσότερες παρατηρήσεις. Αυτή επίσης καλείται επικρατούσα τιμή της κατανομής—η πιο συχνή τιμή της μεταβλητής.
Η διασπορά είναι ένας τρόπος χαρακτηρισμού του πόσο καλά κατανέμονται οι παρατηρήσεις στις κατηγορίες. Οι περισσότερες παρατηρήσεις συγκεντρώνονται σε μία κατηγορία, ή κατανέμονται περίπου ομοιόμορφα σε όλες τις κατηγορίες;
Πίνακες Συχνοτήτων
Οι τιμές των κατηγορικών μεταβλητών μπορούν επίσης να συνοψιστούν με πίνακες συχνοτήτων. Έχουμε χρησιμοποιήσει τη συνάρτηση table() στο προηγούμενο κεφάλαιο. Χρησιμοποιήστε την table() για να δείτε τις κατανομές των μεταβλητών Gender και RaceEthnic από το πλαίσιο δεδομένων Fingers.
Μερικές φορές μπορεί να θέλουμε να δούμε και το συνολικό άθροισμα των παρατηρήσεων στα επίπεδα μιας κατηγορικής μεταβλητής. Για να εμφανίσουμε τον πίνακα συχνοτήτων της μεταβλητής RaceEthnic μαζί με το συνολικό άθροισμα των τιμών, μπορούμε να χρησιμοποιήσουμε τη συνάρτηση table() σε συνδυασμό με τη συνάρτηση addmargins(). Η addmargins() προσθέτει το σύνολο (άθροισμα) των συχνοτήτων στον πίνακα.
Τις περισσότερες φορές μπορεί να είναι πιο χρήσιμο να εξετάσουμε τις σχετικές συχνότητες (αναλογίες) παρά τις απόλυτες συχνότητες. Μπορούμε να χρησιμοποιήσουμε τη συνάρτηση prop.table:
Δοκιμάστε να χρησιμοποιήσετε την addmargins() μαζί με την prop.table() για τη μεταβλητή RaceEthnic. Ποιο προβλέπετε ότι θα είναι το συνολικό άθροισμα;
Έπειτα πολλαπλασιάστε τις τιμές της prop.table() με το 100 και χρησιμοποιήστε τη συνάρτηση round() με την παράμετρο digits = 2, όπως παρακάτω:
Πιστεύετε ότι θα μπορούσαμε να χρησιμοποιήσουμε την table() και για ποσοτικές μεταβλητές όπως το μήκος αντίχειρα (Thumb); Ας το δοκιμάσουμε εδώ. Γράψτε κώδικα για τη δημιουργία ενός πίνακα συχνοτήτων για τη μεταβλητή Thumb.
Τι παρατηρείτε σε σύγκριση με τους πίνακες συχνοτήτων των ποιοτικών μεταβλητών;
Ανακεφαλαίωση
Ας ανακεφαλαιώσουμε τους τρόπους με τους οποίους μπορούμε να συνοψίσουμε τους διαφορετικούς τύπους μεταβλητών.
Οι κατανομές των ποιοτικών μεταβλητών συνοψίζονται καλύτερα με πίνακες συχνοτήτων και ραβδογράμματα.
Οι κατανομές των ποσοτικών μεταβλητών αναλύονται καλύτερα με ιστογράμματα και boxplot.
Για τους δύο τύπους μεταβλητών, μπορεί κανείς να επιλέξει να χρησιμοποιήσει απόλυτες συχνότητες ή σχετικές συχνότητες (όπως πυκνότητα πιθανότητας ή αναλογία), ανάλογα με τον σκοπό. Είναι σημαντικό να διαθέτουμε ένα ολοκληρωμένο σύνολο εργαλείων για την εξέταση όλων των τύπων μεταβλητών.
Μεταβλητή
Είδος οπτικοποίησης
Κώδικας R
Ποιοτική
Πίνακας συχνοτήτων, Ραβδόγραμμα
table, gf_bar
Ποσοτική
Ιστόγραμμα, Boxplot
gf_histogram, gf_boxplot
4.9 Η Διαδικασία Παραγωγής των Δεδομένων
Μπορούμε να μάθουμε πολλά εξετάζοντας τις κατανομές των δεδομένων (σε ιστογράμματα, boxplot κ.λπ.). Αλλά να έχετε υπόψη ότι τα πραγματικά δεδομένα προέρχονται πάντα από ένα δείγμα (είναι οι παρατηρήσεις που πραγματικά μετρήθηκαν) και επομένως αποτελούν μόνο ένα υποσύνολο του συνόλου του πληθυσμού (όλες οι παρατηρήσεις που παρουσιάζουν ενδιαφέρον). Επειδή τα δεδομένα προέρχονται πάντα από ένα δείγμα, θα χρησιμοποιούμε εναλλακτικά τους όρους «κατανομή δείγματος» και «κατανομή δεδομένων».
Όταν εξετάζουμε δεδομένα, το ενδιαφέρον μας δεν εστιάζεται μόνο στην κατανομή τους, αλλά και στον πληθυσμό από τον οποίο αντλήθηκαν. Σε αυτό το μάθημα, εμβαθύνουμε λίγο περισσότερο στον πληθυσμό. Δεν θέλουμε μόνο να χρησιμοποιήσουμε τα δεδομένα μας για να κατανοήσουμε καλύτερα τον πληθυσμό από τον οποίο προέρχονται, αλλά θέλουμε επίσης να κατανοήσουμε τις διαδικασίες που δημιούργησαν τη μεταβλητότητα στον ίδιο τον πληθυσμό, η οποία με τη σειρά της αντικατοπτρίζεται στα δεδομένα. Αυτό είναι που αναφέρουμε ως Διαδικασία Παραγωγής των Δεδομένων (ΔΠΔ).
Αν η απάντησή μας στην ερώτηση «Γιατί η κατανομή του δείγματος είναι αυτή που είναι;» είναι απλώς «Επειδή έτσι είναι και η κατανομή του πληθυσμού», δεν είναι πολύ ικανοποιητική. Θα θέλαμε να συνεχίσουμε ρωτώντας «Γιατί η κατανομή του πληθυσμού είναι έτσι;» Η απάντηση σε αυτή την ερώτηση αφορά τη ΔΠΔ, η οποία είναι συχνά αυτό που μας ενδιαφέρει περισσότερο.
Πολλοί φοιτητές βρίσκουν την έννοια του πληθυσμού πιο εύκολα κατανοητή από τη ΔΠΔ. Γιατί εισάγουμε την έννοια της ΔΠΔ; Εν μέρει χρησιμοποιούμε τη ΔΠΔ επειδή μας κρατά εστιασμένους στις διαδικασίες που προκαλούν τη μεταβλητότητα στον πραγματικό κόσμο. Αλλά χρησιμοποιούμε επίσης τη ΔΠΔ για έναν άλλο λόγο. Ακόμη και όταν μελετάμε ολόκληρο τον πληθυσμό, πρέπει να εξετάσουμε τις διαδικασίες που προκαλούν τη μεταβλητότητα σε αυτόν τον πληθυσμό. Για παράδειγμα, αν θέλουμε να κατανοήσουμε τη συμμετοχή των ψηφοφόρων στις εκλογές κάθε περιφέρειας της Ελλάδας για ένα συγκεκριμένο έτος, θα έχουμε δεδομένα από ολόκληρο τον πληθυσμό – δηλαδή, από ολόκληρη τη χώρα. Στην περίπτωση αυτή δεν υπάρχει κάποιος μεγαλύτερος πληθυσμός από τον οποίο λαμβάνουμε δείγμα. Αλλά εξακολουθεί να υπάρχει μια ΔΠΔ, ένα σύνολο διαδικασιών που παράγουν την κατανομή της συμμετοχής των ψηφοφόρων. Και συχνά, η ΔΠΔ παραμένει άγνωστη, ακόμη και όταν έχουμε δεδομένα για ολόκληρο τον πληθυσμό. Γι’ αυτό και παρουσιάζουμε εδώ την έννοια της ΔΠΔ.
Είτε εξετάζουμε την κατανομή για μεμονωμένες μεταβλητές (όπως κάνουμε σε αυτό το κεφάλαιο), είτε τις σχέσεις μεταξύ μεταβλητών (όπως στο επόμενο κεφάλαιο), θέλουμε πάντα να εμβαθύνουμε, προσπαθώντας να κατανοήσουμε ποιες διαδικασίες μπορεί να παρήγαγαν τη μεταβλητότητα που βλέπουμε στα δεδομένα μας.
Παράδειγμα: Η ΔΠΔ του Χρόνου Αναμονής Λεωφορείου
Ακολουθεί ένα απλό παράδειγμα. Το παρακάτω ιστόγραμμα δείχνει την κατανομή 60.000 χρόνων αναμονής ατόμων σε μια στάση λεωφορείου που βρίσκεται κάπου στο κέντρο της Αθήνας.
Σχήμα 4.18
Περιγράψτε τι βλέπετε στο ιστόγραμμα. Σε ποια συμπεράσματα καταλήγετε για τον χρόνο αναμονής λεωφορείου;
Γιατί νομίζετε ότι η κατανομή έχει αυτό το σχήμα; Ποια διαδικασία ή διαδικασίες θα μπορούσαν να εξηγήσουν αυτό το σχήμα;
Από το ιστόγραμμα μπορείτε να δείτε ότι οι περισσότεροι άνθρωποι περιμένουν μόνο σύντομο χρόνο για το λεωφορείο, ενώ κάποιοι άνθρωποι καταλήγουν να περιμένουν μεγαλύτερους χρόνους. Αλλά για να απαντήσουμε στο «γιατί» απαιτείται να κοιτάξουμε πέρα από τα δεδομένα του ιστογράμματος για να εξετάσουμε τη Διαδικασία Παραγωγής αυτών των Δεδομένων.
Για να κατανοήσουμε καλύτερα τη ΔΠΔ ας φανταστούμε τους ανθρώπους που περιμένουν σε μια στάση λεωφορείου και το χρόνο αναμονής τους. Χρειάζεται να επιστρατεύσουμε την καθημερινή μας γνώση για το σύστημα δημόσιων συγκοινωνιών και το πώς λειτουργεί. Τα λεωφορεία έχουν συνήθως σταθερό πρόγραμμα δρομολογίων, και επειδή πολλοί από τους επιβάτες είναι τακτικοί που δεν θέλουν να περιμένουν στη στάση λεωφορείου για μεγάλο χρονικό διάστημα, ξέρουν περίπου πότε θα έρθει το λεωφορείο και προσπαθούν να φτάσουν στη στάση λίγο πριν έρθει.
Σε τι νομίζετε ότι οφείλεται εκείνο το «βουναλάκι» στα δεξιά της κατανομής;
Ο Πληθυσμός είναι το Αποτέλεσμα της ΔΠΔ Μακροπρόθεσμα
Για κάποιες περιπτώσεις δεδομένων, αξίζει να σκεφτούμε τον πληθυσμό. Αν λάβετε δείγμα από πιθανούς ψηφοφόρους για να προβλέψετε το αποτέλεσμα των εκλογών, μπορείτε να φανταστείτε το συνολικό πληθυσμό των ψηφοφόρων που βρίσκεται «εκεί έξω», και απλώς περιμένουν να συμπεριληφθούν στο δείγμα (ή όχι). Αλλά για τους ανθρώπους που περιμένουν σε μια στάση λεωφορείου, ο πληθυσμός αλλάζει συνεχώς.
Υπάρχει μια βαθιά και σημαντική σχέση μεταξύ της ΔΠΔ και του πληθυσμού. Ο πληθυσμός είναι το μακροπρόθεσμο αποτέλεσμα πολλών διαδικασιών, τις οποίες αναφέρουμε συνολικά ως Διαδικασία Παραγωγής των Δεδομένων. Θα μπορούσατε να σκεφτείτε τη ΔΠΔ ως πολλούς αιτιακούς παράγοντες, ο καθένας με κάποια πιθανότητα εμφάνισης, που παράγουν την κατανομή του πληθυσμού με την πάροδο του χρόνου.
Επειδή η ΔΠΔ και ο πληθυσμός συνδέονται με αυτόν τον τρόπο, μερικές φορές θα χρησιμοποιούμε εναλλακτικά τους δύο όρους. Όταν το κάνουμε αυτό, τονίζουμε ότι η εξήγηση του φαινομένου που μελετούμε δενs αφορά μόνο τα δεδομένα μας αλλά και όλες τις διαδικασίες που παρήγαγαν τις κατανομές που βλέπουμε. Περιλαμβάνει τις διαδικασίες (π.χ., δειγματοληψία και ερευνητικός σχεδιασμός) που είχαν ως αποτέλεσμα τα δεδομένα μας, αλλά επίσης τις διαδικασίες που δημιούργησαν τη μεταβλητότητα στον κόσμο από τον οποίο συλλέχθηκαν τα δεδομένα.
Ένας ερευνητής παρατηρεί ότι η κατανομή των εισοδημάτων σε μια πόλη έχει έντονη δεξιά ασυμμετρία (πολλοί άνθρωποι με χαμηλά εισοδήματα, λίγοι με πολύ υψηλά). Για να κατανοήσει αυτό το φαινόμενο, πρέπει να εξετάσει:
Επεξήγηση
Τις κοινωνικοοικονομικές διαδικασίες που δημιουργούν αυτή την ανισότητα είναι η σωστή απάντηση.
Γιατί αυτή η επιλογή είναι σωστή:
Αυτή η ερώτηση αφορά τη Διαδικασία Παραγωγής των Δεδομένων (ΔΠΔ). Όταν βλέπουμε ένα συγκεκριμένο μοτίβο στα δεδομένα (εδώ τη δεξιά ασυμμετρία των εισοδημάτων), πρέπει να κατανοήσουμε τις υποκείμενες διαδικασίες που το προκαλούν.
Εκπαιδευτικό σύστημα: Πώς η εκπαίδευση επηρεάζει τις ευκαιρίες καριέρας
Αγορά εργασίας: Διαθεσιμότητα θέσεων εργασίας, δεξιότητες που ζητούνται
Θεσμικοί παράγοντες: Κατώτατος μισθός, φορολογικό σύστημα
Κοινωνικοί παράγοντες: Κληρονομικότητα, δικτύωση, διακρίσεις Γιατί οι άλλες επιλογές δεν είναι σωστές:
Α) Στατιστικές ιδιότητες: Αυτές περιγράφουν το μοτίβο αλλά δεν εξηγούν γιατί υπάρχει
Β) Μέγεθος δείγματος/μέθοδος συλλογής: Αφορά την ποιότητα των δεδομένων, όχι τη ΔΠΔ
Δ) Σύγκριση με άλλες πόλεις: Μπορεί να επιβεβαιώσει το μοτίβο αλλά δεν εξηγεί τις αιτίες του
Βασική αρχή της ΔΠΔ:
Όπως αναφέρεται στο κείμενο: “θέλουμε επίσης να κατανοήσουμε τις διαδικασίες που δημιούργησαν τη μεταβλητότητα στον ίδιο τον πληθυσμό”
Πρακτική εφαρμογή: - Ερώτηση δεδομένων: “Πόσο ασύμμετρη είναι η κατανομή;” - Ερώτηση ΔΠΔ: “Ποιες διαδικασίες δημιουργούν αυτή την ασυμμετρία;”
Η ΔΠΔ μας βοηθά να κατανοήσουμε το “γιατί” πίσω από τα μοτίβα που παρατηρούμε.
4.10 Από τα Δεδομένα στη ΔΠΔ
Η ανάλυση δεδομένων περιλαμβάνει ένα πέρα-δώθε μεταξύ της κατανομής των δεδομένων, από τη μια πλευρά, και της καλύτερης εικασίας μας για το πώς θα μοιάζει η κατανομή του πληθυσμού, από την άλλη. Πρέπει να το έχουμε αυτό υπόψη για να κατανοήσουμε τη ΔΠΔ που μπορεί να παρήγαγε τη μεταβλητότητα στον πληθυσμό και κατά συνέπεια τη μεταβλητότητα που βλέπουμε στα δεδομένα μας.
Καθώς μαθαίνετε να σκέφτεστε ως στατιστικολόγος, βοηθάει να κατανοήσετε τις δύο βασικές προσεγγίσεις που θα χρησιμοποιείτε ως μέρος αυτού του πέρα-δώθε.
Κοιτάζοντας μια κατανομή δεδομένων, προσπαθείτε να φανταστείτε πώς θα μπορούσε να μοιάζει η κατανομή του πληθυσμού, και ποιες διαδικασίες θα μπορούσαν να παράγουν μια τέτοια κατανομή. Θα ονομάσουμε αυτή τη στρατηγική από κάτω προς τα πάνω καθώς κινούμαστε από συγκεκριμένα δεδομένα προς την πιο άγνωστη, αφηρημένη ΔΠΔ.
Σκεπτόμενοι για τη ΔΠΔ, και όλα όσα γνωρίζετε για τον κόσμο, προσπαθείτε να φανταστείτε πώς θα έπρεπε να μοιάζει η κατανομή των δεδομένων, αν η θεωρία σας για τη ΔΠΔ είναι αληθής. Θα το ονομάσουμε αυτή τη στρατηγική από πάνω προς τα κάτω καθώς κινούμαστε από τις ιδέες μας για τη ΔΠΔ στην πρόβλεψη πραγματικών δεδομένων.
Χρησιμοποιήσαμε την προσέγγιση από κάτω προς τα πάνω προηγουμένως όταν εξετάσαμε την κατανομή των χρόνων αναμονής σε μια στάση λεωφορείου και προσπαθήσαμε να φανταστούμε τη διαδικασία που την παρήγαγε. Η προσέγγιση από πάνω προς τα κάτω θα ήταν σχετική αν ρωτούσαμε: τι θα γινόταν αν το σύστημα των λεοφωρείων λειτουργούσε διαφορετικά; Τι θα γινόταν αν, αντί να ακολουθεί το πρόγραμμα δρομολογίων, κάθε λεωφορείο περίμενε στη στάση και έφευγε κάθε φορά που περίμεναν εκεί 10 άτομα;
Σε ένα σύστημα λεωφορείων όπου ένα λεωφορείο φεύγει από τη στάση κάθε φορά που συγκεντρώνονται 10 επιβάτες, πώς θα έμοιαζε η κατανομή των χρόνων αναμονής των επιβατών;
Επεξήγηση
Μια κατανομή με πολλούς επιβάτες να περιμένουν λίγο και λίγους να περιμένουν περισσότερο είναι η σωστή απάντηση.
Γιατί αυτή η επιλογή είναι σωστή:
Σε αυτό το σύστημα, ένα λεωφορείο περιμένει στη στάση μέχρι να μαζευτούν 10 επιβάτες και μετά φεύγει. Φανταστείτε ότι οι επιβάτες φτάνουν στη στάση σε τυχαίες στιγμές. Ο πρώτος επιβάτης που φτάνει μετά την αναχώρηση του προηγούμενου λεωφορείου πρέπει να περιμένει μέχρι να έρθουν άλλοι 9, οπότε περιμένει περισσότερο. Ο 10ος επιβάτης, που φτάνει τελευταίος, δεν περιμένει σχεδόν καθόλου, γιατί το λεωφορείο φεύγει μόλις φτάσει. Οι υπόλοιποι επιβάτες (2ος, 3ος, κ.λπ.) περιμένουν κάπου ενδιάμεσα. Επειδή οι επιβάτες φτάνουν τυχαία, οι περισσότεροι είναι πιθανό να φτάσουν όταν η ομάδα των 10 είναι σχεδόν πλήρης (π.χ., ως 8οι, 9οι ή 10οι), οπότε περιμένουν λίγο. Λιγότεροι φτάνουν νωρίς (π.χ., ως 1οι ή 2οι), οπότε λιγότεροι περιμένουν πολύ. Αυτό δημιουργεί μια κατανομή όπου οι μικροί χρόνοι αναμονής είναι πιο συνηθισμένοι, ενώ οι μεγάλοι χρόνοι είναι σπανιότεροι. Σε ένα ιστόγραμμα, αυτό θα φαινόταν σαν μια καμπύλη με ψηλό σημείο κοντά στους μικρούς χρόνους και μια μακριά ουρά προς τους μεγαλύτερους χρόνους.
Πώς λειτουργεί το σύστημα:
Όταν φτάνουν οι επιβάτες, ο χρόνος που περιμένουν εξαρτάται από το πόσο κοντά είναι η ομάδα των 10 στο να συμπληρωθεί.
Οι τελευταίοι επιβάτες περιμένουν λιγότερο, ενώ οι πρώτοι περιμένουν περισσότερο.
Επειδή οι επιβάτες φτάνουν τυχαία, οι περισσότεροι τείνουν να φτάνουν αργότερα στην ομάδα, οδηγώντας σε περισσότερους μικρούς χρόνους αναμονής. Γιατί οι άλλες επιλογές δεν είναι σωστές:
Α) Ομοιόμορφη κατανομή: Οι χρόνοι αναμονής δεν είναι ίδιοι για όλους. Σε ένα σύστημα με σταθερό πρόγραμμα (π.χ., λεωφορείο κάθε 10 λεπτά), οι χρόνοι αναμονής μπορεί να είναι πιο ομοιόμορφοι (από 0 έως 10 λεπτά). Εδώ, όμως, οι χρόνοι εξαρτώνται από το πότε φτάνει κάθε επιβάτης στην ομάδα των 10, οπότε δεν είναι ίδιοι.
Β) Συμμετρική κατανομή: Μια συμμετρική κατανομή θα σήμαινε ότι οι μικροί και οι μεγάλοι χρόνοι αναμονής είναι εξίσου συχνοί, αλλά εδώ οι μικροί χρόνοι είναι πιο συχνοί, επειδή οι περισσότεροι επιβάτες φτάνουν αργότερα στην ομάδα.
Δ) Πολλοί περιμένουν πολύ, λίγοι λίγο: Αυτό είναι το αντίθετο από το τι συμβαίνει. Οι περισσότεροι επιβάτες περιμένουν λίγο, γιατί φτάνουν όταν η ομάδα είναι σχεδόν πλήρης.
Βασική αρχή της Διαδικασίας Παραγωγής Δεδομένων (ΔΠΔ):
Όπως αναφέρεται στο κείμενο: “Σκεπτόμενοι για τη ΔΠΔ, προσπαθείτε να φανταστείτε πώς θα έπρεπε να μοιάζει η κατανομή των δεδομένων, αν η θεωρία σας για τη ΔΠΔ είναι αληθής.” Εδώ, η ΔΠΔ είναι ο τρόπος που φτάνουν οι επιβάτες και η συνθήκη ότι το λεωφορείο φεύγει με 10 επιβάτες. Αυτό οδηγεί σε μια κατανομή όπου οι μικροί χρόνοι αναμονής είναι πιο συχνοί.
Πρακτική εφαρμογή: - Ερώτηση δεδομένων: «Πώς μοιάζει το ιστόγραμμα των χρόνων αναμονής;» - Ερώτηση ΔΠΔ: «Πώς ο τρόπος που φτάνουν οι επιβάτες και η συνθήκη των 10 επιβατών δημιουργούν αυτό το σχήμα;»
Η κατανόηση του πώς λειτουργεί το σύστημα μας βοηθά να προβλέψουμε ότι οι περισσότεροι επιβάτες θα περιμένουν λίγο, δημιουργώντας μια κατανομή με αυτή τη μορφή.
Μπορέσατε πιθανώς να φανταστείτε το σχήμα της κατανομής. Το να έχουμε κάποιες προσδοκίες για τη ΔΠΔ (είτε είναι σωστές είτε λάθος) μπορεί να μας βοηθήσει να ερμηνεύσουμε οποιαδήποτε δεδομένα συλλέξουμε.
Και οι δύο προσεγγίσεις, από πάνω προς τα κάτω και από κάτω προς τα πάνω, είναι σημαντικές. Μερικές φορές δεν έχουμε ιδέα πώς είναι η ΔΠΔ, οπότε δεν έχουμε άλλη επιλογή παρά να χρησιμοποιήσουμε τη στρατηγική από κάτω προς τα πάνω, αναζητώντας στοιχεία στα δεδομένα. Βασισμένοι σε αυτά τα στοιχεία, δημιουργούμε υποθέσεις για τη ΔΠΔ.
Αλλά άλλες φορές, έχουμε κάποιες καλές ιδέες για τη ΔΠΔ που μπορούμε να ελέγξουμε κοιτάζοντας την κατανομή των δεδομένων. Στην προσέγγιση από πάνω προς τα κάτω λέμε: αν η θεωρία μας είναι σωστή, πώς θα έπρεπε να μοιάζει η κατανομή των δεδομένων; Αν μοιάζει όπως προβλέπουμε, η θεωρία μας υποστηρίζεται. Αλλά αν δεν μοιάζει, μπορούμε να είμαστε αρκετά σίγουροι ότι κάνουμε λάθος για τη ΔΠΔ.
Όταν Γνωρίζουμε τη ΔΠΔ: Η Περίπτωση της Ρίψης Ζαριών
Η κατανόησή μας για τη ΔΠΔ είναι συχνά ασαφής, ατελής, και μερικές φορές εντελώς λανθασμένη. Αλλά κάποιες ΔΠΔ είναι γνωστές, όπως οι ρίψεις νομισμάτων και ζαριών, οι οποίες είναι αμιγώς τυχαίες διαδικασίες.
Η τυχαιότητα είναι μια σημαντική ΔΠΔ για το πεδίο της στατιστικής. Συχνά αμφισβητούμε αν η κατανομή στα δεδομένα μας θα μπορούσε να προκύψει από αμιγώς τυχαίες διαδικασίες. Μπορούμε να αρχίσουμε να απαντούμε σε αυτή την ερώτηση ακολουθώντας μια προσέγγιση από πάνω προς τα κάτω: σκεπτόμενοι μια αμιγώς τυχαία διαδικασία και εξετάζοντας τις διάφορες κατανομές δεδομένων που θα μπορούσε να παράγει.
Τα ζάρια παρέχουν ένα οικείο μοντέλο για να σκεφτόμαστε τις τυχαίες διαδικασίες. Παρέχουν επίσης ένα χρήσιμο παράδειγμα για να σκεφτόμαστε τις σχετικές έννοιες του δείγματος, του πληθυσμού και της ΔΠΔ. Στις περισσότερες έρευνες, προσπαθούμε να κατανοήσουμε ΔΠΔ που δεν γνωρίζουμε ήδη, οπότε μπορούμε μόνο να ασχοληθούμε με σκέψη από κάτω προς τα πάνω, ξεκινώντας με ένα δείγμα και προσπαθώντας να μαντέψουμε πώς θα μπορούσε να είναι η ΔΠΔ. Με τα ζάρια έχουμε την πολυτέλεια να πάμε από πάνω προς τα κάτω, ξεκινώντας με τη ΔΠΔ, απλώς επειδή γνωρίζουμε ποια είναι η ΔΠΔ.
Ρίχνουμε ένα εξάπλευρο ζάρι και έρχεται ο αριθμός 3, όπως στην εικόνα. Ποια είναι η διαδικασία που οδήγησε σε αυτό το αποτέλεσμα;
Σχήμα 4.19
Ρίχνουμε ξανά ένα εξάπλευρο ζάρι. Ποια είναι η πιθανότητα να εμφανιστεί το νούμερο 3; Επιλέξτε την καλύτερη εκτίμηση.
Επεξήγηση
Κάθε νούμερο, συμπεριλαμβανομένου του 3, έχει την ίδια πιθανότητα να εμφανιστεί είναι η σωστή απάντηση.
Γιατί αυτή η επιλογή είναι σωστή:
Όταν ρίχνετε ένα κανονικό εξάπλευρο ζάρι, κάθε μία από τις έξι πλευρές (1, 2, 3, 4, 5 ή 6) έχει την ίδια πιθανότητα να εμφανιστεί, γιατί το ζάρι είναι φτιαγμένο έτσι ώστε να είναι δίκαιο. Φανταστείτε ότι πετάτε το ζάρι στον αέρα: κάθε πλευρά έχει εξίσου καλές πιθανότητες να βγει. Το ότι το 3 εμφανίστηκε στην προηγούμενη ρίψη δεν επηρεάζει τη νέα ρίψη, γιατί κάθε ρίψη είναι ανεξάρτητη. Αυτή η διαδικασία, που ονομάζεται Διαδικασία Παραγωγής Δεδομένων (ΔΠΔ), μας λέει ότι το 3 έχει την ίδια πιθανότητα με οποιοδήποτε άλλο νούμερο σε κάθε νέα ρίψη. Έτσι, η καλύτερη εκτίμηση είναι ότι το 3 έχει την ίδια πιθανότητα να εμφανιστεί όπως και τα άλλα νούμερα.
Πώς λειτουργεί η διαδικασία:
Ένα κανονικό εξάπλευρο ζάρι έχει έξι πλευρές, καθεμία με την ίδια πιθανότητα να εμφανιστεί.
Κάθε ρίψη είναι τυχαία και ανεξάρτητη, δηλαδή το αποτέλεσμα της προηγούμενης ρίψης δεν επηρεάζει την επόμενη.
Το 3 είναι εξίσου πιθανό με τα 1, 2, 4, 5 ή 6 σε κάθε ρίψη. Γιατί οι άλλες επιλογές δεν είναι σωστές:
Α) Το 3 θα εμφανιστεί σίγουρα, γιατί εμφανίστηκε και την προηγούμενη φορά: Αυτό είναι λάθος, γιατί η προηγούμενη ρίψη δεν επηρεάζει την επόμενη. Κάθε ρίψη είναι ανεξάρτητη, και το 3 δεν είναι πιο πιθανό μόνο επειδή εμφανίστηκε πριν.
Β) Το 3 είναι λιγότερο πιθανό, γιατί μόλις εμφανίστηκε: Αυτό είναι λάθος για τον ίδιο λόγο. Οι ρίψεις του ζαριού είναι ανεξάρτητες, οπότε το προηγούμενο αποτέλεσμα δεν κάνει το 3 λιγότερο πιθανό.
Δ) Δεν μπορούμε να κάνουμε καμία εκτίμηση: Αυτό δεν είναι σωστό, γιατί γνωρίζουμε ότι το ζάρι είναι δίκαιο και κάθε πλευρά έχει την ίδια πιθανότητα. Μπορούμε να εκτιμήσουμε ότι το 3 έχει την ίδια πιθανότητα με τα άλλα νούμερα.
Βασική αρχή της Διαδικασίας Παραγωγής Δεδομένων (ΔΠΔ):
Όπως αναφέρεται στο κείμενο: «Κοιτάζοντας μια κατανομή δεδομένων, προσπαθείτε να φανταστείτε πώς θα μπορούσε να μοιάζει η κατανομή του πληθυσμού και ποιες διαδικασίες θα μπορούσαν να παράγουν μια τέτοια κατανομή.» Εδώ, η ΔΠΔ είναι η τυχαία ρίψη ενός κανονικού ζαριού, όπου κάθε πλευρά έχει την ίδια πιθανότητα. Αυτό μας βοηθά να προβλέψουμε ότι το 3 είναι εξίσου πιθανό με οποιοδήποτε άλλο νούμερο στην επόμενη ρίψη.
Πρακτική εφαρμογή: - Ερώτηση δεδομένων: «Ποιο νούμερο μπορεί να δείξει το ζάρι στην επόμενη ρίψη;» - Ερώτηση ΔΠΔ: «Ποια διαδικασία καθορίζει το αποτέλεσμα της επόμενης ρίψης;» (Απάντηση: Μία τυχαία ρίψη ενός κανονικού ζαριού με ίσες πιθανότητες)
Η κατανόηση της ΔΠΔ μας βοηθά να προβλέψουμε ότι το 3 έχει την ίδια πιθανότητα με τα άλλα νούμερα σε κάθε νέα ρίψη.
Χρήση της R για να Δημιουργήσουμε μια ΔΠΔ
Θα μπορούσαμε να μελετήσουμε τη ΔΠΔ της ρίψης ζαριών απλώς ρίχνοντάς τα χιλιάδες φορές. Αλλά ευτυχώς δεν χρειάζεται να το κάνουμε αυτό. Μπορούμε να ζητήσουμε από την R να ρίξει τα ζάρια για εμάς, όχι μόνο μία αλλά πολλές φορές. Αν αφήσουμε το πρόγραμμά μας για προσομοιωμένες ρίψεις ζαριών να εκτελείται για πολύ χρόνο, μπορούμε να δούμε πώς θα μοιάζει τελικά η κατανομή του πληθυσμού.
Ας ξεκινήσουμε προγραμματίζοντας μια ΔΠΔ που θα παράγει τυχαία έναν ακέραιο αριθμό μεταξύ του 1 και του 6. Ουσιαστικά, αυτό είναι μία ρίψη ενός ζαριού: μια τυχαία διαδικασία που επιλέγει έναν από τους 6 πιθανούς αριθμούς σε ένα ζάρι. Για να προσομοιώσουμε αυτή τη διαδικασία στην R, μπορούμε να ξεκινήσουμε δημιουργώντας ένα διάνυσμα με τους αριθμούς 1 έως 6.
Όπως ισχύει για ένα πραγματικό ζάρι, το διάνυσμα dice_outcomes περιέχει κάθε αριθμό από το 1 έως το 6. Αν επιλέξουμε αριθμούς τυχαία από αυτό το διάνυσμα, μπορούμε να προσομοιώσουμε τη ΔΠΔ της ρίψης ζαριών. Για να προσομοιώσουμε μια μοναδική ρίψη ζαριού, μπορούμε να εκτελέσουμε τον παρακάτω κώδικα:
Αυτή η εντολή λέει στην R να επιλέξει τυχαία έναν από τους έξι αριθμούς στο διάνυσμα dice_outcomes. Αν εκτελέσουμε τη συνάρτηση sample(), θα επιστρέψει ένα διάνυσμα με μία μοναδική τιμή. Για παράδειγμα, το τρέξαμε μόλις τώρα και πήραμε το παρακάτω αποτέλεσμα. Όπως φαίνεται, το προσομοιωμένο μας ζάρι έφερε 2 αυτή τη φορά.
[1] 2
Δοκιμάστε να χρησιμοποιήσετε αυτή τη ΔΠΔ στον κώδικα που ακολουθεί.
Δοκιμάστε να εκτελέσετε τον κώδικα προσομοίωσης ρίψης ζαριού μερικές φορές. Γιατί βγάζει αυτούς τους συγκεκριμένους αριθμούς; Η απάντηση σε αυτή την ερώτηση θα ήταν, «Είναι απλώς τυχαιότητα.» Ακόμη και αν η προσομοιωμένη ΔΠΔ ρίψης ζαριού σας έδινε ένα εκπληκτικό μοτίβο (π.χ., πέντε 1 στη σειρά), η εξήγηση θα εξακολουθούσε να είναι, «Είναι απλώς τυχαιότητα.» Μπορούμε να το πούμε αυτό επειδή δημιουργήσαμε εμείς οι ίδιοι τη ΔΠΔ χρησιμοποιώντας την R και γνωρίζουμε ποια είναι!
Τι εννοούμε όμως όταν λέμε «τυχαιότητα»; Μια τυχαία διαδικασία είναι μια όπου τα μεμονωμένα γεγονότα είναι απρόβλεπτα, παρόλο που οι μακροπρόθεσμες πιθανότητες διαφορετικών γεγονότων είναι γνωστές. Στην περίπτωση των ζαριών, δεν μπορούμε να προβλέψουμε ποιος αριθμός θα βγει σε οποιαδήποτε συγκεκριμένη περίσταση. Ωστόσο, γνωρίζουμε ότι κάθε ένας από τους αριθμούς 1 έως 6 έχει ίση πιθανότητα να βγει μακροπρόθεσμα.
Το παρακάτω ραβδόγραμμα αναπαριστά αυτή την ιδέα με μια ομοιόμορφη κατανομή πιθανότητας. Η πιθανότητα να έρθει ένας συγκεκριμένος αριθμός θα ήταν 1/6 ή 0,167.
Θεωρητικά, αν τρέχαμε αυτή τη ΔΠΔ ρίψης ζαριού πολλές φορές (χιλιάδες!), θα καταλήγαμε με μια κατανομή πληθυσμού παρόμοια με το παραπάνω διάγραμμα.
(Σημειώστε ότι παρόλο που το διάγραμμα μοιάζει με ιστόγραμμα δεν είναι. Χρησιμοποιούμε την gf_bar() αντί της gf_histogram() επειδή τα αποτελέσματα της ρίψης ζαριού είναι κατηγορίες, όχι ποσότητες. Οι αριθμοί 1 έως 6 δεν είναι, σε αυτή την περίπτωση, τιμές κάποιας συνεχούς μεταβλητής αλλά απλώς τα ονόματα 6 πιθανών αποτελεσμάτων.)
4.11 Από τη ΔΠΔ στον Πληθυσμό και στο Δείγμα
Μια Μακροπρόθεσμη Εκτέλεση της ΔΠΔ μας
Τώρα που έχουμε γράψει κώδικα για να προσομοιώσουμε τη ΔΠΔ της ρίψης ζαριού μία φορά, μπορούμε να τον χρησιμοποιήσουμε για να ρίξουμε το ζάρι 10, 100, 1.000 ή ακόμη και 10.000 φορές. Εκ πρώτης όψεως, μπορεί να νομίζετε ότι θα μπορούσαμε απλώς να αλλάξουμε τον κώδικα για τη ρίψη ζαριού σε sample(dice_outcomes, 10) για να ρίχνει το ζάρι 10 φορές. Αλλά αυτό δεν θα λειτουργήσει.
Ο λόγος που δεν λειτουργεί είναι ότι έτσι ζητάμε από την R να επιλέξει τυχαία δείγμα 10 διαφορετικών αριθμών όταν υπάρχουν μόνο 6 αριθμοί στο διάνυσμα! Η συνάρτηση sample(), εξ ορισμού, κάνει δειγματοληψία χωρίς επανατοποθέτηση. Όταν επιλέγει έναν αριθμό, αυτός ο αριθμός δεν είναι πλέον διαθέσιμος (δηλαδή, δεν επιστρέφεται στο διάνυσμα) για να επιλεγεί ξανά. Μπορούμε να πούμε στην R να κάνει δειγματοληψία με επανατοποθέτηση προσθέτοντας την επιπλέον παράμετρο replace = TRUE ως εξής: sample(dice_outcomes, 10, replace = TRUE).
Δοκιμάστε να εκτελέσετε τον λανθασμένο κώδικα που δίνεται παρακάτω. Στη συνέχεια διορθώστε τον κώδικα για να κάνει δειγματοληψία με επανατοποθέτηση.
Έχουμε προσομοιώσει 10 ρίψεις ζαριού, αλλά αυτό δύσκολα θα μετρούσε ως η «μακροπρόθεσμη εκτέλεση» που απαιτείται για να προσεγγίσουμε έναν πληθυσμό. Στο παρακάτω πλαίσιο, επεξεργαστείτε τον κώδικα για να δημιουργήσετε 1.000 ρίψεις ζαριού και αποθηκεύστε το αποτέλεσμα σε ένα νέο διάνυσμα που ονομάζεται large_sample. Στη συνέχεια δημιουργήστε ένα ραβδόγραμμα της κατανομής των ρίψεων ζαριού στο διάνυσμα large_sample. Τι σχήμα περιμένετε να δείτε στο ραβδόγραμμα;
Αυτό το μεγαλύτερο δείγμα μοιάζει πολύ περισσότερο με αυτό που θα περιμέναμε να μοιάζει η κατανομή των ρίψεων ζαριού. Δοκιμάστε να προσομοιώσετε ένα ακόμη μεγαλύτερο δείγμα εκτελόντας τη ΔΠΔ σας 10.000 φορές. Όσο περισσότερες φορές εκτελέσουμε τη ΔΠΔ, τόσο περισσότερο αρχίζει να μοιάζει με αυτό που περιμένουμε να δούμε.
Όταν εκτελείτε μια ΔΠΔ (π.χ., δειγματοληψία με επανατοποθέτηση, ή επαναδειγματοληψία, από τους αριθμούς 1 έως 6) για μεγάλο αριθμό επαναλήψεων (π.χ., 10.000 φορές), καταλήγετε σε μια κατανομή που μπορούμε να αρχίσουμε να ονομάζουμε πληθυσμό. Αλλά ακόμη και αν ρίξετε το ζάρι μόνο μία φορά, η ΔΠΔ παραμένει η ίδια. Αυτός είναι ο λόγος που κάνουμε διάκριση μεταξύ του πληθυσμού και της ΔΠΔ.
Μεγάλα Δείγματα Έναντι Μικρών Δειγμάτων
Τα μεγάλα δείγματα είναι αρκετά καλά στο να αντιπροσωπεύουν μια κατανομή πληθυσμού και τη ΔΠΔ. Για παράδειγμα, είδαμε ότι μεγαλύτερα δείγματα, των 1.000 ή 10.000 ρίψεων ζαριού, αντιστοιχούν σε μια ομοιόμορφη κατανομή με κάθε αποτέλεσμα να είναι περίπου εξίσου πιθανό, ακριβώς όπως θα προβλέπαμε βάσει της κατανόησής μας για τη ΔΠΔ της ρίψης ενός ζαριού.
Αλλά τι γίνεται με τα μικρότερα δείγματα; Για πρακτικούς λόγους, συχνά έχουμε ένα μικρό δείγμα, ίσως μόνο 100 ή 24 ή 12 παρατηρήσεις. Πόσο καλά αντικατοπτρίζουν τα μικρά δείγματα την κατανομή του πληθυσμού;
Εξέταση της Μεταβλητότητας σε Μικρότερα Δείγματα
Ας χρησιμοποιήσουμε την τυχαία διαδικασία μας για να παράγουμε μικρότερα δείγματα ρίψεων ζαριού. Μπορούμε να κάνουμε δειγματοληψία με επανατοποθέτηση προσθέτοντας την παράμετρο replace = TRUE.
Ποια από τις παρακάτω γραμμές κώδικα θα κάνει δειγματοληψία με επανατοποθέτηση 100 φορές από το διάνυσμα dice_outcomes (το οποίο περιέχει τους αριθμούς 1 έως 6) και θα το αποθηκεύσει ως my_sample;
Επεξήγηση
Γ - my_sample <- sample(dice_outcomes, 100, replace = TRUE) είναι η μόνη σωστή απάντηση.
Γιατί η Γ είναι σωστή:
Για να κάνουμε δειγματοληψία με επανατοποθέτηση από ένα διάνυσμα με λιγότερα στοιχεία από όσα θέλουμε να επιλέξουμε, χρειαζόμαστε:
Τη συνάρτηση sample() - για τυχαία επιλογή στοιχείων
Το διάνυσμα προέλευσης (dice_outcomes) - από όπου θα επιλέξουμε
Τον αριθμό επιλογών (100) - πόσα στοιχεία θέλουμε
replace = TRUE - για να επιτρέψουμε την επαναχρησιμοποίηση των ίδιων στοιχείων
Ανάθεση στη μεταβλητήmy_sample - για αποθήκευση του αποτελέσματος
Γιατί οι άλλες επιλογές είναι λάθος:
Α - my_sample <- c(1:100): Δημιουργεί ένα διάνυσμα με τους αριθμούς 1 έως 100, όχι δειγματοληψία από τα αποτελέσματα ζαριού (1-6).
Β - my_sample <- sample(dice_outcomes, 100): Θα προσπαθήσει να επιλέξει 100 διαφορετικά στοιχεία από ένα διάνυσμα που έχει μόνο 6 στοιχεία. Αυτό θα δώσει σφάλμα επειδή δεν υπάρχουν αρκετά μοναδικά στοιχεία.
Δ - sample(dice_outcomes, 100): Εκτός από το πρόβλημα της μη επανατοποθέτησης, το αποτέλεσμα δεν αποθηκεύεται σε μεταβλητή.
Βασική αρχή: Όταν θέλουμε να κάνουμε δειγματοληψία περισσότερων στοιχείων από όσα υπάρχουν στο αρχικό διάνυσμα, πρέπει να ορίσυμε την παράμετρο replace = TRUE για να επιτρέψουμε την επαναχρησιμοποίηση των ίδιων στοιχείων.
Χρησιμοποιήστε την sample() για να δημιουργήσετε ένα δείγμα 100 ρίψεων ζαριού. Γράψτε κώδικα για να δημιουργήσετε ένα ραβδόγραμμα με τα αποτελέσματα.
Παρακάτω βρίσκεται ένα από τα τυχαία δείγματα που δημιουργήσαμε. Το τυχαίο δείγμά σας θα φαίνεται διαφορετικό από το δικό μας, φυσικά, επειδή είναι τυχαίο! Παρατηρήστε ότι ούτε το δείγμα σας ούτε το δικό μας μοιάζει πολύ με την ομοιόμορφη κατανομή που θα περιμέναμε βάσει της γνώσης μας για τη ΔΠΔ.
Τώρα ας πάρουμε ένα ακόμη μικρότερο δείγμα μόλις 12 ρίψεων ζαριού. Τροποποιήστε τον παρακάτω κώδικα για να προσομοιώσετε 12 ρίψεις ζαριού και αποθηκεύστε το ως διάνυσμα που ονομάζεται my_sample. Πώς νομίζετε ότι θα μοιάζει η κατανομή αυτού του δείγματος; Πόσο κοντά θα είναι το σχήμα του στην ομοιόμορφη κατανομή που αναμέναμε;
Έχουμε αναπαραστήσει παραπάνω τρία διαφορετικά δείγματα 12 ρίψεων ζαριού. Παρατηρήστε ότι οι τυχαία δημιουργημένες κατανομές των δειγμάτων μας δεν είναι τέλεια ομοιόμορφες. Στην πραγματικότητα, μπορεί να μη φαίνονται καθόλου ομοιόμορφες! Μπορεί ακόμη να αναρωτιέστε, αν είναι αυτή πραγματικά μια τυχαία διαδικασία. Ακόμη και αν προσομοιώσετε 12 ρίψεις ζαριού μερικές ακόμη φορές (δοκιμάστε να πατήσετε Run Code μερικές φορές), οι περισσότερες από τις κατανομές δεν θα φαίνονται πολύ ομοιόμορφες.
Πιστεύετε ότι αυτά τα δείγματα δημιουργήθηκαν τυχαία από μια ομοιόμορφη ΔΠΔ (στην οποία κάθε ένας από τους αριθμούς 1 έως 6 είχε ίση πιθανότητα να επιλεγεί); Ή πιστεύετε ότι κάτι δεν πάει καλά με την προσομοίωσή μας; Εξηγήστε την απάντησή σας.
Η αλήθεια είναι ότι κάθε ένα από αυτά τα δείγματα δημιουργήθηκε από μια τυχαία διαδικασία παραγωγής δεδομένων: προσομοίωση ρίψεων ζαριού. Και παρόλο που γνωρίζουμε ότι αυτή η διαδικασία θα παρήγαγε μια ομοιόμορφη κατανομή πληθυσμού μακροπρόθεσμα, τα δείγματά μας των 12 ή των 100 ρίψεων συνήθως δε φαίνονται ομοιόμορφα.
Το σημαντικό που χρειάζεται να κατανοήσουμε είναι ότι οι δειγματικές κατανομές μπορεί να διαφέρουν, ακόμη και αρκετά, από την υποκείμενη κατανομή πληθυσμού από την οποία προέρχονται. Αυτό είναι που ονομάζουμε δειγματική μεταβλητότητα (η μεταβλητότητα από δείγμα σε δείγμα). Τα μικρά δείγματα (ακόμη και δείγματα μεγέθους 100 θεωρούνται «μικρά») δε θα μοιάζουν απαραίτητα με τον πληθυσμό από τον οποίο προέρχονται, ακόμη κι αν δημιουργήθηκαν από μια αμιγώς τυχαία διαδικασία.
4.12 Ερωτήσεις Επανάληψης Κεφαλαίου 4
Στις ερωτήσεις που ακολουθούν θα αναφερόμαστε σε ένα υποθετικό πλαίσιο δεδομένων που ονομάζεται GreekCities. Παρακάτω βλέπετε ένα τμήμα του πλαισίου δεδομένων καθώς και τους ορισμούς των μεταβλητών που περιλαμβάνει.
Education - Ποσοστό κατοίκων με τριτοβάθμια εκπαίδευση
Unemployment - Ποσοστό ανεργίας στην περιοχή
PhysicalActivity - Ποσοστό κατοίκων που έκαναν άσκηση τον τελευταίο μήνα
Smokers - Ποσοστό κατοίκων που καπνίζουν
1. Ποιες από τις παρακάτω μεταβλητές θα ήταν κατάλληλο να αναπαρασταθούν με ιστόγραμμα; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Όλες οι επιλογές (HouseholdIncome, IQ, Population, Education, Obese, και Smokers) είναι σωστές απαντήσεις.
Γιατί όλες αυτές οι μεταβλητές είναι κατάλληλες για ιστόγραμμα:
✓ HouseholdIncome (Μέσο οικογενειακό εισόδημα): - Ποσοτική μεταβλητή - μετρά εισόδημα σε ευρώ - Συνεχής κλίμακα - μπορεί να πάρει πολλές διαφορετικές αριθμητικές τιμές
✓ IQ (Δείκτης νοημοσύνης): - Ποσοτική μεταβλητή - αριθμητική μέτρηση νοημοσύνης - Συνεχής κλίμακα - συνήθως από 50-150
✓ Population (Πληθυσμός σε χιλιάδες): - Ποσοτική μεταβλητή - μετρά αριθμό κατοίκων - Συνεχής κλίμακα - μπορεί να πάρει πολλές τιμές
✓ Education (Ποσοστό με τριτοβάθμια εκπαίδευση): - Ποσοτική μεταβλητή - μετρά ποσοστό σε αριθμητική κλίμακα - Συνεχής κλίμακα - μπορεί να πάρει τιμές από 0% έως 100%
✓ Obese (Ποσοστό παχυσαρκίας): - Ποσοτική μεταβλητή - μετρά ποσοστό σε αριθμητική κλίμακα - Συνεχής κλίμακα - τιμές από 0% έως 100%
✓ Smokers (Ποσοστό καπνιστών): - Ποσοτική μεταβλητή - μετρά ποσοστό σε αριθμητική κλίμακα - Συνεχής κλίμακα - τιμές από 0% έως 100%
Όλες οι μεταβλητές εκτός από την City και Region είναι ποσοτικές και επομένως κατάλληλες για ιστόγραμμα. Οι City και Region είναι οι μόνες ποιοτικές μεταβλητές που θα ήταν κατάλληλο να αναπαρασταθούν με ραβδόγραμμα.
2. Ποια εντολή θα οπτικοποιούσε την κατανομή της μεταβλητής Smokers;
Επεξήγηση
gf_histogram(~ Smokers, data = GreekCities) είναι η σωστή απάντηση.
Γιατί αυτή η επιλογή είναι σωστή:
Η σωστή σύνταξη για τη δημιουργία ιστογράμματος με το πακέτο ggformula είναι:
gf_histogram(~ μεταβλητή, data = πλαίσιο_δεδομένων)
Στοιχεία της σωστής σύνταξης: 1. gf_histogram - η σωστή συνάρτηση για ιστογράμματα 2. Παρενθέσεις () - απαραίτητες για κλήση συνάρτησης 3. ~ Smokers - το σύμβολο tilde (~) ακολουθούμενο από το όνομα της μεταβλητής 4. data = GreekCities - καθορίζει το πλαίσιο δεδομένων που περιέχει τη μεταβλητή
Γιατί οι άλλες επιλογές είναι λάθος:
Β - gf_histogram ~ Smokers: - Δεν έχει παρενθέσεις () για κλήση συνάρτησης - Δεν καθορίζεται το πλαίσιο δεδομένων - Η σύνταξη είναι εσφαλμένη
Γ - histogram(Smokers, GreekCities): - Η histogram() δεν είναι η σωστή συνάρτηση στο ggformula - Λάθος σύνταξη παραμέτρων - Δεν χρησιμοποιεί το σύμβολο ~
Δ - histogram ~ Smokers: - Η histogram() δεν είναι η σωστή συνάρτηση - Δεν έχει παρενθέσεις - Δεν καθορίζεται το πλαίσιο δεδομένων
Στο πακέτο ggformula, οι συναρτήσεις για διαγράμματα ακολουθούν τη μορφή: gf_τύπος_διαγράμματος(~ μεταβλητή, data = δεδομένα)
3. Τι θα κάνει ο παρακάτω κώδικας, πέρα από τη δημιουργία του ιστογράμματος;
gf_histogram(~ Education, data = GreekCities) %>%gf_labs(title ="Κατανομή Κατοίκων με Τριτοβάθμια Εκπαίδευση", x ="Ποσοστό")
Επεξήγηση
Θα δώσει στο ιστόγραμμα έναν τίτλο και θα ορίσει και τον τίτλο του άξονα x είναι η σωστή απάντηση.
Ανάλυση του κώδικα:
Ο κώδικας χρησιμοποιεί τη συνάρτηση gf_labs() για να προσθέσει τίτλους στο διάγραμμα:
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Χρώμα κόκκινο: Ο κώδικας δεν περιέχει καμία παράμετρο για χρώμα (όπως fill ή color). Η gf_labs() προσθέτει μόνο τίτλους, όχι χρώματα.
Β - Καθορισμός πλαισίου δεδομένων και μεταβλητής: Αυτό γίνεται ήδη στην πρώτη γραμμή του κώδικα (gf_histogram(~ Education, data = GreekCities)). Η gf_labs() δεν καθορίζει τα δεδομένα ή τις μεταβλητές.
Δ - Δημιουργία νέου πλαισίου δεδομένων: Η gf_labs() δεν δημιουργεί δεδομένα. Προσθέτει μόνο τίτλους σε υπάρχον διάγραμμα.
Τι κάνει η gf_labs(): Η συνάρτηση gf_labs() (labels) χρησιμοποιείται για να προσθέσει ή να τροποποιήσει: - title - τίτλος διαγράμματος - x - τίτλο άξονα x - y - τίτλο άξονα y - subtitle - υπότιτλος διαγράμματος - caption - λεζάντα διαγράμματος
4. Ας υποθέσουμε ότι δημιουργήσατε ένα ιστόγραμμα της μεταβλητής PhysicalActivity. Ενώ θέλατε να το ορίσετε να έχει 15 διαστήματα τιμών (bins), κατά λάθος το ορίσατε να έχει 5 διαστήματα τιμών. Ποια θα είναι η διαφορά στο αποτέλεσμα σε σχέση με αυτό που αρχικά επιθυμούσατε;
Επεξήγηση
Το λανθασμένο ιστόγραμμα θα έχει λιγότερες λεπτομέρειες από αυτό που θα θέλατε να είχατε δημιουργήσει αρχικά είναι η σωστή απάντηση.
Πώς επηρεάζει ο αριθμός των διαστημάτων (bins) ένα ιστόγραμμα:
Με 5 διαστήματα (αυτό που δημιουργήσατε κατά λάθος): - Λιγότερες ράβδοι - μόνο 5 ράβδοι στο ιστόγραμμα - Ευρύτερα διαστήματα τιμών - κάθε ράβδος καλύπτει μεγαλύτερο εύρος τιμών - Λιγότερες λεπτομέρειες - χάνονται οι λεπτομέρειες της δομής της κατανομής - Γενική εικόνα - βλέπετε μόνο ένα γενικό σχήμα της κατανομής
Με 15 διαστήματα (αυτό που θέλατε): - Περισσότερες ράβδοι - 15 ράβδοι στο ιστόγραμμα - Στενότερα διαστήματα τιμών - κάθε ράβδος καλύπτει μικρότερο εύρος τιμών - Περισσότερες λεπτομέρειες - μπορείτε να δείτε λεπτομέρειες της κατανομής - Λεπτομερής εικόνα - καλύτερη ανάλυση του σχήματος της κατανομής
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Περισσότερες ράβδους: Λάθος! Με 5 διαστήματα τιμών θα έχετε λιγότερες ράβδους (5) από ό,τι με 15.
Β - Ελλείπουσες τιμές: Λάθος! Όλα τα δεδομένα θα εξακολουθούν να εμφανίζονται, απλώς θα είναι ομαδοποιημένα σε λιγότερα διαστήματα τιμών.
Γ - Καμία διαφορά λόγω ίδιου μεγέθους δείγματος: Λάθος! Ο αριθμός των παρατηρήσεων (N) δεν επηρεάζει τον τρόπο που ο αριθμός των διαστημάτων τιμών αλλάζει την εμφάνιση του ιστογράμματος.
Βασική αρχή: Λιγότερα διαστήματα τιμών = λιγότερες λεπτομέρειες, περισσότερα διαστήματα τιμών = περισσότερες λεπτομέρειες
5. Ας υποθέσουμε ότι κατά τη διαδικασία μιας προκαταρτικής διερεύνησης των δεδομένων σας δημιουργήσατε αρκετά ιστογράμματα. Ανάμεσά τους είναι ένα ιστόγραμμα απόλυτης συχνότητας της μεταβλητής PhysicalActivity και ένα ιστόγραμμα σχετικής συχνότητας της ίδιας μεταβλητής. Αν χρησιμοποιήσατε τις προεπιλεγμένες τιμές παραμέτρων για καθένα από αυτά τα ιστογράμματα, τι θα έχουν κοινό; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Α (Ίδιος αριθμός ράβδων), Γ (Ίδια μεταβλητή), και Δ (Ίδιο σχήμα κατανομής) είναι οι σωστές απαντήσεις.
Τι είναι κοινό μεταξύ των δύο ιστογραμμάτων:
✓ Α - Ίδιος αριθμός ράβδων: - Και τα δύο ιστογράμματα χρησιμοποιούν τις ίδιες προεπιλεγμένες τιμές παραμέτρων - Η R θα δημιουργήσει τον ίδιο αριθμό διαστημάτων τιμών (συνήθως περίπου 30) για την ίδια μεταβλητή - Τα όρια των διαστημάτων θα είναι ίδια
✓ Γ - Ίδια μεταβλητή: - Και τα δύο εμφανίζουν την κατανομή της μεταβλητής PhysicalActivity - Χρησιμοποιούν ακριβώς τα ίδια δεδομένα - Η μόνη διαφορά είναι η κλίμακα του άξονα y
✓ Δ - Ίδιο σχήμα κατανομής: - Το σχήμα της κατανομής (συμμετρικό, ασύμμετρο, μονοκόρυφο κ.λπ.) παραμένει το ίδιο - Οι σχετικές αναλογίες μεταξύ των ράβδων είναι ίδιες - Αλλάζει μόνο η κλίμακα του άξονα y, όχι το σχήμα της κατανομής
Γιατί το Β είναι λάθος:
✗ Β - Ίδια κλίμακα άξονα y: - Άξονας x: Θα έχει τον ίδιο τίτλο (PhysicalActivity) και στα δύο - Άξονας y: Θα έχει διαφορετικό τίτλο και κλίμακα: - Ιστόγραμμα απόλυτης συχνότητας: Συχνότητα ή “Count” ή “Frequency” - Ιστόγραμμα σχετικής συχνότητας: Σχετική Συχνότητα ή Πυκνότητα πιθανότητας ή “Relative Frequency”, “Proportion”, ή “Density”
Βασική αρχή: Τα ιστογράμματα απόλυτης και σχετικής συχνότητας είναι ουσιαστικά το ίδιο διάγραμμα με διαφορετικό τίτλο και κλίμακα στον άξονα y.
6. Ποια εντολή από τις παρακάτω θα δημιουργούσε ένα ιστόγραμμα σχετικής συχνότητας της μεταβλητής PhysicalActivity;
Επεξήγηση
gf_dhistogram(~ PhysicalActivity, data = GreekCities) είναι η σωστή απάντηση.
Γιατί αυτή η επιλογή είναι σωστή:
Στο πακέτο ggformula, η συνάρτηση gf_dhistogram() δημιουργεί ιστογράμματα πυκνότητας πιθανότητας (density histograms), τα οποία εμφανίζουν σχετικές συχνότητες αντί για απόλυτες συχνότητες.
Τι σημαίνει το ‘d’ στη gf_dhistogram(): - ‘d’ = density (πυκνότητα πιθανότητας) - Ο άξονας y δείχνει πυκνότητα αντί για απόλυτο πλήθος παρατηρήσεων - Η συνολική περιοχή κάτω από το ιστόγραμμα ισούται με 1 - Αυτό επιτρέπει εύκολη σύγκριση μεταξύ δειγμάτων διαφορετικού μεγέθους
Γιατί οι άλλες επιλογές είναι λάθος:
Α - gf_densityhist(): Αυτή η συνάρτηση δεν υπάρχει στο πακέτο ggformula. Είναι εσφαλμένο όνομα συνάρτησης.
Β - gf_histogram(): Αυτή δημιουργεί ιστόγραμμα απόλυτης συχνότητας (frequency histogram), όχι σχετικής συχνότητας. Ο άξονας y δείχνει το πλήθος των παρατηρήσεων.
Δ - gf_relativehist(): Αυτή η συνάρτηση δεν υπάρχει στο πακέτο ggformula. Είναι εσφαλμένο όνομα συνάρτησης.
7. Γιατί πρέπει να εξετάσετε ένα ιστόγραμμα μιας μεταβλητής πριν κάνετε άλλες στατιστικές αναλύσεις; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Α (Σχήμα κατανομής) και Β (Εντοπισμός σφαλμάτων) είναι οι σωστές απαντήσεις.
Γιατί είναι σημαντική η εξέταση ιστογραμμάτων πριν από άλλες αναλύσεις:
✓ Α - Εξέταση σχήματος κατανομής: - Κατανόηση της φύσης των δεδομένων: Βλέπετε αν η κατανομή είναι κανονική, ασύμμετρη, δικόρυφη κ.λπ. - Επιλογή κατάλληλων στατιστικών μεθόδων: Πολλές στατιστικές τεχνικές προϋποθέτουν συγκεκριμένα σχήματα κατανομής - Εντοπισμός μοτίβων: Μπορείτε να δείτε αν τα δεδομένα συμπεριφέρονται όπως αναμένεται
✓ Β - Εντοπισμός σφαλμάτων δεδομένων: - Ακραίες τιμές: Μπορείτε να εντοπίσετε τιμές που δεν έχουν νόημα (π.χ. ηλικία 200 ετών) - Σφάλματα καταχώρησης: Λάθη στην πληκτρολόγηση (π.χ. 1.500 αντί για 15.00) - Προβλήματα μονάδων: Δεδομένα σε λάθος μονάδες μέτρησης (π.χ. χιλιοστά αντί για εκατοστά) - Ελλείπουσες τιμές: Κενά ή παράξενα μοτίβα στα δεδομένα
Γιατί οι άλλη επιλογή είναι λάθος:
✗ Γ - Απαίτηση της R: - Η R δεν έχει καμία τεχνική απαίτηση για δημιουργία ιστογράμματος πριν από άλλες συναρτήσεις - Μπορείτε να εκτελέσετε οποιαδήποτε στατιστική ανάλυση χωρίς να έχετε δει πρώτα ιστόγραμμα - Η ανάγκη για τη δημιουργία ιστογραμμάτων είναι αναλυτική, όχι τεχνική
Βασική αρχή της διερευνητικής ανάλυσης: Όπως τονίζεται στο κείμενο: “Εάν δεν είχαμε εξετάσει την κατανομή της μεταβλητής, δεν θα είχαμε εντοπίσει αυτή την ανωμαλία και θα μπορούσαμε να καταλήξουμε σε εσφαλμένα συμπεράσματα.”
Τα ιστογράμματα είναι το πρώτο βήμα για την κατανόηση των δεδομένων σας!
8. Αποφασίζετε να φτιάξετε ένα ιστόγραμμα σχετικής συχνότητας για τη μεταβλητή PhysicalActivity και έχετε προσθέσει στον κώδικά σας την ακόλουθη γραμμή:%>% gf_density()
Τι θα δείτε τώρα που δεν βλεπατε προηγουμένως;
Επεξήγηση
Μια εξομαλυμένη καμπύλη πυκνότητας πιθανότητας που επικαλύπτει τις ράβδους σας είναι η σωστή απάντηση.
Τι κάνει η gf_density() όταν προστίθεται με %>%:
Όταν χρησιμοποιείτε τον τελεστή διοχέτευσης %>% για να προσθέσετε την gf_density() σε ένα υπάρχον ιστόγραμμα, η συνάρτηση:
Προσθέτει μια καμπύλη πάνω από το υπάρχον ιστόγραμμα
Δεν αντικαθιστά τις ράβδους του ιστογράμματος
Δημιουργεί μια εξομαλυμένη αναπαράσταση της κατανομής
Βοηθά στην οπτικοποίηση του γενικού σχήματος της κατανομής
Πώς φαίνεται το αποτέλεσμα: Θα δείτε το ιστόγραμμά σας (ράβδους) με μια εξομαλυμένη, συνεχή γραμμή να περνάει πάνω από αυτό, δείχνοντας το γενικό σχήμα της κατανομής.
Γιατί οι άλλες επιλογές είναι λάθος:
Β - Μήνυμα σφάλματος: Η gf_density() δεν απαιτεί υποχρεωτικά τον ορισμό παραμέτρων. Μπορεί να λειτουργήσει χωρίς παραμέτρους, χρησιμοποιώντας τις ίδιες μεταβλητές από την προηγούμενη συνάρτηση.
Γ - Άξονας y με πυκνότητα πιθανότητας: Αν είχατε ήδη ένα ιστόγραμμα σχετικής συχνότητας (π.χ. από την gf_dhistogram()), ο άξονας y θα έδειχνε ήδη πυκνότητα πιθανότητας. Η gf_density() δεν αλλάζει τον άξονα y.
Δ - Καμπύλη αντί για ράβδους: Η gf_density()προσθέτει μια καμπύλη, δεν αντικαθιστά τις ράβδους. Οι ράβδοι του ιστογράμματος θα παραμείνουν ορατές.
Πρακτική χρησιμότητα: Η συνδυασμένη εμφάνιση ιστογράμματος και καμπύλης πυκνότητας πιθανότητας είναι χρήσιμη επειδή: - Το ιστόγραμμα δείχνει τα πραγματικά δεδομένα - Η καμπύλη πυκνότητας δείχνει το εξομαλυμένο σχήμα της κατανομής - Μαζί βοηθούν στην καλύτερη κατανόηση του μοτίβου των δεδομένων
9. Ας υποθέσουμε ότι το ιστόγραμμα της μεταβλητής PhysicalActivity έχει ασυμμετρία στα δεξιά. Δηλαδή, η λεπτή, μακρύτερη ουρά βρίσκεται στα δεξιά της κατανομής. Τι μπορεί να σημαίνει αυτό;
Επεξήγηση
Ο πληθυσμός στις περισσότερες περιοχές είναι καθιστικός είναι η σωστή απάντηση.
Τι σημαίνει ασυμμετρία στα δεξιά:
Όταν μια κατανομή έχει ασυμμετρία στα δεξιά:
Ο κύριος όγκος των δεδομένων βρίσκεται στις χαμηλότερες τιμές (αριστερά)
Μια μακριά ουρά εκτείνεται προς τις υψηλότερες τιμές (δεξιά)
Οι περισσότερες παρατηρήσεις συγκεντρώνονται στο κάτω άκρο της κλίμακας
Λίγες παρατηρήσεις βρίσκονται στο πάνω άκρο της κλίμακας
Εφαρμογή στη φυσική δραστηριότητα:
Αν το ιστόγραμμα της PhysicalActivity (ποσοστό κατοίκων που συμμετείχαν σε φυσική δραστηριότητα) έχει ασυμμετρία στα δεξιά:
Οι περισσότερες περιοχές έχουν χαμηλά ποσοστά φυσικής δραστηριότητας
Λίγες περιοχές έχουν υψηλά ποσοστά φυσικής δραστηριότητας
Αυτό σημαίνει ότι στις περισσότερες περιοχές ο πληθυσμός είναι λιγότερο δραστήριος
Γιατί οι άλλες επιλογές είναι λάθος:
Α & Δ - “Πολύ δραστήριος”: Αυτό θα ίσχυε αν η κατανομή ήταν ασύμμετρη στα αριστερά, όπου οι περισσότερες περιοχές θα είχαν υψηλά ποσοστά φυσικής δραστηριότητας.
Γ - “Συνολικά καθιστικός”: Αυτό είναι υπερβολική γενίκευση. Η δεξιά ασυμμετρία δείχνει ότι οι περισσότερες περιοχές έχουν χαμηλά επίπεδα, όχι απαραίτητα ότι ο συνολικός πληθυσμός είναι καθιστικός (επειδή οι μεγάλες περιοχές μπορεί να έχουν διαφορετικά επίπεδα).
Βασική αρχή ερμηνείας ασυμμετρίας: - Ασυμμετρία στα δεξιά → Οι περισσότερες τιμές είναι χαμηλές - Ασυμμετρία στα αριστερά → Οι περισσότερες τιμές είναι υψηλές - Συμμετρική κατανομή → Οι τιμές κατανέμονται ομοιόμορφα γύρω από το κέντρο
10. Το παρακάτω ιστόγραμμα δείχνει την κατανομή του πληθυσμού σε εκατομμύρια στις περιοχές μιας χώρας. Ποιες από τις ακόλουθες δηλώσεις είναι αληθείς βάσει του ιστογράμματος; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Β (Λίγες περιοχές με υψηλούς πληθυσμούς) και Γ (Δεξιά ασυμμετρία) είναι οι σωστές απαντήσεις.
Ανάλυση των χαρακτηριστικών του ιστογράμματος:
✓ Β - Μόνο λίγες περιοχές έχουν πολύ υψηλούς πληθυσμούς: - Το ιστόγραμμα δείχνει ότι οι περισσότερες περιοχές έχουν χαμηλό πληθυσμό - Υπάρχουν μόνο λίγες περιοχές στη δεξιά ουρά με υψηλούς πληθυσμούς ✓ Γ - Το σχήμα της κατανομής έχει ασυμμετρία στα δεξιά: - Κύριος όγκος των δεδομένων στις χαμηλές τιμές (αριστερά) - Μακριά ουρά που εκτείνεται προς τις υψηλές τιμές (δεξιά) - Χαρακτηριστικό σχήμα δεξιάς ασυμμετρίας
Γιατί οι άλλες επιλογές είναι λάθος:
✗ Α - Πληθυσμός περίπου 0: - Αυτό είναι παραπλανητικό και τεχνικά λάθος - Οι περισσότερες περιοχές έχουν χαμηλό πληθυσμό (0.2-0.8 εκατομμύρια), όχι μηδενικό - Καμία περιοχή δεν έχει μηδενικό πληθυσμό - Η συγκέντρωση στο αριστερό άκρο δεν σημαίνει “περίπου 0”
✗ Δ - Μόνο μικρές περιοχές στη δεξιά ουρά: - Αυτό είναι αντίθετο από την πραγματικότητα - Στη δεξιά ουρά βρίσκονται οι μεγαλύτερες περιοχές (με περισσότερους κατοίκους) - Οι μικρές περιοχές βρίσκονται στην αριστερή πλευρά της κατανομής - Η ερώτηση μπορεί να δημιουργεί σύγχυση μεταξύ “γεωγραφικού μεγέθους” και “πληθυσμού”
Σημαντική διευκρίνιση για την επιλογή Δ: Η μεταβλητή στο ιστόγραμμα μετρά πληθυσμό, όχι γεωγραφική έκταση. Στη δεξιά ουρά βρίσκονται οι περιοχές με τον μεγαλύτερο πληθυσμό, όχι οι γεωγραφικά μικρότερες.
11. Ας υποθέσουμε ότι δημιουργείτε ένα ιστόγραμμα της μεταβλητής Unemployment και διαπιστώνετε ότι η κατανομή μοιάζει να είναι περίπου κανονική. Ποιες από τις ακόλουθες δηλώσεις είναι πιθανώς αληθείς; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Όλες οι επιλογές (Α, Β, Γ, Δ) είναι σωστές όταν μια κατανομή είναι “περίπου κανονική”.
Χαρακτηριστικά κανονικής κατανομής:
✓ Α - Σχήμα καμπάνας: - Η κανονική κατανομή έχει το χαρακτηριστικό σχήμα καμπάνας - Ψηλή στο κέντρο και σταδιακά μειώνεται προς τα άκρα - Οι ουρές εκτείνονται συμμετρικά και προς τις δύο κατευθύνσεις
✓ Β - Μονοκόρυφη: - Έχει μία ξεκάθαρη κορυφή στο κέντρο της κατανομής - Δεν υπάρχουν πολλαπλές κορυφές - Η μέγιστη συχνότητα εμφανίζεται σε μία συγκεκριμένη περιοχή
✓ Γ - Συγκέντρωση στο κέντρο: - Οι περισσότερες παρατηρήσεις συγκεντρώνονται γύρω από τη μέση τιμή - Λιγότερες παρατηρήσεις βρίσκονται στα άκρα της κλίμακας
✓ Δ - Περίπου συμμετρική: - Η αριστερή και δεξιά πλευρά της κατανομής είναι περίπου ίσες - Η διάμεσος και ο μέσος όρος βρίσκονται περίπου στην ίδια θέση - Δεν υπάρχει σημαντική ασυμμετρία προς καμία κατεύθυνση
Γιατί όλα αυτά ισχύουν για την κανονική κατανομή:
Η κανονική κατανομή είναι ένα θεωρητικό μοντέλο που συνδυάζει όλα αυτά τα χαρακτηριστικά: - Μαθηματικός ορισμός: Συμμετρική, μονοκόρυφη, σχήμα καμπάνας - Κεντρική τάση: 68% των τιμών εντός 1 τυπικής απόκλισης από το κέντρο - Πρακτική εφαρμογή: Πολλές μεταβλητές (όπως π.χ. το IQ) αναμένεται να ακολουθούν προσεγγιστικά αυτό το μοτίβο
12. Στο πλαίσιο δεδομένων GreekCities, η μεταβλητή PhysicalActivity λήφθηκε μέσω έρευνας σε τυχαίο δείγμα κατοίκων σε κάθε πόλη, ρωτώντας τους αν είχαν συμμετάσχει σε φυσική δραστηριότητα τον τελευταίο μήνα. Δεδομένης αυτής της πληροφορίας, ερμηνεύστε το 62.1 στον παρακάτω πίνακα.
City PhysicalActivity
1 Αθήνα 58.3
2 Θεσσαλονίκη 62.1
3 Πάτρα 68.7
Επεξήγηση
Το 62.1 τοις εκατό των κατοίκων της Θεσσαλονίκης που συμμετείχαν στην έρευνα δήλωσαν ότι συμμετείχαν σε φυσική δραστηριότητα εκείνο το μήνα είναι η σωστή απάντηση.
Γιατί αυτή η ερμηνεία είναι σωστή:
Βασικά στοιχεία της έρευνας: - Μέθοδος: Έρευνα σε τυχαίο δείγμα κατοίκων - Ερώτηση: Αν είχαν συμμετάσχει σε φυσική δραστηριότητα τον τελευταίο μήνα - Αποτέλεσμα: Ποσοστό θετικών απαντήσεων
Κρίσιμες διευκρινίσεις: 1. “Συμμετείχαν στην έρευνα” - Τα δεδομένα προέρχονται από δείγμα, όχι από όλους τους κατοίκους 2. “Δήλωσαν” - Βασίζεται σε αυτό-αναφερόμενες απαντήσεις, όχι σε άμεση παρατήρηση 3. “Εκείνο το μήνα” - Αναφέρεται στη συγκεκριμένη χρονική περίοδο της έρευνας
Γιατί οι άλλες επιλογές είναι λάθος:
Α - “62.1 φορές το χρόνο”: - Λάθος μονάδα μέτρησης - το 62.1 είναι ποσοστό, όχι συχνότητα - Η ερώτηση αφορούσε συμμετοχή ναι/όχι, όχι πόσες φορές
Β - “62.1% όλων των κατοίκων της Θεσσαλονίκης”: - Αγνοεί ότι τα δεδομένα προέρχονται από δείγμα, όχι από όλο τον πληθυσμό - Παρόλο που το δείγμα μπορεί να είναι αντιπροσωπευτικό, έχουμε δεδομένα μόνο από το δείγμα
Δ - “Συμμετείχαν σε αγώνα δρόμου”: - Εντελώς λάθος ερμηνεία - η ερώτηση αφορούσε οποιαδήποτε φυσική δραστηριότητα, όχι συγκεκριμένα αγώνα δρόμου - Αλλάζει ουσιαστικά το νόημα της μεταβλητής
13. Στο πλαίσιο δεδομένων GreekCities, η μεταβλητή PhysicalActivity λήφθηκε μέσω έρευνας σε τυχαίο δείγμα κατοίκων της κάθε πόλης, ρωτώντας τους αν είχαν συμμετάσχει σε φυσική δραστηριότητα τον τελευταίο μήνα. Ποιος είναι ο στόχος μας στην ανάλυση τέτοιων δεδομένων; (Υπάρχουν περισσότερες από μία σωστές απαντήσεις.)
Επεξήγηση
Γ (Κατανόηση τυχαίων διαδικασιών) και Δ (Κατανόηση πληθυσμού) είναι οι σωστές απαντήσεις.
Βασικοί στόχοι της στατιστικής ανάλυσης:
✓ Γ - Κατανόηση των διαδικασιών που παρήγαγαν τη μεταβλητότητα στο δείγμα: - Διαδικασία Παραγωγής Δεδομένων (ΔΠΔ): Ποιες διαδικασίες προκαλούν τις διαφορές μεταξύ των πόλεων; - Αιτιακοί παράγοντες: Τι επηρεάζει τα επίπεδα φυσικής δραστηριότητας (κλίμα, αστικοποίηση, πολιτικές υγείας); - Κατανόηση μοτίβων: Γιατί κάποιες περιοχές έχουν υψηλότερα ή χαμηλότερα επίπεδα;
✓ Δ - Κατανόηση του πληθυσμού: - Γενίκευση: Χρήση του δείγματος για εκτιμήσεις σχετικά με ολόκληρο τον πληθυσμό της Ελλάδας - Εκτιμήσεις παραμέτρων: Ποια είναι τα πραγματικά επίπεδα φυσικής δραστηριότητας; - Συγκρίσεις περιοχών: Ποιες περιοχές έχουν όντως υψηλότερα επίπεδα δραστηριότητας;
Γιατί οι άλλες επιλογές είναι λάθος:
✗ Α - Κατανόηση κάθε ατόμου στο δείγμα: - Η στατιστική ανάλυση εστιάζει σε μοτίβα και τάσεις, όχι σε μεμονωμένα άτομα - Τα δεδομένα είναι συγκεντρωτικά (ποσοστά ανά περιοχή), όχι ατομικά - Δεν έχουμε πληροφορίες για συγκεκριμένα άτομα στο δείγμα
✗ Β - Αποκλειστικά για το συγκεκριμένο δείγμα: - Αυτό θα ήταν περιγραφική στατιστική χωρίς γενικεύσεις - Δεν θα είχε πρακτική αξία για λήψη αποφάσεων ή κατανόηση του φαινομένου - Η λέξη “αποκλειστικά” είναι το κλειδί - περιορίζει υπερβολικά τον στόχο
Σχέση μεταξύ των δύο σωστών στόχων: - Βραχυπρόθεσμα: Κατανοούμε τον πληθυσμό (τι συμβαίνει) - Μακροπρόθεσμα: Κατανοούμε τις διαδικασίες (γιατί συμβαίνει) - Πιθανός τελικός σκοπός: Βελτίωση της δημόσιας υγείας μέσω στοχευμένων παρεμβάσεων
Πρακτική εφαρμογή: Αυτή η ανάλυση θα μπορούσε να βοηθήσει στη διαμόρφωση πολιτικών για την προώθηση της φυσικής δραστηριότητας, τον εντοπισμό περιοχών που χρειάζονται στήριξη, ή την κατανόηση των παραγόντων που συμβάλλουν σε υγιεινούς τρόπους ζωής.
Αν μια άλλη ομάδα ερευνητών χρησιμοποιούσε ακριβώς το ίδιο πρωτόκολλο για τη διεξαγωγή έρευνας σε τυχαίο δείγμα κατοίκων της κάθε πόλης και ρωτούσε για τη φυσική τους δραστηριότητα, θα έπαιρνε τις ίδιες τιμές για τη μεταβλητή PhysicalActivity όπως φαίνονται στο πλαίσιο δεδομένων GreekCities; Αν ναι, γιατί; Αν όχι, γιατί όχι;
15. Αν θέλατε να πάρετε τη σύνοψη των πέντε αριθμών για τη μεταβλητή PhysicalActivity, ποιον κώδικα θα εκτελούσατε;
Επεξήγηση
favstats(~ PhysicalActivity, data = GreekCities) είναι η σωστή απάντηση.
Γιατί αυτή η επιλογή είναι σωστή:
Η συνάρτηση favstats() (“favorite statistics”) από το πακέτο mosaic παρέχει μια περιεκτική σύνοψη που περιλαμβάνει:
Τη σύνοψη των πέντε αριθμών: - min - Ελάχιστη τιμή (Q0) - Q1 - Πρώτο τεταρτημόριο (25ο εκατοστημόριο) - median - Διάμεσος (Q2, 50ο εκατοστημόριο) - Q3 - Τρίτο τεταρτημόριο (75ο εκατοστημόριο) - max - Μέγιστη τιμή (Q4)
Επιπλέον στατιστικά: - mean - Μέσος όρος - sd - Τυπική απόκλιση - n - Αριθμός παρατηρήσεων - missing - Αριθμός ελλειπουσών τιμών
Γιατί οι άλλες επιλογές είναι λάθος:
Α - sort(GreekCities, PhysicalActivity): - Η sort() ταξινομεί δεδομένα, δεν υπολογίζει στατιστικά - Λάθος σύνταξη - δεν είναι σωστός τρόπος να ταξινομήσετε ένα data frame - Δεν παράγει τη σύνοψη των πέντε αριθμών
Γ - make five num summary(GreekCities.PhysicalActivity): - Αυτή η συνάρτηση δεν υπάρχει στην R - Λάθος σύνταξη (κενά στο όνομα συνάρτησης, τελεία αντί για $) - Εσφαλμένη αναφορά στη μεταβλητή
Δ - gf_histogram(GreekCities$PhysicalActivity): - Δημιουργεί ιστόγραμμα, όχι αριθμητική σύνοψη - Οπτική αναπαράσταση, όχι υπολογισμός στατιστικών - Δεν παρέχει τους ακριβείς αριθμούς της σύνοψης
Εναλλακτικές μέθοδοι: Αν δεν είχατε το πακέτο mosaic, θα μπορούσατε να χρησιμοποιήσετε: - summary(GreekCities$PhysicalActivity) - βασική συνάρτηση της R - quantile(GreekCities$PhysicalActivity) - για τα τεταρτημόρια - fivenum(GreekCities$PhysicalActivity) - βασική R για τους πέντε αριθμούς
Η favstats() είναι η πιο περιεκτική και εύκολη επιλογή.
16. Αν θέλατε να δείτε την κατανομή για τη μεταβλητή Education (ποσοστό κατοίκων με τριτοβάθμια εκπαίδευση), και εκτελέσετε τον ακόλουθο κώδικα, τι θα ήταν λάθος στη σύνταξη;gf_histogram(~ Education, data = GreekCities, bins = 10)
Επεξήγηση
Τίποτα είναι η σωστή απάντηση.
Γιατί ο κώδικας είναι απολύτως σωστός:
Ο κώδικας gf_histogram(~ Education, data = GreekCities, bins = 10) είναι γραμμένος σωστά και θα λειτουργήσει χωρίς προβλήματα:
Ανάλυση κάθε μέρους: - gf_histogram: Σωστή συνάρτηση από το πακέτο ggformula για δημιουργία ιστογραμμάτων - ~ Education: Σωστή σύνταξη με το tilde (~) για καθορισμό της μεταβλητής στον άξονα x - data = GreekCities: Σωστός καθορισμός του πλαισίου δεδομένων - bins = 10: Έγκυρη παράμετρος που καθορίζει τον αριθμό των διαστημάτων τιμών στο ιστόγραμμα
Γιατί οι άλλες επιλογές είναι λάθος:
Β - “Το ~ είναι περιττό”: Λάθος! - Το σύμβολο ~ είναι υποχρεωτικό στη σύνταξη του ggformula - Χωρίς το ~, ο κώδικας θα δώσει σφάλμα - Το ~ υποδηλώνει τη σύνταξη: “y ~ x” ή στην περίπτωση ιστογράμματος “~ x”
Γ - “Το gf_ είναι περιττό”: Λάθος! - Το gf_ είναι απαραίτητο μέρος του ονόματος της συνάρτησης - Οι συναρτήσεις του πακέτου ggformula ξεκινούν με gf_ (graphics formula) - Χωρίς το gf_, η συνάρτηση δεν θα αναγνωριστεί
Δ - “bins = 10 θα επιστρέψει σφάλμα”: Λάθος! - Η παράμετρος bins είναι έγκυρη και χρήσιμη - Καθορίζει τον αριθμό των διαστημάτων τιμών (bins) στο ιστόγραμμα - Το 10 είναι μια λογική τιμή για τον αριθμό των bins
Τι θα κάνει ο κώδικας: Θα δημιουργήσει ένα ιστόγραμμα της μεταβλητής Education με 10 διαστήματα τιμών, δείχνοντας την κατανομή των ποσοστών κατοίκων με τριτοβάθμια εκπαίδευση στις διάφορες περιοχές.
Μια ομάδα ερευνητών μελέτησε τα οφέλη της άσκησης στην υγεία. Ανάμεσα στις πολλές πιθανές μεταβλητές αποτελέσματος, μία από αυτές που μελέτησαν ήταν και ο αριθμός των επισκέψεων σε γιατρό κατά τη διάρκεια μιας περιόδου 90 ημερών. Θα τους συμβουλεύατε να αφαιρέσουν τις ακραίες τιμές από αυτή τη μεταβλητή από το δείγμα τους; Αν ναι, γιατί; Αν όχι, γιατί όχι;
18. Η μεταβλητή Unemployment είναι ποσοτική. Δείχνει το ποσοστό ανεργίας σε κάθε πόλη. Ποιο είναι το πιο κατάλληλο διάγραμμα για να αναπαρασταθούν αυτά τα δεδομένα;
Επεξήγηση
Το Ιστόγραμμα είναι η σωστή απάντηση.
Γιατί το ιστόγραμμα είναι κατάλληλο:
Η μεταβλητή Unemployment είναι ποσοτική (συνεχείς) που καταγράφει ποσοστό: - Μπορεί να πάρει τιμές από 0% έως 100% - Οι τιμές είναι συνεχείς
Χαρακτηριστικά ιστογράμματος για ποσοτικές μεταβλητές: - Συνεχή διαστήματα τιμών (bins): Ομαδοποιεί τις τιμές σε εύρη (π.χ. 10-15%, 15-20%) - Συνεχείς ράβδοι: Δεν υπάρχουν κενά μεταξύ των ράβδων, δείχνοντας τη συνέχεια - Σχήμα κατανομής: Δείχνει πώς κατανέμονται οι τιμές της ανεργίας - Κέντρο και διασπορά: Βοηθά να δούμε τυπικά επίπεδα ανεργίας και τυχόν εξαιρέσεις
Γιατί το ραβδόγραμμα δεν είναι κατάλληλο:
Τα ραβδογράμματα χρησιμοποιούνται για κατηγορικές (ποιοτικές) μεταβλητές: - Διακριτές κατηγορίες: Όπως ονόματα, χρώματα, κόμματα - Κενά μεταξύ ράβδων: Δείχνουν ότι οι κατηγορίες είναι ξεχωριστές - Χωρίς φυσική σειρά: Οι κατηγορίες δεν έχουν αριθμητική σχέση
Προβλήματα αν χρησιμοποιούσαμε ραβδόγραμμα: - Θα χάσουμε την αίσθηση της συνέχειας των ποσοστών ανεργίας - Δεν θα φαίνεται το σχήμα της κατανομής - Θα είναι δύσκολο να εντοπίσουμε μοτίβα στα δεδομένα
Γιατί οι άλλες επιλογές είναι λάθος:
Β - Ραβδόγραμμα: Λάθος, γιατί τα ραβδογράμματα είναι για ποιοτικές μεταβλητές.
Γ - Εξίσου κατάλληλα: Λάθος, γιατί τα ιστογράμματα είναι ειδικά σχεδιασμένα για ποσοτικές μεταβλητές.
Δ - Κανένα δεν είναι κατάλληλο: Λάθος, γιατί τα ιστογράμματα είναι βασικό διάγραμμα για ποσοτικές μεταβλητές.
19. Ποια από τις παρακάτω εντολές σας βοηθά να εντοπίσετε γρήγορα τον αριθμό των πόλεων με υψηλά επίπεδα ανεργίας (>20%) και τον αριθμό των πόλεων με χαμηλά επίπεδα ανεργίας (≤20%);
Επεξήγηση
table(GreekCities$Unemployment > 20) είναι η σωστή απάντηση.
Καταμέτρηση κατηγοριών: Μετράει πόσες φορές εμφανίζεται κάθε κατηγορία
Λογικές συνθήκες: Μπορεί να χρησιμοποιήσει συνθήκες όπως Unemployment > 20
Γρήγορη σύνοψη: Παρέχει άμεσα τα αποτελέσματα σε μορφή πίνακα
Αναμενόμενο αποτέλεσμα:
FALSE TRUE
37 13
(όπου FALSE = ανεργία ≤20%, TRUE = ανεργία >20%)
Γιατί οι άλλες επιλογές είναι λάθος:
Α - unemployment_levels(~ Unemployment, data = GreekCities): - Η συνάρτηση unemployment_levels()δεν υπάρχει στην R ή στα βασικά πακέτα - Εσφαλμένο όνομα συνάρτησης - Θα δώσει σφάλμα “function not found”
Β - gf_boxplot(~ Unemployment, data = GreekCities): - Τα boxplot δείχνουν την κατανομή μιας ποσοτικής μεταβλητής - Δεν δίνουν αριθμητικά αποτελέσματα καταμέτρησης - Είναι διάγραμμα, δεν δείχνει καταμέτρηση
Γ - str(~ Unemployment, data = GreekCities): - Η str() δείχνει τη δομή ενός αντικειμένου, όχι καταμέτρηση - Λάθος σύνταξη για τη str() (δεν χρησιμοποιεί formula syntax με ~) - Δεν θα δώσει καταμέτρηση κατηγοριών
Εναλλακτικές μέθοδοι: Άλλοι τρόποι για την ίδια πληροφορία: - table(GreekCities$Unemployment > 20) - βασική συνάρτηση της R - sum(GreekCities$Unemployment > 20) - για πλήθος πόλεων με υψηλή ανεργία - GreekCities %>% count(Unemployment > 20) - με το πακέτο dplyr
20. Αν σας ενδιέφεραν οι αναλογίες αντί για τις απόλυτες συχνότητες, ποια συνάρτηση θα χρησιμοποιούσατε με τον παραπάνω κώδικα;
Β - percentage.table(): - Αυτή η συνάρτηση δεν υπάρχει στην βασική έκδοση της R - Εσφαλμένο όνομα συνάρτησης
Γ - relative.freq(): - Αυτή η συνάρτηση δεν υπάρχει στην βασική έκδοση της R - Εσφαλμένο όνομα συνάρτησης
Δ - proportion.table(): - Αυτή η συνάρτηση δεν υπάρχει στην βασική έκδοση της R - Εσφαλμένο όνομα συνάρτησης (η σωστή είναι prop.table)
Επιπλέον χρήσιμες επιλογές:
# Για ποσοστά (επί τοις εκατό)prop.table(table(GreekCities$Unemployment >20)) *100# Για στρογγυλοποίησηround(prop.table(table(GreekCities$Unemployment >20)), 3)
Βασική αρχή: Η prop.table() είναι βασική συνάρτηση της R για μετατροπή απόλυτων συχνοτήτων σε αναλογίες.
Στο πλαίσιο δεδομένων GreekCities, η μεταβλητή PhysicalActivity λήφθηκε μέσω έρευνας σε τυχαίο δείγμα κατοίκων σε κάθε πόλη, ρωτώντας τους αν είχαν συμμετάσχει σε φυσική δραστηριότητα τον τελευταίο μήνα. Στην Θεσσαλονίκη, το 65.2 τοις εκατό των ερωτηθέντων απάντησε θετικά σε αυτή την ερώτηση. Δεν γνωρίζουμε πόσοι ερωτηθέντες συμμετείχαν. Σε ποια περίπτωση θα περιμένατε ότι η πραγματική αναλογία στον πληθυσμό θα ήταν παρόμοια με αυτή στο δείγμα: (α) αν είχατε ένα μικρό δείγμα ερωτηθέντων, ή (β) αν είχατε ένα μεγάλο δείγμα ερωτηθέντων; Γιατί;
Δίνεται ξανά ένα τμήμα του πλαισίου δεδομένων GreekCities:
Education - Ποσοστό κατοίκων με τριτοβάθμια εκπαίδευση
Unemployment - Ποσοστό ανεργίας στην περιοχή
PhysicalActivity - Ποσοστό κατοίκων που έκαναν άσκηση τον τελευταίο μήνα
Smokers - Ποσοστό κατοίκων που καπνίζουν
22. Δημιουργήστε ένα ιστόγραμμα της μεταβλητής Smokers, χωρίς να καθορίσετε συγκεκριμένο αριθμό διαστημάτων τιμών (bins) ή συγκεκριμένο εύρος διαστήματος. Πού περίπου βρίσκεται η κορυφή του ιστογράμματος;
Επεξήγηση
29 είναι η σωστή απάντηση.
Πώς να δημιουργήσετε το ιστόγραμμα:
gf_histogram(~ Smokers, data = GreekCities)
Ερμηνεία της κορυφής: Η κορυφή του ιστογράμματος (peak) βρίσκεται στο διάστημα που περιέχει τις περισσότερες παρατηρήσεις. Στα δεδομένα GreekCities, οι περισσότερες περιοχές έχουν ποσοστά καπνιστών γύρω στο 29%.
23. Τροποποιήστε το ιστόγραμμα της μεταβλητής Smokers έτσι ώστε να περιλαμβάνει μόνο 5 διαστήματα τιμών (bins). Εντοπίστε το διάστημα τιμών που αντιπροσωπεύει τις πόλεις με το υψηλότερο ποσοστό κατοίκων που καπνίζουν. Ποια περίπου τιμή βρίσκεται στο κέντρο του διαστήματος;
Επεξήγηση
30 είναι η σωστή απάντηση.
Πώς να δημιουργήσετε το ιστόγραμμα:
gf_histogram(~ Smokers, data = GreekCities, bins =5)
24. Πειραματιστείτε, χρησιμοποιώντας διαφορετικούς αριθμούς διαστημάτων (bins) στο ιστόγραμμά σας για τη μεταβλητή Smokers. Πώς μπορείτε να αλλάξετε τον αριθμό των διαστημάτων έτσι ώστε να μην εμφανίζονται κενά μεταξύ των ράβδων στο ιστόγραμμα;
Επεξήγηση
Με τον ορισμό ενός μικρού αριθμού διαστημάτων είναι η σωστή απάντηση.
Γιατί λιγότερα διαστήματα εξαλείφουν τα κενά:
Μεγαλύτερο εύρος διαστημάτων: - Όταν έχετε λίγα διαστήματα (π.χ. 3-5), κάθε διάστημα καλύπτει μεγαλύτερο εύρος τιμών - Περισσότερες παρατηρήσεις “χωρούν” σε κάθε διάστημα - Μειώνεται η πιθανότητα να υπάρχουν διαστήματα χωρίς παρατηρήσεις
Παράδειγμα:
# Με κενά (πολλά bins)gf_histogram(~ Smokers, data = GreekCities, bins =20)# Χωρίς κενά (λίγα bins)gf_histogram(~ Smokers, data = GreekCities, bins =3)
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Κενά εγγενή στα δεδομένα: - Λάθος! Τα κενά επηρεάζονται άμεσα από τον αριθμό των διαστημάτων - Ο αριθμός των bins καθορίζει πόσο “λεπτομερές” είναι το ιστόγραμμα
Β - Μεγάλος αριθμός διαστημάτων: - Αντίθετο αποτέλεσμα! Περισσότερα bins = περισσότερα κενά - Με πολλά στενά διαστήματα, πολλά θα είναι άδεια - Ειδικά σε μικρά δείγματα, πολλά bins δημιουργούν “τρύπες”
25. Αλλάξτε το ιστόγραμμα της μεταβλητής Smokers στο πλαίσιο δεδομένων GreekCities σε ιστόγραμμα πυκνότητας πιθανότητας χρησιμοποιώντας την gf_dhistogram() αντί της gf_histogram(). Τι άλλαξε;
Επεξήγηση
Ο άξονας y είναι η σωστή απάντηση.
Τι αλλάζει με το gf_dhistogram():
Άξονας Y - Κύρια αλλαγή: - gf_histogram(): Άξονας y δείχνει “Count” (πλήθος παρατηρήσεων) - gf_dhistogram(): Άξονας y δείχνει “Density” (πυκνότητα πιθανότητας)
Σύγκριση κωδίκων:
# Κανονικό ιστόγραμμα (συχνότητες)gf_histogram(~ Smokers, data = GreekCities)# Ιστόγραμμα πυκνότηταςgf_dhistogram(~ Smokers, data = GreekCities)
Τι σημαίνει πυκνότητα πιθανότητας: - Πυκνότητα = Συχνότητα / (Συνολικός αριθμός × Εύρος διαστήματος) - Η συνολική περιοχή κάτω από το ιστόγραμμα πυκνότητας πιθανότητας ισούται με 1 - Επιτρέπει σύγκριση μεταξύ δειγμάτων διαφορετικού μεγέθους
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Άξονας x: - Ο άξονας x παραμένει ίδιος (Smokers) - Δεν αλλάζουν οι τιμές ή η κλίμακα του x
Β - Σχήμα κατανομής: - Το σχήμα παραμένει το ίδιο - Αλλάζει μόνο η κλίμακα του άξονα y, όχι το σχήμα της κατανομής
Δ - Τίποτα: - Λάθος, γιατί ο άξονας y αλλάζει σημαντικά - Από απόλυτη συχνότητα δείχνει πυκνότητα πιθανότητας
Πότε να χρησιμοποιείτε κάθε τύπο: - gf_histogram(): Όταν θέλετε να δείτε πόσες παρατηρήσεις υπάρχουν - gf_dhistogram(): Όταν θέλετε να συγκρίνετε σχήματα κατανομών
26. Χρησιμοποιήστε τον τελεστή %>% για να προσθέσετε την gf_density() (εξομαλυμένη καμπύλη) στο ιστόγραμμα πυκνότητας πιθανότητας της μεταβλητής Smokers. Πώς μοιάζει αυτή η καμπύλη;
Επεξήγηση
Μονοκόρυφη είναι η σωστή απάντηση.
Πώς να δημιουργήσετε το διάγραμμα:
gf_dhistogram(~ Smokers, data = GreekCities) %>%gf_density()
Τι δείχνει η καμπύλη πυκνότητας πιθανότητας: Η καμπύλη εμφανίζει μία κύρια κορυφή γύρω στο 28–30%.
Τι σημαίνει μονοκόρυφη κατανομή: Υποδηλώνει ότι τα δεδομένα συγκεντρώνονται γύρω από μία κεντρική τιμή, χωρίς ξεκάθαρες διακριτές ομάδες.
Γιατί οι άλλες επιλογές είναι λάθος:
Β - Ομοιόμορφη: Θα ήταν επίπεδη κατανομή χωρίς κορυφές
Γ - Δικόρυφη: Θα υπήρχαν δύο ξεκάθαρες κορυφές
Δ - Έντονα Ασύμμετρη: Η κατανομή είναι σχετικά συμμετρική, όχι έντονα ασύμμετρη
Ορολογία κορυφών: - Μονοκόρυφη: Μία κορυφή - Δικόρυφη: Δύο κορυφές - Πολυκόρυφη: Περισσότερες από δύο κορυφές
27. Ποια είναι η διάμεσος του ποσοστού κατοίκων με τριτοβάθμια εκπαίδευση; (Η μεταβλητή ονομάζεται Education.)
Επεξήγηση
35.55 είναι η σωστή απάντηση.
Πώς να υπολογίσετε τη διάμεσο:
# Μέθοδος 1: Χρήση της median()median(GreekCities$Education)# Μέθοδος 2: Χρήση της favstats()favstats(~ Education, data = GreekCities)
Αποτελέσματα:
min Q1 median Q3 max mean sd n missing
29.4 33.425 35.55 38.575 45.6 36.178 3.724069 50 0
Τι είναι η διάμεσος: Η διάμεσος είναι η τιμή που χωρίζει το δείγμα στη μέση όταν οι παρατηρήσεις είναι ταξινομημένες σε αύξουσα σειρά.
Ερμηνεία: - Το 50% των πόλεων έχει ποσοστό τριτοβάθμιας εκπαίδευσης κάτω από 35.55% - Το άλλο 50% των πόλεων έχει ποσοστό πάνω από 35.55% - Η διάμεσος είναι λιγότερο ευαίσθητη σε ακραίες τιμές από το μέσο όρο (36.178)
Σύγκριση με άλλα στατιστικά: - Μέσος όρος: 36.178% (ελαφρώς υψηλότερος από τη διάμεσο) - Q1 (1ο τεταρτημόριο): 33.425% - Q3 (3ο τεταρτημόριο): 38.575% - Εύρος: 29.4% - 45.6%
Γιατί οι άλλες επιλογές είναι λάθος: - 38.6: Πολύ κοντά στο Q3, όχι στη διάμεσο - 33.4: Πολύ κοντά στο Q1, όχι στη διάμεσο - 40.0: Πάνω από το Q3, πολύ υψηλή για διάμεσο
28. Μεταξύ ποιων δύο τιμών βρίσκεται το μεσαίο 50% όλων των βαθμολογιών IQ στο πλαίσιο δεδομένων GreekCities;
Επεξήγηση
97.825 και 100.5 είναι η σωστή απάντηση.
Πώς να βρείτε το μεσαίο 50%:
# Χρήση της favstats() για να δείτε όλα τα τεταρτημόριαfavstats(~ IQ, data = GreekCities)# Ή μόνο τα τεταρτημόριαquantile(GreekCities$IQ, c(0.25, 0.75))
Αποτελέσματα από το R:
min Q1 median Q3 max mean sd n missing
96 97.825 98.9 100.5 102.8 99.264 1.741189 50 0
Τι σημαίνει μεσαίο 50%: Το μεσαίο 50% των παρατηρήσεων (γνωστό και ως ενδοτεταρτημοριακό εύρος) βρίσκεται μεταξύ: - Q1 (1ο τεταρτημόριο): 97.825 - Q3 (3ο τεταρτημόριο): 100.5
Ερμηνεία: - Το 25% των πόλεων έχει IQ κάτω από 97.825 - Το 25% των πόλεων έχει IQ πάνω από 100.5 - Το μεσαίο 50% των πόλεων έχει IQ μεταξύ 97.825 και 100.5
Γιατί οι άλλες επιλογές είναι λάθος: - 98.0 και 101.2: Δεν ταιριάζουν με τα πραγματικά Q1 και Q3 - 96.0 και 102.8: Αυτό είναι το συνολικό εύρος (min και max), όχι το μεσαίο 50% - 98.9 και 100.5: Το 98.9 είναι η διάμεσος, όχι το Q1
Έλεγχος για ακραίες τιμές: - Ελάχιστη τιμή: 29.4 (πάνω από το κάτω όριο 25.7) ✓ - Μέγιστη τιμή: 45.6 (κάτω από το πάνω όριο 46.3) ✓
Συμπέρασμα: Όλες οι τιμές βρίσκονται εντός των ορίων, οπότε δεν υπάρχουν ακραίες τιμές.
Γιατί οι άλλες επιλογές είναι λάθος: Όλες οι άλλες επιλογές υποθέτουν την ύπαρξη ακραίων τιμών, αλλά ο μαθηματικός υπολογισμός δείχνει ότι δεν υπάρχουν.
Ερμηνεία: Η απουσία ακραίων τιμών υποδηλώνει ότι τα ποσοστά τριτοβάθμιας εκπαίδευσης στις ελληνικές πόλεις είναι σχετικά ομοιογενή, χωρίς πόλεις με εξαιρετικά υψηλά ή χαμηλά επίπεδα.
30. Δημιουργήστε ένα ραβδόγραμμα για να αναπαραστήσετε τον αριθμό των περιοχών από κάθε περιφέρεια (καταγεγραμμένη στη μεταβλητή Region). Με βάση αυτό που βλέπετε, ποια από τις ακόλουθες δηλώσεις είναι αληθής;
Επεξήγηση
Το Νότιο Αιγαίο έχει τις περισσότερες περιοχές από όλες τις περιφέρειες είναι η σωστή απάντηση.
Ανάλυση της σωστής απάντησης: Το Νότιο Αιγαίο έχει 9 περιοχές (νησιά), που είναι ο μεγαλύτερος αριθμός από όλες τις περιφέρειες.
Γιατί οι άλλες επιλογές είναι λάθος: - Α: Η Κεντρική Μακεδονία έχει 7 πόλεις, όχι περισσότερες από 10 - Γ: Η Αττική έχει 2 πόλεις, η Θεσσαλία έχει 4 πόλεις (λιγότερες από τη Θεσσαλία) - Δ: Η Στερεά Ελλάδα έχει 1 πόλη, η Κρήτη έχει 2 πόλεις (διαφορετικός αριθμός)
31. Ποια αναλογία των πόλεων ανήκει στη Κεντρική Μακεδονία; (Υπόδειξη: χρησιμοποιήστε τη συνάρτηση prop.table().)
Επεξήγηση
.14 είναι η σωστή απάντηση.
Πώς να υπολογίσετε την αναλογία:
# Πρώτα δημιουργήστε τον πίνακα συχνοτήτωνregion_table <-table(GreekCities$Region)# Μετά υπολογίστε τις αναλογίεςprop.table(region_table)# Ή σε μία γραμμή:prop.table(table(GreekCities$Region))
Από τα δεδομένα που έχουμε: - Κεντρική Μακεδονία: 7 πόλεις - Συνολικές πόλεις: 50 πόλεις
Υπολογισμός αναλογίας: Αναλογία = Πόλεις Κεντρικής Μακεδονίας / Συνολικές πόλεις Αναλογία = 7 / 50 = 0.14
Ερμηνεία: Το 14% των πόλεων στο δείγμα ανήκει στη Κεντρική Μακεδονία.
Αναμενόμενο αποτέλεσμα από την prop.table(): Η εντολή θα επιστρέψει δεκαδικούς αριθμούς για κάθε περιφέρεια, και η τιμή για την Κ.Μακεδονία θα είναι 0.14.
Γιατί οι άλλες επιλογές είναι λάθος: - .18: Αντιστοιχεί σε 9/50, που είναι η αναλογία του Νοτίου Αιγαίου - .12: Αντιστοιχεί σε 6/50, που είναι η αναλογία της Πελοποννήσου - .16: Αντιστοιχεί σε 8/50, που δεν υπάρχει στα δεδομένα μας
Το πλαίσιο δεδομένων NutritionStudy περιέχει δεδομένα για 315 ασθενείς ενός νοσοκομείου που είχαν υποβληθεί σε αφαίρεση μη καρκινικού όγκου μέσω χειρουργικής επέμβασης. Περιλαμβάνει τις ακόλουθες μεταβλητές:
Age - Ηλικία του ατόμου (σε έτη)
Vitamin - Χρήση βιταμινών: 1=Τακτική, 2=Περιστασιακή, ή 3=Καμία
Calories - Αριθμός θερμίδων που καταναλώνονται ημερησίως
Fat - Γραμμάρια λίπους που καταναλώνονται ημερησίως
Fiber - Γραμμάρια φυτικών ινών που καταναλώνονται ημερησίως
Alcohol - Αριθμός αλκοολούχων ποτών που καταναλώνονται εβδομαδιαίως
Cholesterol - Χοληστερόλη που καταναλώνεται ημερησίως, σε mg
Gender - Κωδικοποιημένο ως Γυναίκα (Female) ή Άνδρας (Male)
EverSmoke - Κατάσταση καπνίσματος: Ποτέ (Never), Πρώην (Former), ή Τωρινός (Current)
Ακολουθεί το αποτέλεσμα από την εκτέλεση της head(NutritionStudy):
Age Vitamin Calories Fat Fiber Alcohol Cholesterol Gender EverSmoke
1 64 1 1298.8 57.0 6.3 0.0 170.3 Female Former
2 76 1 1032.5 50.1 15.8 0.0 75.8 Female Never
3 38 2 2372.3 83.6 19.1 14.1 257.9 Female Former
4 40 3 2449.5 97.5 26.5 0.5 332.6 Female Former
5 72 1 1952.1 82.6 16.2 0.0 170.8 Female Never
6 40 3 1366.9 56.0 9.6 1.3 154.6 Female Former
32. Το παραπάνω ιστόγραμμα δείχνει την κατανομή της μεταβλητής Alcohol μετά την αφαίρεση μιας ακραίας τιμής. Τι δείχνει ο άξονας y;
Επεξήγηση
Αριθμό ασθενών είναι η σωστή απάντηση.
Τι δείχνει ο άξονας y σε ένα ιστόγραμμα:
Σε ένα ιστόγραμμα, ο άξονας y δείχνει τη συχνότητα - δηλαδή πόσες παρατηρήσεις (σε αυτή την περίπτωση ασθενείς) ανήκουν σε κάθε διάστημα του άξονα x.
Στο συγκεκριμένο παράδειγμα: - Άξονας x: Αριθμός αλκοολούχων ποτών εβδομαδιαίως (Alcohol) - Άξονας y: Πόσοι ασθενείς καταναλώνουν αυτόν τον αριθμό ποτών εβδομαδιαίως
Παράδειγμα ερμηνείας: Αν μια ράβδος στο ιστόγραμμα έχει ύψος 25 για το διάστημα “2-4 ποτά εβδομαδιαίως”, αυτό σημαίνει ότι 25 ασθενείς καταναλώνουν 2-4 ποτά την εβδομάδα.
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Συνολικό αριθμό αλκοολούχων ποτών που καταναλώθηκαν: - Αυτό θα ήταν το άθροισμα όλων των ποτών, όχι η συχνότητα παρατηρήσεων - Δεν είναι αυτό που δείχνει ένα ιστόγραμμα
Β - Αριθμό μεταβλητών: - Οι μεταβλητές είναι τα χαρακτηριστικά που μετράμε (Age, Calories, κλπ.) - Αυτό δεν αλλάζει σε ένα ιστόγραμμα μιας μεταβλητής
Δ - Αριθμό αλκοολούχων ποτών που καταναλώνονται εβδομαδιαίως: - Αυτό είναι αυτό που δείχνει ο άξονας x, όχι ο άξονας y - Ο άξονας y δείχνει πόσοι άνθρωποι καταναλώνουν αυτόν τον αριθμό ποτών
Βασική αρχή ιστογραμμάτων: - Άξονας x: Η μεταβλητή που μελετάμε (στην περίπτωσή μας, ποτά/εβδομάδα) - Άξονας y: Συχνότητα (πόσες παρατηρήσεις/άτομα σε κάθε κατηγορία)
Σημείωση για την υγεία: Η ανάλυση της κατανάλωσης αλκοόλ σε ιατρικές μελέτες βοηθάει στην κατανόηση των παραγόντων κινδύνου και στη διαμόρφωση κατευθυντήριων οδηγιών για την υγεία.
33. Αν η κατανομή της μεταβλητής Fat ήταν περίπου συμμετρική και με σχήμα καμπάνας, τι θα σήμαινε αυτό;
Επεξήγηση
Η επικρατούσα τιμή, η διάμεσος και ο μέσος όρος θα ήταν περίπου ίσα είναι η σωστή απάντηση.
Βασικό χαρακτηριστικό συμμετρικής κατανομής με σχήμα καμπάνας:
Σε μια συμμετρική κατανομή με σχήμα καμπάνας, τα τρία μέτρα κεντρικής τάσης συμπίπτουν: - Μέσος όρος (mean): Το κέντρο - Διάμεσος (median): Η τιμή που χωρίζει τα δεδομένα στη μέση - Επικρατούσα τιμή (mode): Η πιο συχνή τιμή
Στο παράδειγμα της κατανάλωσης λίπους: Αν η μεταβλητή Fat έχει κατανομή με σχήμα καμπάνας, τότε: - Η πιο συνηθισμένη ποσότητα λίπους (επικρατούσα τιμή) = το μέσο όρο του δείγματος - Η διάμεσος της ποσότητα λίπους = το μέσο όρο του δείγματος
Γιατί οι άλλες επιλογές είναι λάθος:
Α - Η τυπική απόκλιση θα ήταν μηδέν: - Τυπική απόκλιση = 0 σημαίνει ότι όλες οι τιμές είναι ίδιες - Αυτό δεν δημιουργεί κατανομή με σχήμα καμπάνας, αλλά μια κάθετη γραμμή
Β - Το 75% θα κατανάλωνε περισσότερο από το μέσο όρο: - Σε συμμετρική κατανομή, ακριβώς το 50% είναι πάνω από το μέσο όρο - Το 75% πάνω από το μέσο όρο υποδηλώνει ασυμμετρία στα δεξιά
Δ - Όλες οι τιμές εντός δύο τυπικών αποκλίσεων: - Στην κανονική κατανομή, περίπου 95% (όχι 100%) βρίσκεται εντός ±2 τυπικών αποκλίσεων - Πάντα υπάρχει μικρό ποσοστό τιμών πέρα από αυτό το εύρος
34. Το πλαίσιο δεδομένων NutritionStudy περιλαμβάνει πληροφορίες για τον αριθμό Calories που κατανάλωναν οι ασθενείς ημερησίως. Δημιουργήστε ένα ιστόγραμμα της μεταβλητής Calories, χωρίς να καθορίσετε συγκεκριμένο αριθμό διαστημάτων (bins) ή συγκεκριμένο μέγεθος διαστήματος. Πού βρίσκεται η κορυφή του ιστογράμματος;
Επεξήγηση
Γύρω στις 1600 είναι η σωστή απάντηση.
Ανάλυση του ιστογράμματος: Από το παρεχόμενο ιστόγραμμα, η υψηλότερη ράβδος (κορυφή) βρίσκεται γύρω στις 1600 θερμίδες, όχι στις 2000 όπως θα περίμενε κανείς.
Χαρακτηριστικά της κατανομής: - Κύρια κορυφή: Γύρω στις 1600 θερμίδες (υψηλότερη συχνότητα ~67 ασθενείς) - Δεξιά ασυμμετρία: Η κατανομή έχει μακριά ουρά προς τα δεξιά - Ακραίες τιμές: Μερικοί ασθενείς με πολύ υψηλή θερμιδική πρόσληψη (4000+ και 6000+ θερμίδες)
Πώς να δημιουργήσετε το ιστόγραμμα:
gf_histogram(~ Calories, data = NutritionStudy)
Γιατί οι άλλες επιλογές είναι λάθος: - 2000 θερμίδες: Αυτή η περιοχή έχει χαμηλότερη συχνότητα από την κύρια κορυφή - 2200 θερμίδες: Ακόμη χαμηλότερη συχνότητα - 1200 θερμίδες: Πολύ αριστερά από την κύρια κορυφή
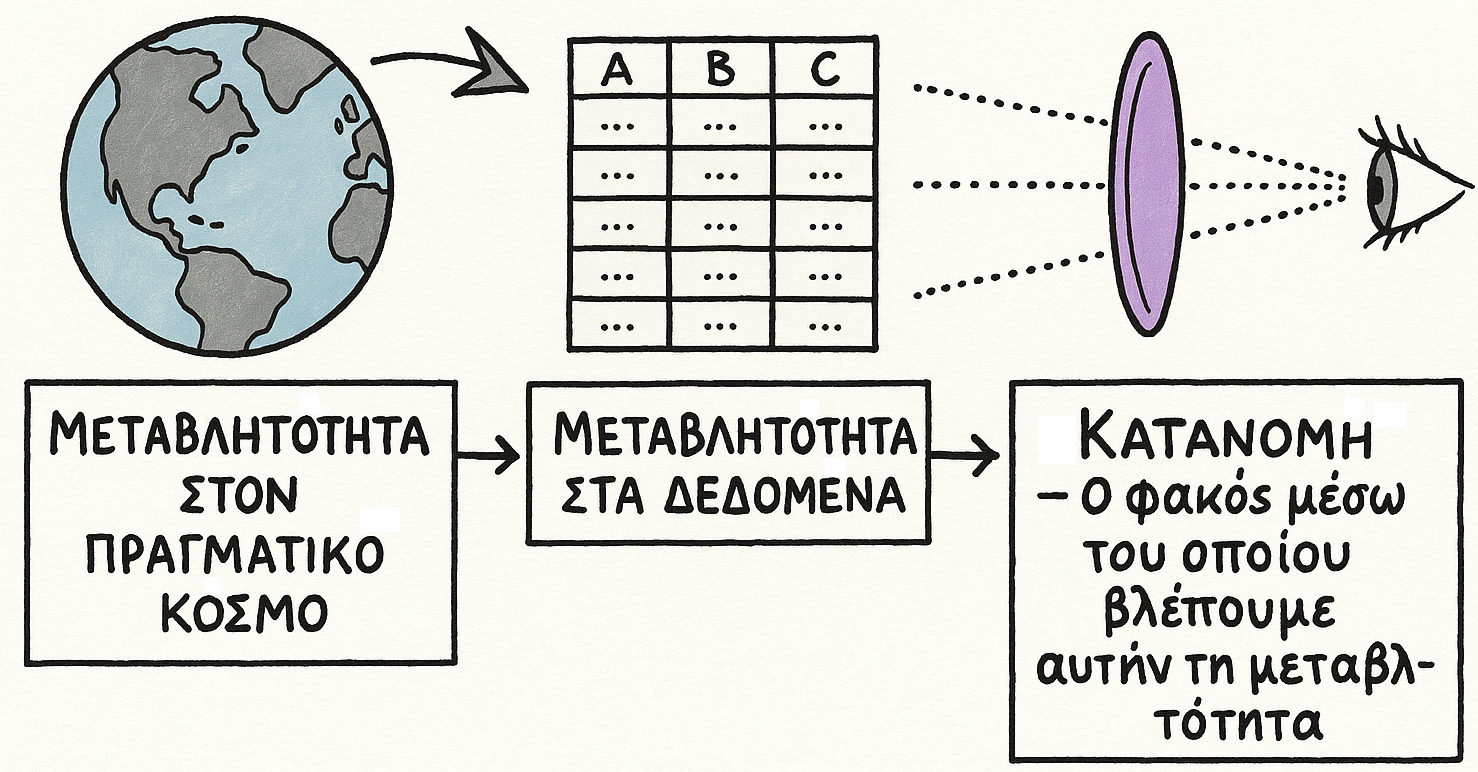
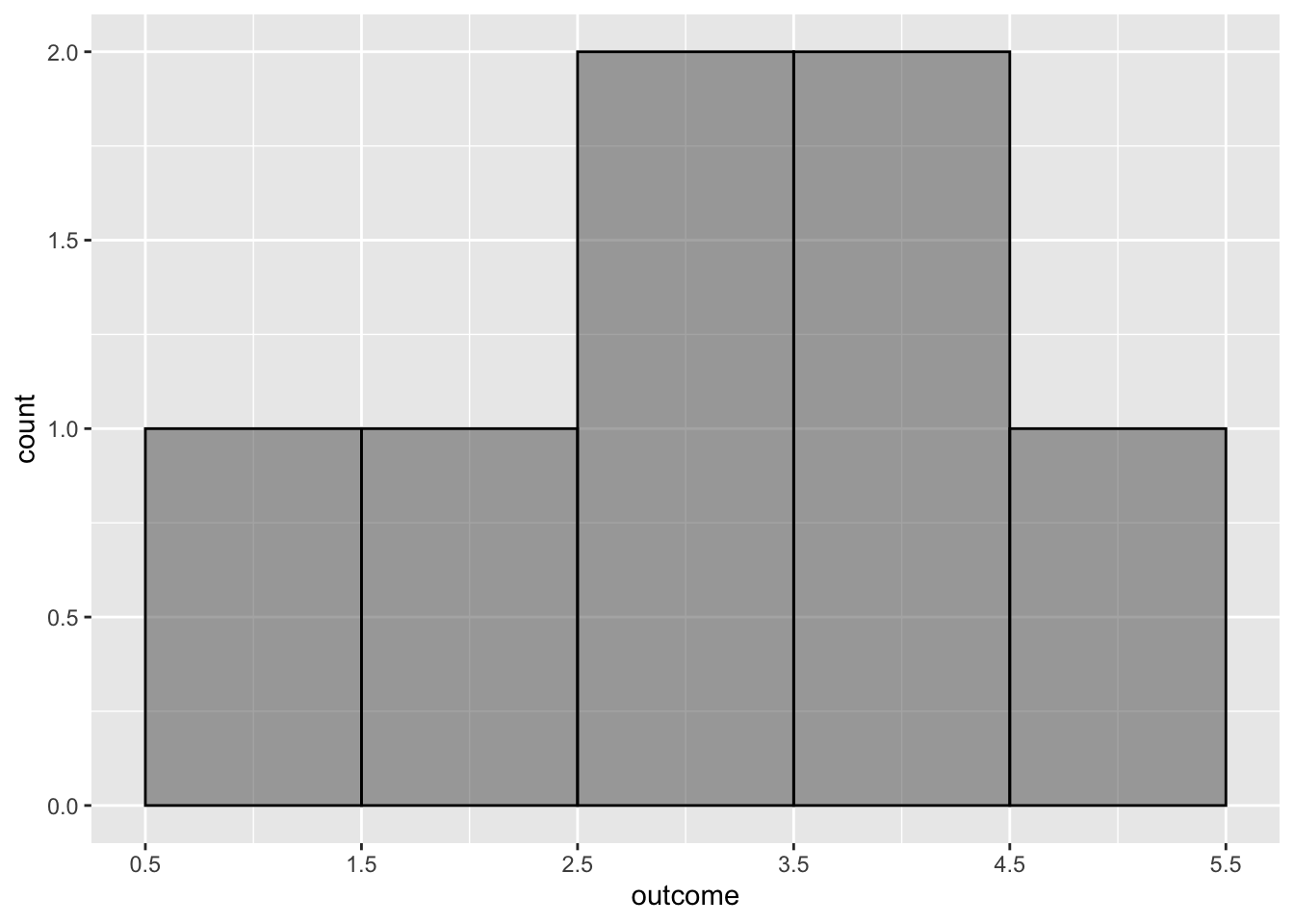
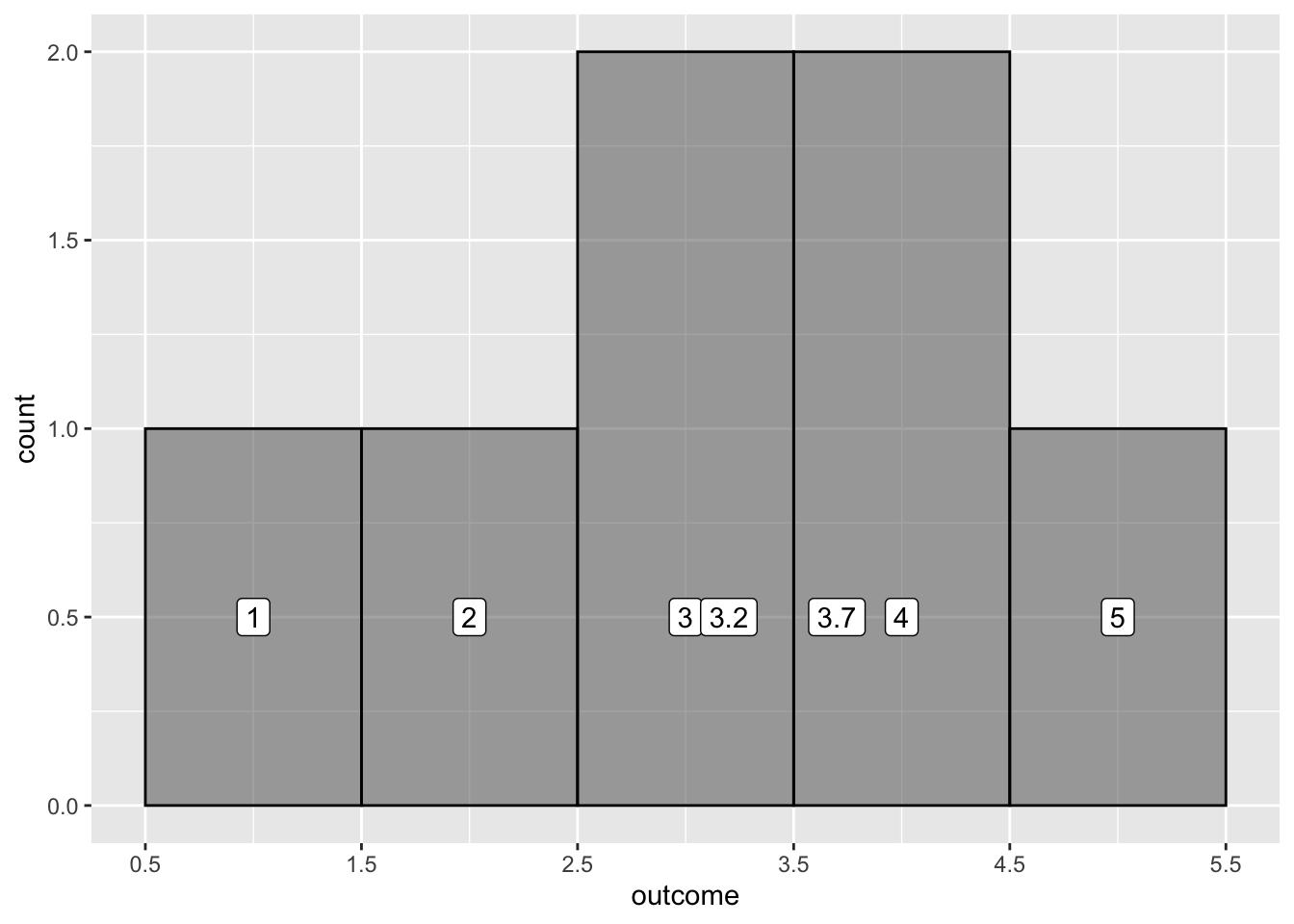
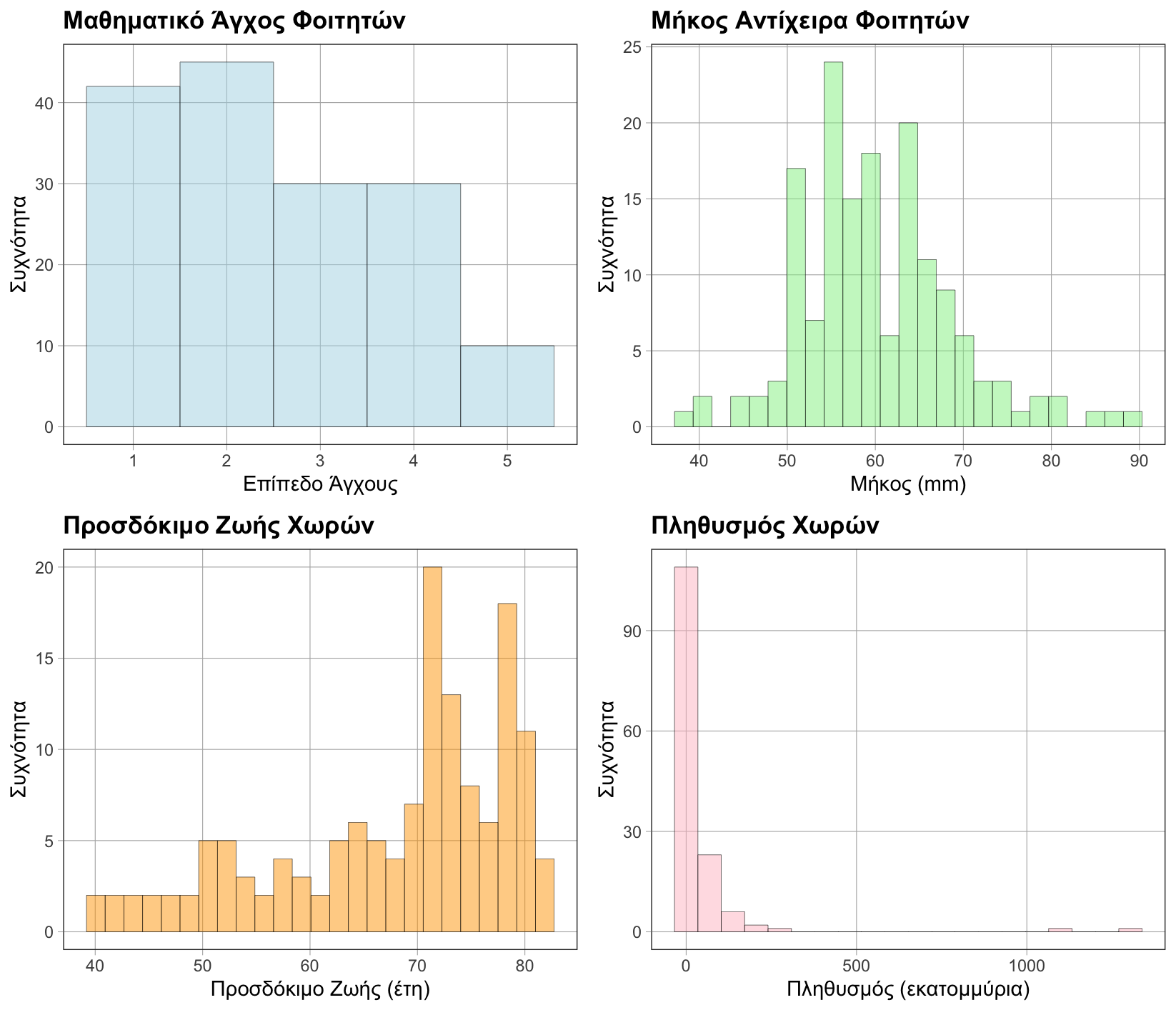
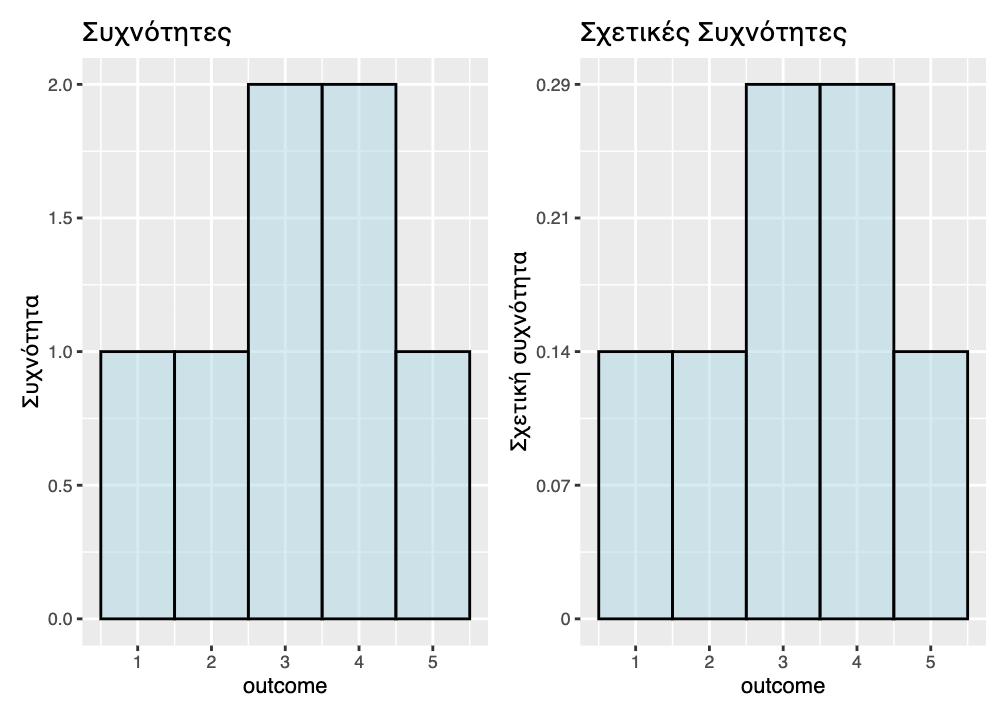
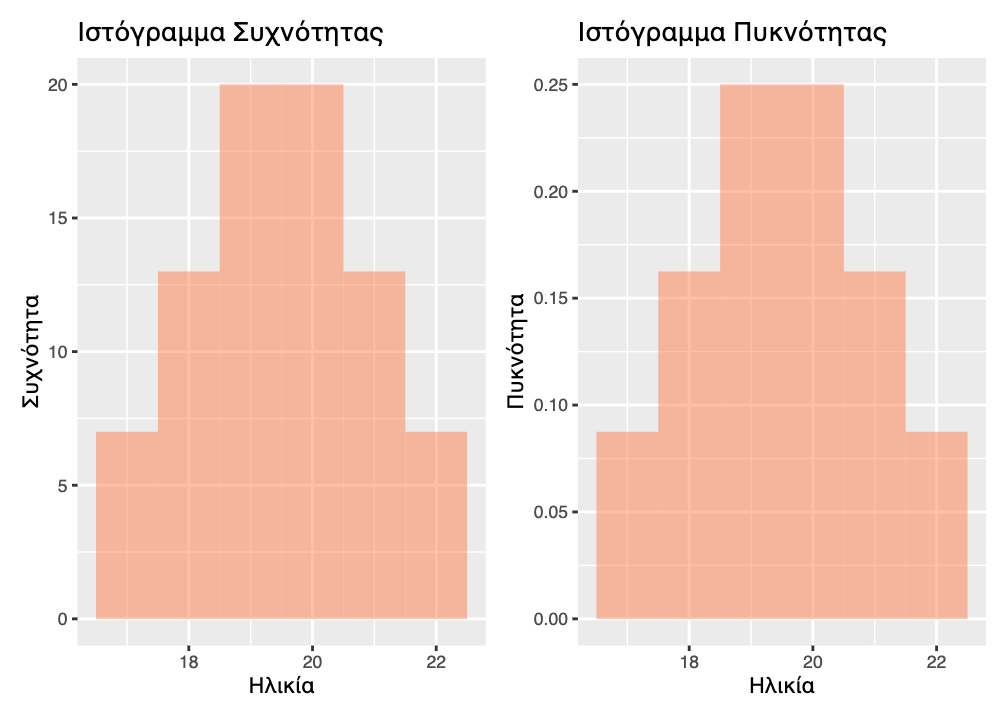
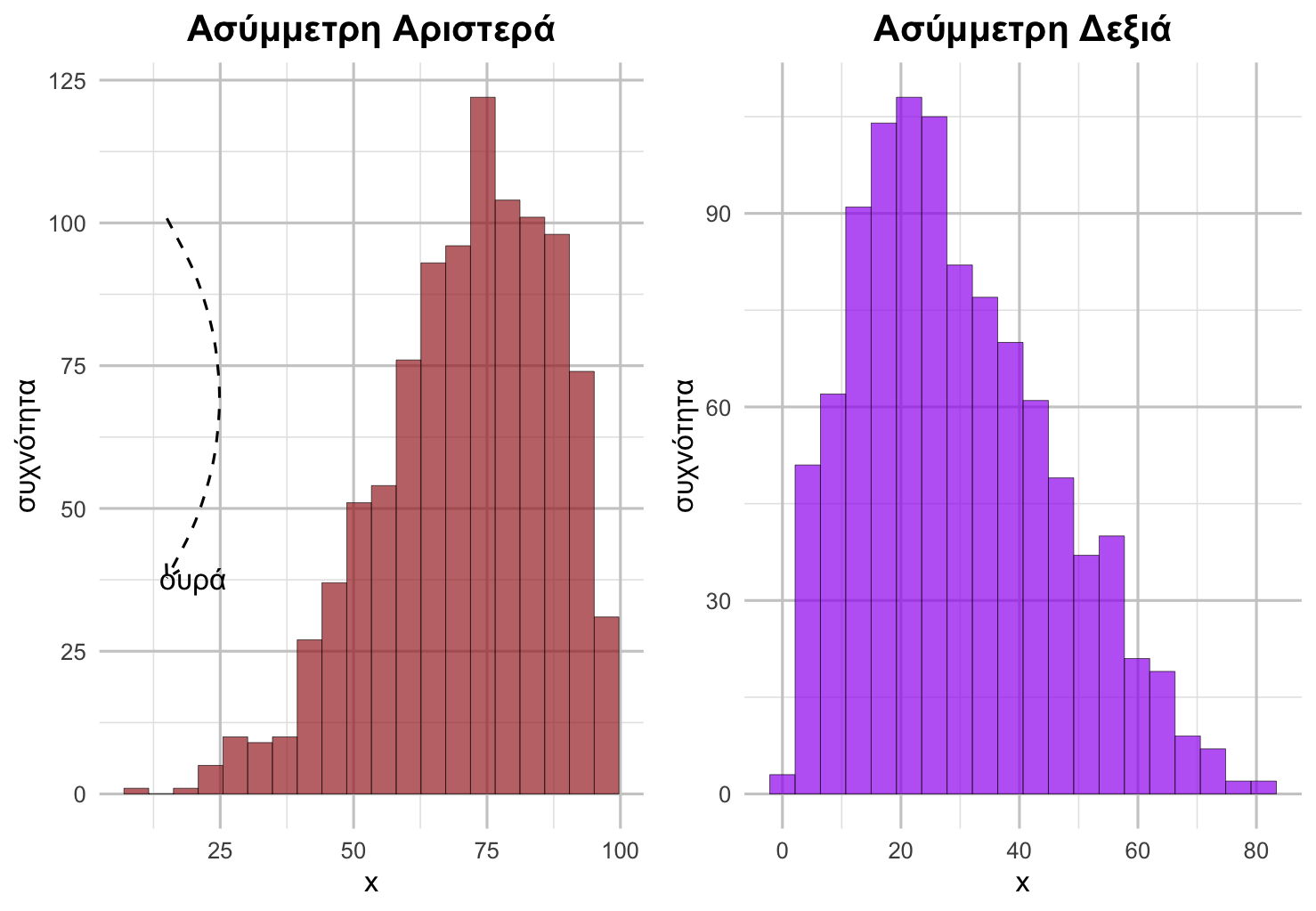
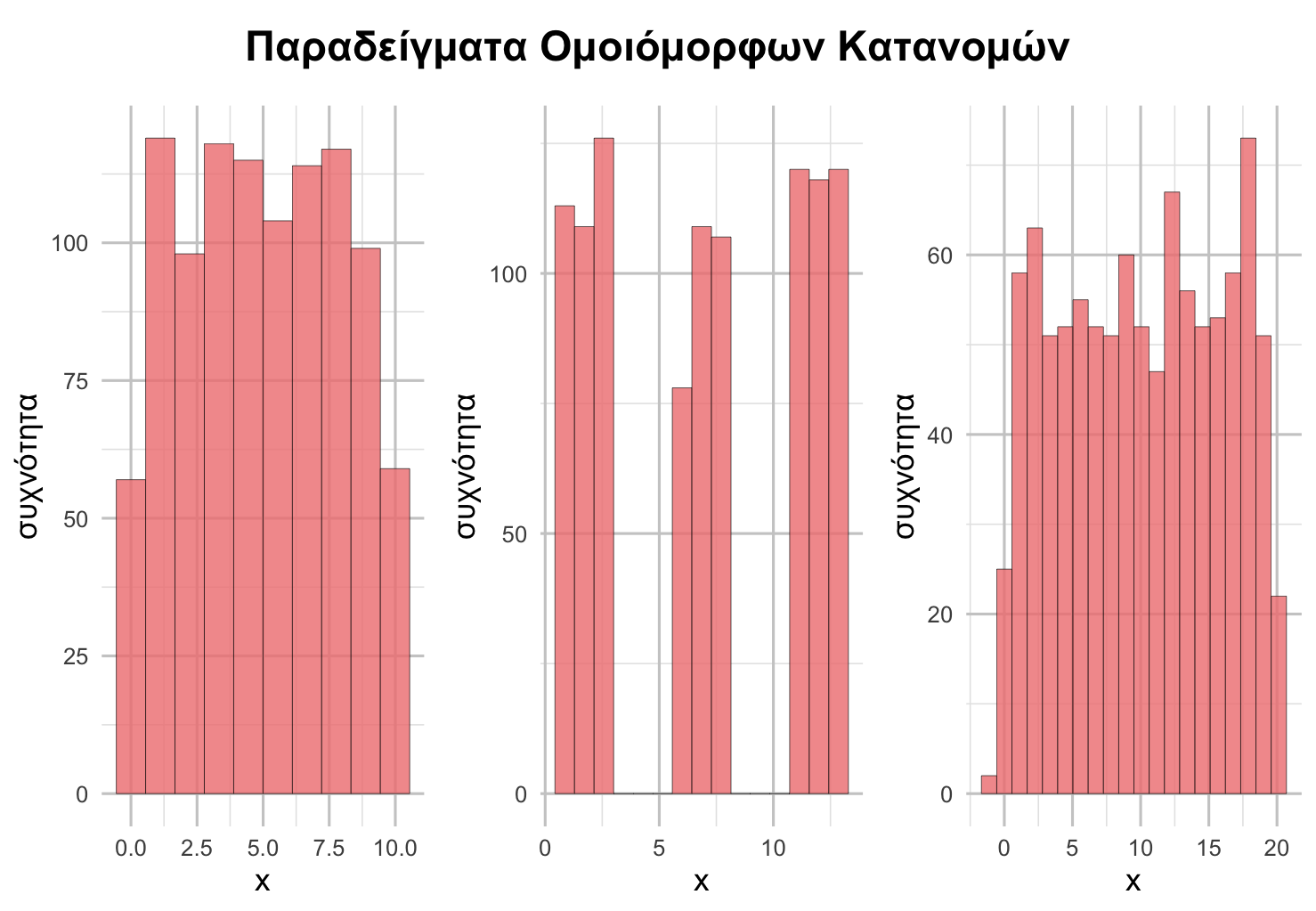
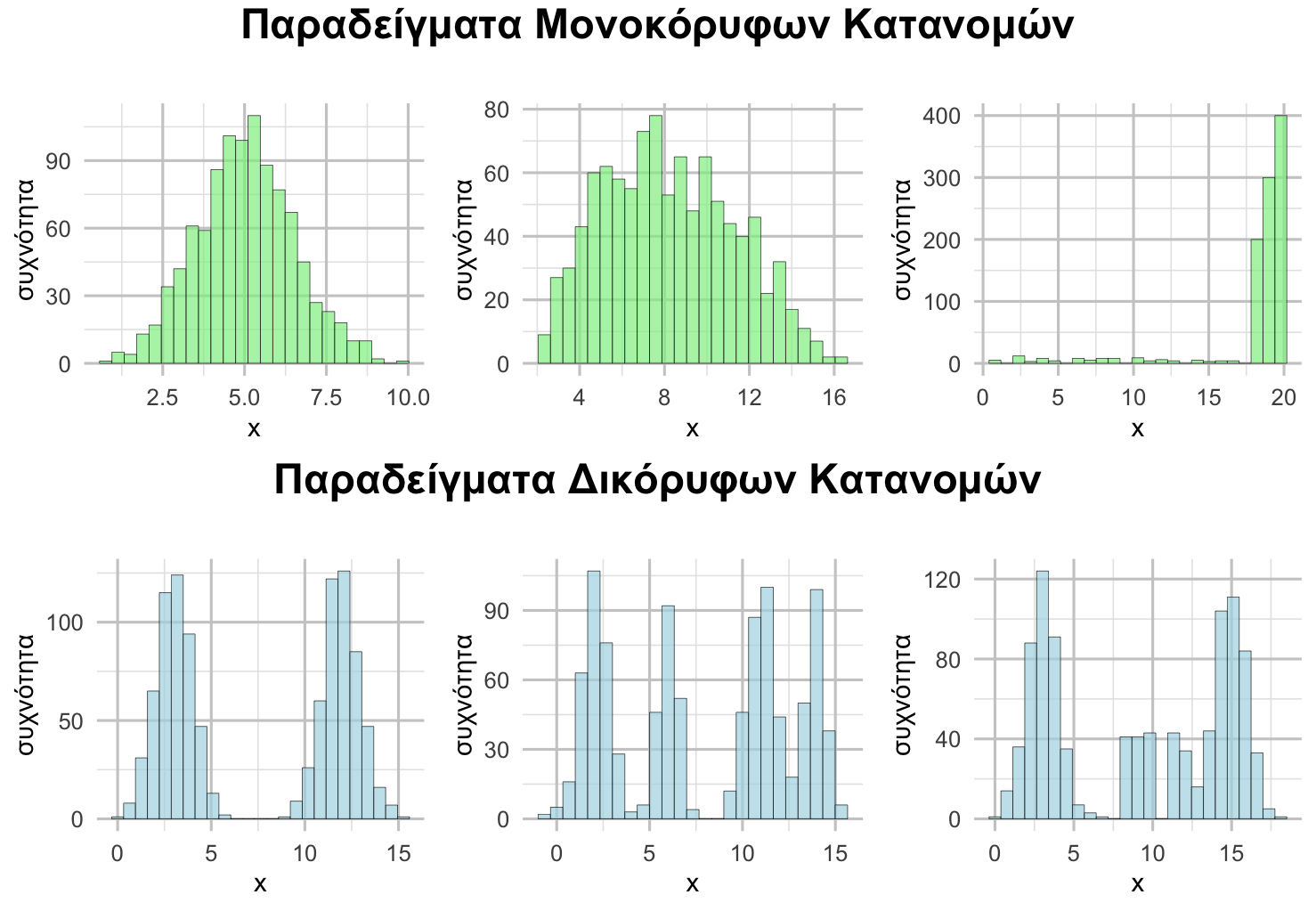
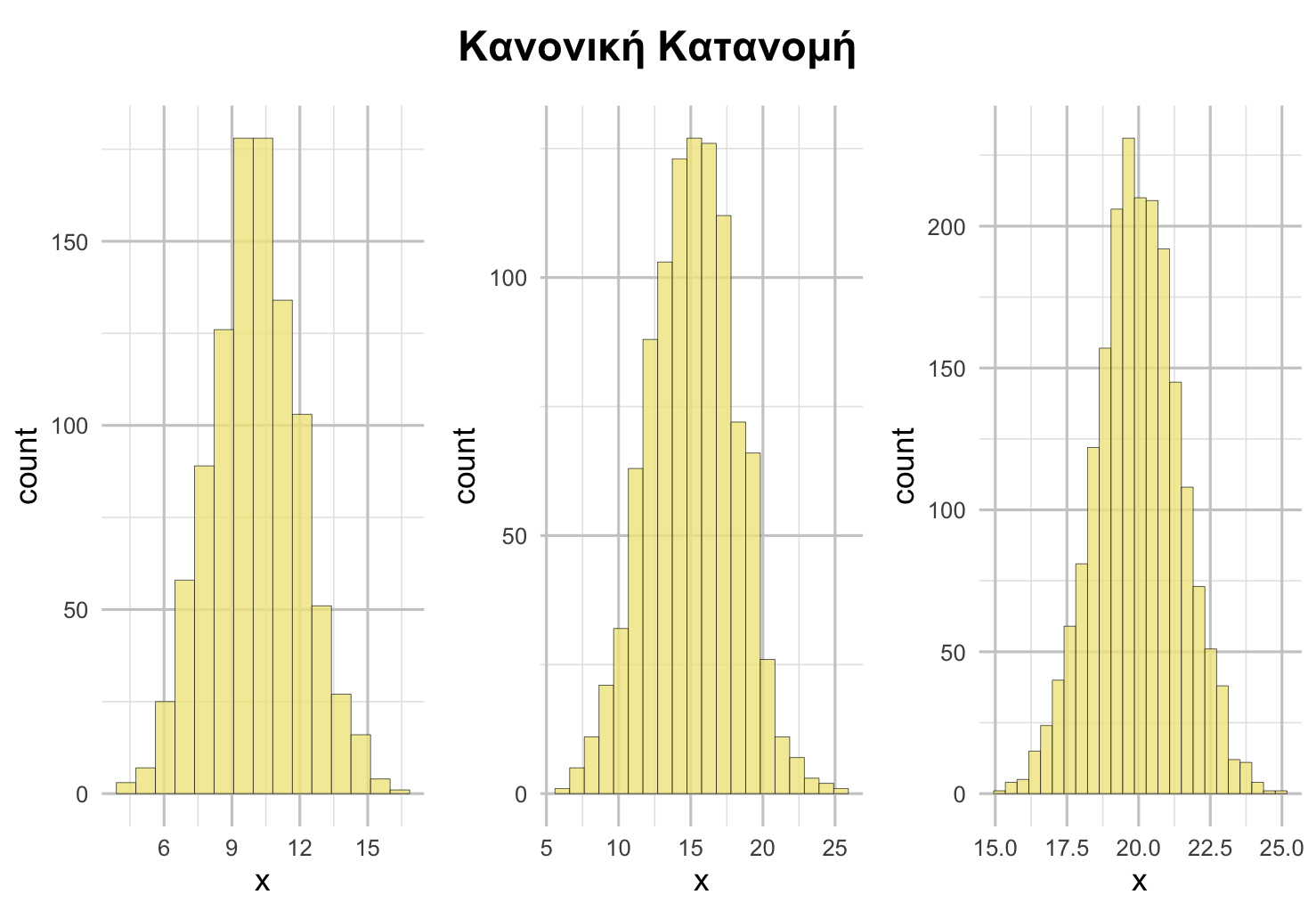
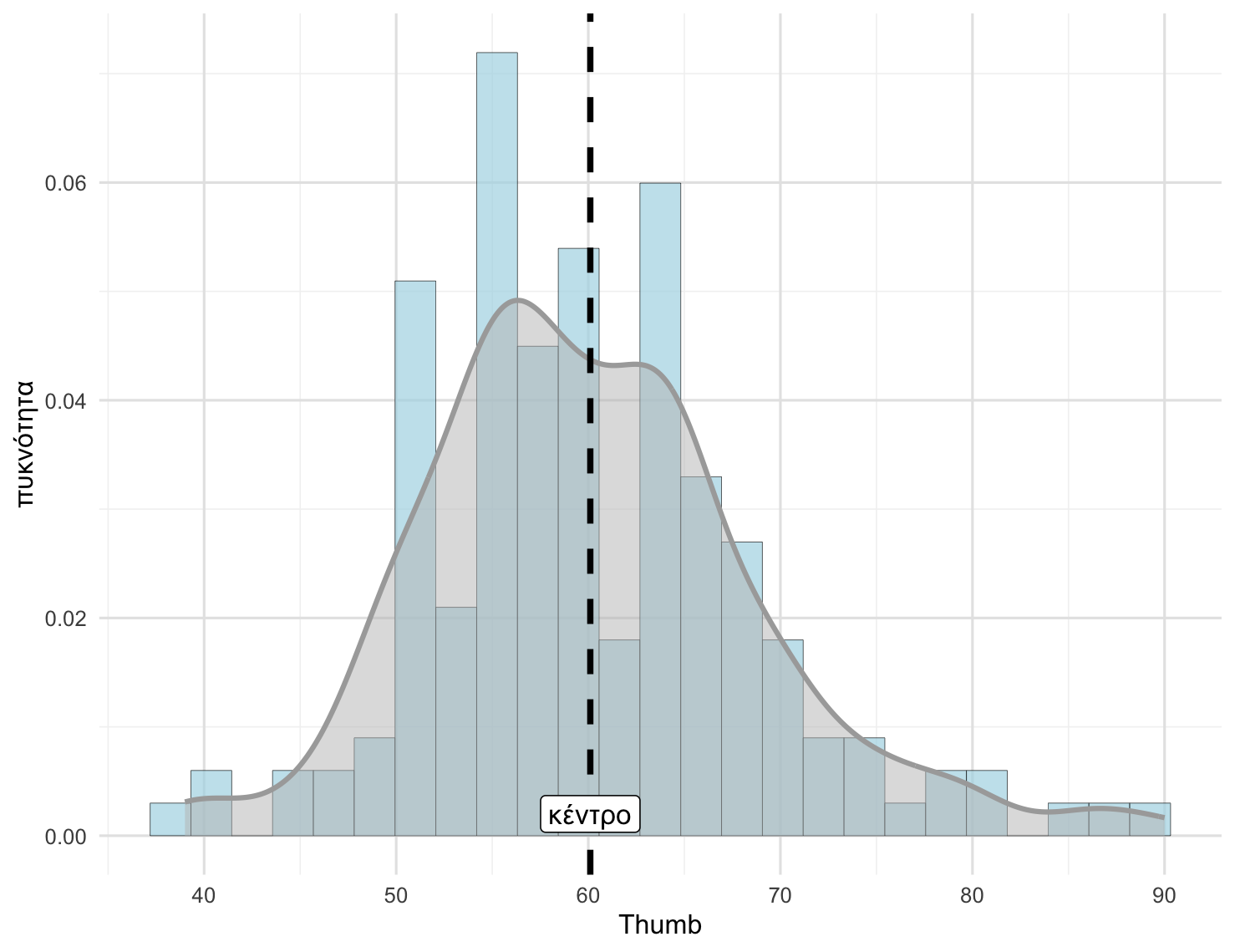
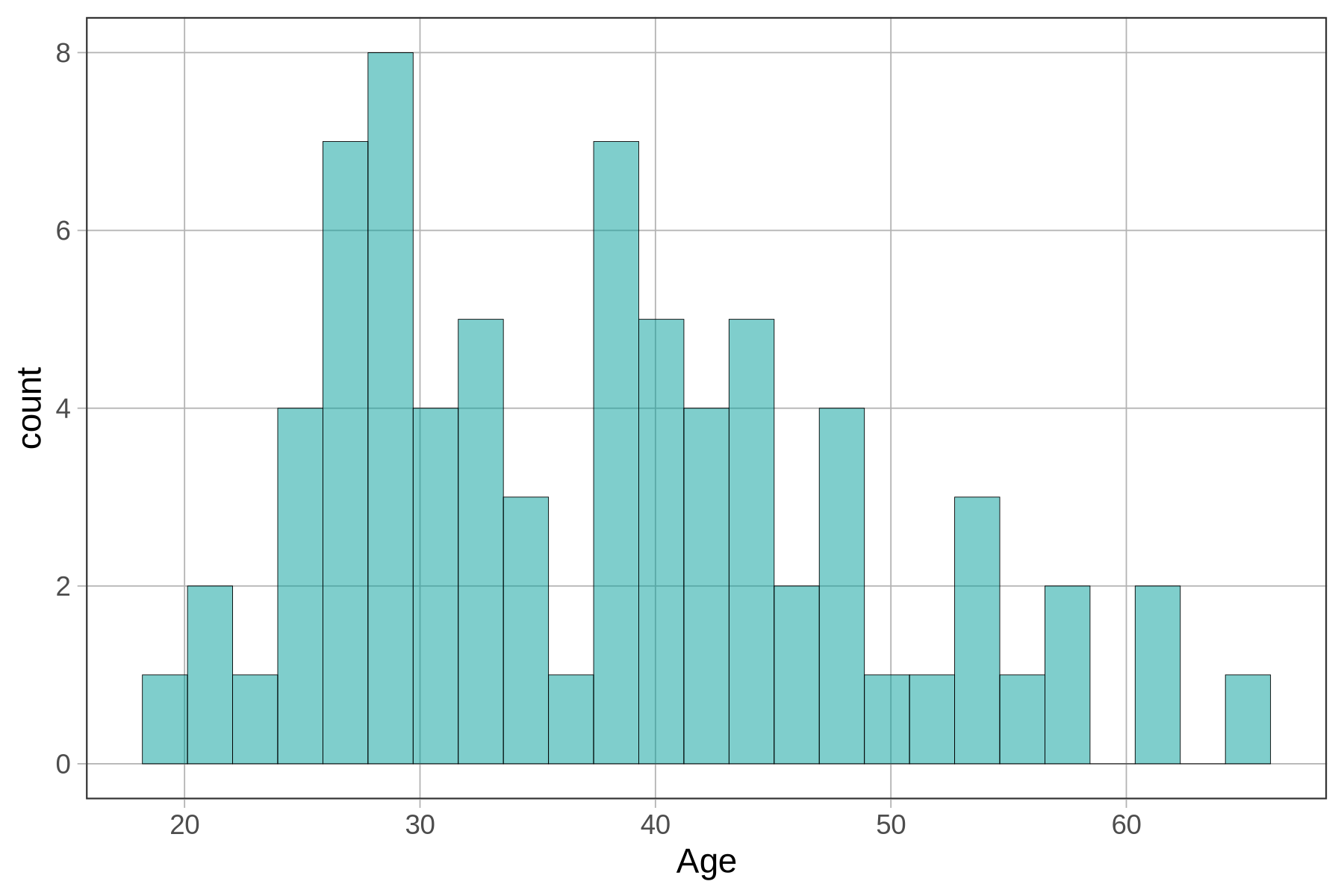
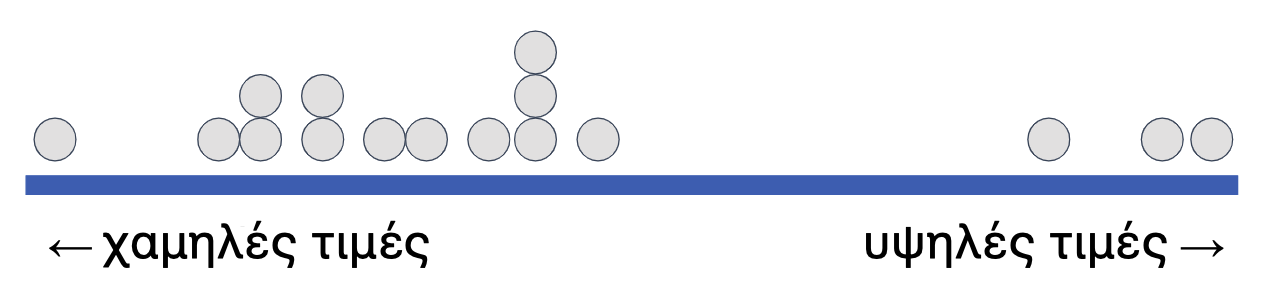
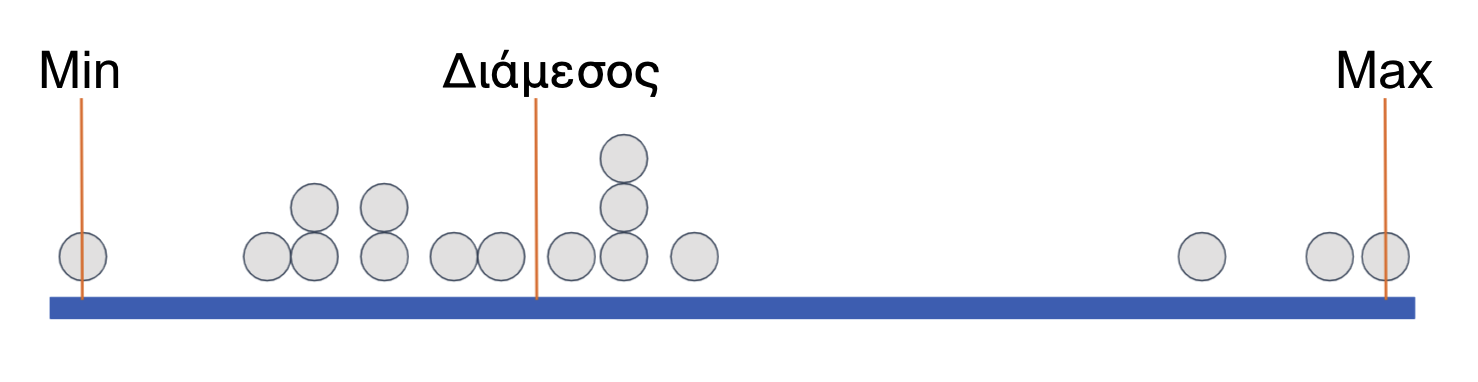 Επισημαίνεται ότι σε περίπτωση άρτιου αριθμού παρατηρήσεων (π.χ., στο παρόν παράδειγμα όπου υπάρχουν οκτώ), δεν υφίσταται «μεσαία τιμή». Σε αυτήν την περίπτωση, η διάμεσος υπολογίζεται ως το ημιάθροισμα των δύο μεσαίων τιμών της μεταβλητής.
Επισημαίνεται ότι σε περίπτωση άρτιου αριθμού παρατηρήσεων (π.χ., στο παρόν παράδειγμα όπου υπάρχουν οκτώ), δεν υφίσταται «μεσαία τιμή». Σε αυτήν την περίπτωση, η διάμεσος υπολογίζεται ως το ημιάθροισμα των δύο μεσαίων τιμών της μεταβλητής.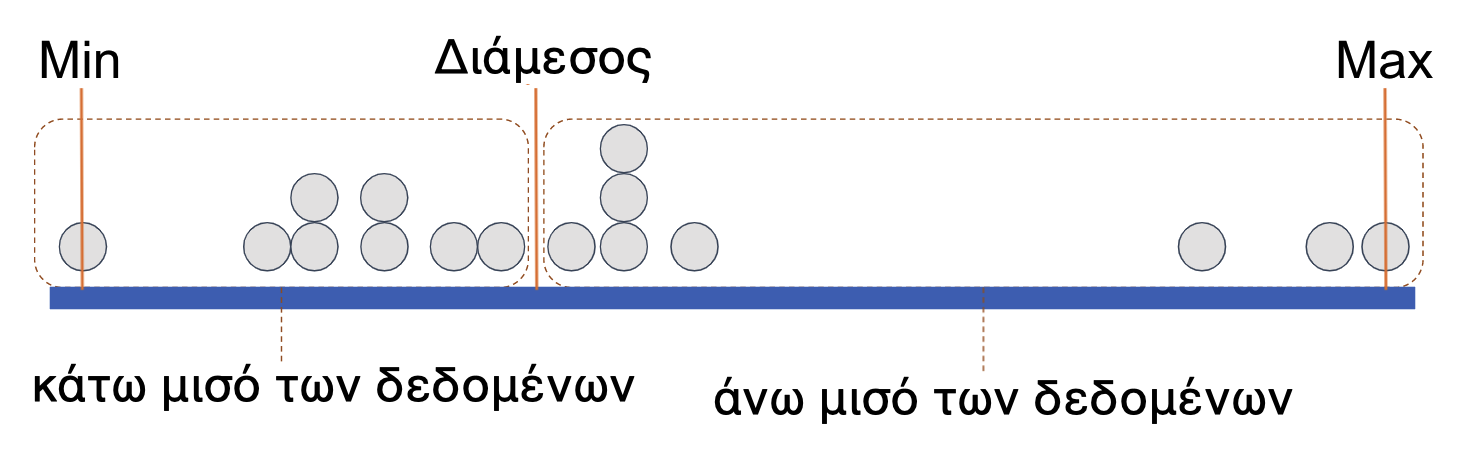 Διαιρώντας εκ νέου κάθε μισό σε δύο ίσα μέρη, προκύπτουν τα τεταρτημόρια, καθένα από τα οποία περιέχει ίσο αριθμό παρατηρήσεων. Η διαδικασία αυτή αντιστοιχεί στην ταξινόμηση ενός μεγάλου διανύσματος τιμών μιας μεταβλητής και στη συνέχεια στον διαχωρισμό του σε τέσσερις ομάδες ίσου μεγέθους.
Διαιρώντας εκ νέου κάθε μισό σε δύο ίσα μέρη, προκύπτουν τα τεταρτημόρια, καθένα από τα οποία περιέχει ίσο αριθμό παρατηρήσεων. Η διαδικασία αυτή αντιστοιχεί στην ταξινόμηση ενός μεγάλου διανύσματος τιμών μιας μεταβλητής και στη συνέχεια στον διαχωρισμό του σε τέσσερις ομάδες ίσου μεγέθους.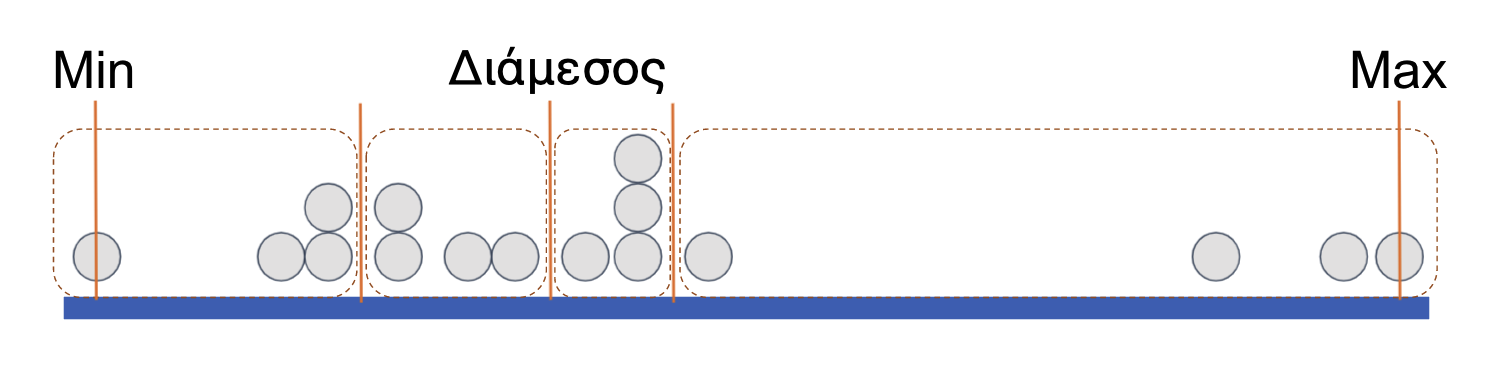
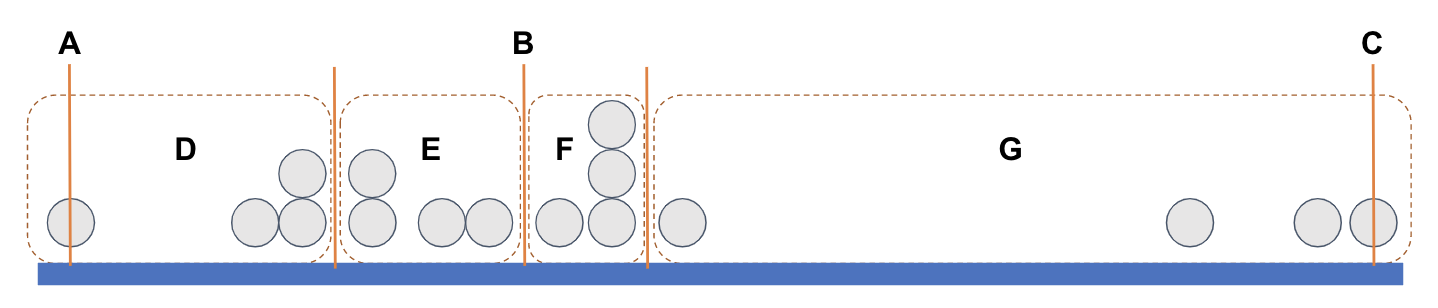
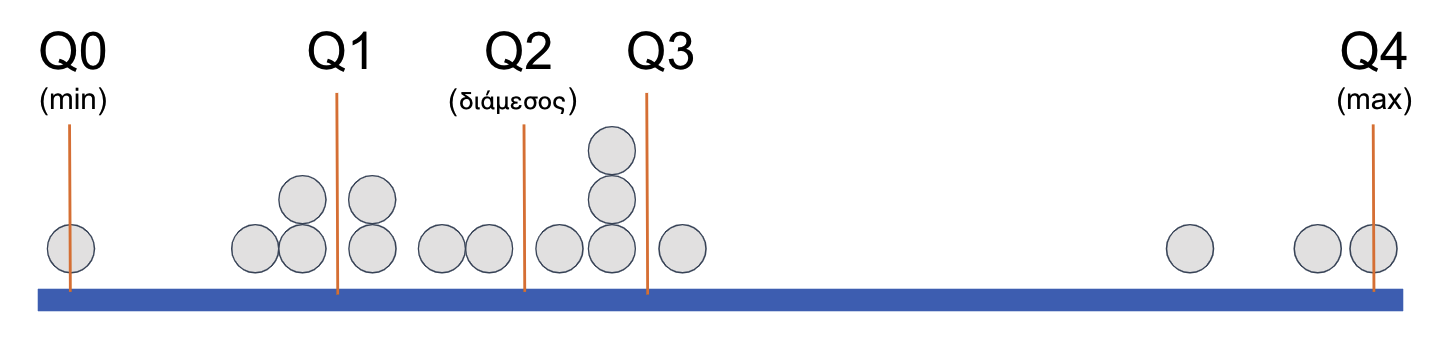
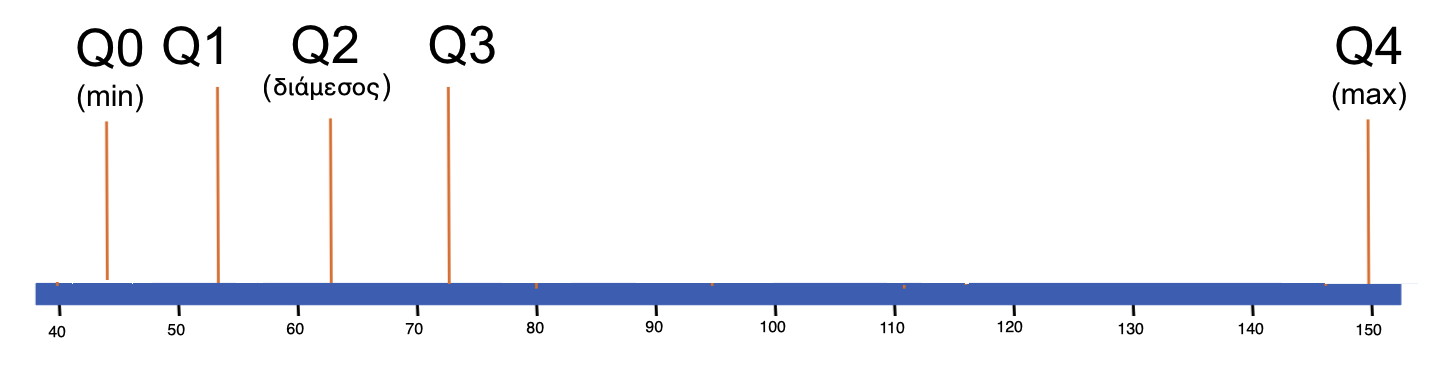 Η σύνοψη των πέντε αριθμών καταδεικνύει ότι, στην συγκεκριμένη κατανομή, τα τρία πρώτα τεταρτημόρια έχουν παρόμοιο εύρος (περίπου 7-11 μονάδες), ενώ το τέταρτο (ανώτερο) τεταρτημόριο είναι σημαντικά ευρύτερο (περίπου 78 μονάδες). Αυτό υποδηλώνει ότι το ανώτερο 25% των δεδομένων εμφανίζει μεγάλη διασπορά στην κλίμακα μέτρησης του βάρους. Είναι σημαντικό να τονιστεί ότι από το παραπάνω διάγραμμα δεν είναι δυνατόν να γνωρίζουμε την κατανομή των δεδομένων εντός κάθε τεταρτημορίου, δηλαδή αν η κατανομή είναι ομοιόμορφη ή όχι μεταξύ των οριακών σημείων των τεταρτημορίων.
Η σύνοψη των πέντε αριθμών καταδεικνύει ότι, στην συγκεκριμένη κατανομή, τα τρία πρώτα τεταρτημόρια έχουν παρόμοιο εύρος (περίπου 7-11 μονάδες), ενώ το τέταρτο (ανώτερο) τεταρτημόριο είναι σημαντικά ευρύτερο (περίπου 78 μονάδες). Αυτό υποδηλώνει ότι το ανώτερο 25% των δεδομένων εμφανίζει μεγάλη διασπορά στην κλίμακα μέτρησης του βάρους. Είναι σημαντικό να τονιστεί ότι από το παραπάνω διάγραμμα δεν είναι δυνατόν να γνωρίζουμε την κατανομή των δεδομένων εντός κάθε τεταρτημορίου, δηλαδή αν η κατανομή είναι ομοιόμορφη ή όχι μεταξύ των οριακών σημείων των τεταρτημορίων.