11Κεφάλαιο: Η Λογική της Στατιστικής Συμπερασματολογίας
«Όψις γάρ των αδήλων τα φαινόμενα.» — Αναξαγόρας
Έως αυτό το σημείο, έχετε αποκτήσει σημαντικά εφόδια στην ανάλυση δεδομένων. Εξοικειωθήκατε με την έννοια της κατανομής και μελετήσατε δύο από τους τρεις πυλώνες της στατιστικής:
Την κατανομή των δεδομένων του δείγματος (αυτήν που παρατηρούμε).
Την κατανομή του πληθυσμού (αυτήν που εκφράζει την υποκείμενη Διαδικασία Παραγωγής των Δεδομένων - ΔΠΔ).
Μάθατε πώς να ορίζετε και να προσαρμόζετε στατιστικά μοντέλα (όπως το Γενικό Γραμμικό Μοντέλο), πώς να ποσοτικοποιείτε την ποιότητα προσαρμογής τους ελαχιστοποιώντας το σφάλμα, και πώς να συγκρίνετε διαφορετικά μοντέλα για να κάνετε προβλέψεις που βελτιώνουν την κατανόηση της ΔΠΔ.
Ωστόσο, η βέλτιστη προσαρμογή ενός μοντέλου στα δεδομένα μας δεν λύνει το βασικό μας πρόβλημα: δεν γνωρίζουμε με βεβαιότητα πόσο καλά το μοντέλο αυτό αντιπροσωπεύει την πραγματική ΔΠΔ. Γνωρίζουμε πώς συμπεριφέρεται το μοντέλο μας και οι εκτιμήσεις των παραμέτρων του (όπως το \(b_0\) και το \(b_1\)) σε σχέση με το συγκεκριμένο δείγμα που έχουμε στα χέρια μας, αλλά η αβεβαιότητα παραμένει για τον ευρύτερο πληθυσμό και τις πραγματικές παραμέτρους (\(\beta_0\) και \(\beta_1\)) από τις οποίες προήλθαν αυτά τα δεδομένα.
Σε αυτό το μέρος του βιβλίου, περνάμε από την περιγραφή στην συμπερασματολογία. Θα εξετάσουμε πώς οι επιστήμονες αξιολογούν την αξιοπιστία των μοντέλων τους και πώς ποσοτικοποιούν το σφάλμα που περιβάλλει τις εκτιμήσεις των παραμέτρων.
Θα συμπληρώσουμε την «Τριάδα των Κατανομών» με την εισαγωγή της δειγματοληπτικής κατανομής (ή κατανομής των εκτιμήσεων).
Τύπος Κατανομής
Αντικείμενο
Κατάσταση
Κατανομή Δείγματος
Παρατηρήσεις στα δεδομένα μας
Πραγματική και Γνωστή
Κατανομή Πληθυσμού (ΔΠΔ)
Οι άγνωστες παρατηρήσεις στον πληθυσμό
Πραγματική αλλά Άγνωστη
Δειγματοληπτική Κατανομή
Στατιστικά (π.χ. μέσος όρος ή \(b_1\))
Υποθετική / «Φανταστική»
Ενώ οι δύο πρώτες κατανομές αφορούν στις γνωστές και άγνωστες παρατηρήσεις, η δειγματοληπτική κατανομή είναι ένα κατασκεύασμα της στατιστικής συλλογιστικής. Απαιτεί από εμάς να κάνουμε υποθετικά σενάρια, ρωτώντας:
«Τι θα συνέβαινε αν επαναλαμβάναμε τη διαδικασία δειγματοληψίας άπειρες φορές;»
11.1 Το Πρόβλημα της Στατιστικής Συμπερασματολογίας
Σε προηγούμενα κεφάλαια, μάθατε πώς να ορίζετε και να προσαρμόζετε στατιστικά μοντέλα σε δεδομένα, και πώς να χρησιμοποιείτε τη σημειογραφία του Γενικού Γραμμικου Μοντέλου (GLM) για να αναπαραστήσετε αυτά τα μοντέλα (π.χ., \(Y_i = b_0 + b_1 X_i + e_i\)). Τέτοια μοντέλα πράγματι μπορεί να είναι τα βέλτιστα που προσαρμόζονται στα δεδομένα μας, αλλά τα δεδομένα μας δεν είναι πάντα αντιπροσωπευτικά της διαδικασίας παραγωγής τους.
Αυτό που μας ενδιαφέρει στην πραγματικότητα είναι να εντοπίσουμε το καλύτερο μοντέλο για τη ΔΠΔ (π.χ., \(Y_i = \beta_0 + \beta_1 X_i + \epsilon_i\)). Ένα πιο σύνθετο μοντέλο είναι πάντα ένα καλύτερο μοντέλο για τα δεδομένα, αλλά είναι και καλύτερο μοντέλο για τη ΔΠΔ συγκριτικά με το κενό μοντέλο; Ποιες είναι οι πραγματικές τιμές των \(\beta_i\) και \(\beta_0\);
Δυστυχώς, δεν μπορούμε να υπολογίσουμε απευθείας τις τιμές των παραμέτρων του μοντέλου στη ΔΠΔ. Μπορούμε φυσικά να τις εκτιμήσουμε με τους συντελεστές \(b_0\) και \(b_1\), αλλά δε γνωρίζουμε πόσο ακριβείς είναι αυτές οι εκτιμήσεις. Στα επόμενα κεφάλαια, θα δούμε πώς να καταλήγουμε σε συμπεράσματα για τη ΔΠΔ, βασιζόμενοι σε μοντέλα που έχουμε εκτιμήσει από ένα δείγμα.
Το πώς γεφυρώνουμε το χάσμα ανάμεσα στα δεδομένα μας και τη ΔΠΔ αναφέρεται συχνά ως το πρόβλημα της στατιστικής συμπερασματολογίας (statistical inference problem). Έχουμε ήδη διερευνήσει άτυπα αυτό το πρόβλημα σε προηγούμενα κεφάλαια. Γνωρίζουμε ότι η ίδια ΔΠΔ μπορεί να παράγει πολλά διαφορετικά δείγματα. Ωστόσο, είναι δύσκολο να γνωρίζουμε ακριβώς από ποια ΔΠΔ προήλθε ένα δείγμα. Στα κεφάλαια που ακολουθούν, διερευνούμε πιθανές λύσεις σε αυτό το πρόβλημα, περιγράφοντας τη λογική της στατιστικής συμπερασματολογίας και τα οφέλη που αποκομίζουμε από αυτήν.
Ποια από τις παρακάτω δηλώσεις είναι αληθής;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Είτε γνωρίζουμε τη ΔΠΔ είτε όχι, τα δείγματα που παράγονται από μια ΔΠΔ θα ποικίλουν.
Τι είναι η Διαδικασία Παραγωγής Δεδομένων (ΔΠΔ);
Η ΔΠΔ είναι η πραγματική, υποκείμενη διαδικασία που παράγει τα δεδομένα που παρατηρούμε. Σκεφτείτε την ως:
Το πραγματικό μοντέλο που ισχύει για το φαινόμενο που μελετάμε
Τη θεωρητική κατανομή από την οποία προέρχονται οι παρατηρήσεις μας
Τις πραγματικές τιμές των παραμέτρων που θέλουμε να βρούμε
Παράδειγμα:
Αν μελετάμε το ύψος των ανθρώπων, η ΔΠΔ περιλαμβάνει:
Την πραγματική κατανομή του ύψους στον πληθυσμό
Τους πραγματικούς παράγοντες που επηρεάζουν το ύψος (γενετική, διατροφή, κλπ.)
Τον πραγματικό μέσο όρο και τυπική απόκλιση του πληθυσμού
Το θεμελιώδες πρόβλημα της στατιστικής
Το κεντρικό πρόβλημα:
Δεν γνωρίζουμε ποτέ την πραγματική ΔΠΔ. Έχουμε μόνο ένα δείγμα δεδομένων από αυτήν.
Η πρόκληση της συμπερασματολογίας:
Έχουμε: Ένα δείγμα δεδομένων (π.χ., 100 παρατηρήσεις)
Θέλουμε να μάθουμε: Την πραγματική ΔΠΔ (τις πραγματικές παραμέτρους του πληθυσμού)
Το πρόβλημα: Διαφορετικά δείγματα από την ίδια ΔΠΔ θα δώσουν διαφορετικές εκτιμήσεις!
Ανάλυση των επιλογών
Α. “Αν γνωρίζαμε πραγματικά τη ΔΠΔ, τότε τα δείγματα που παράγονται από αυτή τη ΔΠΔ δεν θα διαφέρουν μεταξύ τους.” — ΛΑΘΟΣ
Γιατί είναι λάθος:
Αυτή η δήλωση συγχέει την ΔΠΔ με τα δείγματα.
Η ΔΠΔ είναι σταθερή και καθορισμένη
Τα δείγματα από τη ΔΠΔ πάντα ποικίλλουν λόγω τυχαίας μεταβλητότητας
Παράδειγμα:
Ας υποθέσουμε ότι γνωρίζουμε την πραγματική ΔΠΔ:
Ρίχνουμε ένα δίκαιο ζάρι (η ΔΠΔ είναι γνωστή: κάθε αριθμός 1-6 έχει πιθανότητα 1/6)
Οι εκτιμήσεις μας πλησιάζουν τις πραγματικές τιμές των παραμέτρων
Η αβεβαιότητα μειώνεται (μικρότερη τυπική απόκλιση)
Τι ΔΕΝ είναι αλήθεια:
Δεν μπορούμε ποτέ να γνωρίζουμε με βεβαιότητα την πραγματική ΔΠΔ, ανεξάρτητα από το μέγεθος του δείγματος!
Γιατί;
Πάντα υπάρχει αβεβαιότητα:
Ακόμα και με 1,000,000 παρατηρήσεις, έχουμε μόνο μια εκτίμηση
Η πραγματική τιμή της παραμέτρου μπορεί να είναι \(\mu = 100.000\) ή \(\mu = 100.001\)
Σφάλμα δειγματοληψίας:
Κάθε δείγμα (ακόμα και μεγάλο) έχει τυχαία μεταβλητότητα
\(\bar{X} \neq \mu\) (ο μέσος του δείγματος ≠ μέσος του πληθυσμού)
Θεωρητικά όρια:
Για να γνωρίζουμε τη ΔΠΔ, θα χρειαζόμασταν άπειρες παρατηρήσεις
Ή θα έπρεπε να παρατηρήσουμε ολόκληρο τον πληθυσμό
Συμπέρασμα
Η σωστή απάντηση είναι Β:
Είτε γνωρίζουμε τη ΔΠΔ είτε όχι, τα δείγματα που παράγονται από μια ΔΠΔ θα ποικίλουν.
Αυτό συμβαίνει επειδή:
Η τυχαία μεταβλητότητα είναι εγγενής στη δειγματοληψία
Η γνώση της ΔΠΔ δεν εξαλείφει την τυχαιότητα
Κάθε δείγμα είναι μια διαφορετική τυχαία όψη από την ίδια ΔΠΔ
Αυτή η θεμελιώδης αλήθεια είναι η βάση της στατιστικής συμπερασματολογίας:
Επειδή τα δείγματα ποικίλλουν, πρέπει να χρησιμοποιήσουμε στατιστικές μεθόδους για να συμπεράνουμε την άγνωστη ΔΠΔ και να ποσοτικοποιήσουμε την αβεβαιότητα των εκτιμήσεών μας.
Η ομορφιά της στατιστικής:
Παρόλο που δεν μπορούμε ποτέ να γνωρίζουμε την πραγματική ΔΠΔ με βεβαιότητα, μπορούμε να καταλήξουμε με συστηματικό τρόπο σε αξιόπιστα συμπεράσματα για αυτήν!
Μια Νέα Έννοια: Η Δειγματοληπτική Κατανομή
Κλειδί για την επίλυση του προβλήματος της συμπερασματολογίας θα είναι μια νέα και σημαντική έννοια που μας επιτρέπει να παρατηρήσουμε πώς μπορεί να ποικίλλουν διαφορετικά δείγματα που προέρχονται από την ίδια ΔΠΔ και πόσο μπορεί να ποικίλλουν οι εκτιμήσεις των τιμών των παραμέτρων που υπολογίζονται από πολλά διαφορετικά δείγματα. Μπορείτε να σκεφτείτε αυτές τις πολλές εκτιμήσεις των τιμών μιας παραμέτρου ως ένα νέο είδος κατανομής, που ονομάζεται δειγματοληπτική κατανομή (sampling distribution).
Μέχρι αυτό το σημείο, έχουμε εξετάσει δύο ειδών κατανομές: την κατανομή μιας μεταβλητής στο δείγμα και την κατανομή μιας μεταβλητής στη ΔΠΔ (που ονομάζεται και πληθυσμός). Η δειγματοληπτική κατανομή είναι το τρίτο είδος αυτού που αποκαλούμε «Τριάδα των Κατανομών»: η κατανομή των εκτιμήσεων μιας παραμέτρου σε πολλά πιθανά δείγματα, ίδιου μεγέθους, που προέρχονται από μια δεδομένη ΔΠΔ.
Τα δείγματα και οι πληθυσμοί αποτελούνται από υποκείμενα ή αντικείμενα των οποίων τα χαρακτηριστικά μπορούμε να μετρήσουμε (για παράδειγμα, μήκη αντίχειρα ή ύψη μαθητών). Οι δειγματοληπτικές κατανομές, αντιθέτως, αποτελούνται από εκτιμήσεις τιμών παραμέτρων που θα μπορούσαμε να υπολογίσουμε για διαφορετικά δείγματα που προέρχονται από την ίδια ΔΠΔ (για παράδειγμα, μια κατανομή μέσων όρων ή μια κατανομή τιμών \(b_1\)). Σε αυτό το κεφάλαιο, θα εστιάσουμε στη δειγματοληπτική κατανομή του στατιστικού \(b_1\), δηλαδή της εκτίμησης της παραμέτρου \(\beta_1\).
Ποιο από τα παρακάτω ισχύει για τα στατιστικά;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Υπολογίζονται με βάση ένα δείγμα.
Βασικές έννοιες
Παράμετροι (Parameters) vs Στατιστικά ή Εκτιμήσεις Παραμέτρων (Estimates):
Χρησιμοποιούμε αυτά τα στατιστικά ως εκτιμήσεις των παραμέτρων του πληθυσμού
Παράδειγμα:
# Δείγμα από πληθυσμόsample_data <-data.frame(x =c(2, 5, 7, 9, 12),y =c(3, 8, 10, 14, 18))# Εκτίμηση παραμέτρων από το ΔΕΙΓΜΑmodel <-lm(y ~ x, data = sample_data)coef(model)# (Intercept) x # 0.5238 1.4286 ← Αυτές είναι ΕΚΤΙΜΗΣΕΙΣ των b₀, b₁# Οι ΠΡΑΓΜΑΤΙΚΕΣ παράμετροι (β₀, β₁) του πληθυσμού;# ΑΓΝΩΣΤΕΣ! Χρησιμοποιούμε το δείγμα για να τις εκτιμήσουμε.
Γιατί οι άλλες επιλογές είναι λάθος;
Β. «Υπολογίζονται για κάθε παρατήρηση ξεχωριστά» — ΛΑΘΟΣ
Γιατί είναι λάθος:
Τα στατιστικά ΔΕΝ υπολογίζονται για κάθε παρατήρηση — υπολογίζονται για ολόκληρο το δείγμα!
Τι υπολογίζεται για κάθε παρατήρηση:
Τιμές πρόβλεψης (\(\hat{y}_i\)): Για κάθε παρατήρηση
Υπόλοιπα (\(e_i = y_i - \hat{y}_i\)): Για κάθε παρατήρηση
Τι υπολογίζεται για το δείγμα:
Εκτιμήσεις παραμέτρων (\(b_0, b_1\)): Μία τιμή για ολόκληρο το δείγμα
Παράδειγμα:
model <-lm(y ~ x, data = data)# ΜΙΑ εκτίμηση για τον σταθερό όρο (για ΟΛΟ το δείγμα)coef(model)[1] # b₀ = 2.5# ΜΙΑ εκτίμηση για την κλίση (για ΟΛΟ το δείγμα)coef(model)[2] # b₁ = 0.8# ΑΛΛΑ: Διαφορετικές προβλέψεις για κάθε παρατήρησηfitted(model)# [1] 3.1 4.7 5.9 8.3 10.1 ← Μία τιμή πρόβλεψης για κάθε παρατήρηση
Γ. «Οι τιμές τους είναι σχεδόν πάντα ίσες με τις τιμές των παραμέτρων» — ΛΑΘΟΣ
Γιατί είναι λάθος:
Οι τιμές των στατιστικών σχεδόν ποτέ δεν είναι ακριβώς ίσες με τις πραγματικές παραμέτρους!
Η πραγματικότητα:
Λόγω δειγματοληπτικής μεταβλητότητας, οι τιμές των στατιστικών από το δείγμα αναμένεται να διαφέρουν από τις πραγματικές παραμέτρους του πληθυσμού.
Τα στατιστικά:
Είναι αμερόληπτοι εκτιμητές (η τιμή τους θα είναι, κατά μέσο όρο, ίση με την πραγματική τιμή)
Αλλά κάθε μεμονωμένη εκτίμηση θα διαφέρει από την πραγματική τιμή
Δ. «Είναι άγνωστες και δεν μπορούν να υπολογιστούν» — ΛΑΘΟΣ
Γιατί είναι λάθος:
Αυτή η δήλωση συγχέει τις τιμές των στατιστικών με τις τιμές των παραμέτρων!
Η σωστή διάκριση:
Παράμετροι πληθυσμού (\(\beta_0, \beta_1, \mu, \sigma\)):
Είναι άγνωστες
Δεν μπορούν να υπολογιστούν (εκτός αν έχουμε ολόκληρο τον πληθυσμό)
Είναι σταθερές
Τιμές στατιστικών από δείγμα (\(b_0, b_1, \bar{x}, s\)):
Είναι γνωστές
ΜΠΟΡΟΥΝ να υπολογιστούν από το δείγμα
Χρησιμοποιούνται για να προσεγγίσουν τις τιμές των παραμέτρων
Υπολογίζονται με βάση ένα δείγμα και χρησιμοποιούνται για να εκτιμήσουν τις άγνωστες παραμέτρους του πληθυσμού.
Η μεγάλη ιδέα της στατιστικής:
Χρησιμοποιούμε γνωστά στατιστικά από ένα δείγμα για να εξάγουμε συμπεράσματα για άγνωστες παραμέτρους του πληθυσμού.
Απόρριψη του «Κενού» Μοντέλου: Η Βασική Ιδέα
Όταν παρατηρούμε μια διαφορά μεταξύ δύο ομάδων στα δεδομένα μας, μπορεί να μπούμε στον πειρασμό να συμπεράνουμε ότι υπάρχει και διαφορά μεταξύ των δύο ομάδων στον αντίστοιχο πληθυσμό (ΔΠΔ) από τον οποίο προέρχονται. Δηλαδή, όταν το \(b_1\) είναι διαφορετικό από το μηδέν, μπορεί να οδηγηθούμε στο (εσφαλμένο) συμπέρασμα ότι και το \(\beta_1\) δεν θα είναι μηδέν. Το πρόβλημα με αυτόν τον συλλογισμό είναι ότι ακόμα και το «κενό» μοντέλο μιας ΔΠΔ, στο οποίο ισχύει ότι \(\beta_1 = 0\), μπορεί να παράγει δείγματα στα οποία θα υπάρχει διαφορά μεταξύ των δύο ομάδων.
Η βασική ιδέα, που θα αναπτυχθεί σε αυτό το κεφάλαιο, απαιτεί από εσάς να χρησιμοποιήσετε δεξιότητες υποθετικής σκέψης. Χρειάζεται να αναρωτηθείτε: αν υποθέσουμε ότι το «κενό» μοντέλο είναι αυτό που ισχύει για τη ΔΠΔ πόσο πιθανό θα ήταν να παρατηρήσουμε το \(b_1\) που υπολογίσαμε από τα δεδομένα μας; Για να απαντήσουμε σε αυτό θα προσομοιώσουμε με την R μια ΔΠΔ για την οποία ισχύει ότι \(\beta_1 = 0\), και θα δημιουργήσουμε από αυτήν πολλαπλά πιθανά δείγματα. Θα εξετάσουμε τις τιμές \(b_1\) που θα προκύψουν από αυτά τα πολλαπλά δείγματα των προσομοιωμένων δεδομένων και θα διαπιστώσουμε αν τα δικά μας δεδομένα μοιάζουν ή όχι με τα προσομοιωμένα.
Αν μια ΔΠΔ για την οποία ισχύει ότι \(\beta_1 = 0\) συχνά παράγει δείγματα που είναι παρόμοια με το δείγμα μας, τότε μπορούμε να συμπεράνουμε:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Ότι η ΔΠΔ με β₁ = 0 θα μπορούσε να έχει παράγει το δειγματικό b₁.
Κατανόηση του συμβολισμού
Πρώτα, ας ξεκαθαρίσουμε τη διαφορά μεταξύ:
β₁: Η πραγματική παράμετρος στη ΔΠΔ (Διαδικασία Παραγωγής Δεδομένων)
Αυτή είναι η πραγματική τιμή που δεν γνωρίζουμε
Σταθερή, αλλά άγνωστη
Παράδειγμα: Η πραγματική επίδραση των ωρών μελέτης στη βαθμολογία σε ένα μάθημα
b₁: Η εκτίμηση της παραμέτρου β₁ από το δείγμα μας
Αυτή είναι η τιμή που υπολογίζουμε από τα δεδομένα μας
Ποικίλλει από δείγμα σε δείγμα
Παράδειγμα: b₁ = 0.45 (η εκτίμηση από το συγκεκριμένο μας δείγμα)
Απλά:
β₁ = Η πραγματικότητα (άγνωστη)
b₁ = Η εκτίμησή μας (γνωστή)
Το πλαίσιο του προβλήματος
Η κατάσταση:
Έχουμε ένα πραγματικό δείγμα από το οποίο υπολογίσαμε b₁ (π.χ., b₁ = 0.45)
Θέλουμε να ελέγξουμε αν η πραγματική παράμετρος στη ΔΠΔ είναι β₁ = 0 (δηλαδή, δεν υπάρχει κανένα αποτέλεσμα)
Για να το κάνουμε αυτό, προσομοιώνουμε πολλά δείγματα από μια ΔΠΔ όπου β₁ = 0
Η ερώτηση λέει: “Αν ισχύει ότι αυτή η ΔΠΔ (με β₁ = 0) παράγει δείγματα παρόμοια με το δικό μας…”
Ανάλυση των επιλογών
Α. “Ότι μια ΔΠΔ με β₁ = 0 θα μπορούσε να έχει παράγει το δείγμα μας b₁.” — ΣΩΣΤΟ ✓
Γιατί είναι σωστό:
Χρησιμοποιεί τη λέξη “θα μπορούσε” — δείχνει πιθανότητα, όχι βεβαιότητα
Αναγνωρίζει ότι το β₁ = 0 είναι συμβατό με τα δεδομένα μας
Δεν ισχυρίζεται βεβαιότητα, αλλά δυνατότητα
Η λογική:
Αν συχνά η ΔΠΔ (β₁ = 0) παράγει παρόμοια δείγματα, τότε:
Η ΔΠΔ αυτή είναι συνεπής με τα δεδομένα μας
Το δείγμα μας θα μπορούσε πιθανώς να προέρχεται από αυτή
Δεν έχουμε αρκετές ενδείξεις για να την απορρίψουμε
Β. “Ότι μια ΔΠΔ με β₁ = 0 σίγουρα πρέπει να έχει παράγει το δείγμα μας b₁.” — ΛΑΘΟΣ
Γιατί είναι λάθος:
Αυτή η δήλωση είναι υπερβολικά κατηγορηματική και εσφαλμένη:
Η λέξη “Σίγουρα” είναι πολύ ισχυρή
Δεν μπορούμε ποτέ να είμαστε απόλυτα σίγουροι για την άγνωστη ΔΠΔ
Η λέξη “Πρέπει” υπονοεί αναγκαιότητα
Υπάρχουν πολλές πιθανές ΔΠΔ που θα μπορούσαν να παράγουν το δείγμα μας
Το λογικό σφάλμα:
“Αν μια ΔΠΔ με β₁ = 0 μπορεί να εξηγήσει τα δεδομένα, τότε πρέπει να είναι η αλήθεια.”
Γιατί είναι λάθος:
Πολλές διαφορετικές ΔΠΔ θα μπορούσαν να παράγουν το ίδιο δείγμα
Μια ΔΠΔ με β₁ = 0.1 ή β₁ = 0.2 μπορεί επίσης να είναι συμβατή με τα δεδομένα
Γ. “Ότι είναι αδύνατο μια ΔΠΔ με β₁ = 0 να έχει παράγει το δείγμα μας b₁.” — ΛΑΘΟΣ
Γιατί είναι λάθος:
Αυτή η απάντηση λέει:
“Είναι αδύνατο για μια ΔΠΔ με β₁ = 0 να έχει παράγει το δείγμα…”
Η αντίφαση με την εκφώνηση:
Αν συχνά παράγει δείγματα παρόμοια με το δείγμα μας, τότε δεν είναι αδύνατο
Δ. “Ότι είναι απίθανο μια ΔΠΔ με β₁ = 0 να έχει παράγει το δείγμα μας b₁.” — ΛΑΘΟΣ
Γιατί είναι λάθος:
Όπως και η επιλογή Γ, αυτή η απάντηση αντιφάσκει με την εκφώνηση:
Η εκφώνηση της ερώτησης: “Αν συχνά παράγει…”
Αυτή η απάντηση: “Είναι απίθανο…”
Το λογικό σφάλμα:
Αν κάτι είναι συχνό, πιθανό, δεν μπορεί ταυτόχρονα να είναι απίθανο (σπάνιο)!
Σημείωση για τη λέξη “απίθανο”:
Απίθανο σημαίνει: σπάνιο, χαμηλή πιθανότητα
Αυτό θα ήταν το συμπέρασμα αν η δειγματοληπτική κατανομή έδειχνε ότι το δείγμα μας ήταν σπάνιο
Αλλά η ερώτηση λέει το αντίθετο — ότι είναι συχνό
Η μεγάλη εικόνα:
Όπως θα δούμε παρακάτω, χρησιμοποιούμε τη δειγματοληπτική κατανομή για να αξιολογήσουμε αν μια υπόθεση για τη ΔΠΔ είναι εύλογη με βάση τα δεδομένα μας. Αν είναι εύλογη, την κρατάμε ως πιθανή. Αν είναι απίθανη, την απορρίπτουμε και ψάχνουμε για καλύτερες εξηγήσεις.
11.2 Δημιουργία μιας Δειγματοληπτικής Κατανομής
Μια Δεύτερη Ματιά στη Μελέτη για τα Φιλοδωρήματα
Έχουμε παρουσιάσει δύο έννοιες που ίσως σας φαίνονται ακόμα αρκετά αφηρημένες: τη δειγματοληπτική κατανομή και την απόρριψη του κενού μοντέλου. Για να γίνουν πιο συγκεκριμένες, ας επιστρέψουμε στη μελέτη για τα φιλοδωρήματα που είχαμε εξετάσει σε προηγούμενο κεφάλαιο.
Στη μελέτη αυτή, οι ερευνητές εξέτασαν αν η προσθήκη ενός ζωγραφισμένου χαμογελαστού προσώπου στην πίσω πλευρά του λογαριασμού θα έκανε τους πελάτες ενός εστιατορίου να αφήνουν μεγαλύτερα φιλοδωρήματα. Κάθε τραπέζι ανατέθηκε τυχαία σε μία από δύο συνθήκες/ομάδες: να λάβει τον λογαριασμό είτε με χαμογελαστό πρόσωπο είτε χωρίς. Η εξαρτημένη μεταβλητή ήταν το ποσό του φιλοδωρήματος που άφησε κάθε τραπέζι.
Ακολουθεί ένα τυχαίο δείγμα έξι παρατηρήσεων από το σύνολο δεδομένων TipExperiment:
sample(TipExperiment, 6)
TableID Tip Condition
20 20 Control
26 44 Smiley Face
19 21 Control
15 25 Control
25 47 Smiley Face
18 21 Control
Ποιες είναι οι παρατηρήσεις σε αυτή τη μελέτη;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Τα τραπέζια που ανατέθηκαν τυχαία στη συνθήκη με το χαμογελαστό πρόσωπο ή στην ομάδα ελέγχου.
Τι είναι οι «παρατηρήσεις»;
Στη στατιστική, οι παρατηρήσεις είναι οι μονάδες ανάλυσης — τα αντικείμενα ή οι οντότητες για τις οποίες συλλέγουμε δεδομένα. Κάθε παρατήρηση αντιστοιχεί σε μία γραμμή στο σύνολο δεδομένων μας.
Στη μελέτη για τα φιλοδωρήματα:
Κάθε τραπέζι είναι μία παρατήρηση
Για κάθε τραπέζι καταγράφηκε το φιλοδώρημα που άφησε και η συνθήκη στην οποία ανατέθηκε
Τα τραπέζια ανατέθηκαν τυχαία είτε στην ομάδα με το χαμογελαστό πρόσωπο είτε στην ομάδα ελέγχου
Γιατί οι άλλες επιλογές είναι λάθος:
Β (Σερβιτόροι): Οι σερβιτόροι δεν είναι η μονάδα ανάλυσης. Η μελέτη εξετάζει τα φιλοδωρήματα ανά τραπέζι, όχι ανά σερβιτόρο.
Γ (Οι δύο συνθήκες): Οι συνθήκες είναι τα επίπεδα της ανεξάρτητης μεταβλητής, όχι οι παρατηρήσεις. Έχουμε μόνο 2 συνθήκες, αλλά πολλά τραπέζια.
Δ (Εστιατόρια): Η μελέτη πραγματοποιήθηκε σε ένα ή λίγα εστιατόρια. Τα εστιατόρια δεν είναι η μονάδα στην οποία μετράμε τα φιλοδωρήματα.
Πώς αναγνωρίζουμε τις παρατηρήσεις;
Ρωτήστε: «Για ποιον ή για τι συλλέγω δεδομένα; Τι αντιπροσωπεύει κάθε γραμμή στο σύνολο δεδομένων μου;»
Στο TipExperiment, κάθε γραμμή αντιπροσωπεύει ένα τραπέζι με το δικό του TableID, Tip, και Condition.
Αυτή η μελέτη ήταν ένα πείραμα. Τι σημαίνει αυτό;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Οι παρατηρήσεις ανατέθηκαν τυχαία στις συνθήκες.
Τι κάνει μια μελέτη «πείραμα»;
Το βασικό χαρακτηριστικό ενός πειράματος είναι η τυχαία ανάθεση (random assignment). Ο ερευνητής:
Χειρίζεται την ανεξάρτητη μεταβλητή (αποφασίζει ποιες παρατηρήσεις θα λάβουν ποια συνθήκη)
Αναθέτει τυχαία τις παρατηρήσεις στις διάφορες συνθήκες
Γιατί έχει σημασία η τυχαία ανάθεση;
Η τυχαία ανάθεση εξασφαλίζει ότι οι ομάδες είναι συγκρίσιμες πριν την παρέμβαση. Έτσι, αν παρατηρήσουμε διαφορά στα αποτελέσματα, μπορούμε να την αποδώσουμε στην παρέμβαση (το χαμογελαστό πρόσωπο) και όχι σε προϋπάρχουσες διαφορές μεταξύ των ομάδων.
Γιατί οι άλλες επιλογές είναι λάθος:
Α. «Πραγματοποιήθηκε από επαγγελματίες επιστήμονες»
Ο όρος «πείραμα» δεν αναφέρεται στα προσόντα των ερευνητών. Ένα πείραμα ορίζεται από τη μεθοδολογία του, όχι από το ποιος το διεξάγει.
Γ. «Οι παρατηρήσεις με τα υψηλότερα φιλοδωρήματα ανατέθηκαν στη συνθήκη με το χαμογελαστό πρόσωπο»
Αυτό θα ήταν μεροληπτική ανάθεση, όχι τυχαία! Αν οι παρατηρήσεις με υψηλά φιλοδωρήματα τοποθετούνταν σκόπιμα στη μία ομάδα, δεν θα μπορούσαμε να ξέρουμε αν η διαφορά οφείλεται στη ζωγραφιά με το χαμογελαστό πρόσωπο ή στην προϋπάρχουσα τάση για υψηλότερα φιλοδωρήματα.
Δ. «Η ανεξάρτητη μεταβλητή είναι ποιοτική μεταβλητή με δύο ομάδες και μόνο τα πειράματα έχουν τέτοιες μεταβλητές»
Αυτό είναι λάθος. Οι ποιοτικές μεταβλητές υπάρχουν και σε μη πειραματικές μελέτες (μελέτες παρατήρησης ή συσχέτισης).
Πείραμα vs Μελέτη Παρατήρησης
Πείραμα
Μελέτη Παρατήρησης
Ανάθεση
Τυχαία από τον ερευνητή
Φυσική/προϋπάρχουσα
Χειρισμός
Ο ερευνητής ελέγχει τη συνθήκη
Ο ερευνητής απλώς παρατηρεί
Αιτιότητα
Μπορούμε να συμπεράνουμε αιτία-αποτέλεσμα
Μπορούμε να δούμε μόνο συσχέτιση
Παράδειγμα
Μελέτη φιλοδωρημάτων (χαμογελαστό πρόσωπο)
Σύγκριση εισοδήματος ανδρών-γυναικών
Οι ερευνητές θέλουν να διερευνήσουν την υπόθεση ότι τα φιλοδωρήματα εξαρτώνται από τη συνθήκη (ομάδα) — δηλαδή, Φιλοδώρημα = Συνθήκη + άλλοι παράγοντες. Η σημειογραφία του Γενικού Γραμμικού Μοντέλου (GLM) για αυτό το μοντέλο δύο ομάδων είναι:
\[Y_i = b_0 + b_1 X_i + e_i\] όπου:
το \(X_i\) δείχνει αν ένα τραπέζι ήταν στη συνθήκη «Χαμογελαστό Πρόσωπο» ή όχι (κωδικοποιημένο με 0 για την ομάδα ελέγχου και 1 για την ομάδα με το χαμογελαστό πρόσωπο)
το \(b_1\) αντιπροσωπεύει τη διαφορά στο ποσοστό φιλοδωρήματος, κατά μέσο όρο, μεταξύ των δύο συνθηκών
Η τιμή του \(b_1\) είναι αυτή που μας ενδιαφέρει περισσότερο. Αποτελεί την καλύτερη εκτίμησή μας για το \(\beta_1\), δηλαδή την πραγματική επίδραση της προσθήκης του χαμογελαστού προσώπου στη Διαδικασία Παραγωγής Δεδομένων (ΔΠΔ).
Πριν εξετάσουμε τα αποτελέσματα της μελέτης, ας σκεφτούμε τι θα περιμέναμε να δούμε αν γνωρίζαμε ότι ένα συγκεκριμένο μοντέλο της ΔΠΔ ήταν αληθές. Αν όντως υπάρχει όφελος από τη ζωγραφιά του χαμογελαστού προσώπου (δηλαδή αν το \(\beta_1\) είναι θετικός αριθμός), θα περιμέναμε τα δείγματα που προέρχονται από αυτή τη ΔΠΔ να έχουν θετικές τιμές \(b_1\)κατά μέσο όρο.
Αν η πραγματική ΔΠΔ είναι ότι το χαμογελαστό πρόσωπο οδηγεί τους πελάτες στο να αφήνουν μικρότερο φιλοδώρημα, τι θα περιμέναμε να δούμε στα δείγματα από αυτή τη ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Οι τιμές \(b_1\) θα ήταν αρνητικές.
Η βασική αρχή
Οι τιμές \(b_1\) που υπολογίζουμε από δείγματα τείνουν να μοιάζουν με την πραγματική παράμετρο \(\beta_1\) από την οποία προέρχονται:
Αν η πραγματική \(\beta_1\) είναι…
…τότε οι τιμές \(b_1\) τείνουν να είναι…
Θετική (όφελος)
Θετικές κατά μέσο όρο
Αρνητική (απώλεια)
Αρνητικές κατά μέσο όρο
Μηδέν (καμία επίδραση)
Γύρω στο 0 (κάποιες + και κάποιες −)
Γιατί οι άλλες επιλογές είναι λάθος:
Α. «Οι τιμές \(b_1\) θα ήταν θετικές»
Αυτό θα συνέβαινε μόνο αν το χαμογελαστό πρόσωπο αύξανε τα φιλοδωρήματα (δηλαδή αν \(\beta_1 > 0\)). Η ερώτηση όμως λέει το αντίθετο.
Γ. «Οι τιμές \(b_1\) θα ήταν γύρω από το 0»
Αυτό θα συνέβαινε μόνο αν δεν υπήρχε καμία επίδραση (δηλαδή αν \(\beta_1 = 0\), δηλαδή ίσχυε το κενό μοντέλο). Αλλά η ερώτηση υποθέτει ότι υπάρχει αρνητική επίδραση.
Δ. «Δεν θα υπήρχε τρόπος να προβλέψουμε»
Αυτό είναι λάθος. Υπάρχει ξεκάθαρη σχέση μεταξύ \(\beta_1\) και \(b_1\): οι τιμές \(b_1\) κατανέμονται γύρω από την πραγματική τιμή \(\beta_1\). Αυτό είναι θεμελιώδες στη στατιστική — τα στατιστικά μας τείνουν να πλησιάζουν τις πραγματικές παραμέτρους.
Συμπέρασμα
Αν η πραγματική επίδραση είναι αρνητική (\(\beta_1 < 0\)), τότε τα δείγματα θα τείνουν να δίνουν αρνητικές τιμές \(b_1\). Αυτή η αντιστοιχία μεταξύ της πραγματικής παραμέτρου και των δειγματικών εκτιμήσεων είναι η βάση της στατιστικής συμπερασματολογίας.
Αν η πραγματική ΔΠΔ είναι ότι το χαμογελαστό πρόσωπο δεν έχει καμία επίδραση, τι θα περιμέναμε να δούμε στα δείγματα από αυτή τη ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — Οι τιμές \(b_1\) θα ήταν γύρω από το 0 — κάποιες θετικές και κάποιες αρνητικές.
Το κενό μοντέλο: \(\beta_1 = 0\)
Όταν λέμε ότι το χαμογελαστό πρόσωπο δεν έχει καμία επίδραση, εννοούμε ότι στην πραγματική ΔΠΔ:
\[\beta_1 = 0\]
Αυτό σημαίνει ότι ο (πληθυσμιακός) μέσος όρος φιλοδωρημάτων είναι ακριβώς ο ίδιος και στις δύο ομάδες:
\[\mu_{\text{χαμογ}} = \mu_{\text{ελέγχου}}\]
Τι συμβαίνει όμως στα δείγματα;
Ακόμα κι αν \(\beta_1 = 0\) στη ΔΠΔ, οι τιμές \(b_1\) που υπολογίζουμε από δείγματα δεν θα είναι ακριβώς μηδέν.
Γιατί;
Λόγω της τυχαίας δειγματοληπτικής μεταβλητότητας:
Κάθε δείγμα είναι διαφορετικό
Ακόμα κι αν δεν υπάρχει πραγματική διαφορά, τυχαίνει μερικές φορές να πέσουν περισσότερα υψηλά φιλοδωρήματα στη μία ομάδα
Έτσι, κάποια \(b_1\) θα είναι λίγο θετικά, κάποια λίγο αρνητικά
Το κλειδί: Οι τιμές \(b_1\) θα κυμαίνονται γύρω από το 0, χωρίς συστηματική τάση προς τη μία ή την άλλη κατεύθυνση.
Αν και δεν μπορούμε να προβλέψουμε την ακριβή τιμή του \(b_1\) που θα προκύψει από ένα συγκεκριμένο δείγμα, μπορούμε να κάνουμε προβλέψεις για το μέσο όρο των \(b_1\) που θα προέκυπταν από πολλά τυχαία δείγματα.
Κατά μέσο όρο, οι τιμές \(b_1\) τείνουν να μοιάζουν με την «γονική» τιμή \(\beta_1\) από την οποία προέρχονται:
Αρνητική τιμή \(\beta_1\) → τείνει να παράγει αρνητικές τιμές \(b_1\)
Θετική τιμή \(\beta_1\) → τείνει να παράγει θετικές τιμές \(b_1\)
Το κενό μοντέλο είναι μια ειδική περίπτωση στην οποία \(\beta_1 = 0\). Αν το κενό μοντέλο είναι αληθές, σημαίνει ότι η ζωγραφιά του χαμογελαστού προσώπου δεν έχει καμία επίδραση στο πόσο του φιλοδωρήματος που αφήνουν τα τραπέζια. Οι τιμές \(b_1\) που θα παράγονταν από πολλά τυχαία δείγματα μιας ΔΠΔ όπου \(\beta_1 = 0\) θα τείνουν να είναι κοντά στο μηδέν, αλλά δεν θα είναι απαραίτητα ακριβώς μηδέν. Μπορούμε να δημιουργήσουμε μια δειγματοληπτική κατανομή για να διαπιστώσουμε αν το δειγματικό μας \(b_1\) θα μπορούσε να έχει παραχθεί από το κενό μοντέλο.
Δημιουργία Δειγματοληπτικής Κατανομής με Βάση το Κενό Μοντέλο
Ας κάνουμε τώρα μια υποθετική σκέψη. Αν δεν υπήρχε καμία επίδραση του χαμογελαστού προσώπου στο ποσοστό του φιλοδωρήματος, τότε τα τραπέζια θα είχαν αφήσει το ίδιο ποσοστό φιλοδωρήματος ανεξάρτητα από τη συνθήκη στην οποία είχαν ανατεθεί τυχαία.
Ένα από τα μεγάλα πλεονεκτήματα στις μέρες μας είναι ότι δεν περιοριζόμαστε στο να φανταζόμαστε απλώς πώς θα έμοιαζαν οι τιμές \(b_1\) αν δεν υπήρχε καμία επίδραση του χαμογελαστού προσώπου στη ΔΠΔ. Μπορούμε να χρησιμοποιήσουμε τον υπολογιστή μας (εδώ την R) για να προσομοιώσουμε τη ΔΠΔ στην οποία ισχύει ότι \(\beta_1 = 0\).
ΣυμβουλήΥπενθύμιση
Οι όροι «κενό μοντέλο», «\(\beta_1 = 0\)» και «καμία επίδραση» σημαίνουν όλοι το ίδιο πράγμα: κανένα μέρος της μεταβλητότητας στο ποσοστό φιλοδωρήματος των τραπεζιών δεν οφείλεται στο χαμογελαστό πρόσωπο.
Μπορούμε να χρησιμοποιήσουμε τη συνάρτηση shuffle() για να προσομοιώσουμε αυτή την υποθετική κατάσταση. Η συνάρτηση αυτή ανακατανέμει ή ανακατεύει τυχαία κάθε φιλοδώρημα (που αντιπροσωπεύει κάθε τραπέζι) είτε στη συνθήκη «χαμογελαστό πρόσωπο» είτε στην ομάδα ελέγχου.
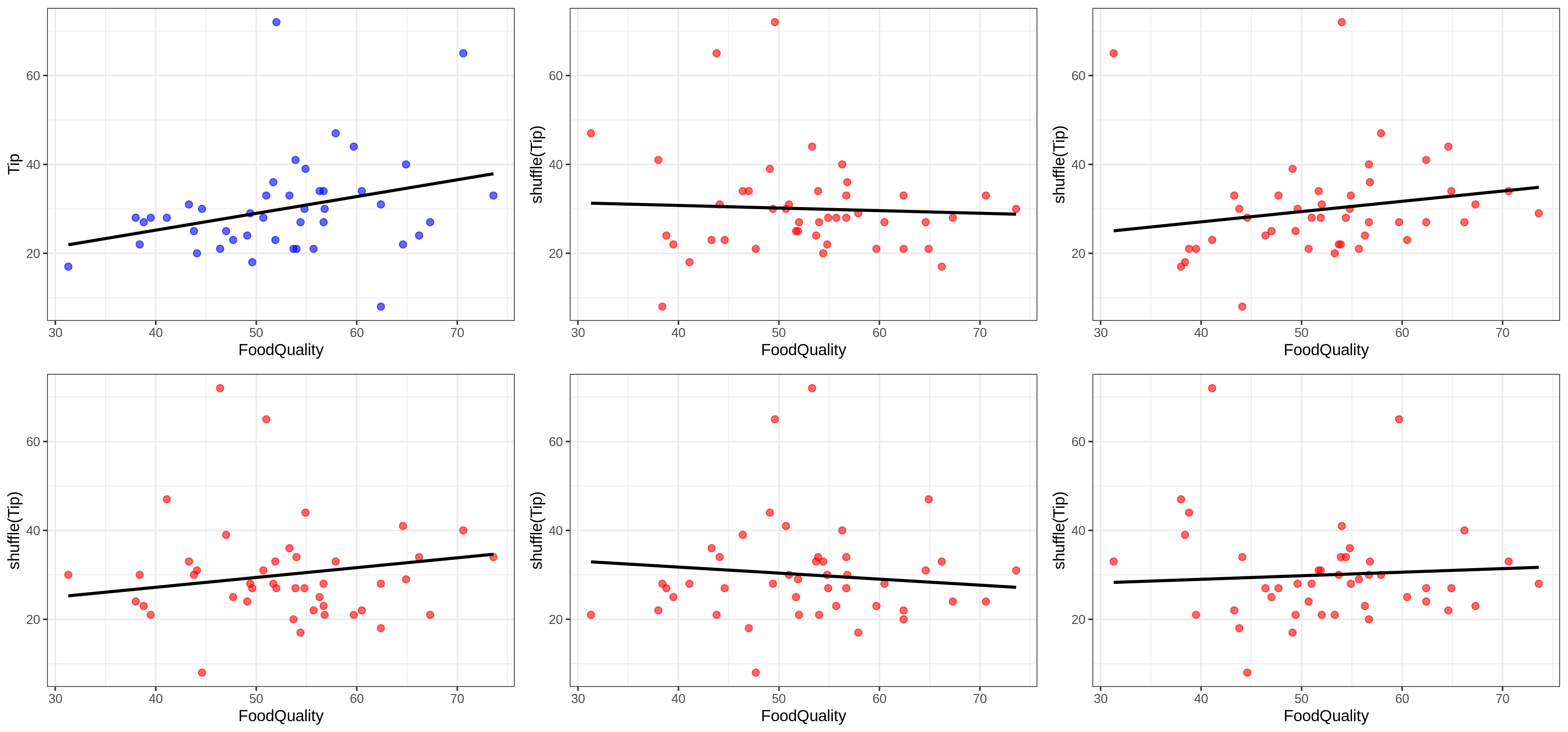
Το παρακάτω διάγραμμα δείχνει τα πραγματικά δεδομένα του δείγματος (το διάγραμμα με πράσινο χρώμα επάνω αριστερά) μαζί με 8 διαφορετικές τυχαίες ανακατανομές των φιλοδωρημάτων στις δύο συνθήκες. Για κάθε ανακατανομή, έχουμε σχεδιάσει το μέσο όρο φιλοδωρήματος (οι μαύρες γραμμές) για κάθε συνθήκη.
Κάθε ένα από αυτά τα διαγράμαμτα αναπαριστά μία τυχαία ανακατανομή των δεδομένων και το μοντέλο που προσαρμόζεται καλύτερα στα ανακατανεμημένα δεδομένα. Ας θυμηθούμε, πώς αναπαρίστανται οι τιμές \(b_1\) σε κάθε διάγραμμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — Η κατακόρυφη απόσταση μεταξύ των δύο μαύρων γραμμών.
Τι αναπαριστά το \(b_1\);
Στο μοντέλο δύο ομάδων:
\[Y_i = b_0 + b_1 X_i + e_i\]
όπου \(X_i = 0\) για την ομάδα ελέγχου και \(X_i = 1\) για την ομάδα με το χαμόγελαστό πρόσωπο:
\(b_0\) = ο μέσος όρος της ομάδας ελέγχου (όταν \(X = 0\))
\(b_0 + b_1\) = ο μέσος όρος της ομάδας με το χαμογελαστό πρόσωπο (όταν \(X = 1\))
Το \(b_1\) είναι η κατακόρυφη απόσταση μεταξύ των δύο οριζόντιων γραμμών.
Γιατί οι άλλες επιλογές είναι λάθος:
Α. «Η μαύρη γραμμή της ομάδας ελέγχου»
Αυτή η γραμμή αναπαριστά το μέσο όρο της ομάδας ελέγχου, δηλαδή το \(b_0\) (ή \(\bar{Y}_{\text{ελέγχου}}\)), όχι το \(b_1\).
Β. «Η μαύρη γραμμή της ομάδας με το χαμογελαστό πρόσωπο»
Αυτή η γραμμή αναπαριστά το μέσο όρο της ομάδας με το χαμογελαστό πρόσωπο, δηλαδή το \(b_0 + b_1\) (ή \(\bar{Y}_{\text{χαμόγ}}\)), όχι μόνο το \(b_1\).
Σημασία για την κατανόηση της δειγματοληπτικής κατανομής
Όταν κοιτάζουμε τα 9 διαγράμματα:
Κάθε διάγραμμα έχει δύο μαύρες γραμμές (μέσους όρους)
Η απόσταση μεταξύ τους διαφέρει από διάγραμμα σε διάγραμμα
Αυτές οι διαφορετικές αποστάσεις είναι οι διαφορετικές τιμές \(b_1\)
Όπως θα δούμε παρακάτω, αν συλλέξουμε όλες αυτές τις αποστάσεις (π.χ. από 1000 τυχαία ανακατέματα), παίρνουμε τη δειγματοληπτική κατανομή του \(b_1\)
Επειδή αυτά τα δεδομένα και οι τιμές \(b_1\) δημιουργήθηκαν από το κενό μοντέλο:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Οι τιμές \(b_1\) τείνουν να είναι κοντά στο 0.
Τι σημαίνει «κενό μοντέλο»;
Το κενό μοντέλο υποθέτει ότι:
\[\beta_1 = 0\]
Δηλαδή, δεν υπάρχει καμία επίδραση του χαμογελαστού προσώπου στα φιλοδωρήματα. Οι δύο ομάδες έχουν τον ίδιο πραγματικό μέσο όρο στη ΔΠΔ.
Η βασική αρχή
Οι τιμές \(b_1\) από δείγματα τείνουν να συγκεντρώνονται γύρω από την πραγματική παράμετρο \(\beta_1\).
Τι κάνει η συνάρτηση shuffle();
Η shuffle()ανακατανέμει τυχαία τα φιλοδωρήματα στις συνθήκες, σπάζοντας οποιαδήποτε σχέση μεταξύ τους. Αυτό προσομοιώνει ακριβώς έναν κόσμο όπου:
Η συνθήκη δεν επηρεάζει το φιλοδώρημα
\(\beta_1 = 0\)
Οποιαδήποτε διαφορά μεταξύ των ομάδων είναι καθαρά τυχαία
Γιατί οι άλλες επιλογές είναι λάθος:
Οι τιμές 20, 30 και 40 δεν έχουν καμία σχέση με το \(b_1\) στο κενό μοντέλο.
Αυτές οι τιμές μοιάζουν με τιμές φιλοδωρημάτων (η μεταβλητή \(Y\))
Το \(b_1\) όμως είναι η διαφορά μεταξύ μέσων όρων, όχι ένας μέσος όρος
Στο κενό μοντέλο, η αναμενόμενη διαφορά είναι 0, όχι 20, 30 ή 40
Ο παρακάτω κώδικας υπολογίζει τη τιμή \(b_1\) από ένα μόνο τυχαίο ανακάτεμα των δεδομένων. Μπορείτε να τον εκτελέσετε μερικές φορές για να δείτε ότι κάθε ανακάτεμα δίνει διαφορετική τιμή \(b_1\). Έπειτα τροποποιήστε τον κώδικα προσθέτοντας τη συνάρτηση do() για να προσομοιώσετε 1000 τιμές \(b_1\), μία για κάθε ανακάτεμα των δεδομένων.
Αυτές είναι πάρα πολλές τιμές! Ωστόσο, μπορούμε να παρατηρήσουμε κάποια πράγματα ακόμα κι αν απλώς κοιτάξουμε τις πρώτες από αυτές:
Οι τιμές \(b_1\)ποικίλλουν κάθε φορά που ανακατεύουμε και υπολογίζουμε μια νέα τιμή \(b_1\)
Κάποιες τιμές \(b_1\) είναι θετικές και κάποιες αρνητικές
Αν και δεν μπορούσαμε να προβλέψουμε αν η πρώτη τιμή \(b_1\) θα ήταν θετική ή αρνητική, γνωρίζαμε ήδη ότι μερικές θα ήταν θετικές και μερικές αρνητικές
Παρόλο που οι 1000 τιμές που παρήγαγε η R μοιάζουν με την κατανομή μιας μεταβλητής για ένα δείγμα παρατηρήσεων, διαφέρουν από αυτήν σε δύο σημαντικά σημεία:
Δε βασίζονται στη μέτρηση μιας ακόμη μεταβλητής, αλλά σε μια διαδικασία τυχαίας παραγωγής — οι τιμές δημιουργούνται τυχαία από την R
Κάθε τιμή αντιπροσωπεύει ένα στατιστικό ή εκτίμηση παραμέτρου, όχι μια μεμονωμένη παρατήρηση — κάθε τιμή είναι μια υποθετική τιμή \(b_1\)
ΣημαντικόΟρισμός: Δειγματοληπτική Κατανομή
Οι κατανομές που έχουν αυτά τα χαρακτηριστικά ονομάζονται δειγματοληπτικές κατανομές (sampling distributions).
Μια δειγματοληπτική κατανομή είναι η κατανομή των εκτιμήσεων μιας παραμέτρου (ή ενός στατιστικού) που υπολογίζεται από τυχαία παραγόμενα δείγματα ίδιου μεγέθους.
Οι δειγματοληπτικές κατανομές δεν είναι τα δεδομένα που συλλέξαμε, αλλά μπορούν να κατασκευαστούν χρησιμοποιώντας τα δεδομένα μας. Ενώ έχουμε συλλέξει μόνο ένα δείγμα παρατηρήσεων για μια δεδομένη μελέτη, οι δειγματοληπτικές κατανομές είναι προσομοιώσεις του τι θα μπορούσε να συμβεί αν είχαμε κάνει την ίδια μελέτη πολλές φορές.
Οι δειγματοληπτικές κατανομές μας επιτρέπουν να δούμε πώς θα μπορούσε να μοιάζει η δειγματική μεταβλητότητα αν επαναλαμβάναμε την ίδια διαδικασία συλλογής δεδομένων (επιλογή ενός τυχαίου δείγματος ή τυχαία ανάθεση σε συνθήκες) πολλές φορές.
11.3 Διερεύνηση της Δειγματοληπτικής Κατανομής του \(b_1\)
Είναι δύσκολο να μελετήσουμε μια μεγάλη λίστα τιμών \(b_1\) και να καταλήξουμε σε κάποιο συμπέρασμα. Αν όμως σκεφτούμε αυτούς τους αριθμούς ως μια κατανομή — μια δειγματοληπτική κατανομή — μπορούμε να χρησιμοποιήσουμε τα ίδια εργαλεία οπτικοποίησης και ανάλυσης που χρησιμοποιούμε για να κατανοήσουμε μια οποιαδήποτε κατανομή. Για παράδειγμα, μπορούμε να χρησιμοποιήσουμε ένα ιστόγραμμα για να εξετάσουμε τη δειγματοληπτική κατανομή των τιμών \(b_1\).
Ο παρακάτω κώδικας αποθηκεύει τις τιμές \(b_1\) (εκτιμήσεις της παραμέτρου \(\\beta_1\)) από 1000 τυχαία ανακατέματα των δεδομένων της μελέτης του φιλοδωρήματος σε ένα πλαίσιο δεδομένων με το όνομα sdob1, που είναι ακρωνύμιο του sampling distribution of b1s (δειγματοληπτική κατανομή των τιμών \(b_1\)).
Ποιο είναι το όνομα αυτού του πλαισίου δεδομένων;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — sdob1
Ανάλυση του κώδικα
sdob1 <-do(1000) *b1(shuffle(Tip) ~ Condition, data = TipExperiment)
Σε αυτή τη γραμμή κώδικα:
Ο τελεστής <- είναι ο τελεστής ανάθεσης στην R
Ό,τι βρίσκεται στα αριστερά του <- είναι το όνομα που δίνουμε στο αντικείμενο
Ό,τι βρίσκεται στα δεξιά του <- είναι η τιμή που αποθηκεύεται
Επομένως, το sdob1 είναι το όνομα του πλαισίου δεδομένων που δημιουργούμε.
Τι σημαίνει το sdob1;
Το όνομα sdob1 είναι ένα ακρωνύμιο που επιλέξαμε για να θυμόμαστε τι περιέχει:
sampling distribution of b1s
= δειγματοληπτική κατανομή των \(b_1\)
Θα μπορούσατε να επιλέξετε οποιοδήποτε άλλο όνομα προτιμάτε (π.χ., my_distribution, shuffled_b1s, κλπ.).
Γιατί οι άλλες επιλογές είναι λάθος:
Επιλογή
Τι είναι στην πραγματικότητα
Tip
Μια μεταβλητή (στήλη) μέσα στο TipExperiment — το ποσό του φιλοδωρήματος
Condition
Μια μεταβλητή (στήλη) μέσα στο TipExperiment — η συνθήκη (Control ή Smiley Face)
b1
Μια μεταβλητή (στήλη) μέσα στο sdob1 — οι τιμές \(b_1\) από κάθε ανακατανομή
TipExperiment
Το αρχικό πλαίσιο δεδομένων με τα πραγματικά δεδομένα της μελέτης
Ποιο είναι το όνομα της (μοναδικής) μεταβλητής μέσα σε αυτό το πλαίσιο δεδομένων;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — b1
Τι περιέχει το sdob1;
Όταν εκτελούμε:
sdob1 <-do(1000) *b1(shuffle(Tip) ~ Condition, data = TipExperiment)head(sdob1)
Για να αναφερθούμε στη μεταβλητή b1 μέσα στο sdob1, χρησιμοποιούμε:
sdob1$b1
Γιατί οι άλλες επιλογές είναι λάθος:
Επιλογή
Τι είναι στην πραγματικότητα
Tip
Μεταβλητή μέσα στο TipExperiment, όχι στο sdob1
Condition
Μεταβλητή μέσα στο TipExperiment, όχι στο sdob1
sdob1
Το όνομα του πλαισίου δεδομένων, όχι της μεταβλητής
TipExperiment
Ένα άλλο πλαίσιο δεδομένων (τα αρχικά δεδομένα)
Αυτή είναι μια εντολή για να δημιουργήσουμε ένα ιστόγραμμα: gf_histogram(~ Thumb, data = Fingers)
Ποια είναι η γενική σύνταξη αυτής της εντολής;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — gf_histogram(~ μεταβλητή, data = πλαίσιο δεδομένων)
Ανάλυση του κώδικα
gf_histogram(~ Thumb, data = Fingers)
Στοιχείο
Ρόλος
Παράδειγμα
gf_histogram()
Η συνάρτηση που δημιουργεί το ιστόγραμμα
—
~ Thumb
Η μεταβλητή που θέλουμε να αναπαραστήσουμε
Thumb
data = Fingers
Το πλαίσιο δεδομένων που περιέχει τη μεταβλητή
Fingers
Η γενική σύνταξη
gf_histogram(~ μεταβλητή, data = πλαίσιο δεδομένων)
Μετά το ~ βάζουμε το όνομα της μεταβλητής (στήλης) που θέλουμε να αναπαραστήσουμε
Μετά το data = βάζουμε το όνομα του πλαισίου δεδομένων που περιέχει αυτή τη μεταβλητή
Γιατί η επιλογή Α είναι λάθος;
Η επιλογή Α (gf_histogram(~ πλαίσιο δεδομένων, data = μεταβλητή)) έχει τη σειρά ανάποδα:
Βάζει το πλαίσιο δεδομένων μετά το ~ (λάθος)
Βάζει τη μεταβλητή μετά το data = (λάθος)
Αν προσπαθήσετε να εκτελέσετε κώδικα με αυτή τη σειρά, η R θα δώσει σφάλμα.
Μνημονικός κανόνας
«Τι θέλω να δω; Από πού;»
~ μεταβλητή → Τι θέλω να αναπαραστήσω
data = πλαίσιο δεδομένων → Από πού να πάρω τα δεδομένα
Στο παραπάνω ιστόγραμμα, σε τι αναφέρεται η συχνότητα (count) στον άξονα y (π.χ., 50);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Στον αριθμό των ανακατανεμημένων δειγμάτων.
Τι αναπαριστά αυτό το ιστόγραμμα;
Αυτό το ιστόγραμμα δείχνει τη δειγματοληπτική κατανομή των \(b_1\) — δηλαδή, τις 1000 τιμές \(b_1\) που προέκυψαν από 1000 ανακατανομές (shuffles) των δεδομένων.
Άξονας x (b1): Οι τιμές \(b_1\) (διαφορές μέσων όρων)
Άξονας y (count): Πόσες από τις 1000 ανακατανομές έδωσαν τιμή \(b_1\) σε κάθε διάστημα
Γιατί η επιλογή Α είναι λάθος;
Τα τραπέζια είναι οι παρατηρήσεις στα αρχικά δεδομένα (TipExperiment), όχι στη δειγματοληπτική κατανομή.
Αν προσθέτατε τα ύψη όλων των ράβδων, ποιο θα ήταν το άθροισμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — 1000.
Τι αναπαριστά αυτό το ιστόγραμμα;
Αυτό το ιστόγραμμα δείχνει τη δειγματοληπτική κατανομή των \(b_1\) — δηλαδή, τις 1000 τιμές \(b_1\) που προέκυψαν από 1000 ανακατανομές (shuffles) των δεδομένων.
Άξονας x (b1): Οι τιμές \(b_1\) (διαφορές μέσων όρων)
Άξονας y (count): Πόσες από τις 1000 ανακατανομές έδωσαν τιμή \(b_1\) σε κάθε διάστημα
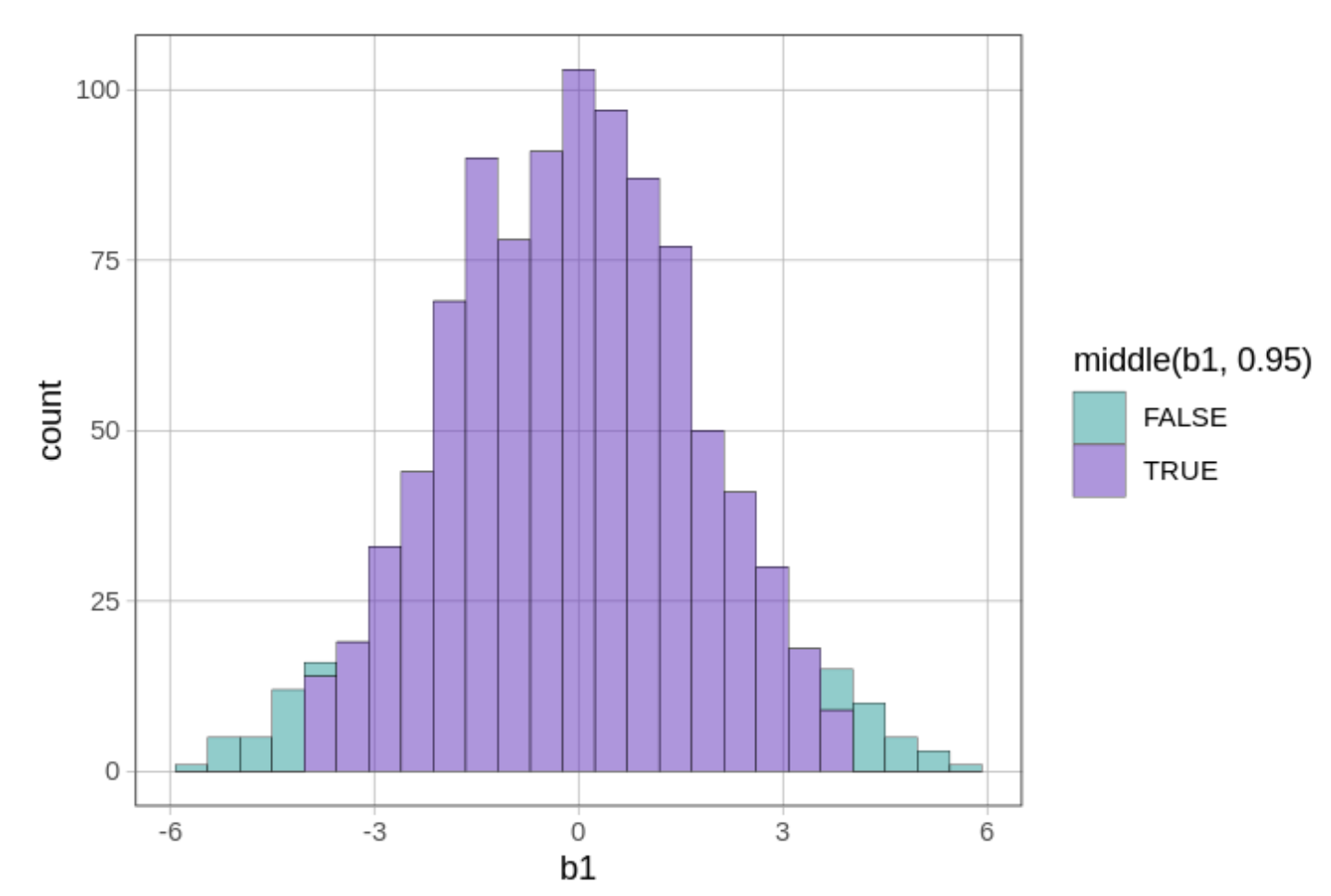
Αν και το παραπάνω ιστόγραμμα μοιάζει με άλλα που έχετε δει, δεν είναι το ίδιο! Αυτό το ιστόγραμμα αναπαριστά τη δειγματοληπτική κατανομή των τιμών \(b_1\) από 1000 τυχαία ανακατέματα των δεδομένων.
Υπάρχουν μερικά πράγματα που μπορούμε να παρατηρήσουμε:
Σχήμα: Κάπως κανονικό (συγκεντρωμένο στη μέση και συμμετρικό)
Κέντρο: Φαίνεται να είναι γύρω στο 0
Εύρος: Οι περισσότερες τιμές βρίσκονται μεταξύ -10 και 10
Επειδή η δειγματοληπτική κατανομή βασίζεται στο κενό μοντέλο, για το οποίο ισχύει ότι \(\beta_1 = 0\), περιμένουμε ότι οι εκτιμήσεις των τιμών της παραμέτρου θα συγκεντρώνονται γύρω από το 0. Αλλά περιμένουμε επίσης να ποικίλλουν λόγω της δειγματοληπτικής μεταβλητότητας. Ακόμα κι αν παρατηρούσαμε μια τιμή \(b_1\) τόσο υψηλή όσο τα $10, θα μπορούσε να είναι απλώς το αποτέλεσμα τυχαίας δειγματοληπτικής μεταβλητότητας.
Από το ιστόγραμμα μπορούμε να δούμε ότι ενώ δεν είναι αδύνατο να παραχθεί μια τιμή \(b_1\) ίση με 9 ή 10, τέτοιες τιμές είναι πολύ λιγότερο συχνές από τιμές όπως -1 ή 1. Σε αυτή την περίπτωση, το \(b_1\) αναπαριστά τη διαφορά των μέσων όρων μεταξύ των δύο συνθηκών/ομάδων. Επομένως, ένας άλλος τρόπος να το διατυπώσουμε αυτό είναι:
Είναι εύκολο να παραχθούν τυχαία μικρές διαφορές μέσων όρων (π.χ., -1 ή 1), αλλά δύσκολο να παραχθούν τυχαία μεγάλες διαφορές (π.χ., -10 ή 10).
Κοιτάζοντας απλά το ιστόγραμμα μπορούμε να πάρουμε μια ιδέα της πιθανότητας να λάβουμε μια συγκεκριμένη τιμή \(b_1\) από αυτή τη ΔΠΔ για την οποία γνωρίζουμε ότι \(\beta_1 = 0\). Όταν χρησιμοποιούμε αυτές τις συχνότητες για να εκτιμήσουμε μια πιθανότητα, χρησιμοποιούμε αυτή την κατανομή των τυχαίων \(b_1\) ως μια κατανομή πιθανότητας.
Χρήση της Δειγματοληπτικής Κατανομής για την Αξιολόγηση του Κενού Μοντέλου
Χρησιμοποιήσαμε την R για να προσομοιώσουμε έναν κόσμο όπου το κενό μοντέλο είναι αληθές, ώστε να κατασκευάσουμε μια δειγματοληπτική κατανομή. Τώρα ας επιστρέψουμε στον αρχικό μας στόχο: να δούμε πώς αυτή η δειγματοληπτική κατανομή μπορεί να χρησιμοποιηθεί για να αξιολογήσουμε αν το κενό μοντέλο θα μπορούσε να εξηγήσει τα δεδομένα που συλλέξαμε, ή αν πρέπει να απορριφθεί.
Η βασική ιδέα είναι η εξής: Χρησιμοποιώντας τη δειγματοληπτική κατανομή των δειγματικών τιμών \(b_1\) που θα μπορούσαν πιθανόν να προκύψουν από μια ΔΠΔ στην οποία το κενό μοντέλο είναι αληθές (δηλαδή στην οποία \(\beta_1 = 0\)), μπορούμε να εξετάσουμε την τιμή \(b_1\) του δείγματός μας και να εκτιμήσουμε πόσο πιθανή θα ήταν μια τέτοια τιμή αν το κενό μοντέλο ήταν, πράγματι, αληθές.
Αν κρίνουμε ότι η τιμή \(b_1\) που παρατηρήσαμε στο δείγμα μας είναι απίθανο να έχει προέλθει από το κενό μοντέλο τότε απορρίπτουμε το κενό μοντέλο ως μοντέλο της ΔΠΔ
Αν κρίνουμε ότι η τιμή \(b_1\) που παρατηρήσαμε στο δείγμα μας είναι πιθανό να έχει προέλθει από το κενό μοντέλο τότε αποδεχόμαστε το κενό μοντέλο, τουλάχιστον μέχρι να έχουμε περισσότερες ενδείξεις που να υποδεικνύουν το αντίθετο
Στη μελέτη του φιλοδωρήματος, η τιμή \(b_1\) αναπαριστά τη μέση διαφορά στα φιλοδωρήματα μεταξύ των τραπεζιών που έλαβαν το ζωγραφισμένο χαμογελαστό πρόσωπο και αυτών που δεν το έλαβαν.
Στατιστικά που βρίσκονται στα άκρα (στις ουρές) της δειγματοληπτικής κατανομής (βλ. παραπάνω ιστόγραμμα) είτε προς τη θετική κατεύθυνση (π.χ., τα φιλοδωρήματα είναι κατά μέσο όρο 8 δολάρια μεγαλύτερα στην ομάδα με το χαμογελαστό πρόσωπο) είτε προς την αρνητική (π.χ., -8 δολάρια, που αντιπροσωπεύει πολύ μικρότερα φιλοδωρήματα στην ομάδα με το χαμογελαστό πρόσωπο), είναι απίθανο να έχουν προέλθει από μια ΔΠΔ όπου \(\beta_1\) = 0. Και τα δύο αυτά είδη απίθανων δειγμάτων θα μας έκαναν να αμφισβητήσουμε ότι το κενό μοντέλο παρήγαγε τα δεδομένα μας.
Με άλλα λόγια: αν είχαμε ένα στατιστικό που πέφτει είτε στο άνω άκρο είτε στο κάτω άκρο της δειγματοληπτικής κατανομής, θα μπορούσαμε να απορρίψουμε το κενό μοντέλο ως το πραγματικό μοντέλο της ΔΠΔ.
Στη στατιστική, αυτό αναφέρεται συνήθως ως έλεγχος διπλής κατεύθυνσης (two-tailed test), επειδή αν το πραγματικό μας στατιστικό βρίσκεται είτε στο άνω είτε στο κάτω άκρο αυτής της δειγματοληπτικής κατανομής, θα έχουμε λόγο να απορρίψουμε το κενό μοντέλο. Απορρίπτοντας το μοντέλο στο οποίο \(\beta_1 = 0\), αποφασίζουμε ότι κάποια εκδοχή του σύνθετου μοντέλου, όπου \(\beta_1 \neq 0\), πρέπει να είναι αληθής. Δεν θα γνωρίζουμε ακριβώς ποια είναι η πραγματική τιμή του \(\beta_1\). Θα γνωρίζουμε μόνο ότι πιθανότατα αυτή η τιμή δεν είναι 0. Με πιο παραδοσιακούς στατιστικούς όρους, θα έχουμε βρει μια στατιστικά σημαντική διαφορά μεταξύ των μέσων όρων της ομάδας του χαμογελαστού προσώπου και της ομάδας ελέγχου.
Φυσικά, ακόμα κι αν παρατηρήσουμε μια δειγματική τιμή \(b_1\) σε κάποια από τις ουρές της δειγματοληπτικής κατανομής και αποφασίσουμε να απορρίψουμε το κενό μοντέλο, θα μπορούσαμε να κάνουμε λάθος. Απλώς λόγω τυχαιότητας, κάποιες από τις δειγματικές τιμές \(b_1\) θα τύχει να βρίσκονται στις ουρές της δειγματοληπτικής κατανομής ακόμα κι αν το κενό μοντέλο είναι πράγματι αληθές. Το να εξαπατηθούμε με αυτόν τον τρόπο — δηλαδή να οδηγηθούμε στο να απορρίψουμε το κενό μοντέλο ενώ στην πραγματικότητα είναι αληθές — ονομάζεται Σφάλμα Τύπου Ι.
11.4 Τι Θεωρείται Απίθανο;
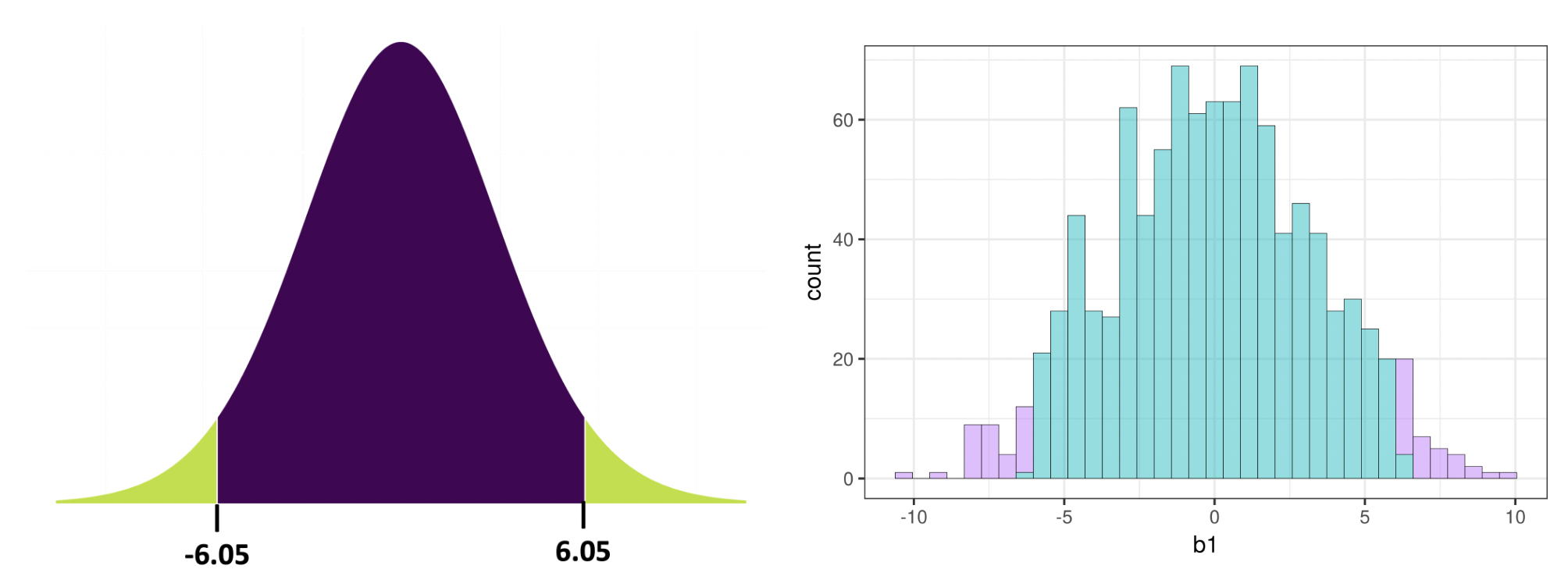
Όλα αυτά, ωστόσο, εγείρουν το ερώτημα πόσο ακραία θα πρέπει να είναι η δειγματική τιμή \(b_1\) ώστε να απορρίψουμε το κενό μοντέλο. Αυτό που θεωρείται απίθανο για ένα άτομο μπορεί να μη φαίνεται εξίσου απίθανο σε κάποιο άλλο. Θα ήταν χρήσιμο να υπάρχει ένα κοινά αποδεκτό κριτήριο για το τι συνιστά «απίθανο» πριν εξετάσουμε το πραγματικό δειγματικό μας στατιστικό. Ο ορισμός του «απίθανου» εξαρτάται τόσο από τον σκοπό του στατιστικού μοντέλου όσο και από τις συμβάσεις που υιοθετεί η εκάστοτε επιστημονική κοινότητα.
Στις κοινωνικές επιστήμες, ένα σύνηθες κριτήριο είναι το εξής: ένα στατιστικό του δείγματος θεωρείται απίθανο όταν η πιθανότητα να προκύψει μια τόσο ακραία τιμή (είτε προς την αρνητική είτε προς τη θετική κατεύθυνση) από μια συγκεκριμένη ΔΠΔ είναι μικρότερη από 0.05 (5%). Τον αριθμητικό αυτόν ορισμό του «απίθανου» τον συμβολίζουμε με το ελληνικό γράμμα \(\alpha\). Έτσι, όταν οι επιστήμονες αναφέρουν ότι «όρισαν το \(\alpha\) = 0.05», εννοούν ακριβώς αυτό το κριτήριο. Αν επιθυμούν έναν αυστηρότερο ορισμό του απίθανου, μπορούν να θέσουν το \(\alpha = 0.001\), υποδηλώνοντας ότι η τιμή του στατιστικού θα πρέπει να είναι εξαιρετικά απίθανη προκειμένου να απορριφθεί το κενό μοντέλο της ΔΠΔ.
Για τη δειγματοληπτική κατανομή των \(b_1\) που δημιουργήσαμε από τυχαία ανακατέματα των δεδομένων της μελέτης για τα φιλοδωρήματα ας θέσουμε το επίπεδο σημαντικότητας \(\alpha\) = 0.05. Αν πάρουμε τις 1000 τιμές \(b_1\) και τις βάλουμε στη σειρά, το κατώτερο 2.5% και το ανώτερο 2.5% των τιμών αντιστοιχούν στο πιο ακραίο 5% της δειγματοληπτικής κατανομής και, συνεπώς, στις λιγότερο πιθανές τιμές να έχουν παραχθεί λόγω τυχαιότητας.
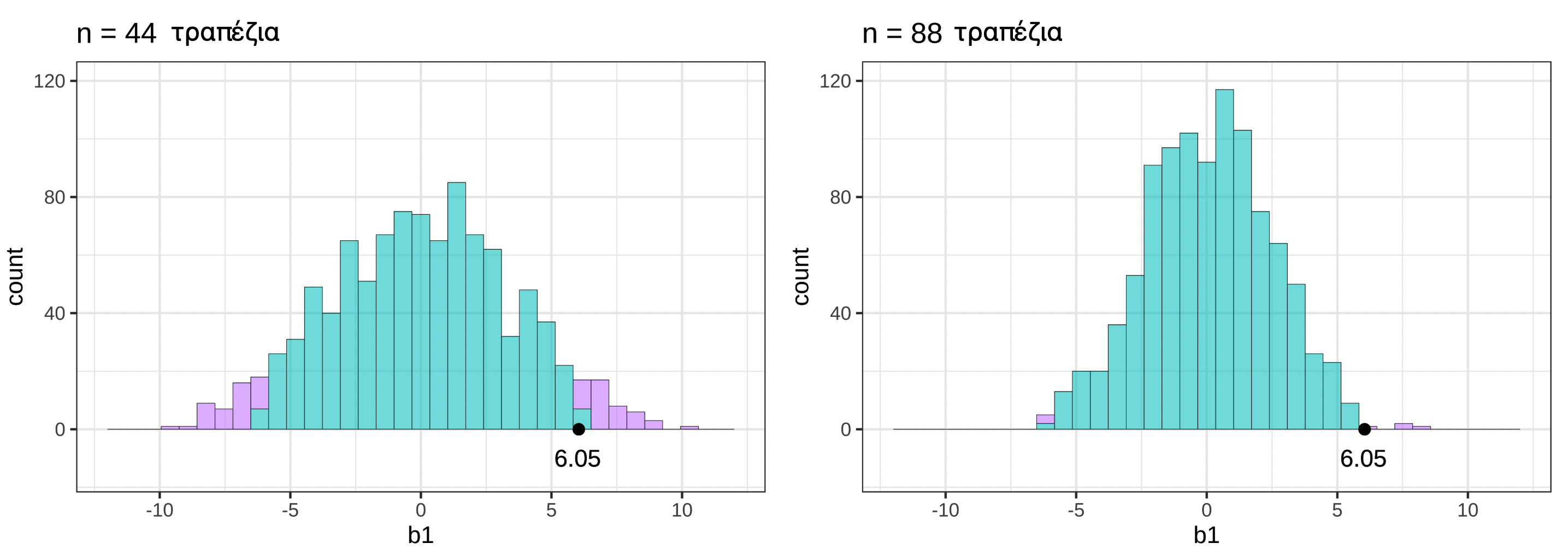
Ποιο από τα παρακάτω ιστογράμματα αναπαριστά το 5% (0.05) των πιο απίθανων τιμών \(b_1\) στη δειγματοληπτική κατανομή που κατασκευάστηκε από 1000 τυχαία ανακατέματα των δεδομένων του πειράματος του φιλοδωρήματος;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β
Τι ψάχνουμε;
Το 5% (0.05) των πιο απίθανων τιμών \(b_1\) είναι οι τιμές που βρίσκονται στα δύο άκρα (ουρές) της κατανομής:
2.5% στην αριστερή ουρά (πολύ αρνητικές τιμές)
2.5% στη δεξιά ουρά (πολύ θετικές τιμές)
Αυτές οι ακραίες τιμές είναι απίθανο να παραχθούν τυχαία αν το κενό μοντέλο είναι αληθές.
Ανάλυση των επιλογών:
Α. ΛΑΘΟΣ — Δείχνει μόνο τη δεξιά ουρά χρωματισμένη κόκκινη. Αυτό θα ήταν σωστό για έλεγχο μονής κατεύθυνσης (one-tailed test), αλλά εμείς χρησιμοποιούμε έλεγχο διπλής κατεύθυνσης.
Β. ΣΩΣΤΟ ✓ — Δείχνει και τις δύο ουρές χρωματισμένες κόκκινες (2.5% αριστερά + 2.5% δεξιά = 5% συνολικά). Αυτό είναι το σωστό για έλεγχο διπλής κατεύθυνσης.
Γ. ΛΑΘΟΣ — Δείχνει περίπου το 50% της κατανομής χρωματισμένο κόκκινο, όχι το 5%. Η κόκκινη περιοχή είναι πολύ μεγάλη.
Γιατί έχει σημασία;
Σε έναν έλεγχο διπλής κατεύθυνσης (two-tailed test):
Απορρίπτουμε το κενό μοντέλο αν η τιμή \(b_1\) είναι πολύ θετική ή πολύ αρνητική
Και οι δύο κατευθύνσεις είναι ενδιαφέρουσες
Επομένως, χρειαζόμαστε κόκκινο χρώμα και στις δύο ουρές
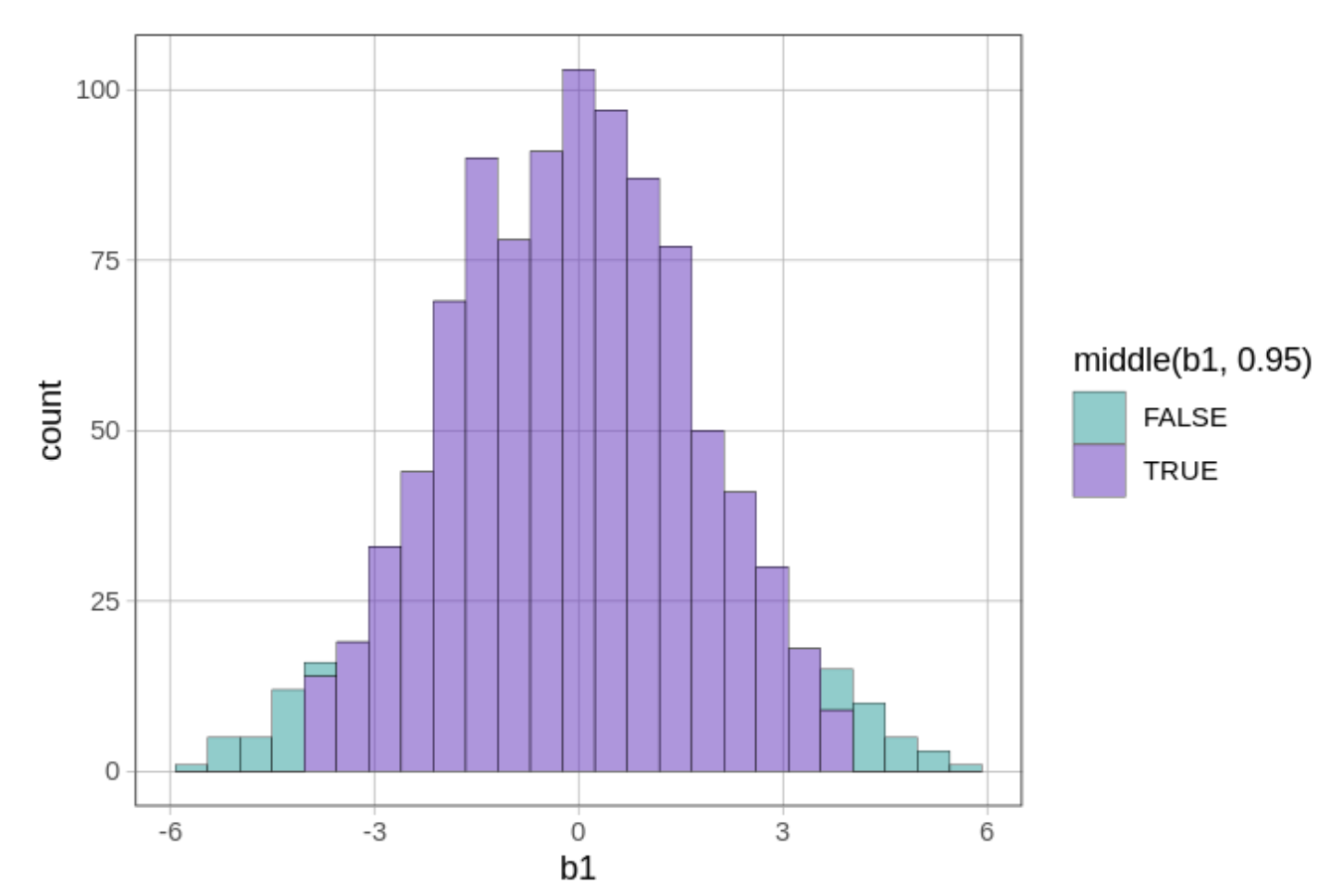
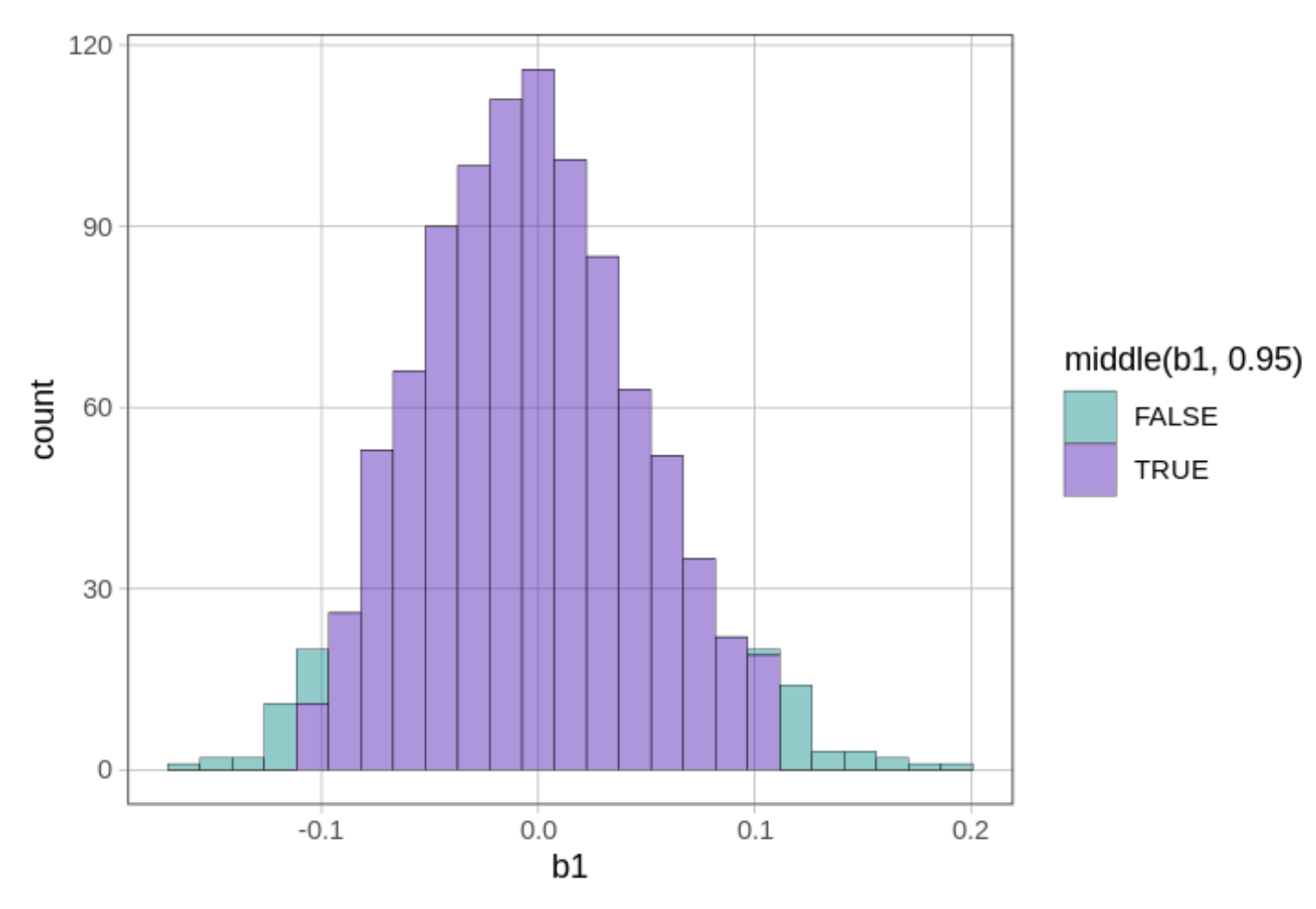
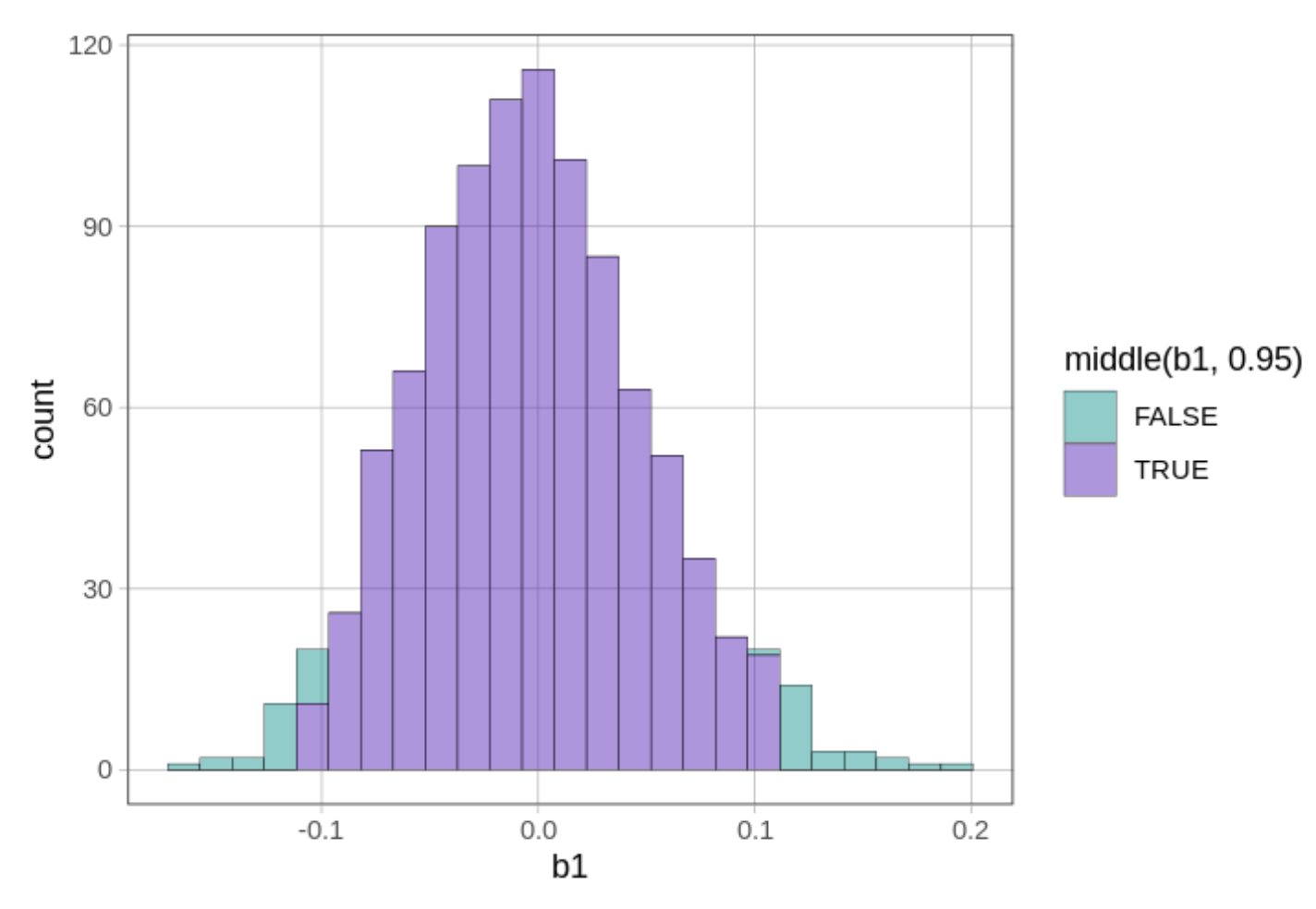
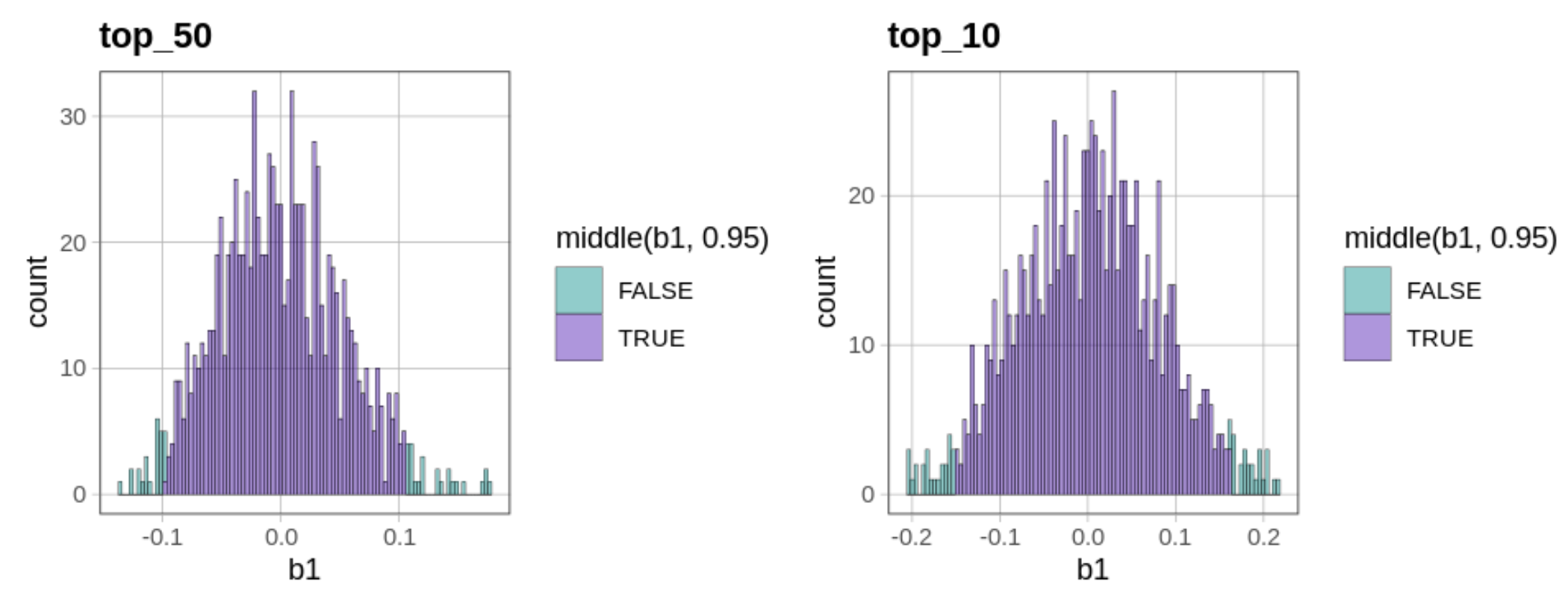
Σε έναν έλεγχο διπλής κατεύθυνσης, θα απορρίψουμε το κενό μοντέλο της ΔΠΔ αν η τιμή του \(b_1\) του δείγματός μας βρίσκεται έξω από την κεντρική περιοχή του 0.95 των τυχαία παραγόμενων τιμών \(b_1\). Μπορούμε να χρησιμοποιήσουμε τη συνάρτηση middle() για να χρωματίσουμε το μεσαίο 0.95 των τιμών \(b_1\) με διαφορετικό χρώμα.
gf_histogram(~b1, data = sdob1, fill =~middle(b1, .95))
Η παράμετρος fill = υποδεικνύει στην R ότι θέλουμε οι ράβδοι του ιστογράμματος να γεμίσουν με διαφορετικά χρώματα. Το σύμβολο ~ δηλώνει ότι το χρώμα γεμίσματος θα εξαρτάται από το αν η τιμή του \(b_1\) που απεικονίζεται βρίσκεται στο κεντρικό 0.95 της δειγματοληπτικής κατανομής ή όχι.
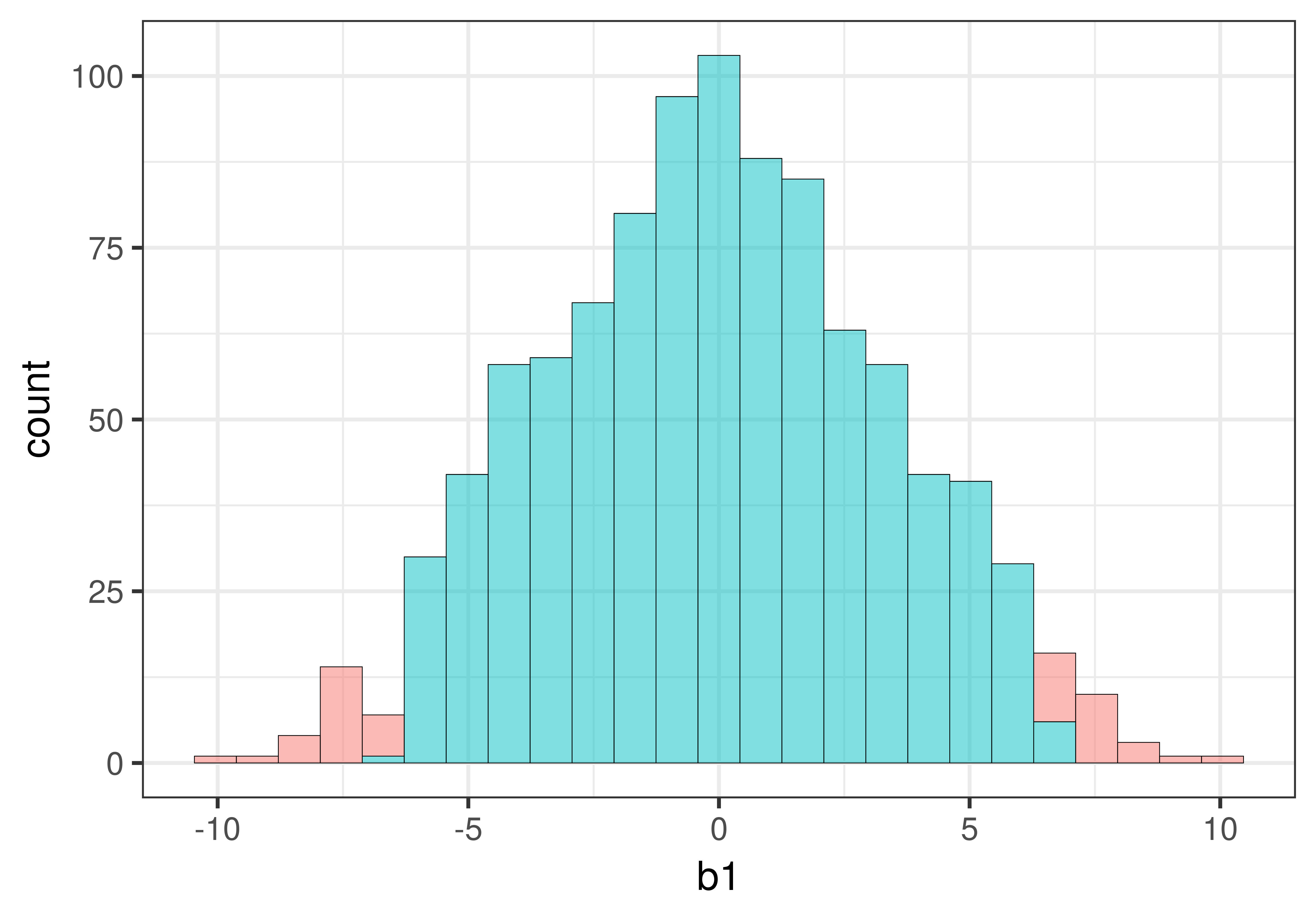
Το παρακάτω ιστόγραμμα δείχνει πώς εμφανίζεται η δειγματοληπτική κατανομή όταν προσθέτουμε την παράμετρο fill = ~middle(b1, .95) στη συνάρτηση gf_histogram().
Μπορεί να αναρωτιέστε γιατί ορισμένες ράβδοι του ιστογράμματος περιλαμβάνουν τόσο κόκκινο όσο και πράσινο χρώμα. Αυτό συμβαίνει επειδή τα δεδομένα σε ένα ιστόγραμμα ομαδοποιούνται σε διαστήματα τιμών (bins). Η τιμή 6.59, για παράδειγμα, ομαδοποιείται στο ίδιο διάστημα με την τιμή 6.68, αλλά ενώ η τιμή 6.59 βρίσκεται εντός του κεντρικού 95% (και επομένως χρωματίζεται με πράσινο), η τιμή 6.68 βρίσκεται λίγο έξω από το άνω όριο, στην περιοχή του 0.025 (και επομένως χρωματίζεται με κόκκινο).
Αν θέλετε να δείτε πιο καθαρά τα όρια, θα μπορούσατε να δοκιμάσετε να κάνετε τα διαστήματα τιμών μικρότερα, ή με άλλα λόγια, να δημιουργήσετε περισσότερα διαστήματα τιμών στο ιστόγραμμα. Έτσι θα είναι πιο πιθανό να έχετε μόνο ένα χρώμα σε κάθε διάστημα τιμών.
Ξαναδημιουργήσαμε το ιστόγραμμα, αλλά αυτή τη φορά ορίσαμε το bins = 100 (ο προεπιλεγμένος αριθμός διαστημάτων τιμών είναι 30). Προσθέσαμε επίσης την παράμετρο show.legend = FALSE για να αφαιρέσουμε το υπόμνημα και έτσι να αφήσουμε περισσότερο χώρο για το ιστόγραμμα.
gf_histogram(~b1, data = sdob1, fill =~middle(b1, .95), bins =100, show.legend =FALSE)
Η αύξηση του αριθμού των διαστημάτων τιμών είχε ως αποτέλεσμα κάθε διάστημα να αντιπροσωπεύεται από ένα μόνο χρώμα. Αλλά δημιούργησε και κάποια κενά στο ιστόγραμμα, δηλαδή άδεια διαστήματα τιμών στα οποία δεν βρέθηκε καμία από τις τιμές \(b_1\). Αυτό δεν είναι πρόβλημα, είναι απλώς μια φυσική συνέπεια της αύξησης του αριθμού των διαστημάτων.
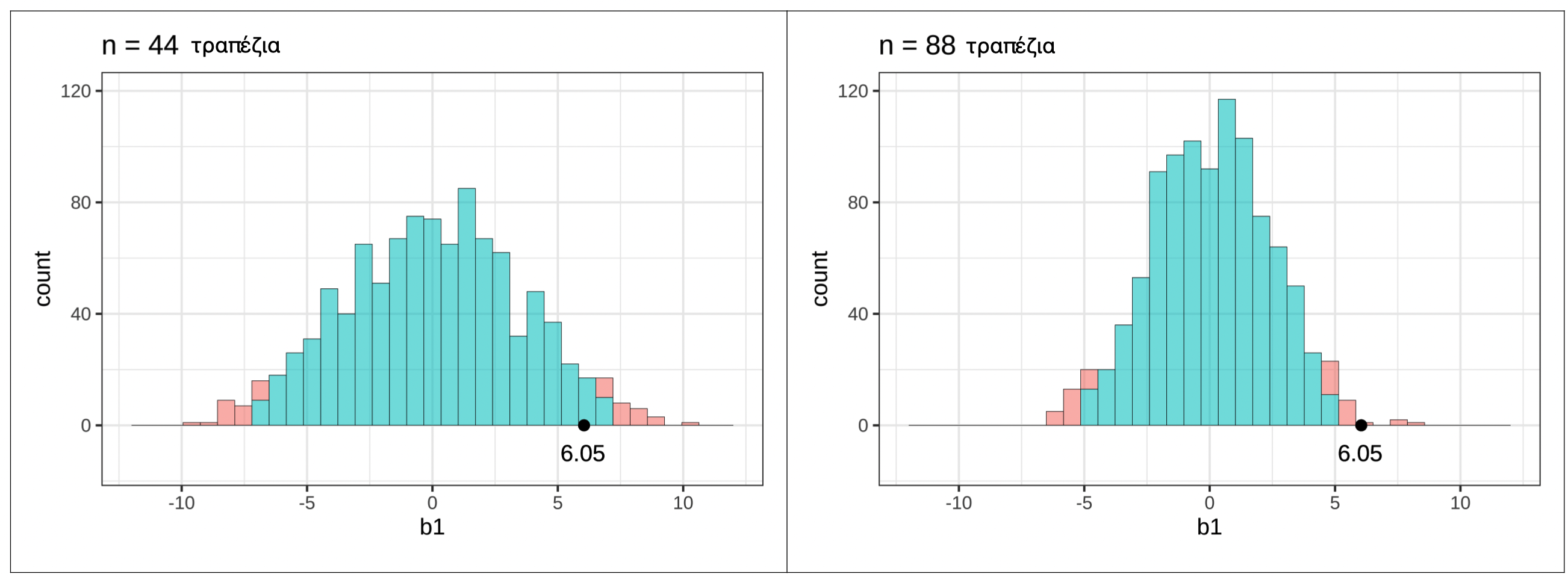
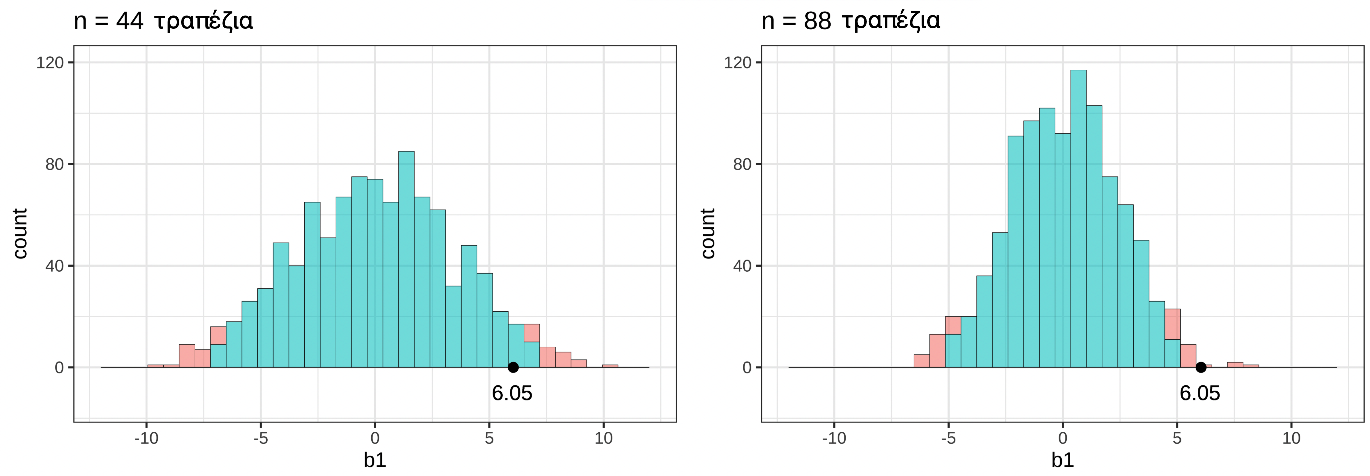
Η κόκκινη μπάρα κάτω από το βέλος αντιπροσωπεύει την τιμή \(b_1\) για ένα μόνο τυχαίο δείγμα από το κενό μοντέλο. Πόσες μεμονωμένες παρατηρήσεις χρησιμοποιήθηκαν για τον υπολογισμό αυτής της τιμής \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — 44, ο αριθμός των τραπεζιών στο αρχικό πλαίσιο δεδομένων
Γιατί 44;
Κάθε τιμή \(b_1\) στη δειγματοληπτική κατανομή υπολογίζεται από ένα πλήρες δείγμα — δηλαδή από όλα τα 44 τραπέζια του αρχικού συνόλου δεδομένων TipExperiment.
Η διαδικασία shuffle()ανακατανέμει τα 44 φιλοδωρήματα στις δύο συνθήκες, αλλά ο συνολικός αριθμός των παρατηρήσεων παραμένει 44.
Γιατί οι άλλες επιλογές είναι λάθος:
Α. 1000 — Αυτός είναι ο αριθμός των τιμών \(b_1\) στη δειγματοληπτική κατανομή (πόσες φορές επαναλάβαμε τη διαδικασία), όχι ο αριθμός των παρατηρήσεων που χρησιμοποιήθηκαν για τον υπολογισμό κάθε\(b_1\).
Β. 22 — Αυτός είναι ο αριθμός των τραπεζιών σε κάθε ομάδα, αλλά η τιμή \(b_1\) υπολογίζεται χρησιμοποιώντας και τις δύο ομάδες μαζί (22 + 22 = 44).
Βρίσκεται η τιμή \(b_1\) του δείγματός μας επάνω σε αυτό το ιστόγραμμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Όχι, όλες αυτές είναι τυχαία δημιουργημένες τιμές \(b_1\)
Τι περιέχει το ιστόγραμμα;
Το ιστόγραμμα δείχνει τη δειγματοληπτική κατανομή — δηλαδή 1000 τιμές \(b_1\) που δημιουργήθηκαν με τυχαία ανακατανομή (shuffle) των δεδομένων, προσομοιώνοντας έναν κόσμο όπου το κενό μοντέλο είναι αληθές.
Πού βρίσκεται η τιμή \(b_1\) του δείγματός μας;
Η πραγματική τιμή \(b_1\) που υπολογίσαμε από τα αρχικά δεδομένα του πειράματος δεν περιλαμβάνεται σε αυτό το ιστόγραμμα με την έννοια ότι δεν είναι μία από τις τιμές που χρησιμοποιήθηκαν για να δημιουργηθεί. Αυτή είναι η τιμή που θέλουμε να συγκρίνουμε με τη δειγματοληπτική κατανομή, για να δούμε αν είναι αρκετά ακραία ώστε να απορρίψουμε το κενό μοντέλο.
Με λίγα λόγια:
Ιστόγραμμα: 1000 τιμές \(b_1\) από προσομοιώσεις (κενό μοντέλο)
Δείγμα μας: 1 τιμή \(b_1\) από τα πραγματικά δεδομένα (δεν χρησιμοποιήθηκε για τη δημιουργία του ιστογράμματος)
ΣημαντικόΣημαντικό
Θυμηθείτε ότι αυτό το ιστόγραμμα αναπαριστά μια δειγματοληπτική κατανομή. Όλες αυτές οι τιμές \(b_1\) ήταν το αποτέλεσμα 1000 τυχαίων ανακατεμάτων των δεδομένων μας. Καμία από αυτές δεν είναι η τιμή \(b_1\) που υπολογίστηκε από τα πραγματικά δεδομένα του πειράματος φιλοδωρημάτων. Όλες αυτές οι τιμές \(b_1\) δημιουργήθηκαν από μια ΔΠΔ για την οποία ισχύει ότι το κενό μοντέλο είναι αληθές.
Στο πραγματικό πείραμα, φυσικά, έχουμε στη διάθεσή μας μόνο ένα δείγμα. Αν η πραγματική δειγματική τιμή \(b_1\) βρεθεί στην περιοχή της δειγματοληπτικής κατανομής που είναι χρωματισμένη κόκκινη (με βάση το \(\alpha\) που ορίσαμε), θα αμφιβάλλουμε ότι παράχθηκε από τη ΔΠΔ που υποθέτει ότι \(\beta_1 = 0\). Σε αυτή την περίπτωση, με βάση το επίπεδο σημαντικότητας \(\alpha\) που έχουμε θέσει, θα απορρίπταμε το κενό μοντέλο. Αυτή η απόφασή μας θα μπορούσε να είναι σωστή…
Αλλά θα μπορούσε να είναι και λάθος. Με δεδομένο ότι το κενό μοντέλο είναι αληθές, το 0.05 (5%) των τιμών \(b_1\) που θα μπορούσαν να προκύψουν από διαφορετικές τυχαιοποιήσεις των τραπεζιών στις συνθήκες θα ήταν αρκετά ακραίες ώστε να μας οδηγήσουν (εσφαλμένα) στην απόρριψη του κενού μοντέλου. Αν απορρίπταμε το κενό μοντέλο ενώ, στην πραγματικότητα, αυτό είναι αληθές, θα κάναμε ένα Σφάλμα Τύπου Ι. Ορίζοντας το \(\alpha\) ίσο με 0.05, δηλώνουμε στην ουσία ότι σε όλη αυτή τη διαδικασία είμαστε εντάξει με το να έχουμε ένα ποσοστό Σφάλματος Τύπου Ι ίσο με 5%.
Ποιο είναι το Αντίθετο του Απίθανου;
Μας ενδιαφέρει αν το δειγματικό \(b_1\) βρίσκεται στα άκρα του 5%. Αλλά τι γίνεται αν δεν βρίσκεται στα άκρα αλλά αντίθετα βρίσκεται στο κεντρικό τμήμα της δειγματοληπτικής κατανομής; Θα πρέπει στην περίπτωση αυτή να το αποκαλέσουμε «πιθανό»;
Για να είμαστε ακριβείς, αν το στατιστικό μας βρίσκεται στο μεσαίο 0.95 της δειγματοληπτικής κατανομής, σημαίνει ότι δεν είναι απίθανο να έχει προκύψει από μια ΔΠΔ όπου \(\beta_1 = 0\). Αλλά το να ισχυριστούμε ότι είναι «πιθανό» να έχει προκύψει από αυτήν τη ΔΠΔ είναι κάπως προβληματικό και πιθανώς παραπλανητικό. Επειδή ο ορισμός μας για το απίθανο είναι οτιδήποτε έχει πιθανότητα 0.05 ή μικρότερη, ακόμα κι αν ένα ενδεχόμενο έχει πιθανότητα 0.06 (6%) θα αναφέρουμε ότι δεν είναι απίθανο. Αλλά δύσκολα κάποιος θα αποκαλούσε κάτι που έχει πιθανότητα να συμβεί 6% ως «πιθανό».
Αν ένα ενδεχόμενο έχει πιθανότητα να συμβεί 0.051 (5.1%) και έχουμε ορίσει το \(\alpha\) μας ίσο με 0.05, θα ήταν πιο ακριβές να πούμε ότι το ενδεχόμενο είναι:
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Όχι απίθανο
Η λογική:
Με \(\alpha\) = 0.05, ο ορισμός μας για το «απίθανο» είναι οτιδήποτε έχει πιθανότητα να συμβεί μικρότερη από 5% (0.05).
Επειδή 0.051 > 0.05, το ενδεχόμενο δεν πληροί το κριτήριο για να θεωρηθεί απίθανο.
Γιατί οι άλλες επιλογές είναι λάθος:
Α. «Απίθανο» — Για να είναι απίθανο, η πιθανότητα θα έπρεπε να είναι μικρότερη από 0.05. Το 0.051 είναι οριακά μεγαλύτερο.
Γ. «Πιθανό» — Αυτό είναι παραπλανητικό. Στην καθημερινή γλώσσα, κάτι με πιθανότητα να συμβεί μόλις 5.1% δεν θα το λέγαμε «πιθανό». Ο πιο ακριβής όρος είναι «όχι απίθανο» — που σημαίνει απλώς ότι δεν πληροί το κριτήριο για απόρριψη.
Γίνεται κουραστικό να αναφέρουμε συνεχώς τη φράση «όχι απίθανο», και μερικές φορές ένα κείμενο διαβάζεται ευκολότερα αν απλώς γράφουμε «πιθανό». Απλά να θυμάστε ότι όταν λέμε «πιθανό» συνήθως εννοούμε «όχι απίθανο», αν και αυτό δεν είναι αυτό που στην καθημερινή επικοινωνία εννοούμε με τη λέξη «πιθανό».
11.5 Η Τιμή \(p\)
Εντοπίζοντας το Δειγματικό \(b_1\) στη Δειγματοληπτική Κατανομή
Έχουμε πλέον αφιερώσει αρκετό χρόνο εξετάζοντας τη δειγματοληπτική κατανομή των τιμών \(b_1\) με την παραδοχή ότι το κενό μοντέλο είναι αληθές (δηλαδή ότι \(\beta_1 = 0\)). Έχουμε αναπτύξει την ιδέα ότι οι τιμές των προσομοιωμένων στατιστικών, όπως αυτά που δημιουργήσαμε από τυχαία ανακατέματα των δεδομένων του πειράματος των φιλοδωρημάτων, συνήθως συγκεντρώνονται γύρω από το 0. Τα στατιστικά του δείγματος που καταλήγουν στις ουρές της κατανομής — δηλαδή στο ανώτερο και κατώτερο 0.025 (ή 2.5%) των τιμών — θεωρούνται απίθανα.
Ας τοποθετήσουμε το δειγματικό μας στατιστικό επάνω στο ιστόγραμμα της δειγματοληπτικής κατανομής που δημιουργήσαμε και ας δούμε πού βρίσκεται. Θα βρίσκεται στις ουρές της κατανομής ή στο μεσαίο 0.95 (ή 95%);
Ο παρακάτω κώδικας αποθηκεύει την τιμή \(b_1\) του δείγματός μας στο αντικείμενο sample_b1.
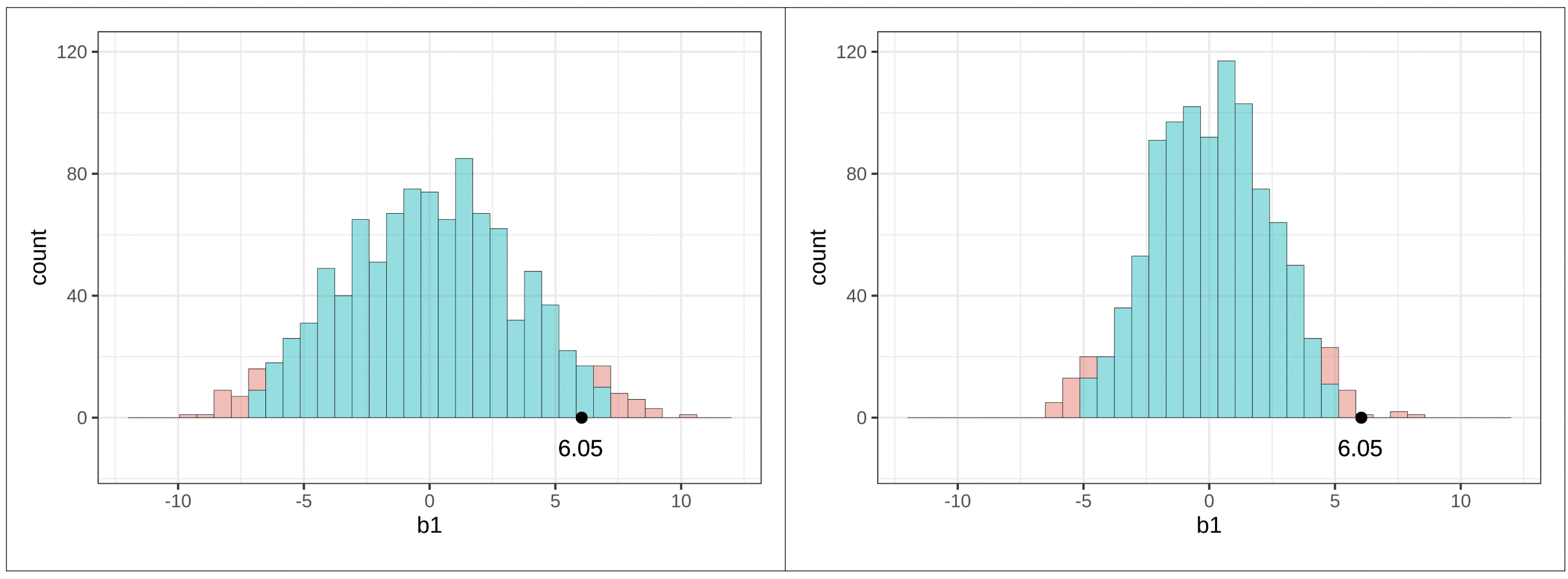
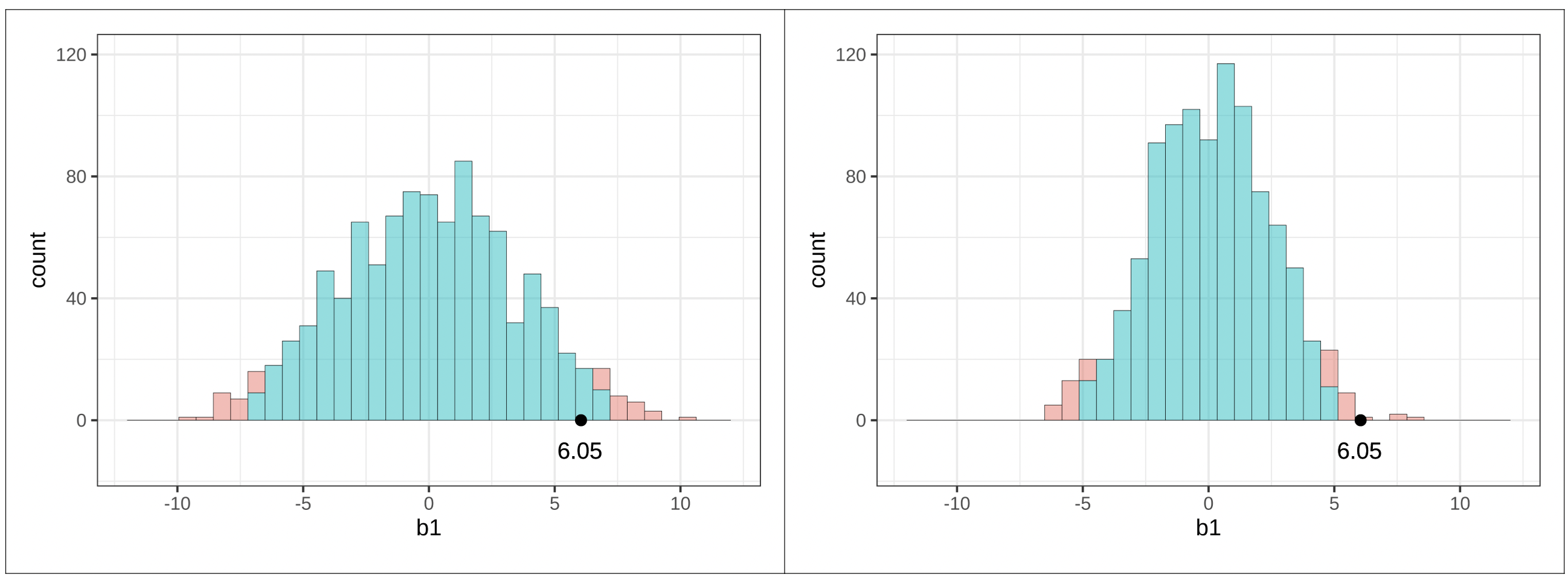
Αν εκτελέσουμε τον κώδικα, θα δούμε ότι η τιμή του δειγματικού \(b_1\) είναι περίπου 6.05: τα τραπέζια στη συνθήκη με το χαμογελαστό πρόσωπο άφησαν, κατά μέσο όρο, 6.05 ποσοστιαίες μονάδες υψηλότερο φιλοδώρημα από τα τραπέζια στην ομάδα ελέγχου.
Με βάση το παραπάνω διάγραμμα, πού νομίζετε ότι θα βρίσκεται η τιμή του δειγματικού \(b_1\) από το πείραμα των φιλοδωρημάτων σε αυτή τη δειγματοληπτική κατανομή που υποθέτει ότι το κενό μοντέλο είναι αληθές; Θα βρίσκεται στο μεσαίο 0.95 ή στις ουρές της κατανομής;
Ας σχεδιάσουμε την τιμή του δειγματικού \(b_1\) στο ιστόγραμμα της δειγματοληπτικής κατανομής. Προσθέτοντας τον παρακάτω κώδικα στη συνάρτηση δημιουργίας του ιστογράμματος (με χρήση του τελεστή %>%) θα τοποθετήσουμε μια μαύρη κουκκίδα ακριβώς στο σημείο που βρίσκεται το δειγματικό \(b_1\), δηλαδή στο 6.05:
gf_point(x =6.05, y =0)
Αν έχετε ήδη αποθηκεύσει την τιμή του \(b_1\) (όπως κάναμε προηγουμένως, στο sample_b1), μπορείτε να γράψετε τον παραπάνω κώδικα και ως εξής:
gf_point(x = sample_b1, y =0)
Μπορούμε εύκολα να διαπιστώσουμε ότι το στατιστικό του δείγματός μας δεν βρίσκεται στην περιοχή των απίθανων τιμών (δηλαδή στις ουρές της δειγματοληπτικής κατανομής). Βρίσκεται οριακά εντός του μεσαίου 0.95 (ή 95%) των τιμών \(b_1\) που παράγονται από το κενό μοντέλο της ΔΠΔ.
Ανακεφαλαίωση της Τριάδας των Κατανομών
Το δύσκολο με τη στατιστική συμπερασματολογία είναι ότι πρέπει να έχουμε στο μυαλό μας ταυτόχρονα και τις τρεις κατανομές που αναφέραμε παραπάνω (δείγματος, ΔΠΔ και δειγματοληπτική κατανομή). Θα παρουσιάσουμε ένα νέο διάγραμμα που δείχνει και τις τρεις αυτές κατανομές μαζί σε σύγκριση μεταξύ τους.
Το παρακάτω διάγραμα αναπαριστά με ποιο τρόπο έχουμε χρησιμοποιήσει μέχρι στιγμής τη δειγματοληπτική κατανομή για να αξιολογήσουμε το κενό μοντέλο (γνωστό και ως μηδενική υπόθεση). Ας ξεκινήσουμε από την κορυφή αυτού του διαγράμματος. Η μπλε οριζόντια γραμμή στο επάνω μέρος αναπαριστά τις πιθανές τιμές του \(\beta_1\) στη ΔΠΔ (ή πληθυσμό από τον οποίο προέρχονται τα δεδομένα). Η πραγματική τιμή του \(\beta_1\) είναι άγνωστη — είναι αυτή που προσπαθούμε να εκτιμήσουμε. Αλλά έχουμε κάνει την υπόθεση ότι είναι 0, οπότε έχουμε βάλει την τιμή 0 μέσα σε κόκκινο πλαίσιο.
Με βάση αυτή την υποθετική ΔΠΔ, προσομοιώσαμε δείγματα που δημιουργήθηκαν από τυχαία ανακατέματα των δεδομένων του πειράματος των φιλοδωρημάτων. Αυτές οι δειγματικές τιμές \(b_1\) τείνουν να συγκεντρώνονται γύρω από το 0 επειδή έχουμε προσομοιώσει το κενό μοντέλο στο οποίο ισχύει ότι \(\beta_1 = 0\). Τα δείγματα που καταλήγουν στις ουρές της κατανομής — το άνω και κάτω 0.025 (ή 2.5%) των τιμών — θεωρείται απίθανο να παρατηρηθούν αν ισχύει το κενό μοντέλο. Έχουμε σχεδιάσει μαύρες διακεκομμένες γραμμές για να αναπαραστήσουμε τα όρια που διαχωρίζουν τις κεντρικές τιμές (που δεν θεωρούνται απίθανες) από τις τιμές που βρίσκονται στο άνω και κάτω άκρο (που θεωρούνται απίθανες).
Τι σημαίνει ότι το δειγματικό \(b_1 = 6.05\) βρίσκεται ανάμεσα στις δύο μαύρες διακεκομμένες γραμμές;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Σημαίνει ότι αυτό το δείγμα δεν είναι απίθανο να έχει παραχθεί από μια ΔΠΔ όπου \(\beta_1 = 0\)
Η λογική:
Οι μαύρες διακεκομμένες γραμμές αναπαριστούν τα όρια που διαχωρίζουν:
Το μεσαίο 95% της κατανομής (όχι απίθανο)
Τις ουρές (το ακραίο 5%, που θεωρείται απίθανο)
Αν το στατιστικό μας βρίσκεται ανάμεσα στις γραμμές, τότε:
Βρίσκεται στο μεσαίο 95% των τιμών
Δεν είναι απίθανο να έχει παραχθεί από το κενό μοντέλο
Δεν απορρίπτουμε το κενό μοντέλο
Γιατί οι άλλες επιλογές είναι λάθος:
Α. «Σίγουρα παράχθηκε από ΔΠΔ με \(\beta_1 = 0\)» — Η στατιστική δεν μας δίνει ποτέ βεβαιότητα. Μπορούμε μόνο να ισχυριστούμε ότι κάτι είναι «όχι απίθανο», αλλά ποτέ «βέβαιο».
Γ. «Είναι απίθανο να έχει παραχθεί από μια ΔΠΔ όπου \(\beta_1 = 0\)» — Αυτό θα ίσχυε αν το στατιστικό μας βρισκόταν έξω από τις διακεκομμένες γραμμές (δηλαδή στις ουρές).
Δ. «Η πραγματική τιμή του \(\beta_1\) είναι \(6.05\)» — Το \(6.05\) είναι η τιμή \(b_1\) του δείγματός μας (εκτίμηση), όχι η πραγματική τιμή \(\beta_1\) της ΔΠΔ. Αυτή η τιμή παραμένει άγνωστη.
Η Έννοια της Τιμής \(p\)
Έχουμε εντοπίσει διαγραμματικά τη δειγματική τιμή \(b_1\) στο πλαίσιο της δειγματοληπτικής κατανομής που δημιουργήθηκε από το κενό μοντέλο, και έχουμε δει ότι βρίσκεται στο μεσαίο 0.95 των προσομοιωμένων τιμών \(b_1\). Αν είχε βρεθεί σε οποιοδήποτε από τα δύο άκρα, θα θεωρούσαμε απίθανο να έχει παραχθεί από το κενό μοντέλο, κάτι που θα μπορούσε να μας οδηγήσει στην απόρριψη του κενού μοντέλου.
Αλλά μπορούμε να κάνουμε κάτι καλύτερο. Δεν χρειάζεται απλώς να θέσουμε μια ερώτηση τύπου ναι/όχι για τη δειγματοληπτική κατανομή μας. Αντί να θέτουμε την ερώτηση αν το δειγματικό \(b_1\) βρίσκεται στην απίθανη περιοχή (ναι ή όχι), θα μπορούσαμε να ρωτήσουμε: ποια είναι η πιθανότητα να πάρουμε μια τιμή \(b_1\) τόσο ακραία ή πιο ακραία από αυτή που παρατηρήθηκε στο πραγματικό πείραμα; Η απάντηση σε αυτή την ερώτηση ονομάζεται τιμή \(p\) (p-value).
Πριν σας δείξουμε πώς υπολογίζεται η τιμή \(p\), ας δούμε λίγο τι σημαίνει αυτή η έννοια.
Το παρακάτω ιστόγραμμα αναπαριστά τη δειγματοληπτική κατανομή που δημιουργήσαμε με την R. Το έχουμε σχεδιάσει έτσι ώστε το άνω και κάτω 0.025 (2.5%) των τιμών \(b_1\) (δηλαδή το πιο ακραίο 5% των τιμών \(b_1\)) να είναι χρωματισμένο με κόκκινο, και το μεσαίο 0.95 με πράσινο.
Δεδομένου ότι υπάρχουν συνολικά 1000 τυχαία δημιουργημένες τιμές \(b_1\) σε αυτή τη δειγματοληπτική κατανομή, πόσες περίπου από αυτές είναι χρωματισμένες με κόκκινο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Περίπου 50
Ο υπολογισμός:
Συνολικές τιμές \(b_1\): 1000
Ποσοστό στις ουρές (κόκκινο): 0.05 (5%)
Αριθμός τιμών με κόκκινο: \(1000 \times 0.05 = 50\)
Από αυτές τις 50:
Περίπου 25 στην κάτω ουρά (αριστερά)
Περίπου 25 στην άνω ουρά (δεξιά)
Ποια είναι η πιθανότητα να πάρουμε μια δειγματική τιμή \(b_1\) που να βρίσκεται στο άνω άκρο (κόκκινη περιοχή), αν το κενό μοντέλο είναι αληθές;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — 0.025
Πώς κατανέμεται το \(\alpha\) = 0.05;
Σε έναν έλεγχο διπλής κατεύθυνσης (two-tailed test), το συνολικό επίπεδο σημαντικότητας \(\alpha\) = 0.05 μοιράζεται εξίσου στις δύο ουρές:
Κάτω ουρά (αριστερά): 0.025 (2.5%)
Άνω ουρά (δεξιά): 0.025 (2.5%)
Σύνολο: 0.025 + 0.025 = 0.05 (5%)
Γιατί οι άλλες επιλογές είναι λάθος;
Επιλογή
Γιατί είναι λάθος
0.05
Αυτό είναι το συνολικό\(\alpha\) και στις δύο ουρές μαζί, όχι μόνο στην άνω
0.95
Αυτή είναι η πιθανότητα να βρεθεί μια τιμή εντός της κεντρικής περιοχής (το πράσινο)
Ποια είναι η πιθανότητα μια τυχαία προσομοιωμένη τιμή \(b_1\) από το κενό μοντέλο να βρίσκεται στο άνω άκρο της δειγματοληπτικής κατανομής (περιοχή με κόκκινο χρώμα);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — 0.025
Η μαύρη κουκκίδα αναπαριστά την πραγματική τιμή \(b_1\) που παρατηρήθηκε στο πείραμα των φιλοδωρημάτων. Ποια είναι η πιθανότητα να πάρουμε μια τυχαία προσομοιωμένη τιμή \(b_1\) από το κενό μοντέλο που είναι μεγαλύτερη από την παρατηρούμενη τιμή \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Θα είναι μεγαλύτερη από 0.025
Η λογική:
Η μαύρη κουκκίδα (η παρατηρούμενη τιμή \(b_1\)) βρίσκεται αριστερά του ορίου της άνω ουράς, δηλαδή μέσα στην πράσινη περιοχή.
Το όριο για την άνω ουρά ορίζει το σημείο όπου το 2.5% των τιμών βρίσκεται δεξιά του
Η παρατηρούμενη τιμή μας βρίσκεται αριστερά από αυτό το όριο
Επομένως, η περιοχή δεξιά της μαύρης κουκκίδας περιλαμβάνει όλη την κόκκινη ουρά (2.5%) συν ένα επιπλέον κομμάτι της πράσινης περιοχής
Αφού η πιθανότητα να βρεθεί μια τιμή δεξιά του ορίου είναι 0.025, η πιθανότητα να βρεθεί μια τιμή δεξιά της μαύρης κουκκίδας (που είναι πιο αριστερά) πρέπει να είναι μεγαλύτερη από 0.025.
Η συνολική επιφάνεια των δύο ουρών που είναι χρωματισμένες με κόκκινο στο παραπάνω ιστόγραμμα αναπαριστά το επίπεδο σημαντικότητας \(\alpha\) = 0.05. Αυτές οι περιοχές αναπαριστούν τις τιμές \(b_1\) που δημιουργήθηκαν από το κενό μοντέλο και τις οποίες έχουμε αποφασίσει να κρίνουμε ως απίθανες με βάση το \(\alpha\) μας. Αυτό σημαίνει ότι αν το κενό μοντέλο είναι αληθές, όπως υποθέσαμε όταν κατασκευάσαμε τη δειγματοληπτική κατανομή, τότε η πιθανότητα να πάρουμε ένα δείγμα στην κόκκινη περιοχή θα είναι 0.05 ή 5%.
Ενώ γνωρίζουμε/ορίζουμε ποια είναι η τιμή \(\alpha\) πριν καν πραγματοποιήσουμε μια μελέτη (είναι το κριτήριο που εμείς έχουμε προκαθορίσει για το τι θα θεωρήσουμε ως απίθανο), η τιμή \(p\) υπολογίζεται αφότου πραγματοποιήσουμε μια μελέτη, με βάση τα δεδομένα του δείγματος. Μπορούμε να αναπαραστήσουμε τη διαφορά μεταξύ αυτών των δύο εννοιών στα παρακάτω διαγράμματα, τα οποία εστιάζουν μόνο στην άνω ουρά της δειγματοληπτικής κατανομής του \(b_1\).
Τιμή \(\alpha\)
Αυτό το διάγραμμα αναπαριστά την έννοια του \(\alpha\). Έχοντας αποφασίσει να ορίσουμε το \(\alpha\) ίσο με 0.05, η κόκκινη περιοχή στην άνω ουρά της δειγματοληπτικής κατανομής αναπαριστά το 0.025 των μεγαλύτερων τιμών \(b_1\) που δημιουργήθηκαν με βάση το κενό μοντέλο.
Τιμή \(p\) (p-value)
Αυτό το διάγραμμα αναπαριστά την έννοια της τιμής \(p\). Ενώ η τιμή \(p\) είναι κι αυτή μια πιθανότητα, αυτή δεν εξαρτάται από την τιμή του \(\alpha\). Στο παρακάτω διάγραμμα, η τιμή \(p\) αναπαρίσταται από τη μοβ περιοχή που βρίσκεται δεξιά από τη δειγματική μας τιμή \(b_1\) και είναι η πιθανότητα να παρατηρήσουμε μια τιμή \(b_1\) ίση ή μεγαλύτερη από τη τιμή \(b_1\) του δείγματός μας, υπό την προϋπόθεση ότι το κενό μοντέλο είναι αληθές.
Η διακεκομμένη γραμμή στο διάγραμμα αριστερά έχει προστεθεί για να οριοθετήσει την τιμή πέρα από την οποία θα θεωρούμε το δειγματικό μας στατιστικό απίθανο, και το μεσαίο 0.95 της δειγματοληπτικής κατανομής που θεωρούμε όχι απίθανο. Έχουμε προσθέσει αυτή τη διακεκομμένη γραμμή και στο διάγραμμα δεξιά για να δείτε από που ξεκινά η περιοχή του \(\alpha\).
Στα παραπάνω διαγράμματα, παρουσιάζουμε μόνο το άνω άκρο της δειγματοληπτικής κατανομής. Αλλά επειδή και μια πολύ χαμηλή τιμή \(b_1\) (για παράδειγμα, η τιμή \(-9\)) θα μας έκανε να αμφισβητήσουμε ότι ισχύει το κενό μοντέλο της ΔΠΔ, θέλουμε να κάνουμε έναν έλεγχο διπλής κατεύθυνσης (two-tailed test). Παρακάτω βάλει τα ίδια διαγράμματα το ένα δίπλα στο άλλο για να δείξουμε και τις δύο ουρές της δειγματοληπτικής κατανομής, αναπαριστώντας ξανά τις περιοχές του \(\alpha\) (με κόκκινο χρώμα) και τις τιμής \(p\) (με μοβ χρώμα).
Ποια είναι η πιθανότητα να πάρουμε μια τυχαία προσομοιωμένη τιμή \(b_1\) από το κενό μοντέλο που είναι πιο ακραία από τη δειγματική τιμή \(b_1\); Να γίνει έλεγχος διπλής κατεύθυνσης.
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Θα είναι μεγαλύτερη από 0.05 επειδή οι μοβ περιοχές είναι λίγο μεγαλύτερες από τις κόκκινες περιοχές.
Η λογική:
Συγκρίνοντας τα δύο διαγράμματα:
Κόκκινες περιοχές (τιμή \(\alpha\) = 0.05): Ξεκινούν από τα όρια του 0.025 (διακεκομμένες γραμμές) και εκτείνονται προς τα άκρα
Μοβ περιοχές (τιμή \(p\)): Ξεκινούν από τη θέση του δειγματικού \(b_1\) (μαύρη κουκκίδα) και εκτείνονται προς τα άκρα
Επειδή το δειγματικό \(b_1\) βρίσκεται πιο αριστερά από το όριο της άνω ουράς (δηλαδή πιο κοντά στο κέντρο της κατανομής), οι μοβ ουρές είναι μεγαλύτερες από τις κόκκινες ουρές.
Επομένως, η τιμή \(p\) (με μοβ) είναι μεγαλύτερη από 0.05 (με κόκκινο). Ωστόσο, όπως βλέπουμε δεν είναι πολύ μεγαλύτερη — σίγουρα όχι τόσο μεγάλη όσο θα ήταν μια τιμή ίση με 0.40 ή 0.80!
Επειδή οι μοβ περιοχές, που αναπαριστούν τις τιμές πάνω ή κάτω από τη δειγματική τιμή \(b_1\), είναι λίγο μεγαλύτερες από τις κόκκινες περιοχές, που αναπαριστούν το \(\alpha\) = 0.05, διαπιστώνουμε ότι η τιμή \(p\) είναι μεγαλύτερη από το 0.05. Αλλά δεν είναι πολύ μεγαλύτερη — σίγουρα όχι τόσο μεγάλη όσο μια τιμή ίση με 0.40 ή 0.80!
Αν στη μελέτη μας είχαμε υπολογίσει δειγματική τιμή \(b_1\) ίση με 9, πώς αυτό θα επηρέαζε το μέγεθος της τιμής του \(\alpha\) (τις κόκκινες περιοχές στο ιστόγραμμα);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — Δεν θα είχε καμία επίδραση στο \(\alpha\), επειδή αυτό είναι το κριτήριο που ορίζουμε για το «απίθανο» και αποφασίζεται πριν γίνει η μελέτη.
Η λογική:
Το \(\alpha\) είναι ένα κριτήριο που ορίζουμε πριν κάνουμε τη μελέτη:
Είναι η απόφασή μας για το τι θα θεωρήσουμε «απίθανο»
Συνήθως ορίζεται στο 0.05 (ή πιο σπάνια στο 0.01, το 0.001 κλπ.)
Δεν εξαρτάται από τα αποτελέσματα του δείγματος
Ανεξάρτητα από το αν το δειγματικό \(b_1\) είναι 6.05 ή 9 ή οποιαδήποτε άλλη τιμή, το \(\alpha\) παραμένει ίσο με 0.05.
Αν στη μελέτη μας είχαμε υπολογίσει δειγματική τιμή \(b_1\) ίση με 9, πώς αυτό θα επηρέαζε το μέγεθος της τιμής \(p\) (τις μοβ περιοχές στο ιστόγραμμα);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Θα την έκανε μικρότερη.
Η λογική:
Η τιμή \(p\) υπολογίζεται μετά τη μελέτη και εξαρτάται από το δειγματικό \(b_1\):
Η τιμή \(p\) είναι η πιθανότητα να πάρουμε μια τιμή \(b_1\)τόσο ακραία ή πιο ακραία από αυτή που παρατηρήσαμε στο δείγμα
Αν το δειγματικό \(b_1\) ήταν \(9\) αντί για \(6.05\):
Η μοβ περιοχή θα ξεκινούσε από το \(9\) στο άνω άκρο (και το \(-9\) στο κάτω άκρο)
Αυτή η περιοχή θα ήταν μικρότερη επειδή το \(9\) είναι πιο ακραία τιμή από το 6.05
Άρα η τιμή \(p\) θα ήταν μικρότερη
Γενικός κανόνας:
Όσο πιο ακραίο το δειγματικό \(b_1\), τόσο μικρότερη η τιμή \(p\).
ΣημαντικόΟρισμός της Τιμής \(p\)
Η τιμή \(p\) είναι η πιθανότητα να παρατηρήσουμε ένα στατιστικό του δείγματος τόσο ακραίο ή πιο ακραίο όσο αυτό που παρατηρήσαμε, υπό την προϋπόθεση ότι το κενό μοντέλο είναι αληθές.
Επομένως, η τιμή \(p\) υπολογίζεται με βάση τόσο την τιμή ενός στατιστικού του δείγματος όσο και το σχήμα της δειγματοληπτικής κατανομής της αντίστοιχης παραμέτρου υπό το κενό μοντέλο. Αντίθετα, η τιμή \(\alpha\) δεν εξαρτάται από την τιμή του στατιστικού του δείγματος.
11.6 Υπολογισμός της Τιμής \(p\) για ένα Δείγμα
Για να υπολογίσουμε την πιθανότητα να πάρουμε μια τιμή \(b_1\) εντός μιας συγκεκριμένης περιοχής (π.χ., μεγαλύτερης από \(6.05\) ή μικρότερη από \(-6.05\)) μπορούμε απλώς να υπολογίσουμε το ποσοστό των τιμών \(b_1\) στη δειγματοληπτική κατανομή που βρίσκεται εντός αυτής της περιοχής. Με αυτόν τον τρόπο, χρησιμοποιούμε την προσομοιωμένη δειγματοληπτική κατανομή των 1000 τιμών \(b_1\) ως μια κατανομή πιθανότητας.
Μπορούμε να χρησιμοποιήσουμε τη συνάρτηση tally() για να βρούμε πόσα προσομοιωμένα δείγματα είναι πιο ακραία από το δειγματικό μας \(b_1\). Η πρώτη γραμμή κώδικα της tally() θα υπολογίσει πόσες τιμές \(b_1\) είναι πιο ακραίες προς τη θετική πλευρά από το δειγματικό μας \(b_1\) (sample_b1 = 6.05), ενώ η δεύτερη γραμμή, πόσες είναι πιο ακραίες προς την αρνητική πλευρά (-6.05).
tally(~ b1 > sample_b1, data = sdob1)tally(~ b1 <-sample_b1, data = sdob1)
Οι δύο γραμμές κώδικα θα δώσουν ένα αποτέλεσμα παρόμοιο με το παρακάτω:
Αν προσθέσουμε τις τιμές στις δύο ουρές (δηλαδή τις 38 ακραίες θετικές και τις 41 ακραίες αρνητικές τιμές \(b_1\)), διαπιστώνουμε ότι υπάρχουν περίπου 80 τιμές \(b_1\) που είναι πιο ακραίες από τη δειγματική μας τιμή \(b_1\).
Τι αντιπροσωπεύουν αυτές οι περίπου 80 τιμές \(b_1\); (Επιλέξτε όλα όσα ισχύουν.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Γ
Γιατί οι Α και Γ είναι σωστές:
Α: Οι 80 τιμές \(b_1\) είναι αυτές που βρίσκονται πιο μακριά από τη δειγματική μας τιμή \(b_1\) (πάνω από \(6.05\) ή κάτω από \(-6.05\)). Αυτές θεωρούνται «απίθανες» με βάση τη θέση του δείγματός μας.
Γ: Η δειγματοληπτική κατανομή δημιουργήθηκε υποθέτοντας ότι το κενό μοντέλο είναι αληθές (\(\beta_1 = 0\)). Οι 80 τιμές είναι αυτές που παράχθηκαν από αυτό το μοντέλο και είναι πιο ακραίες από το δείγμα μας.
Γιατί οι Β και Δ είναι λάθος:
Β: Η δειγματοληπτική κατανομή δημιουργήθηκε από μια ΔΠΔ για την οποία ισχύει το κενό μοντέλο, όχι από οποιαδήποτε ΔΠΔ.
Δ: Η δειγματοληπτική κατανομή δημιουργήθηκε με την παραδοχή ότι ισχύει το κενό μοντέλο, όχι το σύνθετο.
Τι μας λένε αυτές οι 80 τιμές \(b_1\) για την πιθανότητα το δείγμα μας ή ένα πιο ακραίο από αυτό να έχει δημιουργηθεί από μια ΔΠΔ στην οποία δεν υπάρχει επίδραση του χαμογελαστού προσώπου (δηλαδή, στην οποία ισχύει ότι \(\beta_1 = 0\));
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β
Γιατί η Β είναι σωστή:
Δημιουργούμε μια δειγματοληπτική κατανομή υποθέτοντας ότι το κενό μοντέλο είναι αληθές (\(\beta_1 = 0\)). Αν 80 από τις 1.000 προσομοιωμένες τιμές \(b_1\) είναι τόσο ακραίες ή πιο ακραίες από την παρατηρούμενη τιμή \(b_1\) του δείγματός μας, τότε:
\[p = \frac{80}{1000} = 0.08\]
Αυτό σημαίνει ότι υπάρχει περίπου 8% πιθανότητα να παρατηρήσουμε μια τιμή \(b_1\) τόσο ακραία όσο η δική μας (ή πιο ακραία) αν υποθέσουμε ότι το κενό μοντέλο είναι αληθές.
Γιατί η Α είναι λάθος:
Αυτό θα σήμαινε 800 από τις 1.000, όχι 80. Η υποδιαστολή είναι σε λάθος θέση.
Γιατί η Γ είναι λάθος:
Αυτή είναι μια συνηθισμένη παρερμηνεία της τιμής \(p\). Η τιμή \(p\) μας δίνει την πιθανότητα να παρατηρήσουμε τα δεδομένα μας αν ισχύει η υπόθεση του κενού μοντέλου, ΟΧΙ την πιθανότητα το κενό μοντέλο να είναι αληθές. Αυτό είναι ένα πολύ συνηθισμένο λάθος στην ερμηνεία των τιμών \(p\).
Δεδομένου ότι υπάρχουν περίπου 80 τυχαία παραγόμενες τιμές \(b_1\) (από τις 1000) που είναι πιο ακραίες από αυτή στο δείγμα μας, θα λέγαμε ότι υπάρχει πιθανότητα περίπου 0.08 (ή 8%) το κενό μοντέλο να δημιουργήσει ένα δείγμα με τιμή \(b_1\) τόσο ακραία όσο η 6.05. Αυτή η πιθανότητα είναι η τιμή \(p\).
Αντί να χρησιμοποιούμε δύο γραμμές κώδικα — μία για να βρούμε τον αριθμό των τιμών \(b_1\) στο άνω άκρο, και την άλλη στο κάτω άκρο — μπορούμε να χρησιμοποιήσουμε μία μόνο γραμμή ως εξής:
Σημειώστε τη χρήση του τελεστή |, που σημαίνει «ή», για να συνδυάσουμε τα δύο κριτήρια: αυτός ο κώδικας μετράει τον συνολικό αριθμό των τιμών \(b_1\) που είναι είτε μεγαλύτερες από τη θετική τιμή 6.05 είτε μικρότερες από την αρνητική -6.05. Μπορείτε να εκτελέσετε τον κώδικα παρακάτω. Έχουμε προσθέσει στη συνάρτηση tally() την παράμετρο format = "proportion" για να υπολογιστεί απευθείας το ποσοστό ή την τιμή \(p\).
Η τιμή \(p\) για το \(b_1\) στο πείραμα του φιλοδωρήματος βρέθηκε περίπου ίση με 0.08 και συνεπώς είναι μεγαλύτερη από την τιμή \(\alpha\) = 0.05. Επομένως, μπορούμε να ισχυριστούμε ότι το δείγμα μας δεν είναι απίθανο να έχει δημιουργηθεί από μια ΔΠΔ στην οποία ισχύει το κενό μοντέλο. Με άλλα λόγια, θεωρούμε το κενό μοντέλο ως ένα εύλογο μοντέλο για τη ΔΠΔ και επομένως δεν το απορρίπτουμε. Με άλλα λόγια, ακόμα και μια ΔΠΔ στην οποία δεν υπάρχει επίδραση του χαμογελαστού προσώπου μπορεί να παράγει μια τιμή \(b_1\) τόσο ακραία ή πιο ακραία από αυτή που παρατηρήσαμε στο δείγμα μας περίπου στο 0.08 (8%) των περιπτώσεων.
Αν η τιμή \(p\) που βρήκαμε ήταν μικρότερη από 0.05, θα μπορούσαμε να ισχυριστούμε ότι το δείγμα μας είναι απίθανο να έχει δημιουργηθεί από μια ΔΠΔ στην οποία ισχύει το κενό μοντέλο, και έτσι θα απορρίπταμε το κενό μοντέλο ως ένα εύλογο μοντέλο για τη ΔΠΔ.
Τι Σημαίνει να Απορρίπτουμε — ή Όχι — το Κενό Μοντέλο (ή τη Μηδενική Υπόθεση)
Η έννοια της τιμής \(p\), και η χρήση της για να αποφασίσουμε αν θα απορρίψουμε ή όχι το κενό μοντέλο υπέρ του πιο σύνθετου μοντέλου που έχουμε προσαρμόσει στα δεδομένα, προέρχεται από μια παράδοση στη στατιστική συμπερασματολογία γνωστή ως Έλεγχος Στατιστικής Σημαντικότητας της Μηδενικής Υπόθεσης (Null Hypothesis Significance Testing - NHST). Η μηδενική υπόθεση είναι, στην πραγματικότητα, το ίδιο με αυτό που αποκαλούμε κενό μοντέλο. Αναφέρεται σε έναν κόσμο στον οποίο ισχύει ότι \(\beta_1 = 0\).
Ενώ στόχος μας είναι να κατανοήσετε τη λογική του NHST, θέλουμε παράλληλα να είστε προσεκτικοί κατά την ερμηνεία της τιμής \(p\). Η παράδοση του NHST έχει δεχθεί κριτική επειδή συχνά εφαρμόζεται απερίσκεπτα, με έναν ιδιαίτερα τυποποιημένο τρόπο. Άτομα που δεν καταλαβαίνουν πραγματικά τι σημαίνει η τιμή \(p\) μπορεί να καταλήξουν σε εσφαλμένα συμπεράσματα.
Για παράδειγμα, μόλις αποφασίσαμε με βάση μια τιμή \(p\) ίση με 0.08, να μην απορρίψουμε το κενό μοντέλο του ποσοστού φιλοδωρήματος (Tip). Αλλά τι σημαίνει αυτό; Σημαίνει ότι η τιμή της παραμέτρου \(\beta_1\) είναι ίση με 0; Όχι. Σημαίνει ότι θα μπορούσε να είναι ίση με 0 και ότι τα δεδομένα που παρατηρήσαμε είναι συνεπή με το να είναι ίση με 0. Αλλά θα μπορούσε στην πραγματικότητα να είναι ίση και με κάποια άλλη τιμή.
Θα μπορούσε, για παράειγμα, να είναι ίση με 6.05, που ήταν η εκτίμηση της \(\beta_1\) με βάση τα δεδομένα του δείγματος μας. Αν η πραγματική τιμή της \(\beta_1\) ήταν ίση με 6.05, θα μπορούσαμε να είμαστε βέβαιοι ότι το 6.05 θα ήταν μία από τις πολλές πιθανές τιμές της \(\beta_1\) που θα θεωρούνταν εύλογες με βάση τα δεδομένα.
Αν, όμως, τόσο το κενό μοντέλο όσο και το σύνθετο «καλύτερα προσαρμοσμένο» μοντέλο είναι πιθανά αληθινά μοντέλα της ΔΠΔ, πώς πρέπει να αποφασίσουμε ποιο μοντέλο να χρησιμοποιήσουμε;
Κάποιοι ερευνητές, προερχόμενοι από την παράδοση του ελέγχου της μηδενικής υπόθεσης, θα υποστήριζαν ότι, εφόσον δεν μπορούμε να απορρίψουμε το κενό μοντέλο, οφείλουμε να το υιοθετήσουμε. Από αυτή την οπτική, η αποφυγή του Σφάλματος Τύπου Ι έχει ύψιστη προτεραιότητα: δεν θέλουμε να ισχυριστούμε ότι υπάρχει επίδραση του χαμογελαστού προσώπου στη ΔΠΔ όταν στην πραγματικότητα δεν υπάρχει. Στο πλαίσιο αυτό, το Σφάλμα Τύπου Ι θεωρείται σοβαρότερο από το Σφάλμα Τύπου ΙΙ, δηλαδή από το να συμπεράνουμε ότι δεν υπάρχει επίδραση ενώ στην πραγματικότητα υπάρχει στη ΔΠΔ.
Ωστόσο, αυτή η στρατηγική δεν αποτελεί κατ’ ανάγκην την ενδεδειγμένη πορεία δράσης σε όλες τις περιπτώσεις. Για παράδειγμα, όταν ο στόχος είναι να γίνουν καλύτερες προβλέψεις, μπορεί κανείς να επιλέξει το σύνθετο μοντέλο, ακόμη και αν δεν είναι δυνατή η απόρριψη του κενού μοντέλου. Αντίθετα, όταν ο σκοπός είναι η βαθύτερη κατανόηση της ΔΠΔ, έχει αξία η υιοθέτηση της απλούστερης θεωρίας που παραμένει συνεπής με τα διαθέσιμα δεδομένα. Οι επιστήμονες αναφέρονται σε αυτή την προτίμηση υπέρ της απλότητας με τον όρο «φειδωλότητα» (parsimony).
Οι Judd, McClelland και Ryan, στατιστικολόγοι τους οποίους εκτιμούμε ιδιαίτερα, έχουν υποστηρίξει ότι το ζητούμενο είναι απλώς να αποφασίσει κανείς αν ένα μοντέλο είναι «αρκετά καλύτερο ώστε να υιοθετηθεί». Ένα μεγάλο μέρος της στατιστικής συμπερασματολογίας συνίσταται στον εντοπισμό ενός συνόλου εναλλακτικών μοντέλων που είναι συμβατά με τα δεδομένα και στην αξιολόγηση του ποια από αυτά εξυπηρετούν καλύτερα τον εκάστοτε στόχο.
Προτιμούμε να προσεγγίζουμε το πρόβλημα με όρους σύγκρισης μοντέλων αντί ελέγχου της μηδενικής υπόθεσης. Η υπερβολική έμφαση στον έλεγχο της μηδενικής υπόθεσης μπορεί να δημιουργήσει την εντύπωση ότι η ανάλυση ολοκληρώνεται μόλις είτε απορριφθεί είτε δεν απορριφθεί το κενό μοντέλο. Αντίθετα, στο πλαίσιο της μοντελοποίησης, η αναζήτηση του καλύτερου μοντέλου είναι διαρκής: ενός μοντέλου που συμβάλλει ουσιαστικότερα στην κατανόηση της ΔΠΔ ή που δίνει ακριβέστερες προβλέψεις για μελλοντικά γεγονότα.
11.7 Ένα Μαθηματικό Μοντέλο της Δειγματοληπτικής Κατανομής του \(b_1\)
Οι πρώτοι στατιστικολόγοι που ανέπτυξαν τις ιδέες πίσω από τις δειγματοληπτικές κατανομές και τις τιμές \(p\) δεν είχαν υπολογιστές. Μπορούσαν μόνο να φανταστούν πώς θα ήταν να ανακατεύουν τυχαία τα δεδομένα τους για να μιμηθούν μια ΔΠΔ. Αυτό που μπορούμε σήμερα να κάνουμε με την R θα τους φαινόταν σαν θαύμα! Αντί να χρησιμοποιούν υπολογιστικές τεχνικές για να δημιουργήσουν δειγματοληπτικές κατανομές, οι πρώτοι στατιστικολόγοι έπρεπε να αναπτύξουν μαθηματικά μοντέλα για το πώς θα έπρεπε να μοιάζουν οι δειγματοληπτικές κατανομές, και στη συνέχεια να υπολογίσουν πιθανότητες με βάση αυτές τις μαθηματικές κατανομές.
Στην πραγματικότητα, η τιμή \(p\) που βλέπετε στον πίνακα ANOVA που δημιουργείται από τη συνάρτηση supernova() (καθώς και από τα περισσότερα άλλα στατιστικά λογισμικά) υπολογίζεται από ένα μαθηματικό μοντέλο της δειγματοληπτικής κατανομής.
Ο παρακάτω κώδικας προσαρμόζει το μοντέλο της Condition στα δεδομένα TipExperiment και αποθηκεύει το μοντέλο ως Condition_model. Χρησιμοποιήστε τη συνάρτηση supernova() για να δημιουργήσετε τον πίνακα ANOVA για αυτό το μοντέλο, και κοιτάξτε την τιμή \(p\) (στη δεξιότερη στήλη του πίνακα).
Analysis of Variance Table (Type III SS)Model: Tip ~ Condition SS df MS F PRE p--------------------|---------------------------------Model (error reduced) |402.0231402.0233.3050.0729 .0762Error (from model) |5108.95542121.642--------------------|---------------------------------Total (empty model) |5510.97743128.162
Η τιμή \(p\) από τη συνάρτηση supernova(), στρογγυλοποιημένη στο δεύτερο δεκαδικό ψηφίο, είναι περίπου 0.08, πολύ κοντά σε αυτήν που υπολογίσαμε χρησιμοποιώντας την εμπειρική δειγματοληπτική κατανομή μετά από 1000 τυχαία ανακατέματα. Η προσέγγιση που βασίζεται στο μαθηματικό μοντέλο δεν είναι κατ’ ανάγκην καλύτερη από την προσέγγιση με το τυχαίο ανακάτεμα· το σημαντικό είναι ότι και οι δύο μέθοδοι οδηγούν σε παρόμοιο αποτέλεσμα. (Αν και η εκτέλεση της supernova() είναι ταχύτερη, αρκετοί θεωρούν την έννοια της δειγματοληπτικής κατανομής πιο κατανοητή όταν τη δημιουργούν από την αρχή με τη χρήση της συνάρτησης shuffle().)
Η κατανομή \(t\)
Η μαθηματική συνάρτηση που χρησιμοποιεί η supernova() για να προσεγγίσει τη δειγματοληπτική κατανομή του \(b_1\) —καθώς και πολλών άλλων εκτιμητών παραμέτρων— είναι γνωστή ως κατανομή \(t\). Η κατανομή \(t\) σχετίζεται με την κανονική κατανομή και, πράγματι, της μοιάζει αρκετά.
Στο παρακάτω σχήμα, η κατανομή \(t\) (με κόκκινη γραμμή) προβάλλεται επάνω στη δειγματοληπτική κατανομή που κατασκευάσαμε με τη χρήση της shuffle(). Όπως φαίνεται, προσεγγίζει πολύ την κανονική κατανομή, την οποία γνωρίζετε ήδη.
Όπως φαίνεται στο παραπάνω ιστόγραμμα, ενώ η δειγματοληπτική κατανομή που δημιουργήσαμε με τη συνάρτηση shuffle() είναι μη ομαλή (διότι αποτελείται από 1000 μόλις επιμέρους τιμές \(b_1\)), η κατανομή \(t\) είναι μια εξομαλυμένη καμπύλη, μια συνεχής μαθηματική συνάρτηση. Αν θέλετε να δείτε την εξίσωση που περιγράφει αυτή την συνάρτηση, μπορείτε να την βρείτε εδώ.
Ενώ το σχήμα της κανονικής κατανομής καθορίζεται μόνο από το μέσο όρο και την τυπική απόκλιση, η κατανομή \(t\) αλλάζει ελαφρώς σχήμα ανάλογα με το πόσες παρατηρήσεις περιλαμβάνονται στα δείγματα που απαρτίζουν τη δειγματοληπτική κατανομή. (Στην πράξη, εξαρτάται από τους βαθμούς ελευθερίας (df) εντός της κάθε ομάδας, οι οποίοι όπως έχετε μάθει είναι ίσοι με \(n-1\). Για τη μελέτη των φιλοδωρημάτων, οι βαθμοί ελευθερίας είναι 42, δηλαδή 21 για κάθε ομάδα.)
Στο παρακάτω διάγραμμα, μπορείτε να δείτε πώς αλλάζει το σχήμα της κατανομής \(t\) όταν αλλάζουν οι βαθμοί ελευθερίας (df). Παρατηρήστε ότι όταν οι βαθμοί ελευθερίας φτάσουν την τιμή 30, η κατανομή \(t\) μοιάζει πολύ με την κανονική κατανομή (καμπύλη με μαύρο χρώμα).
Χρήση της κατανομής \(t\) για τον υπολογισμό πιθανοτήτων
Στη δειγματοληπτική κατανομή που δημιουργήσατε με τη χρήση της shuffle(), μπορούσατε απλώς να μετρήσετε πόσες τιμές \(b_1\) ήταν πιο ακραίες από την παρατηρούμενη τιμή \(b_1\) του δείγματος, προκειμένου να υπολογίσετε την τιμή \(p\). Η κατανομή \(t\) λειτουργεί με τον ίδιο τρόπο, με τη διαφορά ότι ο υπολογισμός των πιθανοτήτων στις άνω και κάτω ουρές απαιτεί πιο σύνθετες μαθηματικές πράξεις. Ευτυχώς, δεν χρειάζεται να κάνετε αυτούς τους υπολογισμούς με το χέρι· η R τους κάνει για εσάς, για παράδειγμα όταν χρησιμοποιείτε τη συνάρτηση supernova().
Ακολουθεί ένα διάγραμμα της κατανομής \(t\) (αριστερά) που αναπαριστά την τιμή \(p\) ως τη συνολική περιοχή που βρίσκεται στις δύο ουρές με ανοιχτό πράσινο χρώμα, και το ιστόγραμμα των τιμών \(b_1\) της δειγματοληπτικής κατανομής (δεξιά) που δείχνει το ίδιο πράγμα αλλά με μοβ χρώμα. Ο οριζόντιος άξονας και στα δύο διαγράμματα έχει επισημανθεί με τιμές του \(b_1\) για να είναι ευκολότερη η σύγκρισή τους.
Τι είναι παρόμοιο σε αυτές τις δύο κατανομές; (Επιλέξτε όλα όσα ισχύουν.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Β, Ε, ΣΤ, Θ, ΙΑ
Γιατί αυτές είναι σωστές:
Α & Β: Και οι δύο κατανομές έχουν περίπου κανονικό, συμμετρικό σχήμα καμπάνας.
Ε: Και οι δύο αναπαριστούν τη δειγματοληπτική κατανομή των τιμών \(b_1\) — δηλαδή, την κατανομή των τιμών \(b_1\) που θα μπορούσαν να προκύψουν από πολλά δείγματα.
ΣΤ: Και οι δύο έχουν κέντρο το 0 επειδή και οι δύο υποθέτουν ότι ισχύει το κενό μοντέλο (\(\beta_1 = 0\)).
Θ: Και οι δύο κατασκευάστηκαν υποθέτοντας ότι το κενό μοντέλο είναι αληθές, δηλαδή ότι η πραγματική επίδραση είναι 0.
ΙΑ: Και οι δύο μέθοδοι καταλήγουν σε παρόμοιες τιμές \(p\) (περίπου 0.08).
Γιατί οι άλλες είναι λάθος:
Γ & Δ: Δεν αναπαριστούν τη δειγματοληπτική κατανομή ή τον πληθυσμό των φιλοδωρημάτων — αναπαριστούν τη δειγματοληπτική κατανομή του \(b_1\).
Ζ: Δεν έχουν κέντρο το \(6.05\) — είναι κεντραρισμένες στο 0.
Η & Ι: Δεν υποθέτουν θετική ή αρνητική επίδραση — υποθέτουν μηδενική επίδραση.
Τι είναι διαφορετικό σε αυτές τις δύο κατανομές;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α
Γιατί είναι σωστή:
Α: Η κατανομή \(t\) είναι ένα μαθηματικό μοντέλο — μια θεωρητική κατανομή που ορίζεται από εξισώσεις. Το ιστόγραμμα, αντίθετα, προέκυψε από προσομοίωση: επαναλαμβάνοντας πολλές φορές τυχαίο ανακάτεμα των δεδομένων και υπολογίζοντας κάθε φορά την τιμή \(b_1\).
Γιατί οι άλλες είναι λάθος:
Β: Το αντίστροφο — το ιστόγραμμα δεν είναι μαθηματικό μοντέλο.
Γ & Δ: Και οι δύο μέθοδοι είναι έγκυρες για αυτή την περίπτωση — καμία δεν είναι «λανθασμένη».
Ε & ΣΤ: Και οι δύο κατανομές αναπαριστούν τη δειγματοληπτική κατανομή του \(b_1\), όχι την κατανομή των φιλοδωρημάτων στη ΔΓΠ.
Ο Έλεγχος \(t\) Δύο Δειγμάτων
Αν έχετε παρακολουθήσει μαθήματα στατιστικής στο παρελθόν, πιθανώς να έχετε ακουσει για τον έλεγχο \(t\) (t-test). Ο έλεγχος \(t\) χρησιμοποιείται για τον υπολογισμό της τιμής \(p\) για τη διαφορά μεταξύ δύο ομάδων με ανεξάρτητες παρατηρήσεις. Το πείραμα των φιλοδωρημάτων είναι ακριβώς μια τέτοια περίπτωση: το \(b_1\) με το οποίο δουλεύαμε μέχρι τώρα είναι η διαφορά των μέσων όρων φιλοδωρήματος μεταξύ των δύο ομάδων τραπεζιών, αυτών που έλαβαν το χαμογελαστό πρόσωπο και αυτών που δεν το έλαβαν.
Μπορείτε να χρησιμοποιήσετε την R για να κάνετε εφαρμόσετε έναν έλεγχο \(t\) στα δεδομένα του πειράματος με τα φιλοδωρήματα:
Αν εκτελέσετε αυτόν τον κώδικα θα σας δώσει τιμή \(p\) ίση με 0.0762, η οποία είναι ακριβώς αυτή που είδατε στον πίνακα ANOVA που παράχθηκε από τη συνάρτηση supernova(). Παρόλο που το αποτέλεσμα της supernova() δεν σας δείχνει το στατιστικό \(t\) ή άλλες λεπτομέρειες για το πώς υπολογίζει την τιμή \(p\), στο παρασκήνιο χρησιμοποιεί την κατανομή \(t\) για τον υπολογισμό των τιμών \(p\).
ΣυμβουλήΣημείωση
Η μέθοδος που έχετε μάθει, δηλαδή αυτή της δημιουργίας ενός μοντέλου δύο ομάδων και της σύγκρισής του με το κενό μοντέλο, είναι πολύ πιο ισχυρή και γενικεύσιμη από τον έλεγχο \(t\). Αλλά αν κάποιος σας ρωτήσει αν γνωρίζετε τον έλεγχο \(t\), μπορείτε να απαντήσετε θετικά. Είναι ένας παραδοσιακός, μαθηματικός τρόπος να κάνετε ακριβώς αυτό που ήδη έχετε μάθει να κάνετε — να συγκρίνετε ένα μοντέλο με το κενό μοντέλο — απλώς χρησιμοποιεί θεωρητικές κατανομές αντί για προσομοίωση. (Η μέθοδος που έχετε μάθει με τη χρήση της shuffle() ονομάζεται μερικές φορές και έλεγχος τυχαιοποίησης ή έλεγχος μεταθέσεων — randomization test ή permutation test.)
11.8 Παράγοντες που Επηρεάζουν την Τιμή \(p\)
Τι θα Γινόταν αν το Δειγματικό \(b_1\) Ήταν 10;
Η δειγματική τιμή του \(b_1\) στο πείραμα των φιλοδωρημάτων ήταν ίση με \(6.05\). Με βάση τη δειγματοληπτική κατανομή που δημιουργήσαμε για το \(b_1\) υποθέτοντας ότι ισχύει το κενό μοντέλο, υπολογίσαμε την πιθανότητα να πάρουμε ένα δείγμα με \(b_1\) τόσο ακραίο ή πιο ακραίο από το 6.05 ως περίπου ίση με 0.08. Με βάση το επίπεδο σημαντικότητας \(\\alpha\) που ορίσαμε ίσο με 0.05, αποφασίσαμε ότι το 6.05 δεν είναι απίθανο να έχει προκύψει από το κενό μοντέλο, και έτσι δεν απορρίψαμε το κενό μοντέλο.
Φανταστείτε, τώρα, η μέση διαφορά ανάμεσα στην ομάδα με το χαμογελαστό πρόσωπο και την ομάδα ελέγχου να ήταν ίση με 10 ποσοστιαίες μονάδες. Πώς θα επηρέαζε αυτό την τιμή \(p\), και πώς θα επηρέαζε την απόφασή μας σχετικά με το αν θα απορρίψουμε ή όχι το κενό μοντέλο της ΔΠΔ;
Στο παρακάτω σχήμα έχουμε αναπαράγει τη δειγματοληπτική κατανομή του \(b_1\) υποθέτοντας ότι το κενό μοντέλο της ΔΠΔ είναι αληθές. Οι κόκκινες ουρές μαζί δείχνουν το 0.05 (5%) των πιο ακραίων τιμών \(b_1\), με κάθε ουρά να περιλαμβάνει το 0.025 (2.5%), ή το μισό, των ακραίων τιμών.
Αν το δειγματικό \(b_1\) ήταν 10 (αντί για 6), θα βρισκόταν στην πιθανή ή στην απίθανη περιοχή αυτής της δειγματοληπτικής κατανομής;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Στην απίθανη
Κοιτάζοντας το ιστόγραμμα, η τιμή \(b_1 = 10\) θα βρισκόταν πολύ δεξιά, πέρα από την κόκκινη ουρά. Αυτό σημαίνει ότι θα έπεφτε στην απίθανη περιοχή — μια τιμή που είναι πολύ σπάνιο να παραχθεί από το κενό μοντέλο.
Ποια θα ήταν η τιμή \(p\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Πολύ μικρή, σίγουρα μικρότερη από 0.05
Η τιμή \(p\) είναι η πιθανότητα να πάρουμε μια τιμή \(b_1\)τόσο ακραία ή πιο ακραία από αυτή που παρατηρήσαμε.
Με \(b_1 = 6.05\), η τιμή \(p\) ήταν περίπου 0.08
Με \(b_1 = 10\), η τιμή θα ήταν πολύ πιο ακραία
Επομένως, η τιμή \(p\) θα ήταν πολύ μικρότερη — σίγουρα κάτω από 0.05
Γενικός κανόνας: Όσο πιο ακραίο το \(b_1\), τόσο μικρότερη η τιμή \(p\).
Πώς θα επηρέαζε μια τιμή \(b_1\) ίσο με 10 τη σκέψη μας για το κενό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Θα αύξανε την αμφιβολία μας ότι το δείγμα μας παράχθηκε από το κενό μοντέλο.
Αν η τιμή \(b_1 = 10\) είναι απίθανο να παραχθεί από το κενό μοντέλο (τιμή \(p < 0.05\)), τότε:
Αμφισβητούμε ότι το κενό μοντέλο είναι αληθές
Απορρίπτουμε το κενό μοντέλο
Συμπεραίνουμε ότι πιθανώς υπάρχει πραγματική επίδραση του χαμογελαστού προσώπου (\(\beta_1 \neq 0\))
Η τιμή \(p\) επηρεάζεται σίγουρα από το πόσο μακριά είναι η παρατηρούμενη τιμή \(b_1\) από το 0. Δεδομένου ότι το 10 είναι πιο μακριά από το 0 από ό,τι το \(6.05\) από το 0, όταν \(b_1 = 10\), η τιμή \(p\) θα είναι μικρότερη. Όσο πιο μακριά είναι το \(b_1\) από το 0, τόσο μικρότερη η τιμή \(p\), που σημαίνει ότι είναι τόσο λιγότερο πιθανό η παρατηρούμενη τιμή \(b_1\) να έχει παραχθεί από το κενό μοντέλο.
Τυπικό Σφάλμα και Τιμή \(p\)
Η απόσταση μεταξύ του \(b_1\) και του 0 (ή της υποθετικής τιμής \(\beta_1\)) δεν είναι το μόνο πράγμα που επηρεάζει την τιμή \(p\). Ο άλλος σημαντικός παράγοντας είναι η διασπορά της δειγματοληπτικής κατανομής, η οποία μπορεί να ποσοτικοποιηθεί με το τυπικό σφάλμα.
ΣημαντικόΟρισμός
Το τυπικό σφάλμα (standard error) είναι η τυπική απόκλιση της δειγματοληπτικής κατανομής.
Ρίξτε μια ματιά στις δύο προσομοιωμένες δειγματοληπτικές κατανομές που παρουσιάζονται παρακάτω. Αυτή στα αριστερά είναι αυτή που δημιουργήσαμε χρησιμοποιώντας τη shuffle() για το πείραμα των φιλοδωρημάτων. Αυτή στα δεξιά είναι παρόμοια αλλά το εύρος της είναι σημαντικά μικρότερο. Και οι δύο έχουν περίπου κανονικό σχήμα, και οι δύο αποτελούνται από 1000 τιμές \(b_1\), και οι δύο κατανομές είναι κεντραρισμένες στο 0. Αλλά η τυπική απόκλιση (που στην περίπτωση αυτή την ονομάζουμε τυπικό σφάλμα) είναι μικρότερη για την κατανομή στα δεξιά.
Σε ποια περίπτωση θα ήταν η τιμή \(p\) για την παρατηρούμενη τιμή \(b_1 = 6.05\) μικρότερη: για την πλατύτερη δειγματοληπτική κατανομή (αριστερά) ή για τη στενότερη (δεξιά);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Η τιμή \(p\) θα ήταν μικρότερη για τη στενότερη δειγματοληπτική κατανομή
Η λογική:
Κοιτάζοντας τα δύο διαγράμματα:
Πλατύτερη κατανομή (αριστερά): Η τιμή \(b_1 = 6.05\) (μαύρη κουκκίδα) βρίσκεται κοντά στην ουρά στα δεξιά, αλλά μέσα στην μπλε περιοχή, δηλαδή στο κεντρικό 95% των τιμών της κατανομής. Η τιμή \(p\) είναι περίπου 0.08.
Στενότερη κατανομή (δεξιά): Η ίδια τιμή \(b_1 = 6.05\) βρίσκεται πολύ πιο δεξιά — είναι πολύ πιο ακραία σε σχέση με τις υπόλοιπες τιμές αυτής της κατανομής. Η τιμή \(p\) θα ήταν πολύ μικρότερη.
Γενικός κανόνας:
Όσο στενότερη η δειγματοληπτική κατανομή (μικρότερο τυπικό σφάλμα), τόσο μικρότερη η τιμή \(p\) για την ίδια παρατηρούμενη τιμή \(b_1\).
Αυτό συμβαίνει επειδή σε μια στενότερη κατανομή, η ίδια απόσταση από το 0 αντιπροσωπεύει μια πιο ακραία και πιο απίθανη τιμή.
Το τυπικό σφάλμα της δειγματοληπτικής κατανομής μπορεί να κάνει μεγάλη διαφορά στην αξιολόγησή μας για το κενό μοντέλο. Όσο μικρότερο είναι τόσο πιο εύκολο είναι να απορρίψουμε το κενό μοντέλο, επειδή οποιαδήποτε δειγματική τιμή \(b_1\), θα είναι πιο πιθανό να βρίσκεται στο άνω ή στο κάτω 0.025 της δειγματοληπτικής κατανομής.
Μέγεθος Δείγματος και Τυπικό Σφάλμα
Έχουμε αναφέρει με ποιο τρόπο η τιμή \(p\) επηρεάζεται από το τυπικό σφάλμα (την τυπική απόκλιση της δειγματοληπτικής κατανομής). Και λοιπόν; Μπορούμε πραγματικά να ελέγξουμε την τυπική απόκλιση της δειγματοληπτικής κατανομής; Στην πραγματικότητα, μπορούμε, αν είμαστε εμείς αυτοί που σχεδιάζουν τη μελέτη και συλλέγουν τα δεδομένα.
Υπάρχουν δύο βασικά πράγματα που επηρεάζουν το τυπικό σφάλμα: (1) η τυπική απόκλιση της ΔΠΔ και (2) το μέγεθος του δείγματός μας. Ως ερευνητές, δεν έχουμε έλεγχο στο πόσο μεταβλητή είναι η ΔΠΔ, αλλά επειδή μπορούμε να αποφασίσουμε να συλλέξουμε περισσότερα ή λιγότερα δεδομένα, έχουμε έλεγχο στο μέγεθος του δείγματός μας.
Ας διερευνήσουμε πώς το μέγεθος του δείγματος μπορεί να επηρεάσει τη δειγματοληπτική κατανομή του \(b_1\). Σκεφτείτε ένα εναλλακτικό σύμπαν όπου οι ερευνητές που έκαναν τη μελέτη των φιλοδωρημάτων συνέλεξαν δεδομένα από 88 τραπέζια αντί για μόνο 44. Φανταστείτε ότι το δείγμα είχε την ίδια ακριβώς μέση διαφορά μεταξύ των ομάδων (\(b_1\)) και την ίδια τυπική απόκλιση για το ποσοστό φιλοδωρήματος (Tip) με την αρχική μελέτη, με μοναδική διαφορά ότι απλώς είχε περισσότερα τραπέζια στο δείγμα.
Για να προσομοιώσουμε αυτή τη φανταστική κατάσταση, δημιουργήσαμε ένα νέο πλαίσιο δεδομένων που ονομάζεται TipExp2 που απλώς έχει δύο αντίγραφα κάθε τραπεζιού από το αρχικό TipExperiment. Μπορούμε να εκτελέσουμε τη str() σε αυτό το νέο πλαίσιο δεδομένων για να δούμε πώς μοιάζει.
Χρησιμοποιήστε το παρακάτω τμήμα κώδικα για να συγκρίνετε το νέο πλαίσιο δεδομένων (TipExp2) με το αρχικό (TipExperiment). Συγκεκριμένα, κοιτάξτε το συνολικό μέσο όρο και την τυπική απόκλιση της εξαρτημένης μεταβλητής Tip, για κάθε σύνολο δεδομένων, και επίσης προσαρμόστε το μοντέλο της Condition για να δείτε ποια είναι η τιμή του στατιστικού \(b_1\) για τα δύο σύνολα δεδομένων.
Μπορείτε να συγκρίνετε τα αποτελέσματά σας με τον παρακάτω πίνακα. Τα στατιστικά είναι παρόμοια μεταξύ των δύο δειγμάτων για έναν λόγο: και τα δύο πλαίσια δεδομένων περιλαμβάνουν τα ίδια 44 τραπέζια, είτε μία φορά είτε δύο.
Μέγεθος Δείγματος
Μέσος όρος Tip
Τυπ. Απόκλ. Tip
\(b_1\)
n=44
30.0
11.3
6.05
n=88
30.0
11.3
6.05
Αν και ο διπλασιασμός του μεγέθους του δείγματος δεν επηρεάζει το μέσο όρο, την τυπική απόκλιση ή το \(b_1\) — αυτά είναι όλα χαρακτηριστικά της κατανομής του δείγματος — θα επηρεάσει την τυπική απόκλιση της δειγματοληπτικής κατανομής. Ας εξετάσουμε αυτή την ιδέα δημιουργώντας δύο δειγματοληπτικές κατανομές, μία για το δείγμα με \(n = 44\) και μία για \(n=88\). Θα χρησιμοποιήσουμε ξανά τη συνάρτηση shuffle() για να προσομοιώσουμε το κενό μοντέλο, όπου \(\beta_1 = 0\).
Ακολουθεί κώδικας για να δημιουργήσουμε τις δύο δειγματοληπτικές κατανομές του \(b_1\), μία για το σύνολο δεδομένων με 44 τραπέζια, την άλλη με 88 τραπέζια.
sdob44 <-do(1000) *b1(shuffle(Tip) ~ Condition, data = TipExperiment)sdob88 <-do(1000) *b1(shuffle(Tip) ~ Condition, data = TipExp2)
Στη συνέχεια εκτελέσαμε αυτόν τον κώδικα για να πάρουμε τα ιστογράμματα των δύο δειγματοληπτικών κατανομών του \(b_1\).
gf_histogram(~ b1, data = sdob44, fill =~middle(b1,.95), bins=36, show.legend =FALSE) %>%gf_lims(x =c(-12, 12), y =c(-15,120))gf_histogram(~ b1, data = sdob88, fill =~middle(b1,.95), bins=36, show.legend =FALSE) %>%gf_lims(x =c(-12, 12), y =c(-15,120))
Σημειώστε ότι προσθέσαμε στον κώδικα το (gf_lims(x = c(-12, 12), y = c(-15,120))) για να βεβαιωθούμε ότι οι κλίμακες είναι ίδιες για τα δύο ιστογράμματα ώστε να μπορείτε να τα συγκρίνετε πιο εύκολα. Μπορεί να αναγνωρίζετε αυτά τα ιστογράμματα — είναι τα ίδια με αυτά που παρουσιάσαμε παραπάνω, αλλά τώρα ξέρετε πώς τα δημιουργήσαμε.
Ποιες από τις παρακάτω παρατηρήσεις είναι αληθείς για τις δύο δειγματοληπτικές κατανομές που απεικονίζονται παραπάνω; (Επιλέξτε όλα όσα ισχύουν.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Δ, Ε
Γιατί αυτές είναι σωστές:
Α: Με μεγαλύτερο δείγμα (n=88), οι τιμές \(b_1\) συγκεντρώνονται πιο στενά γύρω από το 0, άρα είναι πιο όμοιες μεταξύ τους.
Ε: Όταν η κατανομή είναι στενότερη, η τιμή \(6.05\) πέφτει πιο έξω (στην «απίθανη» κόκκινη περιοχή).
Γιατί οι άλλες είναι λάθος:
Β & Γ: Το αντίθετο είναι αληθές — μεγαλύτερο δείγμα σημαίνει μικρότερη μεταβλητότητα.
ΣΤ: Το αντίθετο — με μικρότερη μεταβλητότητα, το \(6.05\) είναι στην απίθανη περιοχή, όχι στην πιθανή.
Ζ: Το δειγματικό \(b_1\) παραμένει \(6.05\) και στα δύο σενάρια — το μέγεθος του δείγματος δεν αλλάζει την παρατηρηθείσα τιμή.
Τι είναι παρόμοιο στις δύο δειγματοληπτικές κατανομές; (Επιλέξτε όλα όσα ισχύουν.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Β
Γιατί αυτές είναι σωστές:
Α: Και οι δύο κατανομές έχουν περίπου κανονικό σχήμα (καμπάνα).
Β: Και οι δύο είναι κεντραρισμένες στο 0 επειδή και οι δύο προσομοιώνουν το κενό μοντέλο (\(\beta_1 = 0\)).
Γιατί η Γ είναι λάθος:
Η μεταβλητότητα δεν είναι παρόμοια — η κατανομή με n=88 είναι σημαντικά στενότερη από αυτή με n=44.
Ποια κατανομή έχει μεγαλύτερο τυπικό σφάλμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Αυτή που βασίζεται σε δείγματα με n = 44
Η λογική:
Το τυπικό σφάλμα είναι η τυπική απόκλιση της δειγματοληπτικής κατανομής.
Μικρότερο δείγμα (n=44): Πλατύτερη κατανομή → μεγαλύτερο τυπικό σφάλμα
Μεγαλύτερο δείγμα (n=88): Στενότερη κατανομή → μικρότερο τυπικό σφάλμα
Γενικός κανόνας:
Το τυπικό σφάλμα μειώνεται καθώς το μέγεθος του δείγματος αυξάνεται.
Παρατηρήστε πώς η δειγματοληπτική κατανομή έχει πολύ μικρότερη μεταβλητότητα όταν βασίζεται σε δείγματα 88 τραπεζιών από ό,τι για 44 τραπέζια. Χρησιμοποιήστε το παρακάτω τμήμα κώδικα για να υπολογίσετε τα τυπικά σφάλματα για τις δύο δειγματοληπτικές κατανομές. (Υπόδειξη: Το τυπικό σφάλμα είναι η τυπική απόκλιση μιας δειγματοληπτικής κατανομής.)
[1] 3.534982
[1] 2.413229
Παρόλο που και οι δύο δειγματοληπτικές κατανομές είναι περίπου κανονικές και κεντραρισμένες στο 0 (άλλωστε, το κενό μοντέλο έχει \(\beta_1 = 0\)), το τυπικό σφάλμα είναι μικρότερο στη δειγματοληπτική κατανομή των τιμών \(b_1\) που βασίζεται σε δείγματα 88 τραπεζιών (περίπου 2,4 έναντι 3,5).
Αποδεικνύεται ότι τα μεγαλύτερα μεγέθη δείγματος παράγουν πάντα μικρότερα τυπικά σφάλματα (στενότερες δειγματοληπτικές κατανομές), επειδή σε μεγαλύτερα δείγματα, είναι πολύ πιο δύσκολο να παρατηρήσουμε μια ακραία τιμή \(b_1\) μόνο λόγω τυχαίας μεταβλητότητας. Για να πάρουμε μια ακραία τιμή \(b_1\) μόνο λόγω τυχαίας μεταβλητότητας θα χρειαζόταν πολλά από τα τραπέζια με υψηλά φιλοδωρήματα να τύχει να ανατεθούν στη μία ομάδα και τα τραπέζια με χαμηλά φιλοδωρήματα στην άλλη. Αν είχατε μόνο δύο τραπέζια, αυτό είναι αρκετά εύκολο να συμβεί! Αν είχατε μόνο 4 τραπέζια, αυτό επίσης δεν είναι πολύ δύσκολο. Αλλά καθώς αυξάνετε τον αριθμό των τραπεζιών, είναι δύσκολο να διατηρηθεί αυτό το μοτίβο. Είναι ο ίδιος λόγος που είναι εύκολο κατά τη ρίψη ενός νομίσματος να φέρουμε 2 κορώνες στη σειρά αλλά πολύ δύσκολο να φέρουμε 44 κορώνες στη σειρά. Είναι εύκολο να αναθέσουμε τυχαία μερικά τραπέζια που αφήνουν υψηλά φιλοδωρήματα στην ίδια ομάδα αλλά δύσκολο να αναθέσουμε τυχαία στην ίδια ομάδα 40 τραπέζια που αφήνουν υψηλά φιλοδωρήματα.
Λάβετε υπόψη τις δύο δειγματοληπτικές κατανομές που δημιουργήθηκαν από το κενό μοντέλο της ΔΠΔ για τα παραπάνω δείγματα με 44 και 88 τραπέζια. Ποια δειγματοληπτική κατανομή θα μας οδηγούσε να απορρίψουμε το κενό μοντέλο ως εύλογο μοντέλο της ΔΠΔ που παρήγαγε το δείγμα μας;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Η δειγματοληπτική κατανομή όπου το μέγεθος του δείγματος είναι 88.
Η λογική:
Κοιτάζοντας τα δύο ιστογράμματα:
n = 44: Το δειγματικό \(b_1 = 6.05\) (μαύρη κουκκίδα) βρίσκεται στην άκρη της μπλε περιοχής — είναι όχι απίθανο. Δεν απορρίπτουμε το κενό μοντέλο.
n = 88: Το ίδιο \(b_1 = 6.05\) βρίσκεται έξω από την κόκκινη ουρά — είναι απίθανο. Απορρίπτουμε το κενό μοντέλο.
Η στενότερη κατανομή (n=88) κάνει την ίδια τιμή \(b_1\) να φαίνεται πιο ακραία.
Παρόλο που η δειγματική τιμή \(b_1\) είναι η ίδια και στις δύο περιπτώσεις, όταν το τυπικό σφάλμα είναι μικρότερο, αυτό κάνει το δείγμα μας να φαίνεται λιγότερο πιθανό να έχει παραχθεί από το κενό μοντέλο. Γενικά, η τιμή \(p\) για ένα δειγματικό στατιστικό θα είναι μικρότερη καθώς το μέγεθος του δείγματος γίνεται μεγαλύτερο.
Ας ρίξουμε μια ματιά στην τιμή \(p\), η οποία μπορεί να βρεθεί στον πίνακα ANOVA.
Analysis of Variance Table (Type III SS)
Model: Tip ~ Condition (From TipExperiment)
SS df MS F PRE p
----- ----------------- -------- -- ------- ----- ------ -----
Model (error reduced) | 402.023 1 402.023 3.305 0.0729 .0762
Error (from model) | 5108.955 42 121.642
----- ----------------- -------- -- ------- ----- ------ -----
Total (empty model) | 5510.977 43 128.162
Analysis of Variance Table (Type III SS)
Model: Tip ~ Condition (From TipExp2)
SS df MS F PRE p
----- ----------------- --------- -- ------- ----- ------ -----
Model (error reduced) | 804.045 1 804.045 6.767 0.0729 .0109
Error (from model) | 10217.909 86 118.813
----- ----------------- --------- -- ------- ----- ------ -----
Total (empty model) | 11021.955 87 126.689
Παρατηρήστε ότι η τιμή \(p\) από τα αρχικά δεδομένα είναι 0.0762 αλλά η τιμή \(p\) από τα διπλάσια σε μέγεθος δεδομένα είναι 0.0109. Παρακάτω έχουμε αναπαραστήσει την τιμή \(p\) (με μοβ χρώμα) χρωματίζοντας τις ουρές πέρα από το δείγμα σε καθεμία από αυτές τις δειγματοληπτικές κατανομές.
Ποια είναι η σχέση ανάμεσα στο τυπικό σφάλμα και την τιμή \(p\);
11.9 Έλεγχοι Υποθέσεων για Μοντέλα Παλινδρόμησης
Έχουμε δει αναλυτικά τη λογική του ελέγχου υποθέσεων για μοντέλα ομάδων. Χρησιμοποιήσαμε τη συνάρτηση shuffle() για να δημιουργήσουμε μια δειγματοληπτική κατανομή υποθέτοντας ότι \(\beta_1 = 0\), και στη συνέχεια χρησιμοποιήσαμε τη δειγματοληπτική κατανομή για να υπολογίσουμε την πιθανότητα η δειγματική μας τιμή \(b_1\) ή μια πιο ακραία από αυτή να έχει προέλθει από το κενό μοντέλο.
Τώρα ας εφαρμόσουμε τις ίδιες ιδέες σε μοντέλα παλινδρόμησης. Όπως θα δείτε, η στρατηγική είναι ακριβώς η ίδια. Θέλουμε να δημιουργήσουμε μια δειγματοληπτική κατανομή των τιμών \(b_1\), αν και αυτή τη φορά το \(b_1\) θα αναπαριστά την κλίση της ευθείας παλινδρόμησης, όχι μια διαφορά ομάδων. Ας δούμε πώς γίνεται αυτό προσθέτοντας μια νέα μεταβλητή στο πλαίσιο δεδομένων του πειράματος των φιλοδωρημάτων.
Φιλοδωρήματα = Ποιότητα Φαγητού + Άλλοι Παράγοντες
Έχουμε διερευνήσει την επίδραση του χαμογελαστού προσώπου στο πόσο φιλοδώρημα αφήνουν οι πελάτες σε ένα εστιατόριο. Αλλά σίγουρα υπάρχουν και άλλοι παράγοντες που μπορούν να μας βοηθήσουν να εξηγήσουμε τη μεταβλητότητα στο ποσοστό φιλοδωρήματος. Ένας από αυτούς μπορεί να είναι η αντιλαμβανόμενη ποιότητα του φαγητού. Μπορούμε να διερευνήσουμε αυτή την υπόθεση κοιτάζοντας μια άλλη μεταβλητή που είναι διαθέσιμη στο πλαίσιο δεδομένων TipExperiment: τη μεταβλητή FoodQuality (ποιότητα φαγητού).
Συγκεκριμένα, ζητήθηκε από κάθε πελάτη κάθε τραπεζιού να βαθμολογήσει την ποιότητα του φαγητού σε μια κλίμακα από το 0 έως το 100, με το 50 (τη μέση της κλίμακας) να σημαίνει «περίπου στο μέσο όρο για αυτό το είδος εστιατορίου», το 100 να είναι το καλύτερο φαγητό που έχει δοκιμάσει ποτέ στη ζωή του, και το 0 το χειρότερο. Η μεταβλητή FoodQuality είναι ο μέσος όρος βαθμολογίας για κάθε τραπέζι.
TableID Tip Condition FoodQuality
1 1 39 Control 54.9
2 2 36 Control 51.7
3 3 34 Control 60.5
4 4 34 Control 56.7
5 5 33 Control 51.0
6 6 31 Control 43.3
Δημιουργήσαμε ένα διάγραμμα διασποράς για να εξετάσουμε την υπόθεση ότι η μεταβλητή FoodQuality μπορεί να εξηγεί κάποια από τη μεταβλητότητα στην εξαρτημένη μεταβλητή Tip.
Κοιτάζοντας αυτό το διάγραμμα διασποράς, θεωρείτε ότι το να γνωρίζουμε τη μέση βαθμολογία ποιότητας φαγητού ενός τραπεζιού θα μας βοηθούσε να κάνουμε καλύτερη πρόβλεψη για το φιλοδώρημα που θα αφήσει;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Ναι
Κοιτάζοντας το διάγραμμα διασποράς, φαίνεται να υπάρχει μια θετική τάση ή συσχέτιση διότι καθώς η ποιότητα φαγητού αυξάνεται, το φιλοδώρημα τείνει επίσης να αυξάνεται. Αν και η σχέση δεν είναι πολύ ισχυρή (υπάρχει αρκετή διασπορά), υπάρχει μια γενική ανοδική τάση που υποδηλώνει ότι η FoodQuality θα μπορούσε να βοηθήσει στην πρόβλεψη της Tip.
Με βάση το διάγραμμα διασποράς, πιστεύετε ότι θα μπορέσουμε να απορρίψουμε τελικά το κενό μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Ναι
Το διάγραμμα διασποράς δείχνει μια θετική τάση μεταξύ FoodQuality και Tip. Αν και η σχέση δεν είναι πολύ ισχυρή, η ανοδική τάση υποδηλώνει ότι το μοντέλο με την FoodQuality θα εξηγεί αρκετή μεταβλητότητα ώστε να μπορέσουμε να απορρίψουμε το κενό μοντέλο.
Μοντελοποίηση της Μεταβλητότητας στα Φιλοδωρήματα ως Συνάρτηση της Ποιότητας Φαγητού
Χρησιμοποιήστε το παρακάτω τμήμα κώδικα για να προσαρμόσετε ένα μοντέλο παλινδρόμησης στο οποίο η FoodQuality χρησιμοποιείται για να εξηγήσει την Tip.
Call:
lm(formula = Tip ~ FoodQuality, data = TipExperiment)
Coefficients:
(Intercept) FoodQuality
10.0979 0.3778
Ποια είναι η εκτίμηση για το \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — 0.38
Ανάγνωση της εξόδου:
Στο μοντέλο παλινδρόμησης Tip ~ FoodQuality:
(Intercept) = 10.11 → Αυτό είναι το \(b_0\), ο σταθερός όρος
FoodQuality = 0.38 → Αυτό είναι το \(b_1\), η κλίση
Ερμηνεία του \(b_1 = 0.38\):
Για κάθε αύξηση 1 μονάδας στη βαθμολογία ποιότητας φαγητού, το φιλοδώρημα αυξάνεται κατά μέσο όρο κατά 0.38 ποσοστιαίες μονάδες.
Πως ερμηνεύεται η τιμή του \(b_1\);
Μια αύξηση 0.38 ποσοστιαίων μονάδων στο φιλοδώρημα για κάθε επιπλέον μονάδα αύξησης στη FoodQuality δεν φαίνεται να είναι πολύ μεγάλη. Στην πραγματικότητα, φαίνεται να είναι αρκετά κοντά στο 0. Είναι πιθανό αυτή η τιμή να έχει προκύψει από μια ΔΠΔ στην οποία δεν υπάρχει επίδραση της ποιότητας φαγητού, δηλαδή μια ΔΠΔ όπου \(\beta_1 = 0\); Ή, μπορούμε να απορρίψουμε το κενό μοντέλο υπέρ ενός μοντέλου στο οποίο η FoodQuality επηρεάζει την Tip;
Αξιολόγηση του Κενού Μοντέλου της ΔΠΔ
Ακριβώς όπως κάναμε με το μοντέλο της Condition, μπορούμε να χρησιμοποιήσουμε τη συνάρτηση shuffle() για να προσομοιώσουμε την περίπτωση όπου το κενό μοντέλο είναι αληθές (δηλαδή όπου η πραγματική τιμή της κλίσης στη ΔΠΔ είναι 0), να δημιουργήσουμε μια δειγματοληπτική κατανομή των τιμών \(b_1\) με τυχαία ανακατέματα της Tip, και στη συνέχεια να χρησιμοποιήσουμε τη δειγματοληπτική κατανομή για να υπολογίσουμε την πιθανότητα μια τιμή \(b_1\) τόσο ακραία όσο το 0.38 να έχει δημιουργηθεί από το κενό μοντέλο.
Παρακάτω έχουμε γράψει κώδικα για να δημιουργήσουμε ξανά το διάγραμμα διασποράς. Έχουμε προσθέσει τη συνάρτηση shuffle() γύρω από την εξαρτημένη μεταβλητή (Tip) για να δημιουργήσουμε ένα δείγμα τυχαία ανακατεμένων δεδομένων από το κενό μοντέλο της ΔΠΔ. Στη συνέχεια, χρησιμοποιούμε τη συνάρτηση gf_lm() για να σχεδιάσουμε στο διάγραμμα την προσαρμοσμένη ευθεία παλινδρόμησης.
Εκτελέστε τον κώδικα μερικές φορές απλά για να δείτε τι είδους κλίσεις (\(b_1\)) δημιουργούνται από αυτή τη ΔΠΔ.
Στο παραπάνω διάγραμμα, τα πραγματικά δεδομένα από τη μελέτη των φιλοδωρημάτων εμφανίζονται με μπλε χρώμα (το διάγραμμα διασποράς επάνω αριστερά) μαζί με την καλύτερα προσαρμοσμένη ευθεία παλινδρόμησης (η κλίση της είναι 0.38). Τα άλλα πέντε διαγράμματα (με κόκκινα σημεία) έχουν προκύψει από πέντε τυχαία ανακατέματα, όπως και οι προσαρμοσμένες ευθείες παλινδρόμησης τους.
Τι παρατηρείτε σχετικά με τις κλίσεις στα τυχαία ανακατεμένα δεδομένα (με κόκκινο) που δημιουργήθηκαν από το κενό μοντέλο όπου \(\beta_1 = 0\); (Επιλέξτε όλα όσα ισχύουν)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Γ, Δ, Ε
Γιατί αυτές είναι σωστές:
Γ & Δ: Τα τυχαία ανακατεμένα δεδομένα προέρχονται από μια ΔΠΔ όπου \(\beta_1 = 0\). Επομένως, οι κλίσεις τείνουν να είναι κοντά στο 0 (πιο οριζόντιες) σε σύγκριση με τα πραγματικά δεδομένα που έχουν κλίση 0.38.
Ε: Λόγω της τυχαίας δειγματοληψίας, ακόμα κι όταν \(\beta_1 = 0\), οι δειγματικές κλίσεις \(b_1\) ποικίλλουν — κάποιες τυχαίνει να είναι θετικές, κάποιες αρνητικές, και κάποιες πολύ κοντά στο μηδέν.
Γιατί οι άλλες είναι λάθος:
Α: Οι κλίσεις δεν είναι όλες ίδιες — υπάρχει δειγματοληπτική μεταβλητότητα.
Β: Οι κλίσεις δεν είναι πιο απότομες — είναι πιο επίπεδες επειδή προέρχονται από μια ΔΠΔ με \(\beta_1 = 0\).
Αν η κλίση είναι μια τέλεια οριζόντια γραμμή (π.χ., επίπεδη), ποια θα ήταν η τιμή του \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — 0
Η λογική:
Η κλίση (\(b_1\)) μετρά πόσο αλλάζει το Y για κάθε μονάδα αλλαγής στο X.
Οριζόντια γραμμή: Το Y δεν αλλάζει καθόλου καθώς το X αλλάζει
Καμία αλλαγή σημαίνει κλίση = 0
Αυτός είναι ακριβώς ο λόγος που το κενό μοντέλο έχει \(\beta_1 = 0\) — υποθέτει ότι η ανεξάρτητη μεταβλητή δεν έχει καμία επίδραση στην εξαρτημένη μεταβλητή.
Από τα ανακατεμένα δεδομένα, είδαμε ότι πολλές από τις ευθείες παλινδρόμησης είναι πιο επίπεδες από την ευθεία για τα πραγματικά δεδομένα. Αυτό είναι λογικό δεδομένου ότι προσομοιώνουμε μια ΔΠΔ στην οποία \(\beta_1 = 0\) — θα περιμέναμε πολλές από τις τιμές \(b_1\) να είναι κοντά στο 0. Τώρα ας δημιουργήσουμε μια δειγματοληπτική κατανομή των τιμών \(b_1\) χρησιμοποιώντας τη συνάρτηση b1().
Συμπληρώστε την πρώτη γραμμή κώδικα παρακάτω για να δημιουργήσετε μια δειγματοληπτική κατανομή 1000 τιμών \(b_1\) (sdob1) από το μοντέλο της FoodQuality προσαρμοσμένο στα τυχαία ανακατεμένα δεδομένα. Έχουμε προσθέσει επιπλέον κώδικα για να δημιουργήσουμε ένα ιστόγραμμα της δειγματοληπτικής κατανομής των τιμών \(b_1\) και να αναπαραστήσουμε τη δειγματική τιμή \(b_1\) με μια μαύρη κουκκίδα.
Τι σημαίνει ότι η δειγματική μας τιμή \(b_1\) (0.38, η μαύρη κουκκίδα) βρίσκεται στη δεξιά ουρά της δειγματοληπτικής κατανομής; (Επιλέξτε όλα όσα ισχύουν.)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Β, Γ
Γιατί αυτές είναι σωστές:
Α: Η μαύρη κουκκίδα (\(b_1 = 0.38\)) βρίσκεται στη δεξιά ουρά, πέρα από τις περισσότερες τιμές \(b_1\) που δημιουργήθηκαν από τυχαίο ανακάτεμα.
Β & Γ: Επειδή η δειγματική μας τιμή \(b_1\) βρίσκεται στην ακραία περιοχή, είναι απίθανο να έχει παραχθεί από μια ΔΠΔ όπου \(\beta_1 = 0\) (το κενό μοντέλο).
Γιατί η Δ είναι λάθος:
Η δειγματοληπτική κατανομή δεν μας λέει τίποτα για το πού βρίσκεται η «πραγματική ΔΠΔ» — μας δείχνει μόνο τι θα περιμέναμε αν το κενό μοντέλο ήταν αληθές.
Απλά κοιτάζοντας αυτή τη δειγματοληπτική κατανομή, ποια νομίζετε ότι μπορεί να είναι η τιμή \(p\) από τη supernova();
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Κοντά στο 0
Η λογική:
Κοιτάζοντας το ιστόγραμμα:
Η μαύρη κουκκίδα (\(b_1 = 0.38\)) βρίσκεται στην δεξιά ουρά (δεξί άκρο της δειγματοληπτικής κατανομής)
Πολύ λίγες τιμές \(b_1\) από τα τυχαία ανακατέματα είναι τόσο ακραίες
Η τιμή \(p\) είναι η αναλογία των τιμών που είναι τόσο ακραίες ή πιο ακραίες από αυτήν που παρατηρήσαμε
Αυτή η αναλογία φαίνεται να είναι πολύ μικρή — κοντά στο 0
Αυτό υποδηλώνει ότι θα μπορέσουμε να απορρίψουμε το κενό μοντέλο και να συμπεράνουμε ότι η FoodQuality πιθανώς έχει πραγματική επίδραση στην Tip.
Από αυτή τη δειγματοληπτική κατανομή μπορούμε να δούμε ότι μια τιμή τόσο ακραία όσο το 0.38 πέφτει ακριβώς έξω από την περιοχή της δειγματοληπτικής κατανομής που θεωρούμε πιθανή. Μπορεί να νομίζαμε ότι μια αύξηση 0.38 ποσοστιαίων μονάδων ανά μία μονάδα αύξησης στην ποιότητα φαγητού ήταν κοντά στο 0, αλλά δεν είναι μία από τις πιθανές τιμές \(b_1\) που δημιουργούνται από μια ΔΠΔ όπου το πραγματικό \(\beta_1\) είναι 0! Αυτό υποδηλώνει ότι η τιμή \(p\) θα είναι σχετικά μικρή.
Για να βεβαιωθούμε, ας ρίξουμε μια ματιά στην τιμή \(p\) από τον πίνακα ANOVA.
Analysis of Variance Table (Type III SS)
Model: Tip ~ FoodQuality
SS df MS F PRE p
----- --------------- | -------- -- ------- ----- ----- -----
Model (error reduced) | 525.576 1 525.576 4.428 .0954 .0414
Error (from model) | 4985.401 42 118.700
----- --------------- | -------- -- ------- ----- ----- -----
Total (empty model) | 5510.977 43 128.162
Η τιμή \(p\) είναι περίπου 0.04. Υπάρχει μόνο 4% πιθανότητα η παρατηρούμενη τιμή \(b_1 = 0.38\) να είχε προκύψει απλώς λόγω τυχαίας μεταβλητότητας αν το κενό μοντέλο της ΔΠΔ είναι αληθές.
Αυτή η δειγματοληπτική κατανομή των τιμών \(b_1\) μας λέει ότι αν το κενό μοντέλο της ΔΠΔ ήταν αληθές, το δείγμα μας είναι απίθανο να παρατηρηθεί. Δεδομένου ότι παρατηρήσαμε μια απίθανη τιμή στο δείγμα μας, θα απορρίψουμε το κενό μοντέλο της ΔΠΔ υπέρ ενός μοντέλου που περιλαμβάνει την ποιότητα φαγητού ως ανεξάρτητη μεταβλητή.
11.10 Ασκήσεις Επανάληψης Κεφαλαίου 11
Το πλαίσιο δεδομένων newborns περιέχει πληροφορίες για το βάρος γέννησης και την περίοδο κύησης για 500 νεογνά. Συλλέχθηκε ως μέρος μιας μελέτης του Υπουργείου Υγείας μιας χώρας τα έτη 1961 και 1962. Καταγράφηκαν επίσης πληροφορίες για τους γονείς του μωρού (ηλικία, εισόδημα, εκπαίδευση) και αν η μητέρα κάπνιζε.
Συγκεκριμένα, περιλαμβάνει 500 παρατηρήσεις με τις ακόλουθες μεταβλητές:
gestation διάρκεια κύησης (σε ημέρες)
wt βάρος γέννησης (σε ουγγιές)
age ηλικία της μητέρας σε έτη στο τέλος της εγκυμοσύνης
ed εκπαίδευση της μητέρας: λιγότερο από 8η τάξη, 8η-12η τάξη - δεν αποφοίτησε, απόφοιτος λυκείου - καμία άλλη εκπαίδευση, λύκειο + τεχνική σχολή, λύκειο + κάποιο πανεπιστήμιο, απόφοιτος πανεπιστημίου, τεχνική σχολή - λύκειο ασαφές
dage ηλικία του πατέρα (σε έτη)
ded εκπαίδευση του πατέρα (ίδια κωδικοποίηση με την εκπαίδευση της μητέρας)
income ετήσιο οικογενειακό εισόδημα σε δύο ομάδες: $0-12.500 ή $12.500-22.500
smoke καπνίζει η μητέρα; (ποτέ, ή τώρα)
1. Ας εξετάσουμε την υπόθεση ότι wt = smoke + άλλοι παράγοντες. Αν το κάπνισμα σχετίζεται με χαμηλότερα βάρη γέννησης, τι θα περιμέναμε;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Το \(b_1\) θα ήταν αρνητικό
Η λογική:
Στο μοντέλο wt ~ smoke:
Η μεταβλητή smoke έχει δύο επίπεδα: «ποτέ» και «τώρα»
Το \(b_1\) αναπαριστά τη διαφορά στο μέσο βάρος γέννησης μεταξύ των δύο ομάδων
Αν το κάπνισμα σχετίζεται με χαμηλότερα βάρη γέννησης:
Τα μωρά των καπνιστριών θα έχουν μικρότερο μέσο βάρος
Επομένως, το \(b_1\) (η διαφορά καπνίστριες - μη καπνίστριες) θα είναι αρνητικό
Σημείωση:
Το \(b_0\) αναπαριστά τον μέσο όρο της ομάδας αναφοράς (μη καπνίστριες), ο οποίος θα είναι θετικός (τα μωρά έχουν θετικό βάρος!).
2. Αν το κάπνισμα δεν έχει καμία επίδραση στα βάρη γέννησης στη ΔΠΔ, τι θα περιμέναμε;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Το \(\beta_1\) θα ήταν μηδέν
Η λογική:
Αν το κάπνισμα δεν έχει καμία επίδραση στα βάρη γέννησης στη ΔΠΔ:
Δεν θα υπήρχε διαφορά μεταξύ των μέσων βαρών γέννησης των δύο ομάδων
Η παράμετρος \(\beta_1\) (η πραγματική διαφορά στη ΔΠΔ) θα ήταν μηδέν
Αυτό είναι το κενό μοντέλο ή η μηδενική υπόθεση
Γιατί οι άλλες επιλογές είναι λάθος:
Β. \(\beta_0\) θα ήταν μηδέν: Το \(\beta_0\) είναι ο μέσος όρος της ομάδας αναφοράς — τα μωρά έχουν θετικό βάρος, άρα δεν θα ήταν μηδέν.
Γ. \(e_i\) θα ήταν μηδέν: Τα υπόλοιπα (\(e_i\)) αντιπροσωπεύουν την ατομική μεταβλητότητα — πάντα θα υπάρχει κάποια μεταβλητότητα.
Δ. \(b_0\) θα ήταν μηδέν: Το \(b_0\) είναι η δειγματική εκτίμηση του σταθερού όρου — θα είναι θετικό (μέσο βάρος μωρών).
3. Εκτελέστε κώδικα για να προσαρμόσετε το μοντέλο wt = smoke + άλλοι παράγοντες. Τι αναπαριστά η τιμή \(-9.76\) στο μοντέλο;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — \(b_1\)
Η λογική:
Όταν προσαρμόζουμε το μοντέλο wt ~ smoke, η R μας δίνει:
(Intercept): Ο μέσος όρος βάρους γέννησης για την ομάδα αναφοράς (μη καπνίστριες) — αυτό είναι το \(b_0\)
smokenow: Η διαφορά στο μέσο βάρος γέννησης μεταξύ καπνιστριών και μη καπνιστριών — αυτό είναι το \(b_1\)
Η τιμή \(-9.76\) είναι το \(b_1\) (η δειγματική εκτίμηση), που σημαίνει:
Τα μωρά των μητέρων που καπνίζουν έχουν κατά μέσο όρο \(9.76\) ουγγιές μικρότερο βάρος γέννησης από τα μωρά αυτών που ποτέ δεν υπήρξαν καπνίστριες.
Γιατί όχι \(\beta_1\);
Το \(\beta_1\) είναι η πραγματική παράμετρος στη ΔΠΔ (άγνωστη). Το \(b_1\) είναι η δειγματική εκτίμηση που υπολογίζουμε από τα δεδομένα μας.
4. Σύμφωνα με το προσαρμοσμένο μοντέλο wt = smoke + άλλοι παράγοντες, ποια θα ήταν η τιμή πρόβλεψης του βάρους για ένα νεογνό μιας μητέρας που δεν καπνίζει;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — 123 ουγγιές
Ο υπολογισμός:
Το μοντέλο είναι:
\[\hat{Y}_i = b_0 + b_1 \cdot X_i\]
Όπου:
\(b_0 = 123\) (το intercept, μέσος όρος για μη καπνίστριες)
\(b_1 = -9.76\) (η διαφορά για τις καπνίστριες)
\(X_i = 0\) για μη καπνίστριες, \(X_i = 1\) για καπνίστριες
Για μια μητέρα που δεν καπνίζει (\(X_i = 0\)):
\[\hat{Y}_i = 123 + (-9.76) \cdot 0 = 123\]
Η τιμή πρόβλεψης του βάρους είναι 123 ουγγιές.
Σημείωση:
Για μια μητέρα που καπνίζει (\(X_i = 1\)), η τιμή πρόβλεψης του βάρους θα ήταν:
5. Σύμφωνα με το προσαρμοσμένο μοντέλο wt = smoke + άλλοι παράγοντες, ποια θα ήταν η τιμή του \(X_i\) για ένα νεογνό που γεννήθηκε από μια μητέρα που δεν καπνίζει;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — \(X_i = 0\)
Η λογική:
Στα μοντέλα ομάδων, η R χρησιμοποιεί ψευδομεταβλητή κωδικοποίηση (dummy coding):
Η ομάδα αναφοράς (μη καπνίστριες / «ποτέ») κωδικοποιείται ως \(X_i = 0\)
Η άλλη ομάδα (καπνίστριες / «τώρα») κωδικοποιείται ως \(X_i = 1\)
Επομένως, για μια μητέρα που δεν καπνίζει, \(X_i = 0\).
Γιατί οι άλλες επιλογές είναι λάθος:
Α. \(X_i = 123\): Το 123 είναι το \(b_0\) (ο σταθερός όρος), όχι η τιμή του \(X_i\).
Β. \(X_i = -9.76\): Το \(-9.76\) είναι το \(b_1\) (η κλίση/διαφορά), όχι η τιμή του \(X_i\).
Γ. \(X_i = 1\): Αυτή θα ήταν η τιμή για μια μητέρα που καπνίζει, όχι για μη καπνίστρια.
6. Σύμφωνα με το προσαρμοσμένο μοντέλο wt = smoke + άλλοι παράγοντες, τι αναπαριστά το \(-9.76\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Τη μέση διαφορά στο βάρος των νεογνών που γεννήθηκαν από μητέρες που καπνίζουν σε σχέση με μητέρες που δεν καπνίζουν.
Η λογική:
Στο μοντέλο wt ~ smoke:
\(b_0 = 123\): Ο μέσος όρος βάρους για την ομάδα αναφοράς (μη καπνίστριες)
\(b_1 = -9.76\): Η διαφορά μεταξύ των δύο ομάδων
Το \(-9.76\) σημαίνει:
Τα νεογνά μητέρων που καπνίζουν έχουν κατά μέσο όρο \(9.76\) ουγγιές λιγότερο βάρος από τα νεογνά μητέρων που δεν καπνίζουν.
Γιατί οι άλλες επιλογές είναι λάθος:
Α: Το μέσο βάρος για μη καπνίστριες είναι το \(b_0 = 123\), όχι το \(-9.76\).
Γ: Το μέσο βάρος για καπνίστριες είναι \(b_0 + b_1 = 123 + (-9.76) = 113.24\) ουγγιές.
Δ: Το συνολικό μέσο βάρος όλων των νεογνών δεν είναι το \(-9.76\) (θα ήταν κάπου μεταξύ 113 και 123).
7. Αν οι ερευνητές είχαν συλλέξει ένα διαφορετικό δείγμα 500 νεογνών, ποια τιμή θα ήταν διαφορετική;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — Πιθανότατα, όλα τα παραπάνω
Η λογική:
Αν συλλέξουμε ένα διαφορετικό δείγμα από τον ίδιο πληθυσμό:
\(Y_i\) (τα βάρη γέννησης): Κάθε νεογνό στο νέο δείγμα θα έχει διαφορετικό βάρος — διαφορετικά άτομα, διαφορετικές τιμές.
\(b_1\) (η εκτιμώμενη διαφορά): Επειδή έχουμε διαφορετικά δεδομένα, η εκτίμηση της διαφοράς μεταξύ καπνιστριών και μη καπνιστριών θα είναι διαφορετική.
\(b_0\) (ο εκτιμώμενος μέσος της ομάδας αναφοράς): Ομοίως, ο μέσος όρος για τις μη καπνίστριες στο νέο δείγμα θα είναι διαφορετικός.
Σημαντική διάκριση:
Τι αλλάζει με νέο δείγμα
Τι παραμένει σταθερό
\(Y_i\), \(b_0\), \(b_1\) (δειγματικές τιμές)
\(\beta_0\), \(\beta_1\) (παράμετροι της ΔΠΔ)
Οι παράμετροι της ΔΠΔ (\(\beta_0\), \(\beta_1\)) είναι σταθερές — είναι η «αλήθεια» στον πληθυσμό. Οι δειγματικές εκτιμήσεις (\(b_0\), \(b_1\)) αλλάζουν από δείγμα σε δείγμα.
8. Στον παρακάτω κώδικα, τι κάνει η συνάρτηση shuffle() στο wt;
b1(shuffle(wt) ~ smoke, data = newborns)
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — Ανακατεύει τις τιμές στη στήλη wt.
Τι κάνει η shuffle():
Η συνάρτηση shuffle()ανακατεύει τυχαία τις τιμές της μεταβλητής που της δίνουμε:
Παίρνει όλες τις υπάρχουσες τιμές της wt (τα βάρη γέννησης)
Τις ανακατεύει τυχαία
Τις αντιστοιχίζει σε διαφορετικές γραμμές
Αποτέλεσμα: Η σχέση που υπήρχε μεταξύ wt και smokeσπάει — δηλαδή προσομοιώνουμε έναν κόσμο όπου δεν υπάρχει σχέση μεταξύ καπνίσματος μητέρας και βάρους γέννησης νεογνού (\(\beta_1 = 0\)).
Γιατί οι άλλες επιλογές είναι λάθος:
Α: Δεν δημιουργεί νέες τιμές — χρησιμοποιεί τις υπάρχουσες τιμές, απλώς τις ανακατεύει.
Β: Το αντίθετο — η shuffle()καταστρέφει οποιαδήποτε σχέση υπάρχει μεταξύ wt και smoke.
Γ: Δεν ανακατεύει τις γραμμές — ανακατεύει μόνο τις τιμές της μίας στήλης (wt).
9. Για να πάρουμε το παραπάνω ιστόγραμμα, εκτελέσαμε τον ακόλουθο κώδικα:
sdob1 <-do(1000) *b1(shuffle(wt) ~ smoke, data = newborns)gf_histogram(~b1, data = sdob1, fill =~middle(b1, .95))
Τι αναπαριστά η δειγματοληπτική κατανομή του \(b_1\); (επιλέξτε όλα όσα ισχύουν)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Β και Δ
Γιατί η Β είναι σωστή:
Η shuffle() καταστρέφει οποιαδήποτε σχέση μεταξύ wt και smoke, προσομοιώνοντας έναν κόσμο όπου \(\beta_1 = 0\). Το ιστόγραμμα δείχνει τι τιμές \(b_1\) θα περιμέναμε να δούμε τυχαία σε έναν τέτοιο κόσμο.
Γιατί η Δ είναι σωστή:
Ο κώδικας do(1000) * b1(shuffle(wt) ~ smoke, ...) δημιουργεί ακριβώς αυτό: 1000 τιμές \(b_1\), κάθε μία από ένα διαφορετικό τυχαίο δείγμα. Αυτή είναι η δειγματοληπτική κατανομή του \(b_1\) υπό το κενό μοντέλο.
Γιατί οι άλλες είναι λάθος:
Α: Η κατανομή δεν αποδεικνύει ότι \(\beta_1 = 0\) — απλώς δείχνει τι θα συνέβαινε αν\(\beta_1 = 0\). Χρησιμοποιούμε αυτή την κατανομή για να ελέγξουμε αν η υπόθεση \(\beta_1 = 0\) είναι εύλογη.
Γ: Δεν είναι 1000 βάρη μωρών — είναι 1000 τιμές \(b_1\) (διαφορές μεταξύ ομάδων), καθεμιά υπολογισμένη από ένα δείγμα που προέκυψε από τυχαίο ανακάτεμα.
10. Τι προσομοιώσαμε με τον κώδικα στην Ερώτηση 9; (επιλέξτε όλα όσα ισχύουν)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Γ, Ε
Γιατί αυτές είναι σωστές:
Και οι τρεις σωστές απαντήσεις περιγράφουν το ίδιο πράγμα με διαφορετικούς τρόπους:
Α: Περιγράφει το αποτέλεσμα — δεν υπάρχει διαφορά στο μέσο βάρος μεταξύ των δύο ομάδων.
Γ: Περιγράφει τη ΔΠΔ — δεν υπάρχει σχέση μεταξύ smoke και wt.
Ε: Περιγράφει την παράμετρο — \(\beta_1 = 0\) (η πραγματική διαφορά στη ΔΠΔ είναι μηδέν).
Η shuffle()σπάει τη σχέση μεταξύ wt και smoke, προσομοιώνοντας το κενό μοντέλο.
Γιατί οι άλλες είναι λάθος:
Β. «ΔΠΔ όπου \(\beta_1 = -9.76\)»: Το \(-9.76\) είναι το δειγματικό\(b_1\) που παρατηρήσαμε στα πραγματικά δεδομένα. Η προσομοίωση υποθέτει \(\beta_1 = 0\), όχι \(-9.76\).
Δ. «Μωρά καπνιστριών πιο πιθανό να έχουν χαμηλότερο βάρος»: Αυτό θα σήμαινε \(\beta_1 < 0\), αλλά η προσομοίωση υποθέτει \(\beta_1 = 0\) (καμία διαφορά).
11. Στο παραπάνω ιστόγραμμα, ποια από τις ακόλουθες τιμές του \(b_1\) θα θεωρούνταν «απίθανη»;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — \(b_1 = -5.2\)
Η λογική:
Στο ιστόγραμμα, οι τιμές χρωματίζονται με βάση τη συνάρτηση middle(b1, .95):
Μοβ (TRUE): Το μεσαίο 95% — τιμές που θεωρούνται «όχι απίθανες»
Γαλάζιο (FALSE): Οι ουρές (το ακραίο 5%) — τιμές που θεωρούνται «απίθανες»
Κοιτάζοντας το ιστόγραμμα:
Οι γαλάζιες ουρές ξεκινούν περίπου από \(-5\) και κάτω, και από \(+5\) και πάνω
Η τιμή \(-5.2\) βρίσκεται στην αριστερή γαλάζια ουρά — είναι «απίθανη»
Γιατί οι άλλες επιλογές είναι «όχι απίθανες»:
Α. \(b_1 = 2.5\): Βρίσκεται στη μοβ περιοχή (μεσαίο 95%)
Β. \(b_1 = -2.5\): Βρίσκεται στη μοβ περιοχή
Γ. \(b_1 = 0\): Βρίσκεται στο κέντρο της μοβ περιοχής — η πιο «πιθανή» τιμή!
12. Ποιο είναι το κενό μοντέλο της ΔΠΔ; (επιλέξτε όλα όσα ισχύουν)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α και Β
Γιατί αυτές είναι σωστές:
Και οι δύο περιγράφουν το κενό μοντέλο με διαφορετικούς τρόπους:
Α. \(Y_i = \beta_0 + e_i\): Αυτή είναι η εξίσωση του κενού μοντέλου — η εξαρτημένη μεταβλητή εξηγείται μόνο από τον σταθερό όρο (μέσο όρο) και το σφάλμα. Δεν υπάρχει ανεξάρτητη μεταβλητή.
Β. \(\beta_1 = 0\): Αυτό σημαίνει ότι η ανεξάρτητη μεταβλητή δεν έχει καμία επίδραση — η κλίση/διαφορά είναι μηδέν.
Γιατί οι άλλες είναι λάθος:
Γ. \(\beta_0 = 0\): Το \(\beta_0\) είναι ο μέσος όρος της ομάδας αναφοράς (ή ο σταθερός όρος). Δεν χρειάζεται να είναι μηδέν στο κενό μοντέλο.
Δ. \(\epsilon_i = 0\): Τα σφάλματα δεν είναι ποτέ όλα μηδέν — πάντα υπάρχει κάποια μεταβλητότητα που δεν εξηγείται από το μοντέλο.
13. Τι σημαίνει όταν \(\beta_1 = 0\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Δεν υπάρχει επίδραση της ανεξάρτητης μεταβλητής στην εξαρτημένη μεταβλητή στη ΔΠΔ.
Η λογική:
Το \(\beta_1\) είναι η παράμετρος της ΔΠΔ που αναπαριστά:
Σε μοντέλα ομάδων: την πραγματική διαφορά μεταξύ των ομάδων στον πληθυσμό
Σε μοντέλα παλινδρόμησης: την πραγματική κλίση στον πληθυσμό
Όταν \(\beta_1 = 0\), σημαίνει ότι στη ΔΠΔ (τον «πραγματικό κόσμο») δεν υπάρχει σχέση μεταξύ της ανεξάρτητης και της εξαρτημένης μεταβλητής.
Γιατί οι άλλες είναι λάθος:
Β: Αυτό θα ήταν \(b_1 = 0\) (δειγματική εκτίμηση), όχι \(\beta_1 = 0\) (παράμετρος ΔΠΔ).
Γ: Αυτό αφορά τα υπόλοιπα, όχι το \(\beta_1\).
Δ: Το \(\beta_1 = 0\) δεν είναι λάθος — είναι μια συγκεκριμένη υπόθεση για τη ΔΠΔ.
14. Αν παρατηρήσουμε το παραπάνω ιστόγραμμα, ποια θα ήταν η κατά προσέγγιση τιμή \(p\) για ένα δειγματικό \(b_1\) ίσο με \(-10\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — \(p < 0.05\)
Η λογική:
Κοιτάζοντας το ιστόγραμμα:
Η κατανομή εκτείνεται περίπου από \(-6\) έως \(+6\)
Η τιμή \(b_1 = -10\) είναι πολύ πιο αριστερά από οποιαδήποτε τιμή στην κατανομή
Βρίσκεται πολύ πέρα από την αριστερή γαλάζια ουρά (που αντιπροσωπεύει το 0.025)
Η τιμή \(p\) είναι η πιθανότητα να πάρουμε μια τιμή \(b_1\) τόσο ακραία ή πιο ακραία από -10. Επειδή το \(-10\) είναι πιο ακραίο από σχεδόν όλες τις προσομοιωμένες τιμές:
$\(p\) <$ 0.05
Στην πραγματικότητα, η τιμή \(p\) θα ήταν πολύ μικρότερη από 0.05 — πιθανώς κοντά στο 0.001 ή ακόμα μικρότερη.
Τι σημαίνει αυτό;
Μια τιμή \(b_1 = -10\) θα ήταν εξαιρετικά απίθανη να έχει παραχθεί από μια ΔΠΔ όπου \(\beta_1 = 0\). Θα απορρίπταμε σίγουρα το κενό μοντέλο.
15. Σύμφωνα με το κενό μοντέλο η τιμή του \(b_1\) κατά προσέγγιση θα είναι …;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — 0
Η λογική:
Το κενό μοντέλο υποθέτει ότι \(\beta_1 = 0\) στη ΔΠΔ — δηλαδή, ότι δεν υπάρχει σχέση μεταξύ της ανεξάρτητης και της εξαρτημένης μεταβλητής.
Αν το \(\beta_1 = 0\) είναι αληθές, τότε θα περιμέναμε οι δειγματικές εκτιμήσεις \(b_1\) να είναι κοντά στο 0 (με κάποια τυχαία μεταβλητότητα γύρω από το 0).
Αυτός είναι ο λόγος που η δειγματοληπτική κατανομή που δημιουργούμε με τη shuffle() είναι κεντραρισμένη στο 0.
16. Γιατί περιμένουμε οι τιμές στη δειγματοληπτική κατανομή του \(b_1\) να ποικίλλουν;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Επειδή προέρχονται όλες από μια τυχαία ΔΠΔ.
Η λογική:
Η δειγματοληπτική κατανομή δημιουργείται με τυχαίο ανακάτεμα (shuffling) των δεδομένων. Κάθε φορά που εκτελούμε τη shuffle(), παίρνουμε μια διαφορετική τυχαία αντιστοίχιση μεταξύ των τιμών της wt και της smoke.
Αυτή η τυχαιότητα στη διαδικασία παραγωγής δεδομένων (ΔΠΔ) είναι που δημιουργεί τη μεταβλητότητα στις τιμές \(b_1\).
Γιατί οι άλλες είναι λάθος:
Α: Το μέγεθος δείγματος παραμένει σταθερό (n = 500) σε κάθε ανακάτεμα.
Γ: Σίγουρα περιμένουμε μεταβλητότητα — αυτός είναι ο σκοπός της δειγματοληπτικής κατανομής!
Δ: Η μεταβλητότητα στην wt υπάρχει, αλλά δεν είναι αυτή που εξηγεί τη μεταβλητότητα στις τιμές \(b_1\) — είναι το τυχαίο ανακάτεμα.
17. Είναι δυνατόν να παρατηρηθεί μια τιμή \(b_1\) τόσο υψηλή όσο το 10 στην παραπάνω δειγματοληπτική κατανομή;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Είναι δυνατό, αλλά εξαιρετικά απίθανο.
Η λογική:
Η δειγματοληπτική κατανομή που βλέπουμε βασίζεται σε 1000 προσομοιώσεις. Δείχνει τις τιμές \(b_1\) που παρατηρήθηκαν σε αυτές τις 1000 επαναλήψεις.
Ωστόσο, η θεωρητική δειγματοληπτική κατανομή (με άπειρες επαναλήψεις) θα είχε ουρές που εκτείνονται απεριόριστα. Το ότι δεν βλέπουμε την τιμή 10 στις 1000 προσομοιώσεις μας δεν σημαίνει ότι είναι αδύνατο — απλώς είναι εξαιρετικά απίθανο.
Γιατί οι άλλες είναι λάθος:
Β: Το ότι η ουρά του ιστογράμματος δεν φτάνει στο 10 δεν σημαίνει ότι είναι αδύνατο. Με περισσότερες προσομοιώσεις, θα μπορούσαμε να δούμε πιο ακραίες τιμές.
Γ: Σίγουρα δεν είναι «εξαιρετικά πιθανό» — οι περισσότερες τιμές είναι κοντά στο 0.
Δ: Το ότι οι περισσότερες τιμές είναι γύρω από το μηδέν δεν καθιστά τις ακραίες τιμές αδύνατες — απλώς τις καθιστά σπάνιες.
18. Γράψτε κώδικα για να αξιολογήσετε το μοντέλο wt = smoke + άλλοι παράγοντες με έναν πίνακα ANOVA. Ερμηνεύστε την τιμή \(p\). Ποιο από τα παρακάτω είναι το σωστό;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — Υπάρχει λιγότερο από 0.05 πιθανότητα το δειγματικό μας \(b_1\) να προέρχεται από μια ΔΠΔ όπου \(\beta_1 = 0\).
Ο κώδικας:
supernova(lm(wt ~ smoke, data = newborns))
Το αποτέλεσμα θα δείξει:\(p < 0.05\) (και μάλιστα \(p < 0.001\))
Ερμηνεία της τιμής \(p\):
Η τιμή \(p\) μας λέει την πιθανότητα να παρατηρήσουμε ένα \(b_1\) τόσο ακραίο όσο το \(-9.76\) (ή πιο ακραίο) αν το κενό μοντέλο ήταν αληθές (δηλαδή, αν \(\beta_1 = 0\)).
Επειδή \(p < 0.001\):
Το δειγματικό μας \(b_1\) είναι απίθανο να έχει προκύψει από μια ΔΠΔ όπου \(\beta_1 = 0\)
Απορρίπτουμε το κενό μοντέλο
Συμπεραίνουμε ότι υπάρχει σχέση μεταξύ του αν η μητέρα καπνίζει και του βάρους γέννησης του νεογνού
Γιατί οι άλλες είναι λάθος:
Α: Αναφέρεται σε \(\beta_0 = 0\), αλλά ελέγχουμε αν \(\beta_1 = 0\).
Β & Γ: Η τιμή \(p\) δεν είναι η πιθανότητα το μοντέλο να είναι αληθές ή ψευδές — είναι η πιθανότητα να παρατηρήσουμε τα δεδομένα μας, αν ισχύει το κενό μοντέλο (μηδενική υπόθεση).
Το πλαίσιο δεδομένων top_50 περιέχει πληροφορίες για τα κορυφαία 50 τραγούδια του 2019 στην εφαρμογή Spotify.
track_name Το όνομα του τραγουδιού
artist_name Το όνομα του καλλιτέχνη
genre Το μουσικό είδος του τραγουδιού
bpm Οι παλμοί ανά λεπτό του τραγουδιού (tempo)
danceability Η χορευτικότητα του τραγουδιού: όσο υψηλότερη η τιμή, τόσο πιο εύκολο είναι να χορέψεις σε αυτό το τραγούδι
length Η διάρκεια του τραγουδιού (σε δευτερόλεπτα)
popularity Η δημοτικότητα του τραγουδιού: όσο υψηλότερη η τιμή, τόσο πιο δημοφιλές είναι το τραγούδι
1. Αν θέλαμε να χρησιμοποιήσουμε αυτά τα δεδομένα για να εξετάσουμε την επίδραση της χορευτικότητας στη μέση δημοτικότητα των τραγουδιών, τι θα προσπαθούσαμε να εκτιμήσουμε;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — το \(\beta_1\)
Η λογική:
Στο μοντέλο popularity ~ danceability:
\(\beta_1\) είναι η παράμετρος της ΔΠΔ που αναπαριστά την επίδραση της χορευτικότητας στη δημοτικότητα
Συγκεκριμένα, το \(\beta_1\) μας λέει πόσο αλλάζει η δημοτικότητα για κάθε μονάδα αύξησης στη χορευτικότητα στον πληθυσμό
Χρησιμοποιούμε τα δεδομένα μας για να υπολογίσουμε το \(b_1\) (τη δειγματική τιμή), το οποίο είναι η καλύτερη εκτίμησή μας για την άγνωστη παράμετρο \(\beta_1\).
Γιατί οι άλλες είναι λάθος:
Β. Τυπικό σφάλμα: Το τυπικό σφάλμα είναι η τυπική απόκλιση της δειγματοληπτικής κατανομής, όχι η ίδια η επίδραση.
Γ. \(\beta_0\): Το \(\beta_0\) είναι ο σταθερός όρος (η αναμενόμενη δημοτικότητα όταν η χορευτικότητα είναι 0), όχι η επίδραση της χορευτικότητας.
Δ. \(X_i\): Το \(X_i\) είναι η τιμή της χορευτικότητας για κάθε τραγούδι — είναι η ανεξάρτητη μεταβλητή, όχι η παράμετρος που εκτιμούμε.
2. Γράψτε κώδικα για να προσαρμόσετε ένα μοντέλο που διερευνά αυτή την υπόθεση: popularity = danceability + άλλοι παράγοντες. Επιλέξτε τη σωστή εξίσωση του μοντέλου (στρογγυλοποιημένη σε τρία δεκαδικά).
Για κάθε αύξηση 1 μονάδας στη χορευτικότητα, η δημοτικότητα αναμένεται να αυξηθεί κατά 0.027 μονάδες.
3. Ερμηνεύστε το \(b_1\) στο μοντέλο.
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — Το ποσό κατά το οποίο αναμένεται να αυξηθεί η δημοτικότητα ενός τραγουδιού καθώς η χορευτικότητα αυξάνεται κατά μία μονάδα.
Η λογική:
Στο μοντέλο παλινδρόμησης popularity ~ danceability:
Η δημοτικότητα (popularity) είναι η εξαρτημένη μεταβλητή (\(Y\))
Η χορευτικότητα (danceability) είναι η ανεξάρτητη μεταβλητή (\(X\))
Το \(b_1\) είναι η κλίση της ευθείας παλινδρόμησης, που μας λέει:
Πόσο αναμένεται να αλλάξει η δημοτικότητα* για κάθε μονάδα αύξησης στη χορευτικότητα**.
Με \(b_1\) = 0.027, για κάθε αύξηση 1 μονάδας στη χορευτικότητα, η δημοτικότητα αυξάνεται κατά 0.027 μονάδες.
Γιατί οι άλλες είναι λάθος:
Α: Αυτό περιγράφει το \(b_0\) (σταθερός όρος), όχι το \(b_1\).
Β: Αυτό αντιστρέφει τις μεταβλητές — η χορευτικότητα είναι η ανεξάρτητη, όχι η εξαρτημένη.
Γ: Αυτό επίσης αντιστρέφει τη σχέση — προβλέπουμε τη δημοτικότητα από τη χορευτικότητα, όχι το αντίστροφο.
4. Είναι η δειγματική τιμή \(b_1\) η πραγματική τιμή \(\beta_1\) στη ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Δεν μπορούμε να είμαστε σίγουροι για την πραγματική τιμή της \(\beta_1\) στη ΔΠΔ.
Η λογική:
Η θεμελιώδης διάκριση είναι:
Σύμβολο
Τι είναι
Γνωστό;
\(b_1\)
Δειγματική εκτίμηση
Ναι — το υπολογίζουμε από τα δεδομένα
\(\beta_1\)
Παράμετρος της ΔΠΔ
Όχι — είναι άγνωστη
Το \(b_1\) είναι η καλύτερη εκτίμησή μας για το \(\beta_1\), αλλά:
Κάθε δείγμα θα έδινε διαφορετικό \(b_1\)
Δεν μπορούμε ποτέ να ξέρουμε με βεβαιότητα την πραγματική τιμή \(\beta_1\)
Μπορούμε μόνο να εφαρμόσουμε τους κανόνες της στατιστικής συμπερασματολογίας για το άγνωστο \(\beta_1\) με βάση το γνωστό \(b_1\)
Γιατί οι άλλες είναι λάθος:
Β & Γ: Το μέγεθος δείγματος και το τυπικό σφάλμα επηρεάζουν την ακρίβεια της εκτίμησης, αλλά ακόμα και με τέλειο δείγμα, το \(b_1\) δεν είναι ακριβώς ίσο με το \(\beta_1\).
Δ: Ακόμα και με μεγάλο δείγμα, δεν μπορούμε να είμαστε σίγουροι — μπορούμε μόνο να είμαστε πιο ακριβείς.
5. Γιατί μπορεί να είναι χρήσιμο να υπολογίσουμε τιμές \(b_1\) από πολλά τυχαία δείγματα που προέρχονται από το κενό μοντέλο της ΔΠΔ;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — Επειδή η δειγματοληπτική κατανομή που προκύπτει θα μας δώσει μια ιδέα για το πόσο θα μπορούσαν να ποικίλλουν οι δειγματικές τιμές \(b_1\) από μια τυχαία ΔΠΔ.
Η λογική:
Η δειγματοληπτική κατανομή από το κενό μοντέλο (όπου \(\beta_1 = 0\)) μας δείχνει:
Τι τιμές \(b_1\) θα περιμέναμε να δούμε μόνο από τύχη
Πόσο μεταβλητές είναι αυτές οι τιμές
Αν το πραγματικό μας \(b_1\) είναι ασυνήθιστο σε σχέση με αυτές τις τυχαίες τιμές
Αυτό μας επιτρέπει να αποφασίσουμε αν το δειγματικό μας \(b_1\) θα μπορούσε να έχει προκύψει από τύχη ή αν υποδηλώνει πραγματική σχέση.
Γιατί οι άλλες είναι λάθος:
Α: Ο μέσος της κατανομής από το κενό μοντέλο θα είναι περίπου 0 — δεν μας λέει το πραγματικό \(\beta_1\).
Β: Η κανονικότητα της δειγματοληπτικής κατανομής δεν αποδεικνύει τίποτα για τον πληθυσμό.
Γ: Δεν προσπαθούμε να προσαρμόσουμε καμπύλη στη δειγματική κατανομή.
Το παραπάνω ιστόγραμμα δημιουργήθηκε με τον ακόλουθο κώδικα:
sdob1 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_50)gf_histogram(~b1, data = sdob1, fill =~middle(b1, .95))
6. Ποια από τις παρακάτω δηλώσεις είναι αληθής για το τυπικό σφάλμα της κατανομής του \(b_1\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — Το τυπικό σφάλμα μετρά πόσο μεταβάλλεται το \(b_1\) από δείγμα σε δείγμα.
Η λογική:
Η κατανομή δειγματοληψίας που κατασκευάσαμε με do(1000) * shuffle(...) δείχνει τι τιμές θα παίρναμε για το \(b_1\) αν επαναλαμβάναμε τη διαδικασία πολλές φορές. Το τυπικό σφάλμα είναι απλώς η τυπική απόκλιση αυτής της κατανομής — δηλαδή ένα μέτρο της αβεβαιότητας της εκτίμησής μας.
Μέτρο
Τι μετρά
Τυπική απόκλιση της popularity
Πόσο διαφέρουν μεταξύ τους οι τιμές δημοτικότητας στο δείγμα
Τυπικό σφάλμα του \(b_1\)
Πόσο θα μεταβαλλόταν η εκτίμηση για το \(b_1\) αν είχαμε διαφορετικό δείγμα
Τα δύο αυτά μεγέθη δεν είναι συγκρίσιμα — μετρούν διαφορετικά πράγματα σε διαφορετικές μονάδες.
7. Αν στοιβάζατε όλες τις μπάρες του ιστογράμματος τη μία πάνω στην άλλη, ποια θα ήταν η συνολική συχνότητα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — 1.000
Η λογική:
Κοιτάζοντας τον κώδικα:
sdob1 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_50)
Η συνάρτηση do(1000) εκτελεί το τυχαίο ανακάτεμα 1000 φορές, δημιουργώντας 1000 τιμές \(b_1\).
Κάθε μπάρα στο ιστόγραμμα αναπαριστά ένα διάστημα τιμών που περιέχει κάποιες από αυτές τις 1000 τιμές. Αν στοιβάξουμε όλες τις μπάρες:
Α: Το ιστόγραμμα μετρά πόσες τιμές \(b_1\) υπάρχουν σε κάθε διάστημα τιμών, όχι το άθροισμα των τιμών τους.
Β. 50: Το 50 είναι ο αριθμός των τραγουδιών στο αρχικό σύνολο δεδομένων (top_50), όχι ο αριθμός των προσομοιώσεων.
Γ. 95: Το 95 σχετίζεται με το middle(b1, .95) που χρωματίζει το μεσαίο 95% της κατανομής, αλλά δεν είναι το πλήθος.
8. Παρόλο που η δειγματική τιμή \(b_1\) δεν είναι μηδέν, είναι δυνατό να προήλθε από μια ΔΠΔ όπου \(\beta_1 = 0\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Ναι, επειδή ακόμα κι αν \(\beta_1 = 0\), η ΔΠΔ μπορεί να παράγει δείγματα όπου το \(b_1\) δεν είναι μηδέν.
Η λογική:
Αυτή είναι η θεμελιώδης ιδέα της δειγματοληπτικής μεταβλητότητας!
Ακόμα κι όταν η πραγματική παράμετρος \(\beta_1 = 0\) στη ΔΠΔ:
Κάθε δείγμα θα δώσει μια διαφορετική εκτίμηση \(b_1\)
Αυτές οι εκτιμήσεις θα ποικίλλουν γύρω από το 0
Μερικές θα είναι θετικές, μερικές αρνητικές
Σπάνια θα είναι ακριβώς 0
Αυτός είναι ο λόγος που δημιουργούμε τη δειγματοληπτική κατανομή — για να δούμε τι τιμές \(b_1\) είναι «φυσιολογικές» όταν \(\beta_1 = 0\), ώστε να μπορούμε να κρίνουμε αν η δική μας τιμή \(b_1\) είναι ασυνήθιστη.
Παράδειγμα από το ιστόγραμμα:
Κοιτάζοντας το ιστόγραμμα της ερώτησης 6, βλέπουμε ότι ακόμα κι όταν το κενό μοντέλο (\(\beta_1 = 0\)) είναι αληθές, οι τιμές \(b_1\) κυμαίνονται από περίπου \(-0.15\) έως \(+0.20\). Καμία από αυτές δεν είναι ακριβώς 0!
Το παραπάνω ιστόγραμμα δημιουργήθηκε με τον ακόλουθο κώδικα:
sdob1 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_50)gf_histogram(~b1, data = sdob1, fill =~middle(b1, .95))
9. Εκτελέστε κώδικα για να πάρετε το δειγματικό \(b_1\) για το μοντέλο popularity = danceability + άλλοι παράγοντες. Είναι η δειγματική τιμή \(b_1\) μία από τις «πιθανές» τιμές \(b_1\) στο παραπάνω ιστόγραμμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Ναι, πέφτει μέσα στο μεσαίο 95% των τιμών \(b_1\).
Η λογική:
Από την ερώτηση 2, γνωρίζουμε ότι η δειγματική τιμή \(b_1 = 0.027\).
Κοιτάζοντας το ιστόγραμμα:
Η μοβ περιοχή (μεσαίο 95%) εκτείνεται περίπου από -0.10 έως +0.12
Η τιμή 0.027 βρίσκεται μέσα σε αυτό το εύρος
Επομένως, το δειγματικό \(b_1\) θεωρείται «πιθανό» ή «όχι απίθανο»
Τι σημαίνει αυτό;
Η τιμή \(b_1 = 0.027\)θα μπορούσε να έχει προκύψει από μια ΔΠΔ όπου \(\beta_1 = 0\)
Δεν μπορούμε να απορρίψουμε το κενό μοντέλο
Η χορευτικότητα μπορεί να μην έχει πραγματική επίδραση στη δημοτικότητα
10. Αν το δειγματικό \(b_1\) είναι μία από τις «πιθανές» τιμές \(b_1\) στη δειγματοληπτική κατανομή, τι υποδηλώνει αυτό για τη ΔΠΔ; (επιλέξτε όλα όσα ισχύουν)
ΣημείωσηΕπεξήγηση
Σωστές απαντήσεις: Α, Β, Γ
Γιατί αυτές είναι σωστές:
Και οι τρεις πρώτες επιλογές λένε το ίδιο πράγμα με διαφορετικούς τρόπους:
Α: «Δεν υπάρχει επίδραση της χορευτικότητας στη δημοτικότητα» = \(\beta_1 = 0\)
Β: Απευθείας αναφορά στο \(\beta_1 = 0\)
Γ: «Το κενό μοντέλο είναι αληθές» = \(\beta_1 = 0\)
Αν το δειγματικό μας \(b_1\) πέφτει στο μεσαίο 95% της δειγματοληπτικής κατανομής που δημιουργήθηκε υποθέτοντας \(\beta_1 = 0\), τότε:
Το δείγμα μας είναι συμβατό με την υπόθεση ότι \(\beta_1 = 0\).
Γιατί η Δ είναι λάθος:
Η δειγματοληπτική κατανομή δημιουργήθηκε υποθέτοντας ότι δεν υπάρχει επίδραση (\(\beta_1 = 0\)). Αν το δείγμα μας ταιριάζει σε αυτή την κατανομή, δεν έχουμε λόγο να πιστεύουμε ότι υπάρχει επίδραση.
Σημαντική σημείωση:
Αυτό δεν αποδεικνύει ότι \(\beta_1 = 0\). Απλώς σημαίνει ότι το κενό μοντέλο παραμένει εύλογο — δεν μπορούμε να το απορρίψουμε με βάση τα δεδομένα μας.
11. Όταν χρησιμοποιούμε τη συνάρτηση shuffle() για να δημιουργήσουμε μια δειγματοληπτική κατανομή τιμών \(b_1\), γιατί η κατανομή είναι κεντραρισμένη γύρω από το μηδέν;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Επειδή προσομοιώνουμε μια ΔΠΔ όπου δεν υπάρχει επίδραση της χορευτικότητας στη δημοτικότητα.
Η λογική:
Η συνάρτηση shuffle()ανακατεύει τις τιμές της εξαρτημένης μεταβλητής (popularity), σπάζοντας οποιαδήποτε σύνδεση με την ανεξάρτητη μεταβλητή (danceability).
Αυτό προσομοιώνει μια ΔΠΔ όπου:
\(\beta_1 = 0\) (το κενό μοντέλο είναι αληθές)
Η χορευτικότητα δεν έχει καμία επίδραση στη δημοτικότητα
Οποιαδήποτε παρατηρούμενη σχέση οφείλεται μόνο στην τύχη
Επειδή \(\beta_1 = 0\), οι τιμές \(b_1\) που υπολογίζονται από τα τυχαία ανακατεμένα δεδομένα θα κυμαίνονται γύρω από το 0.
Γιατί οι άλλες είναι λάθος:
Α: Αν προσομοιώναμε το σύνθετο μοντέλο (όπου \(\beta_1 \neq 0\)), η κατανομή θα ήταν κεντραρισμένη σε μια μη μηδενική τιμή.
Γ: Δεν προσομοιώνουμε τα δειγματικά μας δεδομένα — προσομοιώνουμε μια υποθετική ΔΠΔ χωρίς επίδραση.
Δ: Η ΔΠΔ που προσομοιώνουμε δεν έχει «μηδενική πιθανότητα» — είναι απλώς μια υπόθεση που ελέγχουμε.
12. Εκτελέστε τον παρακάτω κώδικα για να αξιολογήσετε το μοντέλο popularity = danceability + άλλοι παράγοντες με έναν πίνακα ANOVA. Ερμηνεύστε την τιμή \(p\).
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — Υπάρχει μικρότερη από 5% πιθανότητα το δειγματικό μας \(b_1\) να προέρχεται από μια ΔΠΔ όπου \(\beta_1 = 0\).
Ο πίνακας ANOVA δείχνει:\(p \approx 0.62\)
Ερμηνεία:
Η τιμή \(p\) = 0.6221 σημαίνει:
Υπάρχει περίπου 62% πιθανότητα να παρατηρήσουμε μια τιμή \(b_1\) τόσο ακραία (ή πιο ακραία) από το 0.027 αν το κενό μοντέλο (\(\beta_1\) = 0) είναι αληθές
Επειδή \(p\) = 0.62 > 0.05$, η δειγματική μας τιμή \(b_1\) είναι «όχι απίθανη»
Δεν απορρίπτουμε το κενό μοντέλο
Δεν έχουμε αρκετές ενδείξεις για να ισχυριστούμε ότι η χορευτικότητα επηρεάζει τη δημοτικότητα
Γιατί οι άλλες είναι λάθος:
Α: Αυτό θα ίσχυε αν \(p < 0.05\), αλλά \(p = 0.62\).
Β & Δ: Η τιμή \(p\)δεν είναι η πιθανότητα ένα μοντέλο να είναι αληθές. Είναι η πιθανότητα να παρατηρήσουμε τα δεδομένα μας αν ισχύει το κενό μοντέλο (μηδενική υπόθεση).
Το παραπάνω ιστόγραμμα δημιουργήθηκε με τον ακόλουθο κώδικα:
sdob1 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_50)gf_histogram(~b1, data = sdob1, fill =~middle(b1, .95))
13. Τι αναπαριστά η χρωματισμένη περιοχή στις δύο εξωτερικές ουρές;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Το \(\alpha\)
Η λογική:
Ο κώδικας fill = ~middle(b1, .95) χρωματίζει:
Μοβ: Το μεσαίο 95% της κατανομής (τιμές «όχι απίθανες»)
Γαλάζιο (ουρές): Το εξωτερικό 5% της κατανομής (τιμές «απίθανες»)
Οι δύο ουρές μαζί αναπαριστούν το \(\alpha\) = 0.05:
Αριστερή ουρά: 0.025 (2.5%)
Δεξιά ουρά: 0.025 (2.5%)
Σύνολο: 0.05 (5%)
Το \(\alpha\) είναι το προκαθορισμένο κριτήριο που χρησιμοποιούμε για να αποφασίσουμε αν μια τιμή είναι «απίθανη».
Διάκριση \(\alpha\) vs \(p\):
\(\alpha\)
Τιμή \(p\)
Τι είναι
Προκαθορισμένο κριτήριο
Υπολογισμένη πιθανότητα
Πότε ορίζεται
Πριν τη μελέτη
Μετά τη μελέτη
Tιμή
0.05
Εξαρτάται από τα δεδομένα
Στο ιστόγραμμα
Οι σταθερές ουρές
Η περιοχή πέρα από τη δειγματική τιμή \(b_1\)
Τα παραπάνω ιστογράμματα δημιουργήθηκαν με τον παρακάτω κώδικα:
sdob1 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_50)# Ιστόγραμμα 1gf_histogram(~b1, data = sdob1, bins =80, fill =~middle(b1, .95)) %>%gf_labs(title ="Histogram 1")# Ιστόγραμμα 2gf_histogram(~b1, data = sdob1, bins =80, fill =~middle(b1, .80)) %>%gf_labs(title ="Histogram 2")
14. Σε ποιο ιστόγραμμα αντιστοιχεί το μεγαλύτερο επίπεδο σημαντικότητας \(\alpha\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Γ — Ιστόγραμμα 2
Η λογική:
Η συνάρτηση middle(b1, x) χρωματίζει το μεσαίο x% της κατανομής με μοβ. Οι ουρές (γαλάζιο) αναπαριστούν το \(\alpha\).
Ιστόγραμμα
middle()
Μεσαίο (μοβ)
Ουρές (alpha)
1
middle(b1, .95)
95%
5% (\(\alpha = 0.05\))
2
middle(b1, .80)
80%
20% (\(\alpha = 0.20\))
Το Ιστόγραμμα 2 έχει \(\alpha = 0.20\), που είναι μεγαλύτερο από το \(\alpha = 0.05\) του Ιστογράμματος 1.
Οπτική επιβεβαίωση:
Κοιτάζοντας τα ιστογράμματα, το Ιστόγραμμα 2 έχει μεγαλύτερη γαλάζια περιοχή στις ουρές — αυτό αντιστοιχεί σε μεγαλύτερο \(\alpha\).
15. Ποιο είναι το επίπεδο \(\alpha\) για το Ιστόγραμμα 2;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Ε — 0.20
Η λογική:
Στο Ιστόγραμμα 2, ο κώδικας χρησιμοποιεί middle(b1, .80):
Η μοβ περιοχή = το μεσαίο 80% της κατανομής
Οι γαλάζιες ουρές = το υπόλοιπο = 20%
\[\alpha = 1 - 0.80 = 0.20\]
Γενικός κανόνας:
Αν middle(b1, x) χρωματίζει το μεσαίο x% με μοβ, τότε:
\[\alpha = 1 - x\]
middle()
Μεσαία περιοχή
\(\alpha\)
middle(b1, .95)
95%
\(1 - 0.95 = 0.05\)
middle(b1, .90)
90%
\(1 - 0.90 = 0.10\)
middle(b1, .80)
80%
\(1 - 0.80 = 0.20\)
Το παραπάνω ιστόγραμμα δημιουργήθηκε με τον ακόλουθο κώδικα:
sdob1 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_50)gf_histogram(~b1, data = sdob1, fill =~middle(b1, .95))
16. Ποιο δειγματικό \(b_1\) θα αντιστοιχούσε σε μεγαλύτερη τιμή \(p\): \(b_1 = 0.05\) ή \(b_1 = 0.5\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Δ — Το \(b_1 = 0.05\) θα αντιστοιχούσε σε μεγαλύτερη τιμή \(p\).
Η λογική:
Η τιμή \(p\) είναι η πιθανότητα να πάρουμε μια τιμή \(b_1\)τόσο ακραία ή πιο ακραία από την παρατηρούμενη, αν το κενό μοντέλο είναι αληθές.
Κοιτάζοντας το ιστόγραμμα:
\(b_1 = 0.05\): Βρίσκεται κοντά στο κέντρο της κατανομής (κοντά στο 0). Πολλές τιμές από την προσομοίωση είναι τόσο ακραίες ή πιο ακραίες → μεγάλη τιμή \(p\).
\(b_1 = 0.5\): Βρίσκεται πολύ μακριά από το κέντρο, πέρα από τη δεξιά ουρά. Σχεδόν καμία τιμή από την προσομοίωση δεν είναι τόσο ακραία → πολύ μικρή τιμή \(p\).
Γενικός κανόνας:
Όσο πιο κοντά στο 0 είναι το \(b_1\), τόσο μεγαλύτερη η τιμή \(p\). Όσο πιο μακριά από το 0 είναι το \(b_1\), τόσο μικρότερη η τιμή \(p\).
Το παραπάνω ιστόγραμμα δημιουργήθηκε με τον ακόλουθο κώδικα:
sdob1 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_50)gf_histogram(~b1, data = sdob1, fill =~middle(b1, .95))
17. Αν παίρναμε ένα δείγμα μόνο 25 τραγουδιών από το πλαίσιο δεδομένων top_50 και δημιουργούσαμε ένα νέο ιστόγραμμα, τι θα άλλαζε στο ιστόγραμμα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Το τυπικό σφάλμα θα ήταν μεγαλύτερο.
Η λογική:
Το μέγεθος δείγματος επηρεάζει το τυπικό σφάλμα (το πλάτος της δειγματοληπτικής κατανομής):
Μέγεθος δείγματος
Τυπικό σφάλμα
Πλάτος κατανομής
Μεγαλύτερο (π.χ. 50)
Μικρότερο
Στενότερη
Μικρότερο (π.χ. 25)
Μεγαλύτερο
Πλατύτερη
Με μικρότερο δείγμα (25 αντί για 50 τραγούδια):
Οι τιμές \(b_1\) θα ποικίλλουν περισσότερο από δείγμα σε δείγμα
Το ιστόγραμμα θα είναι πλατύτερο (μεγαλύτερο τυπικό σφάλμα)
Θα ήταν πιο δύσκολο να απορρίψουμε το κενό μοντέλο
Γιατί οι άλλες είναι λάθος:
Α: Το ιστόγραμμα θα παραμείνει κεντραρισμένο στο 0 — αυτό δεν αλλάζει επειδή ακόμα προσομοιώνουμε το κενό μοντέλο (\(\beta_1 = 0\)).
Γ: Το μέγεθος δείγματος σίγουρα επηρεάζει το τυπικό σφάλμα.
Δ: Το αντίθετο — μικρότερο δείγμα σημαίνει μεγαλύτερο τυπικό σφάλμα.
Τα παραπάνω ιστογράμματα δημιουργήθηκαν με τον παρακάτω κώδικα:
# Ιστόγραμμα 1sdob1 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_50)gf_histogram(~b1, data = sdob1, bins=100, fill =~middle(b1, .95)) %>%gf_labs(title ="top_50")# Ιστόγραμμα 2top_10 <-sample(top_50, 10)sdob1_2 <-do(1000) *b1(shuffle(popularity) ~ danceability, data = top_10)gf_histogram(~b1, data = sdob1_2, bins =100, fill =~middle(b1, .95)) %>%gf_labs(title ="top_10")
18. Το Ιστόγραμμα 2 είναι μια δειγματοληπτική κατανομή που δημιουργήθηκε από ένα δείγμα 10 τραγουδιών από το πλαίσιο δεδομένων top_50. Τι ισχύει για τα ιστογράμματα;
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Β — Το τυπικό σφάλμα είναι μικρότερο για το ιστόγραμμα top_50 από ό,τι για το ιστόγραμμα top_10.
Η λογική:
Κοιτάζοντας τα δύο ιστογράμματα:
top_50 (n = 50): Η κατανομή είναι στενότερη — εκτείνεται περίπου από \(-0.15\) έως \(+0.15\)
top_10 (n = 10): Η κατανομή είναι πλατύτερη — εκτείνεται περίπου από \(-0.25\) έως \(+0.25\)
Γενικός κανόνας:
Μέγεθος δείγματος
Τυπικό σφάλμα
Πλάτος κατανομής
Μεγαλύτερο (50)
Μικρότερο
Στενότερη
Μικρότερο (10)
Μεγαλύτερο
Πλατύτερη
Γιατί οι επιλογές Γ και Δ είναι λάθος:
Το επίπεδο alpha είναι το ίδιο και για τα δύο ιστογράμματα (\(\alpha = 0.05\)), επειδή και τα δύο χρησιμοποιούν middle(b1, .95). Το \(\alpha\) είναι επιλογή του ερευνητή, όχι κάτι που επηρεάζεται από το μέγεθος δείγματος.
19. Ποια από αυτές τις κατανομές θα μπορούσε να σας οδηγήσει να διαπράξετε Σφάλμα Τύπου Ι για ένα δείγμα με \(b_1\) ίσο με \(0{.}11\);
ΣημείωσηΕπεξήγηση
Σωστή απάντηση: Α — Η κατανομή top_50
Τι είναι το Σφάλμα Τύπου Ι;
Σφάλμα Τύπου Ι συμβαίνει όταν απορρίπτουμε το κενό μοντέλο ενώ είναι αληθές. Αυτό μπορεί να συμβεί μόνο αν η δειγματική τιμή \(b_1\) πέφτει στην «απίθανη» περιοχή (τις γαλάζιες ουρές).
Ανάλυση για \(b_1 = 0{,}11\):
Κοιτάζοντας τα δύο ιστογράμματα:
top_50 (στενότερη κατανομή): Η τιμή \(0{.}11\) βρίσκεται στη γαλάζια ουρά (εκτός του μεσαίου 95%). Θα απορρίψουμε το κενό μοντέλο → μπορεί να γίνει Σφάλμα Τύπου Ι.
top_10 (πλατύτερη κατανομή): Η τιμή \(0{.}11\) βρίσκεται μέσα στη μοβ περιοχή (μεσαίο 95%). Δεν θα απορρίψουμε το κενό μοντέλο → δεν μπορεί να γίνει Σφάλμα Τύπου Ι.
Γιατί αυτό έχει σημασία:
Το μεγαλύτερο δείγμα (top_50) έχει στενότερη κατανομή, που σημαίνει:
Είναι πιο εύκολο να απορρίψουμε το κενό μοντέλο
Αλλά αν το κενό μοντέλο είναι αληθές, υπάρχει κίνδυνος Σφάλματος Τύπου Ι
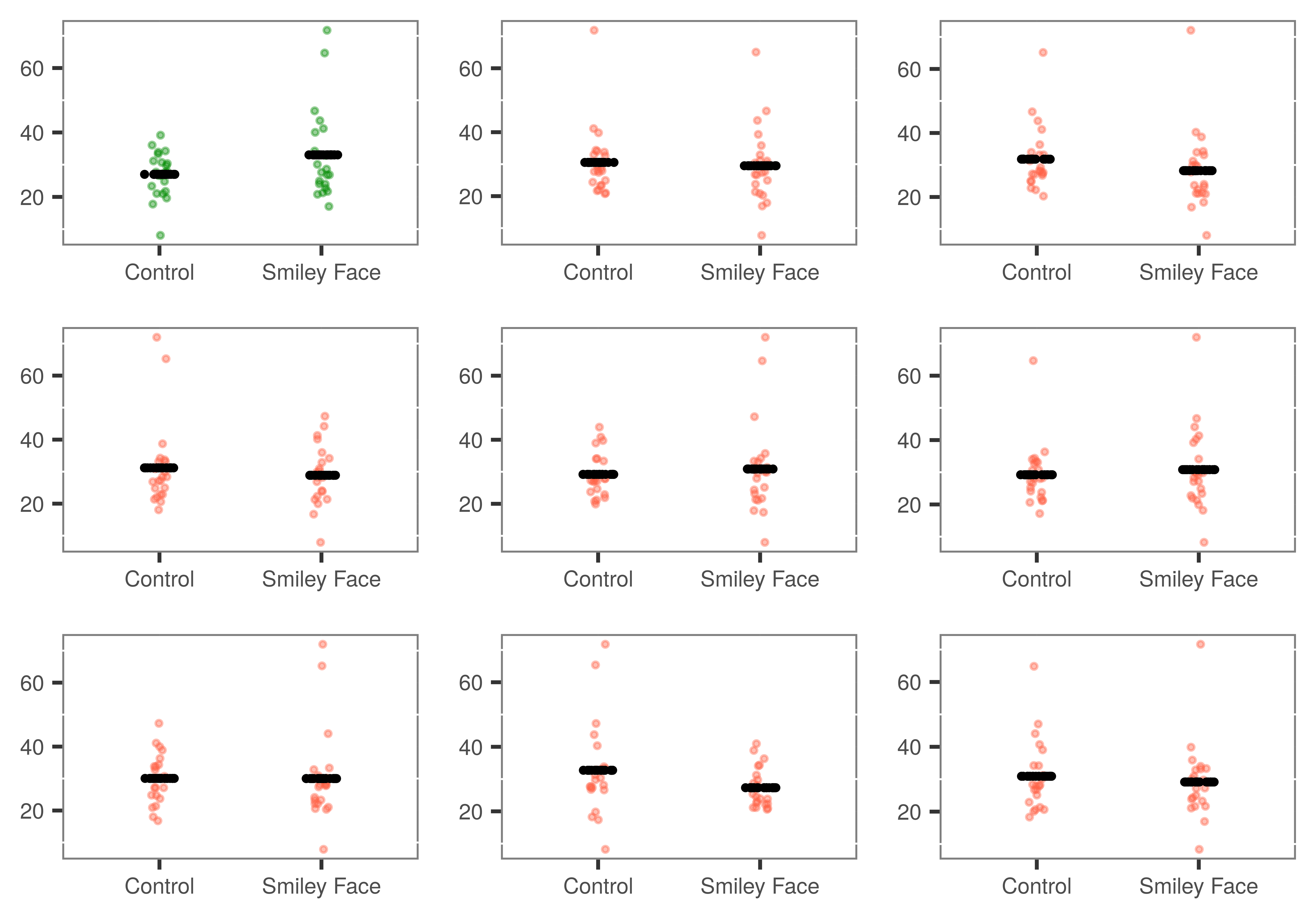
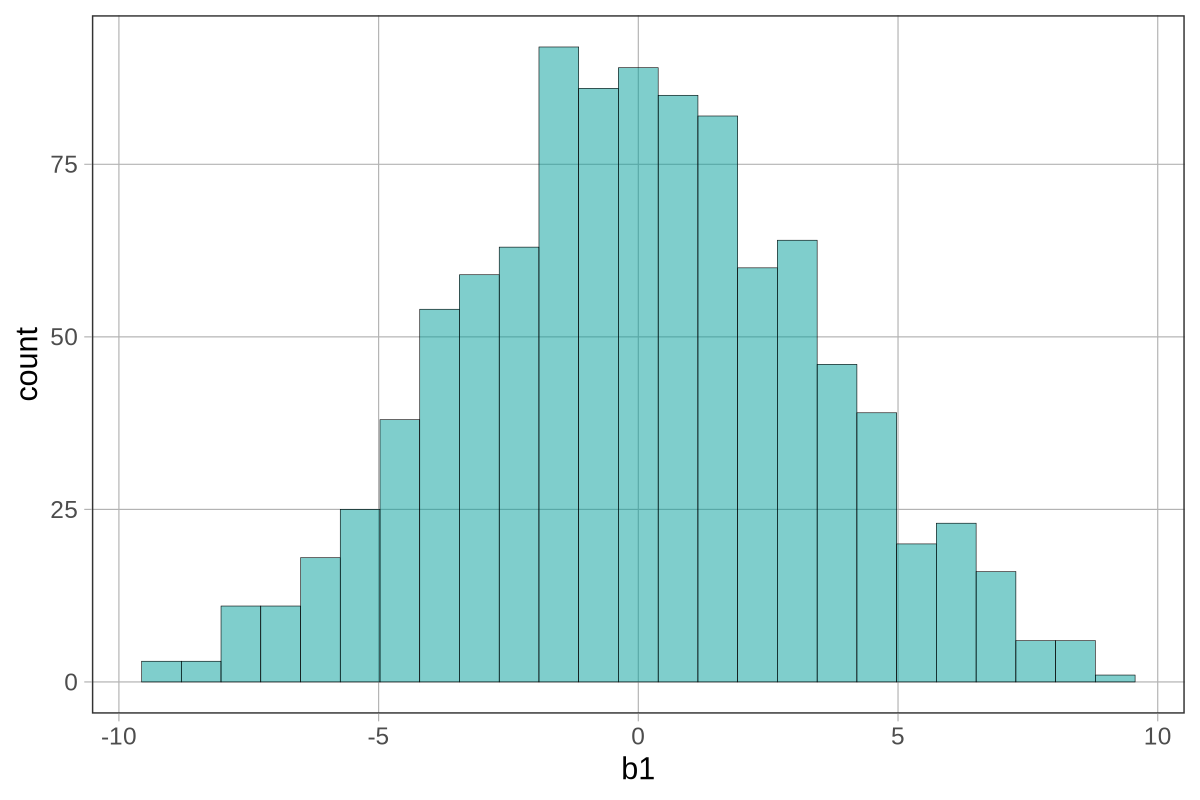
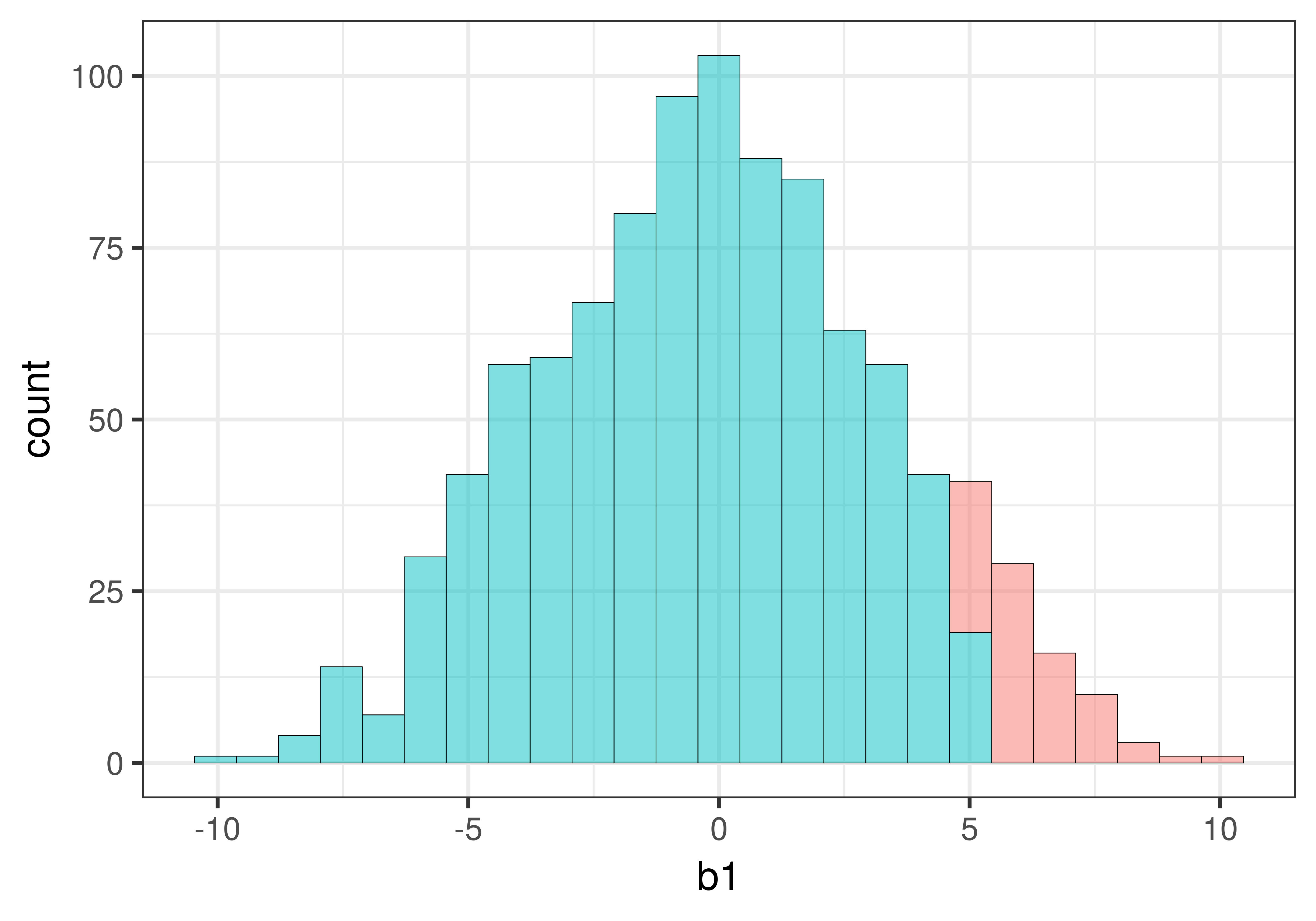
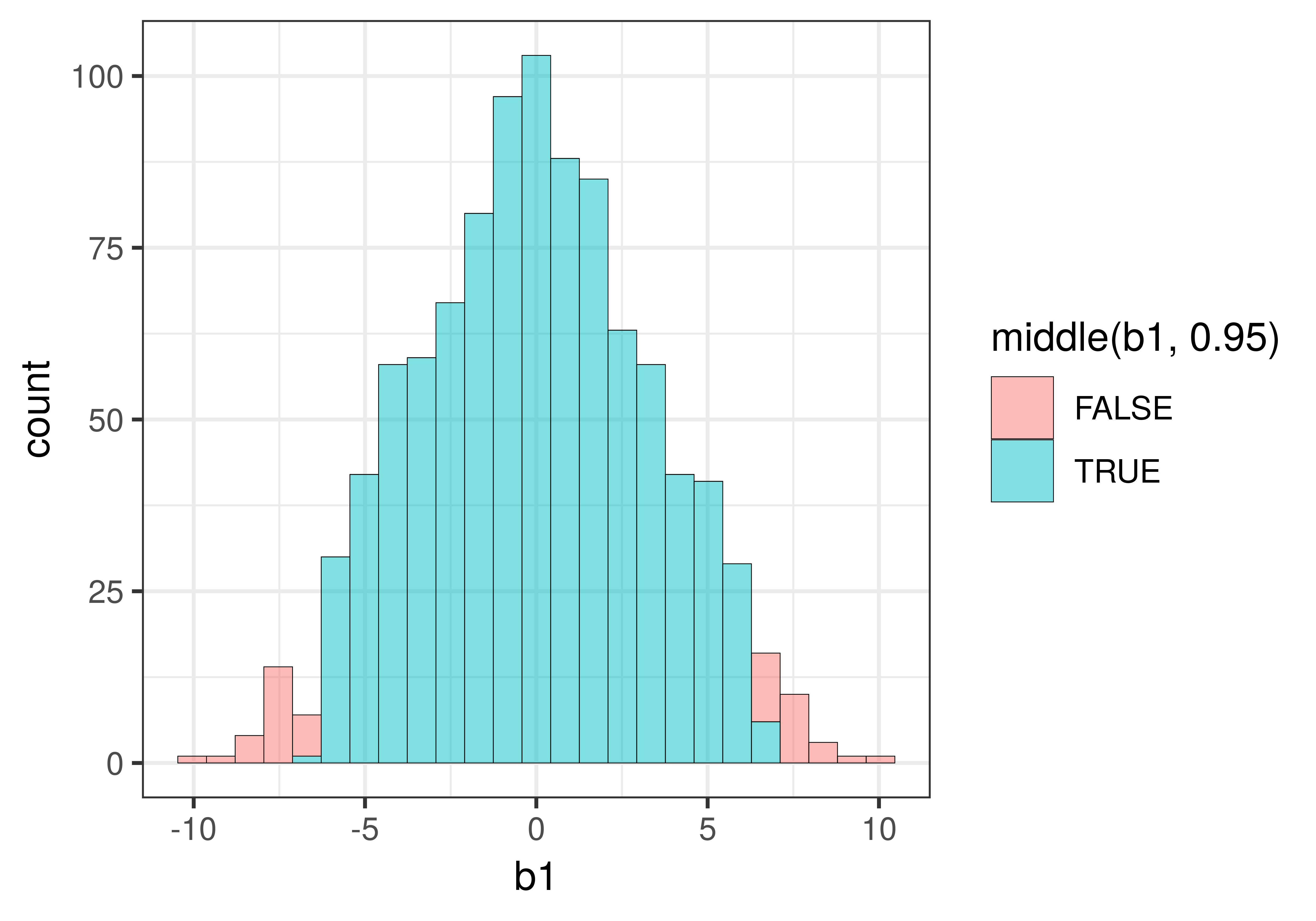
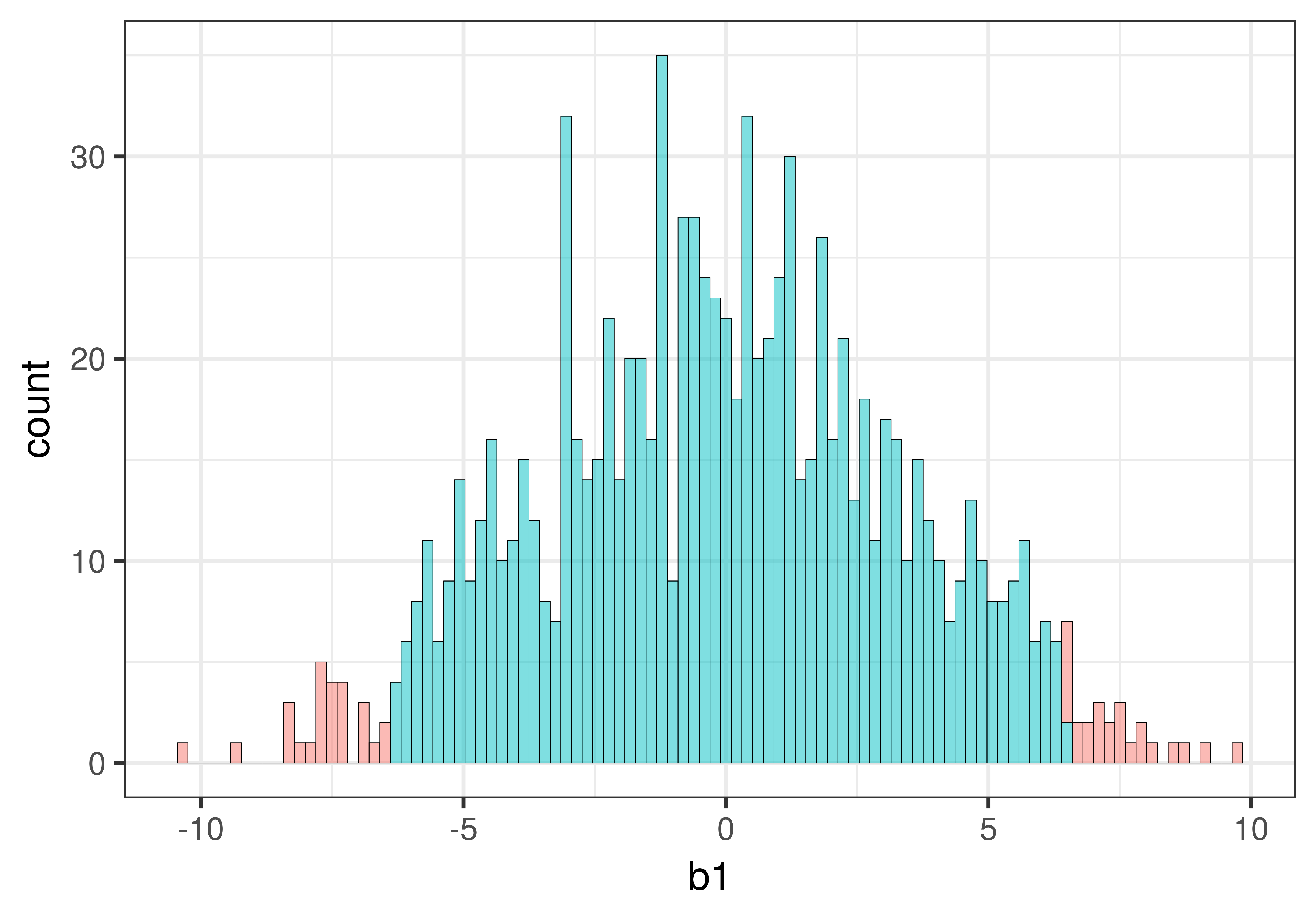 Η αύξηση του αριθμού των διαστημάτων τιμών είχε ως αποτέλεσμα κάθε διάστημα να αντιπροσωπεύεται από ένα μόνο χρώμα. Αλλά δημιούργησε και κάποια κενά στο ιστόγραμμα, δηλαδή άδεια διαστήματα τιμών στα οποία δεν βρέθηκε καμία από τις τιμές
Η αύξηση του αριθμού των διαστημάτων τιμών είχε ως αποτέλεσμα κάθε διάστημα να αντιπροσωπεύεται από ένα μόνο χρώμα. Αλλά δημιούργησε και κάποια κενά στο ιστόγραμμα, δηλαδή άδεια διαστήματα τιμών στα οποία δεν βρέθηκε καμία από τις τιμές 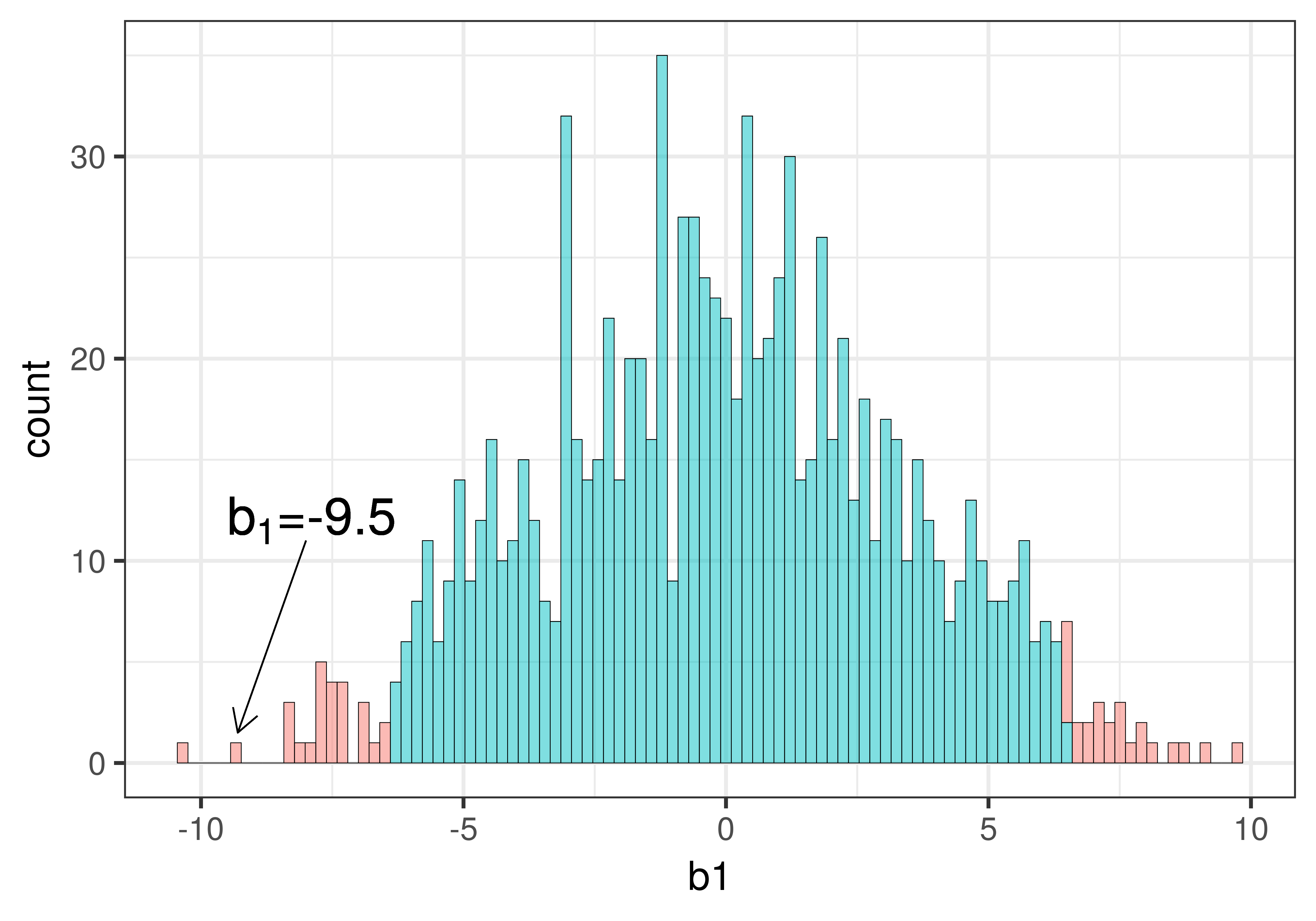
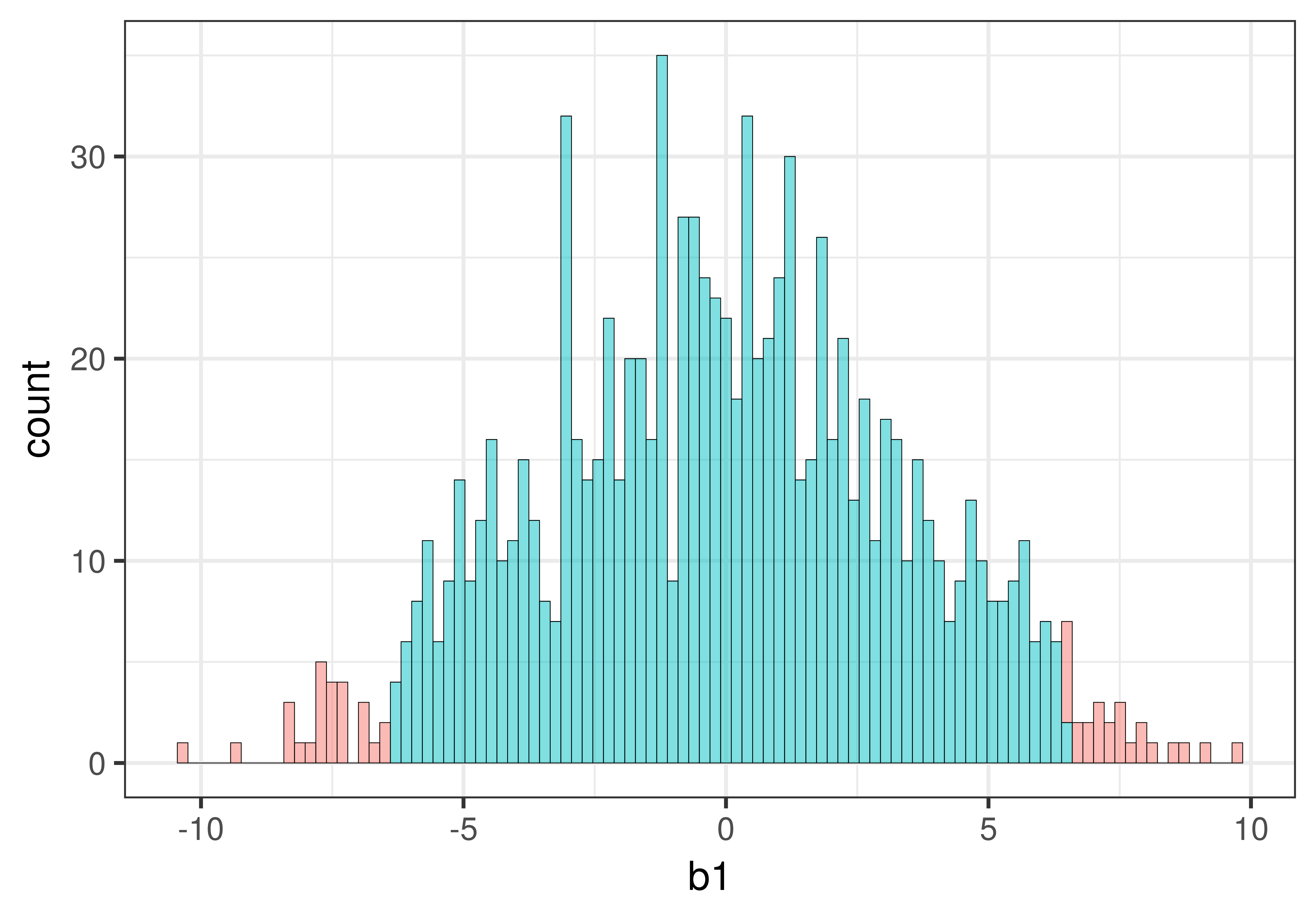
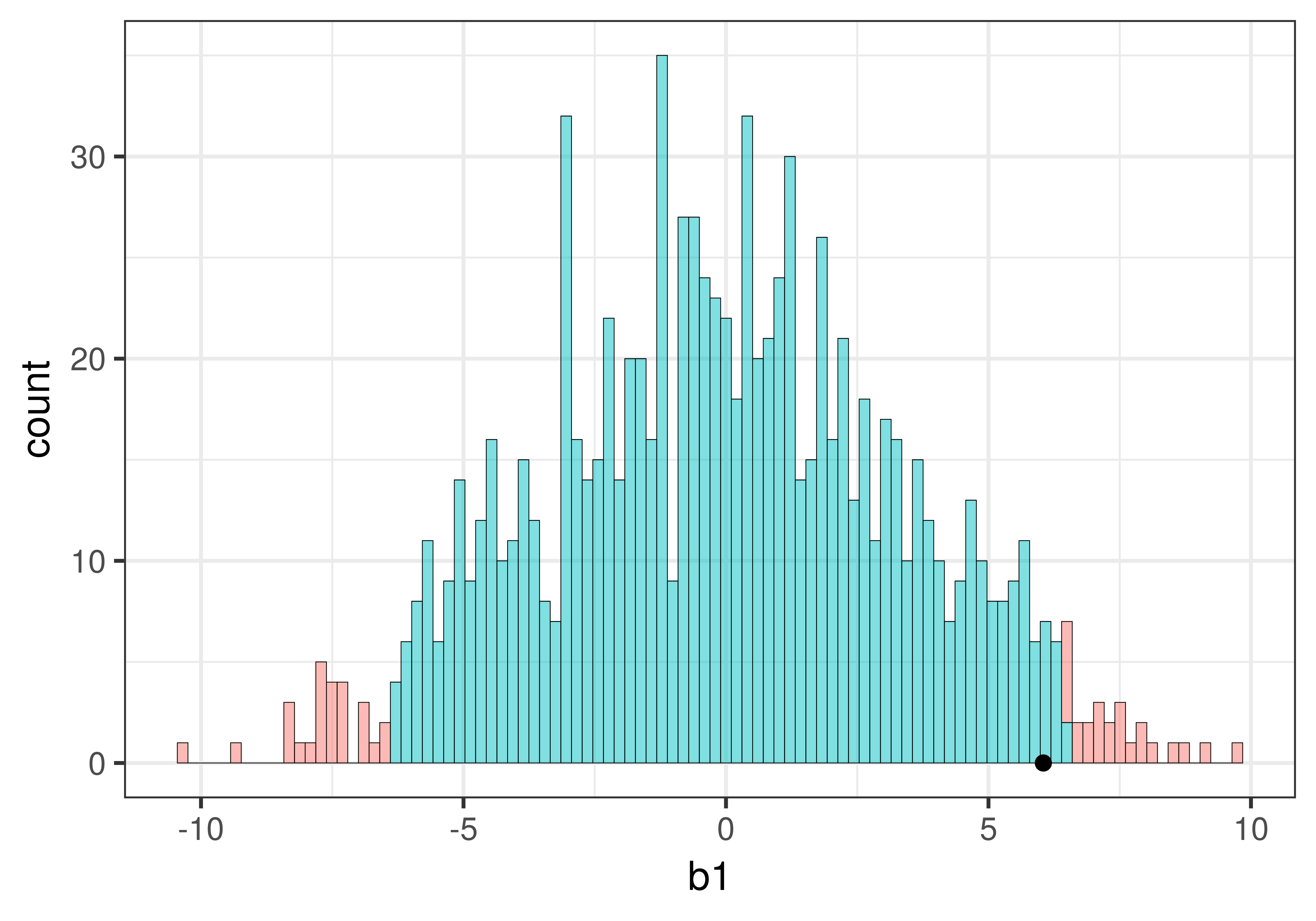
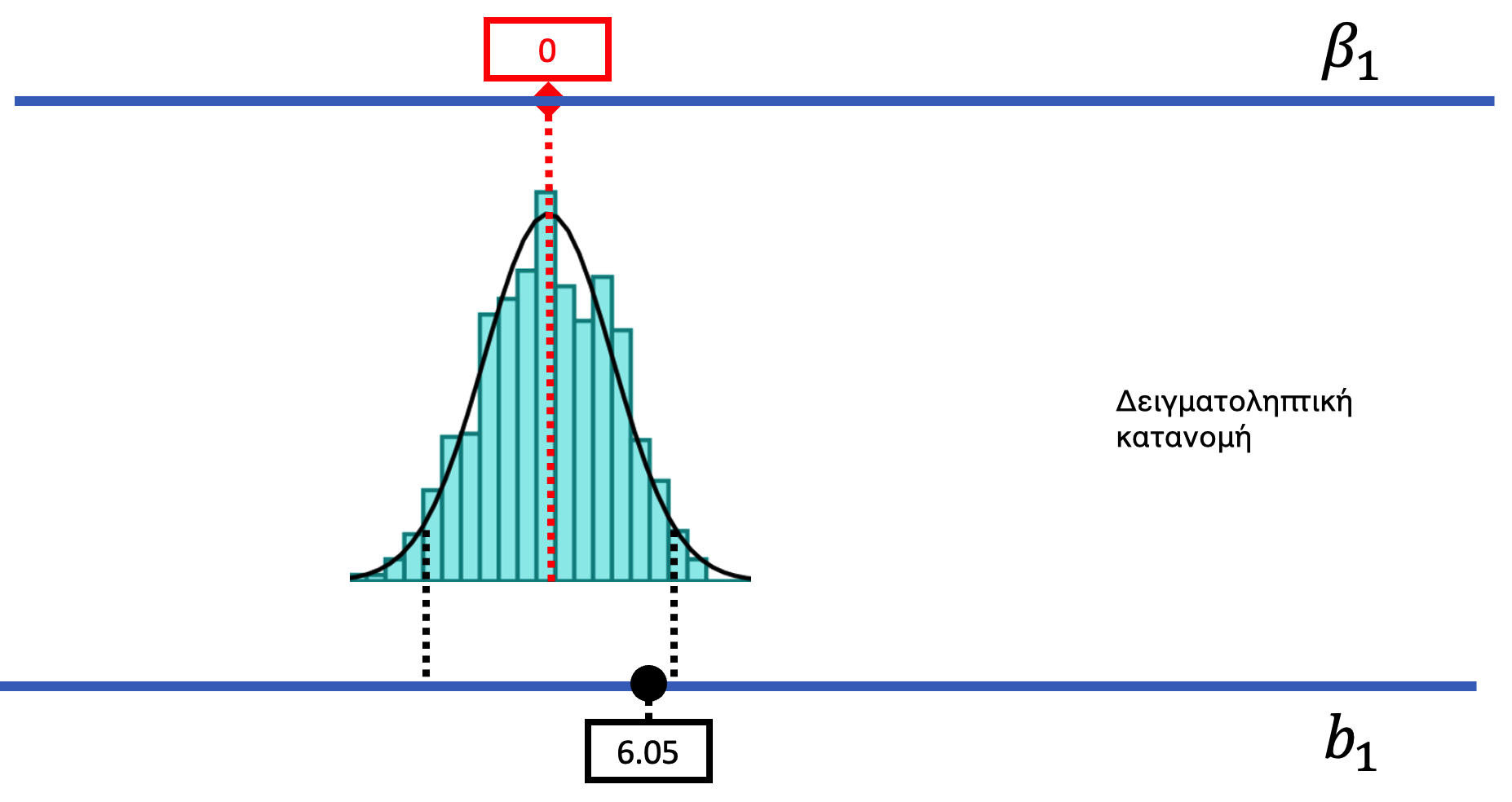 Με βάση αυτή την υποθετική ΔΠΔ, προσομοιώσαμε δείγματα που δημιουργήθηκαν από τυχαία ανακατέματα των δεδομένων του πειράματος των φιλοδωρημάτων. Αυτές οι δειγματικές τιμές
Με βάση αυτή την υποθετική ΔΠΔ, προσομοιώσαμε δείγματα που δημιουργήθηκαν από τυχαία ανακατέματα των δεδομένων του πειράματος των φιλοδωρημάτων. Αυτές οι δειγματικές τιμές 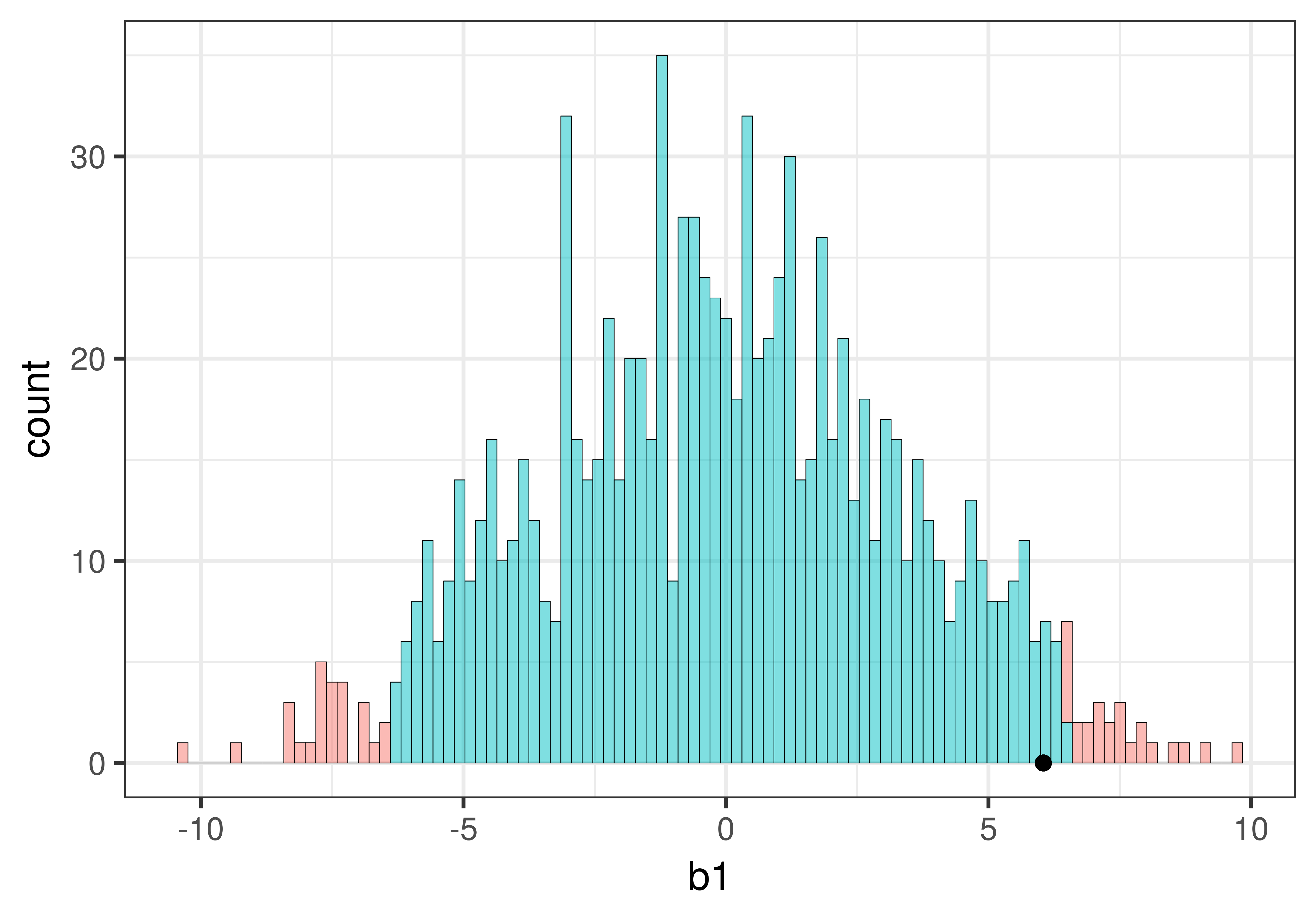
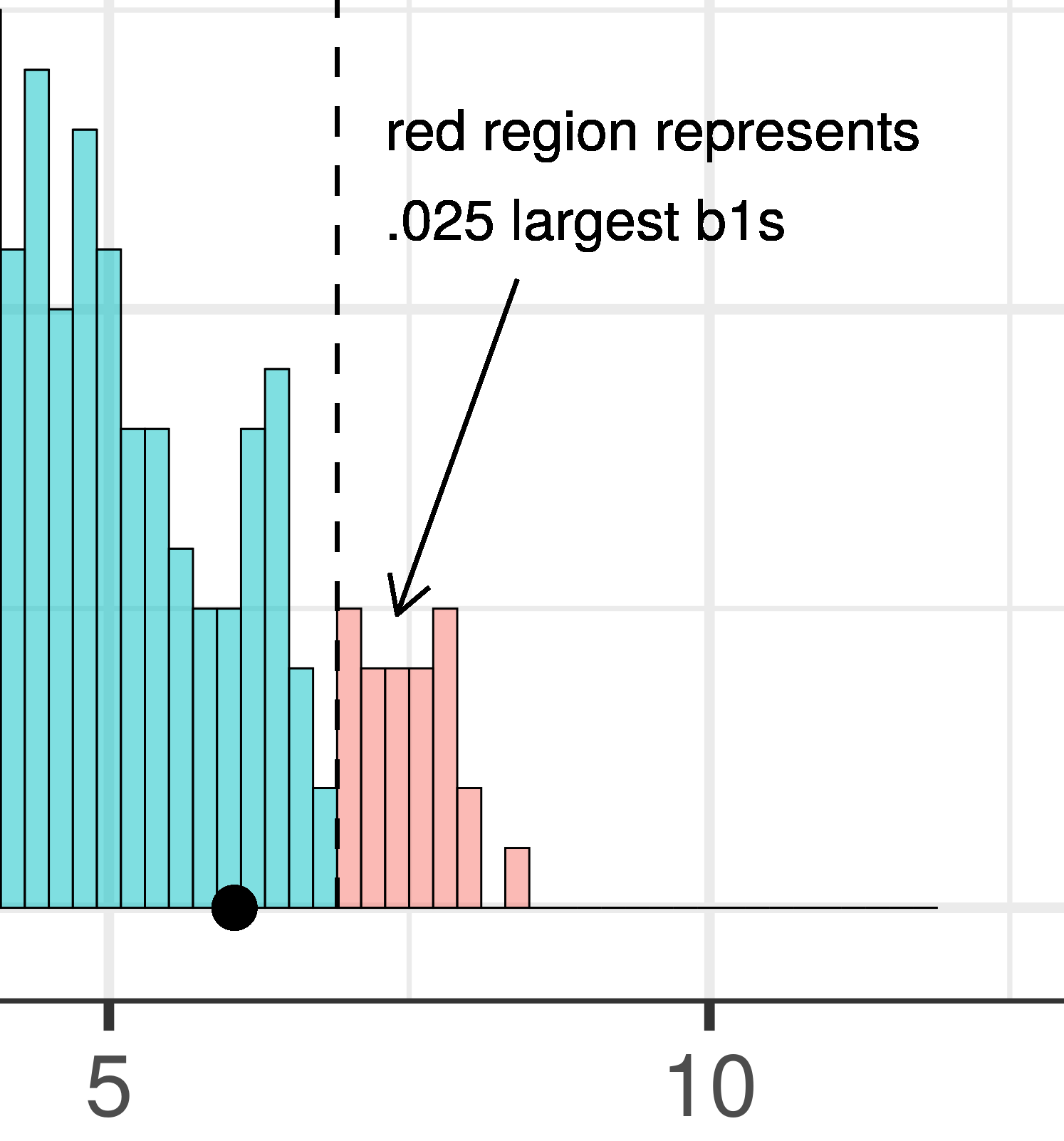

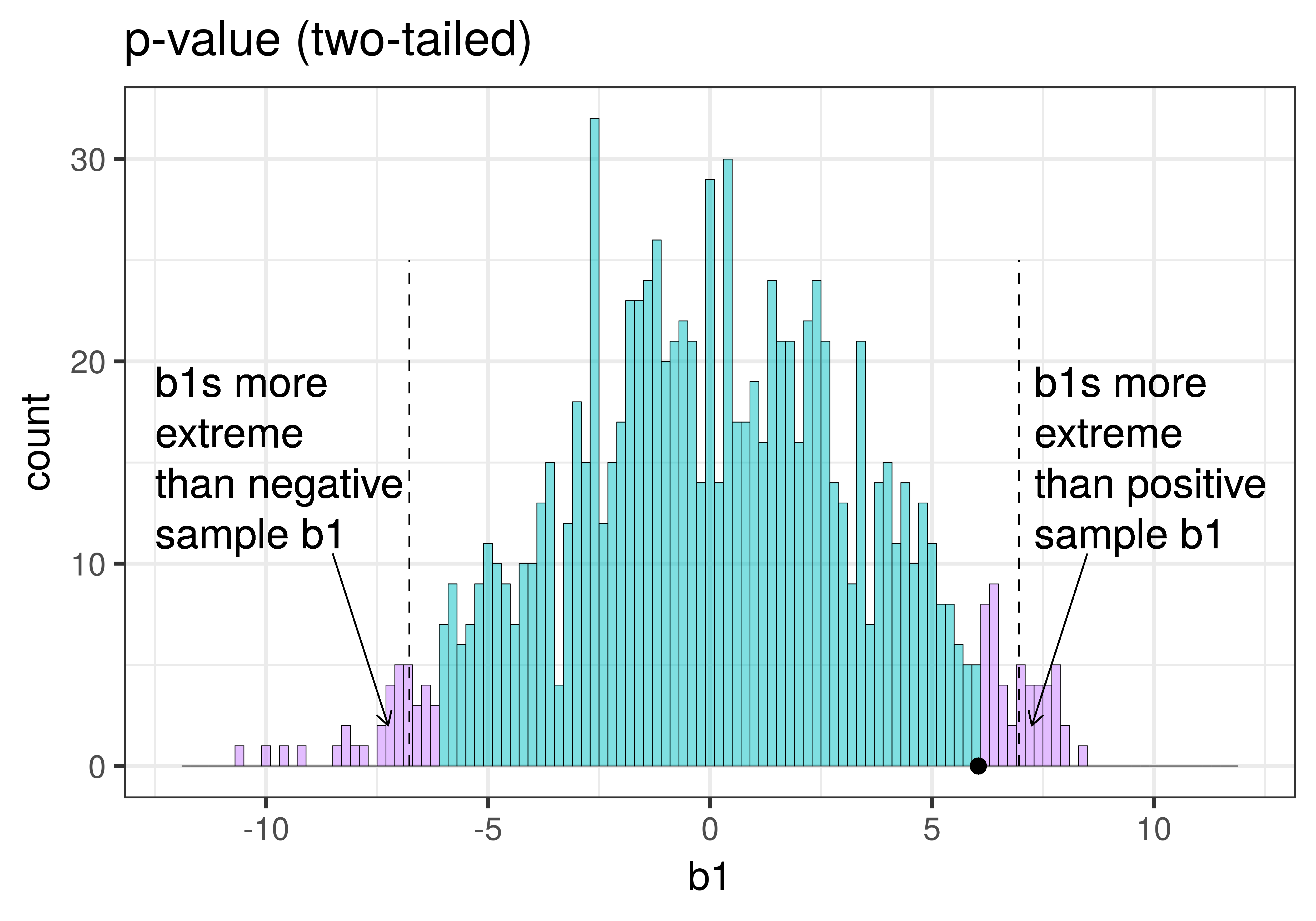
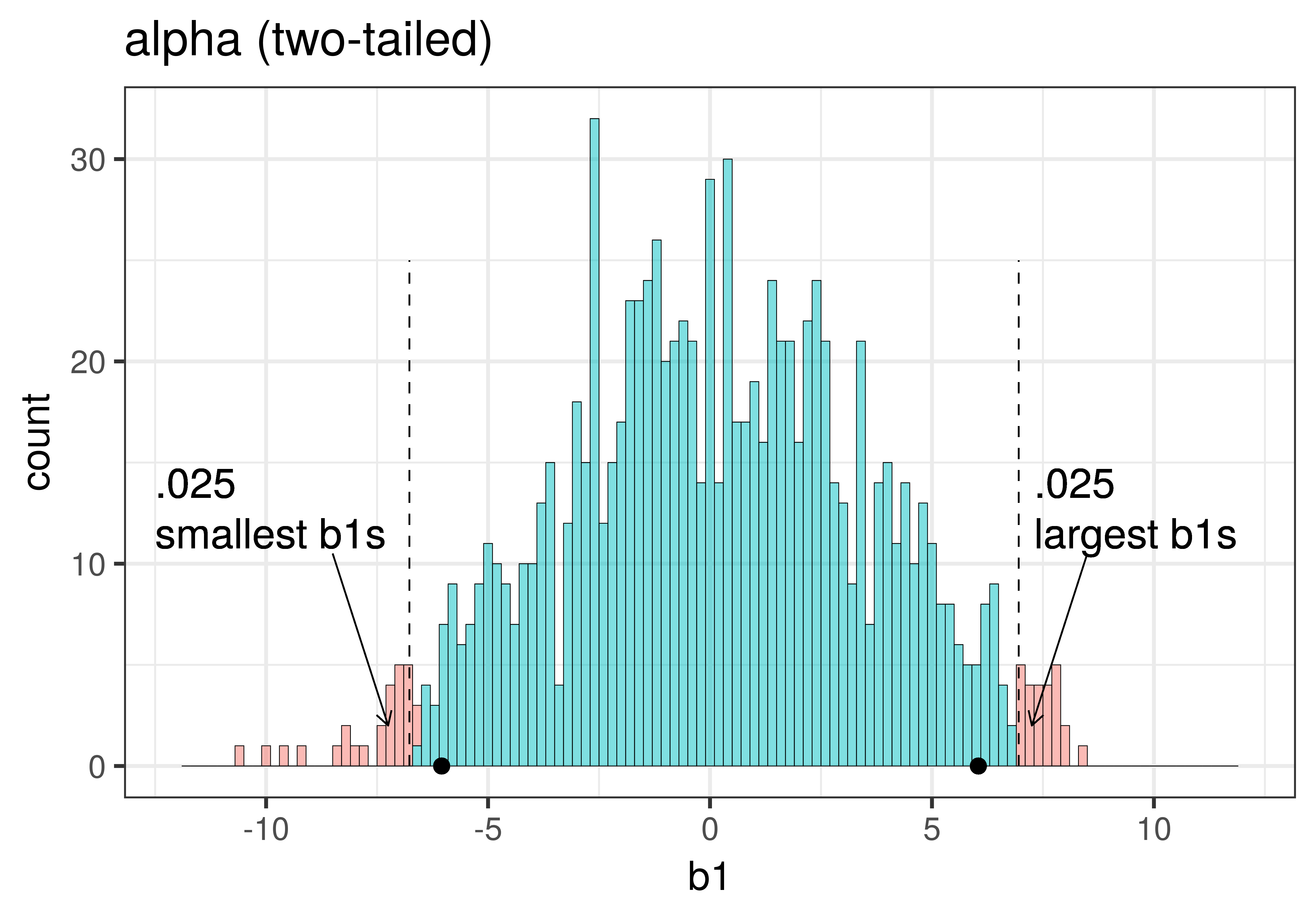
 Όπως φαίνεται στο παραπάνω ιστόγραμμα, ενώ η δειγματοληπτική κατανομή που δημιουργήσαμε με τη συνάρτηση
Όπως φαίνεται στο παραπάνω ιστόγραμμα, ενώ η δειγματοληπτική κατανομή που δημιουργήσαμε με τη συνάρτηση 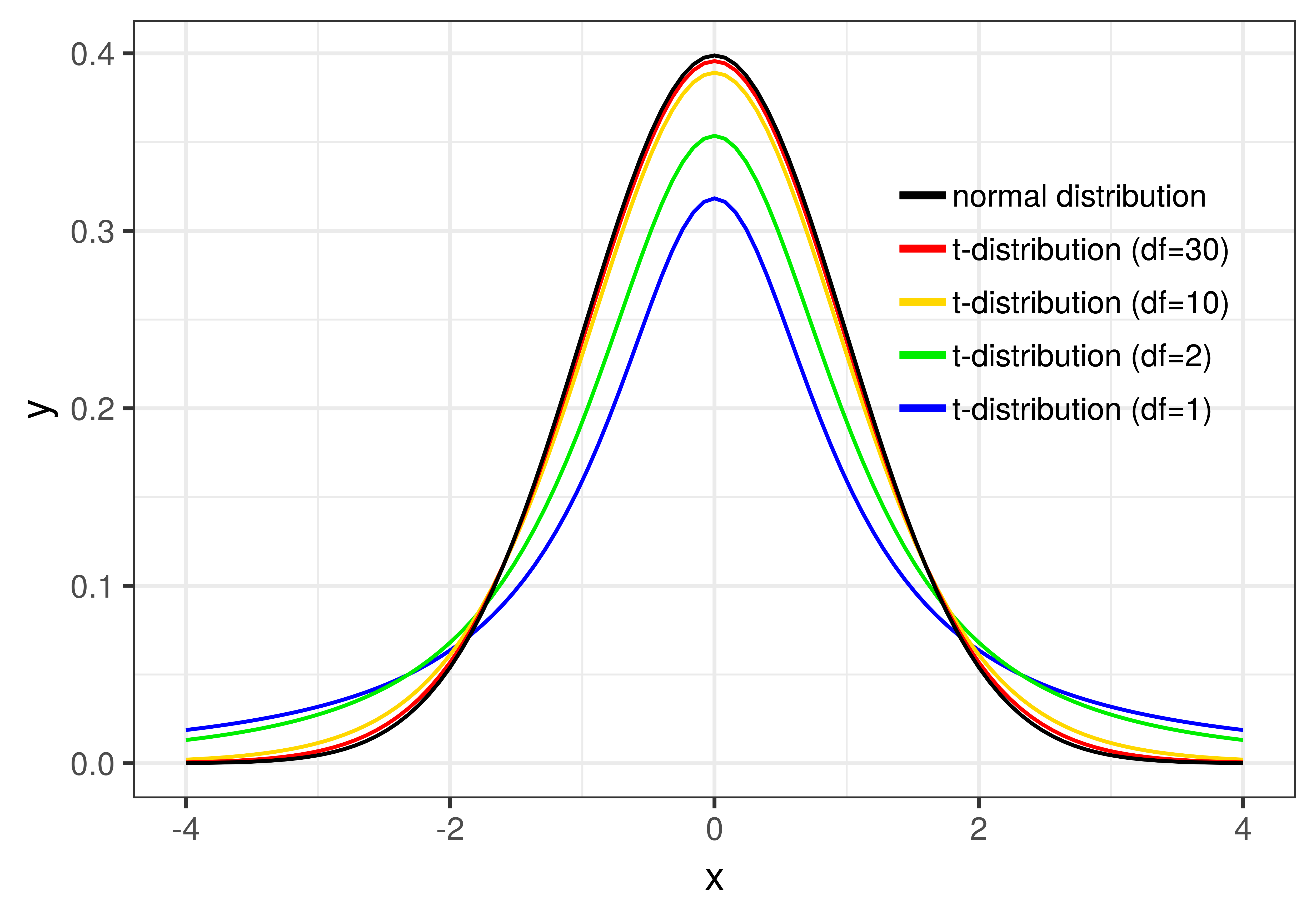
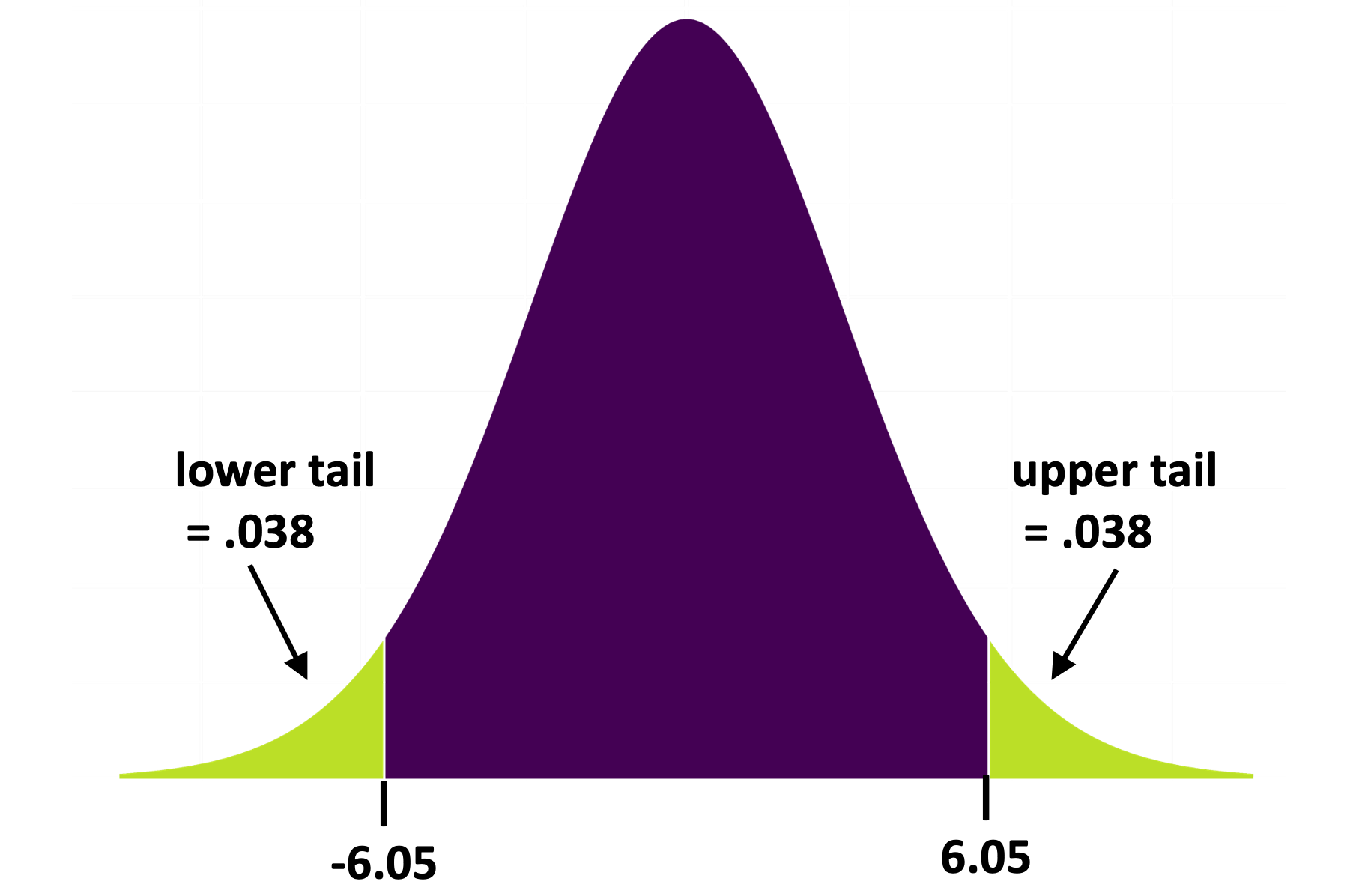 Ακολουθεί ένα διάγραμμα της κατανομής
Ακολουθεί ένα διάγραμμα της κατανομής