13 Κεφάλαιο: Εκτίμηση Παραμέτρων και Διαστήματα Εμπιστοσύνης
I still haven’t found what I’m looking for.
— U2
13.1 Από τους Ελέγχους Υποθέσεων στα Διαστήματα Εμπιστοσύνης
Στα προηγούμενα κεφάλαια εστιάσαμε στη χρήση δεδομένων για την αξιολόγηση του κενού μοντέλου της ΔΠΔ. Δημιουργήσαμε δειγματοληπτικές κατανομές με βάση το κενό μοντέλο, και στη συνέχεια αναρωτηθήκαμε αν μπορούμε να απορρίψουμε το κενό μοντέλο με βάση τα δεδομένα μας. Αν οι ενδείξεις δεν ήταν αρκετά ισχυρές για να δικαιολογήσουν την απόρριψη του κενού μοντέλου, θα κρατούσαμε το κενό μοντέλο ως πιθανό μοντέλο. Αν απορρίπταμε το κενό μοντέλο, από την άλλη, θα υιοθετούσαμε το σύνθετο μοντέλο που είχαμε προσαρμόσει στα δεδομένα.
Το πρόβλημα με αυτή την προσέγγιση είναι ότι εξετάζει μόνο δύο πιθανά μοντέλα της ΔΠΔ: ένα στο οποίο \(\beta_1 = 0\), και ένα στο οποίο \(\beta_1\) είναι ίσο με την εκτίμηση (π.χ. 6.05 στη μελέτη των φιλοδωρημάτων). Αλλά βαθιά μέσα μας, γνωρίζουμε ότι και τα δύο μοντέλα μπορεί να είναι λανθασμένα.
Στη μελέτη των φιλοδωρημάτων, αποτύχαμε να απορρίψουμε το κενό μοντέλο, ακόμα και αν τα τραπέζια που έλαβαν χαμογελαστό πρόσωπο άφησαν φιλοδώρημα κατά 6.05 ποσοστιαίες μονάδες μεγαλύτερο από τα άλλα τραπέζια. Αυτές οι ενδείξεις δεν ήταν αρκετά ισχυρές για να μας κάνουν να απορρίψουμε το κενό μοντέλο. Αλλά σημαίνει αυτό ότι το \(\beta_1\) στη ΔΠΔ είναι στην πραγματικότητα 0; Αν και αυτό είναι πιθανό, υπάρχουν πολλές πιθανές τιμές του \(\beta_1\) που θα ήταν συμβατές με τα δεδομένα μας.
Σε αυτό το κεφάλαιο θα χρησιμοποιήσουμε τις ίδιες δειγματοληπτικές κατανομές που χρησιμοποιήσαμε για τη σύγκριση μοντέλων, αλλά με έναν πιο ευέλικτο τρόπο για να απαντήσουμε σε ένα διαφορετικό ερώτημα: Ποιο είναι το εύρος των πιθανών τιμών για την παράμετρο που προσπαθούμε να εκτιμήσουμε; Στην περίπτωση της μελέτης των φιλοδωρημάτων, είναι ωραίο να γνωρίζουμε ότι το πραγματικό \(\beta_1\) στη ΔΠΔ μπορεί να είναι 0, αλλά τι άλλο θα μπορούσε να είναι; Αν η καλύτερη εκτίμησή μας, με βάση τα δεδομένα, είναι 6.05, θέλουμε να γνωρίζουμε πόσο ακριβής μπορεί να είναι αυτή η εκτίμηση και πόση αβεβαιότητα έχουμε για αυτήν την τιμή.
Ανασκόπηση του Ελέγχου Μηδενικής Υπόθεσης για το \(b_1\)
Ας ξεκινήσουμε επαναλαμβάνοντας τη λογική πίσω από τον έλεγχο μηδενικής υπόθεσης, δηλαδή τον τρόπο με τον οποίο αξιολογήσαμε το κενό μοντέλο. Όπως φαίνεται στο παρακάτω σχήμα, αρχικά φανταζόμαστε έναν κόσμο όπου το κενό μοντέλο είναι αληθές, δηλαδή έναν κόσμο όπου δεν υπάρχει επίδραση του χαμογελαστού προσώπου στο ποσοστό φιλοδωρήματος (Tip). Αναπαριστούμε αυτή την ιδέα βάζοντας την τιμή 0 σε κόκκινο πλαίσιο στο επάνω μέρος, δηλαδή την τιμή που υποθέτουμε ότι έχει το πραγματικό \(\beta_1\) στη ΔΠΔ.
Είναι σημαντικό να θυμόμαστε ότι δεν γνωρίζουμε αν όντως το \(\beta_1 = 0\) ή όχι. Απλώς υποθέτουμε ότι είναι 0 ώστε να μπορέσουμε να εκτιμήσουμε τις συνέπειες που θα μπορούσαν να προκύψουν από έναν τέτοιο κόσμο. Αργότερα θα υποθέσουμε άλλες τιμές του \(\beta_1\), μετακινώντας το κόκκινο κουτί δεξιά και αριστερά για να αναπαραστήσουμε μεγαλύτερες ή μικρότερες τιμές του \(\beta_1\).
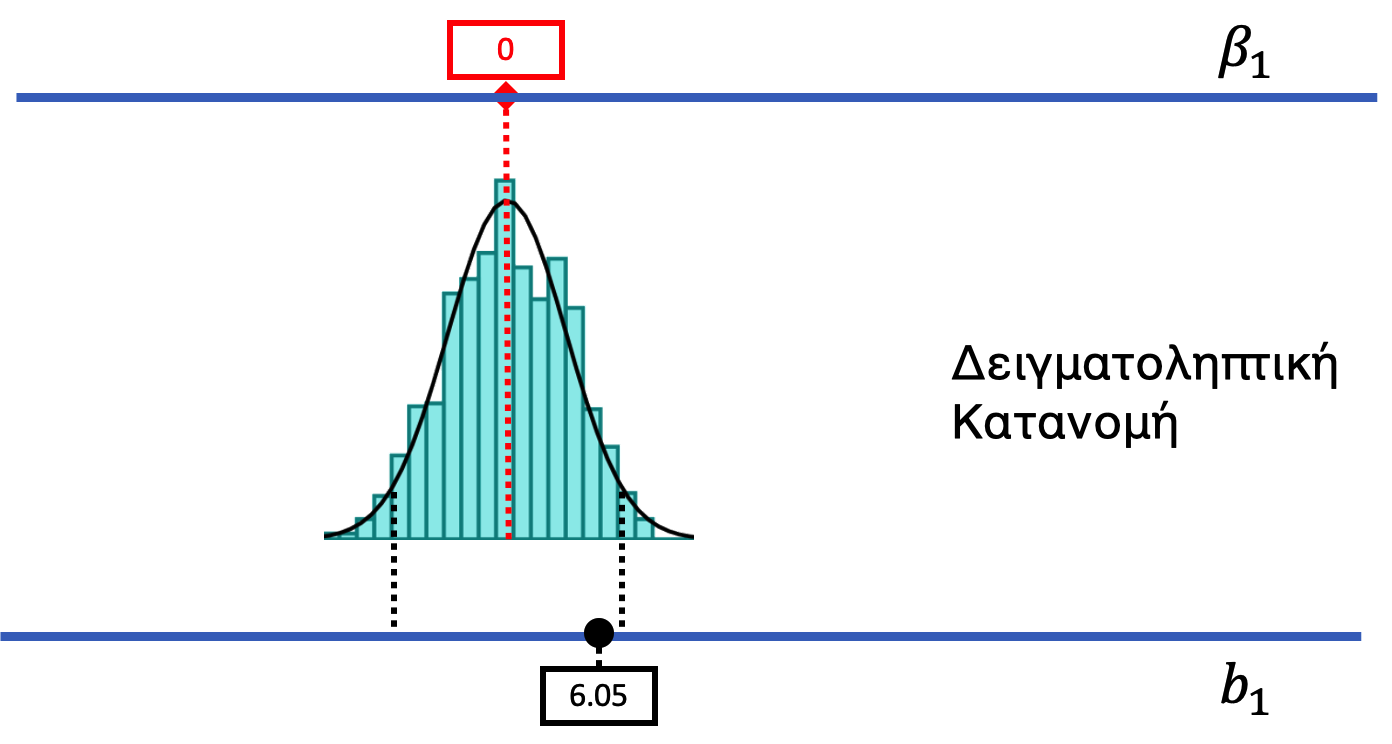
Με την υπόθεση ότι \(\beta_1 = 0\), χρησιμοποιήσαμε τη συνάρτηση shuffle() για να δημιουργήσουμε μια δειγματοληπτική κατανομή (ως ένα ιστόγραμμα, βλ. παραπάνω σχήμα) που μας δείχνει τη διακύμανση στις τιμές \(b_1\) του δείγματος που θα αναμένονταν να παρατηρηθούν λόγω τυχαιότητας αν το κενό μοντέλο ήταν αληθές. (Αυτή η δειγματοληπτική κατανομή έχει σχήμα περίπου Κανονικής κατανομής, και συνήθως μοντελοποιείται με την κατανομή \(t\). Δείχνουμε την κατανομή \(t\) ως μια εξομαλυμένη καμπύλη που επικαλύπτει το ιστόγραμμα.)
Αφού δημιουργήσαμε μια δειγματοληπτική κατανομή, εντοπίσαμε την τιμή \(b_1\) του δείγματός μας (6.05) επάνω στη δειγματοληπτική κατανομή. Η τιμή \(b_1\) του δείγματος, που την αναπαραστήσαμε με μια μαύρη κουκκίδα στο κάτω μέρος του σχήματος, δεν είναι κάτι που φανταζόμαστε ή υποθέτουμε. Είναι η εκτίμηση παραμέτρου που οι ερευνητές υπολόγισαν από τα δεδομένα του δείγματος. Είναι σταθερή και δεν μπορεί να αλλάξει.
Επειδή η τιμή \(b_1\) του δείγματος δεν βρίσκεται στις ουρές αυτής της δειγματοληπτικής κατανομής (το ακραίο 5% που αποτελεί το επίπεδο σημαντικότητας \(\alpha\) που έχουμε προκαθορίσει), αποφασίσαμε να μην απορρίψουμε το κενό μοντέλο (ή μηδενική υπόθεση). Η τιμή \(p\) ήταν περίπου ίση με 0.08, που σημαίνει ότι αν το κενό μοντέλο ήταν αληθές, θα υπήρχε πιθανότητα 0.08 (ή 8%) να λάβουμε μια δειγματική τιμή \(b_1\) τόσο ακραία όσο αυτή στο δείγμα μας απλώς από τύχη.

Στο παραπάνω σχήμα της δειγματοληπτικής κατανομής, τι αντιπροσωπεύουν οι μαύρες διακεκομμένες γραμμές;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Οι διακεκομμένες γραμμές ορίζουν την απίθανη περιοχή της δειγματοληπτικής κατανομής του \(b_1\) — δηλαδή το 5% των πιο ακραίων τιμών \(b_1\) που θα παράγονταν αν το κενό μοντέλο ήταν αληθές. Αυτά είναι τιμές του στατιστικού \(b_1\) για πιθανά δείγματα, όχι τιμές της Tip ή της ΔΠΔ.
13.2 Εναλλακτικές Δειγματοληπτικές Κατανομές
Μέχρι τώρα, αναφερθήκαμε στις δειγματοληπτικές κατανομές με επίκεντρο πάντα το κενό μοντέλο. Στα Κεφάλαια 10 και 11, ξεκινούσαμε πάντα υποθέτοντας ότι \(\beta_1 = 0\) και στη συνέχεια δημιουργούσαμε δειγματοληπτικές κατανομές με βάση αυτήν την υπόθεση. Σε αυτό το κεφάλαιο θα προχωρήσουμε πέρα από το κενό μοντέλο και θα εξετάσουμε εναλλακτικά μοντέλα που θα μπορούσαν να έχουν παράγει το \(b_1\) του δείγματος.
Η βασική μας στρατηγική φαίνεται στο παρακάτω κινούμενο σχήμα. Ξεκινάμε με την ίδια δειγματοληπτική κατανομή που κατασκευάσαμε με βάση το κενό μοντέλο. Αλλά στη συνέχεια τη μετακινούμε αριστερά και δεξιά κατά μήκος της κλίμακας του οριζόντιου άξονα, υποθέτοντας διαφορετικές πιθανές τιμές που μπορεί να λάβει το \(\beta_1\).
 Τι παραμένει σταθερό καθώς μετακινούμε τη δειγματοληπτική κατανομή αριστερά και δεξιά στον άξονα που μετράμε τη διαφορά μεταξύ της ομάδας του χαμογελαστού προσώπου και της ομάδας ελέγχου; (Επιλέξτε όλες τις σωστές απαντήσεις.)
Τι παραμένει σταθερό καθώς μετακινούμε τη δειγματοληπτική κατανομή αριστερά και δεξιά στον άξονα που μετράμε τη διαφορά μεταξύ της ομάδας του χαμογελαστού προσώπου και της ομάδας ελέγχου; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β, Γ, Δ και Ε.
Καθώς μετακινούμε τη δειγματοληπτική κατανομή, το \(b_1\) του δείγματος (Β) παραμένει σταθερό — είναι σταθερό από τα δεδομένα. Το πλάτος (Γ), τα σχετικά όρια (Δ) και το σχήμα (Ε) της κατανομής παραμένουν επίσης σταθερά — αλλάζει μόνο το πού βρίσκεται η κατανομή στον οριζόντιο άξονα (ΣΤ), και αυτό αντικατοπτρίζει την τιμή που υποθέτουμε για το \(\beta_1\), η οποία αλλάζει (Α).
Καθώς εξετάζουμε εναλλακτικά μοντέλα για τη ΔΠΔ, θα υποθέσουμε ότι το σχήμα και η διασπορά της δειγματοληπτικής κατανομής δεν αλλάζουν για διαφορετικές υποθετικές τιμές του \(\beta_1\). Υποθέτοντας ότι το σχήμα και η διασπορά παραμένουν σταθερά, μπορούμε να πάρουμε την κατανομή που φτιάξαμε για το κενό μοντέλο και να τη μετακινήσουμε πάνω στην κλίμακα για να ελέγξουμε οποιαδήποτε άλλη τιμή. Αργότερα θα τεκμηριώσουμε καλύτερα αυτή την υπόθεση.
Καθώς νοητά μετακινούμε τη δειγματοληπτική κατανομή αριστερά και δεξιά στην κλίμακα του οριζόντιου άξονα (κλίμακα μέτρησης του στατιστικού μας), εξετάζουμε διαφορετικές πιθανές τιμές του \(\beta_1\). Για κάθε μία από αυτές τις πιθανές τιμές θέτουμε το ίδιο ερώτημα που θέσαμε χρησιμοποιώντας τη δειγματοληπτική κατανομή με κέντρο το \(\beta_1 = 0\): Δεδομένης της νέας υποθετικής τιμής του \(\beta_1\), είναι πιθανό μια τέτοια ΔΠΔ να παράγει το \(b_1\) του δείγματός μας;
Ας σας δείξουμε τι εννοούμε. Στο παρακάτω σχήμα έχουμε μετακινήσει τη δειγματοληπτική κατανομή που κατασκευάσαμε με βάση το κενό μοντέλο για τη μελέτη των φιλοδωρημάτων προς τα δεξιά μέχρι να κεντραριστεί σε μια ΔΠΔ όπου \(\beta_1 = 6.05\). Θέτουμε τώρα το ερώτημα: «Αν η πραγματική τιμή \(\beta_1\) είναι 6.05, είναι πιθανό να παρατηρήσουμε την τιμή \(b_1\) του δείγματός μας (6.05);»
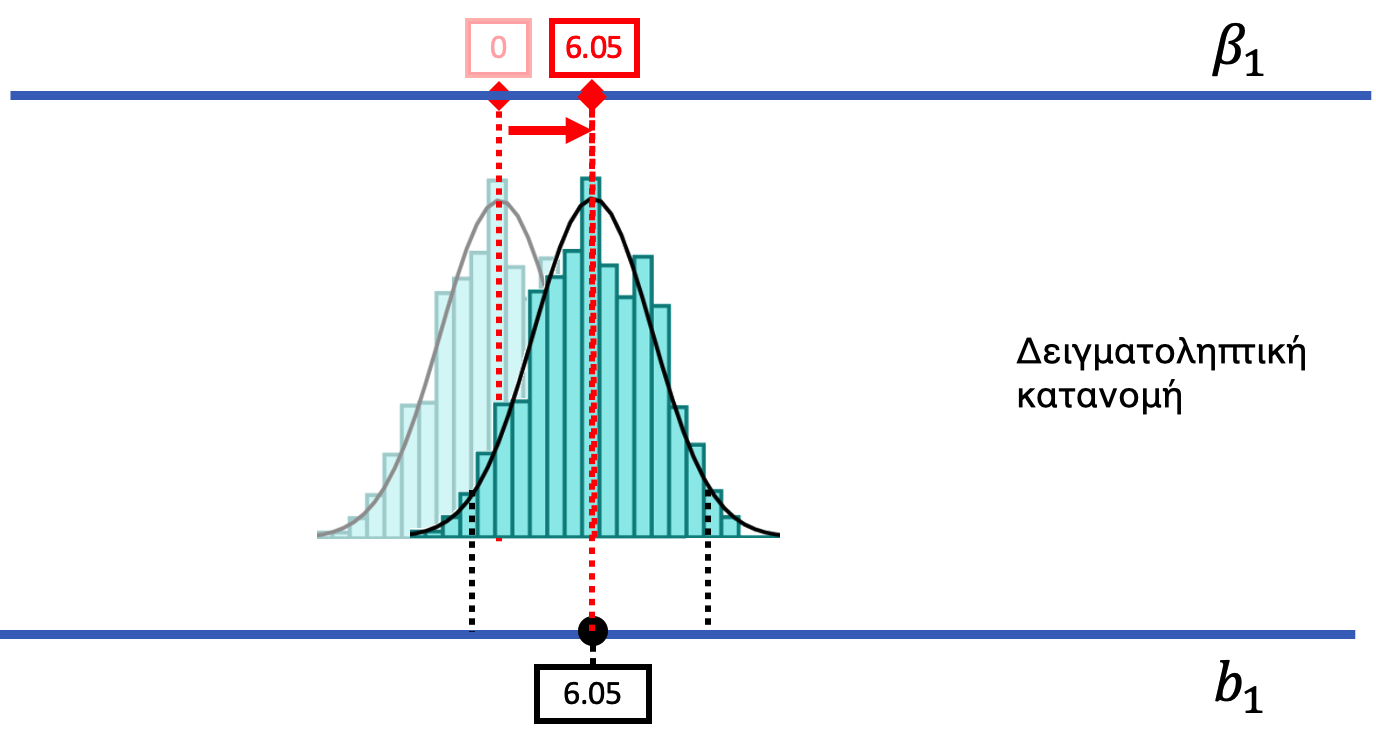
Με βάση το παραπάνω σχήμα, αν η πραγματική τιμή \(\beta_1\) ήταν 6.05, είναι πιθανή η τιμή \(b_1\) του δείγματός μας (6.05); (δηλ. βρίσκεται εντός της κεντρικής περιοχής του 95% των τιμών;)
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Όταν κεντράρουμε τη δειγματοληπτική κατανομή στην τιμή \(\beta_1 = 6.05\), η τιμή \(b_1\) του δείγματος (6.05) βρίσκεται ακριβώς στο κέντρο της κατανομής — άρα είναι η πιο πιθανή τιμή που θα παραγόταν από αυτή τη ΔΠΔ. Βρίσκεται σαφώς εντός της κεντρικής περιοχής του 95% των τιμών.
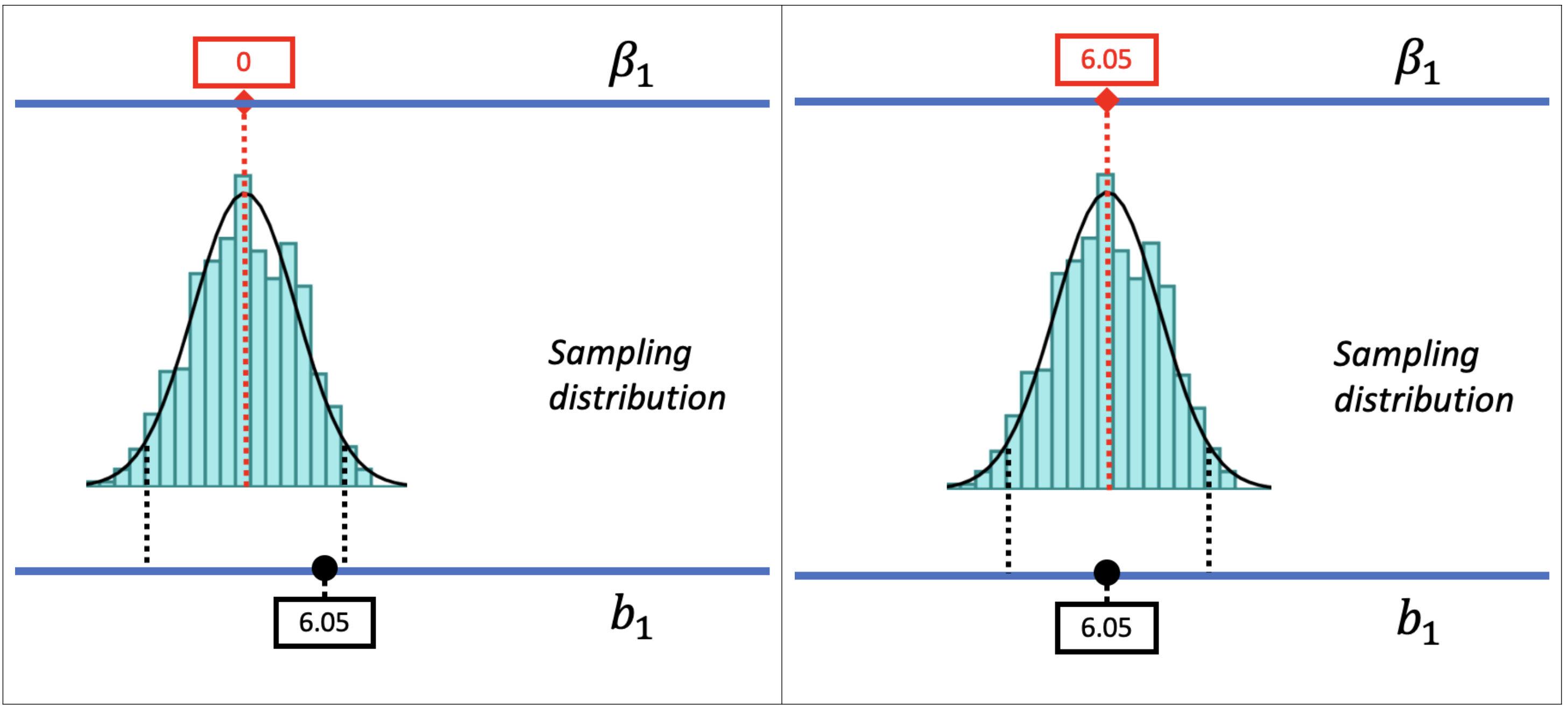
Τι είναι παρόμοιο στις δειγματοληπτικές κατανομές αυτών των δύο εικόνων;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Στο αριστερό μέρος του σχήματος (\(\beta_1 = 0\)), η τιμή \(b_1 = 6.05\) βρίσκεται εντός της περιοχής του 95% — άρα δεν θεωρείται απίθανη. Στο δεξί μέρος (\(\beta_1 = 6.05\)), η τιμή \(b_1 = 6.05\) βρίσκεται ακριβώς στο κέντρο — επίσης πολύ πιθανή. Και οι δύο ΔΠΔ λοιπόν είναι συμβατές με την παρατηρούμενη τιμή \(b_1\) του δείγματος.
Είδαμε πριν ότι μια ΔΠΔ στην οποία \(\beta_1 = 0\) θα μπορούσε να παράγει το παρατηρούμενο \(b_1 = 6.05\). Αυτός ήταν ο λόγος που δεν απορρίψαμε το κενό μοντέλο. Αλλά αυτό δεν σημαίνει ότι το \(\beta_1\) στη ΔΠΔ είναι στην πραγματικότητα ίσο με 0. Οι παραπάνω εικόνες δείχνουν ότι είναι επίσης πιθανό το πραγματικό \(\beta_1\) να είναι ίσο με 6.05! Και το 6.05 ήταν, τελικά, η βέλτιστη εκτίμηση της τιμής \(\beta_1\) με βάση τα δεδομένα.
Από τα όσα είδαμε μέχρι τώρα, μπορούμε να δούμε ότι το \(\beta_1\) θα μπορούσε να είναι 0 ή θα μπορούσε να είναι 6.05. Αλλά αυτές είναι απλώς δύο από τις πολλές πιθανές ΔΠΔ που θα μπορούσαν να έχουν παράγει την τιμή \(b_1 = 6.05\) του δείγματος. Μόλις αρχίσουμε να φανταζόμαστε διαφορετικές πιθανές ΔΠΔ, και τις δειγματοληπτικές κατανομές που η καθεμία θα παρήγαγε, θα δούμε όλο και περισσότερες περιπτώσεις.
Αλλά χρησιμοποιώντας αυτή τη στρατηγική, μπορούμε επίσης να αποκλείσουμε ορισμένες περιπτώσεις. Υπάρχουν τιμές \(\beta_1\) που δεν είναι πιθανό να παράγουν την τιμή του δείγματος. Φανταστείτε μια ΔΠΔ με \(\beta_1\) πολύ μεγαλύτερο από 6.05· για παράδειγμα, έναν κόσμο όπου η πραγματική διαφορά μεταξύ ομάδων είναι 15.00 ποσοστιαίες μονάδες. Για να αναπαραστήσουμε αυτόν τον κόσμο, θα μπορούσαμε να μετακινήσουμε τη ΔΠΔ καθώς και την αντίστοιχη δειγματοληπτική κατανομή της περαιτέρω προς τα δεξιά (βλ. παρακάτω σχήμα).
Μια τέτοια ΔΠΔ θα μπορούσε να παράγει μια ποικιλία δειγμάτων. Αλλά παρατηρήστε ότι η τιμή \(b_1 = 6.05\) του δείγματος δεν βρίσκεται πλέον στην κεντρική περιοχή του 95% — τώρα βρίσκεται στην απίθανη ουρά στα αριστερά. Θα μπορούσαμε να πούμε, επομένως, ότι μια ΔΠΔ με \(\beta_1 = 15.00\) είναι απίθανο να έχει παράγει το \(b_1\) του δείγματος, επειδή η τιμή 6.05 είναι πολύ χαμηλότερη από τις περισσότερες τιμές \(b_1\) που παράγει αυτή η ΔΠΔ.
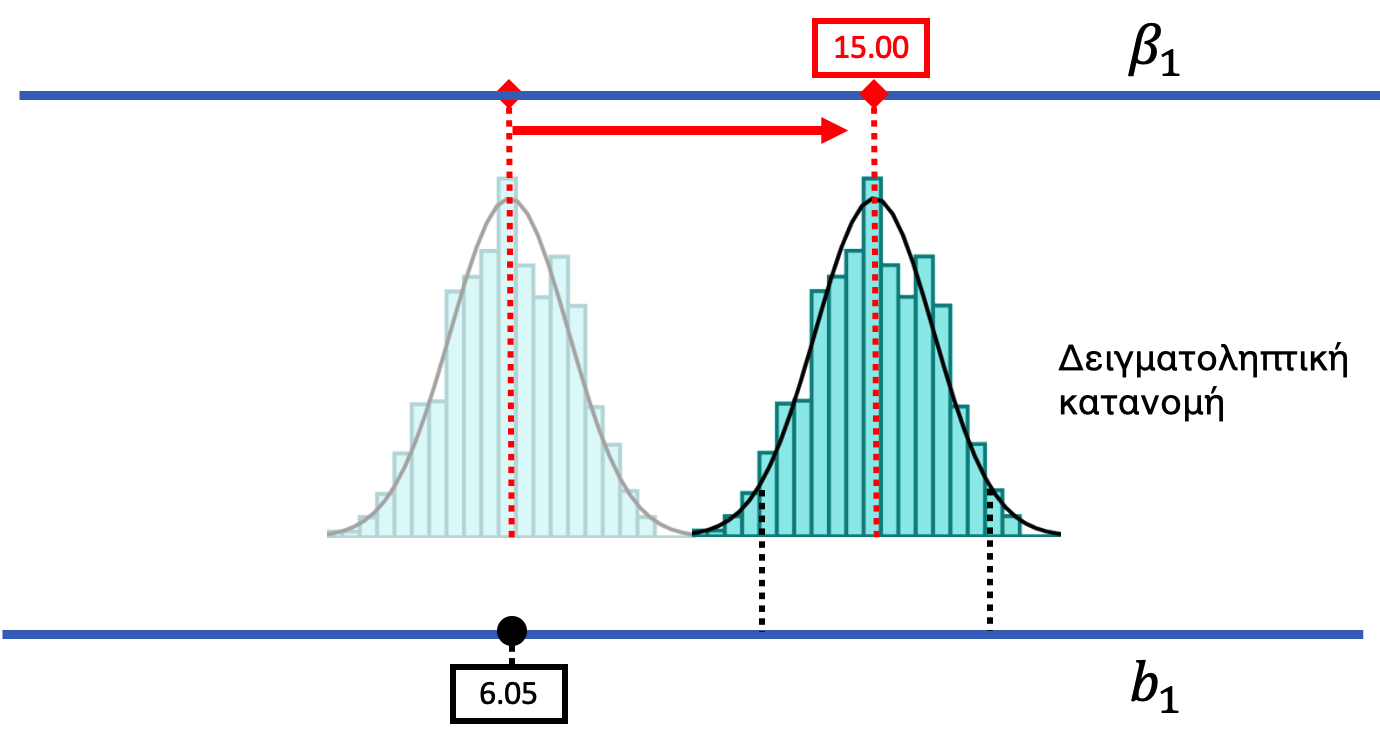
Πώς μπορείτε να καταλάβετε από το παραπάνω σχήμα ότι η τιμή 6.05 είναι απίθανο να παραχθεί από αυτή τη ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Οι μαύρες διακεκομμένες γραμμές ορίζουν την κεντρική περιοχή του 95% της δειγματοληπτικής κατανομής για \(\beta_1 = 15\). Η τιμή \(b_1 = 6.05\) βρίσκεται αριστερά και από τις δύο γραμμές — δηλαδή στην κατώτερη απίθανη ουρά — που σημαίνει ότι μια ΔΠΔ με \(\beta_1 = 15\) θα παράγαγε σπάνια μια \(b_1\) τόσο χαμηλή τιμή όσο το 6.05.
Με την ίδια λογική, αν μετακινήσουμε τη δειγματοληπτική κατανομή πολύ προς τα αριστερά (όπως στο παρακάτω σχήμα), μπορούμε να δούμε ότι είναι απίθανο η τιμή \(b_1 = 6.05\) να προήλθε από μια ΔΠΔ με \(\beta_1\) τόσο χαμηλή όσο −2.00. Μετακινώντας τη δειγματοληπτική κατανομή αριστερά και δεξιά, μπορούμε να αρχίσουμε να βλέπουμε το εύρος των πιθανών τιμών \(\beta_1\) που θα μπορούσαν να έχουν παράγει την τιμή \(b_1\) του δείγματός μας.
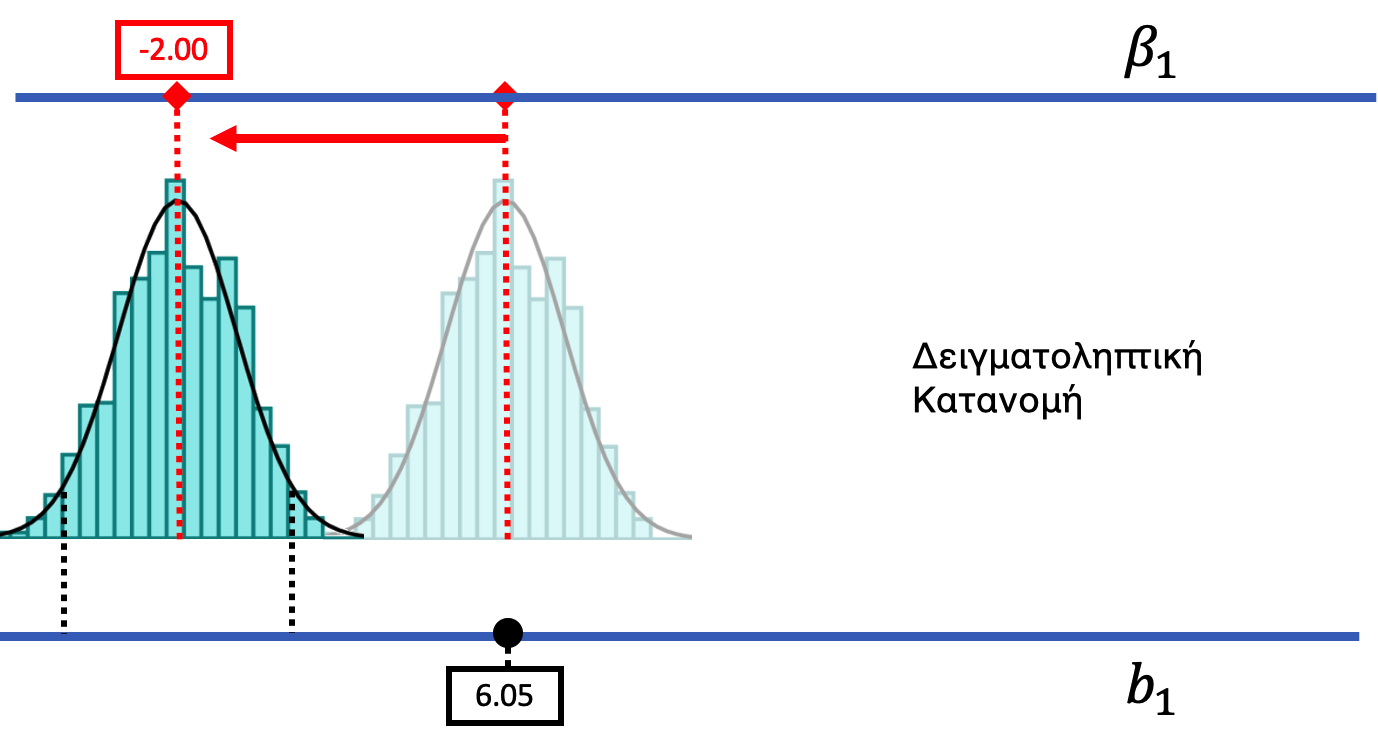
Τι σημαίνει \(\beta_1 = -2.00\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Το \(\beta_1 = -2.00\) είναι παράμετρος της ΔΠΔ — περιγράφει την πραγματική μέση διαφορά στον πληθυσμό, όχι στο δείγμα. Το αρνητικό πρόσημο σημαίνει ότι η ομάδα χαμογελαστού προσώπου θα αφήνε λιγότερο φιλοδώρημα.
Αν η πραγματική τιμή \(\beta_1\) στη ΔΠΔ ήταν −2.00, γιατί θα ήταν απίθανο να παρατηρήσουμε μια τιμή \(b_1 = 6.05\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Αν \(\beta_1 = -2.00\), η δειγματοληπτική κατανομή θα είναι κεντραρισμένη στο −2.00. Το \(b_1 = 6.05\) βρίσκεται πολύ δεξιά από αυτή την κατανομή — στην απίθανη περιοχή της άνω ουράς. Αν και είναι θεωρητικά δυνατό μια αρνητική ΔΠΔ να παράγει μια θετική τιμή \(b_1\), είναι εξαιρετικά απίθανο σε αυτή την περίπτωση.
13.3 Η Βασική Ιδέα του Διαστήματος Εμπιστοσύνης
Αν επεκτείνουμε αυτή την προσέγγιση, θα μπορέσουμε να βρούμε το εύρος των τιμών \(\beta_1\) που θα ήταν πιθανό να παράγουν την τιμή \(b_1\) του δείγματος· αυτή είναι η βασική ιδέα πίσω από τα διαστήματα εμπιστοσύνης (confidence intervals). Χρησιμοποιούμε τη λέξη «πιθανό» για να σημαίνει ότι το δείγμα θα αποτελούσε μέρος του μεσαίου 95% των πιο πιθανών δειγμάτων από αυτές τις ΔΠΔ.
Αντί, λοιπόν, να απαντάμε σε μια ερώτηση τύπου ναι/όχι για το αν πρέπει να απορρίψουμε το κενό μοντέλο ή όχι, τα διαστήματα εμπιστοσύνης μας επιτρέπουν να ποσοτικοποιήσουμε τη διακύμανση μιας εκτίμησης και να κάνουμε δηλώσεις όπως: «Είμαστε 95% βέβαιοι ότι η πραγματική παράμετρος στη ΔΠΔ βρίσκεται μεταξύ αυτών των δύο τιμών.» Για να κάνουμε μια τέτοια δήλωση, χρειαζόμαστε έναν τρόπο να βρούμε ένα κατώτερο και ένα ανώτερο όριο για το πού θα μπορούσε να βρίσκεται η πραγματική τιμή του \(\beta_1\).
Μπορούμε να ξεκινήσουμε τοποθετώντας τη ΔΠΔ και τη δειγματοληπτική κατανομή της με κέντρο στο \(b_1 = 6.05\) του δείγματος. Αυτό έχει νόημα, επειδή η τιμή του \(b_1\) είναι η βέλτιστη εκτίμηση που διαθέτουμε για την τιμή της πραγματικής παραμέτρου. Επιπλέον, δειγματική εκτίμηση είναι αμερόληπτη, που σημαίνει ότι αν επαναλαμβάναμε τη δειγματοληψία πολλές φορές, ο μέσος όρος των \(b_1\) θα ήταν ίσος με την πραγματική τιμή \(\beta_1\). Με άλλα λόγια, η δειγματική εκτίμηση δεν έχει συστηματική τάση να υπερεκτιμά ή να υποεκτιμά την τιμή της παραμέτρου. Άρα, για το συγκεκριμένο δείγμα, θεωρούμε ότι η πραγματική τιμή \(\beta_1\) είναι εξίσου πιθανό να βρίσκεται πάνω ή κάτω από το \(b_1 = 6.05\), γεγονός που δικαιολογεί γιατί «χτίζουμε» το διάστημα εμπιστοσύνης συμμετρικά γύρω από αυτή την τιμή.
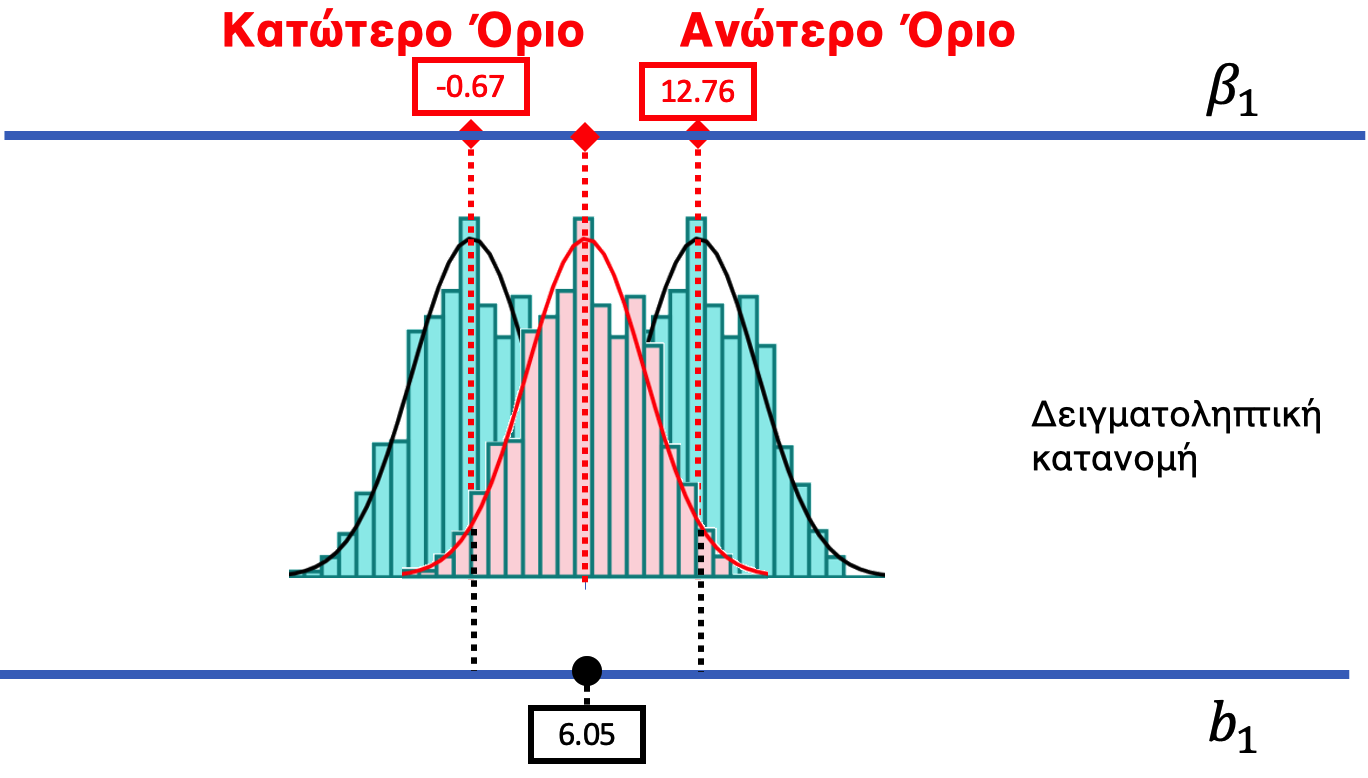
Στο παρακάτω σχήμα, μετακινούμε τη ΔΠΔ και τη δειγματοληπτική κατανομή της προς τα αριστερά, μέχρι να φτάσουμε σε μια τιμή της ΔΠΔ όπου η τιμή \(b_1\) του δείγματος είναι κοντά στο να βρεθεί στην απίθανη περιοχή της ουράς. Όταν μετακινηθούμε στην τιμή \(\beta_1 = -0.67\), μπορούμε να δούμε ότι η τιμή \(b_1\) του δείγματος πέφτει ακριβώς στο όριο αυτού που θα αποκαλούσαμε απίθανο. Έτσι, η τιμή −0.67 είναι η τιμή του \(\beta_1\) που αντιστοιχεί στο κατώτερο όριο του 95% διαστήματος εμπιστοσύνης.

Πώς μπορείτε να καταλάβετε από το παραπάνω σχήμα ότι η δειγματική τιμή 6.05 είναι πιθανό να προέρχεται από μια ΔΠΔ στην οποία \(\beta_1 = -0.67\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η τιμή \(b_1 = 6.05\) βρίσκεται ακριβώς επάνω στο δεξί όριο της δειγματοληπτικής κατανομής για \(\beta_1 = -0.67\) — δηλαδή στο σημείο που χωρίζει την πιθανή περιοχή του 95% από την άνω απίθανη περιοχή του 2.5%. Αυτό σημαίνει ότι βρίσκεται ακόμα «εντός» των ορίων, αν και οριακά.
Αν μετακινούσαμε την τιμή \(\beta_1\) χαμηλότερα από το −0.67, η δειγματοληπτική κατανομή θα μετακινούνταν επίσης πιο αριστερά. Τι θα συνέβαινε με την τιμή \(b_1\) του δείγματος;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η τιμή \(b_1\) του δείγματος είναι σταθερή — δεν αλλάζει. Αλλά αν μετακινήσουμε τη δειγματοληπτική κατανομή ακόμα πιο αριστερά, η τιμή 6.05 θα βρεθεί εκτός της κεντρικής περιοχής του 95%, στην απίθανη περιοχή της άνω ουράς.
Αν μετακινούσαμε το \(\beta_1\) χαμηλότερα από το −0.67, η δειγματοληπτική κατανομή θα μετακινούνταν επίσης πιο κάτω και το παρατηρηρούμενο \(b_1\) θα ήταν όλο και λιγότερο πιθανό να έχει παραχθεί από αυτές τις χαμηλότερες ΔΠΔ. Με αυτόν τον τρόπο, βρήκαμε ένα κατώτερο όριο για το 95% διάστημα εμπιστοσύνης: υπάρχει πιθανότητα μικρότερη από 0.025 (2.5%) για οποιαδήποτε τιμή \(\beta_1\) χαμηλότερη από −0.67 να έχει παράγει μια τιμή \(b_1 = 6.05\).
Ποιος θα ήταν ένας ακριβής ορισμός του «κατώτερου ορίου»;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το κατώτερο όριο του διαστήματος εμπιστοσύνης είναι η χαμηλότερη τιμή \(\beta_1\) για την οποία η παρατηρούμενη \(b_1\) παραμένει εντός της πιθανής περιοχής του 95% της δειγματοληπτικής κατανομής. Για οποιαδήποτε τιμή \(\beta_1\) κάτω από αυτό το όριο, το \(b_1\) του δείγματος θα θεωρείται απίθανο.
Μπορούμε να χρησιμοποιήσουμε παρόμοια προσέγγιση για να βρούμε το ανώτερο όριο του διαστήματος εμπιστοσύνης. Καθώς μετακινούμε τη ΔΠΔ προς τα πάνω (δεξιά), μπορούμε να εξετάσουμε μεγαλύτερες πιθανές τιμές του \(\beta_1\). Σε κάποιο σημείο, καθώς μετακινούμε τη δειγματοληπτική κατανομή προς τα πάνω, θα δούμε το \(b_1\) του δείγματος να πέφτει στην κατώτερη ουρά της δειγματοληπτικής κατανομής. Όταν φτάσουμε στο \(\beta_1 = 12.76\), το \(b_1 = 6.05\) βρίσκεται πέρα από το όριο στην περιοχή που θα αποκαλούσαμε απίθανη. Αυτή η τιμή του \(\beta_1\) θεωρείται το ανώτερο όριο του 95% διαστήματος εμπιστοσύνης.
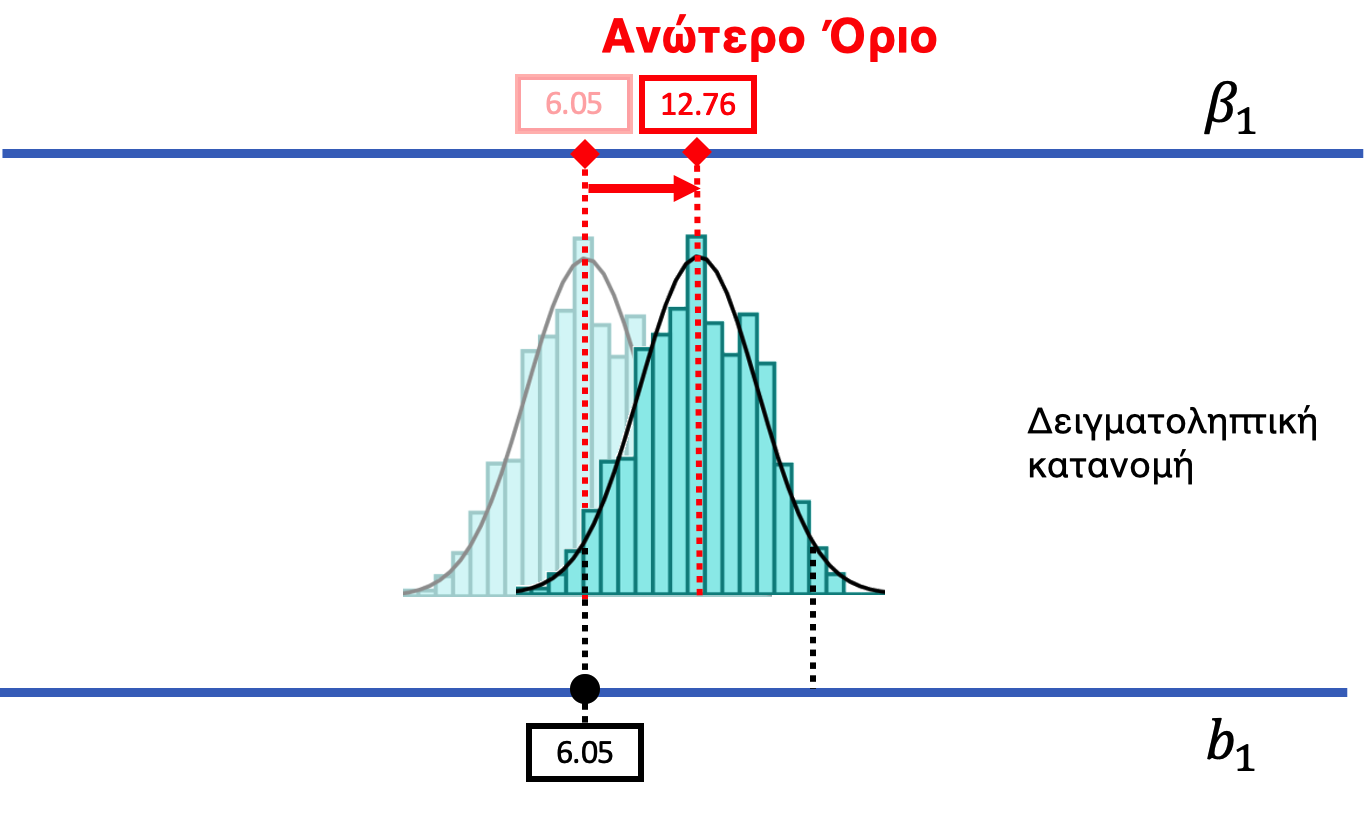
Με δικά σας λόγια, πώς θα ορίζατε το «ανώτερο όριο» ενός διαστήματος εμπιστοσύνης;
Σε ποια κατανομή ορίζονται το ανώτερο και το κατώτερο όριο του διαστήματος εμπιστοσύνης;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Τα όρια του διαστήματος εμπιστοσύνης αναφέρονται στη ΔΠΔ — ορίζουν το εύρος των πιθανών τιμών του \(\beta_1\) (της πραγματικής παραμέτρου) που θα ήταν συμβατές με το παρατηρηθέν \(b_1\) του δείγματος.
Το κατώτερο και ανώτερο όριο ενός διαστήματος εμπιστοσύνης υποδεικνύουν το εύρος των τιμών \(\beta_1\) που θα θεωρούσαμε πιθανό να έχουν παράγει το \(b_1\) του δείγματος.
Συνδυάζοντας όλα τα παραπάνω, μπορούμε να απεικονίσουμε το 95% διάστημα εμπιστοσύνης, και πώς σχετίζεται με τη δειγματοληπτική κατανομή του \(b_1\), ως εξής:

Αν η δειγματική τιμή \(b_1\) έχει πιθανότητα μόνο 2.5% να προέρχεται από μια ΔΠΔ χαμηλότερη από το κατώτερο όριο, και πιθανότητα 2.5% να προέρχεται από ΔΠΔ υψηλότερη από το ανώτερο όριο, τότε συνεπάγεται ότι μπορούμε να είμαστε 95% βέβαιοι ότι το πραγματικό \(\beta_1\) βρίσκεται κάπου μεταξύ των δύο ορίων. Αυτό το διάστημα είναι το 95% διάστημα εμπιστοσύνης.
13.4 Χρήση της Μεθόδου Bootstrap για τον Υπολογισμό του 95% Διαστήματος Εμπιστοσύνης
Η μετακίνηση μιας δειγματοληπτικής κατανομή αριστερά και δεξιά είναι ένας καλός τρόπος για να κατανοήσουμε την έννοια πίσω από τα διαστήματα εμπιστοσύνης, αλλά δεν είναι πολύ καλός τρόπος για να υπολογίσουμε τα πραγματικά ανώτερα και κατώτερα όρια! Σε αυτή την ενότητα θα δούμε μία μέθοδο (μεταξύ πολλών) για τον υπολογισμό ενός διαστήματος εμπιστοσύνης.
Μετακινώντας τη δειγματοληπτική κατανομή, κάνουμε μερικές υποθέσεις. Υποθέτουμε, πρώτα, ότι το σχήμα και η διασπορά της δειγματοληπτικής κατανομής δεν αλλάζουν καθώς τη μετακινούμε αριστερά και δεξιά στην κλίμακα του οριζόντιου άξονα. Η δειγματοληπτική κατανομή είναι περίπου Κανονική για το \(b_1\), που σημαίνει ότι είναι μονοκύρυφη και συμμετρική, με δύο ουρές προς τα αριστερά και τα δεξιά.
Επίσης πρόκειται να υποθέσουμε ότι το κέντρο του διαστήματος εμπιστοσύνης βρίσκεται στην παρατηρούμενη τιμή \(b_1\) του δείγματός μας (π.χ. 6.05 στη μελέτη των φιλοδωρημάτων). Θα επιχειρήσουμε να το δείξουμε αυτό με το παρακάτω σχήμα. Έχουμε χρωματίσει τη δειγματοληπτική κατανομή με κέντρο στο 6.05 με κόκκινο χρώμα. Σχεδιάσαμε επίσης δύο διακεκομμένες μαύρες γραμμές που υποδεικνύουν τα όρια που διαχωρίζουν την πιθανή από την απίθανη περιοχή αυτής της δειγματοληπτικής κατανομής. Πίσω της βρίσκονται οι κατανομές που χρησιμοποιήσαμε για να βρούμε τα ανώτερα και κατώτερα όρια.
Τα δύο όρια του 0.025 ή 2.5% (μαύρες διακεκομμένες γραμμές) στην κόκκινη δειγματοληπτική κατανομή (με κέντρο στην τιμή \(b_1\) του δείγματος) ευθυγραμμίζονται τέλεια με ποιες δύο τιμές;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Αυτή είναι η βασική ιδέα: τα όρια του 0.025 (2.5%) της δειγματοληπτικής κατανομής με κέντρο στην τιμή \(b_1\) του δείγματος αντιστοιχούν ακριβώς στα όρια του 95% διαστήματος εμπιστοσύνης. Αυτό μας δίνει έναν πρακτικό τρόπο να υπολογίσουμε το διάστημα εμπιστοσύνης χωρίς να χρειαστεί να μετακινούμε τη δειγματοληπτική κατανομή.
Το όριο του 0.025 (2.5%) στην αριστερή ουρά της δειγματοληπτικής κατανομής με κέντρο στην τιμή \(b_1\) του δείγματος ευθυγραμμίζεται τέλεια με το κατώτερο όριο του διαστήματος εμπιστοσύνης. Ομοίως, το όριο του 0.025 (2.5%) στη δεξιά ουρά ευθυγραμμίζεται με το ανώτερο όριο του διαστήματος εμπιστοσύνης. Με μια μόνο δειγματοληπτική κατανομή με κέντρο στο \(b_1\), θα μπορούσαμε να υπολογίσουμε τα κατώτερα και ανώτερα όρια.
Η Μέθοδος Bootstrap με τη resample()
Για τον υπολογισμό του διαστήματος εμπιστοσύνης, θα ήταν χρήσιμο να έχουμε μια δειγματοληπτική κατανομή με κέντρο στο \(b_1\) του δείγματος. Δυστυχώς, η συνάρτηση shuffle(), που μιμείται μια ΔΠΔ όπου \(\beta_1 = 0\), παράγει δειγματοληπτική κατανομή με κέντρο στο 0. Αλλά εμείς χρειάζεται να μιμηθούμε μια ΔΠΔ όπου το \(\beta_1\) είναι ίσο με το \(b_1\) του δείγματός μας (6.05).
Μπορούμε να το κάνουμε αυτό με τη συνάρτηση resample(). Η συνάρτηση resample() υποθέτει ότι ολόκληρος ο πληθυσμός αποτελείται από παρατηρήσεις που μοιάζουν ακριβώς με αυτές στο δείγμά μας. Στην περίπτωση του πειράματος των φιλοδωρημάτων, θα υποθέταμε έναν πληθυσμό που αποτελείται από πολλά αντίγραφα των τραπεζιών στο δείγμα του TipExperiment.
Αν πάρουμε πολλά δείγματα από αυτόν τον φανταστικό πληθυσμό, μπορούμε να δημιουργήσουμε μια δειγματοληπτική κατανομή τιμών \(b_1\) που θα έχει κέντρο στο παρατηρούμενο \(b_1\) του δείγματος. Αυτή η προσέγγιση για τη δημιουργία δειγματοληπτικής κατανομής ονομάζεται μέθοδος bootstrap.
Αν πάρουμε ένα δείγμα τραπεζιών από έναν πληθυσμό που αποτελείται από πολλά αντίγραφα των τραπεζιών στο πείραμα φιλοδωρημάτων μας, ποιο πιστεύετε ότι θα είναι το σχήμα της κατανομής της Tip;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Στη μέθοδο bootstrap υποθέτουμε ότι ο πληθυσμός μοιάζει με το δείγμά μας. Άρα η κατανομή της Tip σε αυτόν τον φανταστικό πληθυσμό θα έχει το ίδιο σχήμα με την κατανομή του δείγματός μας — που δεν είναι απαραίτητα κανονική κατανομή.
Χρησιμοποιήσαμε σε άλλο κεφάλαιο του βιβλίου τη συνάρτηση resample() με ένα διάνυσμα (μια λίστα αριθμών) για να προσομοιώσουμε ρίψεις ζαριών. Στη μέθοδο bootstrap, αντί για τιμές από ένα διάνυσμα, θα κάνουμε επαναδειγματοληψία παρατηρήσεων (γραμμών) από ένα πλαίσιο δεδομένων.
Για να δείξουμε πώς γίνεται αυτό, ας εστιάσουμε σε ένα υποσύνολο 6 τραπεζιών από το πλαίσιο δεδομένων TipExperiment. Έχουμε βάλει αυτά τα έξι τραπέζια σε ένα νέο πλαίσιο δεδομένων που ονομάζεται SixTables. Παρακάτω φαίνονται τα περιεχόμενα αυτού του πλαισίου δεδομένων.
TableID Tip Condition
4 34 Control
18 21 Control
43 21 Smiley Face
6 31 Control
25 47 Smiley Face
35 27 Smiley FaceΠαρατηρήστε ότι στο μικρό δείγμα μας των 6 τραπεζιών, υπάρχουν 3 τραπέζια στη συνθήκη του χαμογελαστού προσώπου (Smiley Face) και 3 στη συνθήκη ελέγχου (Control).
Ας δούμε τώρα τι συμβαίνει όταν κάνουμε resample() από αυτό το δείγμα των 6 τραπεζιών.
Στον παρακάτω πίνακα έχουμε βάλει τα αρχικά 6 τραπέζια αριστερά και τα αποτελέσματα της συνάρτησης resample() δεξιά.
| Αρχικά 6 Τραπέζια | 6 Τραπέζια από Επαναδειγματοληψία | |||||
|---|---|---|---|---|---|---|
| TableID | Tip | Condition | TableID | Tip | Condition | |
| 4 | 34 | Control | 43 | 21 | Smiley Face | |
| 18 | 21 | Control | 6 | 31 | Control | |
| 43 | 21 | Smiley Face | 18 | 21 | Control | |
| 6 | 31 | Control | 6 | 31 | Control | |
| 25 | 47 | Smiley Face | 18 | 21 | Control | |
| 35 | 27 | Smiley Face | 35 | 27 | Smiley Face | |
Συγκρίνετε τα αρχικά έξι τραπέζια αριστερά με τα νέα τραπέζια δεξιά. Είναι το νέο σύνολο δεδομένων ακριβώς το ίδιο με το αρχικό; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Γ.
Η συνάρτηση resample() δειγματοληπτεί με αντικατάσταση — κάθε τραπέζι επιστρέφεται στο πλαίσιο δεδομένων μετά την επιλογή του, άρα μπορεί να επιλεγεί ξανά (Β). Αυτό σημαίνει επίσης ότι ορισμένα τραπέζια δεν θα επιλεγούν καθόλου (Γ). Το Δ είναι λάθος — το νέο πλαίσιο δεδομένων περιέχει μόνο παρατηρήσεις που υπάρχουν στο αρχικό.
Η συνάρτηση resample() επιλέγει ένα νέο τυχαίο δείγμα έξι τραπεζιών από το αρχικό σύνολο δεδομένων. Δειγματοληπτεί με επανατοποθέτηση, που σημαίνει ότι όταν η R επιλέγει τυχαία ένα τραπέζι, αυτό μπορεί μετά να επιλεγεί ξανά. Αυτό εξηγεί γιατί ένα τραπέζι από τα αρχικά δεδομένα μπορεί να εμφανίζεται περισσότερες φορές από μία φορές ή και καμία φορά στα νέα δεδομένα.
Αρκετά όμως με τα μόλις έξι τραπέζια!
Ας χρησιμοποιήσουμε τώρα τη resample() για δημιουργήσουμε με τη μέθοδο bootstrap ένα νέο δείγμα 44 τραπεζιών από τα αρχικά τραπέζια της μελέτης φιλοδωρημάτων. Αργότερα, θα επαναλάβουμε αυτή τη διαδικασία πολλές φορές για να δημιουργήσουμε μια δειγματοληπτική κατανομή τιμών \(b_1\). Ας σκεφτούμε τι θα συνέβαινε αν εκτελούσαμε την παρακάτω γραμμή κώδικα στο πλήρες πλαίσιο δεδομένων TipExperiment:
Αν εκτελέσουμε τον κώδικα resample(TipExperiment), ποιο από τα παρακάτω θα ισχύει για το νέο πλαίσιο δεδομένων που θα προκύψει;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η resample() επιλέγει ακριβώς τόσες γραμμές όσες υπάρχουν στο αρχικό data frame (44 τραπέζια) — αλλά με αντικατάσταση. Άρα ο συνολικός αριθμός γραμμών παραμένει ίδιος (Γ), αλλά η κατανομή ανά συνθήκη (Α), οι μέσοι (Β) και το \(b_1\) (Δ) θα μεταβάλλονται σε κάθε resample.
Τόσο το νέο όσο και το αρχικό πλαίσιο δεδομένων θα έχουν 44 τραπέζια. Ωστόσο, επειδή ορισμένα τραπέζια μπορεί να επιλεγούν περισσότερες από μία φορές στο νέο πλαίσιο δεδομένων, και άλλα καθόλου, ο αριθμός των τραπεζιών σε κάθε συνθήκη δεν θα ταιριάζει ακριβώς με τους αριθμούς στο αρχικό πλαίσιο δεδομένων. (Δεν θα ανησυχήσουμε γι’ αυτό προς το παρόν.)
Μπορούμε επίσης να δούμε ότι ο μέσος όρος της Tip για κάθε συνθήκη θα είναι διαφορετικός στο νέο πλαίσιο δεδομένων. Αυτό είναι λογικό επειδή τα τραπέζια που περιλαμβάνονται δεν είναι τα ίδια στα δύο πλαίσια δεδομένων.
Χρησιμοποιήστε το παρακάτω τμήμα κώδικα για να παράγετε την εκτίμηση \(b_1\) για το μοντέλο της Condition τόσο στα αρχικά όσο και στα πλαίσια δεδομένων που προκύπτουν μετά την εφαρμογή της μεθόδου bootstrap. Εκτελέστε τον κώδικα μερικές φορές και δείτε τι παρατηρείτε.
Τι παρατηρείτε ότι αλλάζει κάθε φορά που εκτελείτε αυτές τις δύο γραμμές κώδικα; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Δ.
Η πρώτη τιμή \(b_1\) (από το αρχικό TipExperiment) είναι πάντα 6.05 — τα δεδομένα δεν αλλάζουν (Β). Η δεύτερη \(b_1\) (από το resample(TipExperiment)) αλλάζει κάθε φορά επειδή κάθε επαναδειγματοληψία δημιουργεί ένα διαφορετικό τυχαίο σύνολο δεδομένων (Δ). Το Γ είναι λάθος — δεν προέρχεται από κανονική κατανομή αλλά από τυχαία δειγματοληψία με αντικατάσταση.
Κάθε φορά που εκτελείτε τον κώδικα θα λαμβάνετε δύο τιμές \(b_1\). Η πρώτη βασίζεται στο αρχικό πλαίσιο δεδομένων, και θα είναι πάντα 6.05· αυτό το γνωρίζουμε ήδη! Αλλά η δεύτερη τιμή \(b_1\) θα μεταβάλλεται κάθε φορά που εκτελείτε τον κώδικα. Αυτό συμβαίνει επειδή κάθε φορά που εκτελείτε τον κώδικα, η R υπολογίζει τη διαφορά μέσων όρων στο ποσοστό φιλοδωρήματος μεταξύ της ομάδας χαμογελαστού προσώπου και της ομάδας ελέγχου σε μια νέα εκδοχή του πλαισίου δεδομένων.
13.5 Χρήση της Δειγματοληπτικής Κατανομής Bootstrap για την Εύρεση του Διαστήματος Εμπιστοσύνης
Χρήση της resample() για Bootstrap Δειγματοληπτικής Κατανομής
Τώρα που έχουμε θυμηθεί τι κάνει η συνάρτηση resample(), ας τη χρησιμοποιήσουμε για να δημιουργήσουμε μια δειγματοληπτική κατανομή 1.000 τιμών \(b_1\).
Τροποποιήστε τον κώδικα στο παρακάτω πλαίσιο για να δημιουργήσετε μια δειγματοληπτική κατανομή 1.000 τιμών \(b_1\), κάθε μία με βάση ένα νέο δείγμα που προκύπτει από επαναδειγματοληψία των αρχικών δεδομένων, και αποθηκεύστε την σε ένα νέο πλαίσιο δεδομένων που ονομάζεται sdob1_boot. Έπειτα δημιουργήστε ένα ιστόγραμμα της δειγματοληπτικής κατανομής.

Χρησιμοποιήστε τη συνάρτηση favstats() για να δείτε ποιος είναι ο μέσος όρος των τιμών \(b_1\) στο sdob1_boot.
min Q1 median Q3 max mean sd n missing
-3.219048 3.772727 5.921166 8.480083 15.96154 6.110566 3.381418 1000 0Ο μέσος όρος είναι αρκετά κοντά στο 6.05, τη δειγματική τιμή \(b_1\) από τη μελέτη των φιλοδωρημάτων. Επειδή η νέα δειγματοληπτική κατανομή είναι κεντραρισμένη περίπου στη δειγματική τιμή \(b_1\), μας δίνει αυτό που χρειαζόμαστε για τον υπολογισμό του 95% διαστήματος εμπιστοσύνης για την \(\beta_1\): μια δειγματοληπτική κατανομή με κέντρο στην τιμή \(b_1\) του δείγματος.
Χρήση της Δειγματοληπτικής Κατανομής Bootstrap για την Εύρεση του Διαστήματος Εμπιστοσύνης
Έχουμε τώρα πετύχει να δημιουργήσουμε μια δειγματοληπτική κατανομή bootstrap 1.000 τιμών \(b_1\) με κέντρο στο \(b_1\) του δείγματος (περίπου 6.05) χρησιμοποιώντας τη συνάρτηση resample(). Για να βρούμε τα κατώτερα και ανώτερα όρια του διαστήματος εμπιστοσύνης, θα χρησιμοποιήσουμε τη δειγματοληπτική κατανομή των \(b_1\) ως κατανομή πιθανότητας, ερμηνεύοντας την αναλογία τιμών \(b_1\) που βρίσκονται σε ένα συγκεκριμένο εύρος ως πιθανότητα να βρεθούν μελλοντικές τιμές \(b_1\) στο ίδιο εύρος.
Θέλουμε να βρούμε τα όρια που διαχωρίζουν το μεσαίο 95% της δειγματοληπτικής κατανομής από τις κατώτερες και ανώτερες ουρές του 2.5%, επειδή αυτά τα όρια θα αντιστοιχούν τέλεια με τα κατώτερα και ανώτερα όρια του διαστήματος εμπιστοσύνης.
Για να το κάνουμε αυτό, ξεκινάμε τοποθετώντας τις 1.000 τιμές \(b_1\) σε σειρά. Στη συνέχεια μπορούμε να βρούμε τα όρια που διαχωρίζουν τις υψηλότερες 25 και τις χαμηλότερες 25 τιμές \(b_1\) από τις μεσαίες 950 τιμές.
Μπορούμε να αναπαραστήσουμε διαγραμματικά αυτή τη διαδικασία χρωματίζοντας το μεσαίο 95% διαφορετικά από τις ουρές (.025 σε κάθε ουρά) όπως φαίνεται στο παρακάτω ιστόγραμμα.

Ποιος νομίζετε ότι είναι ο μέσος όρος αυτής της δειγματοληπτικής κατανομής; Γιατί;
Όπως φαίνεται στο παρακάτω σχήμα, το όριο για το κατώτερο .025 (2.5%) των τιμών \(b_1\) βρίσκεται στη 26η τιμή \(b_1\). Το όριο για το ανώτερο .025 (2.5%) βρίσκεται στη 975η τιμή \(b_1\). Αυτά τα δύο όρια αντιστοιχούν στα κατώτερα και ανώτερα όρια του διαστήματος εμπιστοσύνης.

Δίνεται ο κώδικας που θα τοποθετήσει τις τιμές \(b_1\) στη σειρά (από τη χαμηλότερη στην υψηλότερη) και θα αποθηκεύσει τα αναδιατεταγμένα δεδομένα ξανά στο sdob1_boot.
Για να εντοπίσουμε την 26η τιμή \(b_1\) στο ταξινομημένο πλαίσιο δεδομένων (26η από την αρχή), μπορούμε να χρησιμοποιήσουμε αγκύλες (π.χ. [26]).
Χρησιμοποιήστε το παρακάτω τμήμα κώδικα για να εμφανίσετε και την 26η και την 975η τιμή \(b_1\).
[1] -0.02484472
[1] 13.3Με βάση τη δειγματοληπτική κατανομή bootstrap του \(b_1\), το 95% διάστημα εμπιστοσύνης εκτείνεται από περίπου 0 έως 13 (κατά προσέγγιση). Οι δικές σας τιμές θα διαφέρουν ελαφρώς από τις δικές μας, φυσικά, επειδή παράγονται τυχαία. Το συμπέρασμα είναι ότι μπορούμε να είμαστε 95% βέβαιοι ότι η πραγματική τιμή του \(\beta_1\) στη ΔΠΔ βρίσκεται σε αυτό το εύρος.
13.6 Τυχαίο Ανακάτεμα, Επαναδειγματοληψία, και Τυπικό Σφάλμα
Ξεκινήσαμε με την ιδέα ότι θα μπορούσαμε να μετακινήσουμε τη δειγματοληπτική κατανομή του \(b_1\) αριστερά και δεξιά στον άξονα για να βρούμε το κατώτερο και το ανώτερο όριο του διαστήματος εμπιστοσύνης. Παρατηρώντας ότι το κέντρο αυτού του διαστήματος εμπιστοσύνης βρισκόταν ακριβώς στο \(b_1\) του δείγματος, χρησιμοποιήσαμε τη συνάρτηση resample() για να δημιουργήσουμε με τη μέθοδο bootstrap μια δειγματοληπτική κατανομή που θα ήταν κεντραρισμένη στο \(b_1\) του δείγματος. Αυτό μας βοήθησε να υπολογίσουμε το ανώτερο και το κατώτερο όριο.
Για να τα κάνουμε όλα αυτά, ωστόσο, υποθέσαμε ότι οι δειγματοληπτικές κατανομές που παράγονται από διαφορετικές ΔΠΔ (π.χ. διαφορετικές τιμές του \(\beta_1\), όπως 0.00, 6.05, 13.00 κ.λπ.) θα είχαν όλες το ίδιο σχήμα και την ίδια διασπορά. Έχουμε χρησιμοποιήσει πλέον δύο μεθόδους για να δημιουργήσουμε δειγματοληπτικές κατανομές του \(b_1\), καθεμία βασισμένη σε μια διαφορετική ΔΠΔ. Έχουν αυτές οι δειγματοληπτικές κατανομές το ίδιο σχήμα και την ίδια διασπορά;
Me τη συνάρτηση shuffle(), προσομοιώσαμε μια ΔΠΔ στην οποία \(\beta_1 = 0\) (δηλαδή, όπου το κενό μοντέλο είναι αληθές). Αυτή απεικονίζεται στο αριστερό πλαίσιο του παρακάτω σχήματος. Χρησιμοποιώντας τη συνάρτηση resample() (δεξί πλαίσιο του σχήματος), προσομοιώσαμε μια ΔΠΔ στην οποία η πραγματική τιμή του \(\beta_1\) είναι 6.05, δηλαδή η ίδια με το \(b_1\) του δείγματος.
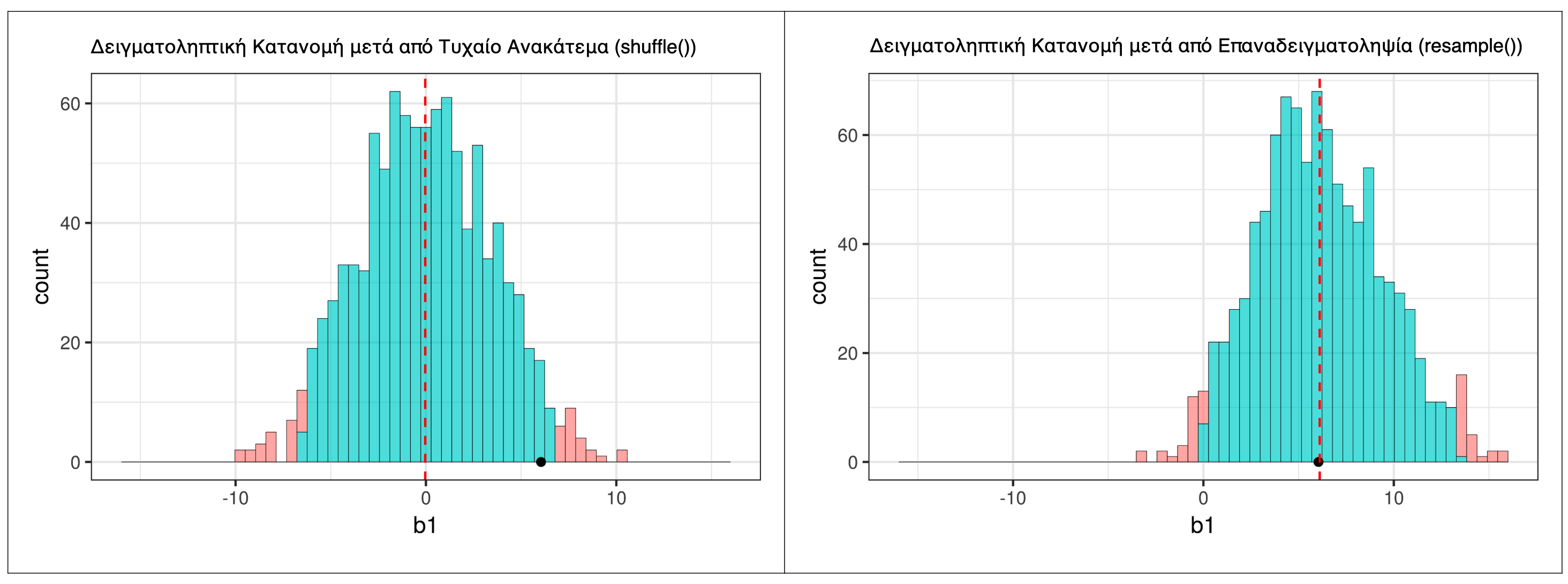
Πώς θα συγκρίνατε το σχήμα αυτών των δύο δειγματοληπτικών κατανομών που παράγονται από διαφορετικές ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Και οι δύο δειγματοληπτικές κατανομές είναι μονοκόρυφες, περίπου συμμετρικές και κωδωνοειδείς — δηλαδή σχεδόν κανονικές στο σχήμα. Δεν χρειάζεται να μοιάζουν με την κατανομή του δείγματος των αρχικών δεδομένων· το Κεντρικό Οριακό Θεώρημα μας λέει ότι οι δειγματοληπτικές κατανομές του \(b_1\) τείνουν προς την κανονική κατανομή ανεξάρτητα από το σχήμα των αρχικών δεδομένων.
Πώς θα συγκρίνατε τη διασπορά αυτών των δύο δειγματοληπτικών κατανομών που παράγονται από διαφορετικές ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Και οι δύο κατανομές εκτείνονται περίπου από το −10 έως το 10 (αριστερά) και από το −4 έως περίπου το 16 (δεξιά) — δηλαδή και οι δύο έχουν εύρος περίπου 20 μονάδων. Αυτό επιβεβαιώνει την υπόθεση που κάναμε νωρίτερα: το σχήμα και η διασπορά της δειγματοληπτικής κατανομής παραμένουν ουσιαστικά τα ίδια όταν μετακινούμε τη ΔΠΔ αριστερά ή δεξιά στον άξονα.
Πώς θα συγκρίνατε τα κέντρα των δύο δειγματοληπτικών κατανομών;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η δειγματοληπτική κατανομή που δημιουργήθηκε με τη shuffle() είναι κεντραρισμένη στο 0, επειδή προσομοιώνει μια ΔΠΔ στην οποία \(\beta_1 = 0\) (κενό μοντέλο). Η δειγματοληπτική κατανομή που δημιουργήθηκε με τη resample() είναι κεντραρισμένη περίπου στο 6.05, επειδή προσομοιώνει μια ΔΠΔ στην οποία η πραγματική τιμή \(\beta_1\) είναι ίση με το \(b_1\) του δείγματος. Αυτή είναι ακριβώς η διαφορά που θέλαμε — ίδιο σχήμα και διασπορά, αλλά διαφορετικό κέντρο.
Παρόλο που τα κέντρα των δύο δειγματοληπτικών κατανομών είναι διαφορετικά, τα σχήματα των δύο κατανομών είναι παρόμοια. Και οι δύο είναι περίπου κανονικές και συμμετρικές. Αν και η κατανομή που δημιουργήθηκε από τη resample() φαίνεται κάπως ασύμμετρη — παρουσιάζει μια ελαφριά ασυμμετρία προς τα δεξιά — θα τη θεωρήσουμε, προς το παρόν, αρκετά κοντά στο να είναι συμμετρική.
Η Σημασία του Τυπικού Σφάλματος
Το πιο σημαντικό χαρακτηριστικό των δειγματοληπτικών κατανομών, ωστόσο, είναι η διασπορά τους. Μπορούμε να εκτιμήσουμε το εύρος με το μάτι στα παραπάνω ιστογράμματα (π.χ. και στα δύο είναι περίπου 20) και ήδη να διαπιστώσουμε ότι είναι παρόμοια. Ένα πιο συχνά χρησιμοποιούμενο μέτρο διασποράς είναι το τυπικό σφάλμα (standard error). Στο παρακάτω πλαίσιο κώδικα, χρησιμοποιήστε τη συνάρτηση favstats() για να υπολογίσετε τα τυπικά σφάλματα των δύο δειγματοληπτικών κατανομών: αυτή που δημιουργήθηκε με τη shuffle() και αυτή που δημιουργήθηκε με τη resample(). (Έχουμε συμπεριλάβει τον κώδικα για τη δημιουργία των δύο δειγματοληπτικών κατανομών.)
Στο πρώτο αποτέλεσμα παρακάτω εμφανίζουμε τα favstats για τις τιμές \(b_1\) που δημιουργήθηκαν με τη shuffle(). Στη δεύτερη, εμφανίζουμε τα favstats για τις τιμές που δημιουργήθηκαν με τη resample().
min Q1 median Q3 max mean sd n missing
-9.954545 -2.5 -0.04545455 2.5 10.22727 -0.03554545 3.498973 1000 0 min Q1 median Q3 max mean sd n missing
-3.219048 3.772727 5.921166 8.480083 15.96154 6.110566 3.381418 1000 0Εξετάστε τους μέσους όρους των δύο δειγματοληπτικών κατανομών. Συμφωνούν με αυτό που θα περιμένατε;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η δειγματοληπτική κατανομή που δημιουργήθηκε με τη shuffle() προσομοιώνει μια ΔΠΔ όπου \(\beta_1 = 0\), οπότε περιμένουμε το μέσο όρο της να είναι κοντά στο 0 (και είναι: −0.04). Η δειγματοληπτική κατανομή που δημιουργήθηκε με τη resample() προσομοιώνει μια ΔΠΔ όπου η πραγματική τιμή \(\beta_1\) είναι ίση με το \(b_1\) του δείγματος (6.05), οπότε περιμένουμε το μέσο όρο της να είναι κοντά στο 6.05 (και είναι: 6.11). Η απάντηση Β είναι λάθος επειδή δεν θα μπορούσαμε να έχουμε προβλέψει τις ακριβείς τιμές — μόνο ότι θα ήταν κοντά στις αναμενόμενες.
Με βάση τα παραπάνω αποτελέσματα τι μπορείτε να πείτε για το τυπικό σφάλμα των δύο δειγματοληπτικών κατανομών του \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Το τυπικό σφάλμα μιας δειγματοληπτικής κατανομής είναι η τυπική απόκλιση των τιμών της. Άρα η στήλη sd στα αποτελέσματα της favstats() μας δίνει ακριβώς αυτό που ψάχνουμε. Για την κατανομή από τη shuffle(), το τυπικό σφάλμα είναι 3.50, και για την κατανομή από τη resample() είναι 3.38 — δηλαδή πολύ κοντά μεταξύ τους. Αυτό επιβεβαιώνει την υπόθεση που κάναμε: η διασπορά της δειγματοληπτικής κατανομής παραμένει ουσιαστικά η ίδια ανεξάρτητα από την τιμή του \(\beta_1\) στη ΔΠΔ.
Τα αποτελέσματα της favstats() φανερώνουν ότι οι μέσοι όροι των δύο δειγματοληπτικών κατανομών είναι περίπου όπως αναμενόταν: η κατανομή που προέκυψε από τυχαίο ανακάτεμα έχει μέσο όρο αρκετά κοντά στο 0, και η κατανομή που προέκυψε από επαναδειγματοληψία έχει μέσο όρο κοντά στη δειγματική τιμή \(b_1 = 6.05\).
Ενώ οι μέσοι όροι είναι διαφορετικοί (0 έναντι 6.05), οι τυπικές αποκλίσεις των δύο κατανομών είναι αρκετά παρόμοιες μεταξύ τους: 3.50 για την κατανομή μετά από τυχαίο ανακάτεμα και 3.38 για την κατανομή μετά απο επαναδειγματοληψία. Επειδή αυτές είναι τυπικές αποκλίσεις δειγματοληπτικών κατανομών, τις ονομάζουμε τυπικά σφάλματα (standard errors).
Το γεγονός ότι τα τυπικά σφάλματα είναι παρόμοια αποτελεί ένα σημαντικό χαρακτηριστικό των δειγματοληπτικών κατανομών. Η σταθερότητα του τυπικού σφάλματος, μαζί με το σχήμα, είναι αυτό που μας επιτρέπει να υποθέτουμε ότι μπορούμε να μετακινούμε δειγματοληπτικές κατανομές αριστερά και δεξιά στον άξονα x όταν κατασκευάζουμε ένα διάστημα εμπιστοσύνης.
Αν η δειγματοληπτική κατανομή έχει μεγαλύτερο τυπικό σφάλμα, τι θα σήμαινε αυτό για ένα διάστημα εμπιστοσύνης που κατασκευάζεται από αυτή τη δειγματοληπτική κατανομή;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το τυπικό σφάλμα είναι ο πιο σημαντικός παράγοντας που καθορίζει το εύρος του διαστήματος εμπιστοσύνης: όσο μεγαλύτερο το τυπικό σφάλμα, τόσο ευρύτερο θα είναι το διάστημα εμπιστοσύνης.
Ένα μεγαλύτερο τυπικό σφάλμα σημαίνει ότι η διασπορά της δειγματοληπτικής κατανομής είναι μεγαλύτερη, πράγμα που με τη σειρά του σημαίνει ότι υπάρχει περισσότερη μεταβλητότητα (ή αβεβαιότητα) στην εκτίμησή μας. Αν υπάρχει περισσότερη μεταβλητότητα στην εκτίμηση, θα πρέπει να είμαστε λιγότερο βέβαιοι ότι η βέλτιστη εκτίμησή μας αντικατοπτρίζει την πραγματική παράμετρο.
Ένας Μαθηματικός Τύπος για το Τυπικό Σφάλμα
Όταν η R μοντελοποιεί μια δειγματοληπτική κατανομή ως κατανομή \(t\), κάνει τον δικό της υπολογισμό για το τυπικό σφάλμα. Το κάνει αυτό με βάση έναν τύπο, που αναπτύχθηκε από μαθηματικούς, ο οποίος αποτελεί μέρος ενός θεωρήματος που ονομάζεται Κεντρικό Οριακό Θεώρημα (Central Limit Theorem).
Το Κεντρικό Οριακό Θεώρημα παρέχει έναν τρόπο εύρεσης του τυπικού σφάλματος μιας δειγματοληπτικής κατανομής με βάση την εκτιμώμενη διακύμανση της εξαρτημένης μεταβλητής. Για τη δειγματοληπτική κατανομή του \(b_1\), όταν το \(b_1\) είναι η διαφορά μεταξύ δύο ομάδων, το τυπικό σφάλμα μπορεί να εκτιμηθεί με τον παρακάτω τύπο:
\[SE_{b_1} = \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}\]
Το \(s_1^2\) σε αυτόν τον τύπο είναι η διακύμανση της εξαρτημένης μεταβλητής (Tip) για την ομάδα 1, που στο παράδειγμά μας θα ήταν η ομάδα ελέγχου (Control). Το \(n_1\) είναι το μέγεθος του δείγματος για την ομάδα ελέγχου. Αντίστοιχα, για την ομάδα Smiley Face θα είναι \(s_2^2\) και \(n_2\).
Μην ανησυχείτε, δεν θα χρειαστεί να εφαρμόσετε εσείς αυτόν τον τύπο για να κάνετε τους υπολογισμούς. Απλώς θέλουμε να γνωρίζετε τι κάνει η R όταν χρησιμοποιεί μια κατανομή \(t\). Δεν ανακατεύει τυχαία ούτε εφαρμοζει τη μέθοδο bootstrap για να δημιουργήσει μια δειγματοληπτική κατανομή και μετά υπολογίζει την τυπική απόκλιση της δειγματοληπτικής κατανομής. Απλώς χρησιμοποιεί τον παραπάνω τύπο.
Μπορούμε να χρησιμοποιήσουμε τον παρακάτω κώδικα (δεν χρειάζεται να τον απομνημονεύσετε) για να προσαρμόσουμε το μοντέλο της Condition στην Tip (αυτό το έχετε κάνει πολλές φορές μέχρι τώρα), και στη συνέχεια να παράγουμε τις εκτιμήσεις και τα τυπικά σφάλματα για τις εκτιμήσεις των παραμέτρων \(b_0\) και \(b_1\).
Estimate Std. Error t value Pr(>|t|)
(Intercept) 27.000000 2.351419 11.482428 1.546877e-14
ConditionSmiley Face 6.045455 3.325409 1.817958 7.620787e-02Στα παραπάνω αποτελέσματα, πού πρέπει να κοιτάξετε για να βρείτε τις εκτιμήσεις των παραμέτρων \(b_0\) και \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η στήλη Estimate περιέχει τις εκτιμήσεις των παραμέτρων: η γραμμή (Intercept) δίνει την εκτίμηση \(b_0 = 27.00\) (το μέσο όρο της ομάδας ελέγχου), και η γραμμή ConditionSmiley Face δίνει την εκτίμηση \(b_1 = 6.05\) (τη διαφορά μεταξύ των δύο ομάδων). Η απάντηση Α δείχνει μόνο μία από τις δύο γραμμές — η εκτίμηση του \(b_0\) βρίσκεται στη γραμμή (Intercept). Η στήλη Std. Error περιέχει τα τυπικά σφάλματα, όχι τις εκτιμήσεις.
Τι είναι η τιμή 3.33; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Δ.
Η τιμή 3.33 είναι το τυπικό σφάλμα του \(b_1\) (Β), το οποίο εξ ορισμού είναι μια εκτίμηση της τυπικής απόκλισης της δειγματοληπτικής κατανομής των \(b_1\) (Δ) — αυτά τα δύο λένε το ίδιο πράγμα με διαφορετικό τρόπο. Παρατηρήστε πόσο κοντά είναι αυτή η τιμή στις τυπικές αποκλίσεις που υπολογίσαμε νωρίτερα από τις προσομοιωμένες δειγματοληπτικές κατανομές (3.50 και 3.38) — η R το υπολόγισε αυτό χρησιμοποιώντας τον τύπο του Κεντρικού Οριακού Θεωρήματος αντί για προσομοίωση. Η απάντηση Α είναι λάθος επειδή η τυπική απόκλιση της Tip αναφέρεται στα ίδια τα δεδομένα, όχι στη δειγματοληπτική κατανομή. Η Γ είναι λάθος επειδή αφορά δειγματοληπτική κατανομή μέσων όρων, όχι \(b_1\). Η Ε είναι λάθος επειδή η πραγματική \(\beta_1\) είναι άγνωστη — αυτή που προσπαθούμε να εκτιμήσουμε.
Η εκτίμηση \(b_1\) βρίσκεται στη δεύτερη γραμμή της στήλης Estimate. Όπως αναμενόταν, είναι 6.05. Το τυπικό σφάλμα της εκτίμησης (που είναι ένας άλλος τρόπος να πούμε την τυπική απόκλιση της δειγματοληπτικής κατανομής) είναι 3.33.
Έχουμε τώρα τρεις διαφορετικές εκτιμήσεις του τυπικού σφάλματος της δειγματοληπτικής κατανομής του \(b_1\): 3.50, 3.38, και 3.33 (από το τυχαίο ανακάτεμα, την επαναδειγματοληψία, και τον μαθηματικό τύπο, αντίστοιχα). Το σημαντικό που πρέπει να παρατηρήσουμε είναι ότι είναι όλες αρκετά κοντά μεταξύ τους.
13.7 Χρήση της Κατανομής \(t\) για την Κατασκευή Διαστήματος Εμπιστοσύνης
Όπως χρησιμοποιήσαμε την κατανομή \(t\) στο προηγούμενο κεφάλαιο για να μοντελοποιήσουμε τη δειγματοληπτική κατανομή του \(b_1\) με σκοπό τον υπολογισμό μιας τιμής \(p\) (η προσέγγιση που χρησιμοποιείται από τη συνάρτηση supernova()), μπορούμε να τη χρησιμοποιήσουμε εδώ για να υπολογίσουμε ένα 95% διάστημα εμπιστοσύνης.
Στο παρακάτω σχήμα, αντικαταστήσαμε τη δειγματοληπτική κατανομή των \(b_1\) μετά από επαναδειγματοληψία με μία που μοντελοποιείται από την εξομαλυμένη κατανομή \(t\) με το αντίστοιχο τυπικό σφάλμα. Όπως και πριν, μπορούμε νοητά να μετακινήσουμε την κατανομή \(t\) αριστερά και δεξιά στην κλίμακα του οριζόντιου άξονα για να βρούμε το κατώτερο και το ανώτερο όριο του διαστήματος εμπιστοσύνης.

Η συνάρτηση της R που υπολογίζει ένα διάστημα εμπιστοσύνης με βάση την κατανομή \(t\) είναι η confint().
Παρακάτω δίνεται ο κώδικας που μπορείτε να χρησιμοποιήσετε για να υπολογίσετε απευθείας ένα 95% διάστημα εμπιστοσύνης που χρησιμοποιεί την κατανομή \(t\) ως μοντέλο της δειγματοληπτικής κατανομής του \(b_1\):
Η συνάρτηση confint() δέχεται ως όρισμα ένα μοντέλο, το οποίο προκύπτει από την εκτέλεση της συνάρτησης lm(). Σε αυτή την περίπτωση, απλώς πληκτρολογήσαμε τη συνάρτηση confint() γύρω από τον κώδικα της lm(). Θα μπορούσατε να πετύχετε το ίδιο αποτέλεσμα χρησιμοποιώντας δύο γραμμές κώδικα — την πρώτη για να δημιουργήσετε το μοντέλο και τη δεύτερη για να εκτελέσετε τη confint(). Δοκιμάστε το στο παρακάτω πλαίσιο κώδικα.
2.5 % 97.5 %
(Intercept) 22.254644 31.74536
ConditionSmiley Face -0.665492 12.75640Όπως βλέπετε, η συνάρτηση confint() επιστρέφει το 95% διάστημα εμπιστοσύνης για τις δύο παραμέτρους που εκτιμούμε στο μοντέλο της Condition. Η πρώτη, που φέρει το όνομα Intercept, είναι το διάστημα εμπιστοσύνης για το \(\beta_0\), το οποίο, σας υπενθυμίζουμε, είναι ο μέσος όρος της ομάδας Control. Η δεύτερη γραμμή μας δείχνει αυτό που μας ενδιαφέρει εδώ, δηλαδή το διάστημα εμπιστοσύνης για το \(\beta_1\).
Χρησιμοποιώντας αυτή τη μέθοδο, το 95% διάστημα εμπιστοσύνης για το \(\beta_1\) εκτείνεται από −0.67 έως 12.76. Ας συγκρίνουμε αυτό το διάστημα εμπιστοσύνης με εκείνο που υπολογίσαμε νωρίτερα στην προηγούμενη σελίδα χρησιμοποιώντας τη μέθοδο bootstrap: από 0 έως 13. Αν και αυτά τα δύο διαστήματα εμπιστοσύνης δεν είναι ακριβώς τα ίδια, είναι εξαιρετικά κοντά, γεγονός που μας οδηγεί στο συμπέρασμα ότι ακόμη και όταν χρησιμοποιούμε πολύ διαφορετικές μεθόδους για την κατασκευή του διαστήματος εμπιστοσύνης, λαμβάνουμε πολύ παρόμοια αποτελέσματα.
Περιθώριο Σφάλματος
Ένας τρόπος να αναφέρουμε ένα διάστημα εμπιστοσύνης είναι απλώς να πούμε ότι εκτείνεται, για παράδειγμα, από το −0.67 έως το 12.76. Αλλά ένας άλλος συνηθισμένος τρόπος να πούμε το ίδιο πράγμα είναι να αναφέρουμε τη δειγματική εκτίμηση (6.05) συν ή πλην το περιθώριο σφάλματος (margin of error) (6.72), το οποίο θα μπορούσατε να το γράψετε ως εξής: \(6.05 \pm 6.72\).
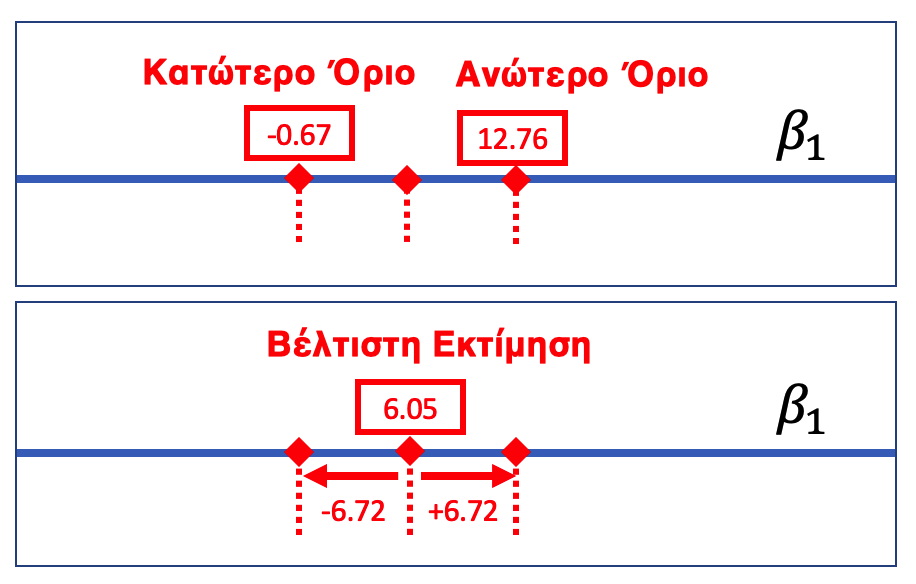 Το περιθώριο σφάλματος είναι η απόσταση μεταξύ του ανώτερου ορίου και της δειγματικής εκτίμησης. Στην περίπτωση του πειράματος των φιλοδωρημάτων αυτό θα ήταν \(12.76 - 6.05\), δηλαδή 6.72. Αν υποθέσουμε ότι η δειγματοληπτική κατανομή είναι συμμετρική, το περιθώριο σφάλματος θα είναι το ίδιο κάτω από τη τιμή της εκτίμησης της παραμέτρου όσο και από πάνω.
Το περιθώριο σφάλματος είναι η απόσταση μεταξύ του ανώτερου ορίου και της δειγματικής εκτίμησης. Στην περίπτωση του πειράματος των φιλοδωρημάτων αυτό θα ήταν \(12.76 - 6.05\), δηλαδή 6.72. Αν υποθέσουμε ότι η δειγματοληπτική κατανομή είναι συμμετρική, το περιθώριο σφάλματος θα είναι το ίδιο κάτω από τη τιμή της εκτίμησης της παραμέτρου όσο και από πάνω.
Μπορούμε να υπολογίσουμε το περιθώριο σφάλματος χρησιμοποιώντας τη confint() για να πάρουμε το ανώτερο όριο του διαστήματος εμπιστοσύνης και στη συνέχεια να αφαιρέσουμε τη δειγματική εκτίμηση. Αλλά μπορούμε να κάνουμε και έναν πρόχειρο υπολογισμό του περιθωρίου σφάλματος χρησιμοποιώντας τον λεγόμενο εμπειρικό κανόνα της Κανονικής κατανομής. Σύμφωνα με τον εμπειρικό κανόνα, το 95% όλων των παρατηρήσεων κάτω από μια καμπύλη Κανονικής κατανομής βρίσκεται μέσα σε συν ή πλην 2 τυπικές αποκλίσεις από το μέσο όρο.
Εφαρμόζοντας αυτόν τον κανόνα στη δειγματοληπτική κατανομή, το παρακάτω σχήμα δείχνει ότι το περιθώριο σφάλματος είναι περίπου ίσο με δύο τυπικά σφάλματα. Αν ξεκινήσουμε με μια κατανομή \(t\) κεντραρισμένη στη δειγματική τιμή \(b_1\), θα χρειαστεί να τη μετακινήσουμε προς τα δεξιά κατά περίπου δύο τυπικά σφάλματα μέχρι να φτάσουμε στο σημείο όπου η δειγματική τιμή \(b_1\) (6.05) θα βρίσκεται οριακά στην κατώτερη ουρά του .025 της νέας κατανομής. Αυτό το σημείο αντιστοιχεί στο ανώτερο όριο του διαστήματος εμπιστοσύνης.

Ποιοι από τους παρακάτω είναι ισοδύναμοι τρόποι για να εκφράσουμε το περιθώριο σφάλματος για τη δειγματική εκτίμηση του \(b_1\) στο μοντέλο της Condition; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β, Δ και Ε.
Το περιθώριο σφάλματος είναι περίπου 6.72 ποσοστιαίες μονάδες (Β) — αυτή είναι η απόσταση από το \(b_1 = 6.05\) έως το ανώτερο όριο 12.76. Αυτό ισούται περίπου με 2 τυπικά σφάλματα (Δ: \(2 \times 3.33 \approx 6.66\)), και εφόσον το τυπικό σφάλμα είναι η τυπική απόκλιση της δειγματοληπτικής κατανομής των \(b_1\), μπορούμε επίσης να πούμε ότι είναι περίπου 2 τυπικές αποκλίσεις στη δειγματοληπτική κατανομή των \(b_1\) (Ε). Η απάντηση Α είναι λάθος επειδή το 3.36 δεν είναι το τυπικό σφάλμα (το σωστό είναι 3.33). Η απάντηση Γ είναι λάθος — η μονάδα μέτρησης είναι ποσοστιαίες μονάδες φιλοδωρήματος, όχι δολάρια.
Ποιες από τις παρακάτω προτάσεις είναι αληθείς; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Δ.
Επειδή υποθέτουμε ότι η δειγματοληπτική κατανομή είναι συμμετρική γύρω από την εκτίμηση της παραμέτρου, τα όρια του διαστήματος εμπιστοσύνης είναι ισαπέχοντα: το ανώτερο όριο βρίσκεται περίπου 2 τυπικά σφάλματα πάνω από τη δειγματική εκτίμηση (Α) και το κατώτερο όριο βρίσκεται περίπου 2 τυπικά σφάλματα κάτω από τη δειγματική εκτίμηση (Δ).
Στην περίπτωση του μοντέλου της Condition, η R υπολόγισε το τυπικό σφάλμα του \(b_1\) (χρησιμοποιώντας τον μαθηματικό τύπο) ως 3.33. Η εκτίμηση της παραμέτρου ήταν 6.05.
Με βάση αυτούς τους αριθμούς, πώς θα μπορούσατε να εκφράσετε το περιθώριο σφάλματος;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το περιθώριο σφάλματος είναι περίπου 2 τυπικά σφάλματα, δηλαδή \(2 \times 3.33 \approx 6.66\) ποσοστιαίες μονάδες. Η εκτίμηση της παραμέτρου (6.05) είναι το κέντρο του διαστήματος εμπιστοσύνης — δεν συμπεριλαμβάνεται στον υπολογισμό του περιθωρίου σφάλματος. Το περιθώριο σφάλματος εξαρτάται μόνο από το τυπικό σφάλμα και το επίπεδο εμπιστοσύνης (95%, που αντιστοιχεί περίπου σε 2 τυπικά σφάλματα).
Αν έχετε μια εκτίμηση του τυπικού σφάλματος, μπορείτε απλώς να τη διπλασιάσετε για να πάρετε κατά προσέγγιση το περιθώριο σφάλματος. Αν, για παράδειγμα, χρησιμοποιήσουμε το τυπικό σφάλμα που έδωσε η R (3.33) για το μοντέλο της Condition, το περιθώριο σφάλματος θα ήταν το διπλάσιο αυτού, δηλαδή 6.66. Αυτό είναι αρκετά κοντά στο περιθώριο σφάλματος που υπολογίσαμε με τη συνάρτηση confint(): 6.72.
Η R χρησιμοποιεί το Κεντρικό Οριακό Θεώρημα για να εκτιμήσει το τυπικό σφάλμα, αλλά έχουμε και άλλους τρόπους να προσεγγίσουμε το τυπικό σφάλμα. Η χρήση της shuffle() για τη δημιουργία της δειγματοληπτικής κατανομής οδήγησε σε ένα ελαφρώς μεγαλύτερο τυπικό σφάλμα, 3.5. Αν το διπλασιάσουμε, λαμβάνουμε ένα περιθώριο σφάλματος 7, ελαφρώς μεγαλύτερο από το 6.66 που πήραμε χρησιμοποιώντας την εκτίμηση του τυπικού σφάλματος από τη R. Γενικά, αν το τυπικό σφάλμα είναι μεγαλύτερο, το περιθώριο σφάλματος θα είναι μεγαλύτερο, και το ίδιο θα ισχύει και για το διάστημα εμπιστοσύνης.
Χρησιμοποιώντας την τυχαιοποιημένη (ή τυχαία ανακατεμένη) δειγματοληπτική κατανομή, θα μπορούσαμε να πούμε ότι το διάστημα εμπιστοσύνης είναι \(6.05 \pm 7\). Ποιος θα ήταν ένας ισοδύναμος τρόπος να περιγραφεί αυτό το διάστημα εμπιστοσύνης; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Δ.
Η έκφραση \(6.05 \pm 7\) σημαίνει ότι το κατώτερο όριο είναι \(6.05 - 7 = -0.95\) και το ανώτερο όριο είναι \(6.05 + 7 = 13.05\) (Α). Είναι επίσης η γενική μορφή «δειγματική εκτίμηση \(\pm\) περιθώριο σφάλματος» (Δ). Οι απαντήσεις Β και Γ είναι λάθος γιατί παρερμηνεύουν τη σχέση μεταξύ της εκτίμησης και του περιθωρίου σφάλματος.
Όταν η R χρησιμοποιεί ένα μαθηματικό μοντέλο της δειγματοληπτικής κατανομής (π.χ. με τη confint()), εκτιμά ένα μικρότερο τυπικό σφάλμα (3.33) σε σύγκριση με το τυχαίο ανακάτεμα (3.5). Επομένως, το διάστημα εμπιστοσύνης από την confint() (−0.67 έως 12.76) είναι:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Μικρότερο τυπικό σφάλμα σημαίνει μικρότερο περιθώριο σφάλματος, που σημαίνει στενότερο διάστημα εμπιστοσύνης. Οι απαντήσεις Γ και Δ είναι λάθος γιατί και τα δύο διαστήματα είναι κεντραρισμένα στην ίδια τιμή εκτίμησης (6.05), άρα δεν είναι μετατοπισμένο το ένα σε σχέση με το άλλο — απλώς το ένα είναι στενότερο από το άλλο.
Η δειγματοληπτική κατανομή του \(b_1\) που δημιουργήθηκε με τη μέθοδο bootstrap είχε τυπικό σφάλμα 3.38. Τι θα σήμαινε αυτό για το διάστημα εμπιστοσύνης; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Δ.
Το τυπικό σφάλμα από τη μέθοδο bootstrap είναι 3.38 — ανάμεσα στο 3.33 (μαθηματικός τύπος) και στο 3.50 (τυχαιοποίηση). Άρα το αντίστοιχο διάστημα εμπιστοσύνης θα είναι στενότερο από εκείνο της τυχαιοποίησης (3.38 < 3.50, άρα Α) αλλά ευρύτερο από εκείνο του μαθηματικού τύπου (3.38 > 3.33, άρα Δ). Ο γενικός κανόνας: μεγαλύτερο τυπικό σφάλμα → ευρύτερο διάστημα εμπιστοσύνης.
13.8 Ερμηνεία του Διαστήματος Εμπιστοσύνης
Τώρα που έχουμε αφιερώσει χρόνο στην κατασκευή διαστημάτων εμπιστοσύνης, είναι σημαντικό να κάνουμε μια παύση και να σκεφτούμε τι σημαίνει ένα διάστημα εμπιστοσύνης και πώς εντάσσεται στις άλλες έννοιες που έχουμε μελετήσει μέχρι τώρα. Με τη συνάρτηση confint(), βρήκαμε ότι το 95% διάστημα εμπιστοσύνης για την επίδραση του χαμογελαστού προσώπου εκτείνεται από −0.67 έως 12.76.
Αυτοί οι αριθμοί αναφέρονται στο πιθανό μέγεθος της επίδρασης:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το διάστημα εμπιστοσύνης αναφέρεται στο εύρος των πιθανών τιμών της πραγματικής παραμέτρου \(\beta_1\) στη ΔΠΔ — δηλαδή στον πληθυσμό. Η δειγματική εκτίμηση \(b_1 = 6.05\) είναι σταθερή (υπολογίζεται από τα δεδομένα), και η δειγματοληπτική κατανομή είναι ένα εργαλείο που χρησιμοποιούμε για να εξάγουμε συμπεράσματα — δεν είναι αυτό που προσπαθούμε να εκτιμήσουμε. Αυτό που προσπαθούμε να εκτιμήσουμε είναι η άγνωστη παράμετρος \(\beta_1\) στη ΔΠΔ, και το διάστημα εμπιστοσύνης μας δίνει ένα εύρος πιθανών τιμών για αυτή.
Τα Διαστήματα Εμπιστοσύνης Αφορούν στη ΔΠΔ
Μια συνηθισμένη παρανόηση για τα διαστήματα εμπιστοσύνης είναι ότι ορίζουν κατώτερα και ανώτερα όρια για το πού θα μπορούσε να πέσει το 0.95 (95%) των τιμών του \(b_1\) (δείτε το αριστερό μέρος του παρακάτω σχήματος). Είναι πολύ λογικό να σκεφτήκατε κι εσείς κάτι τέτοιο, επειδή μέχρι τώρα αφιερώσαμε χρόνο για να υπολογίσουμε ένα διάστημα εμπιστοσύνης κεντράροντας μια δειγματοληπτική κατανομή στη δειγματική τιμή \(b_1\) και στη συνέχεια βρίσκοντας τις τιμές του \(b_1\) που θα έπεφταν πέρα από τα δύο όρια του 0.025.
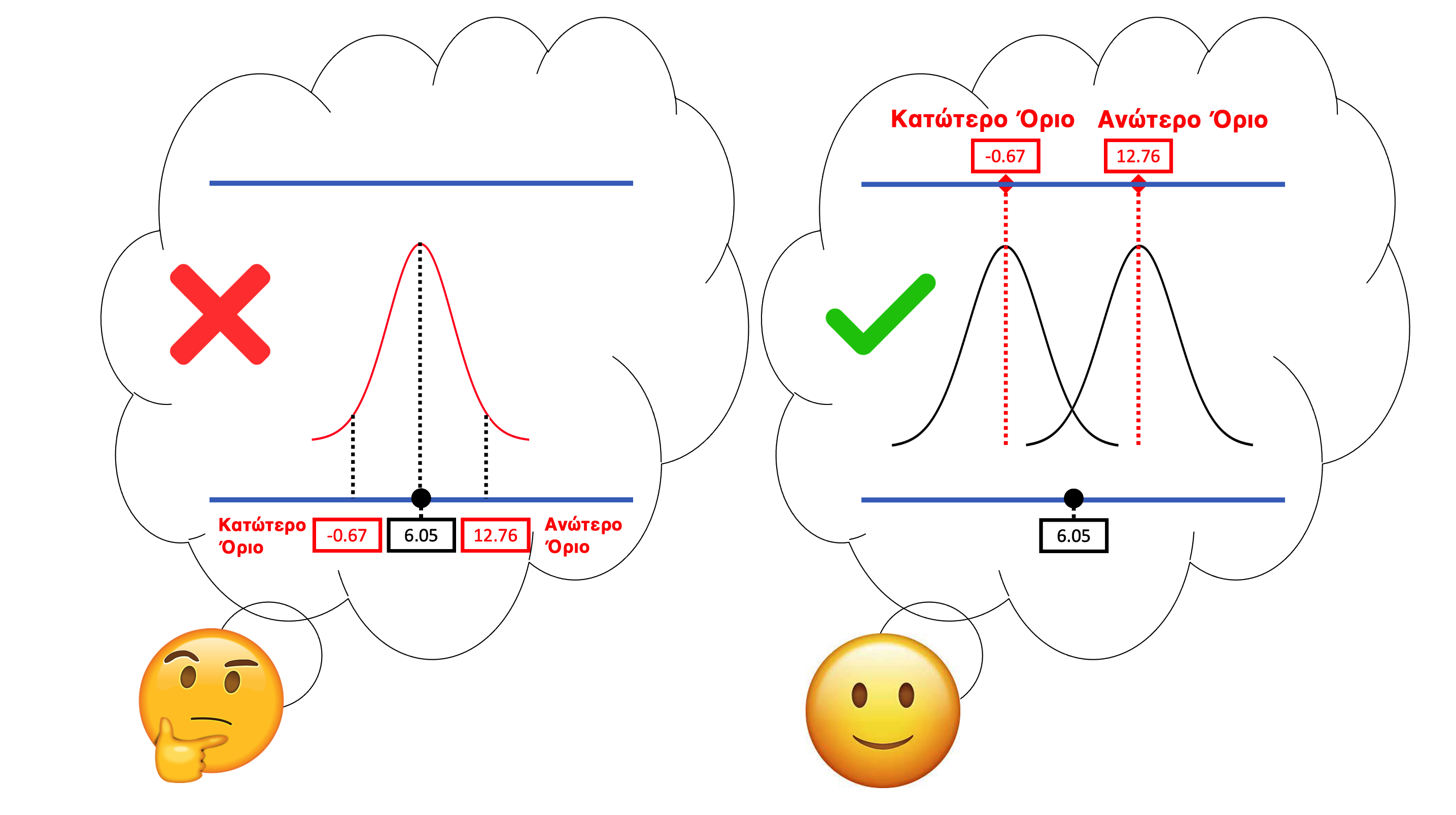
Αλλά αυτή ήταν απλώς μια μέθοδος για τον υπολογισμό του διαστήματος, όχι ένας ορισμός του σε τι αναφέρεται πραγματικά το διάστημα. Είναι σημαντικό να θυμόμαστε ότι αναπτύξαμε την έννοια του διαστήματος εμπιστοσύνης μετακινώντας νοητά τη δειγματοληπτική κατανομή των \(b_1\) αριστερά και δεξιά στην κλίμακα του \(\beta_1\) στη ΔΠΔ, μέχρι να βρούμε τις τιμές του \(\beta_1\) όπου η δειγματική τιμή \(b_1\) βρίσκεται στα όρια του να πέσει στην ουρά της απίθανης περιοχής. Με αυτόν τον τρόπο βρίσκουμε τις ακραίες τιμές του \(\beta_1\) για τις οποίες το \(b_1\) που παρατήρησαν οι ερευνητές εξακολουθεί να είναι πιθανό να εμφανιστεί στην αντίστοιχη δειγματοληπτική κατανομή. (Το δεξί μέρος του παραπάνω σχήματος θα σας υπενθυμίσει αυτόν τον τρόπο σκέψης.)
Αν θέλαμε πραγματικά να γνωρίζουμε το εύρος των πιθανών δειγματικών τιμών \(b_1\) που είναι πιθανές στον κόσμο, θα χρειαζόταν να γνωρίζουμε την πραγματική τιμή \(\beta_1\) στη ΔΠΔ. Αλλά αυτή δεν τη γνωρίζουμε. Γι’ αυτό πρέπει να υποθέτουμε πολλές διαφορετικές τιμές για την παράμετρο \(\beta_1\) μετακινώντας τη δειγματοληπτική κατανομή. Κάθε μία παράγει ένα διαφορετικό εύρος πιθανών τιμών \(b_1\).
Σφάλμα σε μια Εκτίμηση
Όπως προαναφέραμε, η δειγματική τιμή \(b_1\) που παρατηρούν οι ερευνητές είναι η βέλτιστη εκτίμηση που θα μπορούσαν να κάνουν για το ποια θα μπορούσε να είναι η πραγματική τιμή της παραμέτρου \(\beta_1\), με βάση τα διαθέσιμα δεδομένα (δηλαδή, της τρέχουσας μελέτης). Αυτή η εκτίμηση συχνά αναφέρεται ως σημειακή εκτίμηση (point estimate) και είναι η πιο ακριβής δυνατή εκτίμηση με βάση τα διαθέσιμα δεδομένα. Δεν υπάρχει λόγος να αναφέρουμε κάποια άλλη τιμή — οποιαδήποτε άλλη τιμή θα ήταν αυθαίρετη.
Αλλά το να είναι η βέλτιστη δεν σημαίνει ότι είναι και η σωστή. Η σημειακή εκτίμηση είναι σχεδόν σίγουρα λανθασμένη. Μπορεί να είναι πολύ χαμηλή ή μπορεί να είναι πολύ υψηλή, αλλά δεν ξέρουμε προς ποια κατεύθυνση είναι λανθασμένη. Και για να κάνουμε τα πράγματα χειρότερα, δεν μπορούμε να γνωρίζουμε με βεβαιότητα πόσο μακριά είναι από την πραγματική ΔΠΔ εκτός αν γνωρίζουμε ποιο είναι το πραγματικό \(\beta_1\). (Και αν το γνωρίζαμε αυτό, δεν θα προσπαθούσαμε να το εκτιμήσουμε εξαρχής!)
Το διάστημα εμπιστοσύνης είναι ένας τρόπος αντιμετώπισης αυτού του προβλήματος. Μας λέει πόσο λάθος θα μπορούσαμε να είμαστε, ή, με άλλα λόγια, πόσο σφάλμα μπορεί να υπάρχει στην εκτίμησή μας δεδομένου ενός συγκεκριμένου επιθυμητού επιπέδου εμπιστοσύνης.
Τι σημαίνει «σφάλμα στην εκτίμησή μας»;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το «σφάλμα στην εκτίμηση» αναφέρεται στην αβεβαιότητα που έχουμε για το πόσο κοντά βρίσκεται η δειγματική εκτίμησή μας (\(b_1\)) στην πραγματική, άγνωστη παράμετρο (\(\beta_1\)) στη ΔΠΔ. Δεν έχει καμία σχέση με υπολογιστικά σφάλματα (Α), ούτε με υπόλοιπα σε επίπεδο ατομικών παρατηρήσεων (Γ) — τα υπόλοιπα αφορούν την απόκλιση κάθε παρατήρησης από την τιμή πρόβλεψης του μοντέλου, ενώ το σφάλμα σε μια εκτίμηση αφορά την απόκλιση της εκτίμησης από την πραγματική παράμετρο στον πληθυσμό.
Αν το διάστημα εμπιστοσύνης είναι σχετικά ευρύ, όπως συμβαίνει στη μελέτη των φιλοδωρημάτων, θα αναφέραμε κάτι σαν: «η επίδραση της προσθήκης ενός χαμογελαστού προσώπου στον λογαριασμό είναι 6.05 ποσοστιαίες μονάδες. Αλλά υπάρχει μεγάλο σφάλμα σε αυτή την εκτίμηση. Μπορούμε να πούμε με 95% βεβαιότητα ότι η πραγματική επίδραση θα μπορούσε να είναι τόσο χαμηλή όσο το 0 ή ελαφρώς κάτω από αυτό, ή τόσο υψηλή όσο το 13».
Αν το διάστημα εμπιστοσύνης είναι σχετικά στενό, τι από τα παρακάτω θα μπορούσαμε να ισχυριστούμε; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Δ.
Ένα στενό διάστημα εμπιστοσύνης σημαίνει ότι υπάρχει μικρή αβεβαιότητα γύρω από την εκτίμησή μας — οι πιθανές τιμές της πραγματικής παραμέτρου \(\beta_1\) συγκεντρώνονται κοντά στη σημειακή εκτίμηση, άρα η εκτίμηση είναι μάλλον κοντά στην πραγματική τιμή (Α). Το εύρος του διαστήματος εμπιστοσύνης δεν αλλάζει τη σημειακή εκτίμηση — το 6.05 παραμένει η βέλτιστη μεμονωμένη εκτίμηση της \(\beta_1\) ανεξάρτητα από το εύρος του διαστήματος (Δ). Ένα στενό διάστημα απλώς μας δίνει περισσότερη βεβαιότητα γι’ αυτή την εκτίμηση.
Το εύρος του διαστήματος εμπιστοσύνης (ΔΕ) μάς λέει ποια θα μπορούσε να είναι η πραγματική τιμή \(\beta_1\) στη ΔΠΔ δεδομένου ενός συγκεκριμένου επιπέδου εμπιστοσύνης. Όταν το ΔΕ είναι στενότερο, θεωρούμε ότι η εκτίμησή μας είναι πιο κοντά στην πραγματική τιμή \(\beta_1\) από ό,τι όταν το ΔΕ είναι ευρύτερο.
Είναι σημαντικό να σημειωθεί ότι όταν μιλάμε για το σφάλμα σε μια εκτίμηση, χρησιμοποιούμε τον όρο «σφάλμα» για να εννοήσουμε κάτι λίγο διαφορετικό από αυτό που έχουμε μάθει μέχρι τώρα. Προηγουμένως, όταν αναπτύξαμε την έννοια του σφάλματος (όπως στην εξίσωση ΔΕΔΟΜΕΝΑ = ΜΟΝΤΕΛΟ + ΣΦΑΛΜΑ), αναφερόμασταν στην απόκλιση μεταξύ της τιμής πρόβλεψης του ποσοστού φιλοδωρήματος για κάθε τραπέζι βάσει ενός μοντέλου και της πραγματικής τιμής του ποσοστού φιλοδωρήματος που άφησε αυτό το τραπέζι. Τα σφάλματα ήταν τα ατομικά υπόλοιπα για κάθε τραπέζι.
Όταν σκεφτόμαστε όμως το σφάλμα γύρω από μια εκτίμηση παραμέτρου, δεν σκεφτόμαστε πλέον τα τραπέζια ξεχωριστά. Ένα μεμονωμένο τραπέζι δεν μπορεί να έχει τιμή \(b_1\)! Ένα μεμονωμένο τραπέζι δεν μπορεί να έχει διαφορά μέσων όρων μεταξύ τραπεζιών ελέγχου και χαμογελαστού προσώπου. Η ιδέα του \(b_1\) υφίσταται μόνο σε επίπεδο ολόκληρου του δείγματος. Επομένως, το σφάλμα στο \(b_1\) σημαίνει πόσο διαφορετική είναι η δειγματική εκτίμηση από την πραγματική παράμετρο \(\beta_1\) στη ΔΠΔ.
Τι μας δείχνει το διάστημα εμπιστοσύνης;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το διάστημα εμπιστοσύνης μας λέει πόσο σφάλμα μπορεί να υπάρχει στη σημειακή εκτίμηση της παραμέτρου — δηλαδή πόσο μακριά από την πραγματική τιμή \(\beta_1\) θα μπορούσε να είναι η εκτίμησή μας, \(b_1\). Οι απαντήσεις Β και Γ αναφέρονται σε ατομικές παρατηρήσεις ή στη μεταβλητότητα του δείγματος, όχι στην εκτίμηση της παραμέτρου. Η Δ αναφέρεται στη μεταβλητότητα της εξαρτημένης μεταβλητής στη ΔΠΔ, όχι στην παράμετρο. Η Ε δεν αφορά στην αβεβαιότητα σε σχέση με την πραγματική παράμετρο.
Τι Σημαίνει 95% Βεβαιότητα;
Μια απορία που μπορεί να έχετε είναι η εξής: τι σημαίνει να έχουμε 95% βεβαιότητα;
Ας ξεκινήσουμε εξηγώντας τι δεν σημαίνει. Δεν σημαίνει ότι υπάρχει πιθανότητα 95% η πραγματική τιμή \(\beta_1\) να βρίσκεται εντός του διαστήματος εμπιστοσύνης. Αυτό είναι ένα δυσνόητο σημείο και κάτι στο οποίο οι διδάσκοντες της στατιστικής στέκονται πολύ. Αν πείτε ότι υπάρχει 95% πιθανότητα η πραγματική παράμετρος να βρίσκεται σε αυτό το εύρος, θα σας διορθώσουν.
Ένας λόγος που θα σας διορθώσουν είναι ότι το \(\beta_1\) είτε βρίσκεται σε αυτό το εύρος (100%) είτε δεν βρίσκεται σε αυτό το εύρος (0%). Διότι είναι μια σταθερή τιμή, όχι μια τιμή που μεταβάλλεται τυχαία. Επειδή δεν γνωρίζετε ποιο είναι το \(\beta_1\), δεν μπορείτε να πείτε αν η πιθανότητα είναι 100% ή 0%, αλλά σίγουρα δεν είναι 95%. Αυτό που είναι αβέβαιο είναι η γνώση σας (που μετριέται με τη βεβαιότητα αντί για την πιθανότητα).
Ο άλλος λόγος που θα σας διορθώσουν είναι ότι δεν υπάρχει πιθανότητα 95% το \(\beta_1\) να βρίσκεται σε ένα συγκεκριμένο εύρος με δεδομένη την παρατηρούμενη τιμή \(b_1\), αλλά πιθανότητα 95% να λάβουμε την παρατηρούμενη τιμή \(b_1\) αν η πραγματική τιμή \(\beta_1\) βρίσκεται σε ένα συγκεκριμένο εύρος. Στη θεωρία πιθανοτήτων, η πιθανότητα του Α αν ισχύει το Β δεν είναι η ίδια με την πιθανότητα του Β αν ισχύει το Α. (Αυτό σχετίζεται με κάτι που ονομάζεται Κανόνας του Bayes, στο οποίο δεν θα το εμβαθύνουμε εδώ.)
Το 95% αφορά:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το 95% αφορά την πιθανότητα να παρατηρήσουμε ένα δείγμα σαν το δικό μας δεδομένων συγκεκριμένων τιμών \(\beta_1\) — όχι την πιθανότητα η πραγματική παράμετρος να βρίσκεται σε κάποιο εύρος. Το \(\beta_1\) είναι σταθερή τιμή· αυτό που μεταβάλλεται είναι η δειγματική μας εκτίμηση από δείγμα σε δείγμα. Γι’ αυτό μιλάμε για «βεβαιότητα» στη γνώση μας, όχι για πιθανότητα της παραμέτρου.
Λόγω αυτού του ζητήματος, κάποιος (στην πραγματικότητα, ένας μαθηματικός ονόματι Jerzy Neyman, το 1937) σκέφτηκε την ιδέα να αναφέρει «95% βέβαιοι» αντί για «95% πιθανό». Φανταζόμαστε ότι όλοι οι στατιστικοί αναστέναξαν από ανακούφιση.
Όταν κατασκευάζετε ένα 95% διάστημα εμπιστοσύνης, επομένως, λέτε ότι είστε 95% βέβαιοι (σε \(\alpha = 0.05\)) ότι το πραγματικό \(\beta_1\) στη ΔΠΔ βρίσκεται εντός του διαστήματος. Δεν μπορούμε να κατασκευάσουμε ένα 100% διάστημα εμπιστοσύνης, παρεμπιπτόντως, επειδή το μοντέλο πιθανότητας που χρησιμοποιούμε για τη δειγματοληπτική κατανομή — η κατανομή \(t\) — έχει ουρές που ποτέ δεν αγγίζουν πραγματικά το 0 στον άξονα \(y\). Λόγω αυτού, δεν μπορούμε να ορίσουμε το σημείο όπου η πιθανότητα σφάλματος Τύπου I θα ήταν ίση με 0.
Ποιες από τις παρακάτω προτάσεις είναι αληθείς με βάση το 95% διάστημα εμπιστοσύνης για την επίδραση του χαμογελαστού προσώπου στο ποσοστό φιλοδωρήματος (−0.67 έως 12.76);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Μόνο η απάντηση Δ χρησιμοποιεί τη σωστή γλώσσα — «95% βέβαιοι» αντί για «95% πιθανότητα» — και αναφέρεται στη σωστή οντότητα (το πραγματικό \(\beta_1\) στη ΔΠΔ). Η Α συγχέει το διάστημα εμπιστοσύνης με το εύρος των δεδομένων. Η Β είναι υπερβολικά ισχυρή — δεν είναι εγγυημένο· είμαστε 95% βέβαιοι, όχι 100%. Η Γ συγχέει τη σημειακή εκτίμηση με πιθανότητα — δεν υπάρχει «95% πιθανότητα» για ακριβώς μία τιμή. Η Ε συγχέει πάλι το διάστημα εμπιστοσύνης με την κατανομή των μεμονωμένων παρατηρήσεων.
13.9 Διαστήματα Εμπιστοσύνης και Σύγκριση Μοντέλων
Έχουμε πλέον χρησιμοποιήσει τη δειγματοληπτική κατανομή του \(b_1\) για δύο σκοπούς: για να αποφασίσουμε αν θα απορρίψουμε ή όχι το κενό μοντέλο (ή τη μηδενική υπόθεση) και για την κατασκευή ενός διαστήματος εμπιστοσύνης. Ας σκεφτούμε τώρα λίγο πώς συνδέονται αυτές οι δύο χρήσεις μεταξύ τους.
Το διάστημα εμπιστοσύνης μάς παρέχει ένα εύρος μοντέλων της ΔΠΔ (δηλαδή ένα εύρος πιθανών τιμών \(\beta_1\)) τα οποία δεν θα απορρίπταμε. Στην περίπτωση της μελέτης φιλοδωρημάτων, μπορούμε να είμαστε 95% βέβαιοι ότι η πραγματική επίδραση των χαμογελαστών προσώπων στα φιλοδωρήματα στη ΔΠΔ βρίσκεται κάπου μεταξύ −0.67 και 12.76.
Δεδομένου ότι το διάστημα εμπιστοσύνης μας για το \(\beta_1\) είναι από −0.67 έως 12.76, ποιες από αυτές τις τιμές του \(\beta_1\) θα απορρίπταμε; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Ε, ΣΤ και Ζ.
Απορρίπτουμε κάθε τιμή του \(\beta_1\) που δεν βρίσκεται εντός του διαστήματος εμπιστοσύνης (−0.67 έως 12.76). Οι τιμές 15, −2, −10 και −15 βρίσκονται όλες εκτός αυτού του εύρους, οπότε τις απορρίπτουμε. Οι τιμές 10, 2 και 0 βρίσκονται εντός του εύρους, οπότε δεν μπορούμε να τις απορρίψουμε ως πιθανά μοντέλα της ΔΠΔ.
Θα απορρίπταμε οποιεσδήποτε τιμές του \(\beta_1\) δεν εμπίπτουν στο διάστημα εμπιστοσύνης μας. Σε αυτή την περίπτωση, το 0 συμβαίνει να βρίσκεται εντός του διαστήματος εμπιστοσύνης (βλ. το αριστερό πλαίσιο του παρακάτω σχήματος), οπότε δεν το αποκλείουμε ως πιθανό μοντέλο της ΔΠΔ.
 Στο δεξί πλαίσιο του παραπάνω σχήματος, η προσέγγιση της σύγκρισης μοντέλων (ή του ελέγχου υποθέσεων) εξετάζει ένα μόνο συγκεκριμένο μοντέλο της ΔΠΔ, όχι ένα εύρος μοντέλων. Σε αυτό το μοντέλο, στο οποίο \(\beta_1 = 0\) (που ονομάζεται επίσης κενό μοντέλο ή μηδενική υπόθεση), δεν υπάρχει επίδραση του χαμογελαστού προσώπου στη ΔΠΔ. Χρησιμοποιήσαμε τη
Στο δεξί πλαίσιο του παραπάνω σχήματος, η προσέγγιση της σύγκρισης μοντέλων (ή του ελέγχου υποθέσεων) εξετάζει ένα μόνο συγκεκριμένο μοντέλο της ΔΠΔ, όχι ένα εύρος μοντέλων. Σε αυτό το μοντέλο, στο οποίο \(\beta_1 = 0\) (που ονομάζεται επίσης κενό μοντέλο ή μηδενική υπόθεση), δεν υπάρχει επίδραση του χαμογελαστού προσώπου στη ΔΠΔ. Χρησιμοποιήσαμε τη shuffle() για να μιμηθούμε μια τέτοια ΔΠΔ και κατασκευάσαμε μια δειγματοληπτική κατανομή κεντραρισμένη στο 0. Μπορούμε να δούμε στο σχήμα ότι αν μια τέτοια ΔΠΔ ήταν αληθής, η δειγματική μας τιμή \(b_1 = 6.05\) δεν θα ήταν απίθανη.
Στη συνέχεια χρησιμοποιήσαμε τη δειγματοληπτική κατανομή ως κατανομή πιθανότητας για να υπολογίσουμε την πιθανότητα να λάβουμε μια δειγματική τιμή 6.05 ή πιο ακραία, είτε θετική είτε αρνητική, αν το κενό μοντέλο ήταν αληθές (δηλαδή την τιμή \(p\)). Με βάση την τιμή \(p = 0.08\), αποφασίσαμε να μην απορρίψουμε το κενό μοντέλο, καθώς το 0.08 είναι ελαφρώς υψηλότερο από το όριο του 0.05 που είχαμε ορίσει ως επίπεδο σημαντικότητας \(\alpha\).
Αυτές οι δύο προσεγγίσεις — ο έλεγχος μηδενικής υπόθεσης και τα διαστήματα εμπιστοσύνης — αποτελούν και οι δύο τρόπους αξιολόγησης του κενού μοντέλου, και και οι δύο μας οδηγούν στο ίδιο συμπέρασμα για τη μελέτη των φιλοδωρημάτων: το κενό μοντέλο, στο οποίο \(\beta_1 = 0\), δεν μπορεί να αποκλειστεί ως πιθανό μοντέλο της ΔΠΔ.
Αν ένα διάστημα εμπιστοσύνης για το \(\beta_1\) δεν περιλαμβάνει το 0, τι θα λέγαμε για το κενό μοντέλο της ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Αν το 0 δεν περιλαμβάνεται στο διάστημα εμπιστοσύνης, σημαίνει ότι δεν είμαστε 95% βέβαιοι ότι η πραγματική τιμή \(\beta_1\) θα μπορούσε να είναι 0 — άρα απορρίπτουμε το κενό μοντέλο ως πιθανό μοντέλο της ΔΠΔ.
Αν ένα διάστημα εμπιστοσύνης για το \(\beta_1\) δεν περιλαμβάνει το 0, τι θα περιμέναμε να είναι η τιμή \(p\) μας;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Οι δύο προσεγγίσεις είναι άρρηκτα συνδεδεμένες: αν το 95% διάστημα εμπιστοσύνης δεν περιλαμβάνει το 0, τότε η τιμή \(p\) για τον έλεγχο μηδενικής υπόθεσης θα είναι μικρότερη από 0.05 — και οι δύο θα μας οδηγήσουν στην απόρριψη του κενού μοντέλου.
Αν το 95% διάστημα εμπιστοσύνης δεν περιλαμβάνει το 0, τότε θα απορρίπταμε το κενό μοντέλο, επειδή δεν είμαστε βέβαιοι ότι \(\beta_1 = 0\). Και αν το διάστημα εμπιστοσύνης δεν περιλαμβάνει το 0, η τιμή \(p\) για τον έλεγχο μηδενικής υπόθεσης θα ήταν μικρότερη από 0.05, οδηγώντας μας ξανά στην απόρριψη του κενού μοντέλου. Αυτό δεν είναι απλώς σύμπτωση. Οι δύο προσεγγίσεις θα επιβεβαιώνουν πάντα η μία την άλλη, επειδή και οι δύο βασίζονται στην ίδια υποκείμενη λογική και στις ίδιες δειγματοληπτικές κατανομές (δηλαδή με το ίδιο σχήμα και την ίδια διασπορά).
Ως άλλο παράδειγμα, ας εξετάσουμε μια δεύτερη μελέτη φιλοδωρημάτων που πραγματοποιήθηκε από μια άλλη ομάδα ερευνητών. Έλαβαν πολύ παρόμοια αποτελέσματα, αλλά αυτή τη φορά η δειγματική τιμή \(b_1\) ήταν 8.00 (βλ. δεξί πλαίσιο του παρακάτω σχήματος), αντί για 6.05 (που απεικονίζεται στο αριστερό πλαίσιο). Το τυπικό σφάλμα τους (και το περιθώριο σφάλματος) ήταν το ίδιο όπως στην αρχική μελέτη. Το παρακάτω σχήμα απεικονίζει τα αποτελέσματα των δύο μελετών στο πλαίσιο μιας δειγματοληπτικής κατανομής από μια ΔΠΔ όπου \(\beta_1 = 0\).
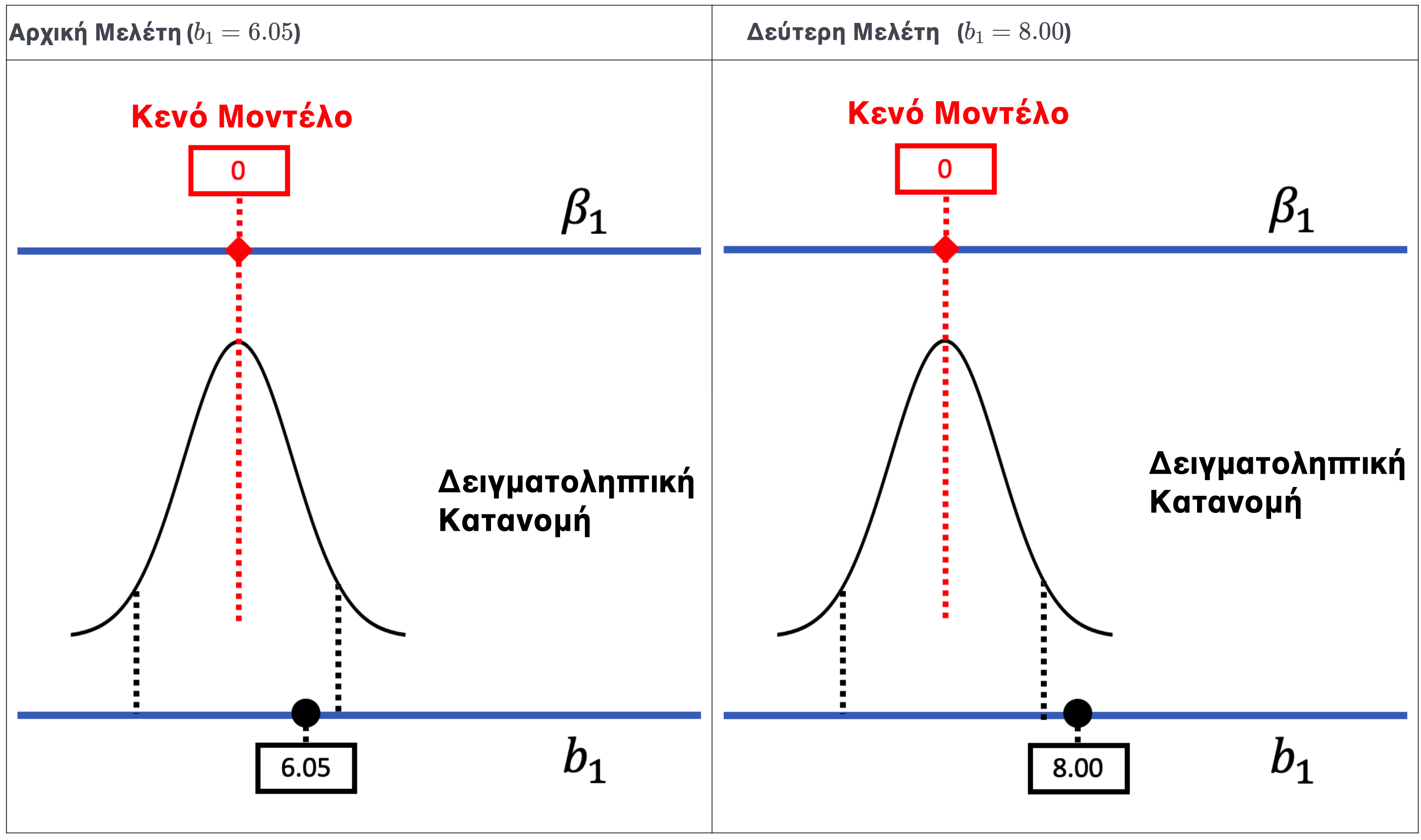
Δεν πιστεύουμε πραγματικά ότι η ΔΠΔ έχει αλλάξει, οπότε δεν θα λέγαμε ότι το \(\beta_1\) έχει αλλάξει για αυτή τη μελέτη. Αλλά όλα τα άλλα θα άλλαζαν — η βέλτιστη εκτίμηση του \(\beta_1\), η τιμή \(p\), και τα διαστήματα εμπιστοσύνης. Η τιμή \(p\) θα ήταν μικρότερη, επειδή η τιμή \(b_1\) θα βρισκόταν τώρα στις απίθανες ουρές αν το κενό μοντέλο ήταν αληθές στη ΔΠΔ.
Ας ρίξουμε μια ματιά στο πώς θα μπορούσε να διαφέρει το διάστημα εμπιστοσύνης μεταξύ αυτών των δύο μελετών.
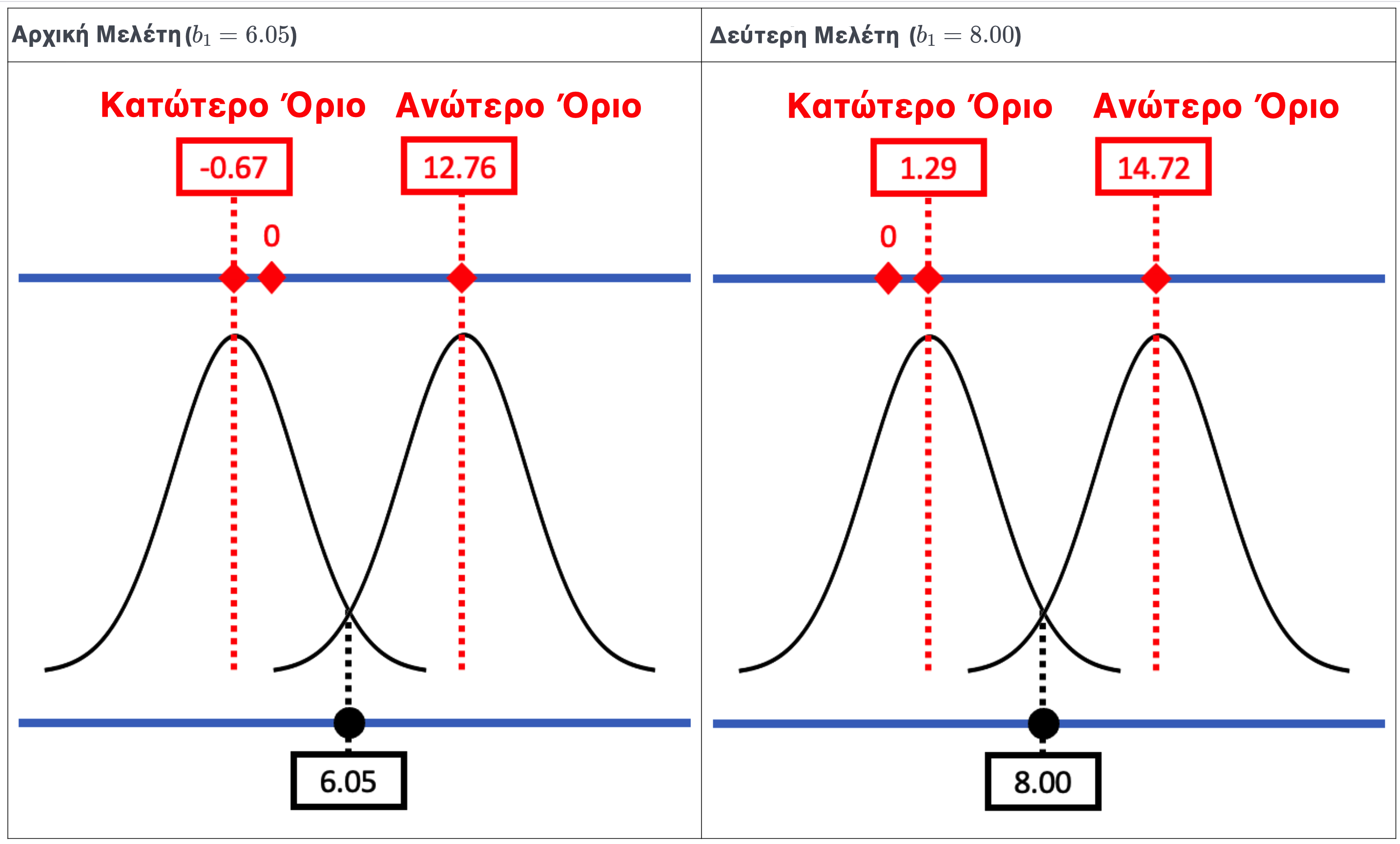
Στη δεύτερη μελέτη (δεξί πλαίσιο του παραπάνω σχήματος), το διάστημα εμπιστοσύνης είναι τώρα:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Επειδή το τυπικό σφάλμα (και το περιθώριο σφάλματος) παραμένει το ίδιο όπως στην αρχική μελέτη, το εύρος του διαστήματος εμπιστοσύνης δεν αλλάζει. Αυτό που αλλάζει είναι η σημειακή εκτίμηση — το \(b_1\) είναι τώρα 8.00 αντί για 6.05. Αφού το διάστημα εμπιστοσύνης είναι πάντα κεντραρισμένο στη δειγματική εκτίμηση, μετατοπίζεται προς τα πάνω κατά την ίδια ποσότητα (περίπου 2 μονάδες) που μετατοπίστηκε και η εκτίμηση.
Στη δεύτερη μελέτη, το διάστημα εμπιστοσύνης:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Στην αρχική μελέτη, το διάστημα εμπιστοσύνης ήταν από −0.67 έως 12.76, μόλις περιλάμβανε το 0. Αν μετατοπίσουμε αυτό το διάστημα προς τα πάνω κατά περίπου 2 μονάδες (από \(b_1 = 6.05\) σε \(b_1 = 8.00\)), το νέο διάστημα θα είναι περίπου από 1.3 έως 14.7, πλέον δεν περιλαμβάνει το 0. Αυτό σημαίνει ότι σε αυτή τη δεύτερη μελέτη θα απορρίπταμε το κενό μοντέλο, σε αντίθεση με την αρχική μελέτη όπου δεν μπορούσαμε.
Στο αριστερό πλαίσιο του σχήματος, το διάστημα εμπιστοσύνης (που οι τιμές του βρίσκονται στα δύο κόκκινα πλαίσια) είναι κεντραρισμένο γύρω από μια υποτιθέμενη τιμή \(\beta_1\) που είναι ίδια με την παρατηρούμενη τιμή \(b_1\) (6.05), και το 0 βρίσκεται οριακά εντός του διαστήματος εμπιστοσύνης. Σε αυτή τη μελέτη, δεν απορρίψαμε το κενό μοντέλο ως μοντέλο της ΔΠΔ, επειδή ήταν μία από τις τιμές που περιλαμβάνονταν στο 95% διάστημα εμπιστοσύνης.
Στο δεξί πλαίσιο του σχήματος, βλέπουμε τι συνέβη στη δεύτερη μελέτη όπου η παρατηρούμενη τιμή \(b_1\) ήταν λίγο υψηλότερη (8.00). Το νέο διάστημα εμπιστοσύνης είναι κεντραρισμένο στο 8.00, και το 0 βρίσκεται τώρα εκτός του διαστήματος εμπιστοσύνης. Με βάση τα αποτελέσματα αυτής της δεύτερης μελέτης, θα απορρίπταμε το κενό μοντέλο ως μοντέλο της ΔΠΔ.
Στη δεύτερη μελέτη, το εύρος του διαστήματος εμπιστοσύνης δεν άλλαξε, αν και η θέση του κατώτερου και ανώτερου ορίου άλλαξε. Γιατί νομίζετε ότι το εύρος δεν άλλαξε;
Αξίζει επίσης να σημειωθεί ότι λαμβάνουμε πολύ περισσότερες πληροφορίες από ένα διάστημα εμπιστοσύνης απ’ ό,τι από την τιμή \(p\). Για παράδειγμα, στην αρχική μελέτη των φιλοδωρημάτων (όπου \(b_1 = 6.05\)), όταν δεν απορρίπτουμε τη μηδενική υπόθεση (0), αυτό δεν σημαίνει ότι μπορούμε να την αποδεχτούμε και να ισχυριστούμε ότι το 0 είναι η πραγματική τιμή του \(\beta_1\). Μπορούμε να δούμε από το διάστημα εμπιστοσύνης ότι, παρόλο που η πραγματική τιμή του \(\beta_1\) στη ΔΠΔ μπορεί να είναι 0, υπάρχουν πολλές άλλες τιμές που μπορεί επίσης να είναι (πολύ μεγαλύτερες από το 0). Τα διαστήματα εμπιστοσύνης μας βοηθούν να θυμόμαστε ότι η μη απόρριψη της μηδενικής υπόθεσης δεν σημαίνει και αποδοχή της.
13.10 Διάστημα Εμπιστοσύνης για το \(\beta_0\)
Έχουμε αφιερώσει πολύ χρόνο δουλεύοντας με το διάστημα εμπιστοσύνης για το \(\beta_1\) στο μοντέλο δύο ομάδων, το μοντέλο που χρησιμοποιήσαμε για να ερμηνεύσουμε τη διακύμανση στο πείραμα των φιλοδωρημάτων. Αλλά μπορούμε να δημιουργήσουμε διαστήματα εμπιστοσύνης και για άλλες παραμέτρους.
Τυπικά δεν δημιουργούμε διαστήματα εμπιστοσύνης γύρω από το \(F\), επειδή η κατανομή \(F\) δεν είναι συμμετρική, γεγονός που καθιστά το διάστημα εμπιστοσύνης δυσκολότερο στην ερμηνεία. Αλλά για οποιαδήποτε από τις παραμέτρους που συμβολίζουμε με \(\beta\), μπορούμε να χρησιμοποιήσουμε τις ίδιες μεθόδους για να βρούμε το διάστημα εμπιστοσύνης τους. Ας δούμε μερικά παραδείγματα, ξεκινώντας με το \(\beta_0\).
Στη μελέτη των φιλοδωρημάτων, έχουμε δώσει βαρύτητα στο διάστημα εμπιστοσύνης για την επίδραση του χαμογελαστού προσώπου στην Tip, που αναπαρίσταται ως \(\beta_1\). Αλλά σε αυτό το μοντέλο δύο ομάδων εκτιμούμε και μια άλλη παράμετρο: το \(\beta_0\). Υπενθυμίζουμε ότι το πλήρες μοντέλο που προσπαθούμε να εκτιμήσουμε είναι:
\[Y_i = \beta_0 + \beta_1 X_i + \epsilon_i\]
Η παράμετρος \(\beta_0\) είναι ο μέσος όρος της Tip για την ομάδα ελέγχου. Αν προσαρμόσουμε το μοντέλο και στη συνέχεια εκτελέσουμε τη confint() σε αυτό, λαμβάνουμε 95% διαστήματα εμπιστοσύνης και για τις δύο παραμέτρους \(\beta_0\) και \(\beta_1\).
Έχετε ξαναδεί το παρακάτω αποτέλεσμα όταν χρησιμοποιήσαμε τη confint() για να πάρουμε το διάστημα εμπιστοσύνης για το \(\beta_1\).
2.5 % 97.5 %
(Intercept) 22.254644 31.74536
ConditionSmiley Face -0.665492 12.75640Αυτή τη φορά θα εστιάσουμε στη γραμμή με τίτλο (Intercept), επειδή αυτή μας δείχνει το διάστημα εμπιστοσύνης για το \(\beta_0\). (Ονομάζεται intercept — σταθερός όρος ή τεταγμένη — επειδή είναι η τιμή πρόβλεψης της Tip όταν \(X = 0\).)
Ποιο είναι το 95% διάστημα εμπιστοσύνης για το \(\beta_0\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το διάστημα εμπιστοσύνης για το \(\beta_0\) βρίσκεται στη γραμμή (Intercept) και εκτείνεται από 22.25 έως 31.75. Οι στήλες 2.5 % και 97.5 % είναι απλώς τα εκατοστημόρια που ορίζουν τα όρια του 95% διαστήματος — όχι οι ίδιες οι τιμές. Το διάστημα −0.67 έως 12.76 είναι το διάστημα εμπιστοσύνης για το \(\beta_1\), όχι για το \(\beta_0\).
Ποια θα ήταν η ερμηνεία αυτού του διαστήματος εμπιστοσύνης;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το \(\beta_0\) στο μοντέλο της Condition είναι ο μέσος όρος φιλοδωρήματος της ομάδας ελέγχου στη ΔΠΔ. Οπότε το διάστημα εμπιστοσύνης γύρω από το \(\beta_0\) μας λέει σε τι εύρος θα μπορούσε να βρίσκεται αυτός ο πληθυσμιακός μέσος όρος. Η απάντηση Γ αφορά την ομάδα χαμογελαστού προσώπου, και η Δ αφορά τη διαφορά μεταξύ των δύο ομάδων — αυτή είναι η ερμηνεία του \(\beta_1\), όχι του \(\beta_0\).
Το \(\beta_0\) αντιπροσωπεύει το μέσο όρο φιλοδωρήματος στη ΔΠΔ για τα τραπέζια που δεν λαμβάνουν χαμογελαστά πρόσωπα. Είναι ο μέσος όρος του πληθυσμού για τα τραπέζια της ομάδας ελέγχου. Το διάστημα εμπιστοσύνης γύρω από το \(\beta_0\) αναγνωρίζει ότι αν και η καλύτερη σημειακή εκτίμηση για τον μέσο όρο της ομάδας ελέγχου στη ΔΠΔ είναι το \(b_0\), είμαστε 95% βέβαιοι ότι η πραγματική τιμή βρίσκεται μεταξύ 22.25 και 31.75 ποσοστιαίων μονάδων.
Τι γίνεται αν θέλαμε να βρούμε το διάστημα εμπιστοσύνης για το \(\beta_0\) στο κενό μοντέλο της Tip; Με άλλα λόγια, ποιος θα ήταν ο μέσος όρος ποσοστού φιλοδωρήματος από όλα τα τραπέζια (τόσο της ομάδας ελέγχου όσο και του χαμογελαστού προσώπου) στη ΔΠΔ; Ποιο είναι το διάστημα εμπιστοσύνης για αυτόν τον μέσο όρο ποσοστού φιλοδωρήματος; Και πάλι, μπορούμε να χρησιμοποιήσουμε τη confint(), η οποία μπορεί να δεχτεί οποιονδήποτε τύπο μοντέλου.
2.5 % 97.5 %
(Intercept) 26.58087 33.46459Ποιο είναι το 95% διάστημα εμπιστοσύνης για το \(\beta_0\) με βάση το κενό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Στο κενό μοντέλο, το \(\beta_0\) αντιπροσωπεύει το συνολικό μέσο όρο της Tip για όλα τα τραπέζια στη ΔΠΔ (χωρίς διάκριση μεταξύ ομάδων). Το 95% διάστημα εμπιστοσύνης γι’ αυτόν το μέσο όρο εκτείνεται από 26.58 έως 33.46 ποσοστιαίες μονάδες.
Παρακάτω παρουσιάζουμε τα αποτελέσματα της confint() τόσο για το μοντέλο της Condition όσο και για το κενό μοντέλο.
2.5 % 97.5 %
(Intercept) 22.254644 31.74536
ConditionSmiley Face -0.665492 12.75640 2.5 % 97.5 %
(Intercept) 26.58087 33.46459Γιατί υπάρχει μόνο μία γραμμή στα αποτελέσματα για το κενό μοντέλο, ενώ υπάρχουν δύο για το μοντέλο της
Condition;
Το μοντέλο της Condition είχε δύο παραμέτρους (\(\beta_0\) και \(\beta_1\)), ενώ το κενό μοντέλο είχε μόνο μία (\(\beta_0\)). Η confint() θα υπολογίσει τα διαστήματα εμπιστοσύνης για κάθε παράμετρο στο μοντέλο, οπότε θα επιστρέψει διαφορετικές γραμμές στα αποτελέσματα ανάλογα με τον αριθμό των παραμέτρων.
Παρατηρήστε ότι το διάστημα εμπιστοσύνης γύρω από το \(\beta_0\) από το κενό μοντέλο εκτείνεται από 26.58 έως 33.46, πράγμα που σημαίνει ότι μπορούμε να είμαστε 95% βέβαιοι ότι ο πραγματικός μέσος όρος ποσοστού φιλοδωρήματος στη ΔΠΔ βρίσκεται μεταξύ αυτών των δύο ορίων. Αυτοί οι αριθμοί είναι διαφορετικοί από το διάστημα εμπιστοσύνης γύρω από το \(\beta_0\) από το μοντέλο της Condition (22.25 και 31.75).
Γιατί το διάστημα εμπιστοσύνης για τον σταθερό όρο (\(\beta_0\)) είναι διαφορετικό στο κενό μοντέλο σε σχέση με το σύνθετο μοντέλο;
13.11 Διάστημα Εμπιστοσύνης για την Κλίση μιας Ευθείας Παλινδρόμησης
Ας επιστρέψουμε στο μοντέλο παλινδρόμησης που προσαρμόσαμε χρησιμοποιώντας την FoodQuality για την πρόβλεψη της Tip. Μπορούμε να ορίσουμε αυτό το μοντέλο της ΔΠΔ ως εξής:
\[Y_i = \beta_0 + \beta_1 X_i + \epsilon_i\]
Ποια παράμετρος είναι η κλίση της ευθείας παλινδρόμησης;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το \(\beta_1\) είναι ο συντελεστής της ανεξάρτητης μεταβλητής \(X_i\) — δηλαδή η κλίση της ευθείας παλινδρόμησης. Μας λέει πόσο αλλάζει η τιμή πρόβλεψης της \(Y\) για κάθε αύξηση μιας μονάδας στην \(X\). Το \(\beta_0\) είναι ο σταθερός όρος (η τιμή της \(Y\) όταν \(X = 0\)), το \(\epsilon_i\) είναι το σφάλμα, και το \(Y_i\) είναι η εξαρτημένη μεταβλητή.
Σκεφτείτε το μοντέλο παλινδρόμησης όπου χρησιμοποιούμε την FoodQuality για να προβλέψουμε την Tip. Ποια γραμμή κώδικα θα μας δώσει τη βέλτιση εκτίμηση της κλίσης αυτής της ευθείας παλινδρόμησης;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Η σύνταξη Tip ~ FoodQuality σημαίνει «πρόβλεψε την Tip από την FoodQuality» — δηλαδή η Tip είναι η εξαρτημένη μεταβλητή και η FoodQuality η ανεξάρτητη. Οι απαντήσεις Β και Γ αντιστρέφουν τη σχέση. Η απάντηση Δ θα δώσει μια τιμή \(b_1\) από ένα σύνολο δεδομένων μετά από επαναδειγματοληψία, όχι από το αρχικό — οπότε δεν θα είναι η «βέλτιστη εκτίμηση» από τα πραγματικά δεδομένα.
Ακολουθεί το αποτέλεσμα της lm() για το προσαρμοσμένο μοντέλο της FoodQuality.
Call:
lm(formula = Tip ~ FoodQuality, data = TipExperiment)
Coefficients:
(Intercept) FoodQuality
10.1076 0.3776 Ποια είναι η κλίση και ποια είναι η σωστή ερμηνεία της σε αυτό το πλαίσιο;
Χρησιμοποιήστε το παρακάτω πλαίσιο κώδικα για να βρείτε το 95% διάστημα εμπιστοσύνης για την κλίση αυτής της ευθείας παλινδρόμησης.
2.5 % 97.5 %
(Intercept) -9.29657877 29.4923793
FoodQuality 0.01546542 0.7400759Ποιο είναι το διάστημα εμπιστοσύνης για την κλίση της ευθείας παλινδρόμησης;
Πώς μοντελοποιεί η confint() τη δειγματοληπτική κατανομή του \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η confint() δεν χρησιμοποιεί προσομοίωση (ούτε τυχαιοποίηση ούτε τη μέθοδο bootstrap) — βασίζεται στον μαθηματικό τύπο του Κεντρικού Οριακού Θεωρήματος, μοντελοποιώντας τη δειγματοληπτική κατανομή ως κατανομή \(t\). Αυτός είναι και ο λόγος που είναι τόσο γρήγορη: δεν χρειάζεται να παράγει χίλια δείγματα για να υπολογίσει το διάστημα.
Ποια είναι η σωστή ερμηνεία του διαστήματος εμπιστοσύνης γύρω από το \(\beta_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το διάστημα εμπιστοσύνης γύρω από το \(\beta_1\) ορίζει το εύρος των πιθανών τιμών \(\beta_1\) στη ΔΠΔ που θα μπορούσαν εύλογα να έχουν παράγει τη δειγματική μας εκτίμηση. Η απάντηση Α είναι λάθος επειδή το διάστημα εμπιστοσύνης δεν μας δίνει την πραγματική τιμή — μας δίνει ένα εύρος πιθανών τιμών. Η Γ αφορά το κενό μοντέλο, που είναι ξεχωριστή έννοια. Η Δ συγχέει την ερμηνεία του διαστήματος εμπιστοσύνης με την ερμηνεία των ομάδων στο μοντέλο δύο ομάδων — εδώ δεν έχουμε ομάδες, έχουμε συνεχή ανεξάρτητη μεταβλητή.
Το \(\beta_1\) αντιπροσωπεύει την προσαύξηση που προστίθεται στην τιμή πρόβλεψης του ποσοστού φιλοδωρήματος στη ΔΠΔ για κάθε επιπλέον μονάδα βαθμολογίας ποιότητας φαγητού. Το διάστημα εμπιστοσύνης του \(\beta_1\) αντιπροσωπεύει το εύρος των τιμών \(\beta_1\) από τις οποίες η δειγματική μας τιμή \(b_1\) εξακολουθεί να είναι πιθανή (δηλαδή, όχι απίθανη). Τιμές \(\beta_1\) τόσο χαμηλές όσο το 0.015 και τόσο υψηλές όσο το 0.74 μπορούν εύλογα να παράγουν τη δειγματική μας τιμή \(b_1\).
Τώρα που δοκιμάσαμε την confint(), προσπαθήστε να χρησιμοποιήσετε τη συνάρτηση resample() για να υπολογίσετε το 95% διάστημα εμπιστοσύνης για την κλίση της ευθείας παλινδρόμησης με τη μέθοδο bootstrap. Δείτε πώς συγκρίνεται το διάστημα εμπιστοσύνης της μεθόδου bootstrap που υπολογίσατε με τα αποτελέσματα που λάβατε χρησιμοποιώντας την confint().
Ποια από αυτές τις γραμμές κώδικα θα έδινε μία τιμή b1() με τη μέθοδο bootstrap από μια κατανομή πληθυσμού που αποτελείται από τραπέζια ακριβώς όπως αυτά του δείγματος;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Στη μέθοδο bootstrap, επαναδειγματοληπτούμε ολόκληρες παρατηρήσεις (γραμμές) από τα αρχικά δεδομένα — διατηρώντας άθικτη τη σχέση μεταξύ των μεταβλητών για κάθε τραπέζι. Η απάντηση Α χρησιμοποιεί τη shuffle(), η οποία προσομοιώνει το κενό μοντέλο (δεν είναι η μέθοδος bootstrap). Η απάντηση Β επαναδειγματοληπτεί μόνο μία στήλη (FoodQuality) — αυτό θα διασπούσε τη σχέση μεταξύ της FoodQuality και της Tip κάθε τραπεζιού. Η σωστή προσέγγιση είναι η Γ: resample(TipExperiment) επαναδειγματοληπτεί ολόκληρο το πλαίσιο δεδομένων, διατηρώντας ίδια τα ζεύγη τιμών (Tip, FoodQuality).
Ακολουθεί ένα ιστόγραμμα της δειγματοληπτικής κατανομής bootstrap που δημιουργήσαμε. Το δικό σας θα είναι λίγο διαφορετικό, φυσικά, επειδή είναι τυχαίο.

Σε τι αναφέρεται ο αριθμός (count) στον άξονα \(y\) του ιστογράμματος (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β, Γ και Ε.
Κάθε παρατήρηση στο ιστόγραμμα είναι μία τιμή \(b_1\) (Β) — δηλαδή μια κλίση (Ε) — που υπολογίστηκε από ένα ξεχωριστό δείγμα bootstrap (Γ). Κάναμε 1.000 επαναδειγματοληψίες, οπότε το ιστόγραμμα δείχνει την κατανομή αυτών των 1.000 εκτιμήσεων της κλίσης. Οι απαντήσεις Α και Δ αφορούν στα αρχικά δεδομένα (τραπέζια και πελάτες), όχι στη δειγματοληπτική κατανομή.
Με μια ματιά στο παραπάνω ιστόγραμμα, ποιες είναι οι τιμές των ορίων (που αντιστοιχούν στο κατώτερο και το ανώτερο όριο του διαστήματος εμπιστοσύνης);
Το κέντρο της δειγματοληπτικής κατανομής bootstrap είναι περίπου ίδιο με τη δειγματική τιμή \(b_1 = 0.38\). Αυτό είναι αυτό που θα περιμέναμε, επειδή η μέθοδος bootstrap υποθέτει ότι το δείγμα είναι αντιπροσωπευτικό της ΔΠΔ.
Όπως εξηγήθηκε προηγουμένως, μπορούμε να χρησιμοποιήσουμε τα όρια του 0.025 που διαχωρίζουν τις απίθανες ουρές από το πιθανό μεσαίο τμήμα της δειγματοληπτικής κατανομής ως έναν βολικό τρόπο να βρούμε το κατώτερο και το ανώτερο όριο του 95% διαστήματος εμπιστοσύνης. Μπορούμε να εκτιμήσουμε αυτά τα όρια διαγραμματικά κοιτάζοντας το ιστόγραμμα, ή μπορούμε να τα υπολογίσουμε ταξινομώντας τη δειγματοληπτική κατανομή bootstrap για να βρούμε το 26ο και το 975ο \(b_1\).
[1] 0.0198060804221204
[1] 0.732391298337459Για να βρούμε το διάστημα εμπιστοσύνης, ταξινομήσαμε τις τυχαία παραγόμενες τιμές \(b_1\) από τη χαμηλότερη στην υψηλότερη και στη συνέχεια χρησιμοποιήσαμε την 26η και την 975η τιμή \(b_1\) ως κατώτερο και ανώτερο όριο του διαστήματος εμπιστοσύνης. Τα δικά σας αποτελέσματα θα είναι λίγο διαφορετικά από τα δικά μας επειδή η επαναδειγματοληψία γίνεται τυχαία. Πήραμε ένα διάστημα εμπιστοσύνης bootstrap από 0.02 έως 0.73, το οποίο είναι κοντά σε αυτό που πήραμε από τη confint() (0.02 και 0.74).
Η δειγματοληπτική κατανομή bootstrap των κλίσεων σε αυτή την περίπτωση δεν είναι ακριβώς συμμετρική· παρουσιάζει μια ελαφριά ασυμμετρία προς τα δεξιά. Για αυτόν τον λόγο, το κέντρο του διαστήματος εμπιστοσύνης δεν θα είναι ακριβώς στη δειγματική τιμή \(b_1\). Αυτό έρχεται σε αντίθεση με τη μαθηματική προσέγγιση, η οποία υποθέτει ότι η δειγματική τιμή \(b_1\) βρίσκεται ακριβώς στο μέσο μιας τέλεια συμμετρικής κατανομής \(t\). Αυτή η διαφορά δεν σημαίνει ότι η μέθοδος bootstrap είναι λιγότερο ακριβής. Μπορεί να υπάρχει κάτι στις κατανομές της FoodQuality και της Tip που οδηγεί σε αυτή την ασυμμετρία.
Το σημαντικό που θέλουμε να εστιάσουμε προς το παρόν είναι ότι όλες αυτές οι μέθοδοι οδηγούν σε περίπου τα ίδια αποτελέσματα. Αυτές οι ομοιότητες μάς δείχνουν τι σημαίνουν τα διαστήματα εμπιστοσύνης και τι μπορούν να μας πουν. Αργότερα, σε πιο προχωρημένα μαθήματα, μπορείτε να ασχοληθείτε με το ερώτημα του γιατί τα αποτελέσματα διαφέρουν μεταξύ των μεθόδων όταν διαφέρουν.
13.12 Διαστήματα Εμπιστοσύνης για Συγκρίσεις κατά Ζεύγη
Σε προηγούμενο κεφάλαιο συζητήσαμε τον έλεγχο των συγκρίσεων κατά ζεύγη (pairwise comparisons) σε ένα μοντέλο τριών ομάδων. Εξετάσαμε κάποια δεδομένα που σύγκριναν τις επιδόσεις μαθητών σε ένα τεστ μαθηματικών αφού έπαιξαν τρία διαφορετικά εκπαιδευτικά παιχνίδια. Πρώτα χρησιμοποιήσαμε έναν έλεγχο \(F\) για να συγκρίνουμε το μοντέλο των τριών ομάδων με το κενό μοντέλο, και αποφασίσαμε να απορρίψουμε το κενό μοντέλο (δηλαδή, ότι οι επιδόσεις και από τα τρία παιχνίδια θα μπορούσαν να μοντελοποιηθούν με τον ίδιο μέσο όρο).
Γνωρίζοντας ότι τουλάχιστον κάποια από τα τρία παιχνίδια διέφεραν στατιστικά σημαντικά μεταξύ τους, αλλά χωρίς να γνωρίζουμε ποια, κάναμε συγκρίσεις κατά ζεύγη, ελέγχοντας τα τρία πιθανά ζεύγη των τριών παιχνιδιών: A, B και C.
Εδώ είναι ο κώδικας που χρησιμοποιήσαμε για να κάνουμε τις συγκρίσεις κατά ζεύγη για το game_model:
Και εδώ είναι τα αποτελέσματα:
Model: outcome ~ game
game
Levels: 3
Family-wise error-rate: 0.05
group_1 group_2 diff pooled_se q df lower upper p_adj
1 B A 2.086 0.516 4.041 102 0.350 3.822 .0142
2 C A 3.629 0.516 7.031 102 1.893 5.364 .0000
3 C B 1.543 0.516 2.990 102 -0.193 3.279 .0920Σημειώστε ότι οι τιμές \(p\) και τα διαστήματα εμπιστοσύνης είναι διορθωμένα (γι’ αυτό και αναφέρονται ως p_adj) με βάση τον έλεγχο HSD του Tukey, ώστε το συνολικό ποσοστό σφάλματος Τύπου I να είναι ίσο με 0.05.
Με βάση αυτά τα αποτελέσματα, ποιες ομάδες θα συμπεραίνατε ότι δεν διαφέρουν στη ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Κοιτώντας τις στήλες p_adj, βλέπουμε ότι οι συγκρίσεις Β vs Α (\(p = 0.0142\)) και C vs Α (\(p < 0.0001\)) έχουν τιμές \(p\) κάτω από 0.05, άρα θα απορρίπταμε το κενό μοντέλο για αυτές — οι ομάδες διαφέρουν. Όμως για τη σύγκριση C vs Β, η τιμή \(p = 0.0920\) είναι πάνω από 0.05, άρα δεν απορρίπτουμε το κενό μοντέλο για αυτό το ζεύγος. Μπορούμε επίσης να το επιβεβαιώσουμε από το διάστημα εμπιστοσύνης: το διάστημα για το ζεύγος C vs Β (−0.193 έως 3.279) περιλαμβάνει το 0, ενώ τα διαστήματα για τις άλλες δύο συγκρίσεις δεν το περιλαμβάνουν.
Η μέση διαφορά μεταξύ των παιχνιδιών Β και C στο δείγμα είναι 1.54. Αλλά η τιμή \(p = 0.09\) μας λέει ότι η παρατηρούμενη διαφορά βρίσκεται εντός του εύρους διαφορών που θα θεωρούσαμε πιθανές αν η πραγματική διαφορά μεταξύ των παιχνιδιών ήταν 0. Για αυτόν τον λόγο, δεν απορρίψαμε το κενό μοντέλο για αυτή τη διαφορά κατά ζεύγη.
Επειδή μάθαμε ότι η σύγκριση μοντέλων (χρησιμοποιώντας την τιμή \(p\)) και τα διαστήματα εμπιστοσύνης είναι αλληλένδετα, θα περιμέναμε αυτό το εύρημα να αντικατοπτρίζεται και στο 95% διάστημα εμπιστοσύνης. Συγκεκριμένα, επειδή δεν απορρίψαμε το κενό μοντέλο με βάση την τιμή \(p\), θα πρέπει να περιμένουμε ότι το διάστημα εμπιστοσύνης θα περιλαμβάνει το 0, πράγμα που σημαίνει ότι μια τιμή \(\beta_1 = 0\) είναι ένα από το εύρος μοντέλων που θα θεωρούσαμε πιθανό να έχουν παράγει τη δειγματική τιμή \(b_1\).
Κοιτάξτε ξανά τα αποτελέσματα της pairwise() (παραπάνω). Πού βρίσκονται τα διαστήματα εμπιστοσύνης των διαφορών;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Οι στήλες lower και upper δίνουν το κατώτερο και το ανώτερο όριο του 95% διαστήματος εμπιστοσύνης για κάθε διαφορά κατά ζεύγη. Η στήλη diff δείχνει τη σημειακή εκτίμηση της διαφοράς μεταξύ των δύο ομάδων, και οι στήλες group_1 και group_2 προσδιορίζουν απλώς ποιες ομάδες συγκρίνονται.
Ποιο από τα τρία διαστήματα εμπιστοσύνης κατά ζεύγη θα περιλαμβάνει το 0;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Το διάστημα εμπιστοσύνης για τη σύγκριση C vs Β εκτείνεται από −0.193 έως 3.279, δηλαδή περιλαμβάνει το 0. Αυτό έρχεται σε συμφωνία με την τιμή \(p = 0.0920\) που είναι πάνω από 0.05. Τα άλλα δύο διαστήματα (0.350 έως 3.822 και 1.893 έως 5.364) δεν περιλαμβάνουν το 0, κάτι που επιβεβαιώνει τις στατιστικά σημαντικές τιμές \(p\) τους.
Όπως φαίνεται παρακάτω, το διάστημα εμπιστοσύνης της διαφοράς μεταξύ των παιχνιδιών C και Β είναι κεντραρισμένο στη δειγματική διαφορά (1.54) αλλά εκτείνεται από −0.19 έως 3.28. Όπως αναμενόταν με βάση την τιμή \(p\) (μεγαλύτερη από 0.05), αυτό το διάστημα περιλαμβάνει το 0.
group_1 group_2 diff pooled_se q df lower upper p_adj
1 B A 2.086 0.516 4.041 102 0.350 3.822 .0142
2 C A 3.629 0.516 7.031 102 1.893 5.364 .0000
3 C B 1.543 0.516 2.990 102 -0.193 3.279 .0920Δοκιμάστε να Προσθέσετε plot = TRUE στη Συνάρτηση pairwise()
Η συνάρτηση pairwise() διαθέτει μια επιλογή που μας βοηθά να οπτικοποιήσουμε τα διαστήματα εμπιστοσύνης κατά ζεύγη σε σχέση το ένα με το άλλο. Απλώς προσθέστε το όρισμα plot = TRUE στη συνάρτηση, ως εξής:
Δοκιμάστε το στο παρακάτω τμήμα κώδικα.

Τι αντιπροσωπεύει η διακεκομμένη γραμμή;
Παρατηρήστε ότι ένα από τα 95% διαστήματα εμπιστοσύνης διασχίζει τη διακεκομμένη γραμμή, η οποία αντιπροσωπεύει μια διαφορά κατά ζεύγη ίση με 0: C και Β. Αλλά τα άλλα δύο διαστήματα εμπιστοσύνης (C − Α και Β − Α) δεν περιλαμβάνουν το 0. Αυτό σημαίνει ότι δεν είμαστε βέβαιοι ότι η μέση διαφορά στη ΔΠΔ για αυτά τα ζεύγη θα μπορούσε να είναι 0. Θα συμπεραίναμε ότι το παιχνίδι Α είναι πράγματι διαφορετικό τόσο από το παιχνίδι Β όσο και από το παιχνίδι C στη ΔΠΔ.
13.13 Τι Επηρεάζει το Εύρος του Διαστήματος Εμπιστοσύνης
Επειδή ο στόχος μας είναι να αποκτήσουμε μια πιο ακριβή εικόνα της ΔΠΔ, θα ήταν καλύτερο να έχουμε ένα στενότερο διάστημα εμπιστοσύνης παρά ένα ευρύτερο. Αν το διάστημα είναι στενότερο, τότε θα έχουμε λιγότερη αβεβαιότητα στην εκτίμηση της παραμέτρου μας, και θα μπορούμε να κάνουμε πιο ακριβείς προβλέψεις για μελλοντικά δείγματα. Για αυτόν τον λόγο, αξίζει να σκεφτούμε λίγο τι καθορίζει το εύρος του διαστήματος εμπιστοσύνης.
Επίπεδο Εμπιστοσύνης
Έχουμε εστιάσει σε ένα επίπεδο εμπιστοσύνης \(\alpha\) ίσο με 0.05 (κατά την αξιολόγηση του κενού μοντέλου ή της μηδενικής υπόθεσης) και στο αντίστοιχο 95% διάστημα εμπιστοσύνης. Ελπίζουμε να σας έχουμε πείσει ότι αυτά τα δύο πάνε μαζί. Αλλά τα 0.05 και 95% δεν είναι τα μόνα κριτήρια που θα μπορούσαμε να χρησιμοποιήσουμε. Θα μπορούσαμε να χρησιμοποιήσουμε ένα 99% ή 90% διάστημα εμπιστοσύνης, ή οποιοδήποτε άλλη τιμή.
Αν έπρεπε να μαντέψετε, ποιο θα ήταν το επίπεδο σημαντικότητας \(\alpha\) που αντιστοιχεί σε ένα 99% διάστημα εμπιστοσύνης; Ποιο θα είναι για ένα 90% διάστημα εμπιστοσύνης;
Το επιθυμητό επίπεδο εμπιστοσύνης θα επηρεάσει το εύρος του διαστήματος εμπιστοσύνης. Για τα ίδια δεδομένα, αν θέλουμε να έχουμε μεγαλύτερη βεβαιότητα ότι η ΔΠΔ βρίσκεται εντός ενός συγκεκριμένου εύρους, θα πρέπει να κάνουμε το διάστημα εμπιστοσύνης μας ευρύτερο.
Σκεφτείτε ένα ακραίο παράδειγμα: αν θέλουμε να είμαστε 100% βέβαιοι ότι η πραγματική τιμή του \(\beta_1\) βρίσκεται εντός του διαστήματος εμπιστοσύνης, θα έπρεπε το διάστημά μας να εκτείνεται από το μείον άπειρο έως το συν άπειρο — τόσο ευρύ όσο θα μπορούσε να είναι ένα διάστημα εμπιστοσύνης! Αυτή είναι η μοναδική περίπτωση να έχουμε 100% βεβαιότητα. Αν θέλουμε μόνο 95% βεβαιότητα, μπορούμε να κάνουμε το διάστημα στενότερο (ευτυχώς!). Και αν θέλουμε ακόμα λιγότερη βεβαιότητα (π.χ. 90% ή 80%), το διάστημα μπορεί να γίνει ακόμα στενότερο.
Για τα ίδια δεδομένα, ποιο θα προβλέπατε ότι είναι ευρύτερο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Όσο μεγαλύτερη βεβαιότητα επιθυμούμε, τόσο ευρύτερο πρέπει να είναι το διάστημα για να χωρέσει αυτή την πρόσθετη βεβαιότητα. Ένα 99% διάστημα εμπιστοσύνης πρέπει να είναι ευρύτερο από ένα 95%, το οποίο με τη σειρά του πρέπει να είναι ευρύτερο από ένα 90%. Σκεφτείτε το ως εξής: για να «πιάσουμε» την πραγματική τιμή με μεγαλύτερη βεβαιότητα, πρέπει να ρίξουμε ένα ευρύτερο δίχτυ.
Όσο περισσότερη βεβαιότητα θέλουμε (99%), τόσο ευρύτερο θα πρέπει να είναι το διάστημα. Αλλά πόσο ευρύτερο;
Χρήση της confint() για Διαφορετικά Επίπεδα Εμπιστοσύνης
Μπορείτε να χρησιμοποιήσετε τη συνάρτηση confint() για να υπολογίσετε τα 90% ή 99% διαστήματα εμπιστοσύνης (ή οποιοδήποτε άλλο επίπεδο εμπιστοσύνης) προσθέτοντας απλώς το όρισμα level = .90 (ή .99) στον παρακάτω κώδικα. (Η προεπιλεγμένη τιμή, αν παραλείψετε αυτό το όρισμα, είναι .95.)
Δοκιμάστε να υπολογίσετε το 90% και 99% διάστημα εμπιστοσύνης για τις παραμέτρους του μοντέλου της Condition τροποποιώντας τον παρακάτω κώδικα. Παρατηρήστε: πόσο ευρύτερο είναι το 99% διάστημα εμπιστοσύνης;
Το κατώτερο όριο του 99% διαστήματος εμπιστοσύνης είναι τώρα −2.93, και το ανώτερο όριο είναι 15.02. Αυξάνοντας την επιθυμητή βεβαιότητά μας, αυξήσαμε επίσης το μέγεθος του διαστήματος εμπιστοσύνης.
Περαιτέρω Διερεύνηση του Επιπέδου Εμπιστοσύνης και του Εύρους του Διαστήματος
Όταν ορίζουμε το \(\alpha = 0.05\) (για το 95% διάστημα εμπιστοσύνης), κάθε μία από τις απίθανες ουρές έχει πιθανότητα 0.025. Αν ορίσουμε ένα \(\alpha\) ίσο με 0.01 (για το 99% διάστημα εμπιστοσύνης), ποια πιθανότητα θα βρίσκεται σε κάθε μία από τις απίθανες ουρές; (Επιλέξτε όλες τις σωστές απαντήσεις.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Γ και Δ.
Το \(\alpha\) μοιράζεται εξίσου μεταξύ των δύο ουρών της δειγματοληπτικής κατανομής. Όταν \(alpha = 0.01\), κάθε ουρά έχει πιθανότητα \(0.01 / 2 = 0.005\) (δηλαδή 0.5%). Οι απαντήσεις Γ και Δ λένε το ίδιο πράγμα με διαφορετικό τρόπο. Το κεντρικό, πιθανό τμήμα της κατανομής καλύπτει το 99% (\(1 - 0.01\)), αφήνοντας το 0.5% σε κάθε ουρά.
Οι ουρές στις απίθανες περιοχές είναι μικρότερες στις δειγματοληπτικές κατανομές που χρησιμοποιούνται για τον προσδιορισμό του 99% διαστήματος εμπιστοσύνης (σε σύγκριση με το 95%). Για να διασφαλίσουμε ότι η δειγματική τιμή \(b_1\) βρίσκεται στο όριο αυτών των μικρότερων ουρών, οι δειγματοληπτικές κατανομές πρέπει να απομακρυνθούν περισσότερο μεταξύ τους.

Το παραπάνω κινούμενο σχήμα μας δείχνει ότι καθώς απομακρύνουμε το κατώτερο και το ανώτερο όριο μεταξύ τους (μετακινώντας έτσι και τις αντίστοιχες δειγματοληπτικές κατανομές τους), οι ουρές πέρα από τη δειγματική τιμή \(b_1\) (τα τμήματα τριγωνικού σχήματος κοντά στο κέντρο του κινούμενου σχήματος) γίνονται μικρότερες. Έτσι φτάνουμε από ένα 95% διάστημα εμπιστοσύνης σε ένα 99%.
Ας ρίξουμε μια πιο προσεκτική ματιά σε αυτή την ιδέα εξετάζοντας μόνο το κατώτερο όριο του διαστήματος εμπιστοσύνης για δύο διαφορετικά επίπεδα εμπιστοσύνης.

Αν φανταστούμε τη δειγματοληπτική κατανομή τοποθετημένη στο ανώτερο όριο του 95% διαστήματος εμπιστοσύνης, προς ποια κατεύθυνση θα χρειαζόταν να τη μετακινήσουμε για να την τοποθετήσουμε στο ανώτερο όριο του 99% διαστήματος εμπιστοσύνης;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Για το ανώτερο όριο μετακινούμε τη δειγματοληπτική κατανομή προς τα πάνω (δεξιά). Καθώς αυξάνεται το επιθυμητό επίπεδο εμπιστοσύνης από 95% σε 99%, η ουρά του 0.025 γίνεται ουρά του 0.005, δηλαδή μικρότερη. Για να πέσει η σταθερή δειγματική τιμή \(b_1\) ακριβώς στην αρχή αυτής της μικρότερης ουράς, η κατανομή πρέπει να μετακινηθεί ακόμα πιο δεξιά, παίρνοντας μαζί της και το ανώτερο όριο του διαστήματος εμπιστοσύνης.
Για να περάσουμε από ένα 95% διάστημα εμπιστοσύνης σε ένα 99% διάστημα, πρέπει να μετακινήσουμε τη δειγματοληπτική κατανομή από το ανώτερο όριο προς τα πάνω και από το κατώτερο όριο προς τα κάτω, απομακρύνοντας έτσι τις δειγματοληπτικές κατανομές περισσότερο μεταξύ τους, κάνοντας το 99% διάστημα εμπιστοσύνης ευρύτερο σε σχέση με το 95% διάστημα εμπιστοσύνης.
Τυπικό Σφάλμα
Εκτός από το επίπεδο εμπιστοσύνης, ο άλλος παράγοντας που επηρεάζει το πλάτος του διαστήματος εμπιστοσύνης είναι το τυπικό σφάλμα. Όσο μεγαλύτερο είναι το τυπικό σφάλμα — δηλαδή όσο ευρύτερη είναι η δειγματοληπτική κατανομή — τόσο ευρύτερο θα είναι το διάστημα εμπιστοσύνης.
Μπορούμε να απεικονίσουμε αυτή την ιδέα στα παρακάτω σχήματα. Στο πρώτο σχήμα, έχουμε και πάλι απεικονίσει το διάστημα εμπιστοσύνης για το \(\beta_1\) για το μοντέλο της Condition στη μελέτη των φιλοδωρημάτων. Κατασκευάσαμε μια δειγματοληπτική κατανομή, στη συνέχεια τη μετακινήσαμε προς τα κάτω και προς τα πάνω μέχρι η δειγματική τιμή \(b_1\) να περάσει στην ζώνη του 0.025.
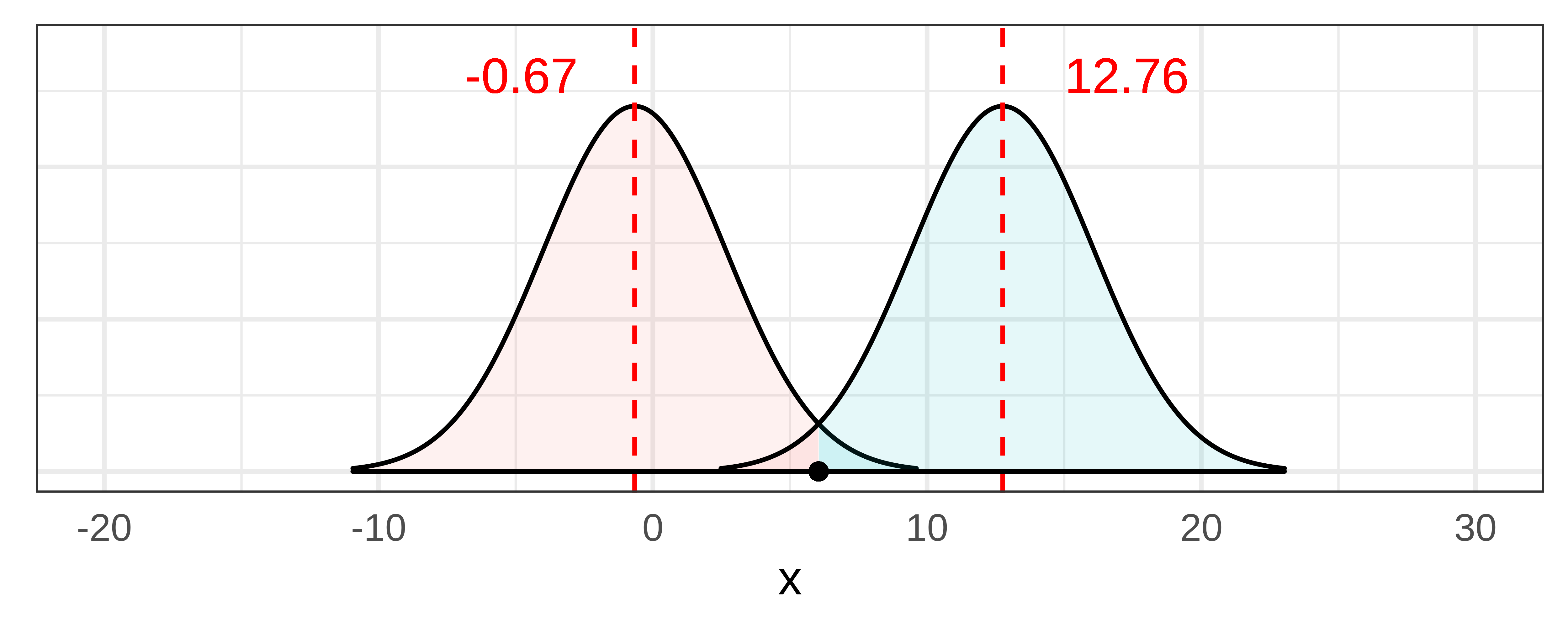
Τώρα, αν μειώσουμε τεχνητά το τυπικό σφάλμα (π.χ. μειώνοντάς το από 3.3 σε 2.0), μπορείτε να δείτε στο παρακάτω σχήμα ότι οι δύο δειγματοληπτικές κατανομές γίνονται στενότερες. Αν δεν μετακινήσουμε τα κέντρα τους από τα προηγούμενα κατώτερα και ανώτερα όρια, μπορείτε να δείτε ότι η δειγματική τιμή \(b_1\) είναι τώρα εξαιρετικά απίθανο να προέρχεται από οποιαδήποτε από αυτές τις στενότερες δειγματοληπτικές κατανομές.
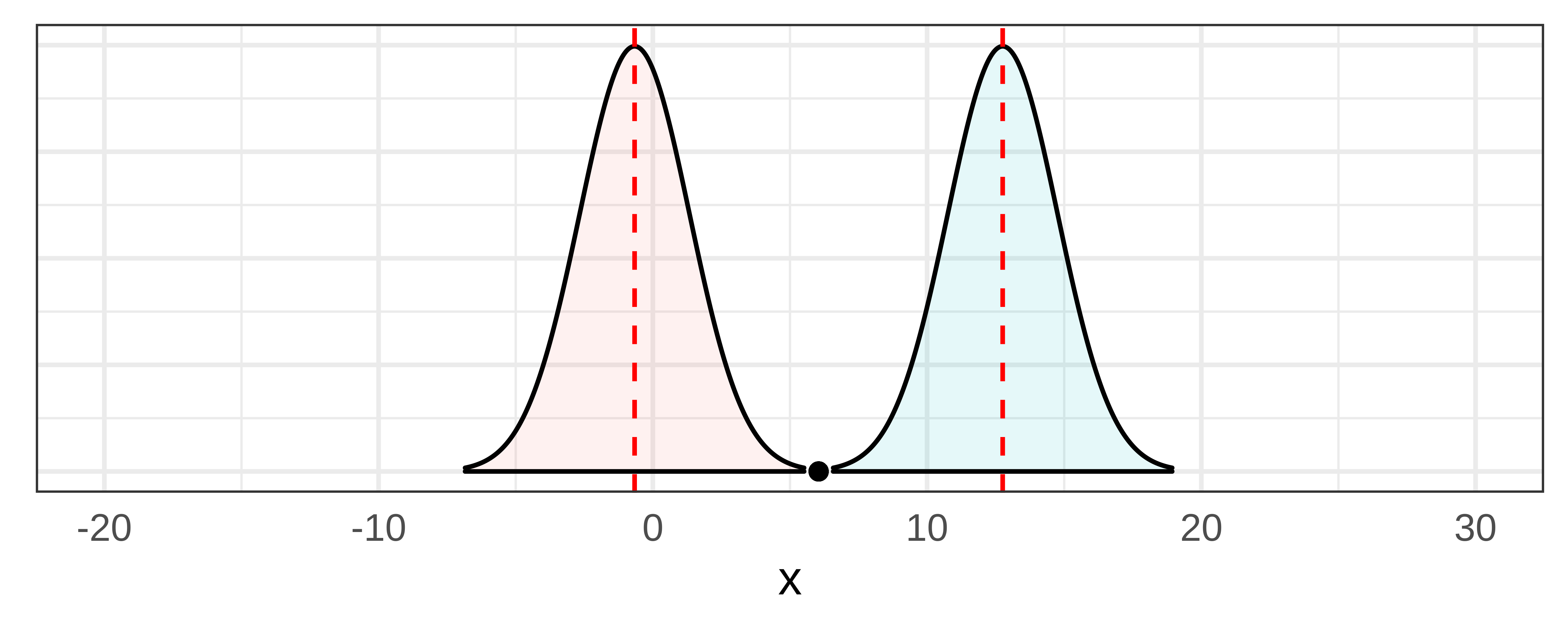
Για να βρούμε το 95% διάστημα εμπιστοσύνης σε αυτόν τον κόσμο με μικρότερο τυπικό σφάλμα, τι θα κάναμε για να αλλάξουμε το παραπάνω σχήμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η δειγματική τιμή \(b_1\) είναι σταθερή — δεν μετακινείται. Αυτό που κάνουμε είναι να μετακινήσουμε τις δύο δειγματοληπτικές κατανομές πιο κοντά μεταξύ τους, μέχρι η δειγματική τιμή \(b_1\) να πέσει ακριβώς στα όρια των απίθανων ουρών τους. Αυτό με τη σειρά του φέρνει τα κατώτερα και ανώτερα όρια του διαστήματος εμπιστοσύνης πιο κοντά μεταξύ τους, κάνοντας το διάστημα στενότερο.
Για να βρούμε το 95% διάστημα εμπιστοσύνης, θέλουμε η δειγματική τιμή \(b_1\) να βρίσκεται ακριβώς στο όριο του 0.025. Για να το κάνουμε αυτό, θα πρέπει να μετακινήσουμε τις στενότερες δειγματοληπτικές κατανομές πιο κοντά μεταξύ τους μέχρι η δειγματική τιμή \(b_1\) να περνά μόλις στην απίθανη ζώνη κάθε δειγματοληπτικής κατανομής. Κάνοντας αυτό, μετακινούνται επίσης το κατώτερο και το ανώτερο όριο (που αναπαρίστανται από τις διακεκομμένες γραμμές) πιο κοντά μεταξύ τους.

Γενικά, επομένως, καθώς το τυπικό σφάλμα γίνεται μικρότερο, το διάστημα εμπιστοσύνης γίνεται στενότερο, και καθώς το τυπικό σφάλμα αυξάνεται, το διάστημα εμπιστοσύνης γίνεται ευρύτερο.
Τι Επηρεάζει το Τυπικό Σφάλμα;
Υπάρχουν δύο πράγματα που επηρεάζουν το τυπικό σφάλμα. Το ένα είναι η τυπική απόκλιση της εξαρτημένης μεταβλητής, σε αυτήν την περίπτωση της Tip, στη ΔΠΔ. Αυτό είναι κάτι για το οποίο έχετε μικρό έλεγχο, εκτός αν σχεδιάζετε τη μέτρηση της εξαρτημένης μεταβλητής και μπορείτε να την κάνετε λιγότερο επιρρεπή σε σφάλματα μέτρησης.
Το άλλο πράγμα που έχει σημαντική επίδραση στο τυπικό σφάλμα είναι το μέγεθος του δείγματος στη μελέτη. Το εξετάσαμε αυτό νωρίτερα όταν είδαμε την επίδραση της αύξησης του αριθμού των τραπεζιών που μελετήθηκαν από \(n = 44\) σε \(n = 88\). Όσο μεγαλύτερο το δείγμα, τόσο μικρότερο το τυπικό σφάλμα. Για αυτόν τον λόγο, αν θέλετε λιγότερη αβεβαιότητα στην εκτίμηση του \(\beta_1\), θα πρέπει να προσπαθήσετε να αυξήσετε το μέγεθος του δείγματος στη μελέτη σας.
Αν χρησιμοποιήσουμε τη R για να υπολογίσουμε ένα 95% διάστημα εμπιστοσύνης από τα αρχικά δεδομένα με 44 τραπέζια (TipExperiment) και από το διπλασιασμένο πλαίσιο δεδομένων με 88 τραπέζια (TipExp2), ποιο θα έχει στενότερο διάστημα εμπιστοσύνης; (Υπενθυμίζεται ότι και οι δύο εκδοχές της Tip έχουν την ίδια τυπική απόκλιση.)
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Μεγαλύτερο μέγεθος δείγματος οδηγεί σε μικρότερο τυπικό σφάλμα, το οποίο με τη σειρά του οδηγεί σε στενότερο διάστημα εμπιστοσύνης. Δεδομένου ότι η τυπική απόκλιση της Tip είναι ίδια και στα δύο πλαίσια δεδομένων, το δείγμα των 88 τραπεζιών θα έχει στενότερο διάστημα εμπιστοσύνης από το δείγμα των 44 τραπεζιών.
Τι σημαίνει ένα στενότερο διάστημα εμπιστοσύνης;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Ένα στενότερο διάστημα εμπιστοσύνης σημαίνει ότι το εύρος των πιθανών τιμών για την πραγματική παράμετρο είναι μικρότερο — δηλαδή έχουμε λιγότερη αβεβαιότητα για την εκτίμησή μας. Προσοχή: δεν σημαίνει ότι είμαστε πιο «βέβαιοι» με την έννοια ότι αλλάζει το επίπεδο εμπιστοσύνης (Α). Το επίπεδο εμπιστοσύνης παραμένει 95% και στις δύο περιπτώσεις — αυτό που αλλάζει είναι η ακρίβεια της εκτίμησής μας.
Στο παρακάτω τμήμα κώδικα, δοκιμάστε να υπολογίσετε το 95% διάστημα εμπιστοσύνης για τα αρχικά δεδομένα με 44 τραπέζια και για το διπλασιασμένο σύνολο δεδομένων με 88 τραπέζια (TipExp2). Προβλέπουμε ότι αυτό που υπολογίζεται από τα 88 τραπέζια θα είναι στενότερο.
13.14 Ασκήσεις Επανάληψης Κεφαλαίου 13
Μια μελέτη εξέτασε αν η χρήση στολής δύτη (wetsuit) επηρεάζει την ταχύτητα κολύμβησης. Δώδεκα αγωνιστικοί κολυμβητές και τριαθλητές κολύμπησαν 1500 μέτρα με μέγιστη ταχύτητα δύο φορές ο καθένας — μία φορά φορώντας στολή δύτη και μία φορά φορώντας κανονικό μαγιό. Η σειρά των δοκιμών ήταν τυχαιοποιημένη. Κάθε φορά, καταγραφόταν η μέγιστη ταχύτητα του κολυμβητή σε μέτρα/δευτερόλεπτο.
Το πλαίσιο δεδομένων Wetsuits περιέχει 12 παρατηρήσεις για τις ακόλουθες τέσσερις μεταβλητές:
-
Wetsuit— Μέγιστη ταχύτητα κολύμβησης (m/sec) όταν ο κολυμβητής φοράει στολή δύτη. -
NoWetsuit— Μέγιστη ταχύτητα κολύμβησης (m/sec) όταν ο κολυμβητής φοράει κανονικό μαγιό. -
Gender— Φύλο του κολυμβητή: F (γυναίκα) ή M (άνδρας). -
Type— Τύπος αθλητή: swimmer (κολυμβητής) ή triathlete (τριαθλητής).
1. Αν οι ερευνητές ενδιαφέρονται για το αν η χρήση στολής δύτη επηρεάζει την ταχύτητα κολύμβησης, ποια είναι η εξαρτημένη μεταβλητή;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Επειδή κάθε κολυμβητής μετρήθηκε δύο φορές (μία με στολή, μία χωρίς), έχουμε δεδομένα κατά ζεύγη (paired data). Η μεταβλητή που μας ενδιαφέρει είναι η διαφορά στην ταχύτητα μεταξύ των δύο συνθηκών για κάθε κολυμβητή. Αυτή η διαφορά μας λέει πόσο επηρέασε η στολή την ταχύτητα του κάθε ατόμου. Οι απαντήσεις Β και Δ είναι μεμονωμένες μετρήσεις — καμία από τις δύο μόνη της δεν μας λέει για την επίδραση της στολής. Η απάντηση Γ (Type) είναι ο τύπος αθλητή και δεν θα μπορούσε να είναι εξαρτημένη.
2. Ο ακόλουθος κώδικας δημιουργεί τη νέα μεταβλητή SpeedUp, τη διαφορά μεταξύ της μέγιστης ταχύτητας του κολυμβητή όταν φοράει στολή δύτη και όταν δεν τη φοράει. Επίσης, αναπαριστά διαγραμματικά τη νέα μεταβλητή σε ένα ιστόγραμμα.

Τι μπορείτε να συμπεράνετε από την κατανομή της SpeedUp;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Όλες οι τιμές της SpeedUp στο ιστόγραμμα είναι θετικές (κυμαίνονται περίπου από 0.04 έως 0.11 m/sec). Επειδή η SpeedUp ορίζεται ως Wetsuit − NoWetsuit, μια θετική τιμή σημαίνει ότι η ταχύτητα με στολή ήταν μεγαλύτερη από την ταχύτητα χωρίς στολή. Εφόσον και οι 12 παρατηρήσεις είναι θετικές, όλοι οι κολυμβητές στο δείγμα ήταν ταχύτεροι όταν φορούσαν στολή δύτη.
3. Η μεταβλητή SpeedUp περιέχει την ταχύτητα κολύμβησης με Wetsuit μείον την ταχύτητα κολύμβησης με NoWetsuit. Το ιστόγραμμα φαίνεται παραπάνω. Θα μπορούσαν αυτές οι διαφορές στην ταχύτητα κολύμβησης να ακολουθούν κανονική κατανομή στον πληθυσμό;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Με ένα δείγμα μόλις 12 παρατηρήσεων, δεν μπορούμε να βγάλουμε σίγουρα συμπεράσματα για το σχήμα της πληθυσμιακής κατανομής. Ακόμα κι αν το ιστόγραμμα του δείγματος δεν φαίνεται πλήρως κανονικό (μοιάζει λίγο δικόρυφο ή ανομοιόμορφο), αυτό μπορεί εύκολα να οφείλεται σε τυχαία διακύμανση δειγματοληψίας — όχι σε μη κανονικότητα στον πληθυσμό. Η απάντηση Α είναι λάθος: η αφαίρεση δύο μετρήσεων δεν εμποδίζει το αποτέλεσμα να είναι κανονικά κατανεμημένο. Η απάντηση Β είναι λάθος: το μικρό μέγεθος δείγματος δεν μας λέει τίποτα για το σχήμα του πληθυσμού. Η απάντηση Δ βγάζει πολύ ισχυρό συμπέρασμα από πολύ λίγα δεδομένα.
4. Ένας ερευνητής αναρωτήθηκε αν μέρος της διακύμανσης στη διαφορά της ταχύτητας οφείλεται στον τύπο του κολυμβητή. Οι τριαθλητές κολυμπούν με στολές δύτη πιο συχνά από τους αγωνιστικούς κολυμβητές, και υπέθεσε ότι ενδεχομένως η εμπειρία τους θα επηρεάσει τα αποτελέσματα αυτής της μελέτης.
Για να διερευνήσει αυτή την περίπτωση, ο ερευνητής εκτέλεσε τον παρακάτω κώδικα για να παράγει ένα διαιρεμένο ιστόγραμμα της SpeedUp ανά τύπο αθλητή (Type).
Οι δύο κάθετες γραμμές αναπαριστούν το μέσο όρο της ομάδας των κολυμβητών και το μέσο όρο της ομάδας των τριαθλητών, αντίστοιχα.
Με βάση το ιστόγραμμα, ποια θα ήταν περίπου η τιμή PRE αυτού του μοντέλου;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το PRE (Proportional Reduction in Error - Αναλογική Μείωση του Σφάλματος) μετρά πόσο καλύτερα προβλέπει ένα σύνθετο μοντέλο σε σύγκριση με το κενό μοντέλο. Κοιτάζοντας τις δύο κάθετες γραμμές που αναπαριστούν τους μέσους όρους των δύο ομάδων, βλέπουμε ότι είναι πολύ κοντά η μία στην άλλη — σχεδόν συμπίπτουν. Αυτό σημαίνει ότι η γνώση του τύπου του αθλητή (κολυμβητής ή τριαθλητής) δεν προσθέτει σχεδόν καμία ανεξάρτητη ισχύ πέρα από τη χρήση του συνολικού μέσου όρου. Επιπλέον, η διακύμανση εντός κάθε ομάδας είναι παρόμοια με τη συνολική διακύμανση. Επομένως, το μοντέλο Type μειώνει ελάχιστα το σφάλμα, και το PRE αναμένεται να είναι κοντά στο 0.
6. Έστω ότι έχετε υπολογίσει το 95% διάστημα εμπιστοσύνης για τη SpeedUp. Για τι ακριβώς είστε βέβαιοι;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το διάστημα εμπιστοσύνης αναφέρεται στην πραγματική παράμετρο στον πληθυσμό (ΔΠΔ) — δηλαδή στο μέσο όρο της SpeedUp στη ΔΠΔ, που αντιπροσωπεύει την πραγματική επίδραση της στολής δύτη στην ταχύτητα κολύμβησης. Η απάντηση Β αναφέρεται σε ποσοστό ατόμων, όχι σε παράμετρο. Η Γ αναφέρεται σε μέσους όρους δειγμάτων, όχι στην πραγματική παράμετρο. Η Δ αναφέρεται στο σχήμα της κατανομής, που δεν είναι αυτό που μετρά ένα διάστημα εμπιστοσύνης.
7. Ποιος είναι ο σκοπός της δημιουργίας μιας δειγματοληπτικής κατανομής μέσων όρων της SpeedUp μέσω επαναδειγματοληψίας (γνωστής και ως μεθόδου bootstrap);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Ο σκοπός της δειγματοληπτικής κατανομής bootstrap είναι να δείξει πώς θα μπορούσε να ποικίλλει η εκτίμησή μας αν παίρναμε διαφορετικά δείγματα από τον πληθυσμό — μας δίνει μια μέτρηση της αβεβαιότητας γύρω από την εκτίμησή μας. Η απάντηση Β είναι λάθος: η μέθοδος bootstrap δεν προσθέτει νέες πληροφορίες στα δεδομένα. Η Γ είναι λάθος: η τύχη (τυχαιότητα) είναι θεμελιώδης στη διαδικασία — δεν μπορεί να εξαλειφθεί. Η Δ είναι λάθος: ο δειγματικός μέσος όρος υπολογίζεται άμεσα από τα δεδομένα, δεν χρειάζεται τη μέθοδο bootstrap για «επιβεβαίωση».
8. Αν δημιουργούσατε μια δειγματοληπτική κατανομή bootstrap 10.000 μέσων όρων από το δείγμα σας της SpeedUp, ποια χαρακτηριστικά θα περιμένατε να έχει;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Μια δειγματοληπτική κατανομή μέσων όρων έχει δύο βασικά χαρακτηριστικά: (1) Σχήμα: σύμφωνα με το Κεντρικό Οριακό Θεώρημα, οι δειγματοληπτικές κατανομές των μέσων όρων τείνουν προς μια κανονική κατανομή, ανεξάρτητα από το σχήμα του αρχικού δείγματος. (2) Διασπορά: η τυπική απόκλιση μιας δειγματοληπτικής κατανομής μέσων (το τυπικό σφάλμα) είναι πάντα μικρότερη από την τυπική απόκλιση των αρχικών δεδομένων — συγκεκριμένα, ισούται με \(s / \sqrt{n}\). Οι μέσοι όροι πολλών παρατηρήσεων ποικίλλουν λιγότερο από τις μεμονωμένες παρατηρήσεις.
Η απάντηση Α είναι λάθος για το σχήμα (η κατανομή θα είναι κανονική, όχι σαν του δείγματος). Η Γ είναι λάθος για τη διασπορά (θα είναι μικρότερη, όχι παρόμοια). Η Δ είναι λάθος μόνο στο θέμα της τυπικής απόκλισης — ο μέσος όρος όντως θα είναι παρόμοιος με τον δειγματικό, αλλά η τυπική απόκλιση θα είναι σαφώς μικρότερη.
9. Υποτίθεται ότι η ταχύτητα κολύμβησης ενός ατόμου φορώντας μόνο το μαγιό του (NoWetsuit) θα προβλέπει τη μέγιστη ταχύτητα του ενώ φοράει στολή δύτη (Wetsuit). Πώς θα αναπαριστούσαμε αυτό το μοντέλο της SpeedUp στο παρακάτω διάγραμμα;

ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Για να αναπαραστήσουμε διαγραμματικά ένα μοντέλο όπου η NoWetsuit προβλέπει την Wetsuit, χρειαζόμαστε μια ευθεία παλινδρόμησης που να περνά μέσα από τα σημεία — συγκεκριμένα, την ευθεία που δίνει η lm(Wetsuit ~ NoWetsuit, data = Wetsuits). Αυτή η ευθεία έχει μια συγκεκριμένη κλίση και σταθερό όρο που εκτιμώνται από τα δεδομένα. Η απάντηση Α (κάθετη γραμμή) δεν αναπαριστά σχέση μεταξύ δύο μεταβλητών. Η Γ (μια μόνο κουκκίδα) επίσης δεν αναπαριστά ένα γραμμικό μοντέλο. Η Δ (οριζόντια γραμμή στο μέσο όρο της Wetsuit) θα ήταν το κενό μοντέλο — αγνοεί την NoWetsuit ως ανεξάρτητη μεταβλητή.
10. Υποτίθεται ότι η ταχύτητα κολύμβησης ενός ατόμου φορώντας μόνο το μαγιό του (NoWetsuit) θα προβλέπει τη μέγιστη ταχύτητά του ενώ φοράει στολή δύτη (Wetsuit). Πώς θα αναπαραστούσαμε το κενό μοντέλο** της SpeedUp στο παρακάτω διάγραμμα;**
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Το κενό μοντέλο υποθέτει ότι η ανεξάρτητη μεταβλητή (NoWetsuit) δεν προβλέπει την εξαρτημένη μεταβλητή (Wetsuit) — δηλαδή η κλίση είναι 0. Οπτικά, αυτό απεικονίζεται ως μια οριζόντια γραμμή στο μέσο όρο της εξαρτημένης μεταβλητής, που σημαίνει ότι προβλέπουμε την ίδια τιμή Wetsuit για όλους, ανεξάρτητα από την NoWetsuit τους. Η απάντηση Α είναι το σύνθετο μοντέλο (ευθεία παλινδρόμησης με κλίση). Η Β είναι κάθετη γραμμή, που δεν έχει νόημα σε αυτό το πλαίσιο. Η Γ είναι μια μεμονωμένη κουκκίδα, που δεν αναπαριστά μοντέλο.
11. Το προσαρμοσμένο μοντέλο που χρησιμοποιεί την ταχύτητα NoWetsuit για να προβλέψει την Wetsuit είναι αυτό:
\[Y_i = 0.1423 + 0.9547 X_i + e_i\]
Πώς θα πρέπει να ερμηνεύσουμε την τιμή 0.9547;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Ο συντελεστής 0.9547 είναι η κλίση (\(\beta_1\)) της ευθείας παλινδρόμησης — μας λέει πόσο αλλάζει η τιμή πρόβλεψης της Wetsuit για κάθε αύξηση μίας μονάδας (1 m/sec) στη NoWetsuit. Η απάντηση Β περιγράφει μια διαφορά μέσων όρων, που είναι διαφορετική έννοια. Η Γ αναφέρεται στον σταθερό όρο \(\beta_0 = 0.1423\) (την τιμή της Wetsuit όταν NoWetsuit = 0), όχι στην κλίση. Η Δ είναι λίγο παραπλανητική — η κλίση δεν εφαρμόζεται «για τη NoWetsuit κάθε ατόμου», αλλά ανά μονάδα NoWetsuit.
12. Τι είδους κατανομή θα δημιουργούσε αυτός ο κώδικας;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Ο κώδικας κάνει τα εξής: η resample(Wetsuits) δημιουργεί ένα νέο δείγμα με τη μέθοδο bootstrap από τα αρχικά δεδομένα, η b1(Wetsuit ~ NoWetsuit, ...) υπολογίζει την κλίση (\(b_1\)) της ευθείας παλινδρόμησης για αυτό το δείγμα, και η do(10000) * ... επαναλαμβάνει τη διαδικασία 10.000 φορές. Το αποτέλεσμα είναι 10.000 εκτιμήσεις κλίσης — δηλαδή μια δειγματοληπτική κατανομή κλίσεων με τη μέθοδο bootstrap. Η απάντηση Β είναι λάθος: η μέθοδος bootstrap δεν δίνει τον πληθυσμό, αλλά μια προσομοίωση της δειγματοληπτικής κατανομής. Οι Γ και Δ αφορούν κατανομές μέσων όρων/διαφορών, ενώ εδώ υπολογίζουμε κλίσεις.
13. Το καλύτερα προσαρμοσμένο μοντέλο που χρησιμοποιεί τη NoWetsuit για να προβλέψει την Wetsuit μπορεί να διατυπωθεί ως εξής:
\[Wetsuit_i = b_0 + b_1(NoWetsuit_i) + e_i\]
Αν το διάστημα εμπιστοσύνης για την \(\beta_1\) είναι 0.9547 m/sec συν ή πλην 0.118 m/sec, ποια από τις ακόλουθες ερμηνείες ΔΕΝ είναι σωστή;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση (δηλαδή, η λανθασμένη ερμηνεία): Β.
Η απάντηση Β συγχέει το διάστημα εμπιστοσύνης με τη σχέση μεταξύ μεμονωμένων παρατηρήσεων. Το διάστημα εμπιστοσύνης για τη \(\beta_1\) αφορά την πραγματική τιμή της κλίσης στη ΔΠΔ — όχι ποσοστό ατόμων ή παρατηρήσεων. Δεν λέει τίποτα για το «95% όλων των ταχυτήτων».
Οι άλλες τρεις απαντήσεις είναι όλες αποδεκτές ερμηνείες: η Α λέει απλώς ότι η πραγματική παράμετρος πιθανότατα βρίσκεται εντός του διαστήματος (σωστό). Η Γ είναι η κλασική τυπική ερμηνεία του 95% διαστήματος εμπιστοσύνης (σωστό). Η Δ αναφέρεται στο γεγονός ότι αν επαναλαμβάναμε τη δειγματοληψία, η κλίση ενός νέου δείγματος θα έπεφτε στο διάστημα εμπιστοσύνης περίπου το 95% των φορών — αυτή είναι μια αποδεκτή, αν και ελαφρώς χαλαρή, ερμηνεία που προσεγγίζει τον τεχνικά σωστό ορισμό της μακροπρόθεσμης συμπεριφοράς.
14. Το καλύτερα προσαρμοσμένο μοντέλο που χρησιμοποιεί τη NoWetsuit για να προβλέψει την Wetsuit μπορεί να διατυπωθεί ως εξής:
\[Wetsuit_i = b_0 + b_1(NoWetsuit_i) + e_i\]
Αν το διάστημα εμπιστοσύνης για το \(\beta_1\) είναι 0.9547 m/sec συν ή πλην 0.118 m/sec, πόσο μεγάλο είναι το τυπικό σφάλμα της δειγματοληπτικής κατανομής του \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Θυμηθείτε τον εμπειρικό κανόνα: το περιθώριο σφάλματος είναι περίπου 2 τυπικά σφάλματα. Άρα, αν το περιθώριο σφάλματος είναι 0.118, το τυπικό σφάλμα είναι περίπου \(0.118 / 2 = 0.059\). Οι απαντήσεις Α και Γ περιλαμβάνουν τη διαίρεση με την τετραγωνική ρίζα του \(n\) — αυτός ο τύπος είναι για το τυπικό σφάλμα του μέσου (\(s / \sqrt{n}\)), όχι για τη σχέση μεταξύ περιθωρίου σφάλματος και τυπικού σφάλματος. Η απάντηση Β χρησιμοποιεί λάθος τιμή — το 0.9547 είναι η εκτίμηση της κλίσης, όχι το περιθώριο σφάλματος.
15. Προσαρμόσαμε ένα μοντέλο με την ταχύτητα NoWetsuit ως ανεξάρτητη μεταβλητή για να προβλέψουμε την ταχύτητα Wetsuit, και στη συνέχεια δημιουργήσαμε μια δειγματοληπτική κατανομή της κλίσης χρησιμοποιώντας τη μέθοδο bootstrap. Ο κώδικας R φαίνεται παρακάτω.
Ποιο θα είναι το κέντρο της δειγματοληπτικής κατανομής του \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η μέθοδος bootstrap υποθέτει ότι το δείγμα μας είναι αντιπροσωπευτικό της ΔΠΔ, οπότε κάνει επαναδειγματοληψία από τα αρχικά δεδομένα για να δημιουργήσει πολλά δείγματα. Το κέντρο της δειγματοληπτικής κατανομής bootstrap θα είναι κοντά στη δειγματική τιμή \(b_1 = 0.9547\) — τη δική μας καλύτερη εκτίμηση της παραμέτρου. Το 10000 είναι απλώς ο αριθμός των επαναλήψεων, όχι μια τιμή \(b_1\). Το 0 θα ήταν το κέντρο αν είχαμε χρησιμοποιήσει τη συνάρτηση shuffle() (προσομοίωση κενού μοντέλου), αλλά η συνάρτηση resample() κάνει κάτι διαφορετικό — κεντράρει την κατανομή στη δειγματική εκτίμηση.
16. Η μέγιστη μέση ταχύτητα κολύμβησης όταν φοράει κανείς στολή δύτη (δηλαδή η Wetsuit) είναι 1.51 m/sec. Αν το περιθώριο σφάλματος είναι 0.08 m/sec, ποιο είναι το εύρος των πιθανών τιμών εντός του οποίου είστε 95% βέβαιοι ότι θα βρίσκεται ο πραγματικός μέσος όρος του πληθυσμού;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Το διάστημα εμπιστοσύνης υπολογίζεται ως η εκτίμηση \(\pm\) περιθώριο σφάλματος. Εδώ: \(1.51 \pm 0.08\), που δίνει εύρος από \(1.51 - 0.08 = 1.43\) έως \(1.51 + 0.08 = 1.59\) m/sec. Η απάντηση Β χρησιμοποιεί λάθος υπολογισμό (φαίνεται να προσθέτει/αφαιρεί 0.04 αντί για 0.08). Οι απαντήσεις Α και Δ είναι λάθος: η τυπική απόκλιση μπορεί να χρησιμοποιηθεί για τον υπολογισμό του τυπικού σφάλματος και στη συνέχεια του περιθωρίου σφάλματος, αλλά μόλις μας δοθεί το περιθώριο σφάλματος (0.08), αυτή η πληροφορία είναι αρκετή από μόνη της για να υπολογίσουμε το διάστημα εμπιστοσύνης.
17. Ποια είναι η αξία της χρήσης της κατανομής \(t\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Η κατανομή \(t\) χρησιμοποιείται για τη μοντελοποίηση της δειγματοληπτικής κατανομής (όχι του πληθυσμού) — αυτή είναι η κρίσιμη διάκριση. Είναι ιδιαίτερα χρήσιμη όταν το μέγεθος του δείγματος είναι μικρό, επειδή λαμβάνει υπόψη την πρόσθετη αβεβαιότητα από το να μην γνωρίζουμε την πραγματική τυπική απόκλιση του πληθυσμού. Η απάντηση Α είναι λάθος λόγω της σύγχυσης ανάμεσα στον πληθυσμό και στη δειγματοληπτική κατανομή. Η Γ είναι λάθος: η κατανομή \(t\) είναι στην πραγματικότητα πιο μεταβλητή (έχει ευρύτερες ουρές) από την κανονική κατανομή, ειδικά για μικρά μεγέθη δείγματος. Η Δ είναι λάθος: οι βαθμοί ελευθερίας είναι παράμετρος της κατανομής \(t\), δεν προκύπτουν από αυτή.
18. Αν αποφασίσετε να αυξήσετε το επίπεδο εμπιστοσύνης σας στην εκτίμηση της Wetsuit (από 95% σε 99%), τι θα συμβεί στο διάστημα εμπιστοσύνης σας;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Όσο μεγαλύτερο το επίπεδο εμπιστοσύνης, τόσο ευρύτερο το διάστημα εμπιστοσύνης. Για να είμαστε περισσότερο βέβαιοι ότι το διάστημα περιέχει την πραγματική παράμετρο, πρέπει να «ρίξουμε ένα ευρύτερο δίχτυ». Η απάντηση Α είναι λάθος: το διάστημα δεν γίνεται «λιγότερο αξιόπιστο» — αντίθετα, γίνεται πιο αξιόπιστο με την έννοια ότι είμαστε πιο βέβαιοι. Οι Β και Γ αναφέρουν λάθος κατεύθυνση (στενότερο).
19. Αν θέλετε να μάθετε αν ένα μοντέλο παλινδρόμησης είναι καλύτερο από ένα απλό μοντέλο ως προς την πρόβλεψη, για ποια παράμετρο θα πρέπει να δημιουργήσετε μια δειγματοληπτική κατανομή;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Για να αξιολογήσουμε αν ένα μοντέλο παλινδρόμησης είναι καλύτερο από το κενό μοντέλο, εστιάζουμε στην κλίση (\(b_1\)) — επειδή το κενό μοντέλο υποθέτει ότι \(\beta_1 = 0\) (καμία σχέση μεταξύ της ανεξάρτητης και της εξαρτημένης μεταβλητής). Αν η κλίση διαφέρει σημαντικά από το 0, τότε το μοντέλο παλινδρόμησης παρέχει χρήσιμες πληροφορίες. Η απάντηση Β είναι λάθος: το διάστημα εμπιστοσύνης δεν είναι παράμετρος, είναι εργαλείο συμπερασματολογίας. Οι Γ και Δ δεν είναι σχετικές με τη σύγκριση μοντέλων παλινδρόμησης.
20. Παρακάτω είναι ο πίνακας ANOVA για το μοντέλο Wetsuit = NoWetsuit + άλλα πράγματα. Με βάση ποια απόσταση υπολογίζεται το SS Error (Σφάλματος);
Analysis of Variance Table (Type III SS)
Model: Wetsuit ~ NoWetsuit
SS df MS F PRE p
----- --------------- | ----- -- ----- ------- ----- -----
Model (error reduced) | 0.199 1 0.199 417.785 .9766 .0000
Error (from model) | 0.005 10 0.000
----- --------------- | ----- -- ----- ------- ----- -----
Total (empty model) | 0.204 11 0.019
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Το SS Error (άθροισμα τετραγώνων σφάλματος) ενός μοντέλου μετρά την απόσταση μεταξύ των πραγματικών τιμών των δεδομένων και των τιμών προβλέψης του μοντέλου — δηλαδή τα υπόλοιπα του μοντέλου. Για το μοντέλο NoWetsuit, αυτό είναι η διακύμανση που παραμένει ανεξήγητη μετά την προσαρμογή του μοντέλου. Η απάντηση Α περιγράφει το SS Total (συνολικό άθροισμα τετραγώνων). Η Β περιγράφει το SS Model (άθροισμα τετραγώνων του μοντέλου). Η Δ είναι συγκεχυμένη — τα υπόλοιπα είναι ήδη αποστάσεις, οπότε «απόσταση μεταξύ υπολοίπων» δεν έχει νόημα.
21. Ποια από τις ακόλουθες είναι η σωστή ερμηνεία του PRE (0.98) στον παρακάτω πίνακα ANOVA;
Analysis of Variance Table (Type III SS)
Model: Wetsuit ~ NoWetsuit
SS df MS F PRE p
----- --------------- | ----- -- ----- ------- ----- -----
Model (error reduced) | 0.199 1 0.199 417.785 .9766 .0000
Error (from model) | 0.005 10 0.000
----- --------------- | ----- -- ----- ------- ----- -----
Total (empty model) | 0.204 11 0.019
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Το PRE (Proportional Reduction in Error — Αναλογική Μείωση Σφάλματος) μετρά το ποσοστό του σφάλματος του κενού μοντέλου που μειώνεται (ή εξηγείται) προσθέτοντας την ανεξάρτητη μεταβλητή. Εδώ, το PRE = 0.98 σημαίνει ότι το 98% της διακύμανσης στη Wetsuit (SS Total) εξηγείται από τη NoWetsuit. Η απάντηση Α είναι λάθος: το SS Total είναι το ίδιο και στα δύο μοντέλα — αυτό που αλλάζει είναι το SS Error. Η Β έχει αντεστραμμένη λογική. Η Γ συγχέει την ερμηνεία του PRE — το PRE δεν αφορά το ποσοστό των παρατηρήσεων που μπορούν να προβλεφθούν, αλλά το ποσοστό της διακύμανσης που εξηγείται.
Ορισμένες από τις ερωτήσεις που ακολουθούν βασίζονται στο πλαίσιο δεδομένων SpeedDating, το οποίο περιέχει 276 παρατηρήσεις και 22 μεταβλητές. Τα δεδομένα προέρχονται από μια μελέτη στην οποία κάθε άτομο συμμετείχε σε ένα τετράλεπτο «ραντεβού» με ένα μέλος του αντίθετου φύλου. Στο τέλος του ραντεβού, ο καθένας αξιολογούσε το άλλο άτομο σε διάφορα χαρακτηριστικά.
Σχετικές μεταβλητές:
-
AgeM— Η ηλικία του άνδρα (σε έτη). -
AttractiveF— Η αξιολόγηση της ελκυστικότητας του άνδρα από τη γυναίκα (κλίμακα 1-10). -
AttractiveM— Η αξιολόγηση της ελκυστικότητας της γυναίκας από τον άνδρα (κλίμακα 1-10). -
DecisionM— Θα ήθελε ο άνδρας ένα ακόμη ραντεβού; (1 = ναι, 0 = όχι). -
FunM— Η αξιολόγηση του άνδρα για το πόσο χιούμορ έχει η γυναίκα (κλίμακα 1-10). -
IntelligentF— Η αξιολόγηση της ευφυΐας του άνδρα από τη γυναίκα (κλίμακα 1-10). -
LikeM— Πόσο συμπαθεί ο άνδρας τη γυναίκα (κλίμακα 1-10). -
RaceF— Η εθνικότητα της γυναίκας (Asian, Black, Caucasian, Latino, ή Other). -
RaceM— Η εθνικότητα του άνδρα (Asian, Black, Caucasian, Latino, ή Other). -
SharedInterestsM— Η αξιολόγηση του άνδρα για το πόσο κοινά ενδιαφέροντα έχει με τη γυναίκα (κλίμακα 1-10).
1. Έστω ότι χρησιμοποιήσατε την lm() για να προσαρμόσετε το κενό μοντέλο για την LikeM, και στη συνέχεια χρησιμοποιήσατε την confint() για να βρείτε το διάστημα εμπιστοσύνης. Τι σας λέει το διάστημα εμπιστοσύνης;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Στο κενό μοντέλο, υπάρχει μόνο μία παράμετρος: το \(\beta_0\), το οποίο είναι ο μέσος όρος της εξαρτημένης μεταβλητής (εδώ LikeM) στη ΔΠΔ. Άρα το διάστημα εμπιστοσύνης που επιστρέφει η confint() αναφέρεται στο \(\beta_0\) (Β), το οποίο είναι ταυτόχρονα ο μέσος όρος της LikeM στη ΔΠΔ (Γ). Αυτές οι δύο διατυπώσεις λένε το ίδιο πράγμα, οπότε η απάντηση Δ είναι η σωστή. Η απάντηση Α είναι λάθος: το κενό μοντέλο δεν έχει \(\beta_1\) — δεν υπάρχει ανεξάρτητη μεταβλητή.
Χρησιμοποιώντας τον παραπάνω κώδικα, προσαρμόζουμε αυτό το μοντέλο:
\[Y_i = b_0 + b_1 X_i + e_i\]
2. Σε τι αναφέρεται το \(X_i\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Στο μοντέλο \(Y_i = b_0 + b_1 X_i + e_i\), ο δείκτης \(i\) αναφέρεται σε κάθε επιμέρους παρατήρηση (εδώ, κάθε άνδρα). Το \(X_i\) είναι η τιμή της ανεξάρτητης μεταβλητής για τον \(i\)-οστό άνδρα — σε αυτό το μοντέλο, η τιμή του στη FunM. Η απάντηση Β περιγράφει το \(b_1\) (την κλίση). Η Γ είναι ο μέσος όρος της FunM, όχι η ατομική τιμή. Η Δ αναφέρεται στην εξαρτημένη μεταβλητή LikeM, που αντιστοιχεί στο \(Y_i\), όχι στο \(X_i\).
3. Ποια κατανομή θα χρησιμοποιούσατε για να δημιουργήσετε ένα διάστημα εμπιστοσύνης γύρω από μια εκτίμηση παραμέτρου;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Τα διαστήματα εμπιστοσύνης κατασκευάζονται χρησιμοποιώντας δειγματοληπτικές κατανομές — κατανομές που δείχνουν πώς θα μπορούσε να ποικίλει η εκτίμηση της παραμέτρου σε διαφορετικά δείγματα. Το εύρος του διαστήματος εμπιστοσύνης καθορίζεται από τη διασπορά αυτής της δειγματοληπτικής κατανομής (το τυπικό σφάλμα). Η απάντηση Β (πληθυσμιακή κατανομή) είναι λάθος: δεν γνωρίζουμε την πληθυσμιακή κατανομή. Η Δ (κατανομή δείγματος) είναι λάθος: η κατανομή του δείγματος μας λέει για τα ίδια τα δεδομένα, όχι για τη μεταβλητότητα της εκτίμησης.
4. Αν αυξήσετε το μέγεθος του δείγματος σε μια μελέτη, πώς επηρεάζει το 95% διάστημα εμπιστοσύνης γύρω από μια εκτίμηση παραμέτρου;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Μεγαλύτερα δείγματα οδηγούν σε μικρότερο τυπικό σφάλμα, το οποίο με τη σειρά του οδηγεί σε στενότερο διάστημα εμπιστοσύνης. Αυτό σημαίνει ότι έχουμε πιο ακριβή εκτίμηση της πραγματικής παραμέτρου. Η απάντηση Γ είναι λάθος: το επίπεδο εμπιστοσύνης (95%) δεν αλλάζει με το μέγεθος του δείγματος — είναι μια επιλογή που κάνουμε εμείς. Αυτό που αλλάζει είναι η ακρίβεια (στενότητα) του διαστήματος.
5. Ποια είναι η διαφορά μεταξύ Τυπικής Απόκλισης και Τυπικού Σφάλματος;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Το τυπικό σφάλμα είναι η τυπική απόκλιση μιας δειγματοληπτικής κατανομής — μετρά πόσο ποικίλλει ένα στατιστικό (όπως μια εκτίμηση παραμέτρου) από δείγμα σε δείγμα. Η τυπική απόκλιση μετρά τη διασπορά μεμονωμένων τιμών στα ίδια τα δεδομένα (δείγμα ή πληθυσμό). Είναι μαθηματικά η ίδια έννοια (τετραγωνική ρίζα της μέσης τετραγωνικής απόκλισης), αλλά εφαρμόζεται σε διαφορετικές κατανομές. Η απάντηση Α μπερδεύει το τυπικό σφάλμα με τα υπόλοιπα. Η Β είναι λάθος — δεν είναι το ίδιο πράγμα. Η Δ είναι λάθος — και οι δύο είναι πάντα θετικές.
6. Προσαρμόζετε ένα μοντέλο παλινδρόμησης, στη συνέχεια κατασκευάζετε ένα 95% διάστημα εμπιστοσύνης για την εκτίμηση του \(\beta_1\). Αν το διάστημα εμπιστοσύνης περιλαμβάνει το 0, τι σημαίνει αυτό;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Όταν ένα 95% διάστημα εμπιστοσύνης για το \(\beta_1\) περιλαμβάνει το 0, σημαίνει ότι το 0 είναι μια από τις πιθανές τιμές που θα μπορούσαν εύλογα να έχουν παράγει το δείγμα μας. Επομένως, δεν μπορούμε να απορρίψουμε το κενό μοντέλο (όπου \(\beta_1 = 0\)) — αυτό ισοδυναμεί με τιμή \(p > 0.05\).
Η απάντηση Γ είναι λάθος επειδή συγχέει την βεβαιότητα με την πιθανότητα — το 95% δεν αναφέρεται στην πιθανότητα μιας συγκεκριμένης τιμής. Η Δ δεν είναι εντελώς λάθος, αλλά είναι ασαφής και ελλιπής — το ουσιαστικό συμπέρασμα δεν είναι ότι «το \(\beta_1\) θα μπορούσε να είναι 0» αφηρημένα, αλλά ότι δεν μπορούμε να απορρίψουμε το κενό μοντέλο στο οποίο \(\beta_1 = 0\). Η Α δίνει το σωστό συμπέρασμα.
7. Οι κατανομές δείγματος αποτελούνται από _______· οι δειγματοληπτικές κατανομές αποτελούνται από _______.
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Αυτή είναι μια κρίσιμη εννοιολογική διάκριση:
- Η κατανομή δείγματος (sample distribution) αποτελείται από τις ατομικές τιμές των δεδομένων μας — για παράδειγμα, τις βαθμολογίες
LikeMγια κάθε έναν από τους 276 άνδρες στοSpeedDating. - Η δειγματοληπτική κατανομή (sampling distribution) αποτελείται από στατιστικά δειγμάτων — για παράδειγμα, τους μέσους όρους της
LikeMαπό χιλιάδες υποθετικά δείγματα των 276 ατόμων, ή τις κλίσεις \(b_1\) από χιλιάδες δείγματα.
Η απάντηση Α αντιστρέφει τη σωστή σχέση (οι παράμετροι αφορούν τον πληθυσμό, όχι κατανομές). Η Γ αναφέρεται στα υπόλοιπα, που δεν είναι σχετικά. Η Δ είναι η αντίστροφη (ανάποδη) απάντηση της σωστής.
Το καλύτερα προσαρμοσμένο μοντέλο που χρησιμοποιεί την AttractiveM για να προβλέψει την LikeM μπορεί να διατυπωθεί ως εξής:
\[LikeM_i = b_0 + b_1 AttractiveM_i + e_i\]
8. Ποια από τις ακόλουθες είναι μια ΛΑΝΘΑΣΜΕΝΗ ερμηνεία του διαστήματος εμπιστοσύνης για το \(\beta_1\) σε αυτό το μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση (δηλαδή, η λανθασμένη ερμηνεία): Γ.
Η απάντηση Γ συγχέει το διάστημα εμπιστοσύνης για μια παράμετρο με ποσοστό ατομικών παρατηρήσεων. Το διάστημα εμπιστοσύνης για το \(\beta_1\) αφορά αποκλειστικά την πραγματική τιμή της κλίσης στη ΔΠΔ — όχι ποσοστό ατομικών αξιολογήσεων LikeM ή τη σχέση τους με τη AttractiveM.
Οι άλλες τρεις είναι όλες αποδεκτές ερμηνείες: η Α αναγνωρίζει σωστά ότι ένα 95% διάστημα εμπιστοσύνης σημαίνει ότι υπάρχει 5% πιθανότητα να μην περιέχει την πραγματική τιμή (σωστό). Η Β είναι μια χαλαρή διατύπωση, αλλά αποδεκτή εκδοχή της σωστής ερμηνείας. Η Δ είναι η κλασική τυπική ερμηνεία του 95% διαστήματος εμπιστοσύνης.
Το καλύτερα προσαρμοσμένο μοντέλο που χρησιμοποιεί την AttractiveM για να προβλέψει την LikeM μπορεί να διατυπωθεί ως εξής:
\[LikeM_i = b_0 + b_1 AttractiveM_i + e_i\]
9. Αν το 95% διάστημα εμπιστοσύνης για το \(\beta_1\) είναι 0.7139 συν ή πλην 0.0814, πόσο μεγάλο είναι το τυπικό σφάλμα της δειγματοληπτικής κατανομής του \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Σύμφωνα με τον εμπειρικό κανόνα, το περιθώριο σφάλματος είναι περίπου 2 τυπικά σφάλματα. Επομένως, το τυπικό σφάλμα υπολογίζεται ως: περιθώριο σφάλματος / 2 = \(0.0814 / 2 \approx 0.04\). Οι απαντήσεις Α και Δ χρησιμοποιούν λανθασμένα τη διαίρεση με την τετραγωνική ρίζα του \(n\) — αυτός ο τύπος είναι για το τυπικό σφάλμα του μέσου (\(s / \sqrt{n}\)), όχι για τη σχέση μεταξύ περιθωρίου σφάλματος και τυπικού σφάλματος σε ένα διάστημα εμπιστοσύνης. Η απάντηση Β χρησιμοποιεί λάθος τιμή — το 0.7139 είναι η εκτίμηση της κλίσης, όχι το περιθώριο σφάλματος.
10. Αν αποφασίσετε να αυξήσετε το επίπεδο εμπιστοσύνης σας για την εκτίμηση της LikeM (από 95% σε 99%), τι θα συμβεί στο διάστημα εμπιστοσύνης σας;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Για να είμαστε πιο βέβαιοι ότι το διάστημα εμπιστοσύνης περιέχει την πραγματική παράμετρο, πρέπει να ρίξουμε ένα ευρύτερο δίχτυ — δηλαδή να δημιουργήσουμε ένα ευρύτερο διάστημα. Το επίπεδο εμπιστοσύνης και το εύρος του διαστήματος συνδέονται άμεσα: υψηλότερο επίπεδο εμπιστοσύνης → ευρύτερο διάστημα. Η απάντηση Α είναι η λάθος κατεύθυνση. Η Β είναι λάθος: η σχέση είναι πάντα η ίδια, ανεξάρτητα από τη διακύμανση στη ΔΠΔ. Η Δ είναι λάθος: ο υπολογισμός δεν είναι πιο δύσκολος — απλώς αλλάζει το όρισμα level στη confint().
11. Το παραπάνω διάραμμα δείχνει την συμπάθεια του άνδρα προς τη γυναίκα (LikeM) ως συνάρτηση του αν θέλει να ξαναβγεί μαζί της (DecisionM, Ναι ή Όχι). Τι δείχνει το διάγραμμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Κοιτάζοντας προσεκτικά το πάνω διάγραμμα (0-No, δηλαδή DecisionM = No), βλέπουμε ότι υπάρχουν γυναίκες με αξιολογήσεις LikeM κοντά στο 8, 9, ακόμα και 10 — δηλαδή γυναίκες που άρεσαν πολύ στους άνδρες, αλλά οι άνδρες δεν ήθελαν να ξαναβγούν μαζί τους. Αυτό φανερώνει ότι η συμπάθεια από μόνη της δεν είναι αρκετή για να αποφασίσει κάποιος για ένα δεύτερο ραντεβού.
Η απάντηση Α είναι λάθος επειδή οι δύο κατανομές επικαλύπτονται — δεν είναι αλήθεια ότι όλες οι γυναίκες της ομάδας «Ναι» συμπαθήθηκαν περισσότερο από όλες της ομάδας «Όχι». Η Β είναι λάθος: στην ομάδα 1-Yes υπάρχουν κάποιες γυναίκες με βαθμολογία κάτω από 6 (γύρω στο 4-5). Η Δ είναι λάθος επειδή και οι Α και Β είναι λάθος.
Analysis of Variance Table
Outcome variable: FunM
Model: lm(formula = FunM ~ AgeM, data = SpeedDating)
SS df MS F PRE p
----- ----------------- -------- --- ------ ------ ----- -----
Model (error reduced) | 0.0706 1 0.0706 0.0218 1e-04 .8827
Error (from model) | 858.3413 265 3.2390
----- ----------------- -------- --- ------ ------ ------ -----
Total (empty model) | 863.9296 269 3.211612. Χρησιμοποιήσαμε τη μεταβλητή AgeM (ηλικία του άντρα) για να προβλέψουμε τις αξιολογήσεις σχετικά με το χιούμορ της γυναίκας (FunM). Η τιμή F για αυτό το μοντέλο στον παραπάνω πίνακα είναι 0.02. Τι μας λέει αυτή η τιμή F;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Καμία από τις πρώτες τρεις ερμηνείες δεν είναι σωστή:
- Α: Η τιμή που συγκρίνουμε με το 0.05 είναι η τιμή \(p\) (εδώ 0.8827), όχι η τιμή \(F\). Επιπλέον, εφόσον \(p > 0.05\), δεν θα απορρίπταμε το κενό μοντέλο — θα το διατηρούσαμε.
-
Β: Το ποσοστό του
SS Totalπου εξηγείται από το μοντέλο είναι το PRE (εδώ 1e-04 = 0.0001 = 0.01%), όχι η τιμή \(F\). Επιπλέον, αν διαβαζόταν ως ποσοστό, η τιμή \(F = 0.02\) δεν αντιστοιχεί σε «2%». - Γ: Η τιμή \(p\) μετρά την πιθανότητα να παρατηρήσουμε ένα δείγμα τόσο ακραίο όσο το δικό μας αν το κενό μοντέλο είναι αληθές — δεν είναι η πιθανότητα να είναι αληθής η μηδενική υπόθεση. Αυτή είναι μια κλασική παρανόηση της τιμής \(p\).
Η τιμή \(F\) από μόνη της είναι ένας λόγος που δείχνει πόσο μεγάλη είναι η εξηγούμενη διακύμανση σε σχέση με την ανεξήγητη — μια τιμή \(F\) κοντά στο 0 δείχνει ότι το μοντέλο εξηγεί πολύ μικρό μέρος της διακύμανσης. Οι ερμηνείες Α-Γ δεν αποδίδουν σωστά τι σημαίνει αυτή η τιμή.
13. Με τον παρακάτω κώδικα, δημιουργήσαμε ένα μοντέλο για να προβλέψουμε την LikeM χρησιμοποιώντας την FunM ως ανεξάρτητη μεταβλητή. Στη συνέχεια κατασκευάσαμε 95% διαστήματα εμπιστοσύνης γύρω από τις εκτιμήσεις των παραμέτρων.
Το αποτέλεσμα φαίνεται παρακάτω.
2.5 % 97.5 %
(Intercept) 1.7045724 3.0122213
FunM 0.5361076 0.7204848Αν επαναλαμβάναμε αυτή τη μελέτη και βρίσκαμε ένα μεγαλύτερο τυπικό σφάλμα, τι θα ήταν διαφορετικό στο διάστημα εμπιστοσύνης για το \(\beta_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β.
Το εύρος του διαστήματος εμπιστοσύνης εξαρτάται άμεσα από το τυπικό σφάλμα: το περιθώριο σφάλματος είναι περίπου 2 τυπικά σφάλματα (για ένα 95% διάστημα). Επομένως, μεγαλύτερο τυπικό σφάλμα → μεγαλύτερο περιθώριο σφάλματος → ευρύτερο διάστημα εμπιστοσύνης. Η απάντηση Α είναι λάθος: το επίπεδο εμπιστοσύνης παραμένει το ίδιο, αλλά το πλάτος αλλάζει με βάση το τυπικό σφάλμα. Η Γ είναι λάθος: το τυπικό σφάλμα είναι ο βασικός καθοριστικός παράγοντας του εύρους του διαστήματος εμπιστοσύνης. Η Δ αναφέρει λάθος κατεύθυνση.
14. Χρησιμοποιώντας το πλαίσιο δεδομένων SpeedDating, προσαρμόστε ένα μοντέλο της LikeM με ανεξάρτητη μεταβλητή τη SharedInterestsM. Ποιο είναι το 95% διάστημα εμπιστοσύνης για το \(\beta_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Εκτελώντας τον κώδικα:
η R θα επιστρέψει δύο γραμμές: μία για το (Intercept) (\(\beta_0\)) και μία για το SharedInterestsM (\(\beta_1\)). Το διάστημα εμπιστοσύνης για το \(\beta_1\) (η κλίση) εκτείνεται περίπου από 0.35 έως 0.53. Αυτό σημαίνει ότι για κάθε αύξηση μίας μονάδας στη βαθμολογία SharedInterestsM, η αναμενόμενη LikeM αυξάνεται κατά 0.35 έως 0.53 μονάδες (με 95% εμπιστοσύνη). Οι άλλες απαντήσεις περιλαμβάνουν τιμές που ανήκουν στο διάστημα εμπιστοσύνης για το \(\beta_0\) (περίπου 3.6 έως 4.7), όχι για το \(\beta_1\).
15. Χρησιμοποιήστε το παραπάνω πλαίσιο κώδικα για να κατασκευάσετε ένα ιστόγραμμα της αξιολόγησης χιούμορ των γυναικών από τους άνδρες (FunM) ανά εθνικότητα του άνδρα (RaceM) στο πλαίσιο δεδομένων SpeedDating. Για ποια από τις εθνικότητες μοιάζει το ιστόγραμμα περισσότερο με το παρακάτω;

ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Εκτελώντας:
η μεγαλύτερη ομάδα στο SpeedDating είναι αυτή των Caucasian ανδρών, και το ιστόγραμμα της θα έχει τον υψηλότερο αριθμό παρατηρήσεων (συμβατό με το διάγραμμα που δείχνει συχνότητες έως και ~38). Οι ομάδες Latino, Black και Asian έχουν πολύ μικρότερο αριθμό παρατηρήσεων στο σύνολο δεδομένων, οπότε τα ιστογράμματά τους θα έχουν χαμηλότερες ράβδους. Το συνολικό σχήμα του παραπάνω ιστογράμματος (ασύμμετρο στα αριστερά, με κορυφή γύρω στο 6.5–7.5) ταιριάζει με την κατανομή της FunM για τους Caucasian άνδρες.
16. Χρησιμοποιώντας το πλαίσιο δεδομένων SpeedDating, εκτελέστε την favstats() για τη μεταβλητή AttractiveF. Παρατηρείστε τις τιμές των στατιστικών που εμφανίζονται. Σε ποια τιμή θα ήταν μικρότερο το άθροισμα τετραγώνων των σφαλμάτων (sum of squares);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α.
Το άθροισμα τετραγώνων των σφαλμάτων (SS Error) ελαχιστοποιείται όταν προβλέπουμε για όλες τις παρατηρήσεις τον μέσο όρο της μεταβλητής. Αυτή είναι μια θεμελιώδης ιδιότητα του μέσου όρου: είναι η τιμή που ελαχιστοποιεί το άθροισμα των τετραγωνικών αποστάσεων από όλες τις τιμές των δεδομένων. Αν εκτελέσουμε την favstats(~ AttractiveF, data = SpeedDating), ο μέσος όρος της AttractiveF είναι περίπου 6.27, οπότε αυτή είναι η τιμή στην οποία το SS Error θα ήταν χαμηλότερο. Η τιμή 1.92 είναι περίπου η τυπική απόκλιση. Η τιμή 1 είναι η ελάχιστη τιμή της μεταβλητής. Η Δ είναι λάθος επειδή γνωρίζουμε με βεβαιότητα ότι ο μέσος όρος ελαχιστοποιεί το SS — αυτή είναι μια μαθηματική ιδιότητα.
17. Αν προσθέσουμε περισσότερους συμμετέχοντες στη μελέτη SpeedDating, ποιο από αυτά δεν θα μπορούσε να επηρεαστεί;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Το \(\beta_0\) είναι η πραγματική παράμετρος στη ΔΠΔ — είναι μια σταθερή ιδιότητα του πληθυσμού και δεν αλλάζει ανεξάρτητα από το πόσα δείγματα παίρνουμε ή πόσο μεγάλο είναι το δείγμα μας. Η προσθήκη περισσότερων συμμετεχόντων στη μελέτη μας δίνει καλύτερη εκτίμηση του \(\beta_0\), αλλά δεν αλλάζει την ίδια την παράμετρο.
Οι άλλοι δείκτες θα επηρεάζονταν:
Το \(\bar{Y}\) (μέσος όρος του δείγματος, Α) είναι ένα στατιστικό υπολογιζόμενο από τα δεδομένα — προσθέτοντας νέες παρατηρήσεις, αλλάζει.
Το \(b_0\) (εκτίμηση της παραμέτρου από τα δεδομένα, Β) επίσης αλλάζει με νέα δεδομένα.
Το \(n\) (μέγεθος του δείγματος, Δ) προφανώς αυξάνεται όταν προσθέτουμε συμμετέχοντες.
Η βασική ιδέα: τα ελληνικά γράμματα (\(\beta\)) αναφέρονται σε σταθερές παραμέτρους του πληθυσμού· τα λατινικά γράμματα (\(b\)) αναφέρονται σε εκτιμήσεις από δείγματα που μεταβάλλονται.
18. Υποθέστε ότι λάβαμε δύο τυχαία δείγματα από έναν πληθυσμό και μετρήσαμε την ίδια εξαρτημένη μεταβλητή. Το ένα δείγμα είχε \(n = 30\), το άλλο \(n = 60\). Ποια από τις ακόλουθες προτάσεις είναι αληθής;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ.
Το άθροισμα τετραγώνων (SS) είναι ένα αθροιστικό μέτρο — προσθέτει τις τετραγωνικές αποκλίσεις από τον μέσο όρο για όλες τις παρατηρήσεις. Όσο περισσότερες παρατηρήσεις έχουμε, τόσο μεγαλύτερο τείνει να είναι το SS. Με \(n = 60\) έναντι \(n = 30\), το άθροισμα 60 τετραγωνικών αποκλίσεων θα είναι σχεδόν σίγουρα μεγαλύτερο από το άθροισμα 30. (Σημειώστε ότι αυτό είναι διαφορετικό από τη διακύμανση ή την τυπική απόκλιση, που διαιρούν διά \(n\) (ή \(n-1\)) και επομένως δεν αλλάζουν συστηματικά με το μέγεθος του δείγματος.)
Η Α είναι λάθος: δείγματα διαφορετικού μεγέθους ανήκουν σε διαφορετικές δειγματοληπτικές κατανομές (το τυπικό σφάλμα διαφέρει). Η Β είναι λάθος: δεν υπάρχει συστηματική σχέση μεταξύ μεγέθους δείγματος και μέσου όρου — και τα δύο δείγματα εκτιμούν τον ίδιο πληθυσμιακό μέσο. Η Γ είναι αντίστροφα λανθασμένη: μεγαλύτερο δείγμα → μικρότερο τυπικό σφάλμα.
19. Αν δημιουργήσετε μια δειγματοληπτική κατανομή με τη μέθοδο bootstrap με βάση το δείγμα δεδομένων σας, ποιος θα είναι ο μέσος όρος της κατανομής bootstrap;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η μέθοδος bootstrap υποθέτει ότι ο πληθυσμός μοιάζει με το δείγμα μας — οπότε επαναδειγματοληπτεί από το ίδιο το δείγμα με αντικατάσταση. Επομένως, οι εκτιμήσεις που παράγει συγκεντρώνονται γύρω από τη δειγματική στατιστική, όχι γύρω από την (άγνωστη) πληθυσμιακή παράμετρο. Η απάντηση Β θα ήταν αληθής μόνο αν είχαμε πρόσβαση στην πραγματική πληθυσμιακή κατανομή. Η Δ (0) είναι ο μέσος μιας ανακατεμένης κατανομής (που προσομοιώνει το κενό μοντέλο), όχι μιας κατανομής bootstrap.
20. Αν χρησιμοποιήσετε τη συνάρτηση shuffle() για να δημιουργήσετε μια τυχαιοποιημένη δειγματοληπτική κατανομή του \(b_1\) (μιας διαφοράς ομάδων) με βάση ένα δείγμα δεδομένων, ποιος θα είναι ο μέσος όρος της προκύπτουσας δειγματοληπτικής κατανομής;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ.
Η συνάρτηση shuffle() ανακατεύει τις τιμές της εξαρτημένης μεταβλητής σε σχέση με την ομαδοποίηση, σπάζοντας οποιαδήποτε σχέση μεταξύ τους. Αυτό προσομοιώνει ένα κενό μοντέλο, στο οποίο δεν υπάρχει πραγματική διαφορά μεταξύ των ομάδων (\(\beta_1 = 0\)). Άρα η προκύπτουσα δειγματοληπτική κατανομή των \(b_1\) θα είναι κεντραρισμένη στο 0. Αντίθετα, η συνάρτηση resample() (μέθοδος bootstrap) διατηρεί τις σχέσεις μεταξύ των μεταβλητών και κεντράρει την κατανομή στη δειγματική εκτίμηση.